はじめに
前回の記事はこちらです。
【SRE実践 1/2】OpenTelemetry + Prometheus + Tempo + Loki + Grafanaでオブザーバビリティ環境の構築
前提
Grafana上でトレース、メトリクス、ログがそれぞれTempo、Prometheus、Lokiから取得できていることを前提とします。
SLAについては、模擬的な実践であるためここでは言及しません。
※多くのベンチャーではエンジニアも一丸となってSLAの策定もする必要があるかと思いますが、一旦この場では割愛します。
ゴール
お題となるサンプルWebサイトに対して仮想のユーザを設定し、SLI/SLOを策定します。
SLI/SLOを正確に計測するために、前回の記事で作成したオブザーバビリティ基盤(Grafana)を使用して、ダッシュボードを作成し可視化します。
従来の場合と、オブザーバビリティを導入した場合で障害対応にどのような変化があるか比較します。
SLIとは
https://sre.google/sre-book/service-level-objectives/
サービスの信頼性やパフォーマンスを数値として表す「測定可能な値」です。
例)サービス:Aのレスポンスが0.5秒以内に返却されること
SLOとは
https://sre.google/sre-book/service-level-objectives/
SLI に対して設定する「達成すべき目標値」
例)月間リクエストのうちの99.9%が、SLI(サービス:Aのレスポンスが0.5秒以内に返却されること)を満たしていること
モニタリング対象(お題)
「自分のスキルや趣味での活動をまとめたポートフォリオWebサイト」を対象とします。
こちらにサンプルコードがありますので、以後こちらを前提として進めます。
https://github.com/HTDevelop/sample_web/
※READMEを読んで立ち上げると「http://localhost:80」でアクセス可能です。
仕様
メインページ(/)
自分のスキルを紹介するページです。サンプルなのでペンギンの紹介にしています。
応援メッセージが送れるようになっており、JavaScriptで非同期で取得・送信しています。
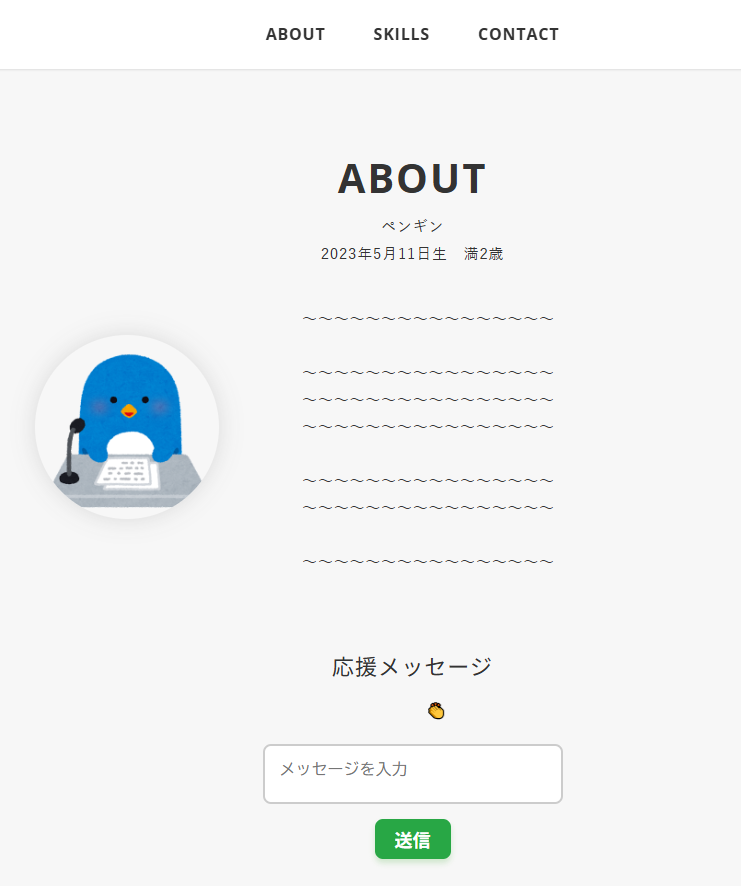
応援メッセージの欄は、このように過去に送信されたメッセージが順番に表示されます。
API(/api/support_msg)
PUT
メッセージを送信するとDynamoDBへレコード保存します。
ただし、今回はサンプルなので実際にDynamoDBへアクセスはせず、何もしない挙動(モック)になっています。
GET
メッセージをDynamoDBから取得し配列で返却します。
ただし、今回はサンプルなので、DynamoDBへアクセスはせず、 ["頑張って!", "スキル凄い!", "👏"]の3件が固定で返却されます。
SLI/SLO策定
ではいよいよ、SLI/SLOの策定をしていきます。
まずはポートフォリオのターゲットから定めていきます。
ポートフォリオのターゲットを決める
適切な目標値を設定するために、このポートフォリオが「誰に対して」、「何を提供したいのか」を決める必要があります。
(ユーザーストーリー的思考です。ユーザストーリーも奥が深いのですが、今回は簡易的に行います。)
-
誰に対して
→ 採用面接官 -
何を提供したいの
→ 自分のスキルを見てもらいたい
(=面接官はこのページを見て応募者のスキルを見たい)
としました。
計測対象の分類をする
今回の登場人物としては、「メインページ」と「API」に分類できます。
どちらも違うドメインを持つサービスと仮定して進めていくこととします。
SLI/SLOを決める
ようやく準備が整いました。それでは考えていきましょう。
メインページのSLI/SLO
