Ateam Brides Inc. Advent Calendar 2021の5日目は
株式会社エイチームブライズの@hyshrが担当します。
これは何?
新型コロナ対策でマスク着用しつつアクリルパネル越しに会話をすると、声が聞こえにくくなり会話がしにくくなったので、Rasberry Pi(以下RasPi)とLED掲示板を組合せて解決を試みた結果です。
背景
新型コロナウィルスの対策の1つで、多くのお店で「アクリルパネルの設置」がされているかと思います。
エイチーム社内にある社食も同様です。
大きなアクリルパネルが隙間なく設置されていて、例えば食後に軽く会話をしようとしても声が届きません。
同僚との会話であれば、もし聞き取れなかったとしても気軽に「もう1回言って」と聞き返せるでしょう。
ただ、偉い人との会話となると、引っ込み思案な私なんかは聞き返せません。
社長とお昼を食べてその後会話をした中で、聞こえたふりをしてうなずく事も多々ありました。
・・・解決方法は何かないのか・・・?
そうだ。
「音声認識したものをLED掲示板みたいなものにほぼリアルタイムで反映することで、聞き取りにくかった言葉も視認出来るし、聞こえたふりをしなくてもよいのでは?」と。
そこで、RasPiとLED掲示板を組み合わせて作ってみようと考えました。
クリスマスだしなんでもいいから光らせたい、という想いもあってのLED掲示板です。
準備したもの
- Rasberry Pi 4
- LED掲示板(32x64)
- ジャンパー線(メスメス)
制作 & 実装
作りたいものの構成を考えました。
- RasPiはAPIの口を作る。表示するテキストを受け取り、LED掲示板に流す。
- 音声認識はブラウザ上で動作するように作成
- ※今回は開発環境で試す
順番としては
- RasPiとLED掲示板を接続
- 接続確認
- RasPi上に簡易的なHTTPサーバを立てる
- ブラウザ上で音声認識し、2で用意したAPIに認識したテキストを渡すものを準備する
1. RasPiとLED掲示板の接続
LED掲示板の基盤には、ピン配置の説明はありませんでした。
ただし、基本的に下記のようになっているようです。
| コネクション | コネクション |
|---|---|
| R1 | G1 |
| B1 | GND |
| R2 | G2 |
| B2 | GND |
| A | B |
| C | D |
| CLK | STB |
| OE | GND |
| ※凹み/切り欠きが左側にくるように見た場合 |
上記LED掲示板のピンと、RasPi側のピンとを接続していきます。
RasPi側のピンとの対応表を、下記まとめを参考にして作ります。
https://github.com/hzeller/rpi-rgb-led-matrix/blob/master/wiring.md
| コネクション | ピン | ピン | コネクション |
|---|---|---|---|
| - | 1 | 2 | - |
|
|
3 | 4 | - |
|
|
5 | 6 | GND |
|
|
7 | 8 | [3]R1 |
| - | 9 | 10 | E |
|
|
11 | 12 | OE- |
|
|
13 | 14 | - |
|
|
15 | 16 | B |
| - | 17 | 18 | C |
|
|
19 | 20 | - |
|
|
21 | 22 | D |
|
|
23 | 24 | [1]R2 |
| - | 25 | 26 | [1]B1 |
| - | 27 | 28 | - |
|
|
29 | 30 | - |
|
|
31 | 32 | [2]R1 |
|
|
33 | 34 | - |
|
|
35 | 36 | [3]G2 |
|
|
37 | 38 | [2]B2 |
| - | 39 | 40 | [3]B2 |
しかし、このままでは、例えばR1が8番ピンと23番ピンにあるため、LED掲示板のR1をどちらに繋げばよいか迷います。
参考にしているサイトに下記画像がありますが
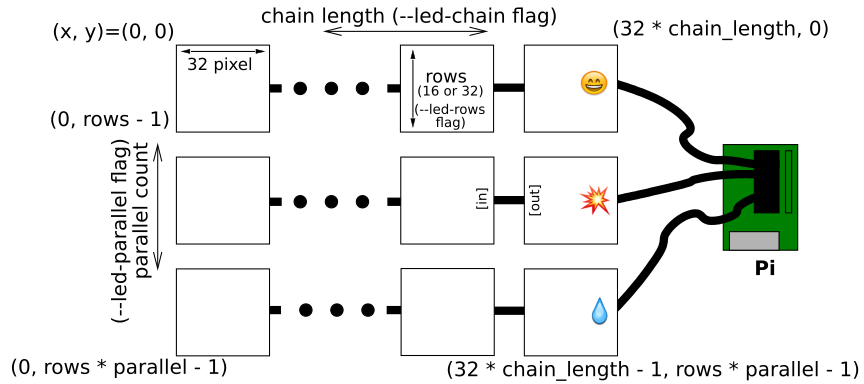
RasPiとLED掲示板は最大3レーン繋げることが出来るため、レーンごとに必要なピンが絵文字で分かれて書かれています。
今回使うLED掲示板は1つなので、対応表上 ![]() が付いているピンを接続していきます。
が付いているピンを接続していきます。
LED掲示板のR1をRasPiの23番ピンのR1と接続する、といった形です。
繋げ終わったものがこちらになります。

これでRasPiとLED掲示板の接続は完了です。
2. 接続確認
動作確認のため、デモを動かしましょう。
https://github.com/hzeller/rpi-rgb-led-matrix
を使います。
// build
git clone https://github.com/hzeller/rpi-rgb-led-matrix.git
cd rip-rgb-led-matrix
make -C examples-api-use
// demo実行
sudo examples-api-use/demo --led-no-hardware-pulse --led-rows=16 --led-cols=32 -D 1 -m 20 examples-api-use/runtext16.ppm
実行結果がこちら。
