前書き
Databricksにdbtのネイティブアダプターが登場しました。
dbtは国内での知名度はまだまだ高くありませんが、DataOpsの中核コンポーネントとして個人的に期待しているツールです。dbtは例えば、データ加工の流れ(リネージュ)の記録、データモデルのドキュメントの生成、単体テストとは別の観点でデータ品質を自動テストする等、様々な機能をシンプルなSQLとYAMLの設定ファイルで実現することができます。
それのどこが便利なの?というのがなかなか伝わりにくいツールな気もするので、実際に動かしながらdbtの良さを噛みしめていこうと思います。
こちらの記事は、dbt Core integration with Databricksを参考にして、記載しています。
環境
Windows 10 Enterprise (version: 1909)
Visual Studio Code (version: 1.62.3)
Python 3.8.8
DataOpsとは
ガートナー社の発表するハイプサイクルの2018年年版に登場したのがはじまりと言われています。
DevOpsなどのxOpsの流れから生まれた潮流で、私は「データに関する関係部門間の知識・技術・考え方のギャップを埋めて、運用を自動化することによって協力体制を築いていこう」という考え方だと認識しています。
特に、データサイエンティスト・データエンジニア・データオーナー(ビジネスドメインを有している専門家)の3者間ですね。
技術的な要素としては以下のようなもので構成されるものです。
- ETL/DWH
- データカタログ
- データリネージュ
- データ品質の自動テスト
- データ品質のモニタリング・異常検知
- ジョブオーケストレーション/スケジューリング
dbtについて
dbtは、オープンソース版のdbt Coreとクラウドサービス版のdbt Cloudがあります。
dbt Coreは、SQLとYAMLファイルで構成されたdbtプロジェクトとCLIツールを通してDatabricksやsnowflake, bigqueryなどのDWHにクエリしてテーブルやビューを作成します。
dbt Cloudは、dbt Coreに加えて、チーム開発のためにWebベースのIDEやスケジューラー、dbtドキュメントの共有などの機能を提供します。
検証の流れ
- 環境準備
- dbtプロジェクトの作成
- dbtのモデル作成と実行 ←この記事はここまで
- より複雑なモデルの作成と実行
- dbtのテスト実行
1. 環境準備
作業ディレクトリの作成
mkdir dbt_demo
cd dbt_demo
Python仮想環境の作成
私は、Pythonのバージョン管理をpyenv、仮想環境をvenvで管理しています。
pyenv local 3.8.8
python -m venv venv
.\venv\Scripts\activate
dbt等のpipインストール
python -m pip install --upgrade pip
pip install dbt-core dbt-databricks
