はじめに
先日、小泉進次郎氏のこの発言に目が留まりました。
「将来的な国会のあり方をイメージすると、何度も同じような質問が繰り返される時は人工知能ではじいてほしいな、と。そういう人工知能の活用とか、未来の国会のあり方、やれることはいっぱいある」(自民・小泉氏「同じような質問、将来はAIではじいて」)
ということで、本当にそんなことが出来るのか、Doc2Vecの勉強も兼ねつつ、ある程度データが入手しやすい「質問主意書」を使って実行してみました。BERT(Bidirectional Encoder Representations from Transformers)やELMo(Embeddings from Language Models)等が出てきている昨今にDoc2Vec?という方もいるかと思いますが、gensimでパッケージ化されていて、手軽に使えるなど、ちょっとした分析をやるにはまだまだ現役なのではと思っています。
質問主意書
国会で質問というと、議員が大臣などに口頭で行っている姿を思い浮かべると思います。法案や政策についての疑問点を内閣に問いただすのは、議員の重要な仕事ですが、こうした質問は文書でも行うことができます。それが質問主意書です。
少数政党を中心に、国会での質問を行う時間は限られています。そんな時によく活用されるのがこの質問主意書です。過去には薬害エイズ事件などが明るみになったこともある国会議員にとっては大事な追求方法のひとつになっています。
