数あるフレームワークに付属するExample、機械学習モデルを実装してみた、という話。これらに共通して言えるのは「テストがない」ということです。
機械学習のモデルだって、アプリケーションに組み込まれればプロダクションコードの一部です。テストがない実装を本番環境に組み込むか?というと通常そんなことありえないと思います。
 ([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
忘れられがちな点ですが、機械学習モデルは「リリースした瞬間」が最高精度になります。なぜなら、リリースした瞬間こそがその時点で手に入るフルフルのデータを使って鍛え上げたモデルであり、それ以降はどんどん未知のデータが入ってくるためです。
そのため、モデルの精度、また妥当性をいつでも検証できるようにしておくというのはとても重要です。これは通常のコードにテストをつける理由と同等で、つまり機械学習モデルだからと言って特別ではないということです。
本稿では、この機械学習モデルのテストの手法について解説をしていきます。もちろん、これは私が現時点で実践している手法であり、今後機械学習のアプリケーションへの適用が進んでくるにつれ、より実践的な手法のノウハウも普及していくのではないかと思います。
機械学習モデルの設計
まず、テストを実施するには適切な設計が行われている必要があります。この点については前に解説をした資料があるので、そちらから引用したいと思います。
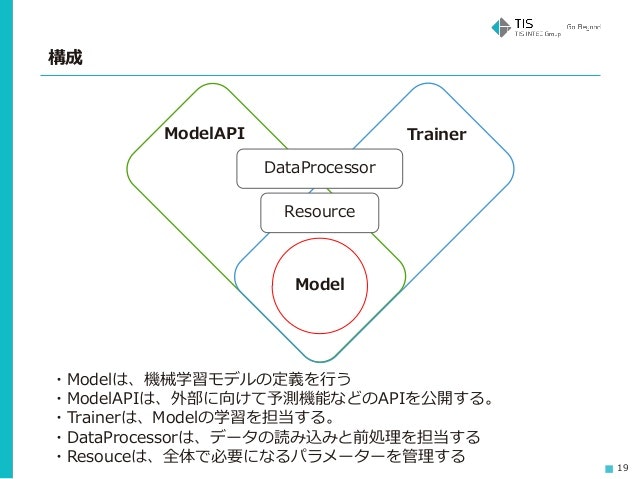
Modelが実際の機械学習モデル(scikit-learnやChainer、TensorFlowで構築するもの)で、多くの場合そこにすべての処理が詰め込まれています。それを、以下のように分けよう、という話です。
- 学習をさせる処理はTrainerに
- 外部からモデルを呼ぶ処理との橋渡しはModelAPIに
- データの抽出、前処理はDataProcessorに
- 学習パラメーター、保存したモデルなどの管理はResourceに
これによって精度が出ないなどの問題が発生した際に、それがモデル本体の問題なのか、学習のさせ方が悪いのか、実はモデルは大丈夫でアプリケーション側から使うときだけ問題があるのか、はてはデータの前処理でミスっているのかなどを切り分けて検証・テストできるようにしよう、ということです。
ただ、入力/出力が明確に定義できる通常のプログラムに比べて、機械学習は出力が不定になります。DataProcessorやResourceは通常のプログラムとほぼ同等のためテストしやすいですが、Model本体も含めたTrainer、ModelAPIについてはこの点が問題になります。
上の資料ではこの点について細かい言及はしなかったのですが、ここからこれらのテストについて見ていきたいと思います。
機械学習モデルのテスト
機械学習モデルにおいてテストすべきことは、主に以下の4点です。
- 動作テスト(Operation Test): 機械学習の実装にエラーがないかをチェックするテスト
- 検証テスト(Verify Test): 機械学習モデルの有効性を検証するためのテスト(ベースラインとの比較など)
- 連携テスト(Integration Test): アプリケーションからの呼び出しが正常に行われるかのテスト
- 評価テスト(Evaluation Test): 実際のサービスで評価指標(KPI)に貢献するかのテスト
これらのテストについて、順を追ってみていきたいと思います。なお、以後のコードの紹介では最近開発した以下のリポジトリから引用していきます。
こちらはTensorFlowベースですが、ほかのライブラリでも考え方は使えると思います(以前Chainerを使った際も同様の設計・テストを行いました)。逆にTensorFlowを使っているとテスト中ハマる点があるので、その問題点への対処についても言及していきます。
動作テスト(Operation Test)
動作テストでは、Modelについてそもそも入力から出力までエラーを吐かずに動くかどうかをチェックします。ニューラルネットワークのモデルの場合は、伝搬(Forward)チェックともいえます。
こちらが、実際に使ったコードになります。
tensorflow_qrnn/test_tf_qrnn_forward.py
入力はランダムなものでかまわないので、出力まできちんと通るかどうかを確認します。
