テックタッチアドベントカレンダー14日目を担当する@ihirokyです。
13日目は @oyoshikeita による 言葉を使ってプロダクトに生命を吹き込む でした。
何気なく眺めているプロダクトがなぜこんなデザインになっているのかが垣間見れて「あーなるほど」と納得してしまいました。自分は何となくに頼りがちな部分がありますが、デザインするにあたりしっかり考えた裏付けをもちプロダクト開発に当たっていきたいです。
さて、テックタッチエンジニア勢の記事はTypeScript/Goが大勢を占めていますが、ネタが無いので心機一転Javaを使ったハードウェアを考えるお話です。6日目の話は忘れました。
今回作成したものは https://github.com/ihiroky/false-sharing に置いてあります。
漏れのある抽象化の法則
私の胸にぶっ刺さっている言葉の一つに、Stackoverflowでお馴染みの Joel Spolsky 氏の名言「漏れのある抽象化の法則」というものがあります1。いろいろな物事は抽象化され、細かいことを気にしなくても扱い安いレベルで機能が提供されています。ただ、その抽象化の内側にいるなにかが特殊な振る舞いをしたとき、一見理解しがたい現象が発生します。これに対処するには結局抽象化がどのように機能し、何を抽象化しているのかを学ぶ必要があります。つまり、抽象化は作業時間を短縮するが学ぶ時間までは短縮してくれません。つまるところ、問題を解決できるエンジニアはすべてを勉強する必要がある、というお話です。ということで、並行処理界隈ではとても有名な Flase Sharing を通して高級なプログラミング言語の上にのっても結局ハードウェアのことを理解していなければその性能はいかせない例を見てみたいと思います。
例題
一つの配列をマルチスレッドで突っつくプログラムを考えます2:
package com.ihiroky;
import java.util.concurrent.atomic.AtomicLongArray;
public class FalseSharingArray implements Runnable {
private AtomicLongArray array_;
private final int arrayIndex_;
private final long iteration_;
public FalseSharingArray(AtomicLongArray array, int arrayIndex, long iteration) {
array_ = array;
arrayIndex_ = arrayIndex;
iteration_ = iteration;
}
@Override
public void run() {
for (long i = 0; i < iteration_; i++) {
array_.set(arrayIndex_, i);
}
}
}
package com.ihiroky;
import java.util.concurrent.atomic.AtomicLongArray;
public class App {
private void runArray(String name, int width) throws Exception {
final int NUM_THREADS = 3;
final long ITERATION = 500_000_000;
var array = new AtomicLongArray(NUM_THREADS * width);
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingArray(array, i * width, ITERATION));
}
long start = System.nanoTime();
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
System.out.println(name + " - duration: " + ((System.nanoTime() - start) / 1000_000) + "ms.");
}
public static void main(String[] args) throws Exception {
App app = new App();
System.out.println(" === Start warm up === ");
app.runArray("array without pad", 1);
app.runArray("array with pad", 8);
System.out.println(" === End warm up === ");
app.runArray("array without pad", 1);
app.runArray("array with pad", 8);
}
}
warm upは置いておくと、App#runArray()メソッドを width を 1 にした場合と 8 にした場合の二通り呼び出しています。この width は、AtomicLongArrayの長さと、FalseSharingArrayクラスがAtomicLongArrayのどこを参照するかを指定するindexに影響しています。
// arrayの要素のうち使うのはNUM_THREADS個だがとびとびに使った場合飛ばし多分長さが必要
var array = new AtomicLongArray(NUM_THREADS * width);
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
// FalseSharingArrayが参照するarrayの要素位置をwidthによりまばらにできる
threads[i] = new Thread(new FalseSharingArray(array, i * width, ITERATION));
}
つまり、FalseSharingArrayがAtomicLongArrayを隙間無く(普通に)使うか、8個おきに使うかの指定です。これを実行してみると:
ihiroky@pclz750hs:~/projects/false-sharing$ gradle run
> Task :run
=== Start warm up ===
array without pad - duration: 37374ms.
array with pad - duration: 13922ms.
=== End warm up ===
array without pad - duration: 24741ms.
array with pad - duration: 7299ms.