ただし、質問主意書を受け取った内閣は、原則として7日以内に文書で回答しなければなりませんが、このときの回答は、閣議を通さなければならないことになっています。閣議を経るということもあって、質問主意書に対する回答は、政府の公式見解として残ることになるため、現場にとっては重たい作業になっているようです。
霞が関の嫌われ者 “質問主意書”って何?
時事用語のABC

今回対象とした期間での質問主意書の提出者をワードクラウドにしてみました。鈴木宗男の圧倒的存在感…。
Doc2Vec
Docment-to-Vectorのことで、ドキュメント=文書の特徴量をベクトルで表すものです。Doc2VecはWord2Vecを開発したTomas Mikilov氏によって提案されたもので、学習方法には下記の2手法が提案されています。
- Distributed Memory Model of Paragraph Vector (PV-DM)
- Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
PV-DMでは、文書ベクトルと連続する単語ベクトルから、直後の単語を予測するように文書ベクトルを学習します。
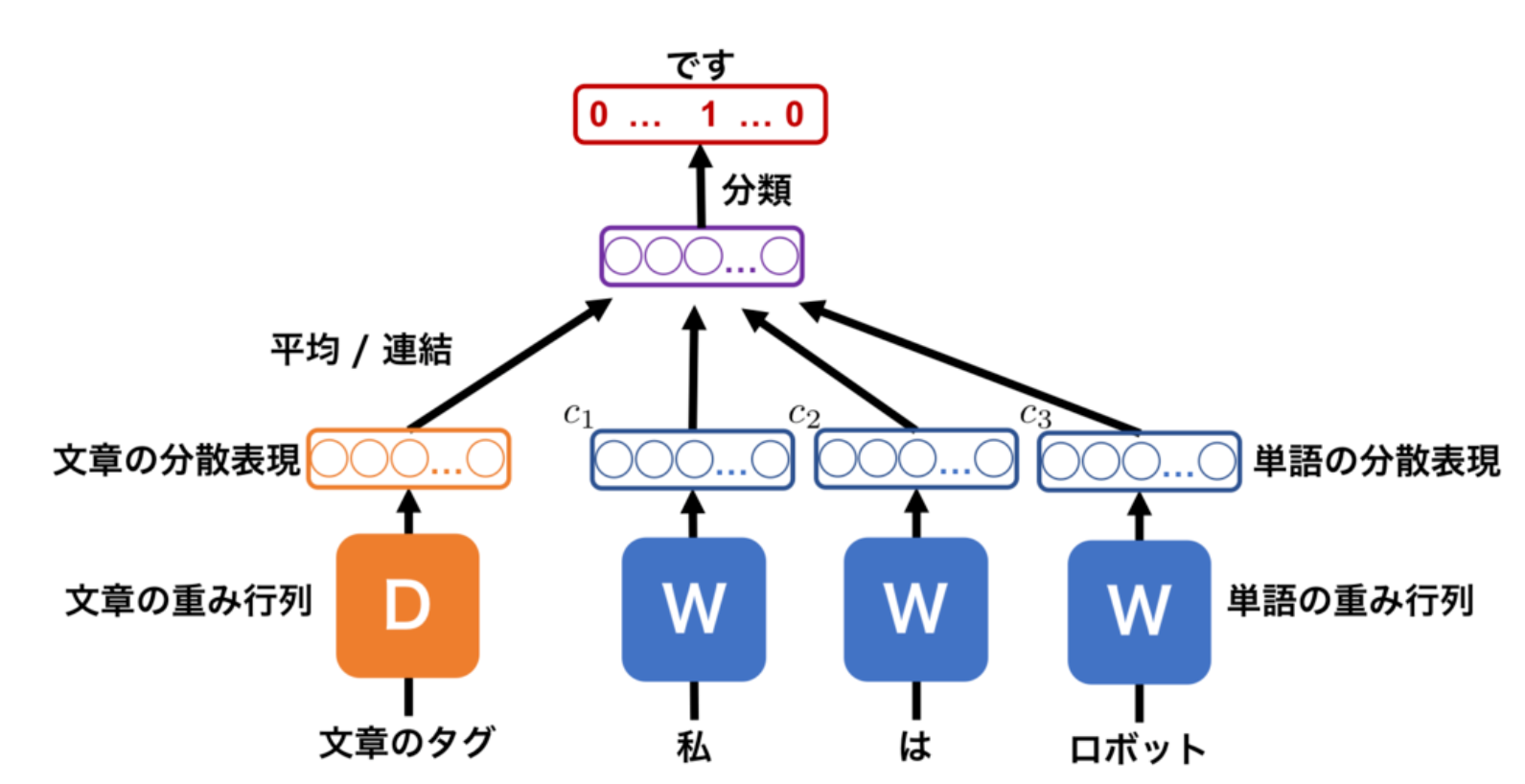
PV-DBOWでは、語順を無視した上で、文章に含まれる単語を当てるように文章ベクトルを学習します。この手法での文の分散表現化は、PV-DMよりも簡単ですが、精度は劣ると紹介されています。
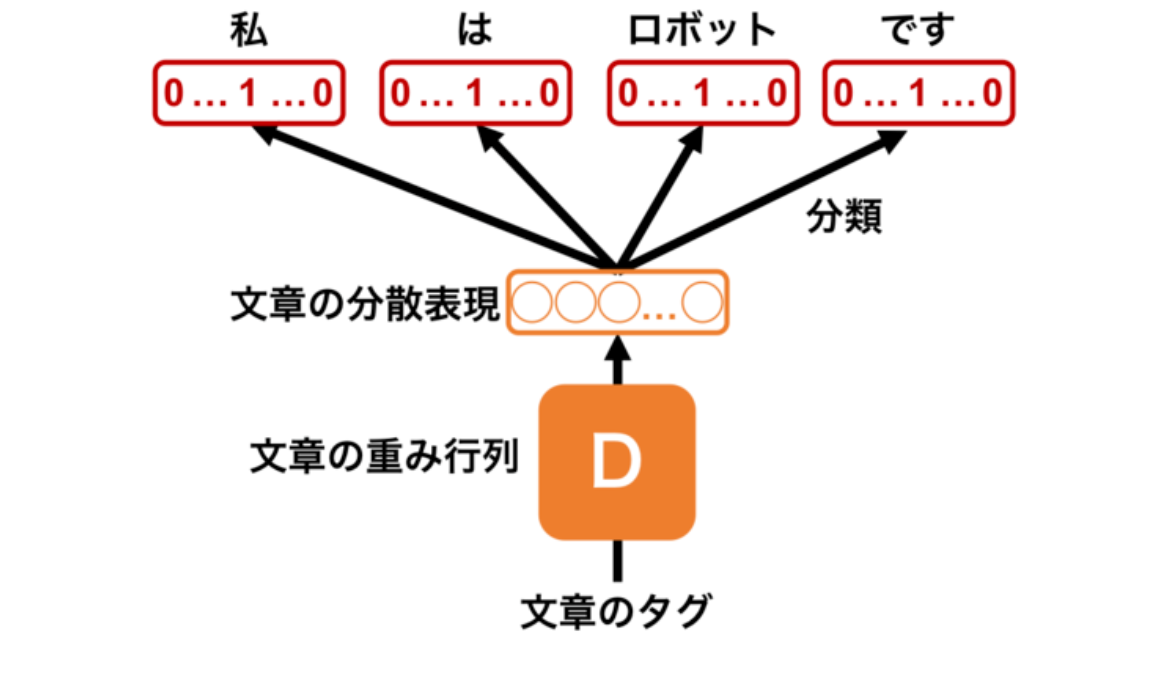
