この記事は、以前投稿した「Asset BundlesでLakeflow Pipelinesを構築してみる(Databricks Web UI編)」の続編です。
前回はDatabricksのWeb環境(ワークスペース)の方法のみを試しましたが、
今回は、ローカルPC(VSCode)とCLIの方法を試しました。
ローカルPCで開発することで**「コーディングAIの力をフルに活用する」**のが狙いです。
1. 開発・デプロイ・実行フロー
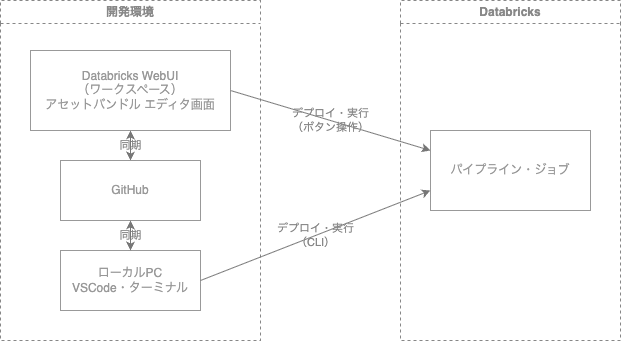
Web UIとローカル開発のフローをまとめると、以下のようになります。
ローカルPCで開発する場合は、CLIコマンドでデプロイ・実行を行います。
Asset BundlesはGit管理し、WebUIとローカルPCの間でGitHub経由で同期します。
| 環境 | 開発スタイル | デプロイ | 実行 |
|---|---|---|---|
| Databricks WebUI | GUIベース(Assistant利用可能) | エディター画面の「デプロイ」ボタン | エディター画面の「実行」ボタン |
| ローカルPC (VSCode) | エディタベース(お好みのAI利用可能) | CLI: databricks bundle deploy
|
CLI: databricks bundle run
|
実際の開発サイクル
- VSCode でコード(SQLやYAML)を書く。
-
ターミナル で
databricks bundle validateを実行して設定ミスがないか確認。 -
databricks bundle deployでDatabricks環境(開発環境等)へ反映。 -
databricks bundle runで動作確認。 - 問題なければ Git へコミット&プッシュして変更を保存。
2. CLIコマンド
ローカル開発で頻繁に使用するコマンドを紹介します。
基本操作
# 設定ファイルの検証
databricks bundle validate
# 開発環境へデプロイ
databricks bundle deploy
# 本番環境へデプロイ(targetが定義されている場合)
databricks bundle deploy --target prod
パイプラインのスマートな実行例
パイプラインのIDをいちいち調べてコピーするのは面倒なので、jq コマンドを使うと、デプロイしたリソースのIDを動的に取得して実行できます。
# パイプラインIDを抽出して即座に実行を開始する
PIPELINE_ID=$(databricks bundle summary -o json | jq -r '.resources.pipelines.ct_de_etl.id')
databricks pipelines start-update $PIPELINE_ID
※ ct_de_etl は resources/ 内に記述したパイプラインのキー名です。
ジョブの実行
# ジョブ名で指定して実行
databricks bundle run sample_job
# パラメータを上書きして実行
databricks bundle run sample_job \
--parameters catalog=custom_catalog \
--parameters schema=custom_schema
おわりに
CLIでAsset Bundlesを試してみて、
狙い通り、WebUIとCLIを両立できることを確認しました。
今後バリバリ使っていきます!