日常の業務やデータ処理の現場では、PDF ファイル内に含まれる表をそのまま Word にコピーできないケースがよくあります。特に表の構造が複雑であったり、ページをまたいだり、不規則なレイアウトを含んでいる場合、手動でのコピーは時間がかかるだけでなく、位置ズレや改行の乱れ、書式崩れが起きやすくなります。
オンラインツールやデスクトップ変換ソフトを試すユーザーも多いものの、大量文書の処理・構造化された抽出・Word 表への正確な書き込みといった要件を満たすには、自動化による処理が最も効率的かつ信頼性の高い方法です。
本記事では Python を用いて PDF ファイルから表を抽出し、そのデータを構造化された Word 文書の表として書き込む方法 を解説します。この処理はすべて自動化でき、財務報表のアーカイブ、契約書中の表抽出、データガバナンス、外部 PDF 報表の変換など、幅広い業務シナリオで活用できます。
本記事では Free Spire.PDF for Python と Free Spire.Doc for Python を使用します。pip でインストール可能です:
pip install spire.pdf.free, spire.doc.free
1. PDF を読み込み、Word 文書を準備する
PDF を処理する前に、まずは元ファイルの読み込みと Word 文書の初期化を行います。
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.doc import Document, FileFormat, DefaultTableStyle, AutoFitBehaviorType, BreakType
input_pdf = "sample.pdf"
output_docx = "output/pdf_table_to_docx.docx"
# PDF 文書を読み込む
pdf = PdfDocument()
pdf.LoadFromFile(input_pdf)
# Word 文書を作成
doc = Document()
section = doc.AddSection()
説明:
-
PdfDocument()は PDF ファイルの読み込みを行い、表抽出の基盤となります。 -
Document()は Word 文書オブジェクトを生成し、表はこのセクション内に追加されます。 - 出力パスを事前に設定しておくことで、プログラムは編集可能な
.docxを直接生成できます。
この段階は、変換処理全体の「基礎フレーム」を用意する工程です。
2. PDF の表を抽出し、Word の表として作成する
続いて、この記事の核心である PDF 表の抽出 → Word 表の生成 を行います。
# PDF の表データを抽出し、Word 文書に書き込む
table_extractor = PdfTableExtractor(pdf)
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
if tables is not None and len(tables) > 0:
for i in range(len(tables)):
table = tables[i]
# Word 表を作成
word_table = section.AddTable()
word_table.ApplyStyle(DefaultTableStyle.ColorfulGridAccent4)
word_table.ResetCells(table.GetRowCount(), table.GetColumnCount())
for j in range(table.GetRowCount()):
for k in range(table.GetColumnCount()):
cell_text = table.GetText(j, k).replace("\n", " ")
tr = word_table.Rows[j].Cells[k].AddParagraph().AppendText(cell_text)
tr.CharacterFormat.FontName = "メイリオ"
