はじめに
私は、ある事業会社で働いているITエンジニアです。
2024年から事業の加速と安定を両立するため、SREチームを立ち上げました。
独自実装によるオブザーバビリティ基盤が既に存在していたため、そちらを拡張することに注力していましたが、
せっかくなのでOSSを活用しながらSREを再履修することにしました。
本記事は2章にわたって記載しますが、以下のような方に是非参考になればと思います。
- SREはなんのためにあるのか知りたい
- SRE活動を始めようと思っているものの、まず何をしたらいいかわからない
- SRE活動を始めてみたものの、どのような効果があるのかわからない
それでは、よろしくお願いいたします。
SREについて
解釈
原典であるSRE本の解釈は様々ありますが、
私にとってSREの真髄は「戦略的リスク管理ができること」と理解しています。
戦略的リスク管理
DevOpsが進んだ現代では、アプリとインフラ両方に責任を持つ開発チームが増えておりますが、
新規開発をしながらも、日々老朽化していくコードやインフラをメンテナンスしなければならない状況に直面することがあるでしょう。
特にマネジメント層においては、「今自分たちは何をするべきなのか?」という問いを常に持ち続ける必要があり、システム信頼性を上げるための保守活動をするべきなのか、新規開発をするべきなのか判断が難しい状況も多々あります。
私は、SREを導入することによって、「今このシステムの保守をする必要があるのか」、「気にせずガンガン開発していいのか」を定量的に判断することができると考えます。
さらには、定量的であるが故にメンバーもその判断ができるようになり、マネジメント層は「ビジネスインパクトの大きい開発タスクの創造」や、「ピープルマネジメント」に注力することができます。
(タスクアサインを待つのではなく、バックログアイテムから自主的にとっていく形が理想)
※SREの本質はこれだけではなく、同時に運用作業の圧縮をエンジニアリングによって行うことで、さらにビジネススピードの加速に貢献することができます。
では、具体的に何をどうしたらいいのか?を記載していきます。
まずは第一歩として「オブザーバビリティ基盤の構築」を本記事で紹介いたします。
前提
- SRE, オブザーバビリティの言葉の意味や、OpenTelemetry、Prometheus、Tempo、Loki、Grafanaの役割は割愛します。
- 動くことを前提としており、ベストプラクティスから遠い実装もありますので、是非本記事を参考にしつつ本番における作りこみをしてみてください!
ゴール
- AWS上にオブザーバビリティ基盤を作成 ←本記事はここです。Grafana上でトレース・メトリクス・ログが見れるようになるまでの環境構築方法を紹介しています。
- SLI/SLOの策定
- Grafanaダッシュボード及びアラートを作成し、SLOを満たしているかモニタリング&監視ができることを確認
