はじめに
近年のディープラーニングの応用には興味をそそられる物が数多くありますが、その内の一つに自動文章生成があります。本の文体からその作者が書いたような文章を生成したり、歌詞を学習して新しい曲を作るなど、ワクワクしますよね。ということで、何か文章を作ってみたいと思ったのですが、本や歌などは山ほどやられているので、何かないかなーと考えていたところ、「ジョジョの世界観を学習させてジョジョワールドを構築できたら面白くね?」と思い至りました。まあ、調べた感じあまりやられてないのは学習データが足りなすぎて上手くいかないからなんだろうなーと分かってはいたのですが、一応トライアルでやってみたので共有します。
ジョジョとは
-おまえは今まで食ったパンの枚数をおぼえているのか?
-だが断る
「ジョジョ知らん」という方も、上記のセリフを一度は聞いた事があるのではないでしょうか?ジョジョとは、荒木飛呂彦先生によって1986年から連載されている少年漫画『ジョジョの奇妙な冒険』のことで、「人間讃歌」をテーマとした、独自の世界観を持つ物語(wikiより)です。 その独特な表現手法から、セリフや効果音(ズキュウウウン、メメタァなど)が最もネットで引用されている漫画な気がします。
LSTM
今回用いたアルゴリズムはLSTM(Long Short Term Memory)です。LSTMは、時系列情報を扱うことのできるニューラルネットワークであるRNN(Recurrent Neural Network)の一種で、入力ゲート、出力ゲート、忘却ゲートと呼ばれる三つのゲートを導入することで、従来ではできなかったデータの長期記憶ができるようになり、文章など長い時系列情報でも取り扱う事ができます。
例えば、「おまえは今まで食ったパンの枚数を覚えているのか?」という文を学習するのに、N字を抜き出して次に来る字を学習します。N=10とすると「おまえは今まで食った」が訓練サンプルとなり、次に来る「パ」がラベルになります。そして、この文を例えば3字ずらして新しいデータを作り、「は今まで食ったパンの」→「枚」というように学習していくわけです。この例からも分かるように、文章生成には膨大な文が学習データとして必要になります。名言集程度の量でこの方法をすると日本語崩壊した文になってしまったので一字毎でなく単語毎に学習させました。すなわち「おまえ は 今 まで 食っ た」→「パン」といった具合です。
LSTMの詳細についてはこちらの記事などが参考になります。
LSTMはKerasなどのフレームワークに用意されているので、自分で実装せず簡単に構築する事ができます。
実装
それでは実装していきます。今回のコードはKerasチームが公開しているlstm_text_generation.pyを大部分参考にしています。また、実行環境はGoogle Colanoratoryです。
ライブラリインポート
まず、必要なライブラリをインポートします。
import os
import re
import bs4
import requests
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.optimizers import Adam
from keras.utils.data_utils import get_file
import numpy as np
import random
import sys
import io
import matplotlib.pyplot as plt
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import MeCab
今回はwebサイトからデータを取得して、形態素解析するので、いつもの機械学習ライブラリ以外にも必要なものをインストールしています。最後の4行はMecabというOSSの形態素解析ツールで、文を単語に分解してくれます。
ジョジョ名言取得
次にスクレイピングで名言を取得します。今回はこちらのwebサイトからいただきました。
'''ジョジョ名言取得'''
with open('jojo.txt', 'a') as f:
url = 'http://kajipon.sakura.ne.jp/art/jojo9.htm'
res = requests.get(url)
res.raise_for_status()
'''取得したhtmlをparseし、セリフ行のみ取得'''
soup = bs4.BeautifulSoup(res.content, 'html.parser')
soup = soup.find_all( text=re.compile("「.+?」+(.+?)+第") )
for s in soup:
txt = s.__str__()
'''余分な箇所を削除'''
txt = re.sub('第.+?巻', '', txt)
txt = re.sub('(.+?)', '', txt)
txt = re.sub('※.+', '', txt)
txt = txt.replace('「', '')
txt = txt.replace('」', '')
print(txt)
f.write(txt)
実行結果はこんな感じです(最初の20行のみ)。
なっ!何をするだァーッ!ゆるさんッ!
さすがディオ!俺達に出来ないことを平然とやってのけるッ!そこにシビれる!あこがれるゥ!