インストールしたライブラリを確認します。
pip list | findstr "dbt databricks"
databricks-sql-connector 0.9.3
dbt 0.21.1
dbt-bigquery 0.21.1
dbt-core 0.21.1
dbt-databricks 0.21.1
dbt-extractor 0.4.0
dbt-postgres 0.21.1
dbt-redshift 0.21.1
dbt-snowflake 0.21.1
dbtのバージョンを確認します。
dbt --version
installed version: 1.0.0
latest version: 1.0.0
Up to date!
Plugins:
- databricks: 1.0.0
Databricks SQLエンドポイントの作成
dbtから接続するDatabricks SQLエンドポイントを作成します(通常のClusterでもOKです)
SQLエンドポイントの場合は、Connection Detailsに接続情報が記載されています。
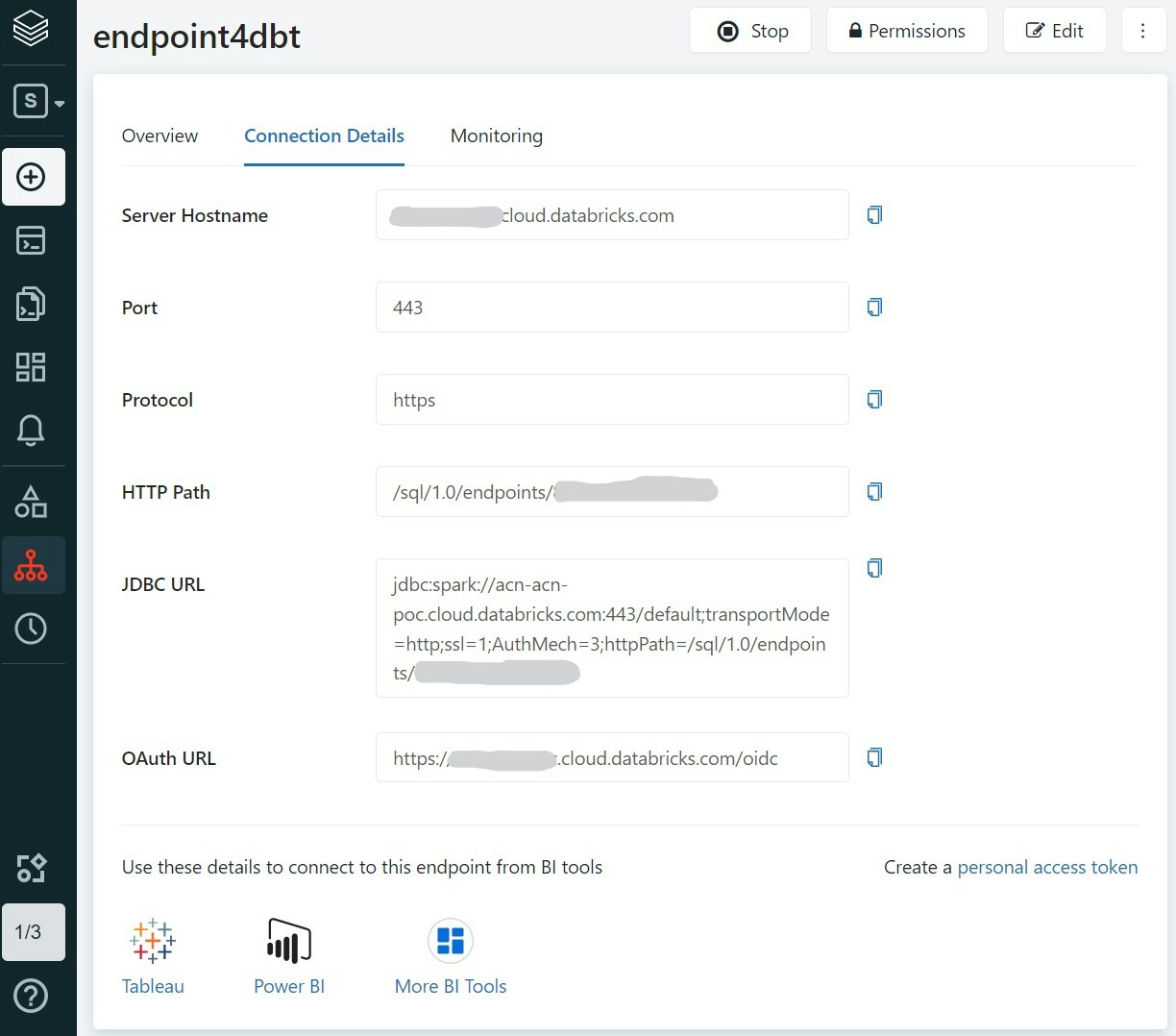
またアクセストークンも必要になるので、右下Create a personal access tokenのリンクから
発行しておきます。
テーブルの準備
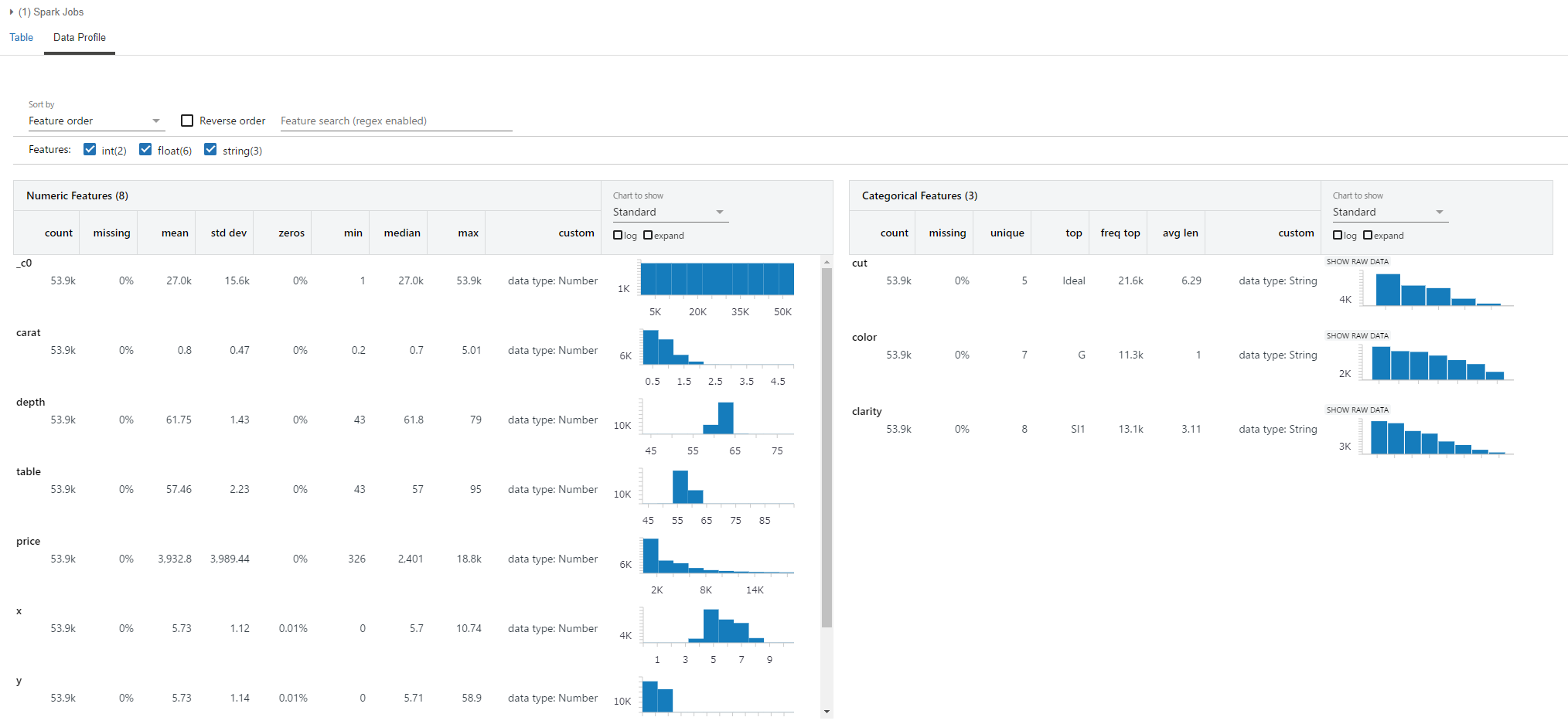
Databricksノートブックで、diamondsサンプルデータからテーブルを作成しておきます。
csv_file = '/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv'
df = (spark.read
.format('csv')
.option("header","true")
.option("inferSchema", "true")
.load(csv_file)
)
df.write.saveAsTable("diamonds")
diamondsテーブルはこんなです。
display(df)
2. dbtプロジェクトの作成
プロジェクトというのはdbtの管理単位でSQLとYAMLファイルで構成されます。
dbt initコマンドを実行すると対話的にプロジェクトを作ることができ、
一般的には以下のようなディレクトリ構成で作成されます。
├─ dbt_project.yml
├─ README.md
├─ analyses
├─ data
├─ dbt_packages
├─ logs
├─ macros
├─ models
├─ snapshots
└─ tests
上記ディレクトリやファイルの他にDWHなどへの接続情報は~/.dbt/profiles.ymlに記録されます。profile.ymlは以下のような構造です。
~/.dbt/profiles.yml
databricks_cluster:
outputs:
dev:
host: xxxxx.cloud.databricks.com
http_path: /sql/1.0/endpoints/8888