自然言語処理技術の活用法 ーDoc2VecとDANを使って論文の質を予測してみた!ーより
データ
今回用いるのはクローリング&スクレイピングをして入手した衆議院と参議院の質問主意書です。本当は第1回国会からの全データを抽出する気でしたが、心が途中で折れたこともあり、平成と令和に絞って質問主意書のデータを抽出しました。対象となる国会は第114回から第200回になります。
なお、今回はDoc2Vecがメインなので、クローリング&スクレイピングのコードは省略し、結果だけを掲載します。
また、今回の記事では第114回国会から第199回国会までを使ってモデリングし、第200回国会での質問主意書の類似度を推定します。
データの中身を見る前にまずはライブラリのインポートから。今回は日本語を用いた作図をしているので、それ用のフォントであるNotoSansMonoCJKjp-Regular.otfを使用してます。豆腐よおさらば。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
from matplotlib.font_manager import FontProperties
font_path = "/mnt/c/u_home/font/NotoSansMonoCJKjp-Regular.otf"
font_prop = FontProperties(fname=font_path)
さて、今回のデータはこのようになっています。上から、第114回~第199回国会までの衆参両院の質問主意書、第200回国会の衆参両院の質問主意書、そして、国会が開会している期間の一覧です(ここのページから入手)。
