追記:
Lucene/Solr Advent Calendar 2014で Lucene 開発者 Mike さんの FST 関連のブログを@moco_beta さんが翻訳してくださっているので,ご紹介しておきます.この記事では解説していない Lucene への導入の背景とか解説されてます ![]() (期せずしてコラボできて感謝です
(期せずしてコラボできて感謝です ![]() )
)
- 22日目:[翻訳] Using Finite State Transducers in Lucene
- 23日目:[翻訳] Finite State Transducers, Part 2
- 24日目:[翻訳] Lucene’s FuzzyQuery is 100 times faster in 4.0
この記事は Go Advent Calendar 2014 19日目の記事です.
- Luceneで使われているFST(有限状態変換機)の構築方法
- FSTを Virtual Machine として実装する方法
についてお話しします.
FST 自体は go とあんまり関係ないんですけど,FST の実装方法を通して最後に go の正規表現エンジンのアプローチについてふれますので,最後までおつきあいいただければと思います.
はじめに
FST というのは Finite State Transducer (有限状態変換機) の略で,有限オートマトンに出力がついたものです.変換機とか言うと小難しい感じがするかもしれませんが,文字列を入力として,文字列を返す単純な機構です.(機能としては map[string]string みたいなものです).
Lucene では FuzzyQuery の処理を FST で書き直して100倍早くなりました.(@moco_betaさんのLucene/Solr Revolution 2014参加報告でもふれられています).また Apache版の形態素解析器 kuromoji の辞書も FST で構築されています(注:atilika版の kuromoji 辞書は Double Arrayです).省メモリで高速な処理が求められるときにわりと汎用に使えることが特徴です.
FSTの例:
| input | output |
|---|---|
| apr | 30 |
| aug | 31 |
| dec | 31 |
| feb | 28, 29 |

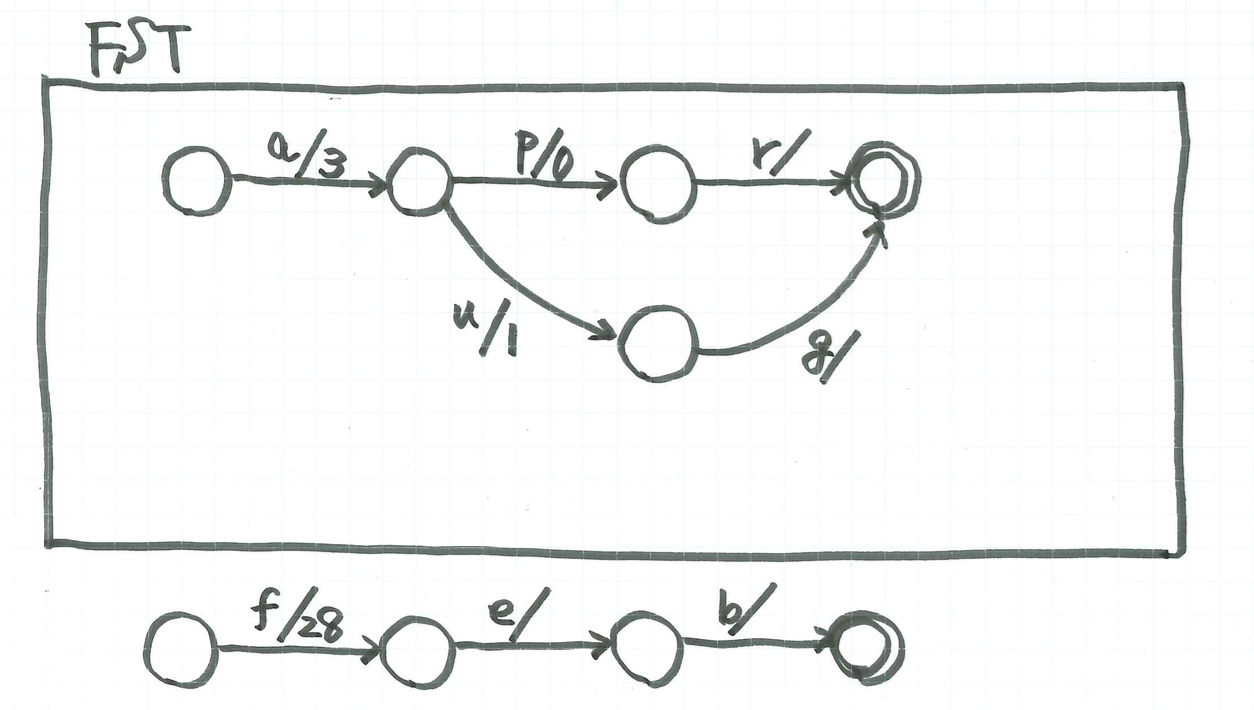
入力と出力のペアに対して,上のようなグラフを作るのが目標です.テーブルの出力のとこは数字が書いてありますが,文字列だと思ってとらえて下さい.map だと出力は1つに限られちゃいますが,ひとつの入力に対して出力が複数あってもいいです.たとえば入力 "feb" に対して,出力は "28" と "29" があります.(2月は28日と29日のときがありますね).
