はじめに
最近の生成AIの発展は何か面白い文章をつくるといったエンタメにも広く活用できると考え,日本語LLMを利用してジョジョっぽい文章を作成してみました.そもそもジョジョとはですが,独特な言い回しを特徴とした作品で,これが元となったセリフがネットミームなどの形で使われているのをよく見ます.このセリフは一種の方言のような性質もあると考えられ「標準語→ジョジョっぽい言葉」という変換をしてみたいというのがモチベーションです.
投稿に当たりこれまでのQiita記事での動向を調べてみましたが,ジョジョ×言語生成はこれまでいくつか試されているようでした.こちらもぜひ読んでみると面白いと思います!
-
LSTMでジョジョに奇妙な名言を制作してみた
Transformer以前の時系列モデルLSTMによるジョジョに出てくるセリフの次単語予測 -
ジョジョの奇妙なGPT-2
GPT2によるジョジョのセリフの次単語予測 -
ジョジョの奇妙なLLMファインチューニング - おれはデータセットを改変するッ!
cyberagent/open-calm-large をジョジョっぽい言葉に改変したデータセットを作成してファインチューニングした例.このモデルではジョジョっぽい言葉で質問応答することが目的.これが方法としては一番今回に近い.
なおコードはgithub上にあげています.
対象者
- ジョジョが好きなひと
- オープンソースLLMのtuningに興味のある人
ジョジョを題材にしていますが最近公開された日本語LLM, Swallow 7B instructをtrainingしていますので,そちらに興味のある人もぜひ読んでみてください.
早速どんなものが生成できたのか
入力したテキストを「回答:」の下に表示するようにしています.ここではキャプチャした画像を載せます.まずは簡単なもので

予想した答えが帰ってきています.次は有名なセリフを少し変えたもので
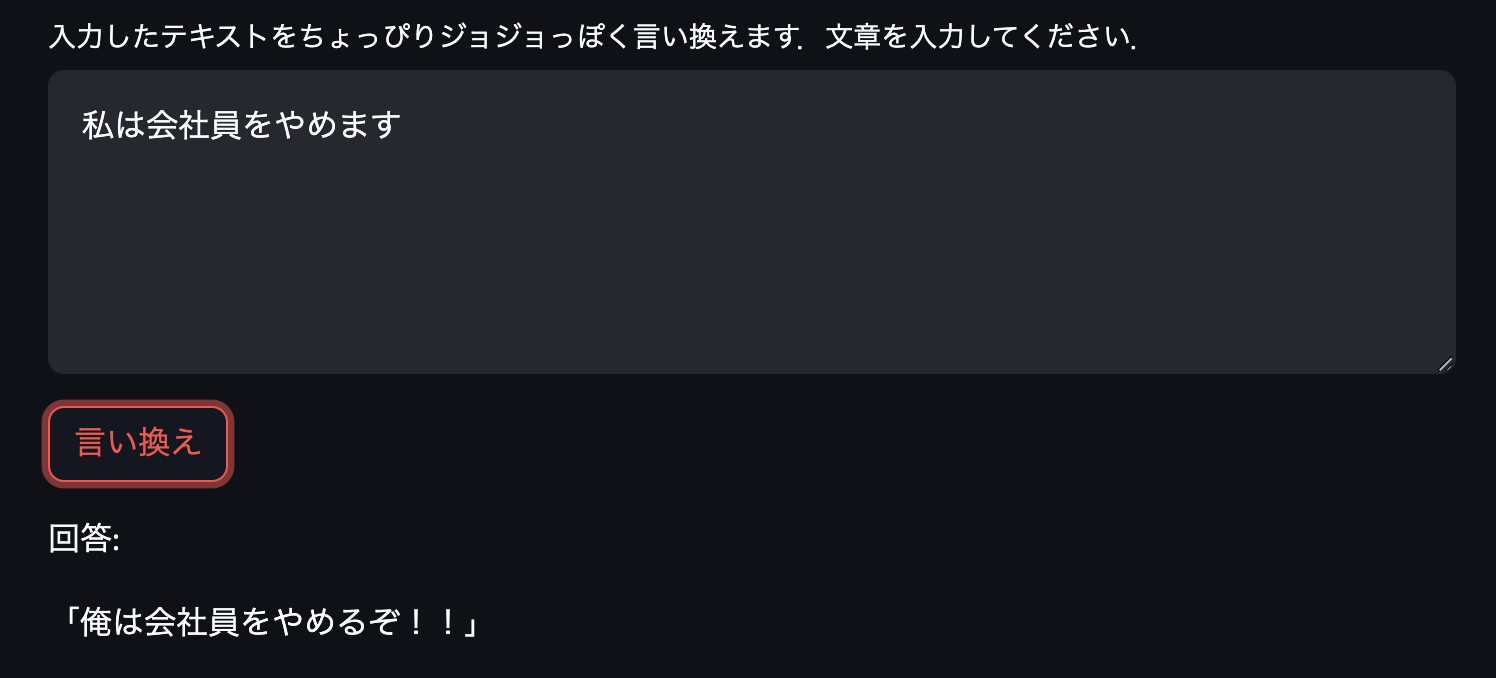
いい感じです.さらにいろいろ入力してみます.