tr.CharacterFormat.FontSize = 11
word_table.AutoFit(AutoFitBehaviorType.AutoFitToWindow)
section.AddParagraph().AppendBreak(BreakType.LineBreak)
重要ポイント解説
(1)PDF をページ単位で読み取り、表を抽出
ExtractTable(i) はページ内の表を解析して返します。
PDF には Word のような「表構造」が存在しないため、線・文字配置・間隔 などを手掛かりに表を推定します。この工程は、正確な表抽出の成否を左右する非常に重要なステップです。
(2)Word 文書に表を動的生成
word_table = section.AddTable()
word_table.ResetCells(row_count, column_count)
抽出した行・列数に基づき、Word 内に同じ構造の表を生成します。
-
ResetCellsは指定行列で空の表を作成します。 - 表スタイルには
ColorfulGridAccent4を使用し、視認性を高めています。
(3)セル内容の整形と書き込み
cell_text = table.GetText(j, k).replace("\n", " ")
PDF ではセル内に不要な改行が含まれることが多いため、Word に書き込む前に整形します。
さらに、読みやすさのため基本的なフォント設定を行います:
tr.CharacterFormat.FontName = "メイリオ"
tr.CharacterFormat.FontSize = 11
これにより、生成された Word 文書は統一された見た目になり、表の可読性も向上します。
(4)表幅の自動調整
word_table.AutoFit(AutoFitBehaviorType.AutoFitToWindow)
テーブルが Word のページ幅に自動調整され、レイアウトの一貫性が保たれます。
3. Word 文書の保存
最後に Word 文書として保存します。
doc.SaveToFile(output_docx, FileFormat.Docx)
これで Word ファイルが生成され、すぐに開いて確認したり、編集作業やレポートへの組み込みが可能になります。
出力結果サンプル
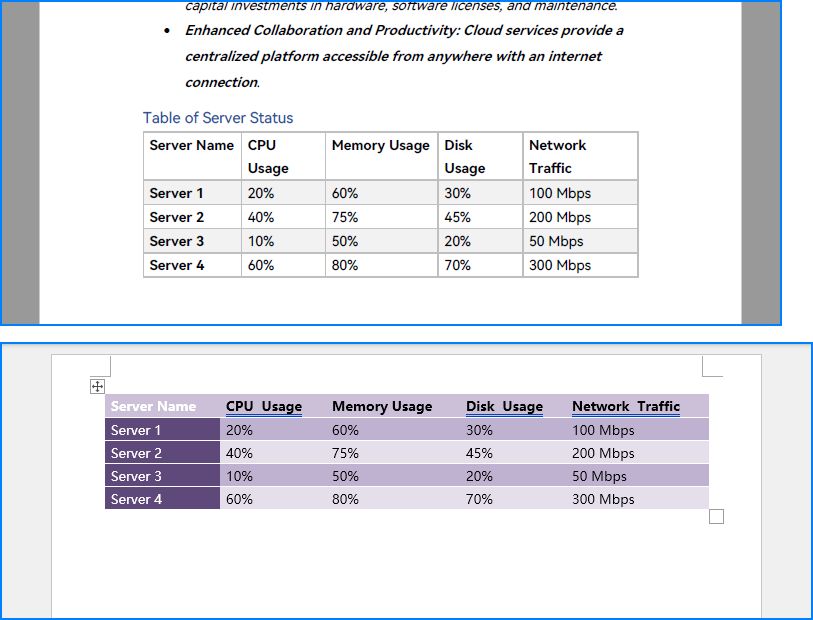
使用した主要クラス・メソッド一覧
一覧として整理したものが以下です:
| クラス / メソッド | 説明 |
|---|---|
PdfDocument |
PDF 文書を表すオブジェクト |
PdfTableExtractor |
PDF から表を解析するためのクラス |
ExtractTable(page_index) |
指定ページの表集合を返す |
Document |
Word 文書オブジェクト |
AddSection() |
セクション追加(表・段落の挿入に使用) |
section.AddTable() |
Word に表を作成 |
ResetCells(row, col) |
Word 表の行列を初期化 |
AppendText() |
セルへ文字を書き込む |
DefaultTableStyle |
Word 表のスタイル設定 |
AutoFitToWindow |
表の幅をページ幅に自動調整 |
まとめ
本記事では、Python を使って PDF の表を自動抽出し、Word の表として書き込む方法 を解説しました。
PDF 表の解析・行列構造の取得・Word 表の作成と書き込みまで、すべての処理を自動化できるため、大量処理や業務システムとの連携に最適 です。
手動コピーによる書式崩れ、オンラインツールの制限、デスクトップソフトの非効率性といった課題に対し、コードによる自動処理は柔軟性・精度・拡張性の面で圧倒的に優れています。
さらに応用として、大量バッチ処理、内容のクリーニング、テンプレート組み込み、OCR と併用した高度抽出 などにも展開可能です。
大量の PDF 表処理や長期的な文書自動化のニーズがある場合、Python ベースのこの方法は業務効率を大きく向上させる強力なソリューションとなるでしょう。