ノードの部分が状態で,そこから出ている矢印が状態遷移になります.矢印には a/b というラベルがついていますが,a の部分が入力とのマッチを意味し,b の部分がそのときの出力を意味します.
上の例で示すFSTで,"aug"を処理するには,"aug"を頭から読んで,入力"a"に対応するの(9)から(3)への矢印を選択します.そのとき,出力として"3"を記録しておきます.そのあと,"u"に対して(3)から(2)への矢印を選択し,"1"を先ほどの出力の末尾に加えます.同様に"g"に対して(2)から(0)への矢印を選びます.このとき出力は何もないので,なにも出力されません.入力がすべて読み終わったときに2重丸の状態にいるときに,これまで記録してきた出力を返します."3","1"と書き込んできたので,結果として"31"が返ります.
このように迷路をたどるように,入力に対して出力を計算して,最後に2重丸の状態にたどり着いていれば,出力,2重丸の状態にたどりつけなければ,何も出力しないという動作を行います.
この辺の仕組みを詳しく知りたいようでしたら,以下の本とかを参考にして下さい.
- 安定の Hopcroft, Ullman :オートマトン言語理論 計算論〈1〉
- 笠井先生と岩田先生の:有限オートマトン入門
- 富田先生の : オートマトン・言語理論
でも,とりあえず,これだけ分かってればこの後も特に困らないはず.
Lucene で使われている FST
Lucene で使われている FST は,ただの FST ではなくて,正確には Minimal Acyclic Subsequential Transducer というものです.このオートマトンはいい性質を持っているので,非常に扱いやすいです.
- 入力をソートしておく必要があるが,構築が簡単
- 構築した FST は決定性 (入力に対して次の状態が一意に決まる)
- 状態数が極小
- TRIE木みたいな形で,prefix を共有しつつ,suffix も共有する (要するに省メモリ)
- 出力する文字列も共有する (とっても省メモリ!)
- つくられるグラフは有向非巡回グラフなので,ノードをトポロジカルソートできる
よくオートマトンを構築するとき,たとえば,正規表現をオートマトンにするときなんかは,非決定性のオートマトンを構築して,決定性のオートマトンに変換して・・・とかいう話になりがちですが,この Minimal Acyclic Subsequential Transducer (以下,単に FST) は構築方法に従って作れば,それで終わりです.いろいろやる必要はありません.
FST を構築する
アルゴリズムは,この論文を参照して下さい.定義と証明が複雑ですが,アルゴリズムのところは非常に簡潔にまとまっているので,アルゴリズムのところだけ抜き出して読めると思います.
アルゴリズムは非常にシンプルです.簡単に解説だけ.
- 入力と出力のペアを入力でソートしておきます.
- 入力を順番に処理していきます.