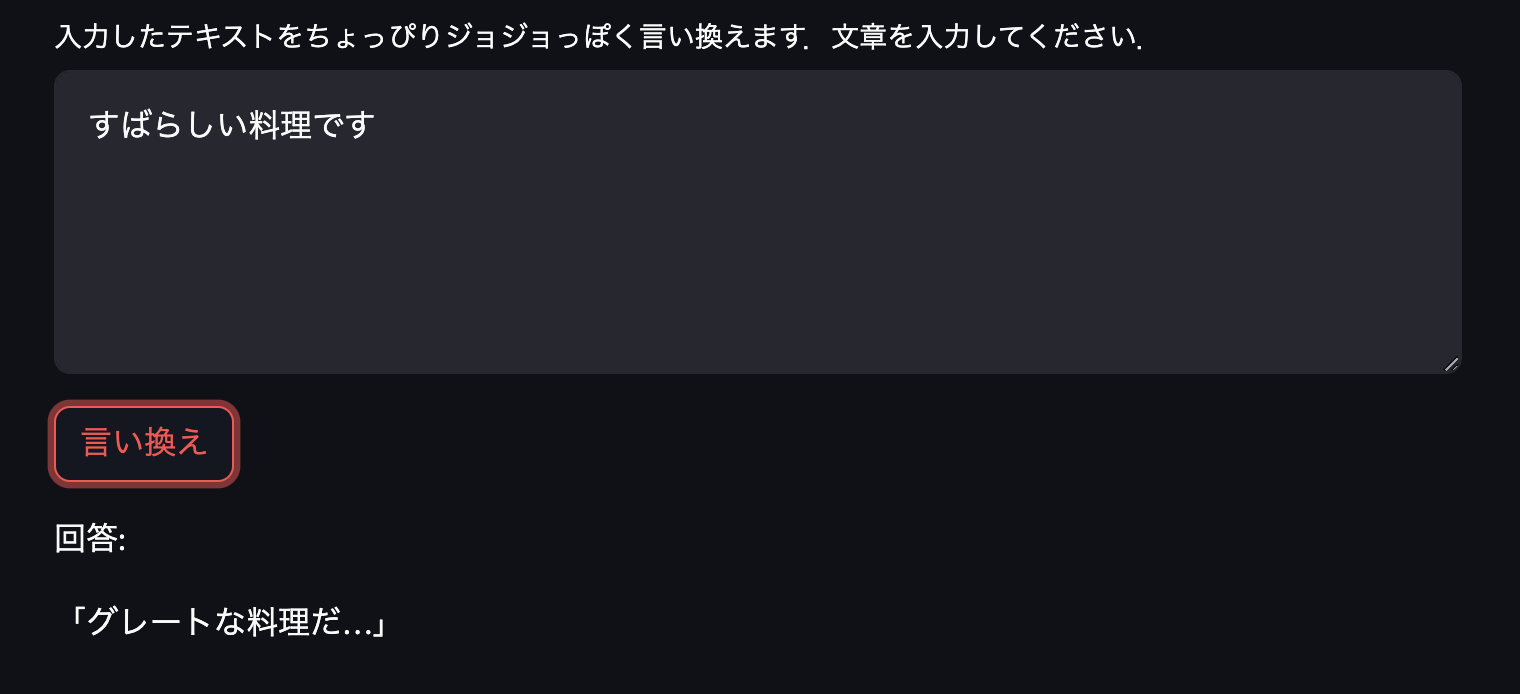
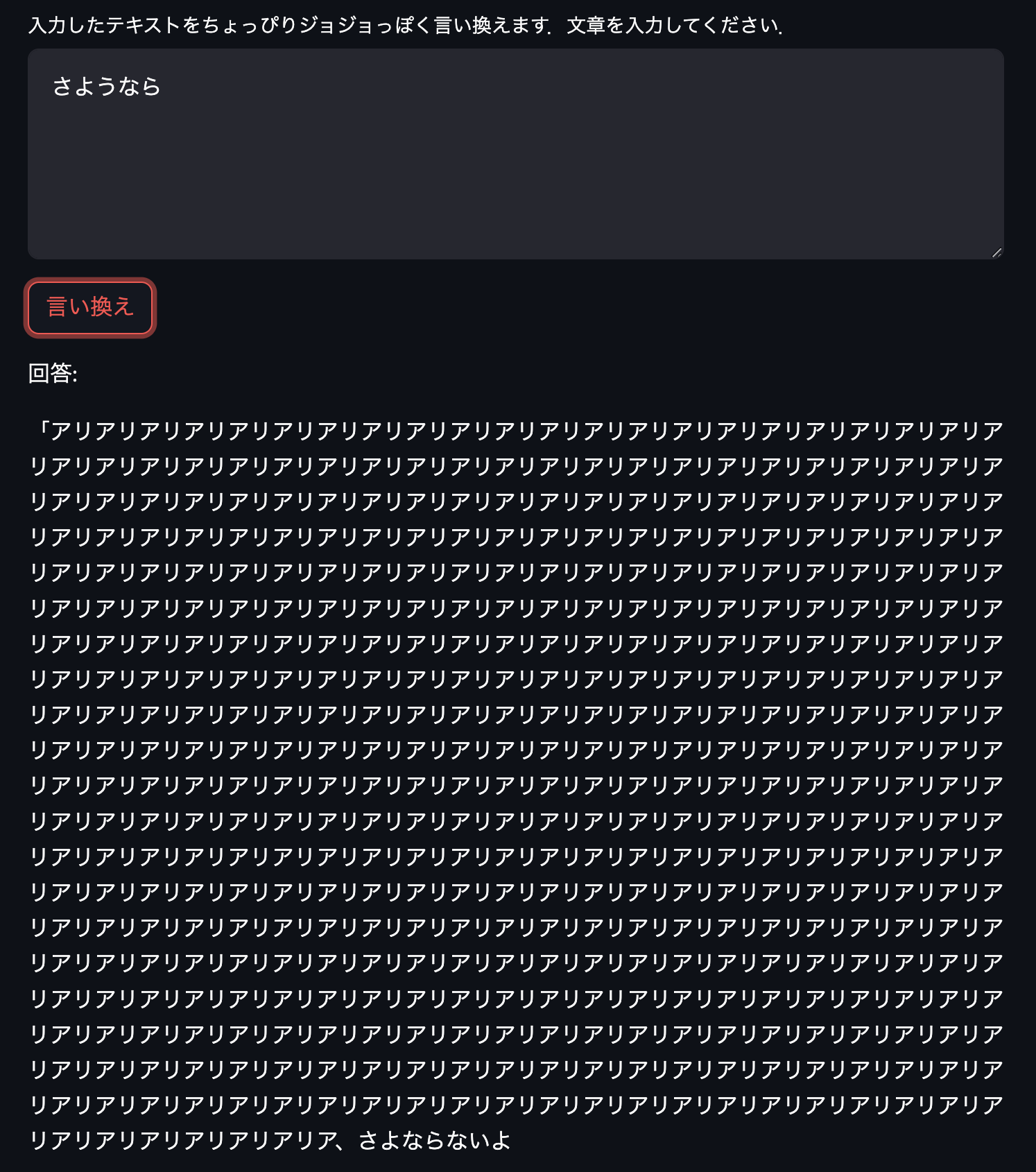
ある程度いい感じの生成ができているようです.なかには「さようなら」の答えのように末尾がよくわからないものが生成されてしまうものもあります.