Webサイトにおいては、多くのユーザがメインコンテンツが表示されるまでに1秒以上かかると遅いと感じ始めるようです。
今回のユーザは「採用面接官」であり、日々多くの書類やポートフォリオに目を通す必要があるので、
レスポンスタイムが遅かったりエラーになった場合に再度アクセスしてくれる可能性は低そうです。
この機会損失は、ショッピングサイトの機会損失と同等もしくはそれ以上だと考え、我々が日々使用している多くのサイトと同等程度のレスポンス及び信頼性が必要と判断します。
また、レスポンスタイムだけではなく、正常に200レスポンスが返ってくることもユーザ体験としては大切です。
(タイムだけだと、500エラーで即レスポンスが返ってくるパターンでも見かけ上OKになってしまう)
以上を踏まえ、メインページのSLIとSLOを以下のように策定しました。
SLI
「1秒以内に正常(200 OK)レスポンスを返すこと」
※この時測定するのは、あくまでサーバ内で計測できるレスポンスになります。
外部ネットワーク遅延、ブラウザの不具合など外部起因の事象については対象外です。
SLO
「月間で99.95%のリクエストがSLIを満たすこと」
繋げると...
「月間で99.95%のリクエストが1秒以内に正常(200 OK)レスポンスを返すこと」という状態を維持し続けることが求められます。
APIのSLI/SLO
応援メッセージに関しては、例えば表示が遅かったり送信エラーになったとして、そこまで選考に影響はなさそうです。
なぜなら、面接官はこのページを見て応募者のスキルを見たいのであって、応援メッセージを送信したいわけでも見たいわけでもないからです。
※あくまで仮定です。本物のプロダクトの場合はもっと深堀して、多くの関係者間で真剣に協議する必要があります。
また、このAPIが失敗したとしても非同期通信(Ajax)なので、他の要素は正常に表示されるはずです。
しかし、応援メッセージ機能は「非同期処理ができますよ」というアピールにもなるので、
メインページまでとはいかなくても、安定している必要はありそうです。
以上を踏まえ、APIのSLI/SLOを以下のように策定しました。
SLI
「5秒以内に正常(200 OK)レスポンスを返すこと」
※GETとPUTでユーザー価値が違うので、分けてもいい気がしますが、今回はシンプルに1つだけにします。
SLO
「月間で99.00%のリクエストがSLIを満たすこと」
繋げると...
「月間で99.00%のリクエストが5秒以内に正常(200 OK)レスポンスを返すこと」 という状態を維持し続けることが求められます。
補足
実際のプロダクトでは、SREチームだけでSLI/SLOを決めることはありません。
必ずステークホルダ間で協議し、合意する必要があります。
そのため、SREチームには経営層及び開発運用の現場相互の理解が必要となります。
モニタリングをする
SLI/SLOが決まったので、さっそく可視化していきましょう。
全体図
このようになります。
緑枠の箇所は、前回の記事で作成したオブザーバビリティ基盤を表しています。
赤枠の箇所は、今回のお題のサンプルページを表しています

Grafana ダッシュボード設定
前回の記事で作成したGrafana環境を使用します。
事前準備
先ほどのペンギンさんのポートフォリオアプリのapp.pyは実行したままにしておいてください。
また、定期的なアクセスをしないとそもそもメトリクスが生成されないので、以下のように別窓で1秒に一回アクセスするようにしましょう。
watch -n 1 curl http://localhost:80
常に成功するページだと観測する意味がないので、ランダムで失敗するようにしてみましょう。
app.pyを以下のように変更します。
import random
~略~
@app.route("/")
def index():
logging.info("Hello!!")