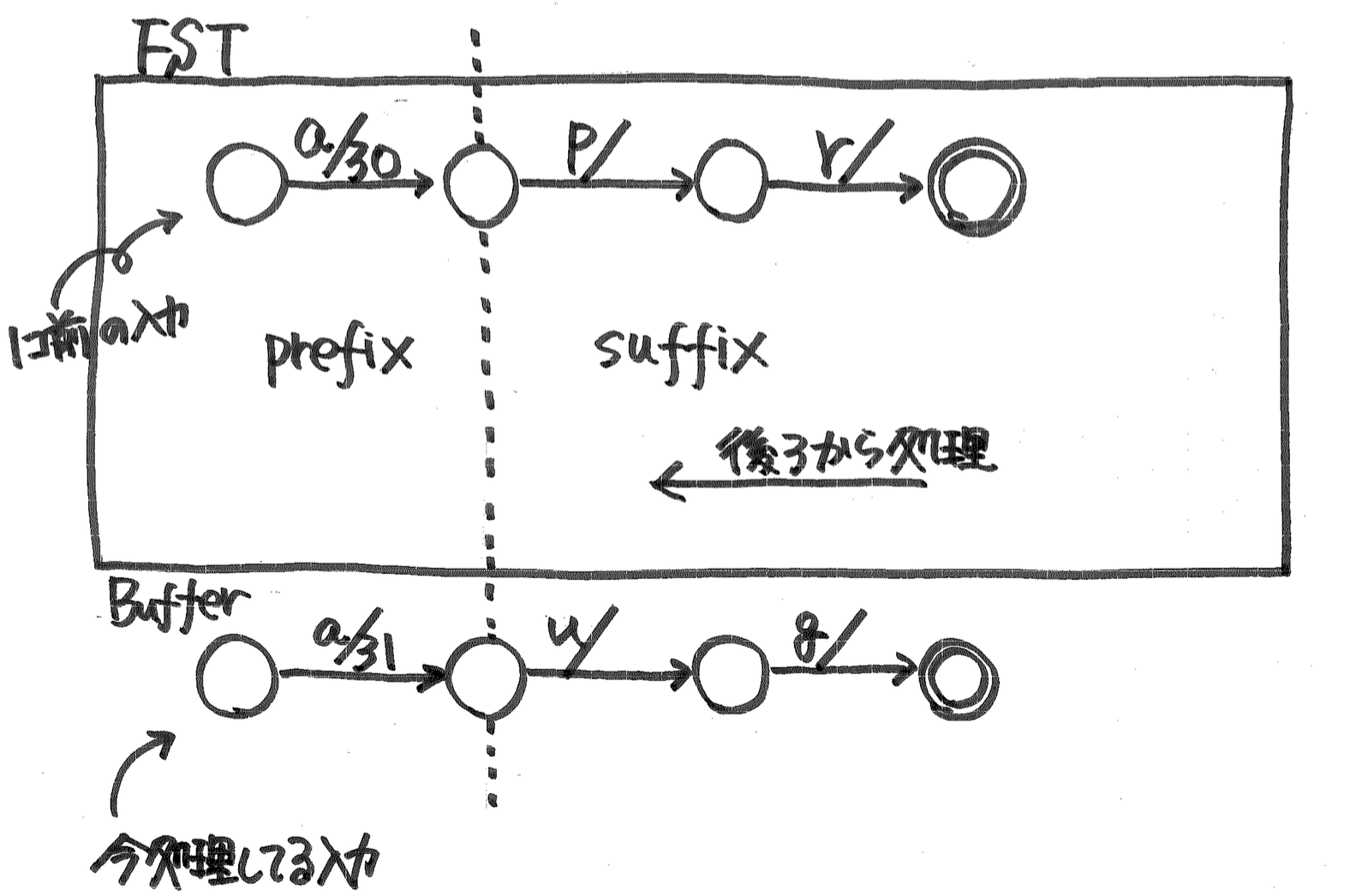
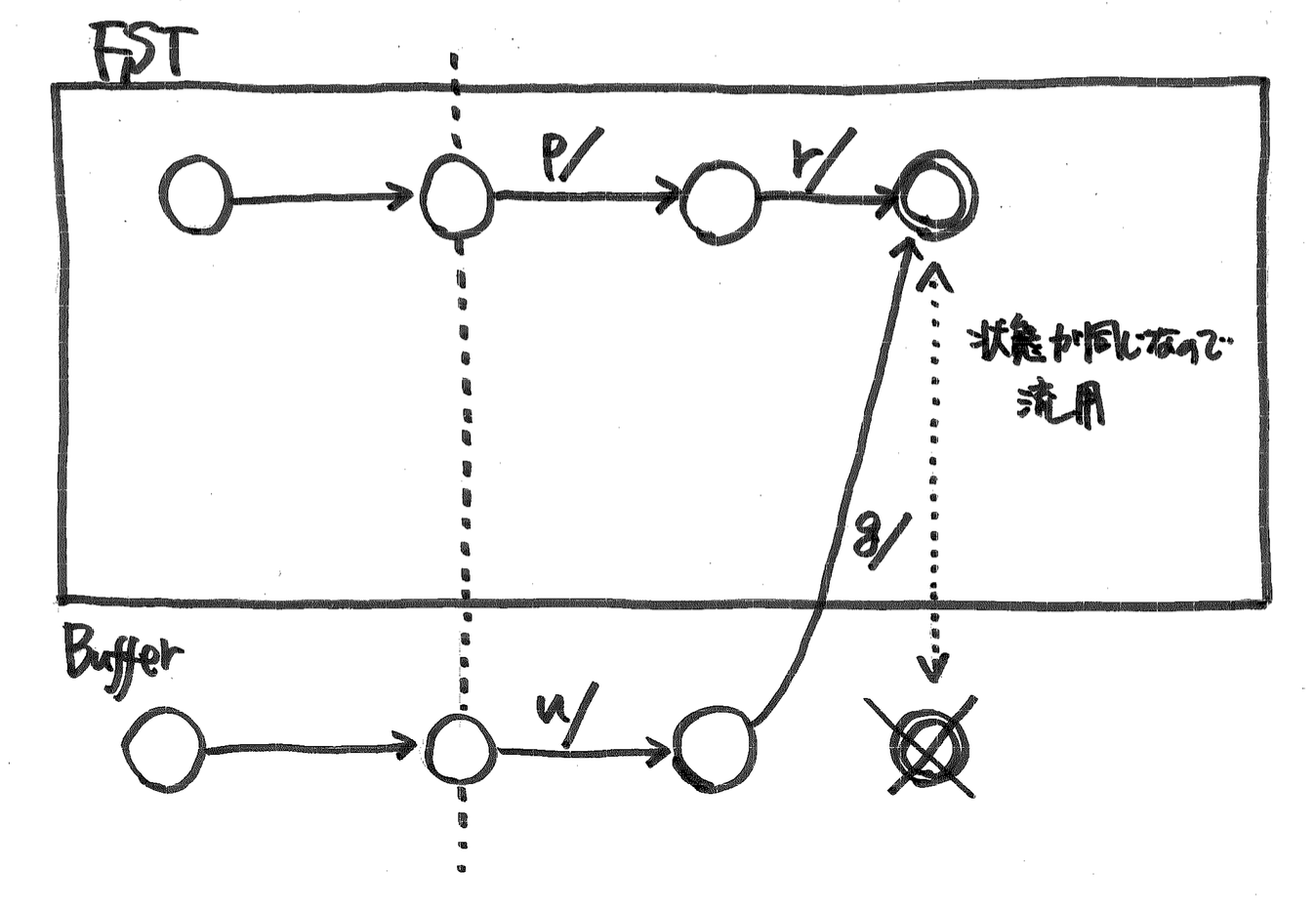
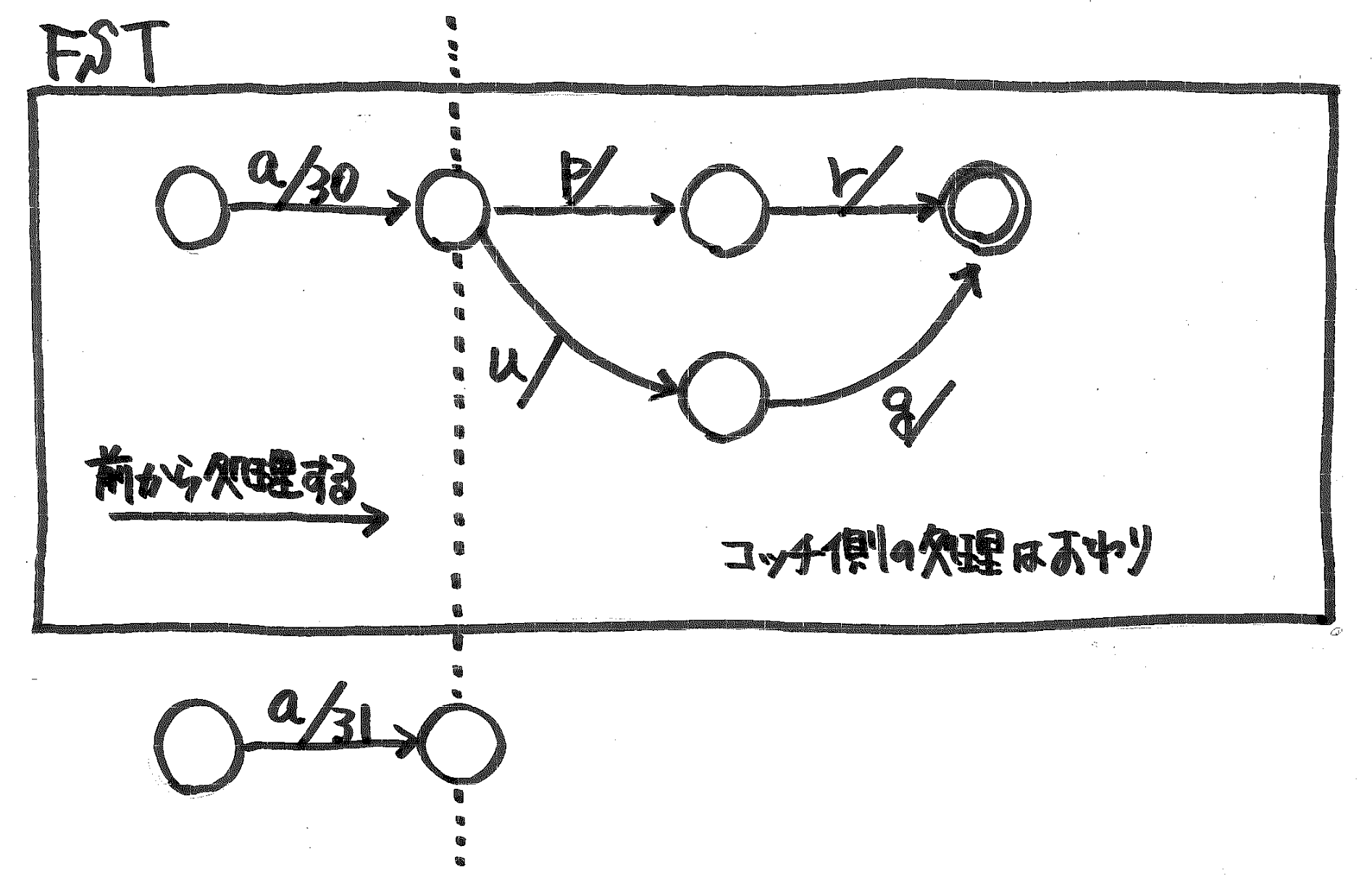
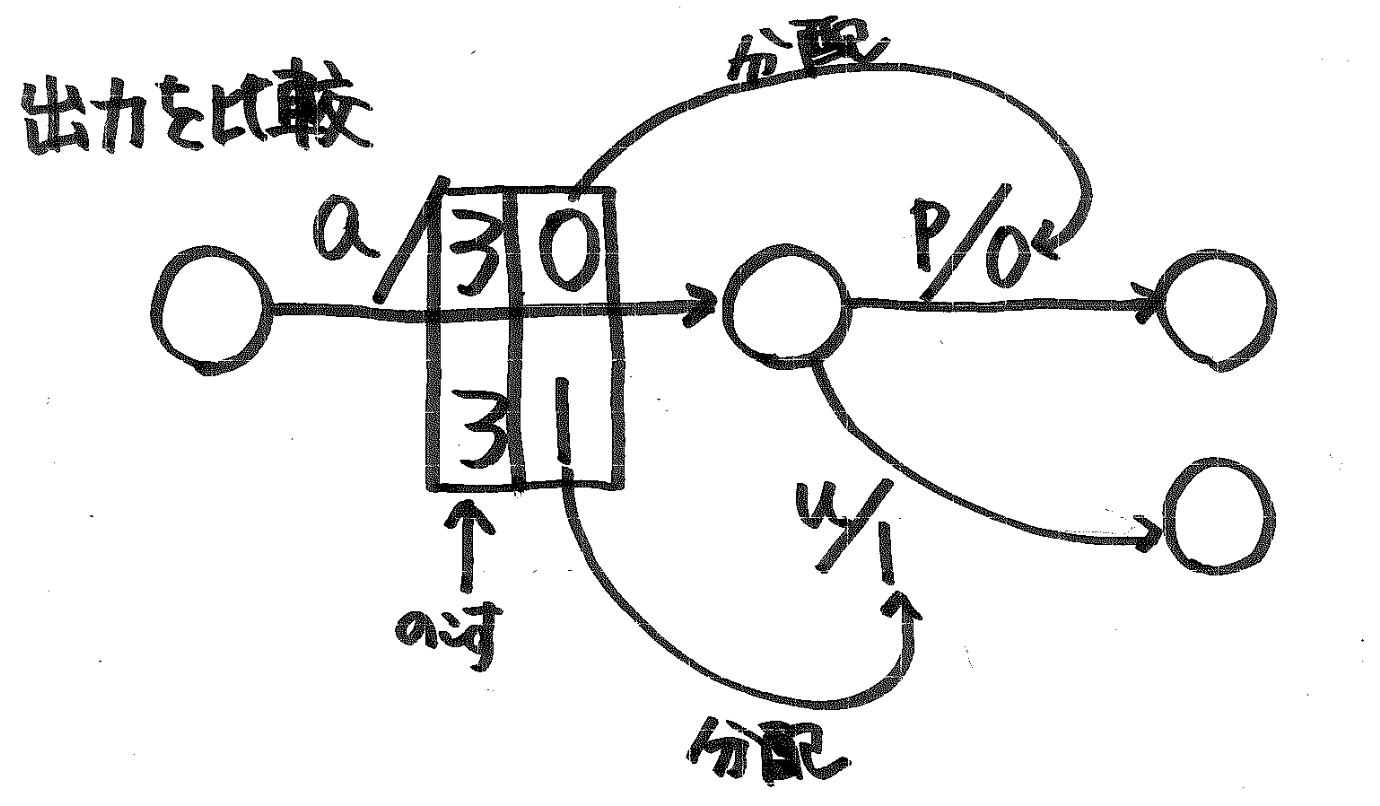
- 今処理している入力と,ひとつ手前に処理した入力を比較 prefix と suffix を計算する.
- suffix を今まで構築したグラフに加える.ただし,同じ状態のものがあれば,それを流用する.
- prefix に対して,今まで構築したグラフの対応する部分を頭から順番にたどっていく.
- グラフにもし出力があれば,今処理しているペアの出力との prefix, suffix をとって,prefix でグラフの出力を置き換える.suffix 部分は状態から出ている辺の出力にくっつける.
こんな感じです.
例:apr / aug の処理
(1)
(2)
(3)
(4)
(5)
FST を簡単なアセンブリ言語に置き換えて Virtual Machine で実行する
FST を構築することが出来ました.でもこれはまだモデルを実直に表現しただけという段階です.これを実装に落とします.うまく説明できないんですが,TRIE と Double Array の関係に似てるかな,と思います.TRIE がモデルとすると,Double Array がその実装という対応です.FST を落とし込む先はオレオレ アセンブリ言語です.
最初に例に出した FST を次のようなアセンブリに置き換えます.先ほど,今作ってるこの FST の性質に触れましたが,この FST は有向非巡回グラフなので,どのノードもその出力辺の先のノードより前にくるように並べることができます.なので,このアセンブリ言語は上から下に順になめていくだけで下から上に戻ってループしたりすることがありません.一方向に読むだけです.
