はじめに
ChatGPTに代表されるLLM(大規模言語モデル)は、公開情報をもとに学習されていることから社内文書については回答できません。社内文書や機密情報など独自の情報についてLLMに回答させる場合は、基本的には以下の2つが挙げられます。
- 社内文書を学習データに加えたLLMの「ファインチューニング」
- 社内文書を検索しプロンプトに含める「検索拡張生成(RAG)」
ファインチューニングの功罪についてはこちらの記事がたいへん勉強になります。
"Fine tuning is for form, not facts"とあるように、ファインチューニングは事実をもとに回答させるというよりも形式に対応させる用途が望ましく、事実を学習させてもハルシネーション(幻覚)が増加することがあるようです。
一方、検索拡張生成(RAG)とは以下のようなものです。
外部の知識ベースから事実を検索して、最新の正確な情報に基づいて大規模言語モデル(LLM)に回答を生成させることで、ユーザーの洞察をLLMの生成プロセスに組み込むというAIフレームワークです。
(中略)
LLMベースの質問応答システムにRAGを実装すると、主に2つの利点があります。すなわち、モデルが最新の信頼できる事実にアクセスできることと、ユーザーがモデルの情報ソースにアクセスできるようにすることで、モデルの主張が正確かどうかをチェック可能にし、最終的に信頼できることを保証することです。
https://www.ibm.com/blogs/solutions/jp-ja/retrieval-augmented-generation-rag/