if random.random() < 0.05: # 0.0〜1.0の間の値、5%未満
raise Exception("test error")
return render_template("index.html")
5パーセントの確率で例外発生して落ちるようにしてみました。
Grafanaダッシュボード作成
Dashboards -> New -> Import を選択

JSONの部分に以下入力(折り畳み)
JSON
{
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": {
"type": "grafana",
"uid": "-- Grafana --"
},
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"id": 3,
"links": [],
"panels": [
{
"datasource": {
"type": "prometheus",
"uid": "beopb6e339r0gd"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "palette-classic"
},
"custom": {
"axisBorderShow": false,
"axisCenteredZero": false,
"axisColorMode": "text",
"axisLabel": "",
"axisPlacement": "auto",
"barAlignment": 0,
"drawStyle": "line",
"fillOpacity": 0,
"gradientMode": "none",
"hideFrom": {
"legend": false,
"tooltip": false,
"viz": false
},
"insertNulls": false,
"lineInterpolation": "linear",
"lineWidth": 1,
"pointSize": 5,
"scaleDistribution": {
"type": "linear"
},
"showPoints": "auto",
"spanNulls": false,
"stacking": {
"group": "A",
"mode": "none"
},
"thresholdsStyle": {
"mode": "off"
}
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 0
},
"id": 1,
"options": {
"legend": {
"calcs": [],
"displayMode": "list",
"placement": "bottom",
"showLegend": true
},
"tooltip": {
"mode": "single",
"sort": "none"
}
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "beopb6e339r0gd"
},
"disableTextWrap": false,
"editorMode": "code",
"exemplar": true,
"expr": "sum(rate(http_server_duration_milliseconds_bucket{le=\"1000\", http_status_code=\"200\", job=\"sample_pr\", http_method=\"GET\", http_target=\"/\"}[1m]))\r\n/\r\nsum(rate(http_server_duration_milliseconds_count{job=\"sample_pr\", http_method=\"GET\", http_target=\"/\"}[1m]))",
"fullMetaSearch": false,
"includeNullMetadata": false,
"instant": false,
"legendFormat": "__auto",
"range": true,
"refId": "A",
"useBackend": false
}