schema: default
threads: 1
token: dapiXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
type: databricks
target: dev
dbt initコマンドを実行して、SQLエンドポイントの接続情報やアクセストークンを入力します。
dbt init demo_project
00:00:00 Running with dbt=1.0.0
00:00:00 Creating dbt configuration folder at ~\.dbt
00:00:00 Setting up your profile.
Which database would you like to use?
[1] databricks
(Don't see the one you want? https://docs.getdbt.com/docs/available-adapters)
Enter a number: 1
host (yourorg.databricks.com): xxxxx.cloud.databricks.com
http_path (HTTP Path): /sql/1.0/endpoints/8888
token (dapiXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX):
schema (default schema that dbt will build objects in): default
threads (1 or more) [1]: 1
00:00:00 Profile databricks_cluster written to ~\.dbt\profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.
dbtからDatabricksのSQLエンドポイントへの接続をテストします。
cd demo_project
dbt debug
00:00:00 Running with dbt=1.0.0
dbt version: 1.0.0
python version: 3.8.8
python path: ...\venv\scripts\python.exe
os info: Windows-10-10.0.xx
Using profiles.yml file at ~\.dbt\profiles.yml
Using dbt_project.yml file at \dbt_demo\demo_project\dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
host: xxxxx.cloud.databricks.com
http_path: /sql/1.0/endpoints/8888
schema: default
Connection test: [OK connection ok]
All checks passed!