- 以上の活動により、チームとビジネスがどう変化するかの想定をまとめる
全体構成
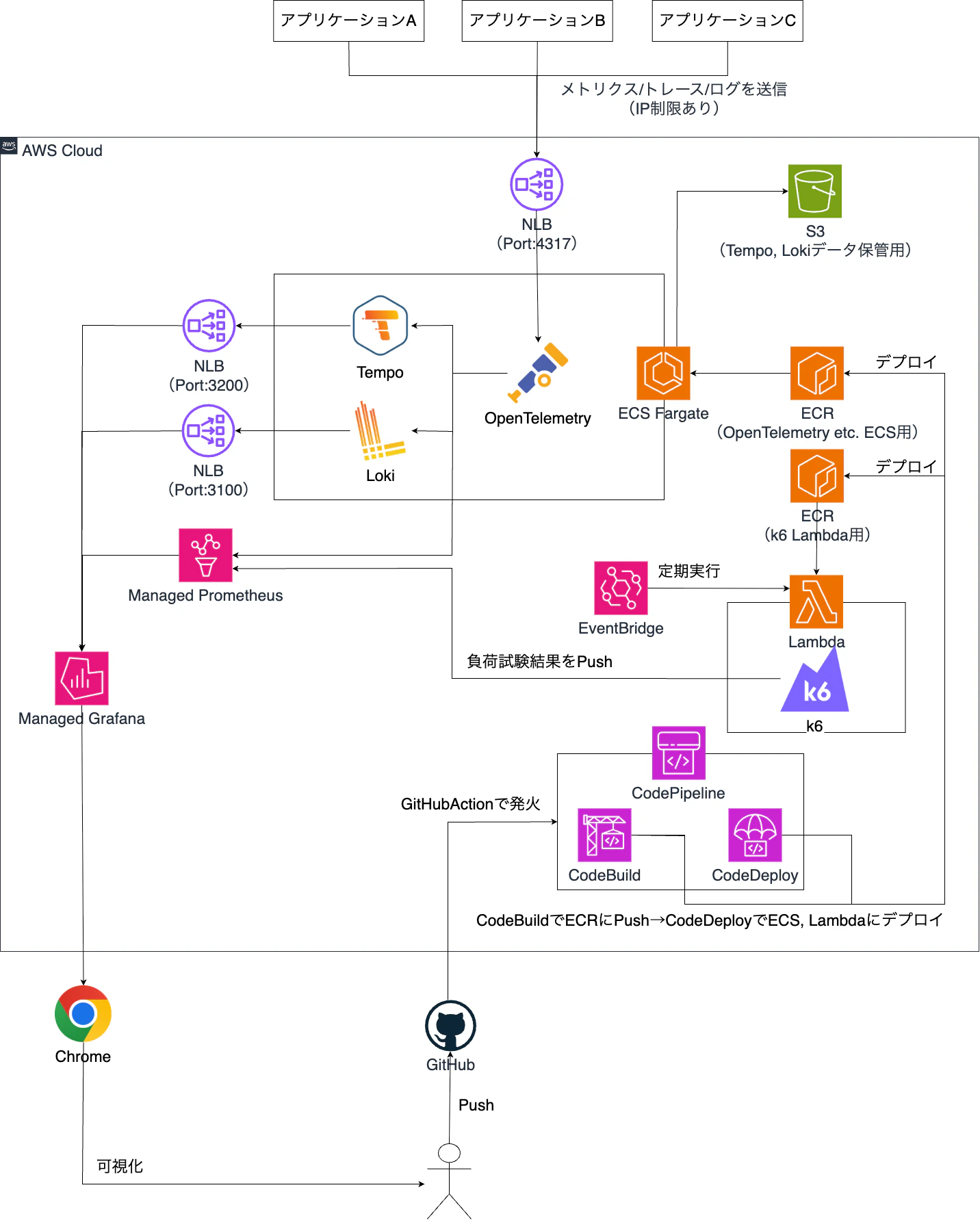
-
OpenTelemetryを受け口とするので、4317ポートの通信をNLB→ECSに伝搬します。
-
Prometheus, Grafanaはマネージドサービスがあるのでそちらを利用します。
-
構成管理はterraformを使用します。
-
サイドカーにしない理由
監視対象がECSFargate上に存在するのであれば、サイドカー構成も考えられますが、
Lambdaやオンプレのリソースを使用した分散システムを想定しており、どこからでもメトリクスやログを投げられるようにしたいと思い、APIサーバ的な立ち位置にしました。 -
EKSにしない理由
個人開発用&まずは動くものをということで、dockerfile1つだけで完結できるECSを採用しました。
しかし、ECSだとPodネットワーク的なクラスタリングが存在せず2タスク以上起動するとデータ不整合が発生するので、実際に本番環境で使用する場合はEKSをご利用ください。
細かい説明はいいから動くものを。という人向け
https://github.com/HTDevelop/observability
こちらにコードがあります。ReadMeに構築手順記載しております。手順を実行することで、CodePipeline以外のリソースを作成することができます。
尚、ここからは上記のinfra/terraformのコードから構築していることを前提とします。
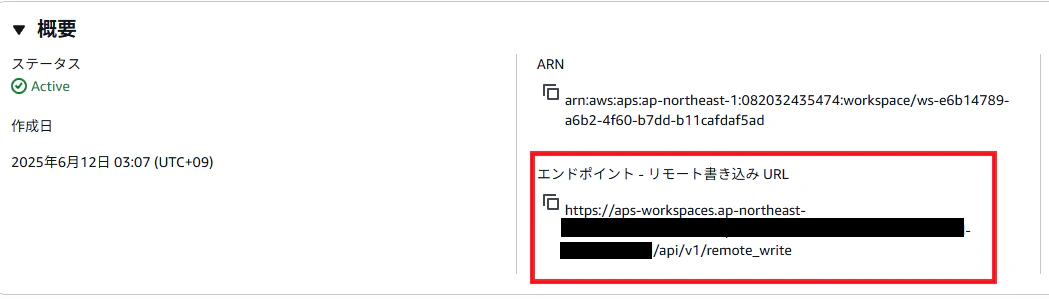
マネージドPrometheus構築
作成後、リモート書き込み用URLが発行されるので、
このURLに向けてOpenTelemetryからデータを送信します。
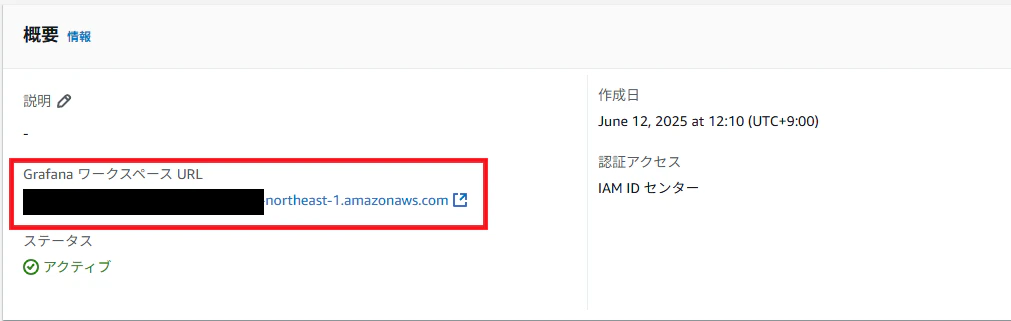
マネージドGrafana構築
作成後、ワークスペースURLが発行されるので、そこにアクセスしてログインします。
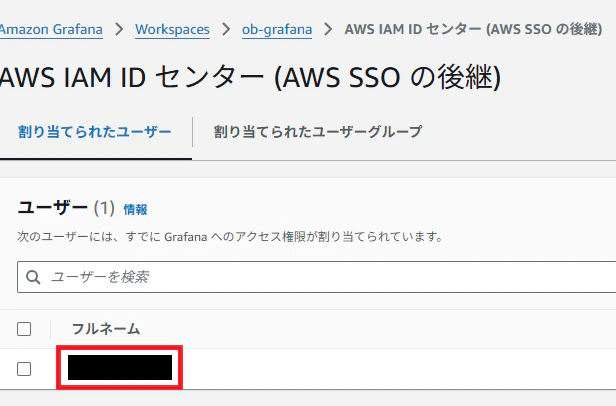
IAM Identity Centerでユーザを発行して紐づけると、Grafana画面にログインできます。

↓
NLB + ECS FargateでOpenTelemetry + Loki + Tempo構築
構成
複雑な構成にはせずに1つのコンテナ内にOpenTelemery, Tempo, Lokiすべて同梱しています。
※前段にも書きましたが、データ整合性の観点からタスク起動数は1にしてください。
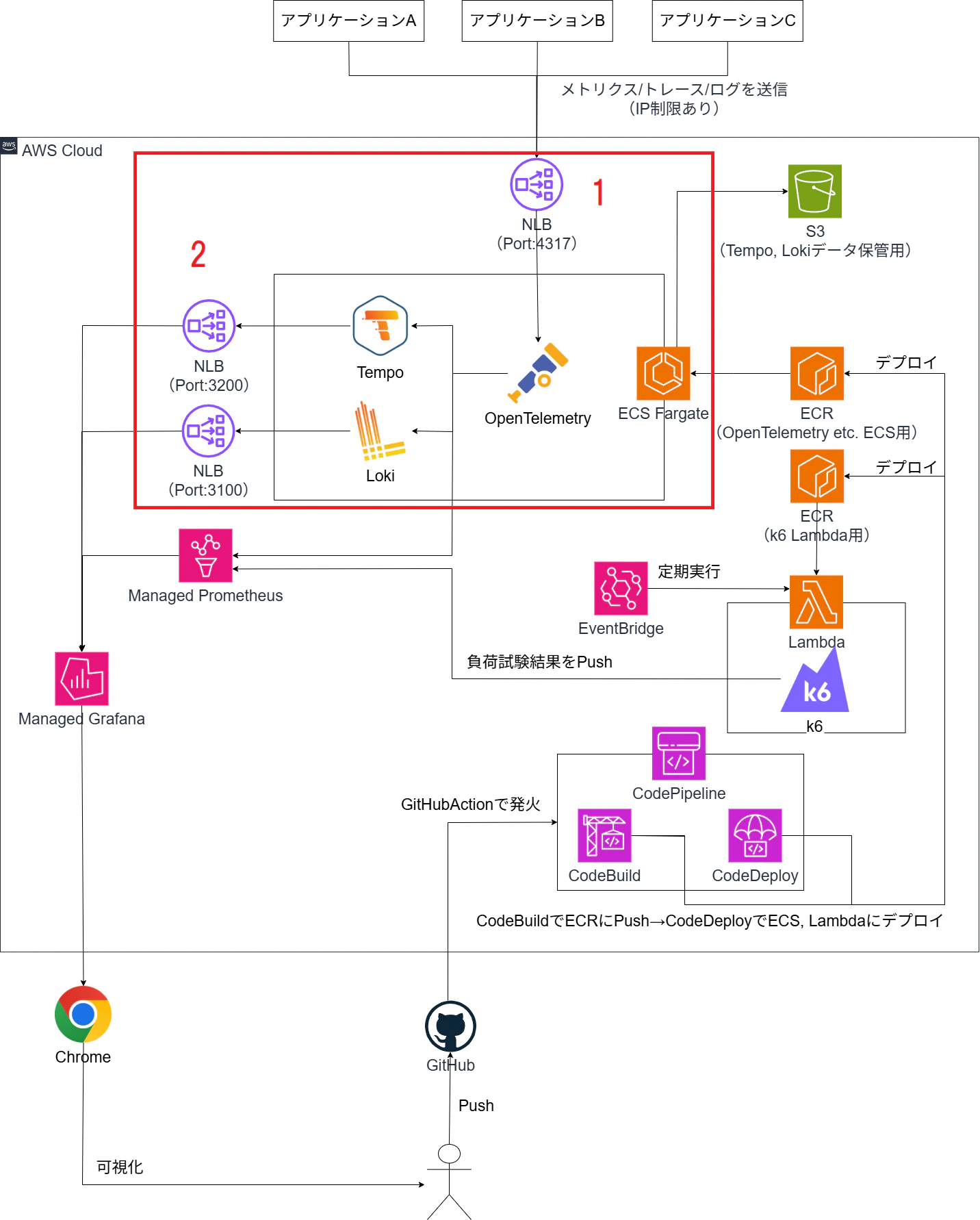
- トレース、メトリクス、ログを受け取るためにNLBでポート4317を受け付けて、ECSに転送します。
この時、セキュリティグループでIP制限をする等してNLBのセキュリティを担保することをおすすめします。 - GrafanaからTempo, Lokiに対してクエリを発行するために、エンドポイントとしてNLBを設置しています。
