イントロ
これは、TensorFlow Advent Calendar 2016 の9日目の記事です.
2015年の11月に公開されたTensorFlowですが,公開当初から「名前空間」の機能がサポートされていました.これはTensorBoardによるグラフ視覚化において使われますが,もちろんそのためだけにあるわけではありません.名前空間は,識別子の管理に非常に有効です.強力な「名前空間」サポートというとC++を思い出しますが,C++の教則本(独習C++)から引用します.
名前空間(namespace)の目的は識別子の名前を局所化し,名前の競合を避けることです.C++のプログラミング環境では,変数,関数,クラスの名前が急増を続けてきました.名前空間が登場する前は,これらのすべての名前がグローバルな名前空間の中で場所を取り合い,多くの競合が発生していました.
一方,Pythonの変数スコープは,ローカル,グローバル(global),+α (nonlocal) と最低限のものしか持っていませんので,TensorFlowのコア部分をC++で書いていたGoogleのエンジニアが,C++レベルの名前空間サポートをTensorFlowに実装しよう,と考えるのは自然と思われます.
Neural Networkも層があまり多くないMLP(Multi-Layer Perceptron)等では,名前管理は困りませんが,深いCNNや,RNNで見られる大きなモデルに対しては,重み共有もありますので,きちんとした変数スコープが必要となります.また,スケールアップを考えると(私自信はほとんど経験ありませんが)Multi-Device(GPU),クラスタといった分散環境にコードを適用させなければなりません.ここでも変数スコープが必要となります.
本記事では,TensorFlowの「名前空間」をしっかりと理解する,という目的で関連APIを確認していきたいと思います.
(プログラミング環境は,TensorFlow 0.11.0, Python 3.5.2, Ubuntu 16.04LTS になります.)
TensorFlow 変数スコープの引っ掛かりポイント
きちんとドキュメントを読めば変数スコープは難しくありませんが,「あいまい」に理解していると以下の点が引っかかるかと思います.
- スコープの定義用に,tf.name_scope() と tf.variable_scope() があるけど何が違うの?
- TensorFlowの変数定義に tf.Variable() を使うと覚えているけど,tf.get_variable() は,いつ使うの?
先に答えを書きますが,設問1への解答は,tf.name_scope() はより汎用的に使うスコープ定義で,tf.variable_scope()は,変数(識別子)を管理するための専用のスコープ定義になります.また,設問2への解答は,tf.Variable() は,よりプリミティブ(低レベル)の変数定義であるのに対し, tf.get_variable() は,変数スコープを考慮した(より高レベルの)変数定義になります.
(関連ドキュメント,TesorFlow - "HOW TO" - "Sharing Variable" に共有変数関係が詳しく説明されています.)
以下,コードを動かして詳細を調べてみたいと思います.
# tf.name_scope
with tf.name_scope("my_scope"):
v1 = tf.get_variable("var1", [1], dtype=tf.float32)
v2 = tf.Variable(1, name="var2", dtype=tf.float32)
a = tf.add(v1, v2)
print(v1.name) # var1:0
print(v2.name) # my_scope/var2:0
print(a.name) # my_scope/Add:0
まず,tf.name_scope() を使って,その中で変数を定義しました.TensorFlowが管理する識別子は,後半に出力させていますが,その出力を print文の右にコメントで表示しています.tf.Variable() で定義した変数v2と,加算演算aに対しては,きちんと "my_scope" のスコープが定義されています.一方で, tf.get_varible() で定義したv1は,見事にスコープを無視してくれました.
# tf.variable_scope
with tf.variable_scope("my_scope"):
v1 = tf.get_variable("var1", [1], dtype=tf.float32)
v2 = tf.Variable(1, name="var2", dtype=tf.float32)
a = tf.add(v1, v2)
print(v1.name) # my_scope/var1:0
print(v2.name) # my_scope_1/var2:0 ... スコープ名がupdateされている.
print(a.name) # my_scope_1/Add:0 ... update後のスコープ名が維持されている.