となり、widthを8にした場合、widthを1にした場合と比べて3倍以上速くなっています。widthが1か8かに関係なくプログラム上配列要素の共有による競合はありません。ただ間をあけただけなのこの差は不思議ですよね。私は不思議でなりませんでした。
こんなイメージ:
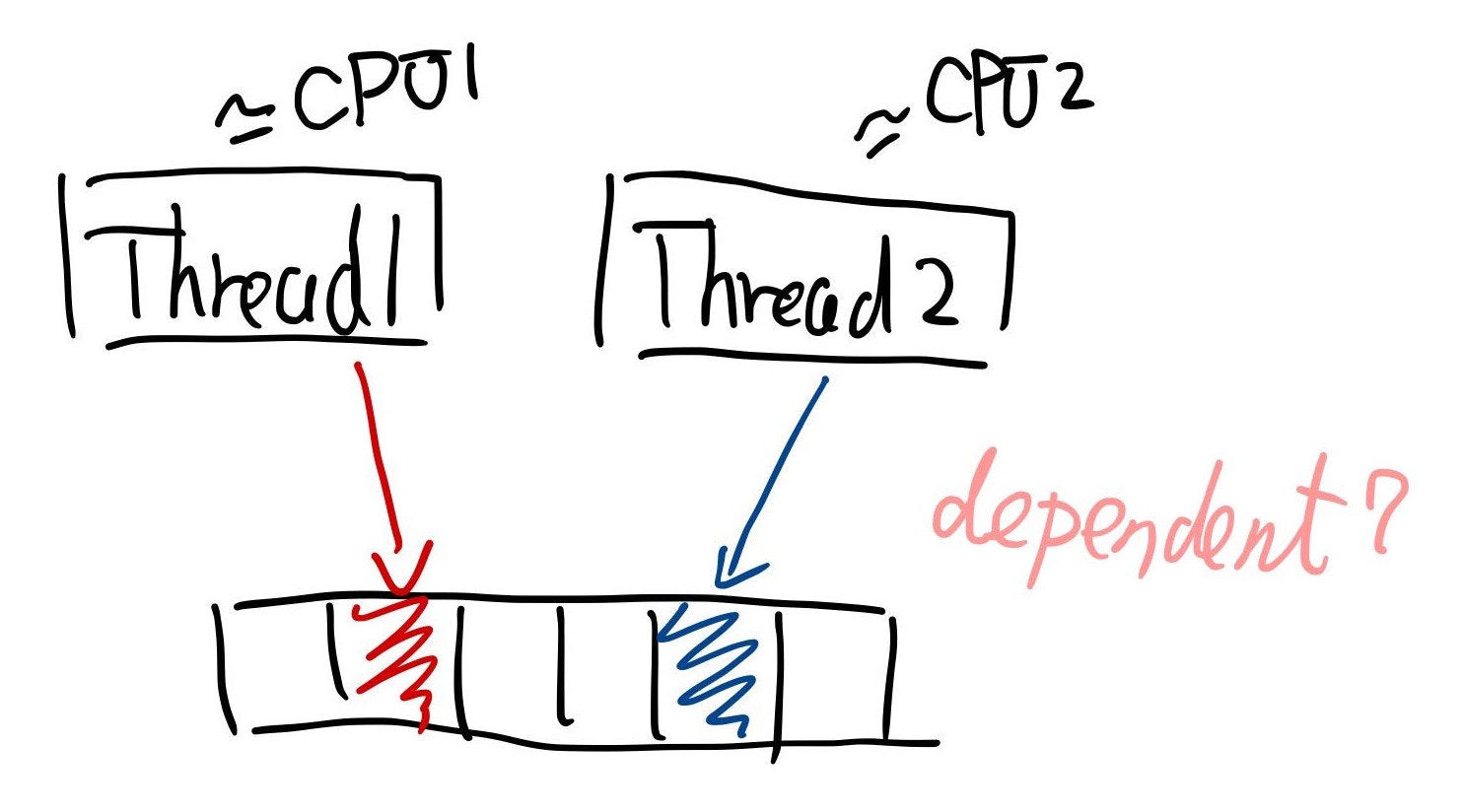
何が漏れている?