],
"title": "SLI 1m",
"type": "timeseries"
},
{
"datasource": {
"type": "prometheus",
"uid": "beopb6e339r0gd"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "palette-classic"
},
"custom": {
"axisBorderShow": false,
"axisCenteredZero": false,
"axisColorMode": "text",
"axisLabel": "",
"axisPlacement": "auto",
"barAlignment": 0,
"drawStyle": "line",
"fillOpacity": 0,
"gradientMode": "none",
"hideFrom": {
"legend": false,
"tooltip": false,
"viz": false
},
"insertNulls": false,
"lineInterpolation": "linear",
"lineWidth": 1,
"pointSize": 5,
"scaleDistribution": {
"type": "linear"
},
"showPoints": "auto",
"spanNulls": false,
"stacking": {
"group": "A",
"mode": "none"
},
"thresholdsStyle": {
"mode": "off"
}
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 0
},
"id": 4,
"options": {
"legend": {
"calcs": [],
"displayMode": "list",
"placement": "bottom",
"showLegend": true
},
"tooltip": {
"mode": "single",
"sort": "none"
}
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "beopb6e339r0gd"
},
"disableTextWrap": false,
"editorMode": "code",
"exemplar": true,
"expr": "increase(http_server_duration_milliseconds_count{job=\"sample_pr\", http_method=\"GET\", http_target=\"/\"}[1m])",
"fullMetaSearch": false,
"includeNullMetadata": true,
"instant": false,
"legendFormat": "__auto",
"range": true,
"refId": "A",
"useBackend": false
}
],
"title": "Request Count 1m",
"type": "timeseries"
},
{
"datasource": {
"type": "loki",
"uid": "feoppl024kh6od"
},
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 8
},
"id": 3,
"options": {
"dedupStrategy": "none",
"enableLogDetails": true,
"prettifyLogMessage": false,
"showCommonLabels": false,
"showLabels": false,
"showTime": false,
"sortOrder": "Descending",
"wrapLogMessage": false
},
"pluginVersion": "10.4.1",
"targets": [
{
"datasource": {
"type": "loki",
"uid": "feoppl024kh6od"
},
"editorMode": "builder",