次に tf.variable_sope() を使いました.(一つ前のスニペットと今回のスニペットは,連続して動かしていることに注意してください.)
tf.get_variable() で定義した変数v1 は,ねらい通りに "my_scope" が変数名についた形で識別子が作られました.また,その下の変数v2と,演算aは,(tf.variable_scope("my_scope") としたにもかかわらず)"my_scope_1" が加わっています.この理由は,本来(プログラム初期状態であったら)"my_scope" をつけるはずでしたが,すでに同じ識別子("my_scope/var2:0")が一つ前のコードスニペットで使用済みであったため,自動で "my_scope_1" にupdateしたためです.(スコープ名のupdate ("my_scope" -> "my_scope_1")後のステートメント a = tf.add(v1, v2) では,このスコープ("my_scope_1")が維持されるようです.)
ややこしくなってきたので,少し整理します.
- tf.name_scope() は,汎用的に用いる名前スコープ定義です.(ご存知の通り,TensorBoardへの出力は,この識別子設定を用います.)
- tf.variable_scope() は,変数の管理に用いるスコープ定義です.(関数名 variable_scope そのままですが...)
- tf.get_variable() は,変数名の識別子(新規か?重複がないか?)を管理しながら,変数の定義を行います.必ず tf.variable_scope() とセットで使います.
上記2つのスニペットでは,実験のため状況を複雑にしていましたが,「tf.get_variable() は,tf.variable_scope()とセットで使う」という基本を守れば,特に難しくありません.
では,tf.get_variable() を使って,共有変数を使うやり方を見ていきたいと思います.
with tf.variable_scope("my_scope2"):
v4_init = tf.constant_initializer([4.])
v4 = tf.get_variable("var4", shape=[1], initializer=v4_init)
print(v4.name) # my_scope2/var4:0
まず,スコープ "my_scope2" の中で,変数 v4 を定義しました.tf.get_variable() では,変数イニシャライザを指定して変数を定義します.ここでは,定数のイニシャライザを使って,v4 に 4. が入るステートメントとしました.TensorFlowへの識別子は,第1引数で "var4" を指定しました.
次に同じ識別子で変数を確保することを試行してみます.
with tf.variable_scope("my_scope2"):
v5 = tf.get_variable("var4", shape=[1], initializer=v4_init)
ValueError: Variable my_scope2/var4 already exists, disallowed. Did you mean to set reuse=True in VarScope? Originally defined at:
File "name_scope_ex.py", line 47, in <module>
v4 = tf.get_variable("var4", shape=[1], initializer=v4_init)
予定通りです.ValueErrorが発生しました.「同じ識別子で変数を取るのはおかしいのでは?」というエラーです.同じ識別子を使っての変数再割当は,以下のように reuse オプションを用います.
with tf.variable_scope("my_scope2", reuse=True):
v5 = tf.get_variable("var4", shape=[1])
print(v5.name) # my_scope2/var4:0
あるいは,以下のようにしてもokです.
with tf.variable_scope("my_scope2"):
tf.get_variable_scope().reuse_variables()
v5 = tf.get_variable("var4", shape=[1])
print(v5.name) # my_scope2/var4:0
以上,tf.variable_scope() と tf.get_variable() の基本機能を確認しました.
共有変数の例 - 自己符号化器(Autoencoder)
さて,共有変数の使用例をみていきたいと思いますが,TensorFlow - Sharing Variable のドキュメントでは,以下の使用例を参考にせよとあります.
- models/image/cifar10.py, Model for detecting objects in images.
- models/rnn/rnn_cell.py, Cell functions for recurrent neural networks.
- models/rnn/seq2seq.py, Functions for building sequence-to-sequence models.
いずれも相当なコード量ですので,今回は,これらとは別の自己符号化器(以下,Autoencoder) の重み共有を取り上げたいと思います.Autoencoderのencode側 / decode側は次のように表すことができます.
y = f(\textbf{W}x + \textbf{b}) \\
\hat{x} = \tilde{f}(\tilde{\textbf{W}}y + \tilde{\textbf{b}})
このような対称な形のAutoencoderでは次のような重み共有を用いることができます.