次は名言や説明的なセリフで試してみます.
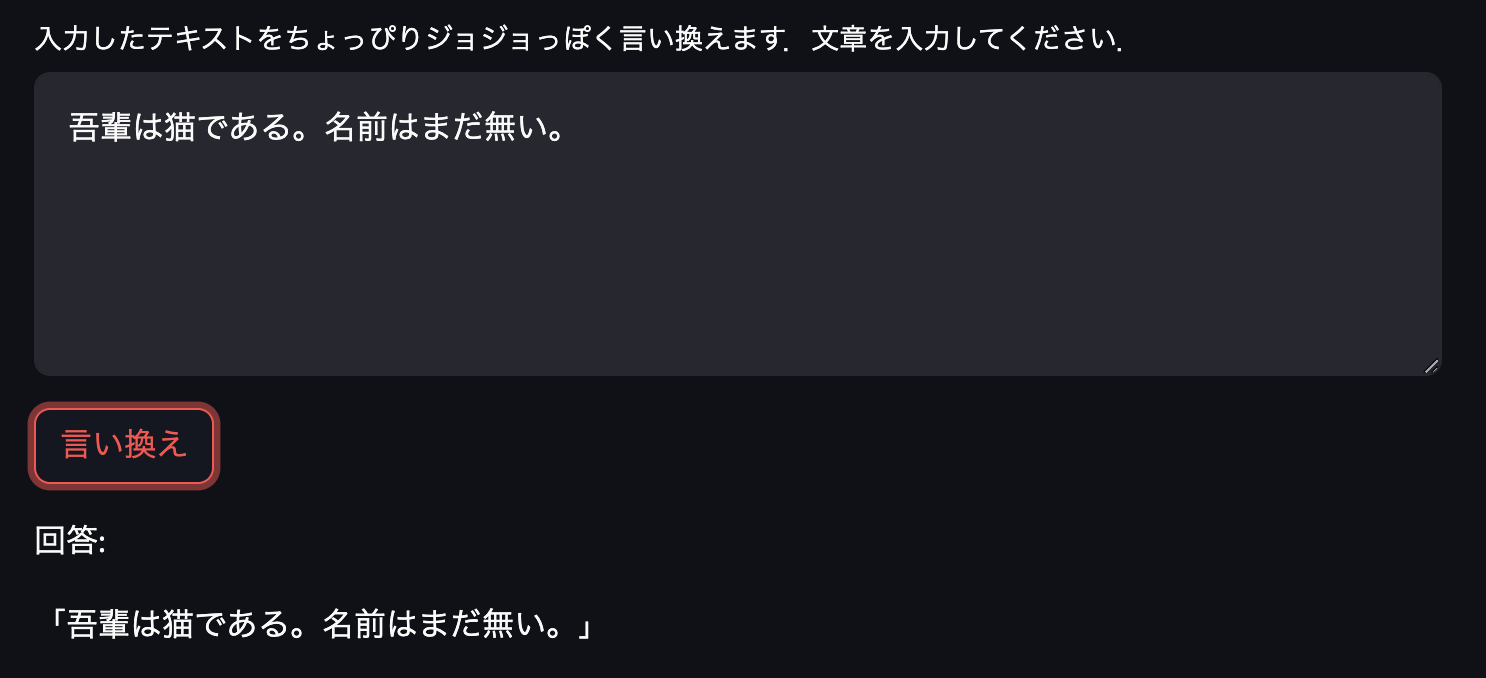
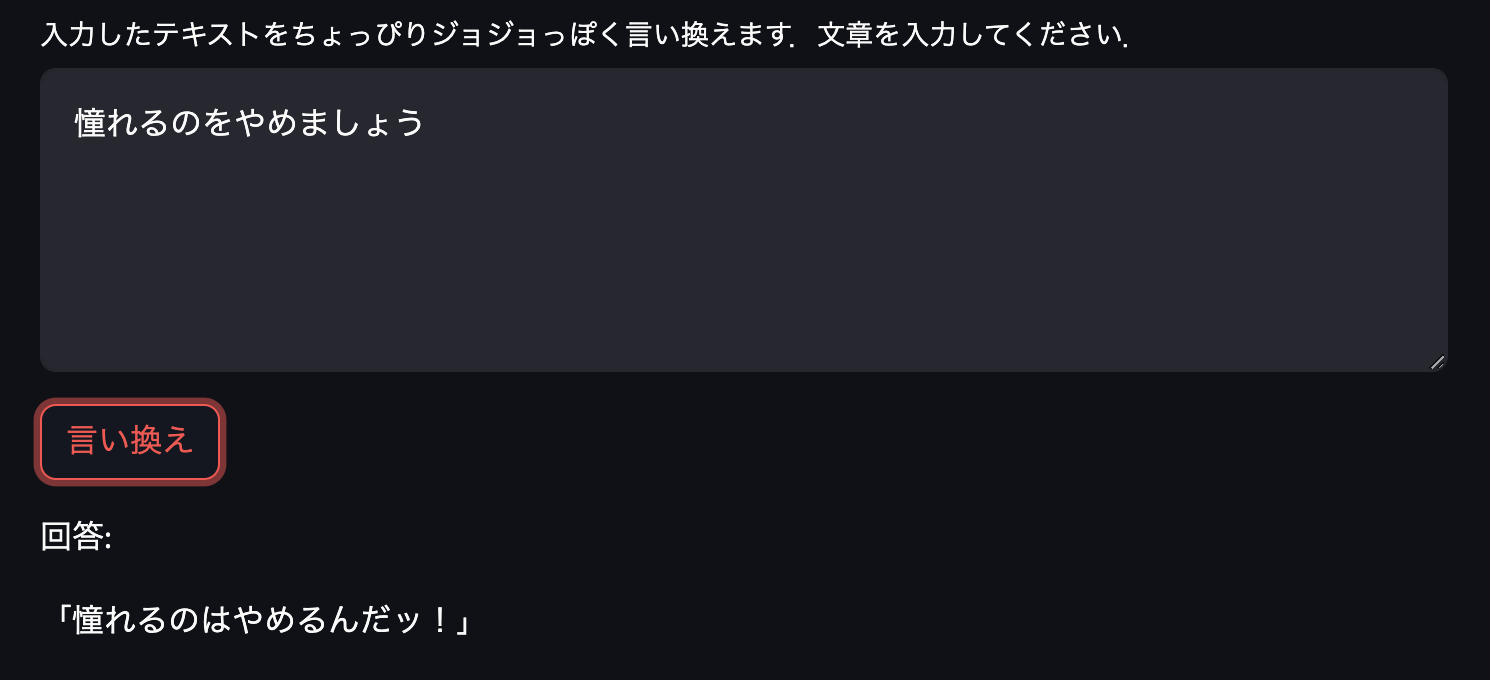
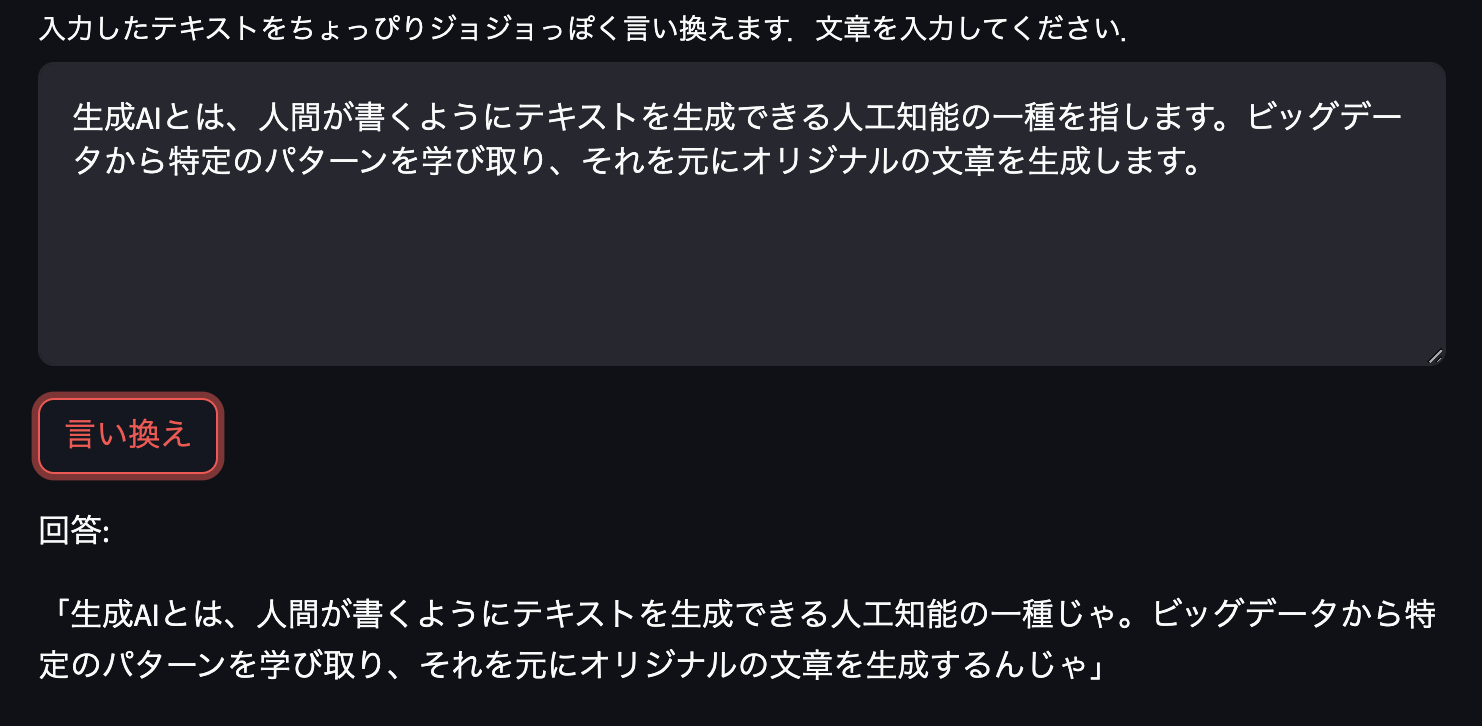