"expr": "{service_name=\"sample_pr\"} |= `Exception occurred`",
"queryType": "range",
"refId": "A"
}
],
"title": "Exception Logs",
"type": "logs"
},
{
"datasource": {
"type": "tempo",
"uid": "ceop5cgjbabk0d"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "thresholds"
},
"custom": {
"align": "auto",
"cellOptions": {
"type": "auto"
},
"inspect": false
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 8
},
"id": 2,
"options": {
"cellHeight": "sm",
"footer": {
"countRows": false,
"fields": "",
"reducer": [
"sum"
],
"show": false
},
"showHeader": true
},
"pluginVersion": "10.4.1",
"targets": [
{
"datasource": {
"type": "tempo",
"uid": "ceop5cgjbabk0d"
},
"filters": [
{
"id": "a4efe055",
"operator": "=",
"scope": "span"
},
{
"id": "service-name",
"operator": "=",
"scope": "resource",
"tag": "service.name",
"value": [
"sample_pr"
],
"valueType": "string"
},
{
"id": "span-name",
"operator": "=",
"scope": "span",
"tag": "name",
"value": [
"GET /"
],
"valueType": "string"
},
{
"id": "status",
"operator": "=",
"scope": "intrinsic",
"tag": "status",
"value": "error",
"valueType": "keyword"
}
],
"limit": 20,
"query": "{resource.service.name=\"sample_pr\" && name=\"GET /\" && status=error}",
"queryType": "traceqlSearch",
"refId": "A",
"tableType": "traces"
}
],
"title": "Error Trace",
"type": "table"
}
],
"refresh": "5s",
"schemaVersion": 39,
"tags": [],
"templating": {
"list": []
},
"time": {
"from": "now-15m",
"to": "now"
},
"timepicker": {},
"timezone": "browser",
"title": "Portfolio Monitoring MainPage",
"uid": "cepburu27fw8wc",
"version": 12,
"weekStart": ""
}
Import後、ダッシュボードに「Portfolio Monitoring MainPage」というものが出現します。

クリックすると、以下のような画面になります。
(わかりやすさ重視のためにRangeをLast 15 minutesにしてください)

ひとつずつ説明していきます。
-
左上
これはSLI値は表しています。つまり、表示期間(今回で言えば15分以内)で「1秒以内に200レスポンスした割合」を表しています。
※計算式としては、1秒以内に200レスポンスしたリクエスト数 / 合計リクエスト数 になります。

データポイントにカーソルを合わせてみます。

