こんにちは、menu事業部バックエンドエンジニアの新田です。
2025年6月4日(水)にLINEヤフー株式会社にてApache Kafka Meetup Japan #16が開催されました!
本記事では、当日のセッションの全体的なレポートと、その中でも特に興味深かった内容を紹介したいと思います。
イベント全体のレポートと各セッションへの所感
イベントは現地・オンラインの両方で開催し、ともに盛況でした。
今回のMeetupでは、Kafkaの共同創業者Jun Raoさんが7年ぶりに来日し、直接話を聞ける貴重な機会となりました。
公開されているスライドや資料は以下からご覧いただけます
- Kafka vs. Pulsar: Performance Evaluation by Petabyte-Scale Streaming Platform Providers
- Investigating Orphaned Memory Mappings for Kafka's Index & TimeIndex Files
合計3つのセッションがあり、以下のようなテーマで発表が行われました。
① Queues for Kafka(Jun Rao, Confluent)
Kafka 4.1で導入予定の新機能「KIP-932 : Queue for Kafka」について解説がありました。
Kafkaでの順序保証について
Kafkaでは、パーティション内でのメッセージの順序は保証されますが、パーティション間での順序保証は難しく、並列処理と順序性の両立が課題となっています。コンシューマーグループ内で複数のパーティションを並列処理する場合、全体としての順序を保つことは容易ではありません。
従来のKafkaでは、パーティション間での順序保証が困難でしたが、KIP-932で導入される「共有グループ(share groups)」により、この課題が解決されます。
シェアグループを使用することで、パーティション間でもメッセージの順序を保ちながら、複数のコンシューマーが協調してメッセージを処理できるようになります。
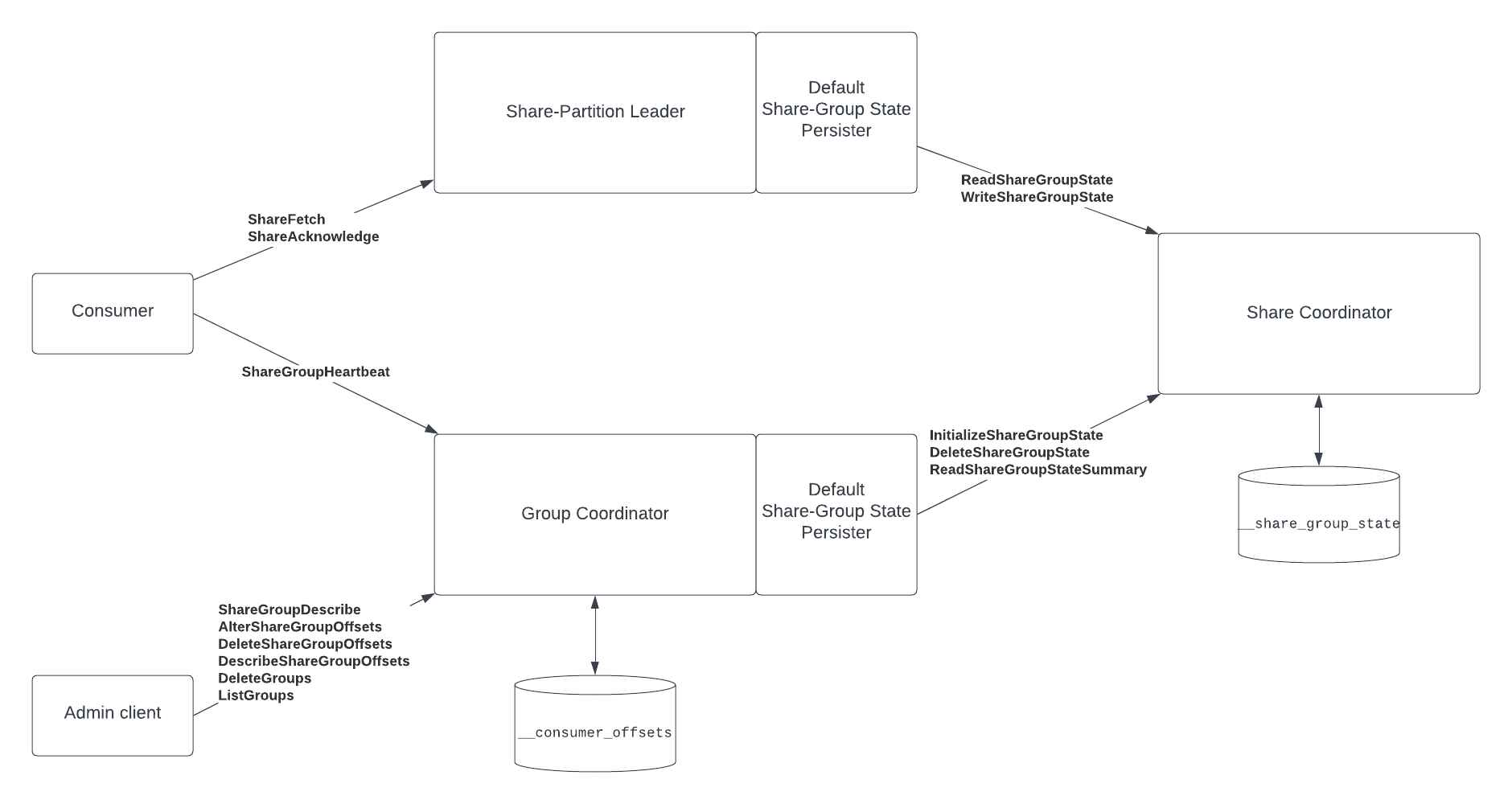
出典: https://cwiki.apache.org/confluence/display/KAFKA/KIP-932%3A+Queues+for+Kafka
また、メッセージごとに個別にackを返すことができるため、従来のコンシューマグループよりも柔軟なリトライ制御や障害処理が可能となります。
これにより、順序性を重視するワークロードでも、Kafkaをより効果的に活用できるようになると感じました。
弊社menuでは、配達員と注文の需給バランスを保つためのシステムでKafkaを活用しており、リアルタイムでの配達状況や注文状況の同期に利用しています。
現在の運用では処理速度を重視していますが、将来的に順序性が重要となるケースでは、今回紹介されたKIP-932のシェアグループ機能が非常に有用になると感じました。
② Kafka vs. Pulsar: Performance Evaluation by Petabyte-Scale Streaming Platform Providers(Takayama Shogo/Mathew Arun, LINEヤフー)
