はじめに
本記事では、Slack BoltとChatGPT、LangChainを用いて社内FAQボットを開発する過程を、Partに分けて解説します。
このアプリについては、2023年の夏ごろに流行りに乗って作ったのですが、今年に入って使ってみると動かなくなっていたので、修正ついでに記事にしてみました。
最終ゴール
Slackから自作のチャットボットに質問し、AWS Lambda経由で独自データを回答するところまでを記載する予定です。
最終システム構想図
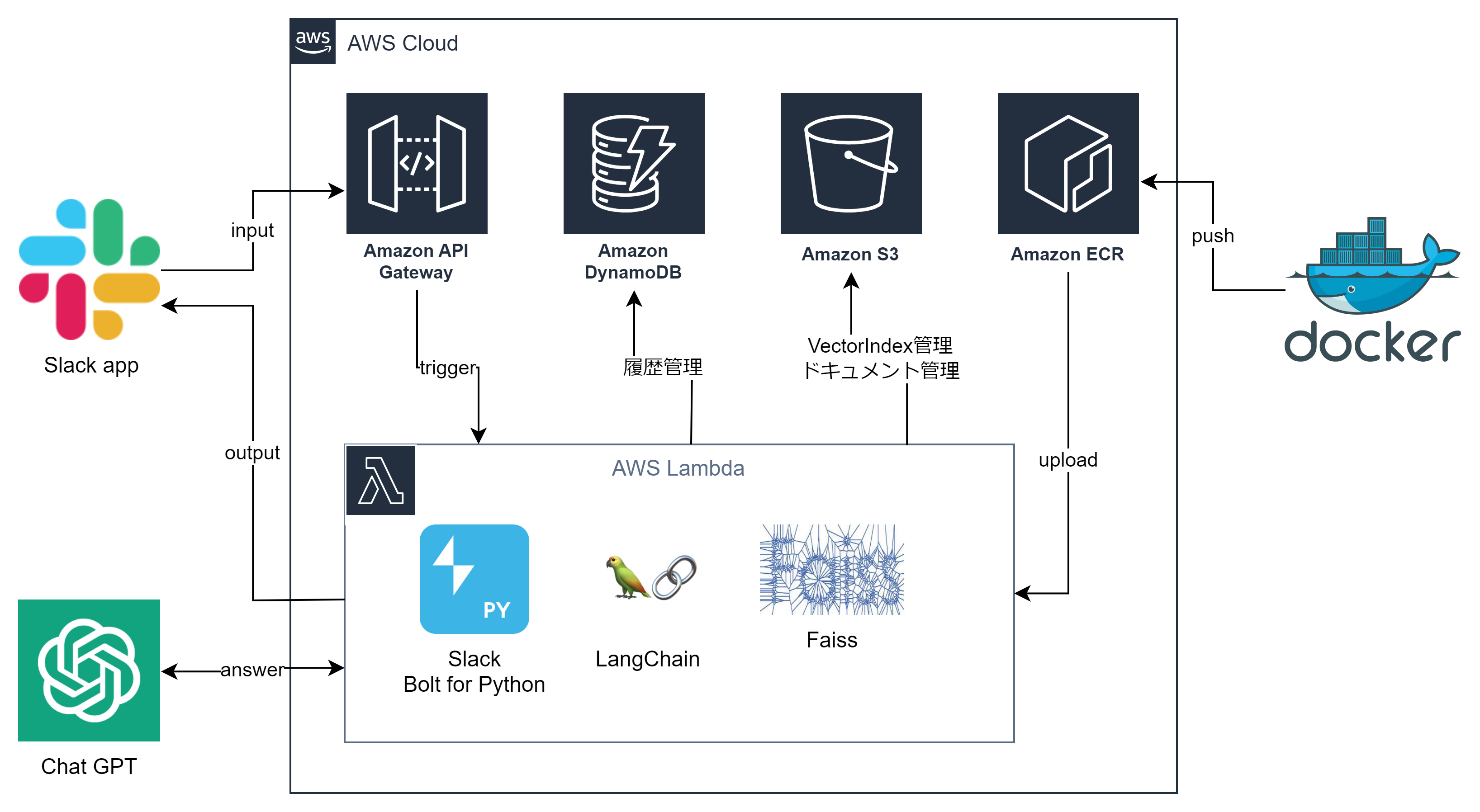
- チャットボットなので、UIはSlackを使い自作Botを作っています。
- AWS LammbdaにSlack Bolt for Pythonで自作Botを実装し、Faissでベクトルデータを検索します。独自データの回答にはChatGPT APIを使用、このあたりをLangChainで制御していきます。
- AWS Lambda上で動かすにあたり、250MB制限やローカルとの環境の違いなどを吸収する為、Dockerを使い開発して、Amazon ECR経由でLambdaにアップロードすることとします。
初回
Part1では、独自データの回答機能について、ベクトルデータの取り扱い、検索、ChatGPT APIとの連携などを説明します。
独自データの回答
1.独自データの取り扱い
社内規程集などの大きなドキュメントをChatGPTのAPIにすべて渡すことはできないので、GTPのEmbeddings APIを使ってドキュメントをベクトルデータに変換しベクターストアとして保存します。こうすることで、Meta社のFaissなどを使用してベクトルデータセットから類似性に基づいて最も近いアイテムを検索して、引っ張ってくることができるようになります。
以下、サンプルです。
import glob
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores.faiss import FAISS
from langchain_openai import OpenAIEmbeddings
faiss_index_dir = 'ベクトルデータのファイルを保存するフォルダを指定してください'
input_document_dir = 'ドキュメントが保存されているフォルダを指定してください'
docs = []
# 指定フォルダ内のPDFファイルをパスをすべて取得
files = glob.glob(os.path.join(
os.path.dirname(input_document_dir), '*.pdf'))
for file in files:
# PDFファイルを読み込み
loader = PyPDFLoader(file)
# ページ単位に分割
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=24)
# 指定サイズでチャンク分割
docs += text_splitter.split_documents(pages)
embeddings = OpenAIEmbeddings()
# ドキュメントをベクトル化
vector_store = FAISS.from_documents(docs, embeddings)
# インデックス保存
vector_store.save_local(os.path.dirname(faiss_index_dir))
今回使用するドキュメントはMicrosoftのWindows で開発環境を設定する です。600ページ程あます。LangChainのPDFLoaderの機能でPDFを読み込みます。読み込んだドキュメントをページ単位に分割してDocumentsオブジェクトのリストにしてくれます。
リスト化したドキュメントを指定のチャンクサイズに分割します。チャンクサイズは大きすぎるとChatGTP APIに渡すときのトークンサイズにひっかかりエラーとなります。
全てのPDFドキュメントの分割が終わると、分割したチャンクをベクターストアに保存します。
このコードを実行すると、ソースで指定した保存先に index.faiss と index.pkl ファイルが作られたと思います。
2.ベクトルデータを検索
先ほど作成したベクターストアを使用して、Faissでどういったデータが返ってくるか見てみましょう。
まず、Faissインデックスファイルを読み込みます。
LangChainの similarity_search を使用してベクトルデータを検索します。
質問は「Djangoプロジェクト」にします。
import os
from langchain_community.vectorstores.faiss import FAISS