data = pd.read_excel("data.xlsx")
data_200 = pd.read_excel("data_200.xlsx")
data_diet_open = pd.read_excel("data_diet_open.xlsx")
それぞれ日付ごとにソートし、上位2つと、下位2つを表示。。
data.sort_values(by=['date']).iloc[np.r_[0:2, -2:0]]
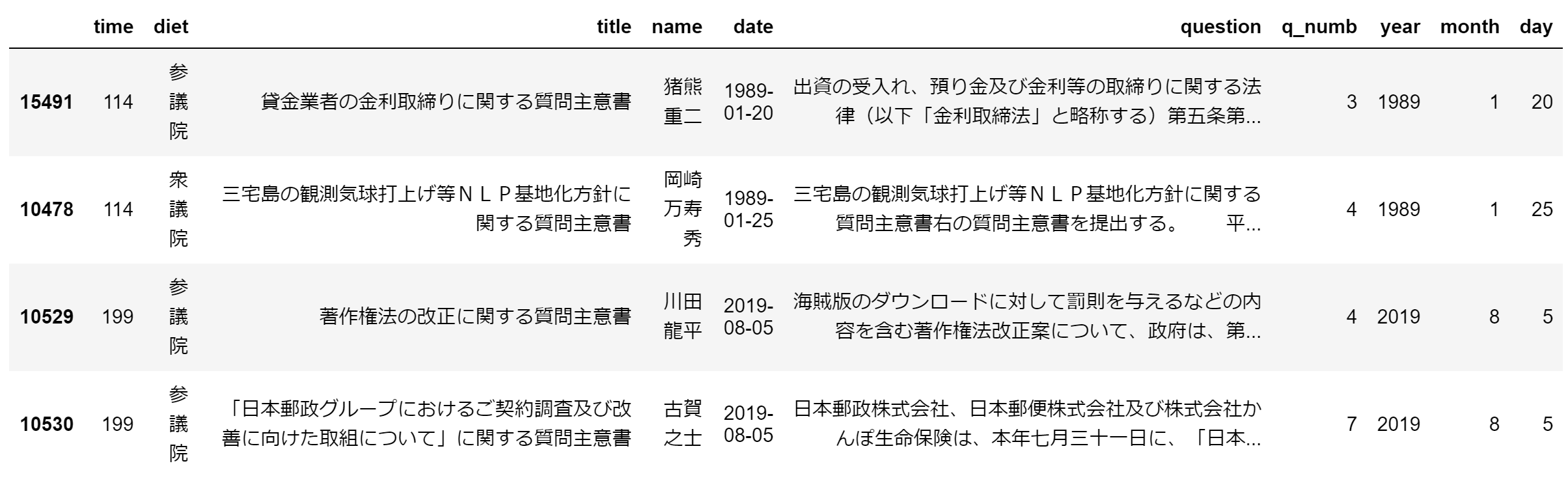
補足すると、
time 質問主意書が提出された国会の会期
diet 衆議院か参議院
title 質問主意書のタイトル
name 質問主意書の提出者
date 質問主意書が提出された日
question 質問主意書の本文
q_numb 質問主意書の質問数(詳細は後述)
year 質問主意書が提出された年
month 質問主意書が提出された月
day 質問主意書が提出された日
今回使用するデータの中で最も古いものは猪熊重二議員が1989-01-20に提出した「貸金業者の金利取締りに関する質問主意書」で、最も新しいのは古賀之士議員が2019-08-05に提出した「「日本郵政グループにおけるご契約調査及び改善に向けた取組について」に関する質問主意書」になります。なお、データ数は15,515です。このデータ数については、少なすぎないという感じでしょうか。