LINEヤフーが実際に大規模本番運用しているKafkaとPulsarのベンチマーク比較について発表がありました。
Apache Pulsarとは?
Apache Pulsarは、Yahoo!が開発した分散メッセージングシステムで、Kafkaと同様にストリーミングプラットフォームとして機能します。Pulsarの特徴として、マルチテナント対応、地理的レプリケーション、統一されたメッセージングモデル(pub-subとキューイングの両方をサポート)などが挙げられます。特に、トピックごとにパーティション数を動的に変更できる機能や、より細かい粒度でのメッセージ配信制御が可能な点がKafkaとの大きな違いです。
両プロダクトのスループットやレイテンシ、ボトルネックの発生ポイントなど、複数のワークロードシナリオでの詳細な比較結果が紹介されました。

出典: https://speakerdeck.com/lycorptech_jp/20250609a?slide=22
特に印象的だったのは、LINEヤフーでは日々Kafkaで2.49PB、Pulsarで1.79PBという膨大なデータを扱っているという点で、その規模の大きさに圧倒されました。
また、ベンチマーク結果から、設定次第でここまでパフォーマンスに大きな差が生まれるのかと改めて驚かされました。
弊社ではBest Practiceに沿った構成を徹底しているため、現状は設定がボトルネックになる心配はほとんどありませんが、運用規模や要件によっては細かな設定の違いが大きな影響を及ぼすことを実感しました。
③ Investigating Orphaned Memory Mappings for Kafka's Index & TimeIndex Files(Mori Masahiro, LINEヤフー)
Kafkaで特定の状況下においてディスク負荷が急激に高まり、最悪の場合クラッシュに至るという問題の調査・解析について発表がありました。
この現象は以前から知られており、過去には KAFKA-4614 にてメモリマッピングを強制的に解除することで解決されていました。
しかし、今回は KAFKA-4614 の修正がすでに適用されているにも関わらず、同様の問題が再発したため、根本的な原因を探るべく徹底的な調査を行ったそうです。
その結果、インデックスファイルのリサイズ時に、古いメモリマッピングがLinux環境で適切に解放されないというバグが存在することを突き止めました。
地道な検証と分析によって根本原因にたどり着いた姿勢は、本当にリスペクトです。
おわりに
今回のMeetupも、Kafkaの最新動向や大規模運用のリアルな知見を学ぶことができ、とても有意義な時間でした。
懇親会では、Kafka4.1のアップデート内容に関してや、日頃の活用方法や課題などの話で盛り上がり、とても充実した時間を過ごすことができました!
以上、Apache Kafka Meetup Japan #16の現地レポートでした。
▼採用情報
レアゾン・ホールディングスは、「世界一の企業へ」というビジョンを掲げ、「新しい"当たり前"を作り続ける」というミッションを推進しています。
現在、エンジニア採用を積極的に行っておりますので、ご興味をお持ちいただけましたら、ぜひ下記リンクからご応募ください。