dockerfile
FROM almalinux:8
RUN dnf install -y curl unzip && dnf clean all
RUN mkdir -p /etc/otelcol /etc/loki /etc/tempo /bin /bin/otelcol /bin/tempo /bin/loki
# --- OpenTelemetry Collector ---
RUN curl -LO https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.128.0/otelcol-contrib_0.128.0_linux_amd64.tar.gz && \
tar -zxvf otelcol-contrib_0.128.0_linux_amd64.tar.gz -C /bin/otelcol
COPY otel-collector-config.yaml /etc/otelcol/config.yaml
# --- Loki ---
RUN curl -LO https://github.com/grafana/loki/releases/download/v3.5.1/loki-linux-amd64.zip && \
unzip loki-linux-amd64.zip -d /bin/loki
COPY loki-config.yaml /etc/loki/config.yaml
# --- Tempo ---
RUN curl -LO https://github.com/grafana/tempo/releases/download/v2.8.0/tempo_2.8.0_linux_amd64.tar.gz && \
tar -zxvf tempo_2.8.0_linux_amd64.tar.gz -C /bin/tempo
COPY tempo-config.yaml /etc/tempo/config.yaml
# エントリーポイントスクリプト
COPY start.sh /start.sh
RUN chmod +x /start.sh
# 必要なポートを公開(OTLP, Loki, Tempoなど)
EXPOSE 4317 4318 3100 3200
CMD ["/bin/sh", "-c", "/start.sh"]
start.sh
/bin/otelcol/otelcol-contrib --config=/etc/otelcol/config.yaml &
/bin/tempo/tempo -config.file /etc/tempo/config.yaml &
/bin/loki/loki-linux-amd64 -config.file /etc/loki/config.yaml
wait -n
exit $?
