PDF文書からテーブルを抽出し、テキスト、CSV、Excelファイルなどの管理しやすい形式に変換することは、データ分析や情報管理において一般的な要件です。このプロセスは、表形式のデータを効率的に扱うことを可能にし、データの操作、分析、他のデータセットとの統合を容易にします。財務報告書、研究論文、または構造化された情報を含むあらゆる文書に取り組む場合でも、これらのテーブルを正確に変換する技術を習得することは、データの完全な潜在能力を引き出すために不可欠です。
この記事では、PDF文書からテーブルデータを効果的に抽出し、テキスト、CSV、Excelファイルに書き込む方法を、シンプルなPythonコードを用いて解説し、PDFテーブルの自動抽出を容易にします。
- Pythonを使用してPDFテーブルデータを取得する方法の紹介
- Pythonを使用してPDFテーブルデータをテキストに抽出
- Pythonを使用してPDFテーブルデータをCSVファイルに抽出
- Pythonを使用してPDFテーブルデータをExcelワークシートに抽出
- Pythonを使用してPDFをExcelファイルに直接変換
この記事では、PDFテーブルデータを抽出するためにSpire.PDF for Pythonが必要です。PyPIからインストール: pip install spire.pdf。
処理するPDF文書:
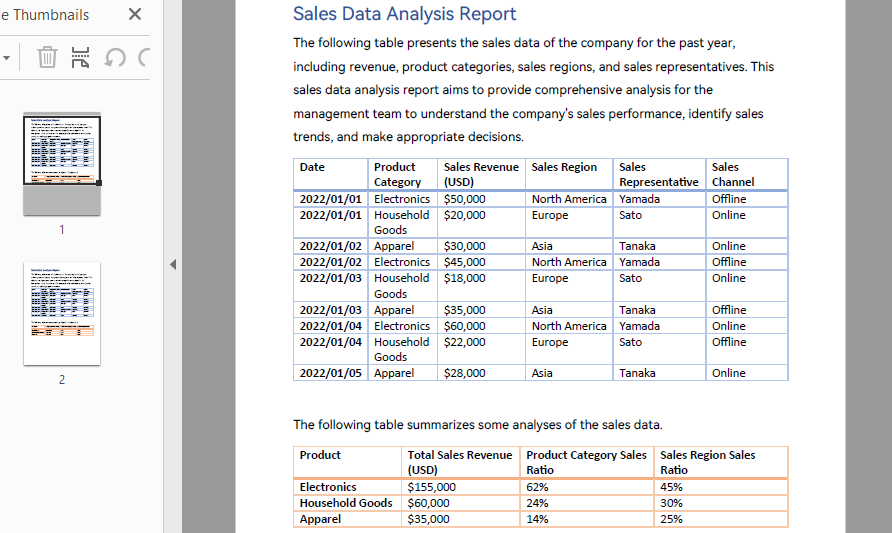
Pythonを使用してPDFテーブルデータを取得する方法の紹介
ライブラリ内のPdfTableExtractorクラスは、PDF文書のテーブル抽出に使用されます。PdfTableExtractor.ExtractTable(pageIndex: int)メソッドを使用して、PDFページからテーブルを抽出し、Utilities_PdfTableオブジェクトのコレクションとしてテーブルを返します。次に、これらのテーブルを反復処理し、Utilities_PdfTable.GetCellText(rowIndex: int, columnIndex: int)メソッドを使用して各テーブルセルのデータを取得します。
PDFフォームからデータを抽出する一般的な手順は以下の通りです:
-
PdfDocumentインスタンスを作成し、PdfDocument.LoadFromFile()メソッドを使用してPDF文書をロードします。 - ドキュメントを使用して
PdfTableExtractorインスタンスを作成します。 -
PdfTableExtractor.ExtractTable(pageIndex: int)メソッドを使用して、文書の各ページからテーブルを抽出します。 - 抽出した各テーブルを反復処理し、
Utilities_PdfTable.GetCellText(rowIndex: int, columnIndex: int)メソッドを使用してセルの値を取得します。 - 取得したテーブルデータを他のファイルに書き込みます。
注意:抽出したテーブルデータを使用して文字列を構築する際、セルテキスト内に改行がある場合は、余分な改行が追加されます。結果のテキストファイルに混乱を招かないよう、これらの改行を削除またはスペースに置き換えるようにしてください。
Pythonを使用してPDFテーブルデータをテキストに抽出
一般的な手順に従ってPDF文書からテーブルデータを取得した後、各テーブルのデータを文字列に書き込んでテキストファイルに保存することで、PDFテーブルデータをテキストファイルに抽出することができます。抽出された表データの改行が削除または置換されていることに注意。
以下は詳細な手順です:
- 必要なモジュールをインポートします:
PdfDocumentとPdfTableExtractor。 -
PdfDocumentインスタンスを作成し、PdfDocument.LoadFromFile()メソッドを使用してPDF文書をロードします。 - ドキュメントを使用して
PdfTableExtractorインスタンスを作成します。 -
PdfTableExtractor.ExtractTable(pageIndex: int)メソッドを使用して、文書の各ページからテーブルを抽出します。 - 抽出したテーブルを反復処理します:
- テーブルデータを保存するための
strオブジェクトを作成します。 -
Utilities_PdfTable.GetCellText(rowIndex: int, columnIndex: int)メソッドを使用してテーブルからセルの値を取得します。 - セルの値を
strオブジェクトに追加します。 -
strオブジェクトをファイルに書き込みます。