0 OUT a 8 "3"
1 OUT d 2 "3"
2 OTB f 0 8
3 BRK e 1
4 BRK b 1
5 ACC 4 8 "8\09"
6 BRK e 1
7 BRK c 5
8 OUT p 3 "0"
9 OTB u 1 "1"
10 BRK g 2
11 BRK r 1
12 ACC
| op | arg1 | arg2 | arg3 | 意味 |
|---|---|---|---|---|
| OUT | ch | jump | str | 現在の入力が ch と一致するならプログラムカウンタ(PC)をjump増加させstrを出力する.一致しない場合はPCを1増やす |
| OTB | ch | jump | str | OUT命令と同じ.ただし入力が一致しないときはプログラムを終了する |
| BRK | ch | jump | --- | 現在の入力が ch と一致するならPCをjump増加させる |
| ACC | --- | --- | --- | プログラムを終了する |
オレオレアセンブリが出来たら,これをバイトコードに落とし込みます.バイトコードへの落とし込み方は,たとえば下の図みたいにします.命令の種類,ラベル,アドレスなどをうまく詰め込みます.設計はオレオレで大丈夫です.オレが考えた最強のバイトコードを作って下さい.
BRK命令
0 1 2 3 4 5 6 7 8 bits
---|---|---|---|---|---|---|---|---|
0 | <op> | <size> |
---|-------------------------------|
1 | <ch> |
---|-------------------------------|
2 | <jump> |
---|-------------------------------|
<op>: 命令, <size>: jump を表現するのに何バイト必要か,
<ch>: 入力と比較するchar, <jump>: jump
そして,これを実行する Virtual Machine を用意します.といってもたいしたものではなく,アセンブリ言語を実行するのと同じ要領で,バイトコードに落とした命令を実行していくだけです.
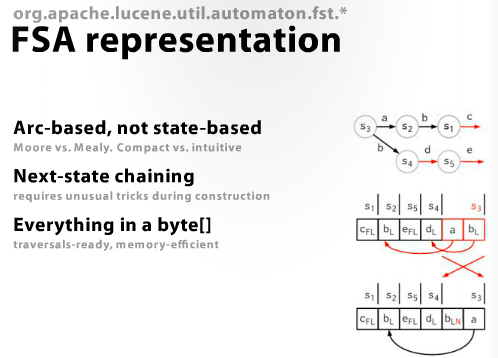
ちなみに,Lucene での実装イメージはこんな感じらしいです.
Finite State Automata in Luceneのスライドより引用.(といいつつ,Lucene のコードは読んでないので詳しいことは分からんです)
Double Array と比較してみる
ここまでくると,性能も気になると思いますので,みんな大好き Double Array と比較してみたいと思います.Double Array は Tail配列とかないオーソドックスな素朴実装です.なので,先に言っておきますが Double Array には不利な条件です.比較の基準が欲しいと云うことなんでお許しください.
Double Array は文字列から数値へのマッピングなので,FST の方も条件をそろえて文字列から数値へのマッピングに修正します.出力する数値を1文字しかない文字列だと思えばいいわけなんで,おおむね処理は同じです.
データは mecab 辞書の見出し語を使って,Double Array と FST を構築して,処理速度を比較してみました.
BenchmarkFstSearch01 1000000000 0.28 ns/op
BenchmarkDaSearch01 2000000000 0.02 ns/op
あれ,10倍以上遅い・・・やっぱり,1byteずつ読むのは効率が悪いみたいです.
ちょっと実験.バイト列を8つごとに int64 相当だと思って数値を取り出すコードを書いて速度を比較してみます.ひとつは1byteごと読んで,値をシフトしながら足す方法.もう一つは,バイト列のポインタを持ってきて,直接 int64 に代入する方法です.
package main
import (
"fmt"
"unsafe"
)
const chunkSize = 8
func test1(tape []byte) int64 {
var v int64
for i := 0; i < len(tape); i += chunkSize {
for j := 0; j < chunkSize; j++ {
v <<= 8
v += int64(tape[i+j])
}
}
return v
}
func test2(tape []byte) int64 {
var p unsafe.Pointer
var v int64
for i := 0; i < len(tape); i += chunkSize {
p = unsafe.Pointer(&tape[i])
v = *((*int64)(p))
}
return v
}
func main() {
tape := make([]byte, chunkSize*1024)
for i := range tape {
tape[i] = byte((i % chunkSize) + 1)
}
// エンディアンの関係で返ってくる値が違うけどいまはそこ問題じゃないので無視
fmt.Println(test1(tape))
fmt.Println(test2(tape))
}
BenchmarkTest1 200000 8178 ns/op
BenchmarkTest2 5000000 653 ns/op
1byte ずつよんでちゃダメですね.