OpenTelemetry設定ファイル(otel-collector-config.yaml)
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
exporters:
otlp/tempo:
endpoint: "localhost:5317"
tls:
insecure: true
sending_queue:
enabled: true
prometheusremotewrite:
endpoint: "https://XXXXXXXXX/api/v1/remote_write"
auth:
authenticator: sigv4auth
debug:
verbosity: detailed
otlphttp/loki:
endpoint: "http://localhost:3100/otlp"
processors:
batch:
connectors:
spanmetrics:
histogram:
explicit:
buckets: [1ms, 10ms, 100ms, 200ms, 300ms, 400ms, 500ms, 600ms, 700ms, 800ms, 900ms, 1s]
metrics_flush_interval: 3s
metrics_expiration: 10s
exemplars:
enabled: true
service:
extensions: [sigv4auth]
pipelines:
metrics:
receivers: [otlp, spanmetrics]
processors: [batch]
exporters: [debug, prometheusremotewrite]
traces:
receivers: [otlp]
processors: [batch]
exporters: [debug, otlp/tempo, spanmetrics]
logs:
receivers: [otlp]
processors: []
exporters: [otlphttp/loki]
- receiversはどこからでも受け付けられるように0.0.0.0を指定しています。
(IP制限はセキュリティグループで行うことにしています) - Tempo(otlp/tempo), Loki(otlphttp/loki)は同一コンテナ内なので、localhostを対象にしています。
- PrometheusはManagedPrometheusに対してインターネットアクセスで書き込むので、prometheusremotewriteの欄にリモード書き込み用URLを指定しています。(このコード上ではマスクしています。)
またAWSリソースにはsigv4auth認証を使用します。 - spanmetricsも送信先に指定すると、より細かくspan単位でのトレース情報が得られます。
- exemplars.enable.trueにするとメトリクス情報にトレースID、スパンIDを紐づけられます。
Loki設定ファイル(loki-config.yaml)
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
log_level: error
grpc_server_max_concurrent_streams: 1000
common:
path_prefix: /tmp/loki
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
limits_config:
metric_aggregation_enabled: true
enable_multi_variant_queries: true
storage_config:
tsdb_shipper:
active_index_directory: /tmp/loki/index
cache_location: /tmp/loki/index_cache
cache_ttl: 24h # Can be increased for faster performance over longer query periods, uses more disk space
aws:
s3: s3://ap-northeast-1/ob-loki-s3
region: ap-northeast-1
access_key_id: XXXXXXXXXXXXXXXXX
secret_access_key: XXXXXXXXXXXXXXXXX
schema_config:
configs:
- from: 2020-07-01
store: tsdb
object_store: aws
schema: v13
index:
prefix: index_
period: 24h
pattern_ingester:
enabled: true
metric_aggregation:
loki_address: localhost:3100