demo実行 pic.twitter.com/iOBGk4Qipc
— hyshr_dev (@HyshrD) December 2, 2021
下のスペースが気になるけれど、大丈夫そう。
3. RasPi上に簡易的なHTTPサーバを立てる
ブラウザで音声認識をするためにはSSL環境でないとマイクが許可されません。
SSL環境からサーバ側にリクエストを投げられるようにするために、サーバ側もSSL対応が必要となります。
opensslで鍵を作るなどして、下記コードでRasPi上にさくっとサーバを立てました。
※基本的にローカル環境までとしているので、Allow-Originは全開放してます
今回rpi-rgb-led-matrixを利用するにあたり、日本語は対応していない模様。
日本語を表示するには、画像変換したものを利用する必要があるとのこと。
参考)
https://thom.hateblo.jp/entry/2020/12/03/025355
import ssl
import json
import logging
from http.server import HTTPServer, SimpleHTTPRequestHandler
from PIL import Image, ImageFont, ImageDraw
# SSL対応のための証明書
CERTFILE="****"
KEYFILE="****"
def createPPM(text):
font = ImageFont.truetype("/user/share/fonts/truetype/fonts-japanese-gothic.ttf")
output_text = ""
for text_color_pair in text:
t = text_color_pair[0]
output_text += t
width, ignore = font.getsize(output_text)
img = Image.new("RGB", (width + 30, 32), "black")
draw = ImageDraw.Draw(img)
x = 0;
for text_color_pair in text:
t = text_color_pair[0]
c = tuple(text_color_pair[1])
draw.text((x, 0), t, c, font = font)
x = x + font.getsize(t)[0]
img.save("/home/pi/message.ppm")
return Popen(["exec /home/pi/tools/rpi-rgb-led-matrix/examples-api-use/demo --led-no-hardware-pulse --led-rows=32 --led-cols=96 -D 1 -m 30 /home/pi/message.ppm"], shell=True)
# 初期化
proc = createPPM([
[u" " + "テスト", [255, 0, 0]],
[u" " + "初期メッセージ表示", [0, 255, 0]],
[u" " + "待機中", [0, 0, 255]]
])
# methodのオーバーライド
class MyHandler(SimpleHTTPRequestHandler):
def do_OPTIONS(self):
self.send_response(200)
self.send_header("Access-Control-Allow-Origin", "*")
self.send_header("Access-Control-Allow-Methods", "GET, POST, OPTIONS")
self.send_header("Access-Control-Allow-Headers", "X-Requested-With, Content-type")
self.end_headers()
def do_POST(self, *args):
global proc
proc.terminate()
if hasattr(self.headers, 'getheader'):
content_len = int(self.headers.getheader('content-length'))
else:
content_len = int(self.headers.get('content-length'))
post_body = self.rfile.read(content_len)
proc = createPPM(json.loads(post_body))
self.send_response(200)
self.send_header("Access-Control-Allow-Origin", "*")
self.end_headers()
context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
context.load_cert_chain(CERTFILE, KEYFILE)
with HTTPServer(("RasPiのIP", 50007), MyHandler) as httpd:
try:
print("serving at address", httpd.server_address, "using cert file", CERTFILE)