社内文書を検索対象とすることでRAGに組み込むことができるため最新の情報にも即座に対応できる上、LLMの回答結果に出典文書を含められるためユーザは回答内容が正しいかどうか社内文書を見て確認できます。
社内文書の事実に基づいて回答が欲しい場合は、検索拡張生成(RAG)が現状ベストプラクティスだと言えるでしょう。
ここで、RAGを利用する場合、プロンプトに社内文書の抜粋を含めるため「社内文書の内容がプロンプトとしてサーバーに渡されAIの学習に利用されるのでは」というご懸念を持たれるかもしれません。
IBMのwatsonxは、LLMのプロンプト、モデルの出力、ファインチューニングモデルの訓練データなどの作業がプライベートに行われ、IBMや他のユーザがアクセスすることはありません。そのため、社内文書をwatsonxとやり取りすることで機密情報が学習されることはないとされています。
本記事では、IBMの生成AI製品であるwatsonx.aiとRAG構築に利用できるOSSのLangChainを使用して、社内文書に回答できるRAGの構築手順をご紹介します。
導入環境
次の環境で確認しました。
- Local PC (Windows11)
- Python v3.10.0
記事執筆時点では、Python v3.12ではPyTorchに対応していないためv3.12を避けてお試しください。
IBM CloudアカウントからAPIキーとプロジェクトIDの取得
IBM watsonxの画面左上のハンバーガーメニューをクリックし、「管理」>「アクセス(IAM)」を選択します。
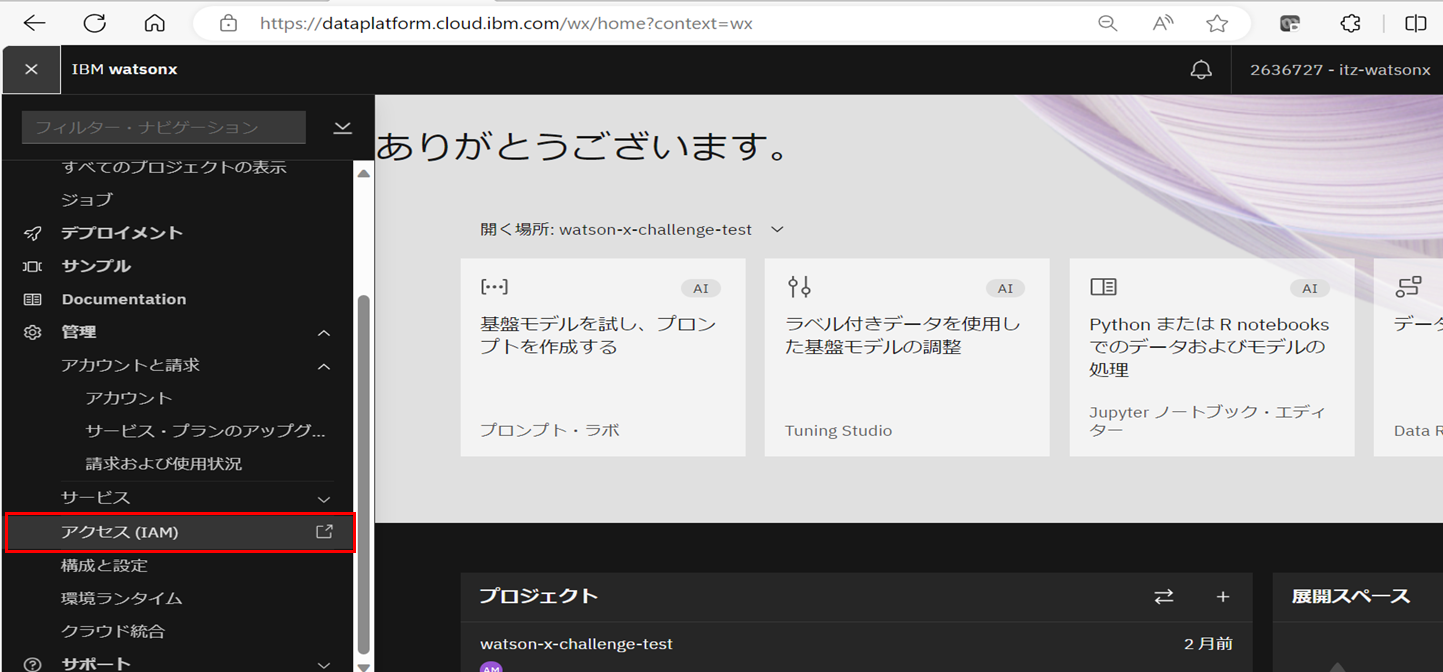