ingester:
chunk_encoding: snappy
wal:
flush_on_shutdown: true
ruler:
alertmanager_url: http://localhost:9093
frontend:
encoding: protobuf
- ECS Fagateにデプロイする都合上、データの永続化に関してはローカルストレージを使用することはできません。
(リリースによるタスクの入れ替えによるデータ消失、複数タスクの起動によるデータ不整合が発生するため)
そのため、S3にデータを配置する構成にしています。 - <s3-name>の欄にはご自身のS3バケット名、access_key_id、secret_access_keyにはS3への読み書き権限があるIAMユーザ等から取得した情報を設定する必要があります。
- AWS認証情報をハードコーディングしたくない場合は、このように設定するとロールを使用して認証できるようですが、記載の感じだとEC2のみかもしれません(未検証)
- flush_on_shutdown: trueとしていますが、これはシャットダウン時に可能な限りWALの情報をストレージに書き込む設定です。これにより、タスク入れ替え時などにデータ消失を防ぎます。
- 設定に関する公式ドキュメントはこちら
Tempo設定ファイル(tempo-config.yaml)
stream_over_http_enabled: true
server:
http_listen_port: 3200
log_level: info
distributor:
receivers:
otlp:
protocols:
grpc:
endpoint: "0.0.0.0:5317"
metrics_generator:
registry:
external_labels:
source: tempo
storage:
path: /var/tempo/generator/wal
remote_write:
- url: https://XXXXXXXXXXXXXXXXX/api/v1/remote_write
send_exemplars: true
sigv4:
region: ap-northeast-1
access_key: XXXXXXXXXXXXXXXXX
secret_key: XXXXXXXXXXXXXXXXX
ingester:
trace_idle_period: 5s
max_block_duration: 1m
flush_all_on_shutdown: true
storage:
trace:
backend: s3
s3:
bucket: <s3-name>
endpoint: s3.ap-northeast-1.amazonaws.com
region: ap-northeast-1
prefix: ob-tempo-
access_key: XXXXXXXXXXXXXXXXX
secret_key: XXXXXXXXXXXXXXXXX
insecure: false
overrides:
defaults:
metrics_generator:
processors: [service-graphs, span-metrics] # enables metrics generator
generate_native_histograms: never
- exemplarsを使って、Prometheusのメトリクスからトレースに飛べるようにprometheusに送信する仕組みを導入しています。
- metrics_generatorによって、span単位でのトレース情報を出力しています。
- flush_all_on_shutdown trueとしていますが、これはLokiと同様にシャットダウン時に可能な限りWALの情報をストレージに書き込む設定です。これにより、タスク入れ替え時などにデータ消失を防ぎます。
- 設定に関する公式ドキュメントはこちら
k6による負荷試験
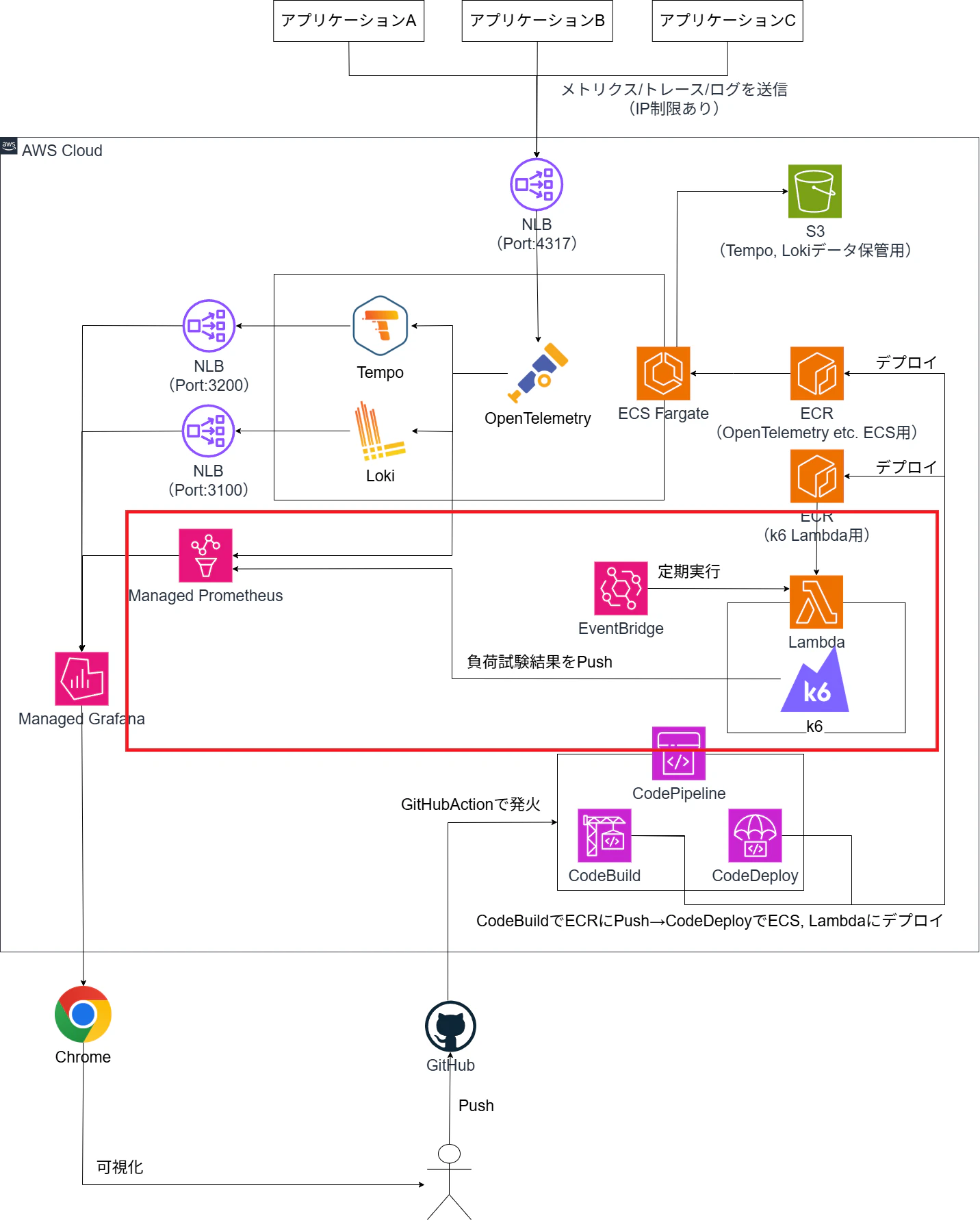
dockerfile
FROM golang:1.24 AS builder
RUN go install go.k6.io/xk6/cmd/xk6@latest
RUN xk6 build --with github.com/grafana/xk6-output-prometheus-remote
FROM public.ecr.aws/lambda/provided:al2
COPY --from=builder /go/k6 /usr/bin/k6
COPY ./k6.js /k6.js
ENTRYPOINT ["k6", "-o", "experimental-prometheus-rw", "run", "/k6.js"]
k6.js
import http from 'k6/http';
import { check } from 'k6';