動作テストはモデルの開発・組み替えなどを行っているときにとりあえず動くかどうかを「なるべく軽く+早く検証する」のが目的で、開発中頻繁に使います(使いました)。そういう意味では、位置づけとしてはコンパイルに近いです。
なお、TensorFlowではunittestを走らせると複数のTestがGlobal Graphの情報を共有し意図しないエラーが発生します。そのため、テストケースごとにGraphを分ける必要がある点に注意してください。
class TestQRNNForward(unittest.TestCase):
def test_qrnn_linear_forward(self):
batch_size = 100
sentence_length = 5
word_size = 10
size = 5
data = self.create_test_data(batch_size, sentence_length, word_size)
with tf.Graph().as_default() as q_linear:
qrnn = QRNN(in_size=word_size, size=size, conv_size=1)
...
特に、変数スコープが切られていないとこの現象はカオス化します。基本的に、TensorFlow利用時においては変数宣言時にvariable_scopeで変数スコープをしっかり切っていくことが重要になります(name_scopeだと重複をチェックできない)。
class QRNNLinear():
def __init__(self, in_size, size):
self.in_size = in_size
self.size = size
self._weight_size = self.size * 3 # z, f, o
with tf.variable_scope("QRNN/Variable/Linear"):
initializer = tf.random_normal_initializer()
self.W = tf.get_variable("W", [self.in_size, self._weight_size], initializer=initializer)
self.b = tf.get_variable("b", [self._weight_size], initializer=initializer)
スコープについてはこちらの記事が詳しいため、ぜひ参考にしてください(TensorBoardでの表示も含め結構技がいるので、その件については別途まとめようと思います)。いずれにせよ、TensorFlow利用時には以下のことを頭においていただければと思います。
 ([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
検証テスト(Verify Test)
動作テストが通るモデルができたら、即本番データを使って学習、というのはちょっと性急です。本番データはそのボリュームも相当なものでしょうし、そのため学習に時間もかかります。よほどの自信がなければ、まず自分のモデルが意図した動作をし、ベースラインよりも良い精度を記録するか、小さめのデータで確認すべきです。これが検証テストです。
逆に言えば、検証テスト用のデータセットとそれに対するベースラインモデルを作っておくことが、機械学習モデルの改善プロセスに役立ちます。検証テスト用のデータセットとは、扱いやすいサイズで、比較的短い時間で学習が完了するようなデータセットです。そして、ベースラインモデルとは、「これを超えてなければNG」という基本的なモデルです。
これがないと、「あともう少しデータを増やせばよくなるかもしれない」「あともう少し学習時間をかければ精度がよくなるかもしれない」という妄想にとらわれて、本質であるアルゴリズムの改善に目がいかなくなる傾向があります。

「うちは本番同等のデータがすぐに扱えるから大丈夫」というのも結構罠で、本番データは実際のデータであるがゆえに傾向が大きく偏っていることがあります(例えば、画像による診断で通常は90%が異常なしの場合単純に「異常なし」と予測するモデルでも90%の精度になる)。データの偏りによって判断に偏りが生まれてしまうのは機械学習における基本的な事項ですが、「本番データを使っている」という安心感がそうした点から目をそらしがちにさせてしまいます。
上記のような問題点を解消するためにも、「扱いやすいサイズ」かつ「ラベルのバランスの取れた」検証テスト用データとその環境を整えることを推奨します。