IBM CloudのIAM管理ページに遷移後、「APIキー」をクリックします。
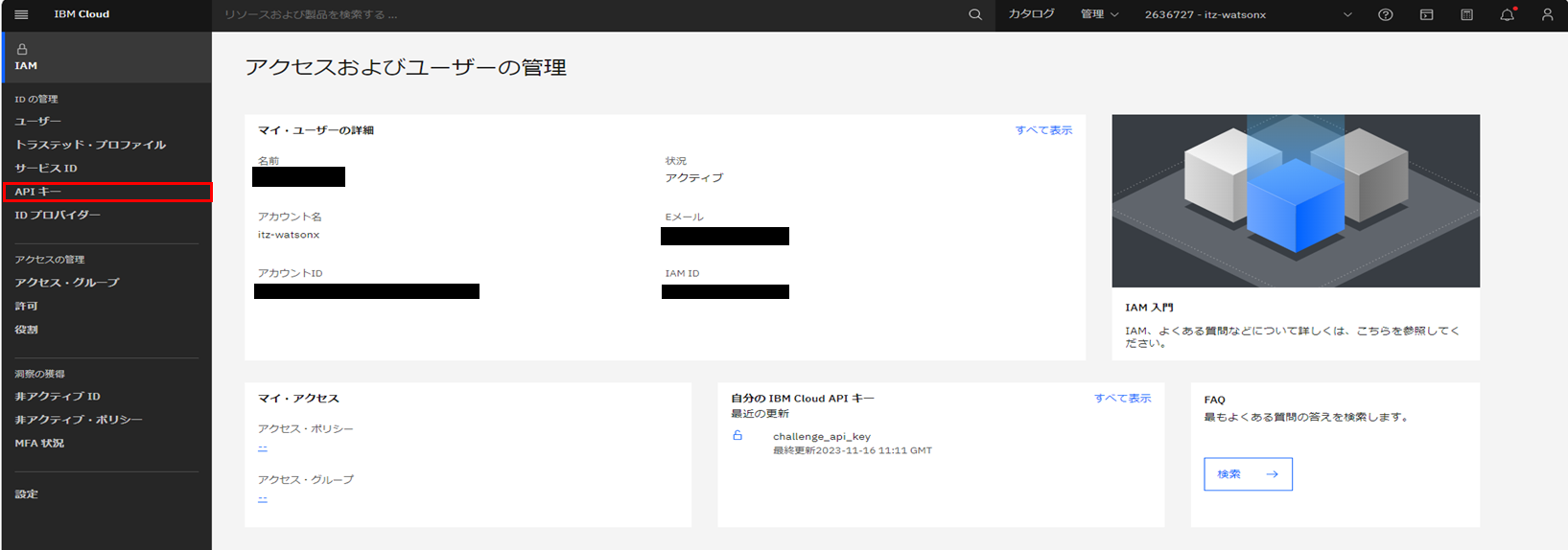
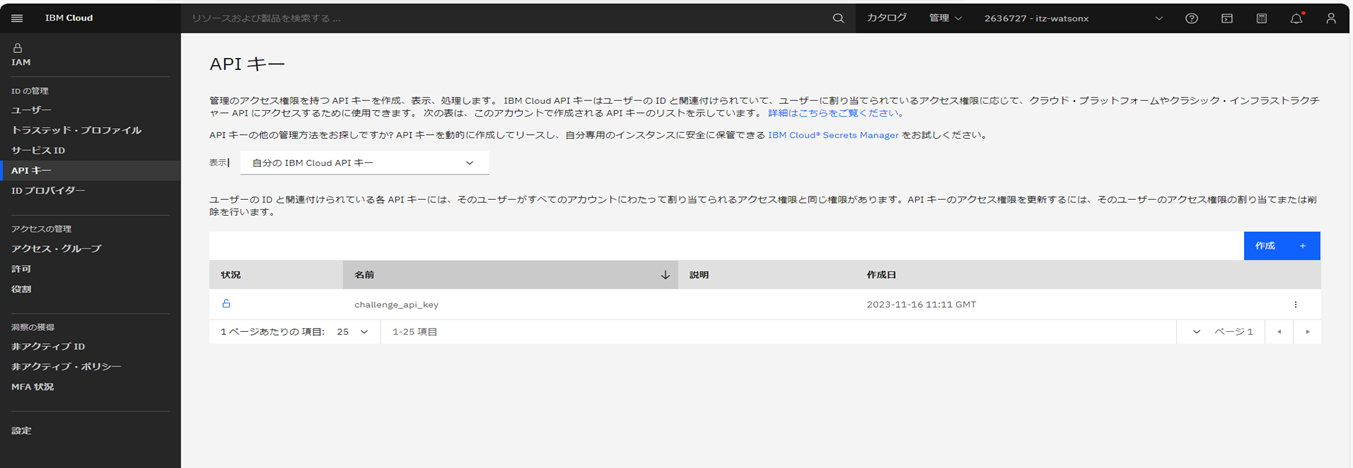
APIキー画面で、「作成」をクリック。
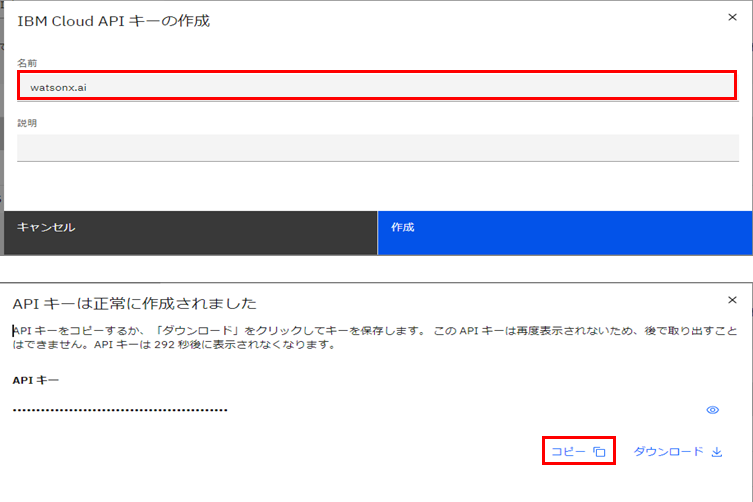
IBM Cloud APIキーの作成画面で、名前に任意の文字列を入力して「作成」をクリックします。
コピーしてメモ帳などに保存するか、ダウンロードしておきます。
watsonx.aiのAPIを使用する際、watsonxのプロジェクトIDが必要になります。
以下の手順でプロジェクトIDを取得します。
1.IBM watsonxの画面でプロジェクトページの「管理」タブを開きます。
2.左メニューから「一般」をクリックします。
3.プロジェクトIDをコピーしてメモ帳などに保存しておきます。
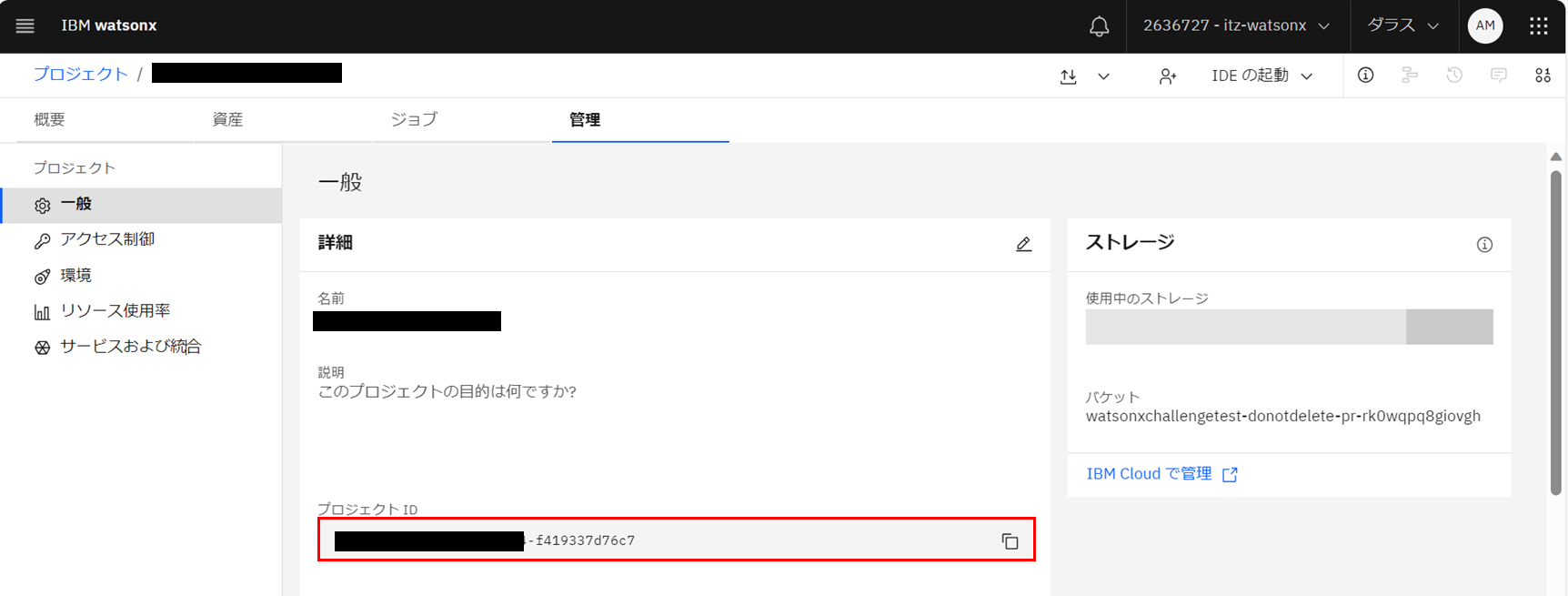
取得したAPIキーとプロジェクトIDはこちらにコピーして貼り付けます。
credentials = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": "[IBM Cloud APIキーをここに貼り付け]"
}
project_id = "[プロジェクトIDをここに貼り付け]"
Pythonライブラリのインストール
watsonx.aiとlangchain、文書検索のためにこちらのライブラリをインストールしておく必要があります。
langchain==0.0.343
sentence-transformers==2.2.2
chromadb==0.4.18
ibm-watson-machine-learning==1.0.330
pydantic==1.10.11
typing-inspect==0.8.0
typing_extensions==4.5.0
requirements.txtとしてテキストファイルに保存してpip installなどでインストールします。
pip install -r requirements.txt
なお、文書検索のためにsentence-transformersをインストールする際にRustを要求されることがあります。こちらのリンクよりrustのインストーラを取得できます。
上記リンクから「rustup-init.exe」をダウンロード、ダブルクリック等で実行します。
実行するとコマンドプロンプトが開き下の選択肢
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
1を入力してEnterでインストールが開始されます。
しばらく待ち、Rust is installed now! … Please Enterと出ればEnterを押下。
インストール完了後、pythonコマンドを打つターミナルで下のコマンドを実行しrustがインストールされていることを確認しておきましょう。
> rustc --version
rustc 1.75.0 (82e1608df 2023-12-21)などとバージョン情報が帰ってくればRustのインストールが完了です!