data.shape
(15515, 10)
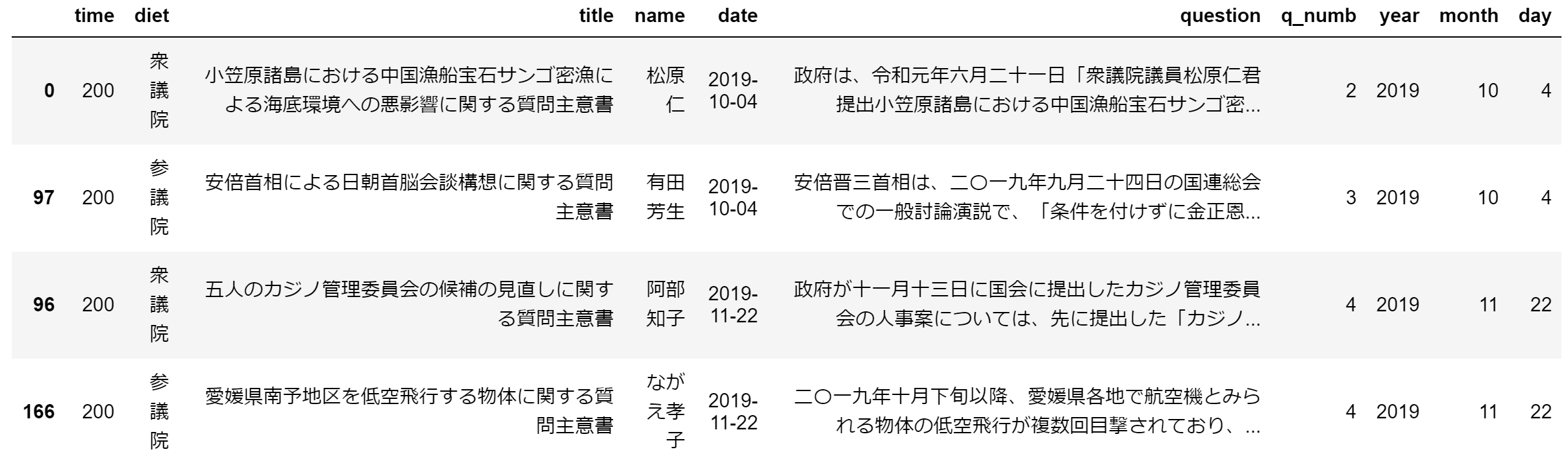
また、第200回国会のデータも同様です。データ数は167です。
data_200.sort_values(by=['date']).iloc[np.r_[0:2, -2:0]]
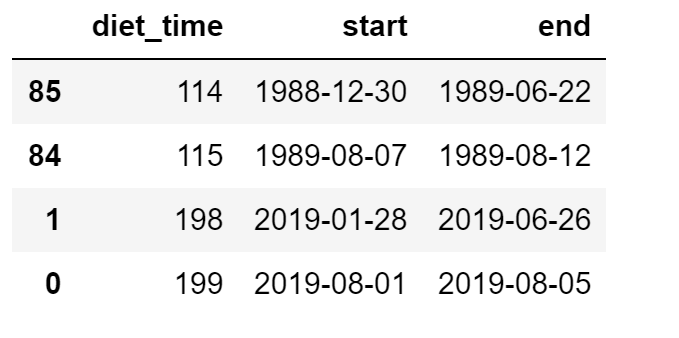
最後に国会会期一覧
EDA
Doc2Vecに行く前に、色々とデータを探索
年・月・日ごとの主意書数
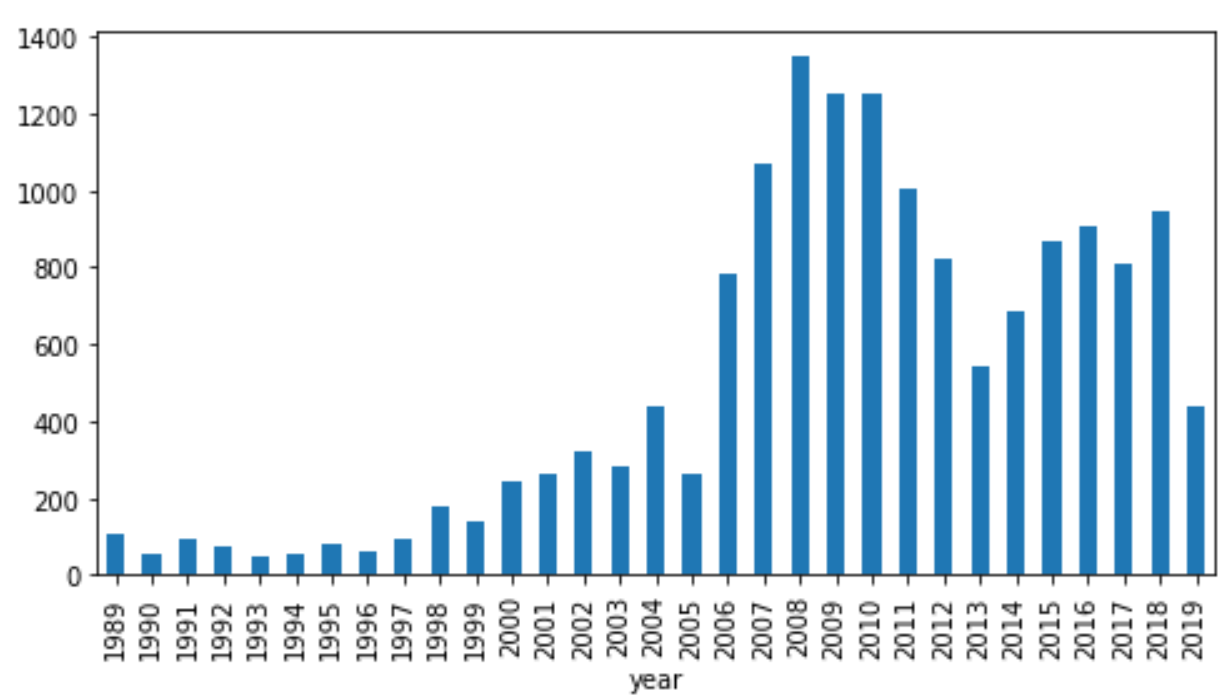
まずは年ごとのグラフ。2006年あたりから急激に増えています。
rcParams['figure.figsize'] = 8,4
data.groupby('year').size().plot.bar()
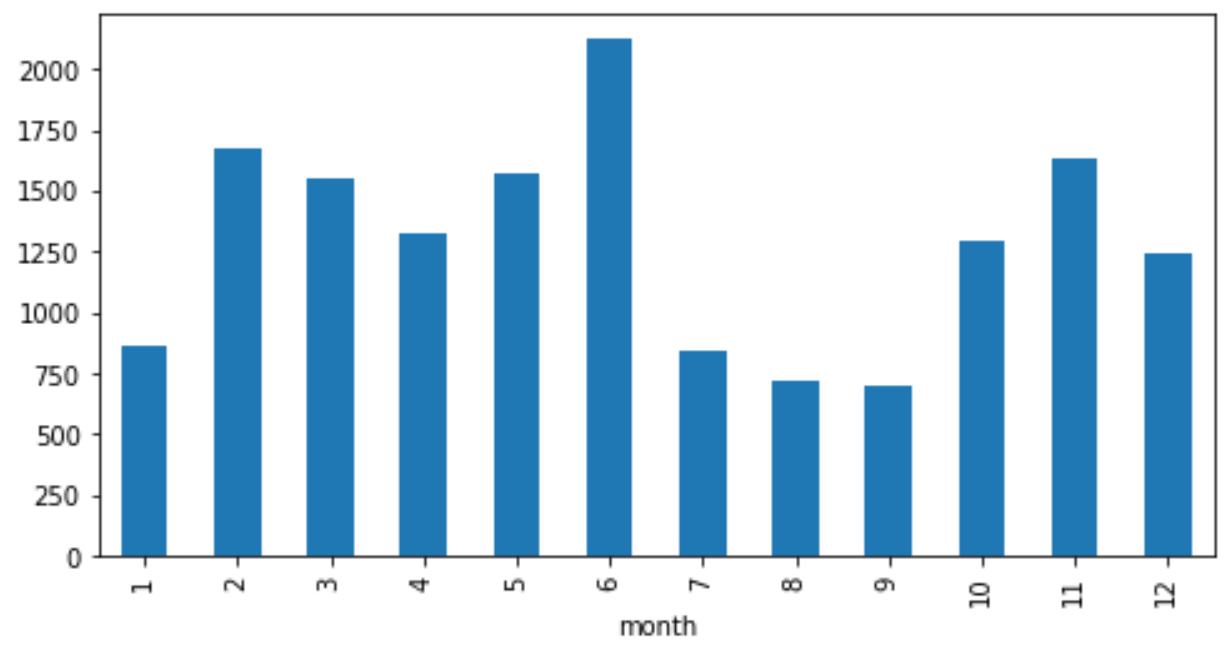
 次に月ごと。6月多し。7月~9月は少なし。
次に月ごと。6月多し。7月~9月は少なし。
rcParams['figure.figsize'] = 8,4
data.groupby('year').size().plot.bar()
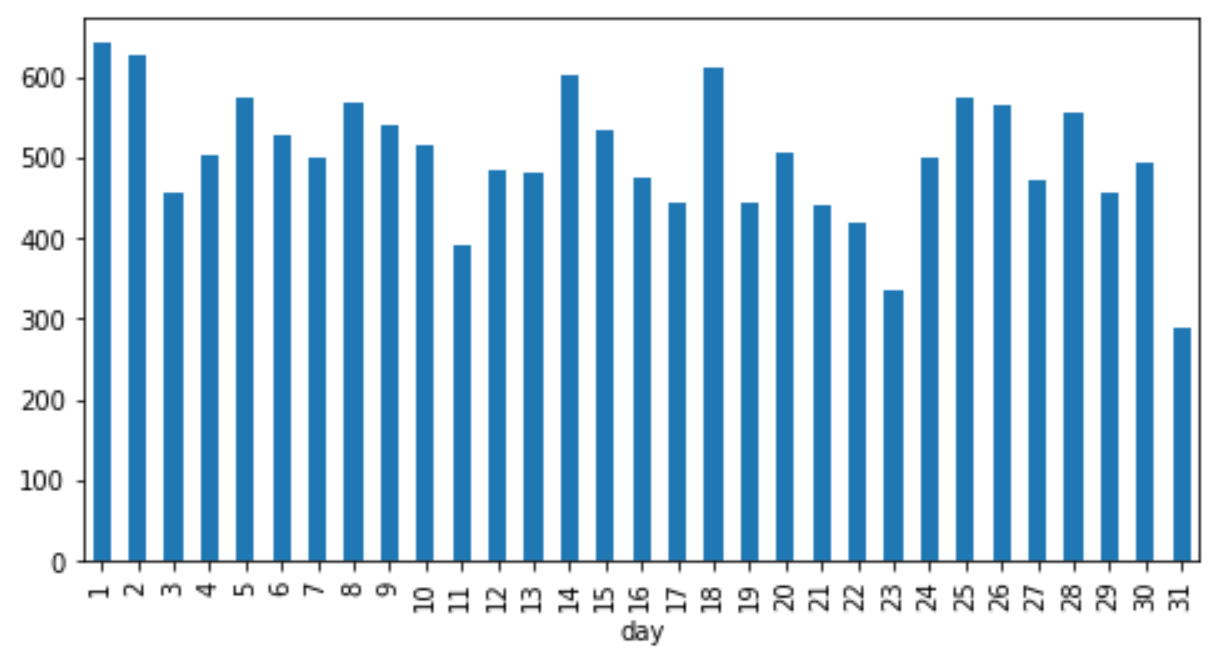
最後に日ごと。31日はそもそも少ないので、主意書数も少ないのは分かるが、それ以外は傾向なし。
rcParams['figure.figsize'] = 8,4