\tilde{\textbf{W} } = \textbf{W} ^{\mathrm{T}}
以上のような構成ネットワークをTensorFlowの共有変数を用いて実装してみます.最初にEncoderクラスを定義します.
# Encoder Layer
class Encoder(object):
def __init__(self, input, n_in, n_out, vs_enc='encoder'):
self.input = input
with tf.variable_scope(vs_enc):
weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.05)
W = tf.get_variable('W', [n_in, n_out], initializer=weight_init)
bias_init = tf.constant_initializer(value=0.0)
b = tf.get_variable('b', [n_out], initializer=bias_init)
self.w = W
self.b = b
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.sigmoid(linarg)
return self.output
変数スコープをオプション vs_enc で指定して設定し,その中で tf.get_variable() でWを定義しています.次にDecoderクラスですが,以下のようにしました.
# Decoder Layer
class Decoder(object):
def __init__(self, input, n_in, n_out, vs_dec='decoder'):
self.input = input
if vs_dec == 'decoder': # independent weight
with tf.variable_scope(vs_dec):
weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.05)
W = tf.get_variable('W', [n_in, n_out], initializer=weight_init)
else: # weight sharing (tying)
with tf.variable_scope(vs_dec, reuse=True): # set reuse option
W = tf.get_variable('W', [n_out, n_in])
W = tf.transpose(W)
with tf.variable_scope('decoder'): # in all case, need new bias
bias_init = tf.constant_initializer(value=0.0)
b = tf.get_variable('b', [n_out], initializer=bias_init)
self.w = W
self.b = b
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.sigmoid(linarg)
return self.output
大部分はEncoderクラスと同じですが,変数Wの定義文を分岐で処理しています.ネットワーク定義部は次のようになります.
# make neural network model
def make_model(x):
enc_layer = Encoder(x, 784, 625, vs_enc='encoder')
enc_out = enc_layer.output()
dec_layer = Decoder(enc_out, 625, 784, vs_dec='encoder')
dec_out = dec_layer.output()
return enc_out, dec_out
Decoderオブジェクトを生成する際,vs_dec='decoder' を指定するか,このオプションを省略すれば,重み変数 W は新規に確保され,上記 vs_dec='encoder' のようにEncoderで用いた変数スコープと同じにした場合,重み変数は,共有変数としてW を再使用するように実装しました.(再使用する場合は,ネットワークと整合させるように W を転置します.)
MNISTデータでの計算実行例を示しますが,まず重み共有をしない場合,次のようになります.
Training...
step, loss = 0: 0.732
step, loss = 1000: 0.271
step, loss = 2000: 0.261
step, loss = 3000: 0.240
step, loss = 4000: 0.234
step, loss = 5000: 0.229
step, loss = 6000: 0.219
step, loss = 7000: 0.197
step, loss = 8000: 0.195
step, loss = 9000: 0.193
step, loss = 10000: 0.189
loss (test) = 0.183986
重み共有をした場合は,次の通りです.
Training...
step, loss = 0: 0.707
step, loss = 1000: 0.233
step, loss = 2000: 0.215
step, loss = 3000: 0.194
step, loss = 4000: 0.186
step, loss = 5000: 0.174
step, loss = 6000: 0.167
step, loss = 7000: 0.154
step, loss = 8000: 0.159
step, loss = 9000: 0.152
step, loss = 10000: 0.152
loss (test) = 0.147831
重み共有の設定により,同じ学習回数での損失(cross-entropy)低下が速くなっています.ネットワークの自由度が約半分ですので,予想通りの結果と言えます.
やや複雑なモデルの例 - 2つのMLPを持つ分類器
もう一つ,やや複雑なモデルを考えてみます.(といってもそれほど複雑ではないのですが...) 扱うデータは上と同様,MNISTを用います.今回は,多クラス分類を行います.分類器としては,隠れ層 x2, 出力層 x1のMLP(Multi-layer Perceptron) を用いました.下図は,TensorBoard のグラフ・チャートです.