この現象は、ハードウェアレベルでみつめ直すとメモリの競合が起きていることが分かります。以下はCPUがメモリ上のデータを使う様子を模式的に表しています:
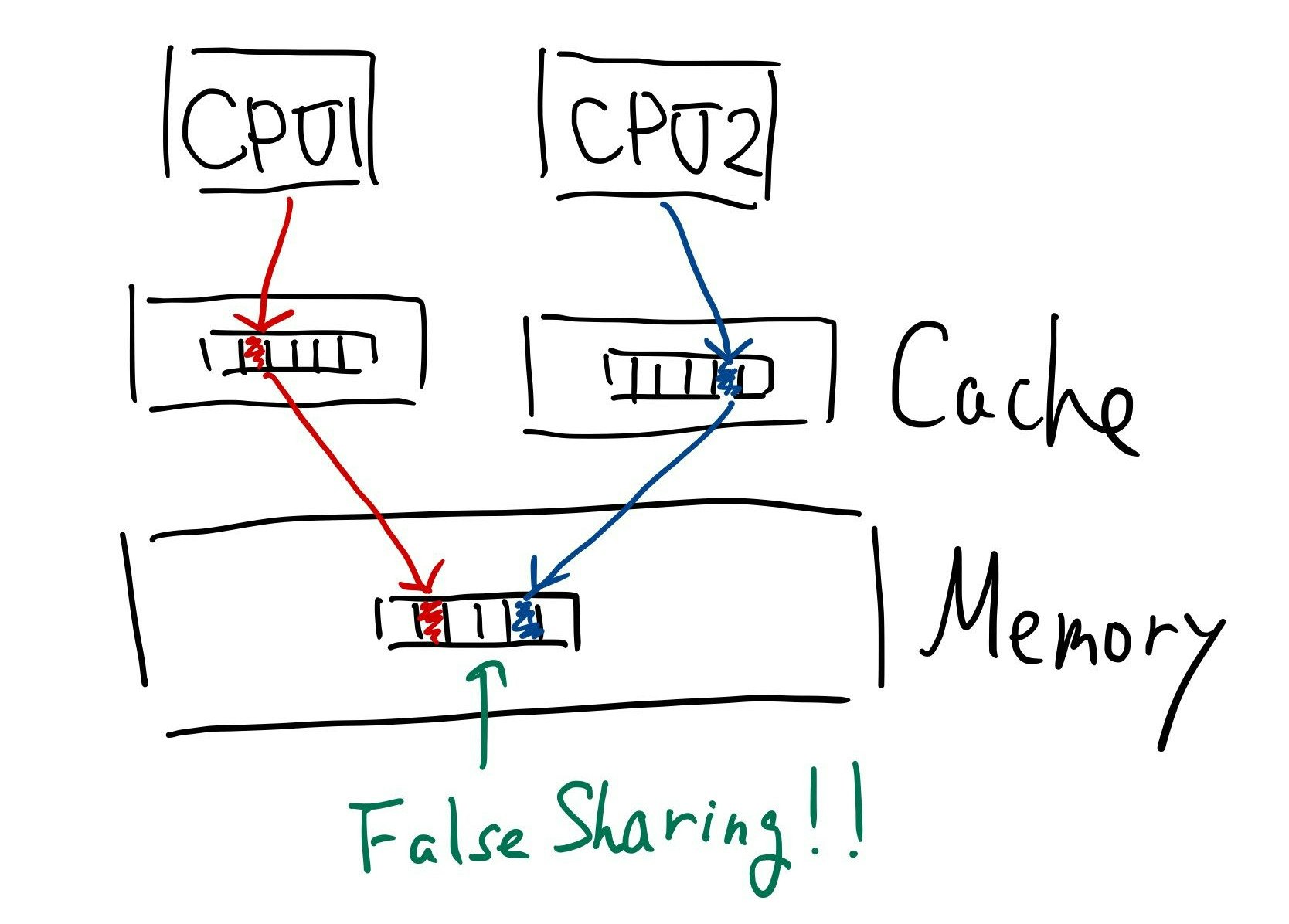
CPUはデータを扱う際に、メモリより高速なキャッシュ上にデータを一時的にロードします。メモリ上のデータをキャッシュに載せる際に、キャッシュラインを単位としてデータをキャッシュ読み込んだりメモリに書き込んだりしています。また、キャッシュラインのサイズはCPUによりいろいろですが、普段触るx64系は大抵64バイトです。つまりキャッシュラインサイズ分まとめてメモリに対してデータの読み書きが行われます。このため、プログラム上では複数のスレッドによる要素の共有はなくとも、その要素がキャッシュライン上に共存していれば複数のCPUからみると変数の共有が行われている状態になります。ここで、同一キャッシュライン上に存在する二つの数値を2つのCPUがそれぞれキャッシュに読み込んでいる状態で片方がその数値を更新した場合、CPU間で整合性をとる取るためにもう片方はキャッシュの読み込みなおしが必要になる、更に更新が起きた場合は…となると、競合が発生します。これが頻発すると、上記プログラムのように顕著な差となって現れます。
このように、本来共有していないデータをキャッシュ上の同一ラインで共有してしまう状況を「False Sharing」と言います。widthを8にしてFalse Sharingを回避できたのは、キャッシュラインが64バイト、longが8バイトだからです(8バイト x 8個 = 64バイト)。
学びはエンジニアの基礎体力
このようにハードウェアがどうなっているかを理解していないとプログラムの動きを予測することは難しいです。一見遠回りに見えても基本的な計算機の仕組みを含めた基本的な事項、流行りの技術の裏側もしっかり学んでおきたいです。それゆえ工学系出身のエンジニアを非常に羨ましく思う今日この頃。
落穂?拾い
AtomicLongArrayを使っている理由
今回配列を持ち出すのにあえて AtomicLongArray を用いました。今回のネタは通常の配列を用いると(通常の方法では)発生しません。キャッシュの一貫性を保つ処理を挟み込まないからです。ざっくりいうと AtomicほんにゃかArray は配列の各要素に対してvolatile相当の処理もできるようになっているところがミソです。