from langchain_openai import OpenAIEmbeddings
faiss_index_dir = 'ベクトルデータのファイルを保存したフォルダを指定してください'
index_path = os.path.join(
os.path.dirname(faiss_index_dir), 'index.faiss')
# Faissインデックス読み込み
vector_store = FAISS.load_local(
os.path.dirname(faiss_index_dir),
OpenAIEmbeddings(),
allow_dangerous_deserialization=True)
# 'ベクターストアからのデータ取得
question = 'Djangoプロジェクト'
document = vector_store.similarity_search(question)
print(document)
実行結果
[Document(page_content='web_project という名前のサブフォルダー。次のファイルが含まれます。\n__init__.py: このフォルダーが Python パッwsgi.py: プロジェクトを実⾏する WSGI 互換 Web サーバーのエントリ ポ\nイント。 通常、このファイルは実稼働 Web サーバーへのフックを Web アプリの開発中に変更する、 Django プロジェクトの設\n定が含まれています。\nurls.py: Django プロジェクトの⽬次が含まれ、これも開発中...
Djangoプロジェクトに関係ありそうな文言が返ってきています。
3.ChatGPT APIを使って回答させる
ベクターストアから取得したベクトルデータと、質問文をChatGPTのAPIに渡して回答させてみましょう。ここからはAPIを呼ぶので費用が掛かってきます。ChatGPTのAPIキーが必要になりますので、まだの方は取得してください。
取得したAPIキーは環境変数などに保存して、お使いになることをお勧めします。
サンプルのソースでも環境変数から取得するようにしていますが、とりあえず試したいというかたは、ChatOpenAI.openai_api_key = '取得したAPIキー' でも大丈夫です。
retriever はLangChain におけるVectorStoreを検索エンジンとして利用するためのインタフェースです。
ChatOpenAI のインスタンス生成時に temperature を指定しています。temperature は答えのランダム性です。数を大きくすると実行毎に回答が変わってきます。
以下、サンプルソースは上のソースの続きです。
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
#OPENAI API KEYを環境変数から取得
ChatOpenAI.openai_api_key = os.environ.get("OPENAI_API_KEY")
retriever = vector_store.as_retriever()
# promptの作成
template = """
contextに従って回答してください:{context}
質問: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(temperature=0.0, max_tokens=1000)
# ChatGPTへの質問生成
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
)
# ChatGPTによる回答生成
ret = chain.invoke(question)
print(ret.content)
Djangoプロジェクトは、PythonのWebアプリケーションフレームワークであり、web_projectという名前のサブフォルダー内に複数のファイルが含まれています。このプロジェクトを検証するためには、python3 manage.py runserverコマンドを使用してDjangoの開発サーバーを起動します。開発サーバーは通常、ポート8000で実行されます。.....
Djangoプロジェクトのデバッグ方法などの説明が返ってきました。
上のベクトルデータ検索で返ってきた内容と照らし合わせると正しそうな回答になっています。600ページを超えるドキュメントからDjangoプロジェクトについて要約できていますね。
ひとまず、ChatGPTで独自データを回答するところまでできました。
次回はSlack Boltで自作ボットの作り、Slackから今回の独自データへの質問と回答ができるようにします。
参考文献