「0.964」と表示されました。
96.64%は「1秒以内に200レスポンス」しているが、残りの0.36%はそうではない(SLIを満たしていない)ということになります。
さきほどアプリで5%の確率で失敗するようにしたので、おおよそ確率通りですね。
それ以外にもtime.sleep(2)とかを入れたりしてレスポンスを遅延させてもこの値は下がります。
レンジをLast 15 minutes -> Last 30 Daysにしてみます。※1時間ほどwatchコマンドでcurlを叩き続けた後です。

過去30日間のデータになるので、SLO(月間で99.95%のリクエストがSLIを満たすこと)を見ることができます。
Last 30 Daysにしたうえで、この値が0.995(=99.95%)を下回らないうちは、
SLO達成状態なので、ガンガン新規開発してよいということになります。
しかし、値は0.944 = 94.4%ですね、99.95%からは程遠い数値になっています。
これは非常にまずいですね、開発チームは今すぐ手を止めてこの値の改善に取り組むべきです
-
右上
これは補助的な役割です。1分間当たりの成功したリクエスト(緑)とそうでないリクエスト(黄色)を表示しています。
この画像では、大体55件くらいが成功していて、5件くらいが失敗してそうですね。
先ほどのwatchコマンドでのcurlは1秒に1回アクセスするようになっているので、計算もあってそうです。
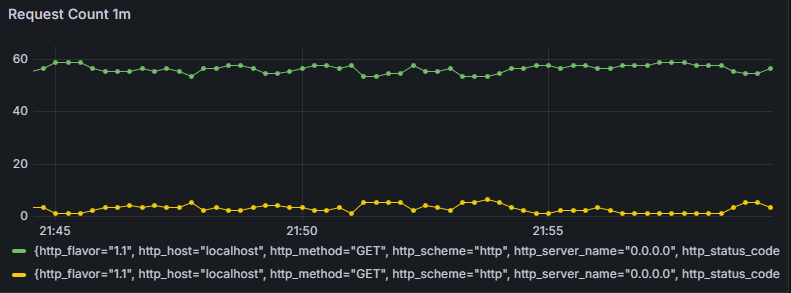
このグラフは何のために用意したかというと、ユーザがこのサービス(≒ページ)にどれだけ関心があるのかを知りたいためです。
仮にSLI/SLOを違反しているサービスが2つあったとします。
サービスAは1000万アクセス、サービスBは100アクセスだとすると、同じ稼働率でもサービスAの方が優先して保守されるべきです。 -
左下
これはアプリケーションから発生するエラーログを表示しています。
先ほどわざと確率でエラーにするようにしましたが、その際「test error」というExceptionが発生するようにしたので、ログに出ていますね。

-
右下
これはエラーだった場合(200以外)の時のトレースを表示しています。

クリックするとトレースの画面に遷移します。

①:赤い丸印になっていますが、これはリクエストが失敗したことを意味します。
②:クリックすると、ログ検索をしてくれます。
③:ログ検索の結果、「test error」が出ていることがわかりました。
メインページはかなり単純な作りなので、恩恵がわかりにくいかもしれませんが、
APIの場合はもう少しわかりやすいので、ご説明いたします。
※ダッシュボードの作成方法は割愛します。
まず、APIのPOSTの処理を見てみましょう。(改めて、ソースはこちら)
@app.route("/api/support_msg", methods=["POST"])
def post_support_msg():
with ob.tracer.start_as_current_span("msg_recive") as span:
data = request.get_json()
msg = data.get("msg")
if msg == "":
return jsonify({"message": "メッセージを入力してください"}), 400
with ob.tracer.start_as_current_span("post_dynamodb") as span:
db = DynamoDB()
db.put_support_msg(msg)
return jsonify({"message": "メッセージありがとうございました!"}), 200
with ob.tracer.start_as_current_span("msg_recive") as span:というのが肝です。
Traceの子として、Spanという属性があります。
このブロックの中で起きることは、すべて"msg_recive"というSpanとなります。
逆に、次のブロックまで処理が進むと、"post_dynamodb"というSpanになります。
Grafana上でどういう表示となるか見てみましょう。