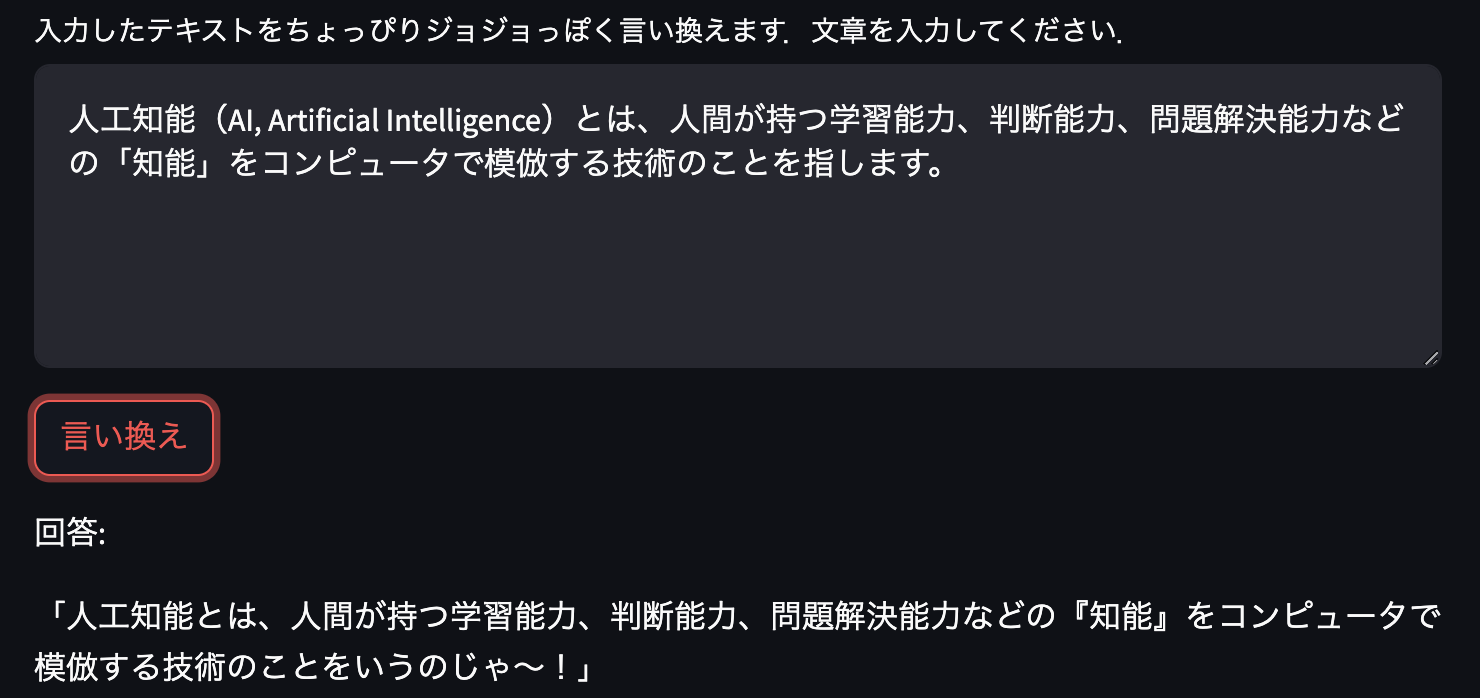
名言は変換されないものもありますね.説明になるとなぜかセリフが老人っぽくなります.老ジョセフが解説役をつとめる文章がトレーニングデータに多かったのでしょうか.
