以前PythonのBeautifulSoupを使ってスクレイピングをしたことがあったのですが、RubyでもNokogiriというライブラリで実現できるということで試してみました。
でまずは完成コード、完成品から
scraping.rb
require 'nokogiri'
require 'open-uri'
require "csv"
require "byebug"
url_base = "https://news.yahoo.co.jp/"
def get_categories(url)
html = open(url)
doc = Nokogiri::HTML.parse(html)
categories = doc.css(".yjnHeader_sub_cat li a")
categories.map do |category|
cat_name = category.text
cat = category[:href]
end
end
@cat_list = get_categories(url_base)
@infos = []
@cat_list.each do |cat|
url = "#{url_base + cat}"
html = open(url)
doc = Nokogiri::HTML.parse(html)
titles = doc.css(".topicsListItem a")
i = 1
titles.each do |title|
@infos << [i,title.text]
i += 1
end
end
CSV.open("result.csv", "w") do |csv|
@infos.each do |info|
csv << info
puts "-------------------------------"
puts info
end
end

それぞれ解説していきます。
ファイルの読み込み
require 'nokogiri'
require 'open-uri'
require "csv"
require "byebug"
今回使うのはNokogiriとopen-uri、そしてCSV保存のためのcsvです。
NokogiriはHTMLやXMLコードを解析し、セレクターによって抜き出してくれるRubyのライブラリです。セレクターはcssの他にxpathでも指定できるので、複雑な構造をしたページでもスクレイピングがスムーズに行えます。
スクレイピング先のページ構造
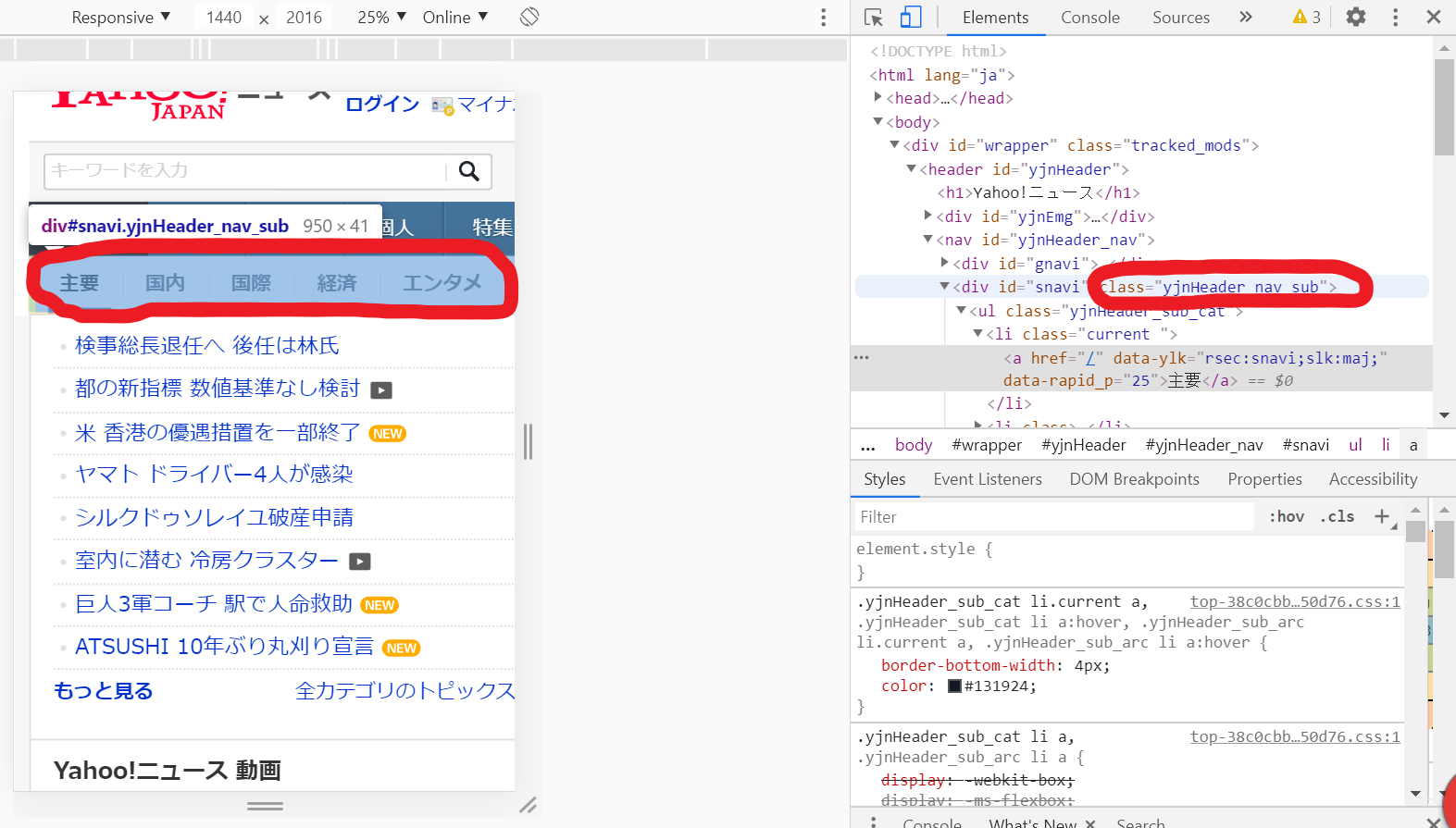
今回は各トピックのタイトルを取得していき、最終的にCSVファイルにまとめます。
トピックのページはyjnHeader_subというクラスのliの中にあるリンク(aタグ)から繋がっているようです。
カテゴリーごとのリンクを取得
url_base = "https://news.yahoo.co.jp/"
def get_categories(url)
html = open(url)
#parseで読み込んだURLのHTMLコードを取得
doc = Nokogiri::HTML.parse(html)
#cssセレクターを使い、先ほどのカテゴリーに繋がっているaタグをすべて取得
categories = doc.css(".yjnHeader_sub_cat li a")
categories.map do |category|
#取得したaタグからhrefの中身(リンク先のURL)をひとつづつ取り出して返します
cat = category[:href]
end
end
# @cat_listとして取得したリンクをまとめておきます
@cat_list = get_categories(url_base)
トピックのタイトルを取得
先ほど取得したリンクを用いてトピックごとのタイトルを取得していきます。
@infos = []
@cat_list.each do |cat|
#トピックページのURLは元のURL + 取得したURLのため
url = "#{url_base + cat}"
html = open(url)
doc = Nokogiri::HTML.parse(html)
titles = doc.css(".topicsListItem a")
i = 1
titles.each do |title|
#CSVにまとめるためにトピックのナンバーとタイトルをセットで格納します
@infos << [i,title.text]
i += 1
end
end
取得したタイトルをCSVにまとめる
最後にまとめたタイトルをCSVに保存します。
# CSVライブラリを使い"result.csv"を新規作成
CSV.open("result.csv", "w") do |csv|
@infos.each do |info|
#csvに追加するとともにログとして使いした項目を出力しています。
csv << info
puts "-------------------------------"
puts info
end
end