まずは、ブラウザでhttp://localhost:80にアクセスして、応援メッセージを送信してみてください。

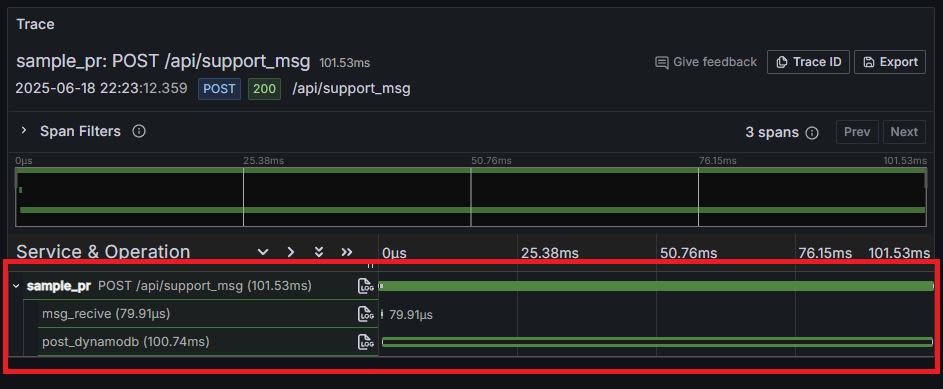
Traceから見ていきます。Explore -> TempoでService Nameのところにsample_prと入れて検索してください。
そうすると、このようにsample_prというTraceの中にmsg_recive, post_dynamodbというSpanが入れ子になったものが検索されます。
これがプログラム中の処理の流れを表現しています。
試しに、post_dynamodbのSpanの中でExceptionを発生させてみます。
with ob.tracer.start_as_current_span("post_dynamodb") as span:
raise Exception("DynamoDBへ接続失敗しました。") # ← 追加
db = DynamoDB()
db.put_support_msg(msg)
return jsonify({"message": "メッセージありがとうございました!"}), 200
もう一度応援メッセージを送信して、再度生成されたTraceを見てみると、以下のようになっています。
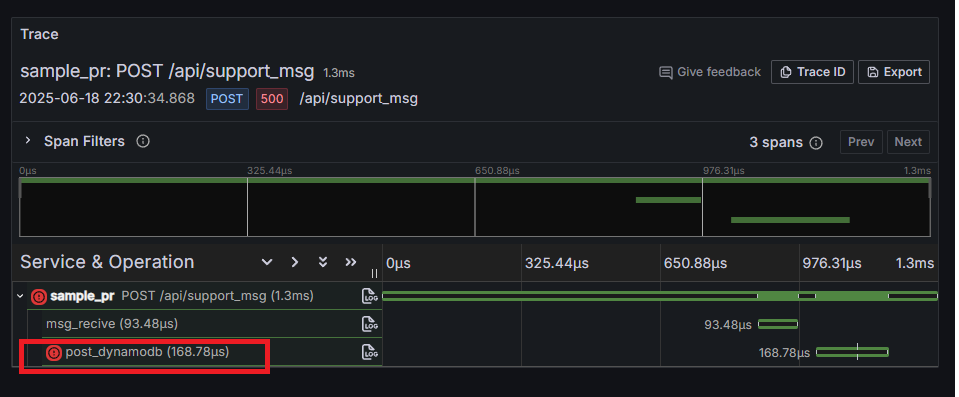
msg_reciveは成功しているのに、post_dynamodbは失敗していますね。
さらに、ログも追ってみます。
DynamoDBへのアクセスに失敗したことがわかりました。

このように、わざわざサーバに入らなくても、どこで何が起きたかが一目でわかります。
【事業目線】SLI/SLOの策定及び可視化をして何がよくなったのか
開発部門の意思決定基準が明確になる
前提として、事業会社における「開発部門」は「コーディング部隊」ではないということを念頭に置いておきます。
事業を背負っているコア部隊ですし、極論ですが意思決定は開発部門が主導するという考え方もあります。
その前提の上で、今回の例ですと99.95%の稼働率を割っているので、開発部門は新規開発をするべきではありません。
稼働率低下の原因を分析し、全員で対処に当たるべきです。
...というのが、今までは「可視化された稼働率」ではなく、多くの優秀なPM,POの野生の勘や経験によって判断されていました。
しかし、ここがロジカルになったことにより、「全員が同じ目線で納得感のある行動ができる」という組織的なアドバンテージも発生します。
ある意味では、「エンジニアリングによる他責思考の排除」とも言えるかもしれません。
また、PM視点で考えれば、新規開発/保守の判断がロジカルになったので、
その分の工数を新機能のアイディアや、障害に対する分析などクリエイティブな活動に時間を費やすことができます。
補足
実際の現場では、「管理職や現場人員の経験による判断」と、「SREによるロジカルな判断」どちらも必要だと感じております。
前者は個人の能力とイコールとも言えますし、決して悪ではないと思います。
むしろそのような考えこそが企業を発展させてきたとも言えます。
機械的なビジネス判断は非常に難しく、本記事は経験による判断を否定するものではありません。
障害発生時に原因特定が迅速に行える(MTTR:平均修復時間の短縮)
私の経験上、従来までの障害の原因特定は以下のようになっていると仮定します。
- 障害発生連絡あり
- Zabbix等で単一メトリクスがエラー(CPU, メモリ高騰)発生していることを確認
- 該当サーバにSSHログインしてログやプロセスを確認して何が起きているか確認
- 関連するサーバにすべてSSHログインして同じ作業を繰り返す
- 調査した情報をかき集め、因果関係を仮説ベースで立てる
- 仮説を元に、コードやインフラのどこが悪いのかを調査
という流れでした。
フロントエンド(例:nginx)やAPサーバのログを個別に確認し、
レスポンスコードやエラー内容からアプリケーション起因かインフラ起因かを判断する必要がありました。
特にコンテナやマイクロサービス構成では、対象のPodやインスタンスを特定するだけでも時間がかかる場合があります。
オブザーバビリティ基盤を活用した場合は以下のようになります。
- 障害発生連絡あり
- Grafanaダッシュボードを確認
