業務でDatabricksを使っています、ikeuchiです
本記事はDatabricks Advent Calendar 2025のシリーズ2の12月7日分です
概要
データエンジニアリング系の新しい機能を試した
- Lakeflow Spark Declarative Pipelines(以降、Lakeflow Pipelinesと記載)
- Databricks Asset Bundles
題材は、過去に個人開発したアプリのデータ分析のための、データの取込・整形とした
Before 従来自分が使用していた方式
- ノートブックを個別で開発
- ジョブを開発環境と本番環境でそれぞれ手動作成
After 今回新たに試す方式
- ノートブックでなくパイプラインを開発
Lakeflow Pipelinesエディターを使用
この開発環境が使いやすそう とくにデータのプレビューやパイプラインのグラフが1つの画面で見れるのが良い!(参考:Lakeflow Pipelines エディタ UI の概要)
従来の方法だと業務で開発メンバーが学ぶ上でハードルが高かったが、これなら馴染みやすそう - 開発環境と本番環境の設定をファイルで一元管理して、自動でジョブ作成
Asset Bundlesを使用
IaCで環境管理をキッチリできる(参考:Databricks アセットバンドルとは)
従来、ジョブのパラメーターの設定が煩雑でミスも発生しがちだったが、これなら改善しそう
補足
- 今回はCLIでなくDatabricks Web UIで実現
ローカル開発してCLIでデプロイするという方法も便利だが、業務で使用する場合には開発メンバーによってはハードルが高いことを考慮
GitHubを使えば、CLIを使うメンバーとWeb UIの共同開発も可能 CLIの方法は今後試してみる予定
公式ドキュメントでは、Databricks Web UIの方は「ワークスペースの」Asset Bundlesと呼ばれている(ちょっと表現わかりにくいかも)
題材、環境設計
データ
ユーザーのアプリ操作ログ
開発範囲