3. dbtのモデル作成と実行
dbtのモデルはdbtの肝となるデータモデルを扱う概念ですが、その実体は単なるSELECT文で、modelsディレクトリにSQLファイルとして配置します。
モデル自体は単なるSELECT文ですが、dbt_projet.ymlまたはモデルSQLファイルのconfigブロックに、モデル設定を記述することで、dbt runコマンドは良しなに環境ごとにビューやテーブルを作成したり、モデル間の依存関係を記録したりと気の利いた処理をしてくれます。
今回は、SQLファイルにconfigブロックを記述していきます。
dbt_demo/demo_project/models/diamonds_four_cs.sql
{{ config(
materialized='table',
file_format='delta'
) }}
select carat, cut, color, clarity
from diamonds
dbt_demo/demo_project/models/diamonds_list_colors.sql
select distinct color
from {{ ref('diamonds_four_cs') }}
sort by color asc
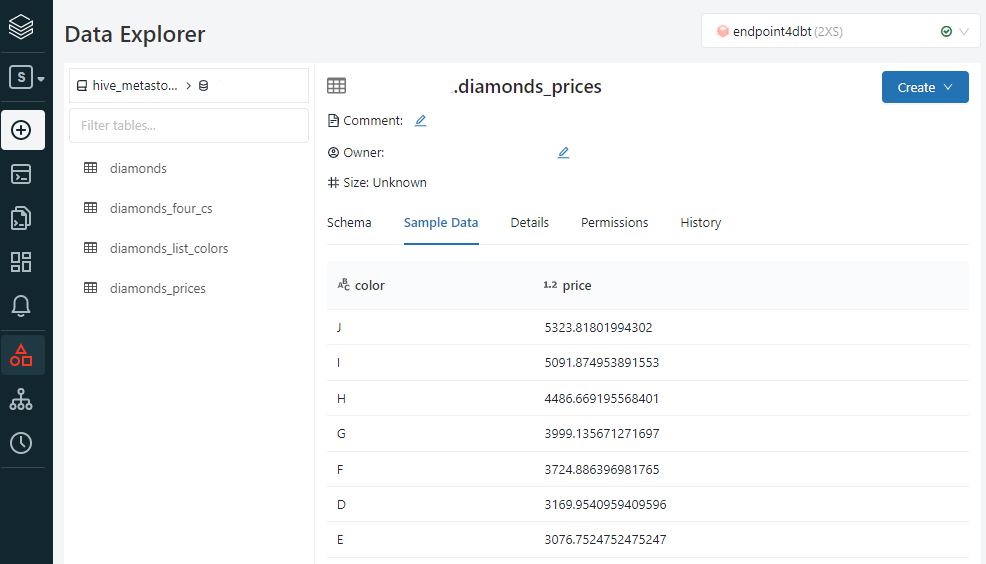
dbt_demo/demo_project/models/diamonds_price.sql
select color, avg(price) as price
from dbt_schema.diamonds
group by color
order by price desc
モデル(SQLファイル)を作成したら、dbt runコマンドで実行します。
dbt run --model models/diamonds_four_cs.sql models/diamonds_list_colors.sql models/diamonds_prices.sql
00:00:00 Running with dbt=1.0.0
00:00:00 Found 5 models, 4 tests, 0 snapshots, 0 analyses, 190 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics
00:00:00
00:00:00 Concurrency: 1 threads (target='dev')
00:00:00
00:00:00 1 of 3 START table model diamonds_four_cs............................ [RUN]
00:00:00 1 of 3 OK created table model diamonds_four_cs....................... [OK in 4.03s]
00:00:00 2 of 3 START view model diamonds_prices.............................. [RUN]
00:00:00 2 of 3 OK created view model diamonds_prices......................... [OK in 1.05s]
00:00:00 3 of 3 START view model diamonds_list_colors......................... [RUN]
00:00:00 3 of 3 OK created view model diamonds_list_colors.................... [OK in 1.37s]
00:00:00
00:00:00 Finished running 1 table model, 2 view models in 10.51s.
00:00:00
00:00:00 Completed successfully
00:00:00
00:00:00 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
以上で、dbtからDatabricksにテーブルとビューを作成することができました。
dbt with Databricksで始めるDataOps(2)では、さらにデータ品質のテストの機能を試していきます。