計算機によって異なるとは思いますが,アライメントを考慮して,(無難に)4バイトずつ読み込むようにチューニングしてみました.お行儀が悪いですが,unsafe.Pointer をつかってバイト列に数値を直接書き込んだり,逆に命令を読み込んだりします.
BenchmarkFstSearch01 2000000000 0.02 ns/op
BenchmarkDaSearch01 2000000000 0.02 ns/op
Double Array と同等の速度になりました ![]()
メモリ使用量はどうでしょうか.
| 手法 | メモリ使用量 |
|---|---|
| Double Array | 約10MB |
| FST | 約1MB |
おお,1/10 になってる!って,これはこのスライドのp.20でもkuromojiの辞書が11.8倍小さく出来たって述べられてたりします ![]() .やってみるまでは,ほんまかいなと半信半疑だったんですが,どうやら本当のようです(そりゃそうだ).
.やってみるまでは,ほんまかいなと半信半疑だったんですが,どうやら本当のようです(そりゃそうだ).
go の正規表現エンジンは Virtual Machine Approach
ここまで,ひたすら FST の話をしてきましたが,やっと go の話が出来ます.実は,go の正規表現エンジンは,オレオレ アセンブリ言語を作って,それを VM で動作させるという方法で実現されています.Ken Thompson が自分のエディタに正規表現の機能を持たせようと思ったときの実装がまさにそれで,正規表現を非決定性オートマトンに落として,オレオレ アセンブリ作って,それを実行する VM を用意するって感じで動作します.この方法のどこがいいかというと,オレオレ アセンブリなので必要に応じて命令を追加して,処理の途中で何かするという拡張が簡単に行えることです.
僕も前職で,オレオレ拡張な,文字列と形態素混じりの正規表現が書けるエンジンを作ったりしました.
正規表現の場合は非決定性のオートマトンをシミュレートするので,OR で分岐したときとかは,深さ優先で行くか,マルチスレッド的にプログラムカウンタを増やして並行に処理していく(幅優先でいく)かといった戦術が選べます.詳しくは
Russ Cox, Regular Expression Matching: the Virtual Machine Approach, 2009.
を参照ください.
regexp には machine なんて構造体が用意されてます.
36 // A machine holds all the state during an NFA simulation for p.
37 type machine struct {
38 re *Regexp // corresponding Regexp
39 p *syntax.Prog // compiled program
40 op *onePassProg // compiled onepass program, or notOnePass
41 q0, q1 queue // two queues for runq, nextq
42 pool []*thread // pool of available threads
43 matched bool // whether a match was found
44 matchcap []int // capture information for the match
45
46 // cached inputs, to avoid allocation
47 inputBytes inputBytes
48 inputString inputString
49 inputReader inputReader
50 }
ほんとはこの辺を調べてまとめようと思ってたんですが,
Goのregexpネタは僕がアドベントカレンダーで書く予定です(牽制)
— Yoshifumi YAMAGUCHI (@ymotongpoo) 2014, 12月 9
とけん制されてしまったので,@ymotongpooさんの記事を楽しみに待ちたいと思います〜 ![]()
おわりに
「pure JavaScript で kuromoji clone な形態素解析器書く!」といった知人に触発されて,じゃぁ go やってみたいから俺は go で形態素解析器書いてみる,となかば冗談で作り始めてみたんですが,go 使ってみると想像以上にプログラミングが楽しく,形態素解析器(kagome)もなんとか完成までもってこれました.はたから JavaScript で組んでるのを見て,go を使えばもっと幸せになれるのに・・・と思ってましたが ![]()
ちなみに pure JavaScript で動く kuromoji.js (atilika公認)も完成してます.takuyaa おそろしい子Σ(꒪д꒪;||)
僕が作ってる FST はまだまだ実験中の状態ですが何かの参考になれば,ということでさらしておきます.うまくいったらkagome の辞書も FST で置き換えてみようかな〜と思っています.
みなさんもオレオレな VM を go で書いてみて下さい.
| package | 説明 |
|---|---|
| mast/ss | 文字列から文字列への変換.遅い |
| mast/si | 文字列から数値(int)への変換.遅い |
| mast/si32 | 文字列から数値(int32)への変換.メモリのアライメント考慮.速度はDouble Array 相当 |