アプリからS3上にエクスポート済みのデータのDatabricksへの取り込み(Bronze)と、
そのデータの整形(Silver)
(その後のGoldレイヤー以降は将来作成予定)
Databricks環境
開発環境(dev)と本番環境(prod)の2つ
Asset Bundlesで環境を選択してデプロイすると、表の通りパラメーターが切り替わって動作するようにした
| S3 bucket | S3 path | カタログ | スキーマ | テーブル | ||
|---|---|---|---|---|---|---|
| 開発 dev | ct-source-dev |
/cloudwatch/... |
→ | ct-dev |
{person name} |
b_cloudwatch, s_cloudwatch |
| 本番 prod | ct-source-prod |
同上 | → | ct-prod |
prod |
同上 |
(ct: アプリ名)
開発と本番の環境分離方法としては、ワークスペースで分ける方法もあるが、今回はカタログで分離
実施内容詳細
0. 事前準備
0.1. 外部ストレージ設定
データ取込元のS3バケットをDatabricksで外部ストレージとしてマウント
0.2. カタログ作成
開発環境と本番環境それぞれのカタログを作成
- ct_dev
- ct_prod
0.3. Gitリポジトリー作成(GitHub)
リポジトリー名:ct_de
(de:データエンジニアリングの略称とした)
1. GitフォルダーとAsset Bundlesの作成
Asset BundlesはGitフォルダーの中に作成(テンプレートはLakeflow PipelinesのSQL)
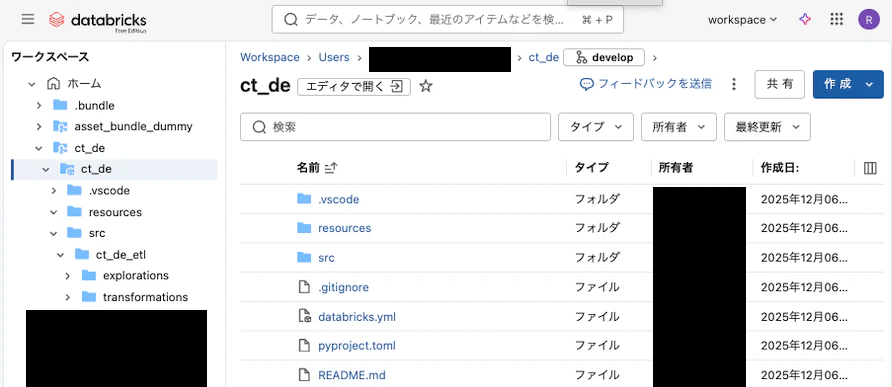
↑Gitフォルダー名とAsset Bundles名が同じ(ct_de)なのでちょっとややこしい
↑2026/01/22追記)1つのフォルダーにできました、その方が良いです(Gitフォルダー兼Asset Bundlesフォルダー)