httpd.socket = context.wrap_socket(httpd.socket, server_side=True)
httpd.serve_forever()
except KeyboardInterrupt:
proc.terminate()
httpd.close()
4. ブラウザ上で音声認識し、2で用意したAPIに認識したテキストを渡すものを準備する
今回は音声入力を3パターンで試してみました。
- Web Speech API
- Google Speech-To-Text API
- Azure Speech Service
4-1. Web Speech API
凝った実装はせずに、RasPiへのメッセージ送信とSpeechRecognitionの実装のみを。
//メッセージ送信
function send_message(value){
let sendData = [[value, [0, 0, 255]]];
// RasPiへリクエストを投げる
let requestOptions = {
method: 'POST',
headers:{'Content-Type': 'application/json'},
body: JSON.stringify([[sendData, [0, 255, 255]]])
}
fetch("RasPiで立てたサーバのURL:Port", requestOptions);
}
// Web Speech API
let SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
let recognition = new SpeechRecognition();
recognition.lang = 'ja-JP';
recognition.interimResults = true;
recognition.continuous = true;
let outputText = '';
recognition.onresult = (event) => {
for (let i = event.resultIndex; i < event.results.length; i++) {
let transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
outputText += transcript;
send_message(outputText);
outputText = "";
}
}
};
recognition.start();
4-2. Google Speech-To-Text
GoogleのSpeech-To-TextをJavascriptから利用する場合、一度ブラウザ上で音声を録音した後、その録音した音声ファイルをSpeech-To-Text APIに投げる必要がありました。
下記内容を参考に実装して試しています。
一部、録音開始/停止をボタンでするのは面倒なので、音量判定の実装を加えました。
import vad from 'voice-activity-detection';
// 音声録音部分はほぼそのまま使わせていただいているので省略
// マイクのみアクセス
let mediaOptions = {
audio: true,
video: false
}
const getMedia = () => {
navigator.mediaDevices
.getUserMedia(mediaOptions)
.then((stream) => {
localStream = stream;
let audioContext = new (window.AudioContext || window.webkitAudioContext)();
let inputSpeech = audioContext.createMediaStreamSource(localStream);
audioContext.resume();
recorder = new window.Recorder(inputSpeech);
// 音量判定
// ノイズ判定が0.35〜0.7の間で録音開始/終了を行う
let options = {
minNoiseLevel: 0.35, // from 0 to 1
maxNoiseLevel: 0.7, // from 0 to 1
onVoiceStart: function(){
recorder.record();
},
onVoiceStop: function () {
recorder.stop();
// Speech to Text
audioRecognize();
recorder.clear();
},
onUpdate: function(val) {
//console.log("update val: " + val);
}
};
vad(audioContext, localStream, options);
})
.catch((error) => {
console.error("mediaDevices.getUserMedia error", error);
return;
});
};
4-3. Azure Speech Service
調べてみると、GoogleのSpeech-To-Textの時のように音声録音の実装無しでブラウザ上でのリアルタイム音声認識ができそうだったので、試してみました。