ディオォォオオーッ!君がッ!泣くまで!殴るのをやめないッ!
ディオ!おまえのくだらないキスがこれを狙っていたのなら予想以上の効果をあげたぞッ!
君らとは闘う動機の格が違うんだ!
ハッタリぬかすなよーッ!金持ちのアマちゃん!
俺は人間をやめるぞ!ジョジョーッ!!
ちがうッ!あの父親の精神は…息子のジョナサン・ジョースターが立派に受け継いでいる!それは彼の強い意志となり、誇りとなり、未来となるだろうぜッ!!
くっそー!侵入罪でとっつかまろーと、この部屋へ入って思いっきり祝ってやるぜーッ!!
スピードワゴンはクールに去るぜ
まあ!なんてこと!骨折している腕で私を!いつだって支えるさ
運命か…人の出会いってのは運命できめられてるのかもしれねえな…
ウホホホッホッホーッ!
関節を外して腕をのばすッ!その激痛は波紋エネルギーでやわらげるッ!
パパウ!パウパウ!波紋カッターッ!!
お前は今まで食ったパンの枚数を覚えているのか?
『波紋』?『呼吸法』だと?フーフー吹くなら…このおれのためにファンファーレでも吹いてるのが似合っているぞッ!
意外!それは髪の毛ッ!
逆に考えるんだ。“あげちゃってもいいさ”と考えるんだ
ふるえるぞハート!燃え尽きるほどヒート!!おおおおおっ、刻むぞ血液のビート!山吹き色の波紋疾走!!
学習データ作成
上で作ったjojo.txtを読み込んで学習データを作ります。なお、文章や歌詞と違って名言は原則独立なので、時系列性がありません。したがって、前の名言の語尾→次の名言の語幹を繋げないように行ごとに学習データを作ります。まずは名言がいくつあるか見てみましょう。
'''ファイル読み込み'''
path = './jojo.txt'
'''セリフを行単位で取得'''
nline = 0
with io.open(path, encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
nline += 1
print('行数:', nline)
行数: 283
全部で283個の名言がありました。
次に、全ての名言を品詞分解し、登場する全ての単語の入れ物 (corpus)、学習データとなる全ての文の入れ物(sentences)、sentencesに対するラベルの入れ物(next_chars)に要素を詰めていきます。なお、学習データの長さは3単語、次のデータを作るためにずらす間隔は1単語としました。
「おまえ は 今」→「まで」
「は 今 まで」→「食っ」
・・・
'''学習するセンテンスサイズと間隔を設定'''
corpus = []
sentences = []
next_chars = []
maxlen = 3
step = 1
mecab= MeCab.Tagger('-Ochasen')
mecab.parse('')
for line in lines:
'''行ごとに品詞を取得'''
corpusl = []
nodel = mecab.parseToNode(line)
while nodel:
corpusl.append(nodel.surface)
corpus.append(nodel.surface)
nodel = nodel.next
'''学習センテンスと教師ラベルを生成'''
for i in range(0, len(corpusl) - maxlen, step):
sentences.append(corpusl[i: i + maxlen])
next_chars.append(corpusl[i + maxlen])
print('センテンス数', len(sentences))
print('単語数 : ', len(corpus))
'''単語の重複を削除したコーパスを生成'''
chars = set(corpus)
print('コーパスサイズ : ', len(chars))
センテンス数 8136
単語数 : 8984
コーパスサイズ : 1883
Mecabの使い方についてはこちらの記事を参考にしました。
corpuslはその行内での単語を格納した一時的なcorpusです。
今回出てきた全単語数は1883で、生成される文章はこれらの単語から作られます。
コンピュータは単語のままでは扱えないので、単語→インデクスとインデクス→単語に対応した辞書をそれぞれ作成します。
最後に学習データxと教師ラベルyをone-hotベクトルとして作ります。
'''単語→数字と数字→単語に対応した辞書をそれぞれ作成'''
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
'''ベクトル化'''
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
LSTMモデル作成
LSTMモデルを作ります。隠れ層のunit数は128,コスト関数はカテゴリカルクロスエントロピー、最適化手法はAdamです。
'''LSTMモデル作成'''
model = Sequential()
model.add(LSTM(128, input_shape = (maxlen, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
optimizer = Adam()
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 128) 1030144
_________________________________________________________________
dense_1 (Dense) (None, 1883) 242907
=================================================================