- Grafana上でトレース確認(ダッシュボードのリンクから飛ぶ)
- ログ確認(とれーのリンクから飛ぶ)
- どのシステムで、何が失敗しているのかを確認
→ 今回で言えば、POSTリクエストにおいてDynamoDBへの接続に失敗していることがわかった。
オブザーバビリティの本にも書かれていることですが、
従来までの障害対応はそのシステムに長く関わっている人間が迅速な対応をすることができました。
しかし、それでは属人化が加速する一方ですし、いつまでも達人頼りになってしまいます。
本来は、歴に関わらず「そのシステムに一番関心のある人」が迅速な対応できることが望ましいと思います。
さいごに
いかがだったでしょうか?
今回はSLI/SLOの策定・可視化についてお話ししました。
SREの活動はもっと広く、トイルの削減やエラーバジェットの管理等ありますが、そちらはまたどこかのタイミングで記事にしたいと思います。
尚すべてのシステムにトレース/メトリクス/ログを送信する仕組みを入れるのも現実問題として大変です。
売上に直結する作業でもないため、理解を得るのは困難を極めると思います。
SRE本原典にも書いている通り、最初から完璧を求めず、少しずつ取り組んでいくことが重要です。
(実際に私はプロダクトオーナーとして、週に5~10%の時間をこのような取り組みに充てる活動を推進しておりました。)
また、あくまでサンプルなので、本番運用においてはもっと考慮しなければならないことはたくさんあります。
SREの言葉の定義・範囲も組織や業務によって様々ですので、是非本記事を参考にしていただき、自分なりのスタイルを確立して頂ければ幸いです。
(おまけ)本番運用する上での課題
参考までに、本番運用するうえで必要と思われる作業を列挙します。
※前回の記事の課題も併せてご覧ください。
- アラートマネージャーによる通知
今回は紹介しませんでしたが、SLOの違反もしくは違反予兆を検知した際に、
アラートマネージャーにより何かしらの(メールやSlack)の通知が必要です。
場合によっては、緊急のケースにて関係者に電話通知をする必要もあるかと思います。
AmazonConnectや、twillioなどの外部サービスに連携も要検討です。 - 監視項目の充実化
今回はFlaskアプリのみの監視となっていますが、実際の運用ではAWSであれば最低でもこのようにALB + ECS Fargateの構成になるかと思います。

この場合、ALB -> ECSのレイテンシや、ALBが返している502レスポンスなども計測する必要があり、
データソースとしてCloudWatchを追加した方がよさそうです。
また、DynamoDBへのPut/Fetchも発生するので、DynamoDB側のレスポンスや負荷も見る必要があります。
このように、システムが複雑になるにつれ、見る項目は多くなっていきますが、
なるべくダッシュボードはシンプルに保ち、リンクと辿っていくと答えにたどり着くような構成にすることがベストです。
(私も模索中です。) - インフラ構成をVPC内に閉じ込める
前回の記事で構築した環境ですが、
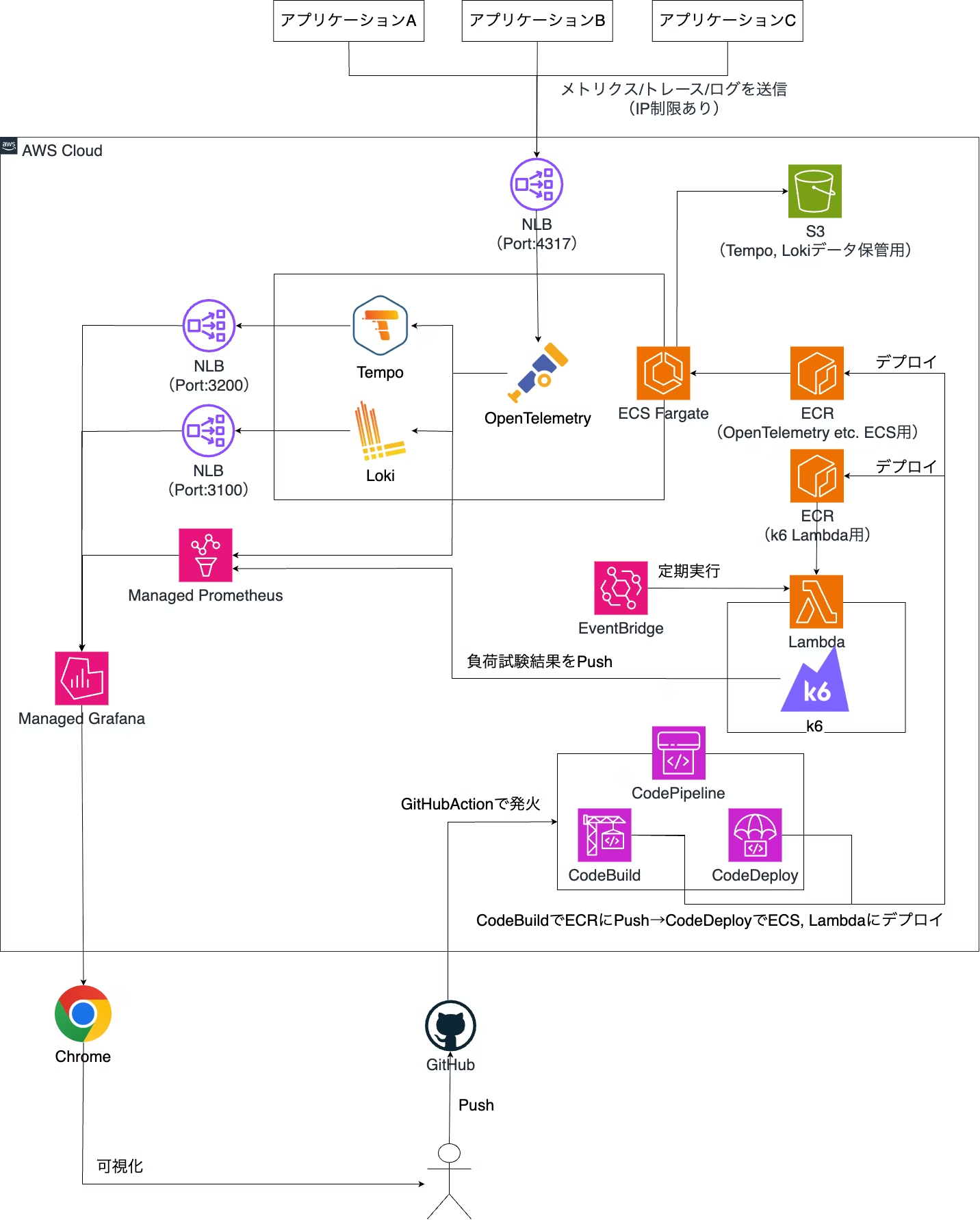
実はセキュリティが甘すぎます。
NLBに関しては4317 -> OpenTelemetryは外部IP制限を行えばよいですが、
3200 -> Tempo, 3100 -> Lokiに関してはManaged GrafanaがグローバルかつIP固定できない仕様のため、
NLBもグローバルに公開せざるを得ません。
幸いにも、Managed GrafanaはVPC接続ができますので、そちらを行ったうえで、プライベートNLBにしてVPC内通信するなど工夫が必要です。
もっと言えば、4317 -> OpenTelemetryはVPN経由にした方が良さそうですね。
AWSのVPNは1本貼ると内部的には2本冗長構成になりますし、自動でフェイルオーバーしてくれます。 - データが来ない場合どうするか
監視対象がダウンしている or OpenTelemetry周りの何かがダウンしている場合はデータが来ないです。
その場合、データが来なければアラートにするようにしておいた方が良さそうですね。
(余談)
2~3週間くらいこの環境で色々試していたら、割とかかっちゃいました。

でも楽しかったのでよしとします!!!!
以上