4-3-1. リソースの作成
Azureのアカウント作成後、ダッシュボード上にある「リソースの作成」をクリック。
4-3-2. 「サービスとマーケットプレースを〜」と書かれている検索バー上で「Speech」と検索
検索をすると「音声」サービスが出てくるので、それを選択します。
4-3-3. 必要項目を入力
無料枠で利用したい場合には、Pricing tireで「Free F0」を選択します。
リソースの作成はこれで完了です。
4-3-4. サンプルコードを利用してみる
サンプルコードがあるので、そのリポジトリをcloneして使ってみましょう。
git clone https://github.com/Azure-Samples/AzureSpeechReactSample.git
cd AzureSpeechReactSample
npm install
npm run dev
App.jsと.envに修正を加えます。
App.jsには下記2点の修正を加えます。
- 言語設定を日本語にする
- RasPiへリクエストする
////
async sttFromMic() {
const tokenObj = await getTokenOrRefresh();
const speechConfig = speechsdk.SpeechConfig.fromAuthorizationToken(tokenObj.authToken, tokenObj.region);
speechConfig.speechRecognitionLanguage = 'ja-JP'; // 日本語設定
const audioConfig = speechsdk.AudioConfig.fromDefaultMicrophoneInput();
const recognizer = new speechsdk.SpeechRecognizer(speechConfig, audioConfig);
this.setState({
displayText: 'speak into your microphone...'
});
recognizer.recognizeOnceAsync(result => {
let displayText;
if (result.reason === ResultReason.RecognizedSpeech) {
displayText = `RECOGNIZED: Text=${result.text}`;
// RasPiへリクエストを投げる
let requestOptions = {
method: 'POST',
headers:{'Content-Type': 'application/json'},
body: JSON.stringify([[result.text, [0, 255, 255]]])
}
fetch("RasPiで立てたサーバのURL:Port", requestOptions);
} else {
displayText = 'ERROR: Speech was cancelled or could not be recognized. Ensure your microphone is working properly.';
}
this.setState({
displayText: displayText
});
});
}
/////
Azureの音声サービスにある「Key and Endpoint」から、キーとRegionの値を.envに反映します。
SPEECH_KEY=キー1の値
SPEECH_REGION=Location/Regionの値
これでAzureでのSpeech Serviceの準備は完了です。
結果
基本的にはどの方法をとったとしても作りたかったものは作れました。
私の体感にはなりますが、音声認識からテキスト化までの速度としては
Web Speech API >= Azure Speech Service > Google Speech-To-Text
音声認識の変換精度としては、色々と試しての体感にはなりますが
Azure Speech Service > Google Speech-To-Text > Web Speech API
といった順序でした。
Gifにしたらアップロードできるサイズの関係で画質が悪いですが、動作としてはこのようなものになります。
動作検証 pic.twitter.com/GzYRkEBMXq
— hyshr_dev (@HyshrD) December 2, 2021
私が「昔々、あるところに大車輪オトーマスがいました」と話し終えた1.5秒後ぐらいには、認識が完了しLED掲示板にも反映されています。
まとめ
サンプルコードレベルでも、やりたいことはさくっとできました。
大きめのLED掲示板で試していますが、小さいサイズのLED掲示板にすることで実用的になるかもしれません。
最初に考えていた、社食でも使えるかもしれません。
.....
いや無い。
iOS/Androidアプリを作って、聞き取れなかった時にアプリを見る、とアプリだけで完結させれば良いのでは?
もしくは、LED掲示板は残しつつも、RasPiにマイクをつけて入力端末を個人が持たなくても機能するようにすれば良いのでは?
次週
RasPi完結型、iOS/Androidアプリ完結型にチャレンジします。