export const options = {
vus: 5,
duration: '5s',
};
export default function () {
const res = http.get('https://test.k6.io/');
check(res, {
'status is 200': (r) => r.status === 200,
});
}
k6テスト用サイトに向けて、5ユーザ5秒間アクセスする設定にしています。
実際にご自身のサイトに向けて行う場合は、ホスティング先の負荷試験ポリシーに沿ってご利用ください。
例:AWSテストポリシー
環境変数
Prometheusに結果を送信するために、環境変数にURLやアクセスキーなどの情報をセットする必要があります。
この環境変数を設定した上で、「- o experimental-prometheus-rw」オプションを指定して実行すると、K6_PROMETHEUS_RW_SERVER_URLで指定したリモートURLに書き込むことができます。

※IAMの詳細は省きますが、Prometheusへのアクセス許可が必要です。
(おまけ)CI/CD
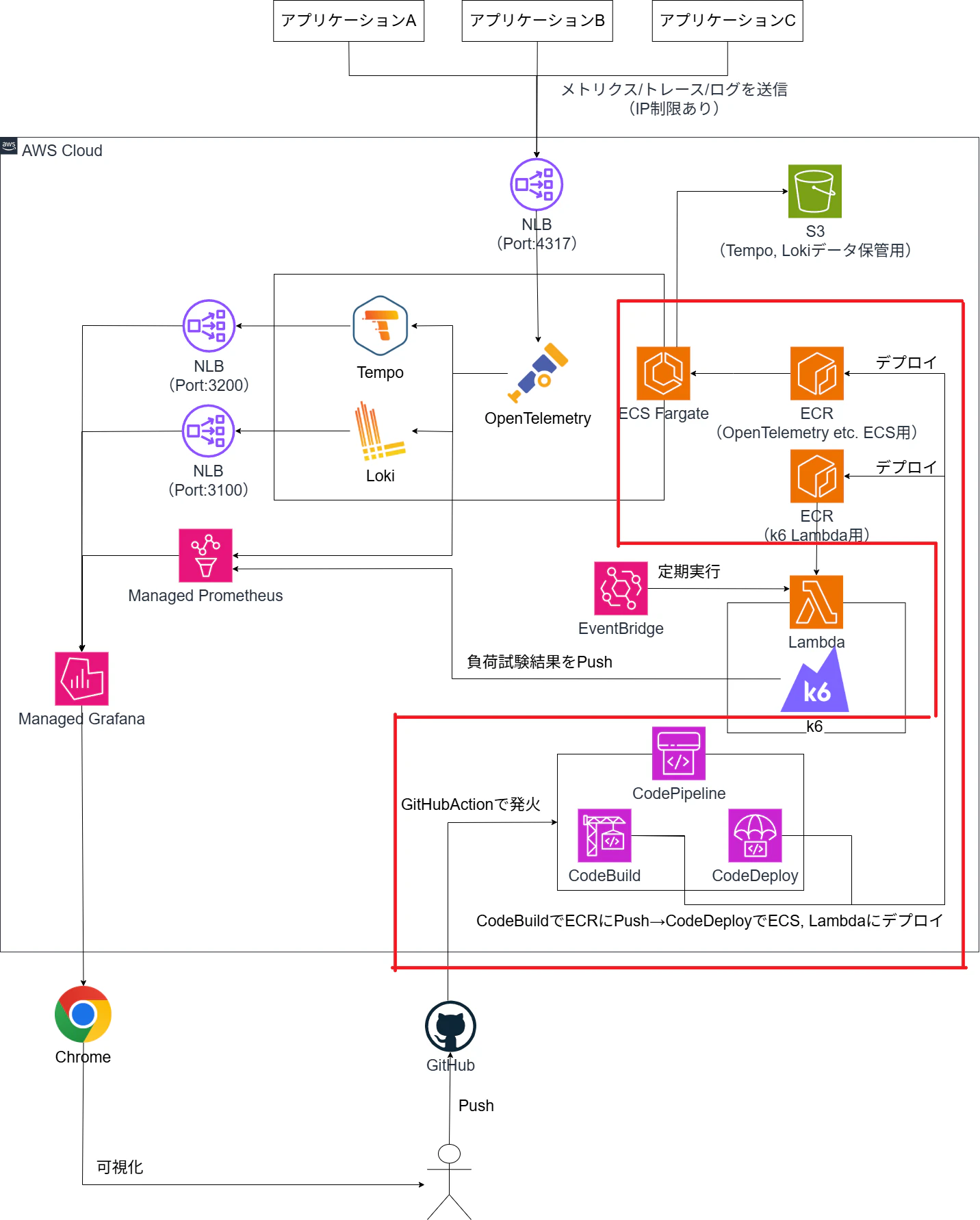
SRE実践をするにあたり、なるべく手作業の繰り返し運用(=トイル)は削減したいので、GitHubAction + CodePipelineで自動化しました。
ビルド→ECRにPush→ECS Fargateにデプロイの流れは色々記事が出回っておりますので、省略します。
Grafana設定
Prometheus
- Connections → Apps → AWS Data Sources → Amazon Managed Service for Prometheusを選択
- workspaceの欄にマネージドPrometheusURL(
https://aps-workspaces.ap-northeast-1.amazonaws.com/workspaces/ws-XXXXXXXXXXXXXXX/)を設定

- Save & testボタンを押下して「Successfully」と表示されればOK
Loki
- Connections → Data sources → Add new data sourceでLokiを選択
- Connectionの欄にLoki用のNLBのドメインURL + 3100(
http://XXXXXXXXX.elb.ap-northeast-1.amazonaws.com:3100) を指定

- Derived fieldsの欄で以下のように入力(ログからトレースを見るために使います。)

- Save & testボタンを押下して「Successfully」と表示されればOK
Tempo
- Connections → Data sources → Add new data sourceでLokiを選択
- Connectionの欄にTempo用のNLBのドメインURL + 3200(
http://XXXXXXXXX.elb.ap-northeast-1.amazonaws.com:3100)を指定

- Trace to metricsの欄に以下のように入力します。(トレースからログを見るために使います。)
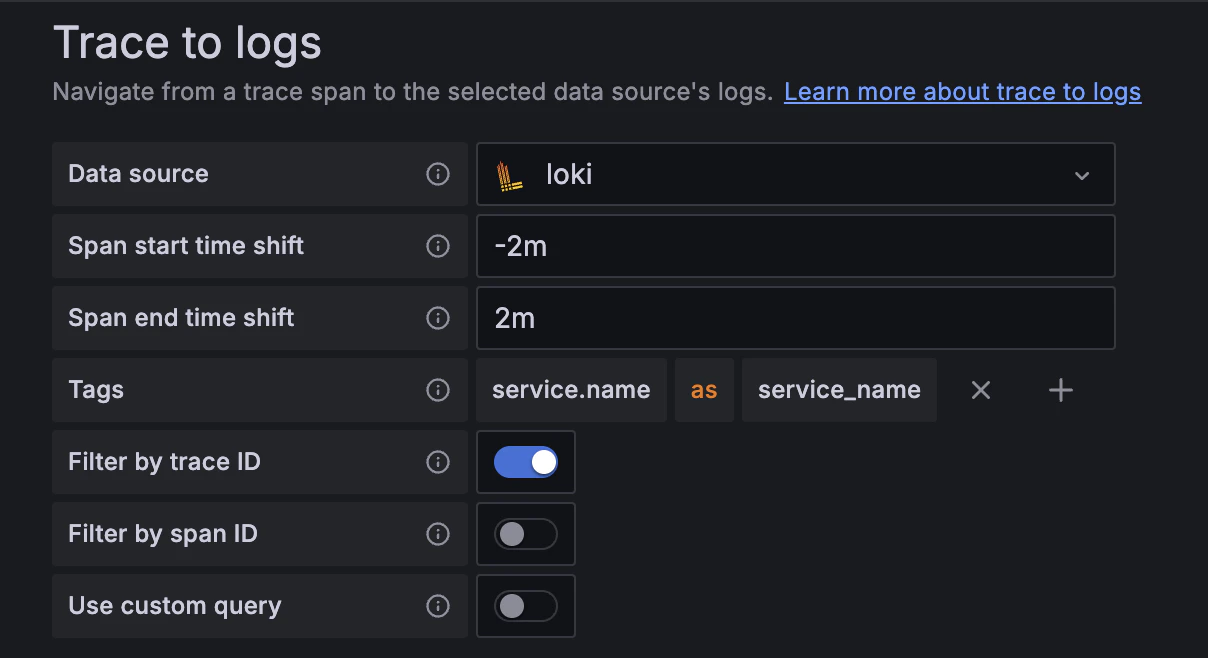
Tagの欄は、Tempoでは「sercvice.name」という名前ですが、Loki上では「service_name」となっているので、トレース→ログ検索の際にマッピングするために設定します。 - Save & testボタンを押下して「Successfully」と表示されればOK
k6
- Dashboards → New → Import → 19665 と入力すると公式がk6用に用意しているダッシュボードを使うことができます。

全体動作確認
監視対象サンプル
Pythonでトレース、メトリクス、ログを投げるスクリプトを書きました。
本来はWebアプリや常駐アプリを監視対象としますが、今回はサンプルとしてそれを模したWhileループにしています。
スクリプト:sapmle_send.py ※長いので折りたたんでいます。
from opentelemetry import trace, metrics
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from opentelemetry.instrumentation.logging import LoggingInstrumentor
from opentelemetry.trace import Status, StatusCode
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry._logs import set_logger_provider
import time