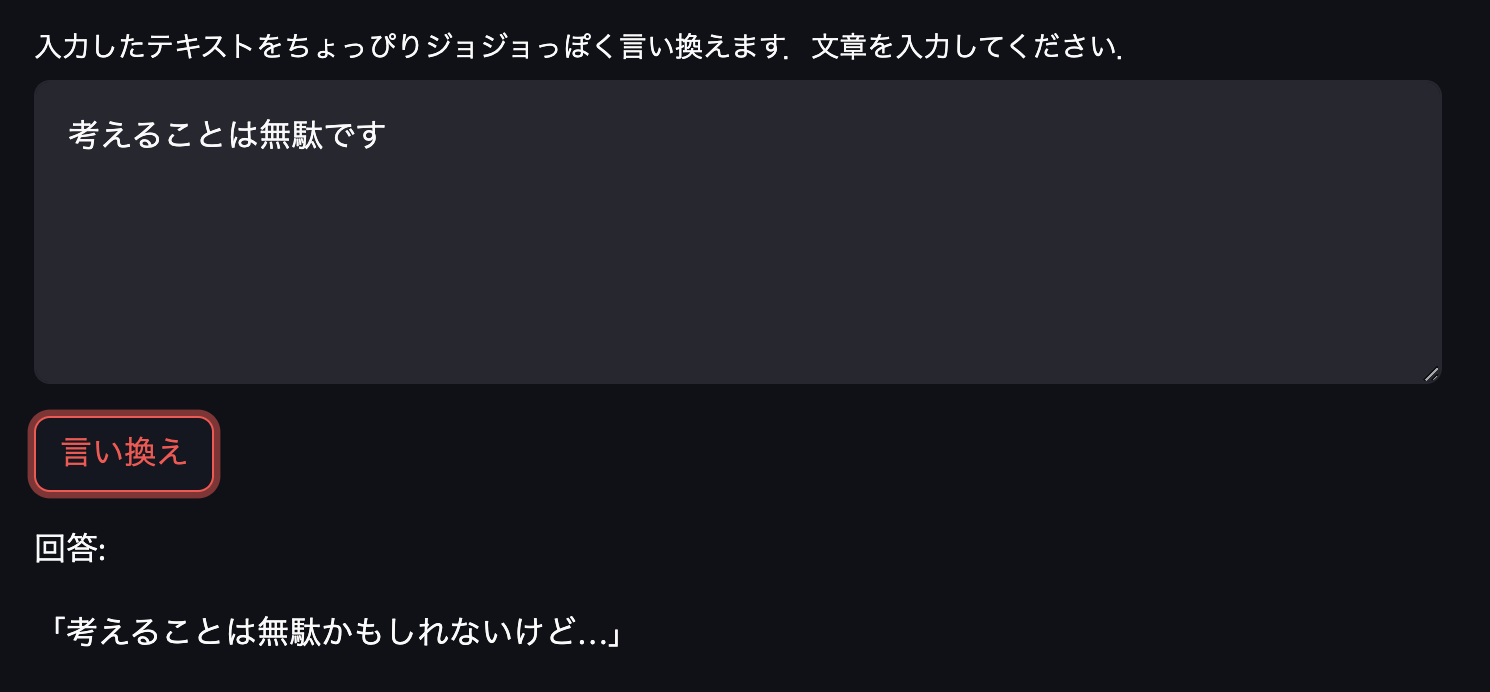
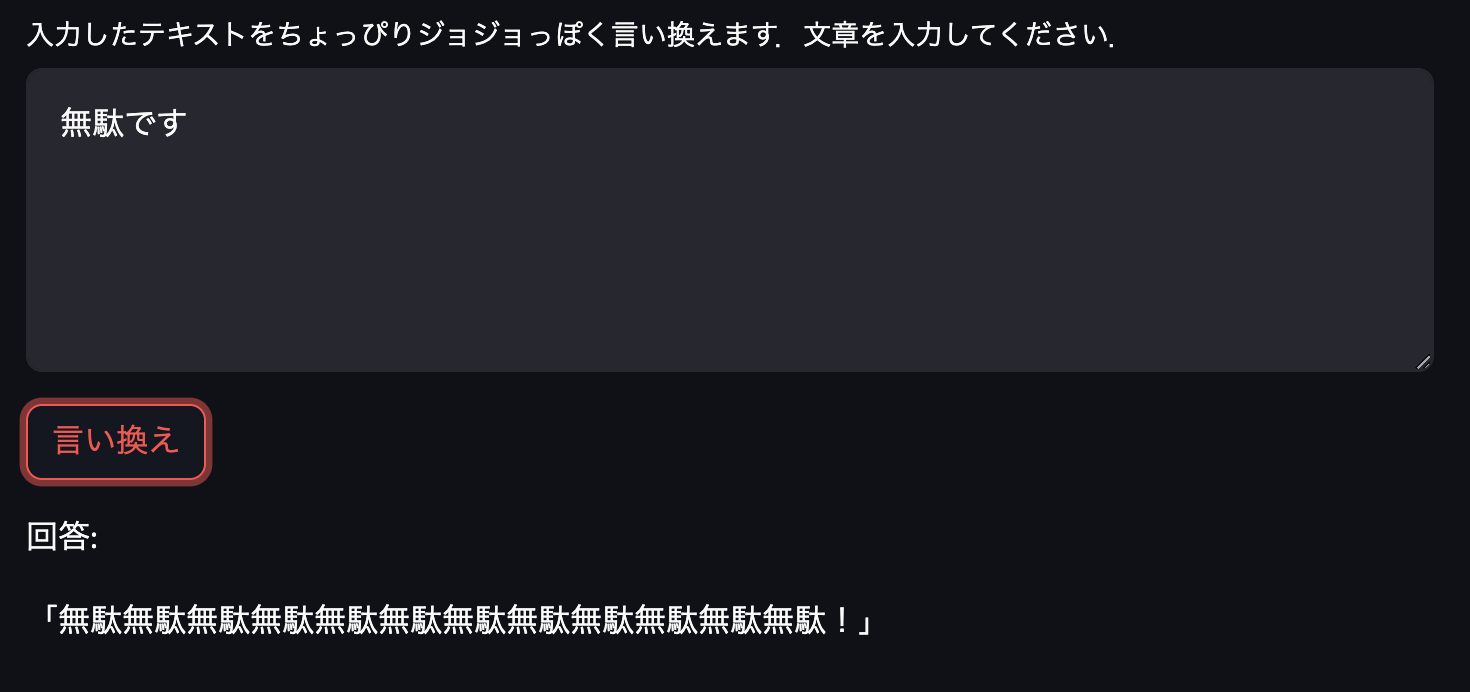
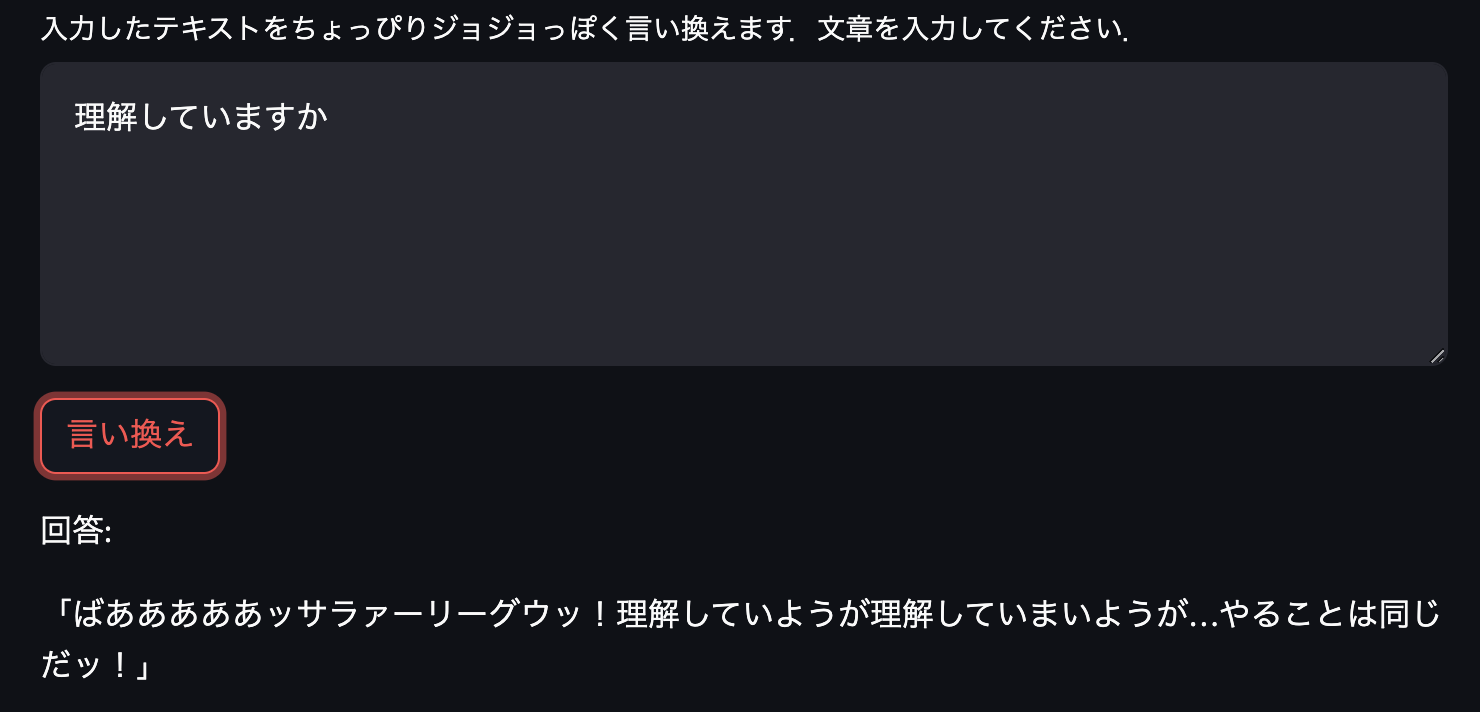
定番の「無駄無駄」を生成してもらったのですが,前になにかあるとうまく生成してくれないようです.また最後の応答のように意味の分からない回答をしてしまうこともあるようでした.しかしながらおよそ期待通りのモデルになっています!
データセットについて
ここからは実際にどのように作成したかになります.興味のない方はここからは飛ばしてもらって大丈夫です.