2. 環境設定ファイルの編集
編集対象:databricks.yml
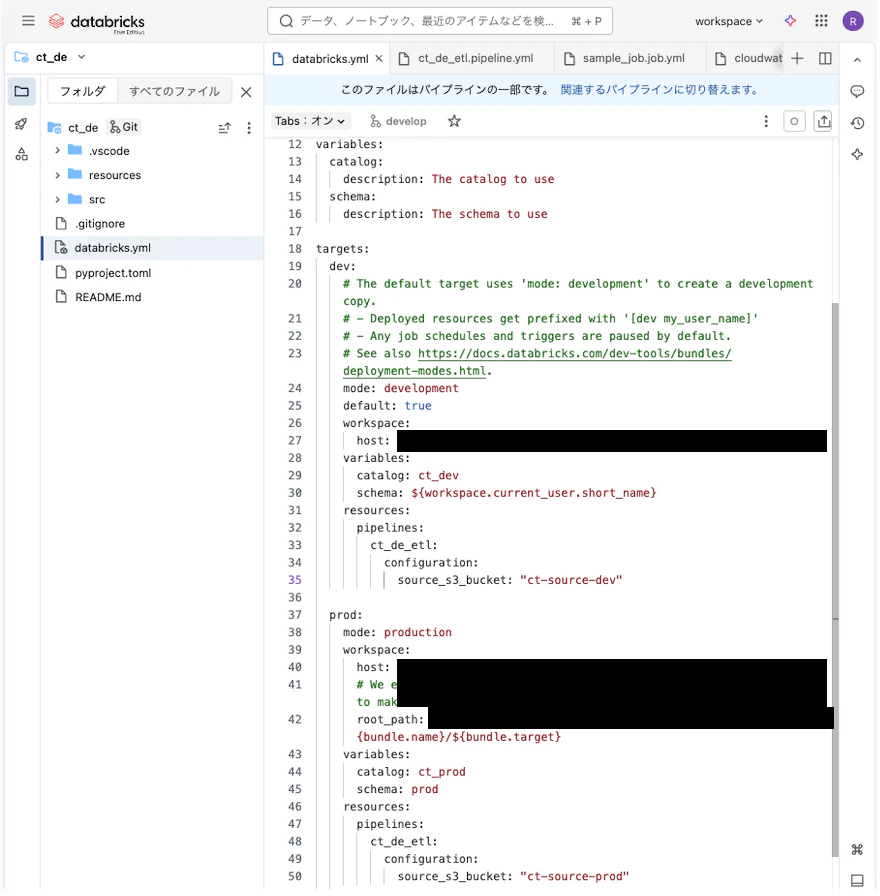
カタログ、スキーマ名
targets.{dev/prod}.variables.catalogに設定する
(テンプレートですでにデフォルト値が記載されているので編集するだけ)
S3バケット名
targets.{dev/prod}.resources.pipelines.{pipeline_name}.configuration.source_s3_bucketに設定する
(テンプレートではresources自体がなかったので追加)
当初この方法が分からず苦戦した 下記の通りGeminiで調査し、実際に試して動作した
参考)Gemini回答:
公式情報とドキュメント
この構成は、以下のDatabricks公式ドキュメントでサポートされている機能の組み合わせです。
Databricks Asset Bundles のターゲット設定
DABsでは targets を使用して、環境ごとにリソース定義(ここではPipelineのconfiguration)をオーバーライドできることが記載されています。
参考: Databricks Asset Bundles の設定 - Targets
Delta Live Tables (Lakeflow) のパラメータ化
DLTパイプライン設定の configuration フィールドでキーバリューペアを定義し、SQLクエリ内でそれらを使用できることが記載されています。
参考: Delta Live Tables パイプラインのパラメーター化
3. データ更新処理のプログラム作成
transformationsフォルダーの中のSQLファイルを編集
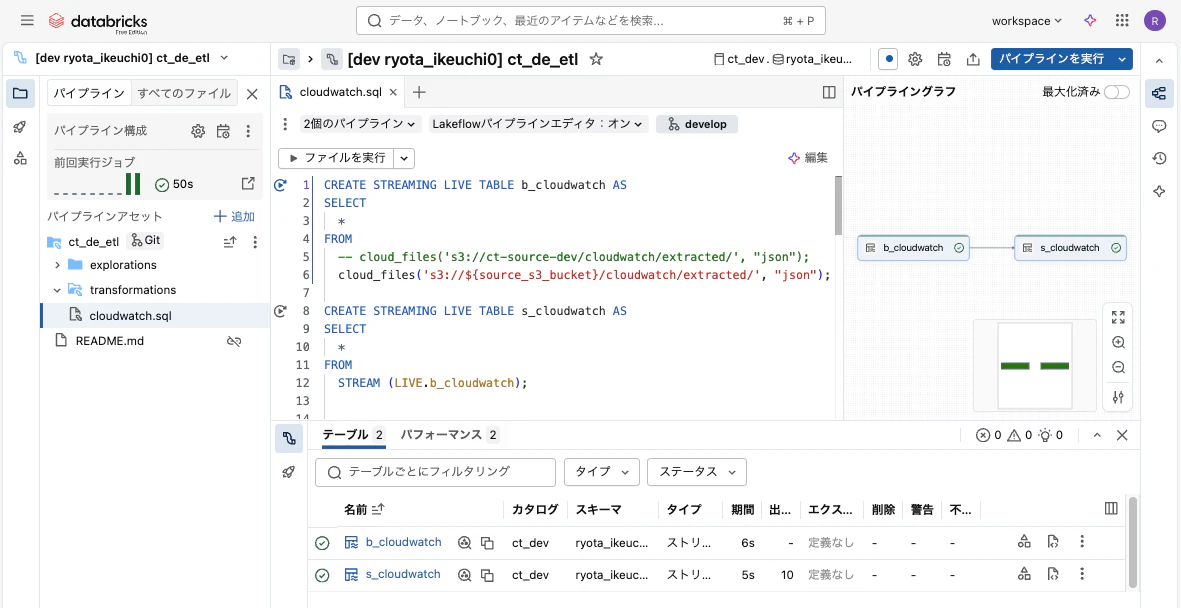
(↑Lakeflowパイプラインエディターの画面)
Bronzeではそのままの形で取り込み、
Silverではパースする予定だったが今回はひとまず簡易的にBronzeそのままとした