import requests
import logging
# Setup Resource
resource = Resource(attributes={
"service.name": "demo-service",
"service.instance.id": "instance-001",
})
# Setup Tracing
trace.set_tracer_provider(TracerProvider(resource=resource))
tracer = trace.get_tracer(__name__)
trace.get_tracer_provider().add_span_processor(
BatchSpanProcessor(OTLPSpanExporter(endpoint="http://ob-grpc-nlb-39f239ed93149806.elb.ap-northeast-1.amazonaws.com:4317", insecure=True))
)
# Setup Metrics
reader = PeriodicExportingMetricReader(
OTLPMetricExporter(endpoint="http://ob-grpc-nlb-39f239ed93149806.elb.ap-northeast-1.amazonaws.com:4317", insecure=True)
)
provider = MeterProvider(resource=resource, metric_readers=[reader])
metrics.set_meter_provider(provider)
meter = metrics.get_meter(__name__)
counter = meter.create_counter("app_requests_total", unit="1", description="Total requests")
# Setup Log
class OTLPFormatter(logging.Formatter):
def format(self, record):
span = trace.get_current_span()
ctx = span.get_span_context()
if ctx.is_valid:
trace_id = format(ctx.trace_id, '032x')
span_id = format(ctx.span_id, '016x')
record.msg = f"[trace_id={trace_id} span_id={span_id}] {record.msg}"
return super().format(record)
provider = LoggerProvider(resource=resource)
processor = BatchLogRecordProcessor(OTLPLogExporter(endpoint="http://ob-grpc-nlb-39f239ed93149806.elb.ap-northeast-1.amazonaws.com:4317", insecure=True))
provider.add_log_record_processor(processor)
set_logger_provider(provider)
# Python 標準 logging と連携
otel_handler = LoggingHandler(level=logging.INFO, logger_provider=provider)
otel_handler.setFormatter(OTLPFormatter())
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
logger.addHandler(otel_handler)
LoggingInstrumentor().instrument(set_logging_format=True)
counter = meter.create_counter("app_requests_total", unit="1", description="Total requests")
def do_work():
with tracer.start_as_current_span("my-span") as span:
span.set_attribute("example.key", "value")
counter.add(1, {"route": "/example"}) # This will be linked via exemplar if setup correctly
time.sleep(0.2)
logger.info(f"This is a test log message from OpenTelemetry")
# Run app
if __name__ == "__main__":