試した環境のCPUと利用するCPUコア
Intel(R) Core(TM) i7-3517U CPU @ 1.90GHz です。古いですね。2コア/ハイパースレッディング有(4スレッド)です。CPUののキャッシュが分かれていることがことの原因なので、プログラム上で1スレッドしか起こさないようにする、(最近はほぼ見ないですが)1コアしかないCPUで試すと、触る要素の間隔を広げても無駄にメモリを消費するだけでスループットは変わりません。
ちなみにテックタッチに買ってもらった開発PCのCPUは i9-9900K です。爆速です。
@jdk.internal.vm.annotation.Contended (旧@sun.misc.Contented)
今回はCPUのキャッシュラインサイズが64バイトと分かっていたので空のlongを7個並べて対処しました。キャッシュラインのサイズはあたりまですが使うハードウェアに依存するため、真っ向から対処しようとすると都度CPUのスペックを確認してコードを書き直す必要があります。都度 configure/make みたいな事をしてもいいんですが、JDKには @Contented という建前上JDK内部使用を前提とした変数のメモリ上の配置を制御するアノテーションが存在しています。これをメンバ変数につけておくとJVMがよしなにレイアウト(パディング)してくれます。何もしないと処理系が変数の並びを変えてくる可能性もあるため、真っ向勝負すると JCTools バリに継承とパディングを駆使する必要が出てきます。@Contentedにいては https://www.javaspecialists.eu/archive/Issue249.html あたりが参考になります。そういえばマイクロベンチの JMH もひたすらパディング仕込んできますね。
終わりに
複雑化するシステムを駆使して価値を生み出すエンジニアは抽象化された生産性の高い技術を駆使しつつも、問題が発生すれば何がどのように抽象化されているかを把握しなぜ目に見える現象がおこっているかを理解し解決していきます。テックタッチのメンバーは最良のプロダクトを生み出すために常に考えつづけ、技術的な壁を乗り越えるために皆学びがすごいです(あせるくらい)。それゆえ困難も乗り越えられているのかなと感じる次第です。
15日目の担当は @terunuma です。何がでるかな〜。