Lakeflow Pipelinesのお作法はまだまだ勉強中("STREAMING LIVE TABLE"など)
環境設定の反映
- カタログ、スキーマ名:SQLファイル上で指定しない(=テーブル名のみを指定する)ことで、databricks.ymlの設定が反映される
- S3バケット名:SQLファイル上で${source_s3_bucket}と記載することで、databricks.ymlの設定が反映される
ただし!Lakeflowパイプラインエディターで実行するときにはこの反映がされず、空文字になってしまうかも?or 一度デプロイしたら反映される?まだここは調査中・・・(上の画像ではハードコーディングをコメントアウトして残している)
4. デプロイ
ターゲットのdev or prodを選択して、デプロイボタンをクリックする
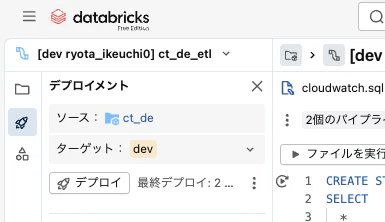
これでパイプラインが作成される
devのパイプライン名は、接頭語に[dev {person_name}]がつく
5. パイプラインの実行
「パイプラインを実行」ボタンをクリック
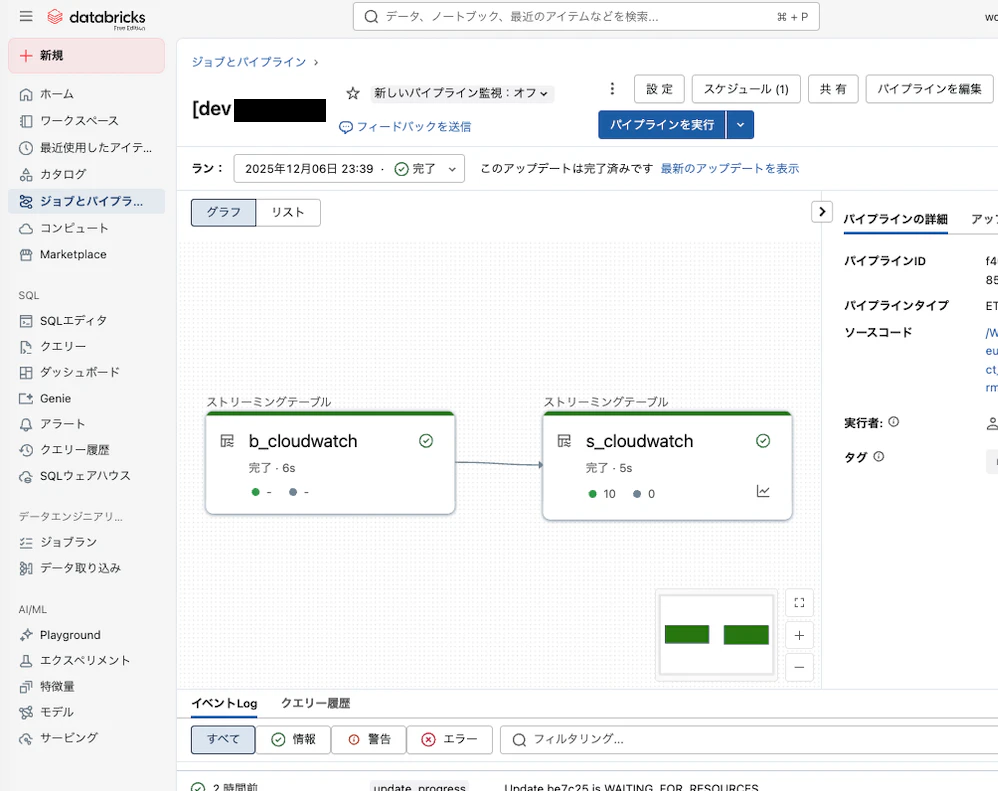
その後、カタログ画面にて、BronzeとSilverのテーブルが作成されていることを確認
6. ジョブの実行
パイプラインと共にジョブもデプロイ済みのはずですので、実行して動作するはず(今回は確認省略)
おわりに
一通り動かすことができました 業務でも便利に使えそう!
Asset BundlesやLakeflow Pipelinesの概念を理解するのが難しく苦労しましたが、
Databricks Academyなどのおかげでここまで来れました 感謝!
今後:
- Lakeflow Pipelinesの勉強を進めて、より本格的に開発する
- CLIでのAsset Bundlesも試してみる
Databricks Advent Calendar 2025のシリーズ2、明日は @soonraah さんです!