- テーブルデータを保存するための
- リソースを解放します。
コード例
from spire.pdf import PdfDocument, PdfTableExtractor
# PdfDocumentオブジェクトを作成
pdf = PdfDocument()
# PDFドキュメントを読み込む
pdf.LoadFromFile("Sample.pdf")
# PdfTableExtractorオブジェクトを作成
extractor = PdfTableExtractor(pdf)
# すべてのページを反復処理
for pageIndex in range(pdf.Pages.Count):
# 各PDFページからテーブルを抽出
tables = extractor.ExtractTable(pageIndex)
# テーブルが複数ある場合は反復処理
if tables is not None:
for tableIndex in range(len(tables)):
# テーブルを取得
table = tables[tableIndex]
# テーブルデータを格納するstrオブジェクトを作成
tableData = ""
# テーブルの行と列を反復処理
for rowIndex in range(table.GetRowCount()):
for colIndex in range(table.GetColumnCount()):
# セルのテキストを取得
text = table.GetText(rowIndex, colIndex)
text = text.replace("\n", " ")
# セルのテキストをテーブルデータに追加
tableData += text
if colIndex < table.GetColumnCount() - 1:
tableData += "\t"
tableData += "\n"
# テーブルデータをテキストファイルに書き込む
with open(f"output/Tables/Page{pageIndex+1}-Table{tableIndex+1}.txt", "w", encoding="utf-8") as f:
f.write(tableData)
# リソースを解放
pdf.Dispose()
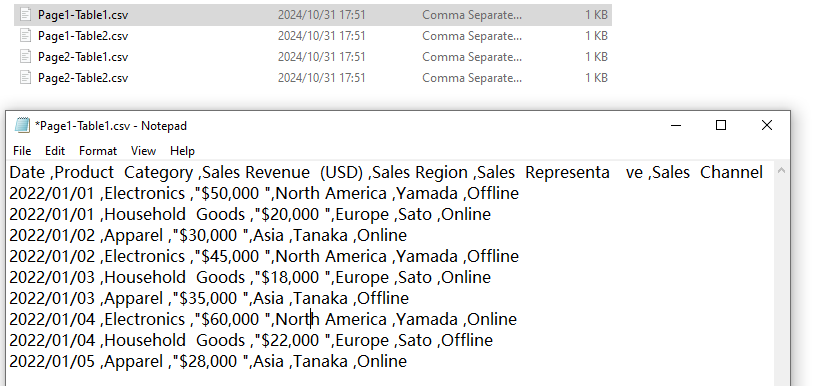
結果

Pythonを使用してPDFテーブルデータをCSVファイルに抽出
同様に、PDF文書からテーブルデータを抽出し、Python標準ライブラリのCSVモジュールを使用して各テーブルをCSVファイルに書き込むことができます。このプロセスでは、結果のCSVファイルを改善するために改行を削除または置き換えることにも注意が必要です。詳細な手順は以下の通りです:
- 必要なモジュールをインポートします:
PdfDocument、PdfTableExtractor、およびCSV。 -
PdfDocumentインスタンスを作成し、PdfDocument.LoadFromFile()メソッドを使用してPDF文書をロードします。 - ドキュメントを使用して
PdfTableExtractorインスタンスを作成します。 -
PdfTableExtractor.ExtractTable(pageIndex: int)メソッドを使用して、文書の各ページからテーブルを抽出します。 - 抽出したテーブルを反復処理します:
- CSVファイルを作成します。
- テーブル内の行を反復処理し、行データを格納するリストを作成します。
-
Utilities_PdfTable.GetCellText(rowIndex: int, columnIndex: int)メソッドを使用して各行のセル値を取得し、リストに追加します。 -
csv.writer().writerow()メソッドを使用して各行をCSVファイルに書き込みます。
- リソースを解放します。
コード例-
from spire.pdf import PdfDocument, PdfTableExtractor
import csv
# PdfDocumentオブジェクトを作成
pdf = PdfDocument()
# PDFドキュメントを読み込む
pdf.LoadFromFile("Sample.pdf")
# PdfTableExtractorオブジェクトを作成
extractor = PdfTableExtractor(pdf)
# すべてのページを反復処理
for pageIndex in range(pdf.Pages.Count):
# 各PDFページからテーブルを抽出
tables = extractor.ExtractTable(pageIndex)