再度sentenc-transformersのインストールを実行しましょう。
文書の読み込み
今回は、社内文書としてテキストファイルがある場合を想定して、文書インデックスを作成していきます。
'https://www.tptc.co.jp/cms/park/pages/park/01_02/point/statu_of_liberty.pdf'
上記リンク先にあるお台場の自由の女神像についての文書をテキストファイルにしたものを使用します。上記からダウンロードしたPDFを"statue_of_liberty.txt"としてpython実行ファイルと同じフォルダに配置してください。
# 文書読み込み
from langchain.document_loaders import TextLoader
filename = 'statue_of_liberty.txt'
loader = TextLoader(filename)
print("loader: {}".format(loader))
documents = loader.load()
なお、Windows PCでTextLoader()を実行する際、以下のようなエラーが発生する可能性があります。
text = f.read()
^^^^^^^^
UnicodeDecodeError: 'cp932' codec can't decode byte 0x9d in position 1205: illegal multibyte sequence
これは、WindowsのエンコーディングがデフォルトでShift-JISのためのエラーです。上のエラーが出た場合は、Powershell等でUTF-8を使用するよう変更します。
New-ItemProperty -LiteralPath 'HKLM:\SYSTEM\CurrentControlSet\Control\Nls\CodePage' -Name 'ACP' -Value '65001' -PropertyType String -Force;
New-ItemProperty -LiteralPath 'HKLM:\SYSTEM\CurrentControlSet\Control\Nls\CodePage' -Name 'OEMCP' -Value '65001' -PropertyType String -Force;
New-ItemProperty -LiteralPath 'HKLM:\SYSTEM\CurrentControlSet\Control\Nls\CodePage' -Name 'MACCP' -Value '65001' -PropertyType String -Force;
上で書いたロケールのエンコーディング設定はこちらの記事を参考にしました。
文書の分割
LangChainには文書分割のライブラリがあるのでそちらを使用します。
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
文書のベクトル化(Embedding)
文書間の類似度を計算するために、文書をベクトル化してデータベースに保存しておきます。ベクトルを保存するデータベースとしては、OSSのベクトルデータベースであるChromaDBを使用します。
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
HuggingFaceEmbeddingsはモデルを指定しない場合デフォルトでall-mpnet-base-v2というモデルを使用します。このモデルは、sentence-transformers(SBERT)を使用して文書・パラグラフを768次元に埋め込みし、コサイン類似度を計算して文書の関連性を決定しています。
詳細はこちらのページを参照ください。
https://huggingface.co/sentence-transformers/all-mpnet-base-v2
LLMのモデルの定義
使用するLLMモデルとモデルのパラメータを記入し、モデルを定義します。
# watsonx.aiの準備
# モデルの選択とパラメータの設定
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.utils.enums import DecodingMethods
model_id = ModelTypes.LLAMA_2_70B_CHAT
parameters = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.MIN_NEW_TOKENS: 1,
GenParams.MAX_NEW_TOKENS: 100
}
# モデルのインスタンスを作成する
from ibm_watson_machine_learning.foundation_models import Model
model = Model(
model_id=model_id,
params=parameters,
project_id=project_id,
credentials=credentials
)
関連文書と質問をLLMに投げる
watsonx.aiは、LangChainと組み合わせて利用できます。その際に.to_langchain()でwatsonxのllmをLangChain用のLLMに変換して使用します。
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=model.to_langchain(),
chain_type="stuff",
retriever=docsearch.as_retriever(),
return_source_documents=True
)
query = "お台場の自由の女神像はいつまで設置されていた?"
answer = qa({"query": query})
print(answer["result"])
print(answer["source_documents"][0].metadata["source"]) # 検索に使用した文書名を出力
実行結果
お台場の自由の女神像は、1998年4月から1999年1月まで設置されていた。
'statue_of_liberty.txt'
文書にある通り正確に回答が返ってきました。
また、出典元の文書名まで正しく出力することができています。
なお、LangChainではLLMに投げるプロンプトの中身をデフォルトでは出力しません。
LLMに渡すプロンプトがどうなっているかを確認する場合は、下のようにverboseの設定が必要です。
chain_type_kwargs={"verbose": True} # 行追加
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=model.to_langchain(),
chain_type="stuff",
retriever=docsearch.as_retriever(),
return_source_documents=True,
verbose=True, # 行追加
chain_type_kwargs=chain_type_kwargs # 行追加
)
verbose=Trueとした場合の実行結果はこちら
> Entering new RetrievalQA chain...
Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1
> Entering new StuffDocumentsChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
自 由 の 女 神
STATUE OF LIBERTY(STATUE DE LA LIBERTÉ)
原題:世界を照らす自由の女神像
1998-1999「日本におけるフランス年」を記念し、パリ市セーヌ川のシーニュ(白鳥)島に 1889年に
設
置された「自由の女神像」が 1998 年4月より 1999 年1月までの間、ここお台場海浜公園のこの台座上に
移築されました。
シーニュ島設置から 109 年目パリを離れて海を渡った世界初の海外公開でした。
レインボーブリッジを背景にお台場に立つ優美な姿は日仏友好のシンボルとして多くの人々に愛され、
フランスへの帰国が近づくにともない復刻像の再建を望む声が強まりました。
そうした背景のもと、フジテレビと臨海副都心まちづくり協議会・二つの自由の像設置委員会が中心となり、
オリジナル像からの完全復刻像制作案をまとめ、オリジナル像所有者であるパリ市に申請。
日本におけるフランス年実行委員会、駐日フランス大使館の協力を得て、1999 年3月パロ市からの正
式
許可を受けフランスに帰った「自由の女神像」の型取りが開始されました。
1999 年9月 パリ近郊、クーベルタン城内「クーベルタン鋳造工房」(Foundry of Coubertin)
で、オリジナル像と同じブロンズ鋳造製法で制作を開始。
2000 年 10 月 完全復像が完成。
2000 年 12 月 22 日 新世紀に世界に照らす、台場の自由の女神像が除幕されました。
協力:「日本におけるフランス年」実行委員会(ARAFJ)
パリ市
フランス大使館
東京都
自由の女神の歴史
1876 年フランス政府は、アメリカ建国 100 周年を祝して特別なプレゼントをニューヨーク市に贈りまし
た。このプレゼントこそが、あの有名なニューヨーク港にそびえ立つ「自由の女神像」。考案者はフランス人
彫刻家フレデリック=オーギュスト・バルトルディ(1834-1904)です。そして、その返礼として、パリ
在住のアメリカ人達による組織「アメリカ・パリ会」からフランス革命 100 周年を記念してフランス 政府に
寄贈されたのが、パリの「自由の女神像」です。
原題「世界を照らす自由の女神像」-「自由こそが異なる民を結びつける重要な要因」-の理念の元に、
1889 年 11 月5日、作者バルトルディ隣席のもとパリ・セーヌ川に浮かぶ中州、シーニュ(白鳥)島 に
於いて公式に除幕されました。
自由の女神像協賛法人名
アクアシティお台場 株式会社ニッポン放送
鹿島建設株式会社 日本郵船株式会社
株式会社産業経済新聞 ホテルグランパシフィックメリディアン
デックス東京ビーチ ホテル日航東京
東京臨海熱供給株式会社 株式会社ゆりかもめ
日本通運株式会社 臨海副都心まちづくり協議会
Question: お台場の自由の女神像はいつまで設置されていた?
Helpful Answer:
> Finished chain.
> Finished chain.
> Finished chain.
お台場の自由の女神像は、1998年4月から1999年1月まで設置されていた。
一番下の行に、回答が出力されました。
最後に、コード全文をこちらに載せておきます。ライブラリインストール後、お試しください。
# IBM Cloud API credentials and watsonx project id
credentials = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": "[IBM Cloud APIキーをここに貼り付け]"
}
project_id = "[プロジェクトIDをここに貼り付け]"
# 文書読み込み
from langchain.document_loaders import TextLoader
filename = 'statue_of_liberty.txt'
loader = TextLoader(filename)
print("loader: {}".format(loader))
documents = loader.load()
# ナレッジベースを作成する
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
loader = TextLoader(filename)
print("loader: {}".format(loader))
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 埋め込み関数を作成する
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
# watsonx.aiの準備
# モデルの選択とパラメータの設定
from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.utils.enums import DecodingMethods
model_id = ModelTypes.LLAMA_2_70B_CHAT
parameters = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.MIN_NEW_TOKENS: 1,
GenParams.MAX_NEW_TOKENS: 100
}
# モデルのインスタンスを作成する
from ibm_watson_machine_learning.foundation_models import Model
model = Model(
model_id=model_id,
params=parameters,
project_id=project_id,
credentials=credentials
)
chain_type_kwargs={"verbose": True} # LLMに投げたプロンプトを確認する場合
# 検索拡張生成を実行する
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=model.to_langchain(),
chain_type="stuff",
retriever=docsearch.as_retriever(),
return_source_documents=True,
verbose=True,
# オプション
chain_type_kwargs=chain_type_kwargs
)
query = "お台場の自由の女神像はいつまで設置されていた?"
answer = qa({"query": query})
print(answer["result"])
print("--------------------")
print(answer["source_documents"][0].metadata["source"]) # 検索に使用した文書名を出力