文字化け対策
しかしこのままではおそらく文字化けしてしまうためBOMを付けて保存し直します。
(本来であればCSV保存中に行うのが正しいのですが、上手くいかなかったためいったんこちらで対応しました)
"result.csv"をメモ帳でopenして、上書き保存を選択。
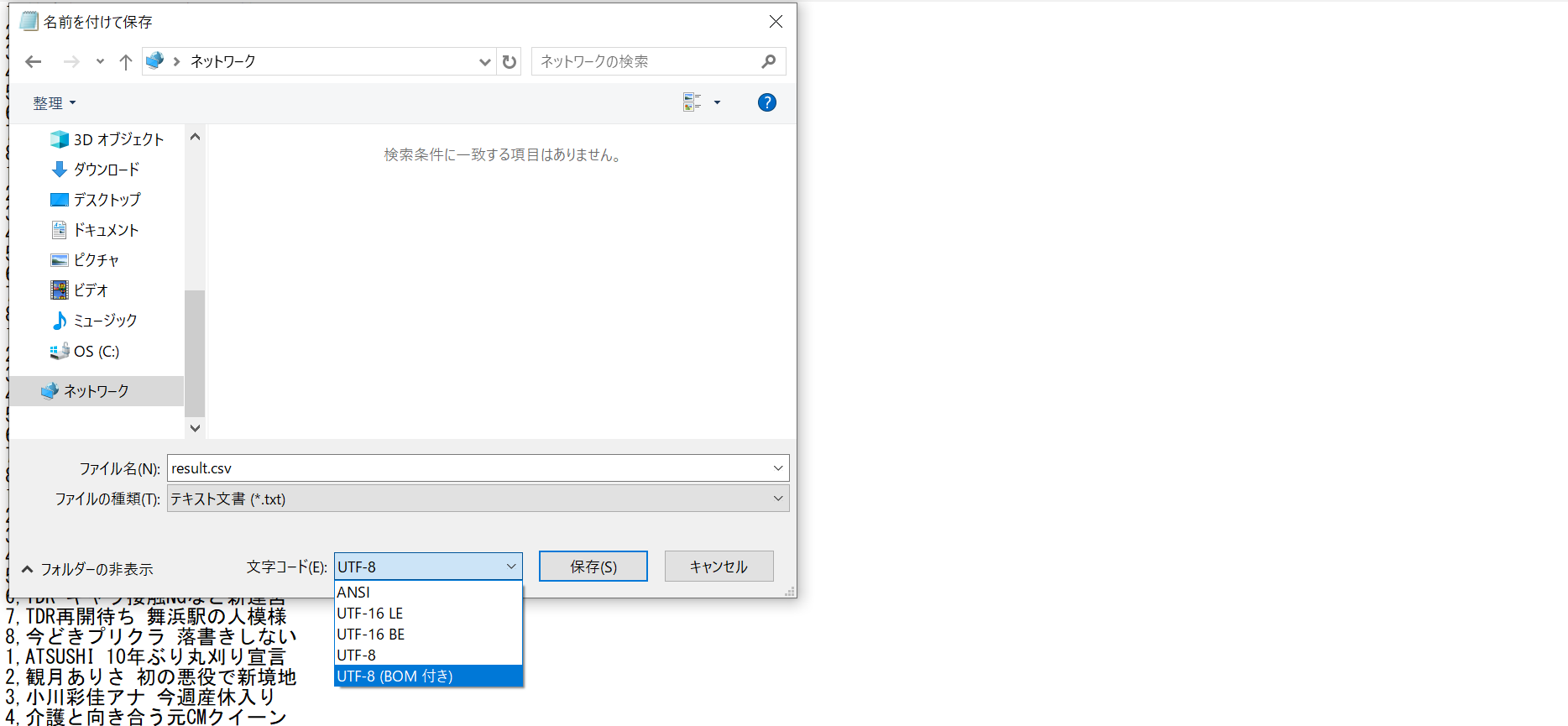
この時**UTF-8(BOM付)**を選択して保存し直してください。

もう一度csvを開くと文字化けが解消されています。
最後に
まだまだ至らない点が多いと思うのでご指摘があればコメントいただけると幸いです。