Fig. Graph of 2 MLP networks
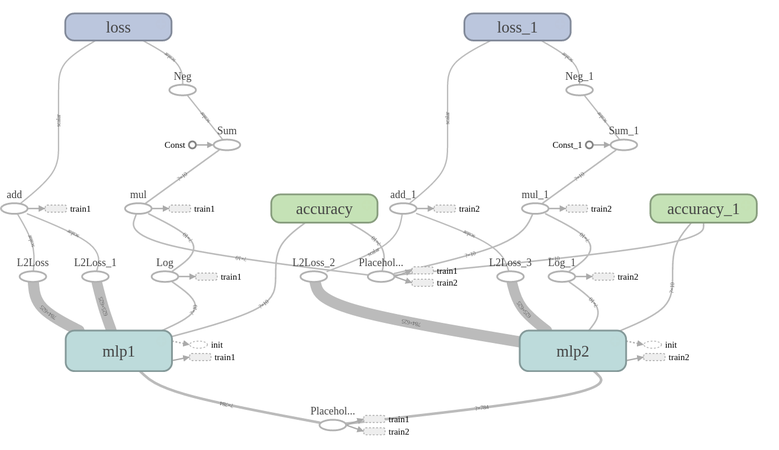
(TensorBoard については使いこなせていません.大まかなイメージとしてとらえて下さい.)
まず,隠れ層(全結合層)と出力層のクラスを定義します.
# Full-connected Layer
class FullConnected(object):
def __init__(self, input, n_in, n_out, vn=('W', 'b')):
self.input = input
weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.05)
bias_init = tf.constant_initializer(value=0.0)
W = tf.get_variable(vn[0], [n_in, n_out], initializer=weight_init)
b = tf.get_variable(vn[1], [n_out], initializer=bias_init)
self.w = W
self.b = b
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.relu(linarg)
return self.output
#
# Read-out Layer
class ReadOutLayer(object):
def __init__(self, input, n_in, n_out, vn=('W', 'b')):
self.input = input
weight_init = tf.random_normal_initializer(mean=0.0, stddev=0.05)
bias_init = tf.constant_initializer(value=0.0)
W = tf.get_variable(vn[0], [n_in, n_out], initializer=weight_init)
b = tf.get_variable(vn[1], [n_out], initializer=bias_init)
self.w = W
self.b = b
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.softmax(linarg)
return self.output
クラスコンストラクタのオプションで,変数名をセットするようにしていますが,ここでは変数共有の操作を行っていません.次に,ネットワーク定義を行う部分が以下です.
# Create the model
def mk_NN_model(scope='mlp', reuse=False):
'''
args.:
scope : variable scope ID of networks
reuse : reuse flag of weights/biases
'''
with tf.variable_scope(scope, reuse=reuse):
hidden1 = FullConnected(x, 784, 625, vn=('W_hid_1','b_hid_1'))
h1out = hidden1.output()
hidden2 = FullConnected(h1out, 625, 625, vn=('W_hid_2','b_hid_2'))
h2out = hidden2.output()
readout = ReadOutLayer(h2out, 625, 10, vn=('W_RO', 'b_RO'))
y_pred = readout.output()
cross_entropy = -tf.reduce_sum(y_*tf.log(y_pred))
# Regularization terms (weight decay)
L2_sqr = tf.nn.l2_loss(hidden1.w) + tf.nn.l2_loss(hidden2.w)
lambda_2 = 0.01
# the loss and accuracy
with tf.name_scope('loss'):
loss = cross_entropy + lambda_2 * L2_sqr
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y_pred,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return y_pred, loss, accuracy
この関数で,オプションとして変数スコープ scope と変数共有フラグである reuse を取るような仕様としました.2つのMLPネットワークで,重み共有は,次のようにスコープ名を揃えてreuse フラグをたてます.
y_pred1, loss1, accuracy1 = mk_NN_model(scope='mlp1')
y_pred2, loss2, accuracy2 = mk_NN_model(scope='mlp1', reuse=True)
重み共有しない場合は,以下のように設定します.(当たり前の構文ではありますが...)
y_pred1, loss1, accuracy1 = mk_NN_model(scope='mlp1')
y_pred2, loss2, accuracy2 = mk_NN_model(scope='mlp2')
計算実験としては,以下の2つのケースを行いました.