下記の実装では、scikit-learnに付属しているdigitという手書き文字のデータセットでテストしています。scikit-learnには手書き文字などのデータセットがあらかじめ付属しているため、これが利用できればデータを用意する手間が省けます。
tensorflow_qrnn/test_tf_qrnn_work.py
本番データがある場合は、単純に期間で抜くのでなく、目的のラベルを勘案しバランスよくサンプリングしたデータセットを作っておくと良いでしょう。これでlossが下がり、精度がきちんと出ているかチェックします。
ベースラインとの比較も検証テストの重要な役割です。一生懸命作ったニューラルネットワークのモデルより、SVMの方が断然よかったなんてことはままある話です(※ベースラインに使うモデルもちゃんとチューニングしましょう。大切なのはニューラルネットを使うことでなく、あなたの目的に合ったモデルを探すことだからです)。幸いscikit-learnには様々なモデルが付属しているため、この検証にはうってつけです。それほど大層なコードを書くことなく、ベースラインとなるモデルとの比較検証ができると思います。
この検証テストという関門を設けることで、筋の悪いモデルに費やす時間とお金(GPU代)を節約できます。
 ([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
([スタジオジブリ 紅の豚](https://www.amazon.co.jp/dp/B00005R5J6) より拝借)
ただ、延々と学習させないと精度が出ないモデルがあることも事実です。こうした場合は、学習時間に対するloss/精度の値(ヴェロシティ的なもの)を記録しておき、それをチェックすることで代替するという手もあります。
連携テスト(Integration Test)
連携テストでは、アプリケーションからの呼び出しが正常に行われるかどうかをチェックします。機械学習モデルを利用する場合、テストすべきなのはその精度だけではなく、前処理なども含みます。
よって、連携テストに当たっては先にDataProcessorは単独でテストをしておきます。その上で、アプリケーションから利用する際のModelAPIが正常に機能するかをテストします。精度については先ほどの評価テスト同様に、検証しやすいサイズのデータセットを用意しておきそれでModel API、つまり実際アプリケーションで稼働する際の精度をテストをすると良いです。というのも、連携テスト時には以下のようなことがよく起こります。
- 予測処理にかける前に、前処理をするのを忘れていた
- 予測結果に、変換をかけるのを忘れていた(値の予測の場合は特に、学習時は予測値を正規化しているので実際に利用する際は逆正規化を行い値をもとに戻す必要がある)
このため、単純に機能するかだけでなく精度を計測しておくことをお勧めします。
このModel APIの精度のテストに使用するデータセットは、機械学習モデルのパフォーマンスを定常的に監視するのにも役立ちます。これにより、再学習・再構築のタイミングを判断できるので、その意味でも評価テストとは別に連携テストを用意しておくことをおすすめします(評価テストよりはもう少し実態よりのデータになる)。
評価テスト(Evaluation Test)
検証テストでベースラインよりも上回っている、連携テストによりアプリケーションから呼べるのも確認している、となった段階で評価テストに移行します。
ここでは、所謂A/Bテストなどを実施します。実施にあたって、必要に応じ検証テストを超える量でのデータでしっかりと学習させます。その後に、既存のモデルと比べて優位に働くかどうかをチェックします。
評価テストの段階でチェックする指標と、検証テストでチェックする指標は大きく異なります。検証テストの段階では精度などのモデルの性能を表す指標をチェックし、評価テストでは「ユーザーのエンゲージメント率」などサービスにおけるKPI(Key Performance Indicator)をチェックします。
最終的に重要なのは精度が高いモデルを構築することではなく、サービスに貢献する、つまりユーザーに価値を与えるモデルを構築することです。この点をチェックするのが、評価テストになります。
以上が、機械学習モデルの実装におけるテスト手法についてになります。実際私も試行錯誤しながら行っているので、こうしているよ、みたいなご意見があればぜひお寄せいただけたらなと思います。