ジョジョのセリフのデータはこの記事のスクレイピングコードを参考に,こちらのWebサイトからいただきました.ここから抽出した名言を私自身で標準語に変換を行い,標準語のソーステキスト,名言のターゲットテキストのペアを300弱ほど用意しました.
例
| 標準語 | ジョジョ名言 |
|---|---|
| 私は人間をやめます。ジョジョさん。 | 俺は人間をやめるぞ!ジョジョーッ!! |
トレーニングコードについて
今回は東工大岡崎研,横田研と産総研のチームにより開発されたSwallow 7B instructを利用しました.
huggingfaceからモデルの重みを読み込み,lightningフレームワークを利用して訓練しています.読み込むモデルの名前とプロンプト作成の関数を書き換えることで,huggingfaceに上がっているCausalモデルであればどのモデルでも基本的に訓練が可能です.
また実行環境はNVIDIA A100 1枚での実行です.
以下はgithubにあげているトレーニングコード一部の説明です.
ライブラリのインポート
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import random
import copy
import datetime
from tqdm import tqdm
import numpy as np
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import pytorch_lightning as pl
from torchinfo import summary
プロンプト作成関数
モデル公開リンク参考
今回は入力情報を利用せずに指示文で構成しました.
def build_prompt(user_query, responses="", inputs="", sep="\n\n### "):
# sys_msg = "以下に、あるタスクを説明する指示があり、それに付随する入力が更なる文脈を提供しています。"
sys_msg = "以下に、あるタスクを説明する指示があります。リクエストを適切に完了するための回答を記述してください。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [":\n" + user_query, ":"]
if responses:
msgs[-1] = ":\n" + responses
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ":\n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
トークンID作成クラス
後述するLightningDataModuleクラスで呼び出して__getitem__関数の戻り値を返します.ソーステキストとターゲットテキストを読み込み,inputs辞書配列からプロンプトを作成してtokenizeしています.今回はCausalLMを利用しているためソースidとターゲットidで同様のinput_idsを一度設定していますが,ターゲットidのみ応答部分以外は-100としています.(-100とすることでこの部分はloss計算に使用されないようです.reference参照)
またbatch sizeを大きくした場合に対応できるようにtokenizerではpaddingトークンを追加しています.bosやeos,unkトークンは設定されていました.
class CreateTokenID(Dataset):
def __init__(self, FT_path,):
self.FT_path = FT_path
self.inputs = []
self.targets = []
self.tokenizer = AutoTokenizer.from_pretrained("tokyotech-llm/Swallow-7b-instruct-hf")
self.tokenizer.add_special_tokens({'pad_token': '<|padding|>'})
self._build()
def __len__(self):
return len(self.inputs)
def __getitem__(self, index):
source_ids = self.inputs[index]["input_ids"].squeeze()
target_ids = self.targets[index]["input_ids"].squeeze()
source_mask = self.inputs[index]["attention_mask"].squeeze()
target_mask = self.targets[index]["attention_mask"].squeeze()
return {"input_ids": source_ids, "attention_mask": source_mask,
"labels": target_ids, "decoder_attention_mask": target_mask}
def _build(self):
src_list, tgt_list = [], []
spath, tpath ="_src", "_tgt"
with open(self.FT_path+spath, "r", encoding="utf-8") as f:
src_list = f.read().split("\n")
src_list.pop(-1)
with open(self.FT_path+tpath, "r", encoding="utf-8") as f:
tgt_list = f.read().split("\n")
tgt_list.pop(-1)
for i, line in tqdm(enumerate(src_list)):
src_tab = src_list[i]
tgt_tab = tgt_list[i]
inputs = {
"user_query": "文「"+src_tab+"」をジョジョっぽく言い換えてください。",
"responses": "",
"inputs": "",
}
src = build_prompt(**inputs)
source_tokenized = self.tokenizer(src, add_special_tokens=False, padding="longest", max_length=SEQUENCE, return_tensors="pt", return_length=True,)
source_len = source_tokenized["length"][0]
inputs["responses"] = "「"+tgt_tab+"」"
tgt = build_prompt(**inputs) + self.tokenizer.eos_token
source_tokenized = self.tokenizer(tgt, add_special_tokens=False, padding="longest", max_length=SEQUENCE, return_tensors="pt")
targets_tokenized = copy.deepcopy(source_tokenized)
targets_tokenized["input_ids"][0][:source_len] = -100
self.inputs.append(source_tokenized)
self.targets.append(targets_tokenized)
Datamoduleクラス
検証データやテストデータ作成のためのデータローダーも設定していますが今回は訓練データのみ利用しています.
class LLMDataModule(pl.LightningDataModule):
def __init__(self, batch_size, FT_path):
super().__init__()
self.batch_size = batch_size
self.FT_path = FT_path
def get_dataset(self, FT_path):
"""データセットを作成する"""
return CreateTokenID(
FT_path,
)
def setup(self, stage=None):
"""初期設定(データセットの読み込み)"""
if stage == 'fit' or stage is None:
self.train_dataset = self.get_dataset(FT_path=self.FT_path+"train")
# self.val_dataset = self.get_dataset(FT_path=self.FT_path+"dev")
if stage == 'test':
self.test_dataset = self.get_dataset(FT_path=self.FT_path+"test")
def train_dataloader(self):
"""訓練データローダーを作成する"""
return DataLoader(self.train_dataset,
batch_size=self.batch_size,
drop_last=True, shuffle=True,
num_workers=4,
)
def val_dataloader(self):
"""バリデーションデータローダーを作成する"""
return DataLoader(self.val_dataset,
batch_size=self.batch_size,
num_workers=4,
)
def test_dataloader(self):
"""訓練データローダーを作成する"""
return DataLoader(self.test_dataset,
batch_size=self.batch_size,
num_workers=4,
)
Trainerクラス
学習クラスです.モデルの読み込みはgpuメモリが限られているためbf16型で読み込みを行っています.さらにメモリを抑えて学習をする場合はLoRA tuning等をするとよいです.LoRA tuningのコードは付録にて説明,githubにてコードを載せています.