- 訓練(Train)データは2つに分割し,2つの分類器 'mlp1', 'mlp2' に供給する.
2つの分類器は,重み共有を設定する.'mlp1'の訓練,'mlp2'の訓練とシリアルに行い.最終的なパラメータを用いてテスト(Test)データを分類する. - 訓練(Train)データは2つに分割し,2つの分類器 'mlp1', 'mlp2' に供給する.'mlp1' と 'mlp2' は独立した(共有設定していない)ネットワークで,それぞれ学習を行う.テストデータはそれぞれの分類器にかけ,その結果をaveragingして,最終分類結果を得る.
重み共有の実験がしたかったので,2つの分類器の層数,ユニット数は同じにする必要があります.但し,全く同じ分類器ではつまらないので,オプティマイザーを別々のものとし,また学習率も微妙に調整しています.
まず,ケースNo.1の実行結果が下記になりました.
Training...
Network No.1 :
step, loss, accurary = 0: 178.722, 0.470
step, loss, accurary = 1000: 22.757, 0.950
step, loss, accurary = 2000: 15.717, 0.990
step, loss, accurary = 3000: 10.343, 1.000
step, loss, accurary = 4000: 9.234, 1.000
step, loss, accurary = 5000: 8.950, 1.000
Network No.2 :
step, loss, accurary = 0: 14.552, 0.980
step, loss, accurary = 1000: 7.353, 1.000
step, loss, accurary = 2000: 5.806, 1.000
step, loss, accurary = 3000: 5.171, 1.000
step, loss, accurary = 4000: 5.043, 1.000
step, loss, accurary = 5000: 4.499, 1.000
accuracy1 = 0.9757
accuracy2 = 0.9744
Network No.2 の学習開始時に,lossが若干増えていますが,No.1 の学習開始時の値比べてかなり小さい点に着目ください.これは,重み共有の結果,(No.1の学習結果を引き継ぎ)パラメータがNo.2の初めから適正化されたところからスタートしたことを示しています.但し,最終的に得られた分類精度,accuracy2 = 0.9744 は,accuracy1 からの向上がなく,この ”アンサンブル学習 もどき”が失敗であることが分かりました.
考えてみれば当然で,分類器として同じものを2回の学習で使いまわしている状況となっていて,
単に学習データを2回に分割して供給しただけですので,これではアンサンブルによる精度向上を期待できません.
ケースNo.2の独立分類器構成で,正しいアンサンブルを行った結果が下記になります.
Training...
Network No.1 :
step, loss, accurary = 0: 178.722, 0.470
step, loss, accurary = 1000: 15.329, 0.990
step, loss, accurary = 2000: 12.242, 0.990
step, loss, accurary = 3000: 10.827, 1.000
step, loss, accurary = 4000: 10.167, 0.990
step, loss, accurary = 5000: 8.178, 1.000
Network No.2 :
step, loss, accurary = 0: 192.382, 0.570
step, loss, accurary = 1000: 10.037, 0.990
step, loss, accurary = 2000: 7.590, 1.000
step, loss, accurary = 3000: 5.855, 1.000
step, loss, accurary = 4000: 4.678, 1.000
step, loss, accurary = 5000: 4.693, 1.000
accuracy1 = 0.9751
accuracy2 = 0.9756
accuracy (model averaged) = 0.9810
期待通り,個々の分類器で 0.975 前後にあった精度(正答率)がモデル平均により 0.980 と若干ですが良くなっています.
(今回作成したコードは,Gist に upload しました.)
少し横道にそれた感がありますが,変数スコープと共有変数の使い方のイメージをつかんでいただけたかと思います.小さいモデルでは,あまり変数スコープを使って変数を管理する必要性はないと思いますが,大きなモデルでは,変数スコープと共有変数を使いたくなる状況があるはずです.他のDeep Learning Frameworkにあまり見られない,TensorFlowの特長ですので,ぜひ使ってみて下さい!