while True:
try:
do_work()
except:
pass
time.sleep(5)
- サンプルスクリプト実行
python sample_send.py
Prometheus確認
- Explore → プルダウンからPrometheusを選び、以下の条件で検索
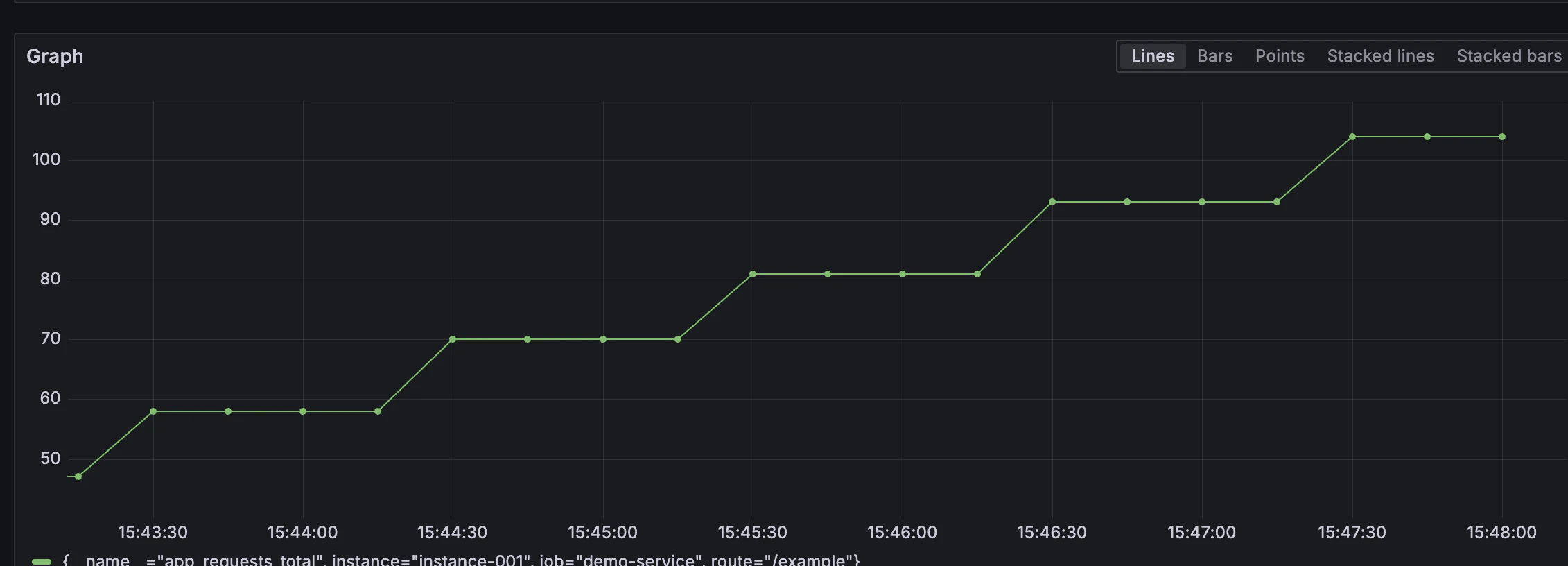
- グラフが表示されればOK(毎ループ + 1するだけなので、徐々に右肩上がりになるはず)
Loki確認
- Explore → プルダウンからLokiを選び、以下の条件で検索

- スクリプト側で設定したログがあればOK

- Derived fieldsの設定がちゃんとできていると、以下のようなボタンが出現します。

- クリックすると該当のトレースIDのトレースが出ます。これによって、わざわざトレースIDをコピーしてTempoの検索をしなくて済みます。

Tempo確認
- Explore → プルダウンからTempoを選び、Searchタブをクリックすると、以下のようにトレース一覧が表示されます。

- Trace to metricsの設定がちゃんとできていれば、以下のボタンが出現します。

- クリックすると、ログ検索ができます。これにより、わざわざLokiの画面に遷移して検索しなくて済みます。

k6結果確認
本構成ではEventBridge→Lambdaで定期実行されますが、以下コマンドで手動実行も可能です。
export K6_PROMETHEUS_RW_SIGV4_REGION=ap-northeast-1
export K6_PROMETHEUS_RW_SIGV4_ACCESS_KEY=XXXXXXXXXXXXXXXXXX
export K6_PROMETHEUS_RW_SIGV4_SECRET_KEY=XXXXXXXXXXXXXXXXXXXXX
export K6_PROMETHEUS_RW_SERVER_URL=https://aps-workspaces.ap-northeast-1.amazonaws.com/workspaces/ws-XXXXXXXXXXXXXXXXX/api/v1/remote_write
k6 -o experimental-prometheus-rw run k6.js
構築の欄で作成したダッシュボード(19665)を確認します。
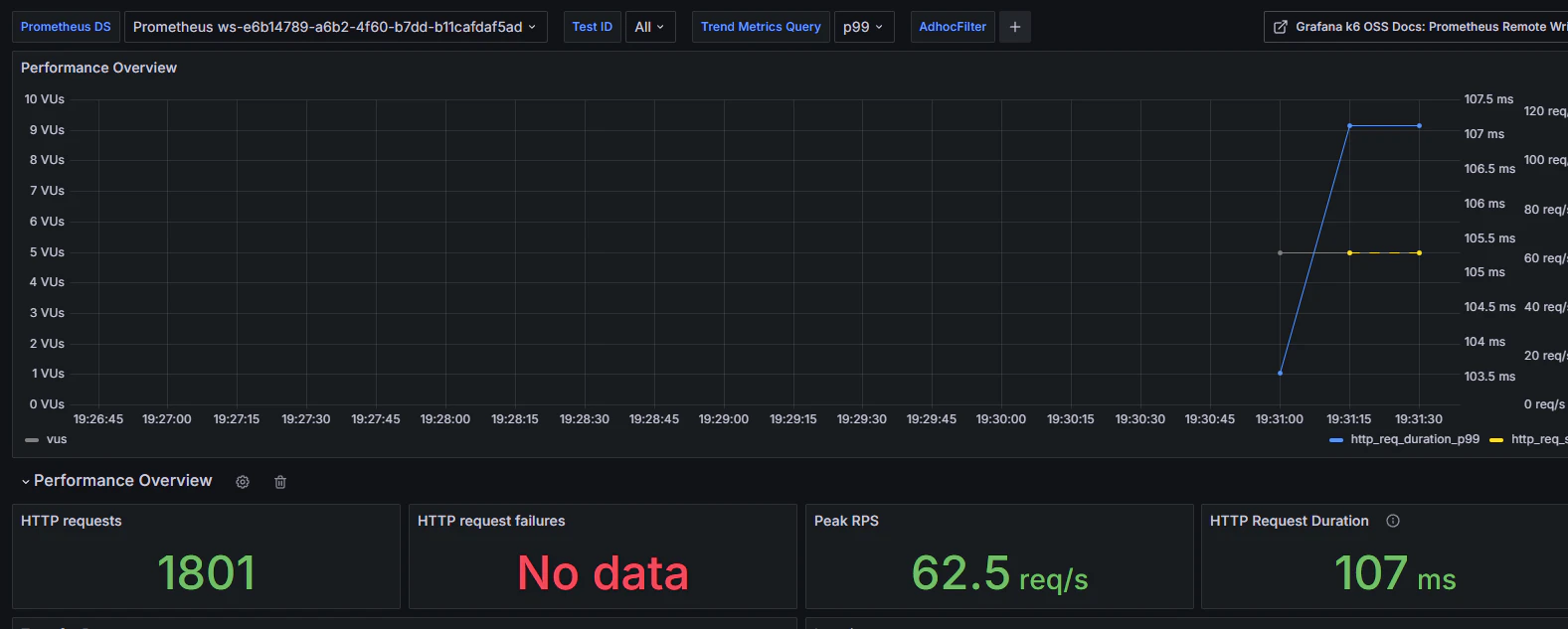
p99のデータ等を見ることができます。
構築完了
ここまでできれば、オブザーバビリティの3本柱のモニタリングが可能になります。
次の章では、実際にこれを使ってモニタリングしつつ、SREとしての活動を実践してみようと思います。
次回:【SRE実践 2/2】SLI/SLO策定・Grafanaダッシュボード活用
本番運用する上での課題
- このオブザーバビリティ環境自体の監視
NLBで常に監視しており、ヘルスチェックNGとなった場合は自動でタスク再生成しますが、
例えば常にヘルスチェックNGでタスク再生成が繰り返し行われている場合などは別途検知が必要なのかもと思いました。
CloudWatchアラームを設定する等、作りこみが必要です。 - 各所に存在するAWS認証情報ハードコーディングの解消
公式ドキュメントを見る限り、ECSタスクロールに適切な権限があればそれを使ってアクセスしてくれるようですが、未検証です。 - exemplarsを使用したtrace_idの出力
トレース→ログ、ログ→トレースはできましたが、exemplarsの設定がうまくいっていないためかメトリクス→トレースの部分が出来ていません。
ローカルに構築した環境ですとうまくいったのですが、要調査です。 - セキュリティ
Managed GrafanaがそのままだとIPを固定することができないため、Tempo, LokiのNLBエンドポイントのインバウンドルールで余計なアクセスを遮断することができません。
VPCに接続するなどして、VPC内の通信にすることで回避できると思いますので、こちらは作りこみが必要です。 - k6の経路
Prometheusに直接投げていますが、OpenTelemetry経由で送信した方が経路的にキレイなので、こちらも作りこみの1つになります。
ハマったところ
- シングル構成のオプション
ECSでさくっと実装。と思い各種config.yamlを公式ドキュメント見ながら設定しておりましたが、
デフォルトがKubernetes前提の設定になっているため、あえて設定しなければならない要素が多く、費用さえ目を瞑ればEKSの方が簡単だったかもしれません。 - 公式ドキュメント読み込み
最初は、ChatGPTで生成されたconfigファイルを使っていましたが、エラー吐くことが多く、
改めて英語の公式ドキュメントをちゃんと読む必要があると思いました。
(そっちのが結果的に早いし理解もできます。日本語自動翻訳→変な箇所があったら原文読む がいいかと)
以上