企業の業務やデータ分析の現場では、PDFファイルにレポートやリスト、統計データが保存されているケースがよくあります。しかし、PDFはデータ処理にはあまり適していません。CSVファイルであれば、Excelやデータベースでの利用が容易で、幅広いシステムに対応できます。
そのため、PDF内の表データを自動的に抽出し、CSVとして出力できる仕組みが求められます。
この記事では、Free Spire.PDF for Java を利用して、JavaプログラムでPDFの表をCSVファイルに変換する手順を詳しく解説します。
環境準備
プロジェクトに Free Spire.PDF for Java を導入する方法は2つあります。公式サイトから jar をダウンロードするか、Mavenを利用します。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>9.13.0</version>
</dependency>
PDF表をCSVに変換する流れ
JavaとFree Spire.PDFを組み合わせることで、PDFの読み込み → 表データ抽出 → CSV出力 までの流れを自動化できます。以下では手順をステップごとに解説します。
Step 1: PDFドキュメントを読み込む
まず、PdfDocument オブジェクトを作成し、処理対象のPDFを読み込みます。
import com.spire.pdf.*;
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
Step 2: PDFの表データを抽出する
PdfTableExtractor クラスを使うと、PDF内の表を認識して抽出できます。抽出した表を行・列ごとに読み取り、StringBuilderでCSV形式に変換します。
import com.spire.pdf.utilities.*;
import java.io.*;
StringBuilder sb = new StringBuilder();
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 1ページ目から表を抽出
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
// 最初の表を取得
PdfTable table = tables[0];
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
CSVではカンマや引用符などの特殊文字に注意が必要です。そのため、以下のようなメソッドを用意します。
private static String escapeCsvField(String text) {
if (text == null) return "";
text = text.replaceAll("[\\n\\r]", "");
if (text.contains(",") || text.contains(";") || text.contains("\"")) {
text = text.replace("\"", "\"\"");
text = "\"" + text + "\"";
}
return text;
}
Step 3: CSVファイルとして保存する
組み立てたCSV文字列をファイルに書き込みます。
try (Writer writer = new OutputStreamWriter(
new FileOutputStream("output/PDFTable.csv"), "UTF-8")) {
writer.write(sb.toString());
}
pdf.close();
System.out.println("PDFの表をCSVに出力しました。");
完全なJavaコード例
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import java.io.*;
public class PdfToCsvExample {
public static void main(String[] args) throws Exception {
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
StringBuilder sb = new StringBuilder();
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
PdfTable table = tables[0];
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
try (Writer writer = new OutputStreamWriter(
new FileOutputStream("output/PDFTable.csv"), "UTF-8")) {
writer.write(sb.toString());
}
pdf.close();
System.out.println("PDFの表をCSVに出力しました。");
}
private static String escapeCsvField(String text) {
if (text == null) return "";
text = text.replaceAll("[\\n\\r]", "");
if (text.contains(",") || text.contains(";") || text.contains("\"")) {
text = text.replace("\"", "\"\"");
text = "\"" + text + "\"";
}
return text;
}
}
出力結果イメージ:
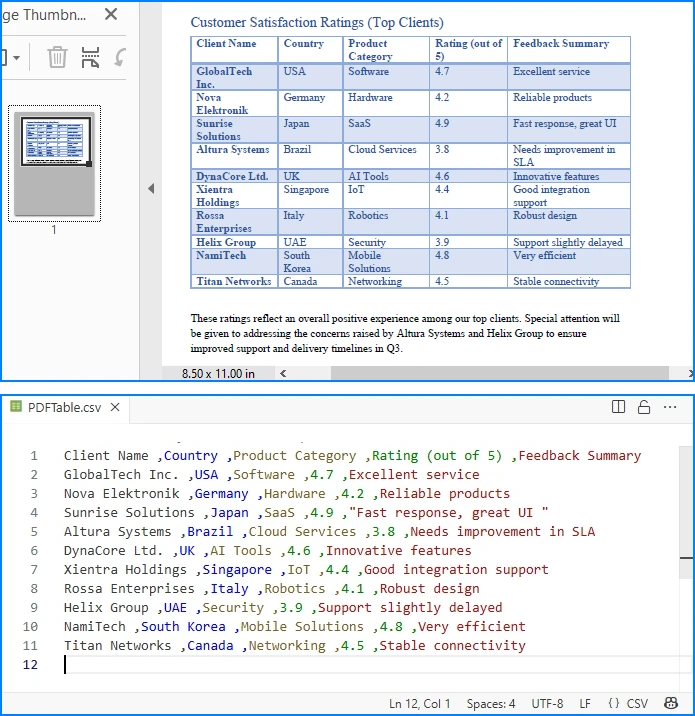
応用例
上記のコードでは1つの表を1つのCSVにまとめましたが、実務では次のような応用も可能です。
1. 各表を個別のCSVに保存
PDF内に複数の表がある場合、それぞれを別のCSVに出力できます。
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (int t = 0; t < tables.length; t++) {
StringBuilder tableContent = new StringBuilder();
PdfTable table = tables[t];
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
tableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) tableContent.append(",");
}
tableContent.append("\n");
}
try (Writer writer = new OutputStreamWriter(
new FileOutputStream("output/Page" + i + "_Table" + t + ".csv"), "UTF-8")) {
writer.write(tableContent.toString());
}
}
}
}
2. すべての表を1つのCSVにまとめる
複数ページにわたる表を統合し、1つのCSVにまとめたい場合は次のようにします。
StringBuilder mergedTableContent = new StringBuilder();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (PdfTable table : tables) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
mergedTableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) mergedTableContent.append(",");
}
mergedTableContent.append("\n");
}
}
}
}
try (Writer writer = new OutputStreamWriter(
new FileOutputStream("output/MergedTable.csv"), "UTF-8")) {
writer.write(mergedTableContent.toString());
}
まとめ
本記事では、Javaで Free Spire.PDF for Java を使い、PDFから表データを抽出してCSVに変換する方法を解説しました。流れは以下の通りです。
- PDFの読み込み
- 表データの抽出
- CSVへの書き込み
さらに、複数表を個別に保存する方法や、1つのCSVに統合する方法も紹介しました。
この方法を使えば、PDFに含まれるレポートや財務一覧、アンケート集計などを効率的にCSV化でき、データ活用の幅が大きく広がります。
詳細な情報やサンプルについては、Spire.PDF for Java チュートリアルセンター を参照してください。