Total params: 1,273,051
Trainable params: 1,273,051
Non-trainable params: 0
_________________________________________________________________
学習
準備ができたので学習していきます。
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
'''epoch毎に生成したセリフを表示する関数'''
def on_epoch_end(epoch, _):
print()
print('----- %d epoch:' % epoch)
start_index = random.randint(0, len(corpus) - maxlen -1)
for diversity in [8.0, 16.0, 32.0, 64.0, 128.0, 256, 512, 1024]:
print('----- diversity:', diversity)
generated = ''
sentence = corpus[start_index: start_index + maxlen]
generated += ''.join(sentence)
print('-----シード "' + ''.join(sentence) + '" で生成:')
sys.stdout.write(generated)
for i in range(10):
x_pred = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose = 0)[0]
next_index = sample(preds, diversity)
next_char = indices_char[next_index]
sentences.append(next_char)
sys.stdout.write(next_char)
sys.stdout.flush()
print()
sampleは確率分布をサンプリングする関数で、tempertureが高いほど予測の低い単語も使うそうです。(https://www.freecodecamp.org/news/applied-introduction-to-lstms-for-text-generation-380158b29fb3/)
オリジナルでは0.2~1.2のような低い値を使っていますが、本データだと数が少なすぎるためか同じ単語しか出力しなくなった(おそらく"安全な"出現頻度の高い単語をひたすら出力している)ので、大きな値にしていろいろな単語を使うようにしています。1エポック毎にランダムに3単語を選び、続く10単語を予測して文を表示させます。
上記の関数を渡してfitします。
print_callback = LambdaCallback(on_epoch_end = on_epoch_end)
history = model.fit(x, y, batch_size=128, epochs=60, callbacks=[print_callback])
学習結果
実行結果は次のようになりました。(抜粋)
~~~
Epoch 5/60
8136/8136 [==============================] - 1s 98us/step - loss: 5.5118
----- 4 epoch後に生成されたセリフ:
----- diversity: 8.0
-----シード "がァーッ!" で生成:
がァーッ!さわやか全員燃え尽きる行うスイだが伝え全部嬉しいドイツ
----- diversity: 16.0
-----シード "がァーッ!" で生成:
がァーッ!ス呼ぶ行うちょ感じこの厳しいスピード誠来
----- diversity: 32.0
-----シード "がァーッ!" で生成:
がァーッ!探すモンキー姿べく可能キチッうけるも輝くこ
----- diversity: 64.0
-----シード "がァーッ!" で生成:
がァーッ!直前知れェェ迷惑プログレバンドお許しジャマかまいW女の子
----- diversity: 128.0
-----シード "がァーッ!" で生成:
がァーッ!来い困難ヘラヘラ埋っすまんマヌケ許さいつく!ぇ
----- diversity: 256
-----シード "がァーッ!" で生成:
がァーッ!するしまっいんザマミロ富士山海ヴェネツィアジョルノッ世界災難
----- diversity: 512
-----シード "がァーッ!" で生成:
がァーッ!尊敬最初みじめほ勇気Wいさぎよくかけこういう万
----- diversity: 1024
-----シード "がァーッ!" で生成:
がァーッ!戦闘Fサメくたばれやっ正しい愛しはっ賭けひょっと
~~~
ジョジョっぽい単語だけど支離滅裂で何がなんやらという感じですね…
~~~
Epoch 33/60
8136/8136 [==============================] - 1s 98us/step - loss: 2.3640
----- 32 epoch後に生成されたセリフ:
----- diversity: 8.0
-----シード "祖父のジョセフ" で生成:
祖父のジョセフちょ話ちょ根ちょ星入っ初恋ない俺
----- diversity: 16.0
-----シード "祖父のジョセフ" で生成:
祖父のジョセフ脳みそ国にかわいい神命がけあり留めォオオォオオオーッやってのける
----- diversity: 32.0
-----シード "祖父のジョセフ" で生成:
祖父のジョセフだろ戦士アアアアア行うレナイッ重要くれる--。の!