# テーブルが複数ある場合は反復処理
if tables is not None:
for tableIndex in range(len(tables)):
# テーブルを取得
table = tables[tableIndex]
# CSVファイルを作成
with open("output/Tables/Page" + str(pageIndex+1) + "-Table" + str(tableIndex+1) + ".csv", "w", newline='', encoding='utf-8') as csvFile:
writer = csv.writer(csvFile)
# テーブルの行と列を反復処理
for rowIndex in range(table.GetRowCount()):
row = []
for colIndex in range(table.GetColumnCount()):
# セルのテキストを取得
text = table.GetText(rowIndex, colIndex)
text = text.replace('\n', ' ')
row.append(text)
writer.writerow(row)
# リソースを解放
pdf.Dispose()
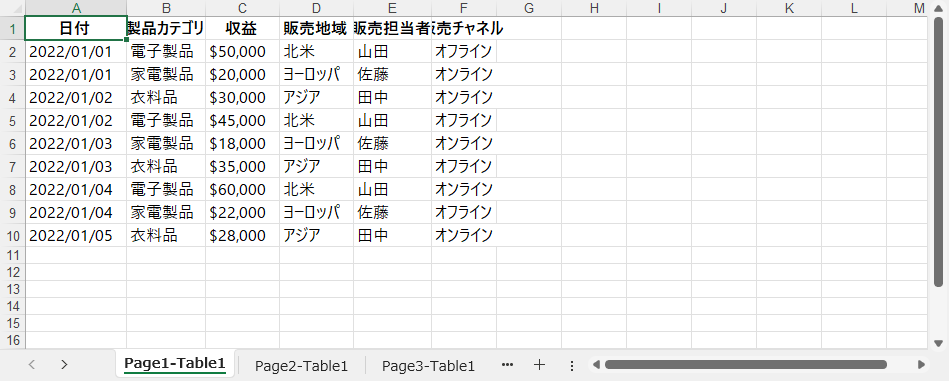
結果
Pythonを使用してPDFテーブルデータをExcelワークシートに抽出
取得したPDFテーブルデータをExcelワークシートに書き込むために、別のライブラリであるSpire.XLS for Pythonを使用できます。PyPIからSpire.XLS for Pythonをインストール:pip install spire.xls。
詳細な手順は以下の通りです:
- 必要なモジュールをインポートします:
PdfDocument、PdfTableExtractor、Workbook、およびspire.xls.FileFormat。 -
PdfDocumentインスタンスを作成し、PdfDocument.LoadFromFile()メソッドを使用してPDF文書をロードします。 - テーブルを保存するための
Workbookインスタンスを作成し、デフォルトのワークシートを削除します:Workbook.Worksheets.Clear()メソッド。 - ドキュメントを使用して
PdfTableExtractorインスタンスを作成します。 -
PdfTableExtractor.ExtractTable(pageIndex: int)メソッドを使用して、文書の各ページからテーブルを抽出します。 - 抽出したテーブルを反復処理します:
- 各テーブルのためにワークシートを追加します:
Workbook.Worksheets.Add(sheetName: str)メソッド。 -
Utilities_PdfTable.GetCellText(rowIndex: int, columnIndex: int)メソッドを使用してテーブルからセルの値を取得します。 -
Worksheet.Range[rowIndex + 1, colIndex + 1].Textプロパティを通じて、ワークシートの対応するセルにセルの値を書き込みます。
- 各テーブルのためにワークシートを追加します:
-
Workbook.SaveToFile()メソッドを使用してワークブックを保存します。 - リソースを解放します。
コード例
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.xls import Workbook, FileFormat, HorizontalAlignType
# PdfDocumentオブジェクトを作成
pdf = PdfDocument()
# PDFドキュメントを読み込む
pdf.LoadFromFile("Sample.pdf")
# Workbookオブジェクトを作成
workbook = Workbook()
# デフォルトのワークシートをクリア
workbook.Worksheets.Clear()
# PdfTableExtractorオブジェクトを作成
extractor = PdfTableExtractor(pdf)
# 各PDFページからテーブルを抽出
for pageIndex in range(pdf.Pages.Count):
tables = extractor.ExtractTable(pageIndex)
# テーブルが複数ある場合は反復処理
if tables is not None:
for tableIndex in range(len(tables)):
# テーブルを取得
table = tables[tableIndex]
# ワークシートをテーブル用に作成
sheet = workbook.Worksheets.Add(f"Page{pageIndex + 1}-Table{tableIndex + 1}")
# テーブルの行と列を反復処理
for rowIndex in range(table.GetRowCount()):
for colIndex in range(table.GetColumnCount()):
# セルの値を取得
text = table.GetText(rowIndex, colIndex)
cellText = text.replace("\n", "")
# セルの値をワークシートの対応するセルに書き込む
sheet.Range[rowIndex + 1, colIndex + 1].Text = cellText
# オプション: テーブルの外観をカスタマイズ
# ヘッダー行のスタイルを設定
sheet.Rows.get_Item(0).Style.Font.FontName = "Yu Gothic UI"
sheet.Rows.get_Item(0).Style.Font.Size = 12
sheet.Rows.get_Item(0).Style.Font.IsBold = True
sheet.Rows.get_Item(0).Style.HorizontalAlignment = HorizontalAlignType.Center
# データ行のスタイルを設定
for i in range(1, sheet.Rows.Count):
sheet.Rows.get_Item(i).Style.Font.FontName = "Yu Gothic UI"
sheet.Rows.get_Item(i).Style.Font.Size = 12
sheet.Rows.get_Item(i).Style.HorizontalAlignment = HorizontalAlignType.Left
# 列を自動調整
for j in range(1, sheet.Columns.Count):
sheet.AutoFitColumn(j)
# ワークブックを保存
workbook.SaveToFile("output/PDFTableToExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
pdf.Close()
結果
Pythonを使用してPDFをExcelファイルに直接変換
PDF文書を直接Excelファイルに変換することも可能です。PdfDocument.SaveToFile(fileName: str, FileFormat.XLSX)メソッドを使用して文書をロードした後に行います。これは、主にテーブルを含むPDF文書に非常に効果的で、テーブルの元の外観をできるだけ保持します。
変換されたExcelワークシート内の余分な空白を最小限に抑えるために、変換前にPDF文書から余白を削除することができます。以下の記事をご参照ください:
PDF文書をExcelファイルに直接変換するための詳細な手順は以下の通りです:
- 必要なモジュールをインポートします:
PdfDocumentとFileFormat。 -
PdfDocumentインスタンスを作成します。 -
PdfDocument.LoadFromFile()メソッドを使用してPDF文書をロードします。 -
PdfDocument.SaveToFile(fileName: str, FileFormat.XLSX)メソッドを使用して文書をExcelファイルに変換して保存します。 - リソースを解放します。
コード例
from spire.pdf import PdfDocument, FileFormat
# PdfDocumentインスタンスを作成
pdf = PdfDocument()
# PDFドキュメントを読み込む
pdf.LoadFromFile("G:/Documents/Sample81.pdf")
# PDFドキュメントをExcelファイルに変換
pdf.SaveToFile("output/PDFToExcel.xlsx", FileFormat.XLSX)
pdf.Close()
結果
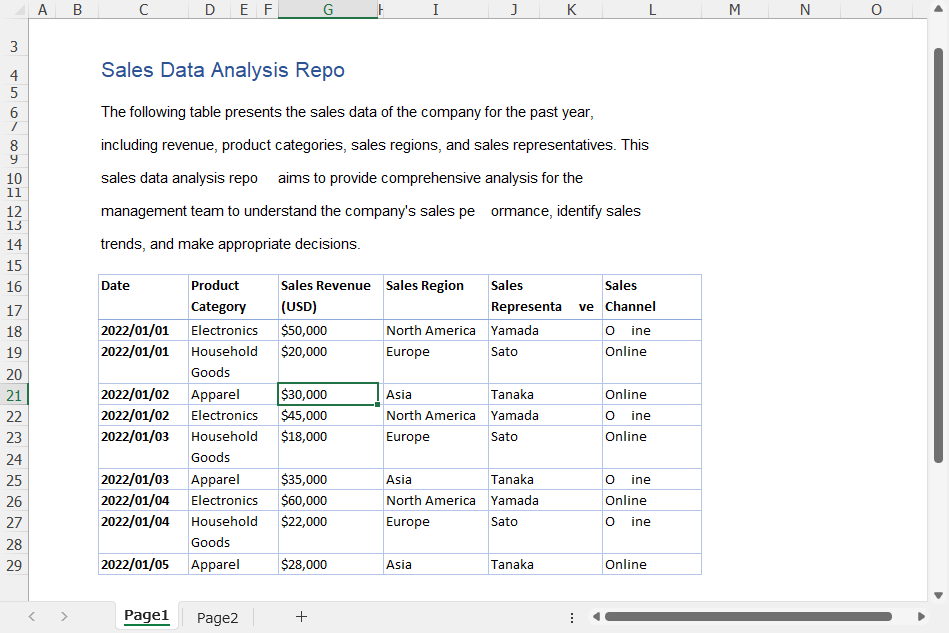
この記事では、PDFテーブルをテキスト、CSV、Excelファイルに抽出する方法と、PDF文書をExcelワークブックに変換する方法を示しました。