今回は訓練のみ回すようにしか設計していません.
class LLMTrainer(pl.LightningModule):
def __init__(self, lr):
super().__init__()
self.model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Swallow-7b-instruct-hf",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
)
self.tokenizer = AutoTokenizer.from_pretrained("tokyotech-llm/Swallow-7b-instruct-hf")
self.tokenizer.add_special_tokens({'pad_token': '<|padding|>'})
self.lr = lr
self.training_step_outputs = []
def forward(self, input_ids, attention_mask, labels=None):
output = self.model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
return output.loss, output.logits
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=self.lr)
def training_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
labels = batch["labels"]
loss, _ = self(input_ids, attention_mask, labels)
self.log("train_loss", loss, prog_bar=True)
wandb.log({"train_step_loss": loss})
self.training_step_outputs.append(loss.item())
return loss
def on_train_epoch_end(self):
epoch_train_loss = sum(self.training_step_outputs) / len(self.training_step_outputs)
wandb.log({"train_loss": epoch_train_loss})
print('-------- Current Epoch {} --------'.format(self.current_epoch + 1))
print('train Loss: {:.4f}'.format(epoch_train_loss))
self.training_step_outputs.clear()
def generate(self, ids, mask):
with torch.no_grad():
output_ids = self.model.generate(
input_ids=ids,
attention_mask=mask,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
output_scores=True,
return_dict_in_generate=True,
pad_token_id=self.tokenizer.pad_token_id,
bos_token_id=self.tokenizer.bos_token_id,
eos_token_id=self.tokenizer.eos_token_id,
)
output = self.tokenizer.decode(output_ids[0][0], skip_special_tokens=True)
return output
main関数
今回はbatch_size 1,学習率 $10^{-4}$,epoch数 50で回しました.
def main():
FT_path = "jojo_"
batch_size = 1
learning_rate = 1e-4
num_epochs = 50
checkpoint_callback = pl.callbacks.ModelCheckpoint(
dirpath="checkpoints_pl",
filename="bestloss_SwallowLoRA_jojo-{epoch:02d}-{train_loss:.2f}-"+date,
monitor="train_loss",
save_last=True,
save_weights_only=True,
mode="min",
)
data_module = LLMDataModule(batch_size, FT_path)
LLM_Module = LLMTrainer(learning_rate).to(DEVICE)
trainer = pl.Trainer(accelerator="gpu", max_epochs=num_epochs, callbacks=[checkpoint_callback])
trainer.fit(LLM_Module, data_module)
アプリケーション化
localhostにてですが,簡単にアプリケーションにしてみようと思いました.streamlitというライブラリでpythonコードを書くだけで簡単にアプリケーションにできるようだったので試してみました.streamlitは自分もあまり詳しくありません.以下コードの一部です.
import streamlit as st
BEST_PATH = "checkpoints_pl/Swallow_jojo_bestmodel.ckpt"
@st.cache_resource
def load_model():
LLM_Module = LLMTrainer().to(DEVICE)
checkpoint_path = BEST_PATH
tokenizer = AutoTokenizer.from_pretrained("tokyotech-llm/Swallow-7b-instruct-hf")
tokenizer.add_special_tokens({'pad_token': '<|padding|>'})
checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
LLM_Module.load_state_dict(checkpoint['state_dict'])
return LLM_Module, tokenizer
def main():
LLM_Module, tokenizer = load_model()
st.title("ジョジョ言い換え")
init_text = "やれやれです"
text = st.text_area("入力したテキストをちょっぴりジョジョっぽく言い換えます.文章を入力してください.", value=init_text, height=150)
if st.button("言い換え"):
user_inputs = {
"user_query": "文「"+text+"」をジョジョっぽく言い換えてください。",
"responses": "",
"inputs": "",
}
text = build_prompt(**user_inputs)
token_ids = tokenizer.encode_plus(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output = LLM_Module.generate(token_ids["input_ids"].to(DEVICE), token_ids["attention_mask"].to(DEVICE))
st.write("回答: ")
st.write(output.replace(text, ""))
streamlitをインポートして,ボタンやテキストボックスの設定を行っています.なおボタンを押した際に逐次コードが実行されてしまうため,毎回モデルをロードすると時間がかかります.@st.cache_resourceのあとの関数は複数回実行された際にキャッシュに変数定義されている場合はそちらを流用するため,モデルロードをそこに持ってくることで時間をかけないようにしています.
To be continued...
(↑ジョジョ関連を取り扱った記事では「結び」をこう書くみたいのなので)
ひととおり作ってみて,日本語LLMはエンタメにも使えるなと実感しました.日本語LLMは今現在もですがテキストを扱うものになら何にでも利用されていくのだと思います.
また今回はデコーダモデルでの検証となりましたが,今回のタスクと似ている翻訳タスクはエンコーダ・デコーダモデルを利用することもあります.データがかなり必要ですが,エンコーダ・デコーダモデルでも気が向いたら試してみたいです.
参考文献
なお訓練データ及び生成したテキストの著作権は荒木氏及び集英社に帰属します.
付録
以下はLoRA trainingコードの一部です.peftライブラリをインストールしてモデル読み込みのあとにLoRAモデルを定義しています.またこの際にattention blockのみにアダプタを作る場合はtarget_modulesをq_projとv_projにしていますが,全レイヤに定義する場合はコメントアウトを外す必要があります.(SwallowはLlama2モデルの継続事前学習モデルためtarget_modulesはこれで問題ないですが,別モデルの場合は各レイヤの名前が異なる場合があるので注意が必要です.)
from peft import get_peft_model, LoraConfig, TaskType
class LLMTrainer(pl.LightningModule):
def __init__(self, lr):
super().__init__()
self.model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Swallow-7b-instruct-hf",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
)
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=[
"q_proj",
# "k_proj",
"v_proj",
# "o_proj",
# "gate_proj",
# "up_proj",
# "down_proj",
# "lm_head",
],
bias="none",
fan_in_fan_out=False,
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
self.model = get_peft_model(self.model, lora_config)
self.model.print_trainable_parameters()
self.tokenizer = AutoTokenizer.from_pretrained("tokyotech-llm/Swallow-7b-instruct-hf")
self.tokenizer.add_special_tokens({'pad_token': '<|padding|>'})
self.lr = lr
self.training_step_outputs = []