----- diversity: 64.0
-----シード "祖父のジョセフ" で生成:
祖父のジョセフ役アンタ撃たでもられ左ラカイハンサムォォォォヘヘヘヘ
----- diversity: 128.0
-----シード "祖父のジョセフ" で生成:
祖父のジョセフ思い出す暮らしくらっネンザ結成もらうなしあり恋並ぶ
----- diversity: 256
-----シード "祖父のジョセフ" で生成:
祖父のジョセフ豚ジョセフられ守るココなさい下すジョジョォォォーーーッ砂漠スカッ
----- diversity: 512
-----シード "祖父のジョセフ" で生成:
祖父のジョセフやれ素顔入っスイエエエエエエエエ邪魔まなざし行く薬学秘密
----- diversity: 1024
-----シード "祖父のジョセフ" で生成:
祖父のジョセフテメー勝てふるえる砂漠いつく折っ付き合い真っ黒ジャマ伝わっ
~~~
多少日本語になってきた感がしないでもないです。
それにしても「祖父のジョセフ脳みそ国」のようなおっかない言葉も出てきています。
~~~
Epoch 60/60
8136/8136 [==============================] - 1s 104us/step - loss: 0.7271
----- 59 epoch後に生成されたセリフ:
----- diversity: 8.0
-----シード "直前まで問題" で生成:
直前まで問題オ怖い量チェリーうける銃撃超え無関係傷つい
----- diversity: 16.0
-----シード "直前まで問題" で生成:
直前まで問題ジョジョーッいつも強なさい謎国王センチ美し関係朝日
----- diversity: 32.0
-----シード "直前まで問題" で生成:
直前まで問題乗客根性まで納得大車輪味方立つ役に立ち昔娘
----- diversity: 64.0
-----シード "直前まで問題" で生成:
直前まで問題っぽく受験生入れジャマ重要差外し無知やり残酷
----- diversity: 128.0
-----シード "直前まで問題" で生成:
直前まで問題気持ち奪っまでかまいエネルギーやめ際立たもっともっフリ
----- diversity: 256
-----シード "直前まで問題" で生成:
直前まで問題母さんコーラ216なにゲドゲド者パパウ血統名誉並ぶ
----- diversity: 512
-----シード "直前まで問題" で生成:
直前まで問題針決断作るスターヴァルキリー探せぱあ法律逆らっフリ
----- diversity: 1024
-----シード "直前まで問題" で生成:
直前まで問題幸福子分かる面前じいさんとっつかまろ命令でるべくもらう
風邪で寝込んで辛いときに脳内に出てきそうな文字列ですね。
60epoch走らせましたが、やはり日本語としておかしくない文はなかなかできませんでした。
単語数やデータ数を考えると妥当だと思います。
しかし、「パパウ血統」や「スターヴァルキリー」などあれかな?と思わせるような単語が随所に出てくるのはジョジョファンとしては非常に面白かったです。改善点はたくさんあると思いますが、改善しても厳しいと思うので今回はここまでにします。
トライアルにしてはまずまずでした。やはり文章生成は面白いですね。
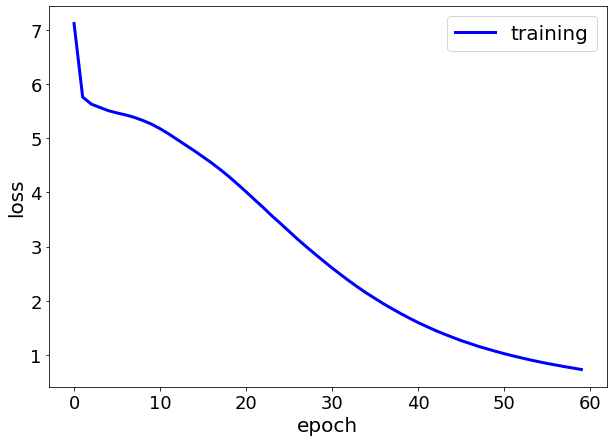
GitHubにコードを置いているので興味があったら遊んでみてください。最後に、コスト関数をプロットしておきます。
'''loss可視化'''
plt.figure(figsize=(10,7))
loss = history.history['loss']
plt.plot(loss, color='b', linewidth=3)
plt.tick_params(labelsize=18)
plt.ylabel('loss', fontsize=20)
plt.xlabel('epoch', fontsize=20)
plt.legend(['training'], loc='best', fontsize=20)
plt.show()