data.groupby('day').size().plot.bar()
日々データに変換
一日いくつの主意書が提出されたのかを把握するために、日付ごとにソートして件数を数えつつ、提出がない日をゼロにして、第114回国会の初日(1988年12月30日)から第199回国会の最終日(2019年8月5日)までの時系列データを作っていきたいと思います。
def convert_to_daily(data):
time_index = pd.DataFrame(index=pd.date_range('19881230','20190805'))
# 対象となる期間の初日と最終日をセット
doc_num_daily = pd.DataFrame(data.groupby('date').size(), columns=['doc_num'])
# 日付ごとに主意書数をカウントし、コラム名を'doc_num'に
data_daily = pd.concat([time_index, doc_num_daily], axis=1) #マージ
data_daily['doc_num'] = data_daily['doc_num'].fillna(0) #欠損値をゼロに
data_daily = data_daily.iloc[:,0] #pandas seriesに
return data_daily
data_daily = convert_to_daily(data) #実行
さらに、国会期間中の場合は、背景色をグレーにする用の関数を作成。
def plot_daily_data(data_daily, start_day, end_day):
subdata = data_diet_open[(data_diet_open['end'] >= start_day) & (data_diet_open['end'] <= end_day)].sort_values(by='diet_time').reset_index(drop=True)
plt.plot(data_daily.loc[start_day:end_day])
plt.title("Number of docments between " + start_day + " and " + end_day)
for i in range(subdata.shape[0]):
plt.axvspan(subdata.start[i],subdata.end[i], color=sns.xkcd_rgb['grey'], alpha=0.5)
ということでプロット。
rcParams['figure.figsize'] = 20,5
start_day = "1988-12-30"; end_day = "2019-12-31"
plot_daily_data(data_daily, start_day, end_day)
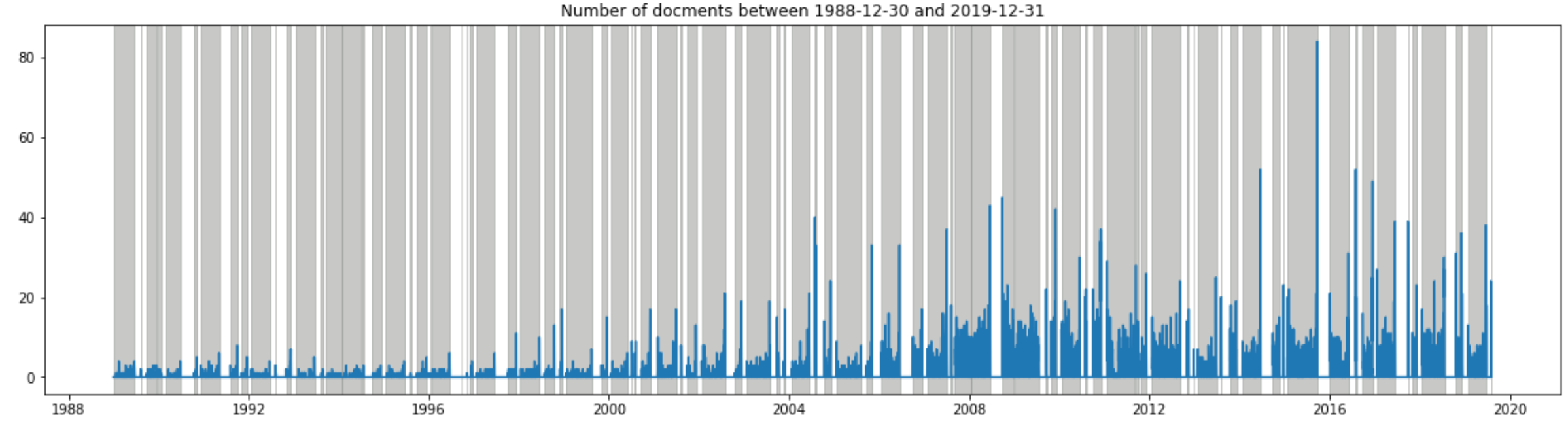
なんとなく右肩上がりで、2004年から増え続けているっぽいのは分かるが見づらい…ので、3分割してみました。
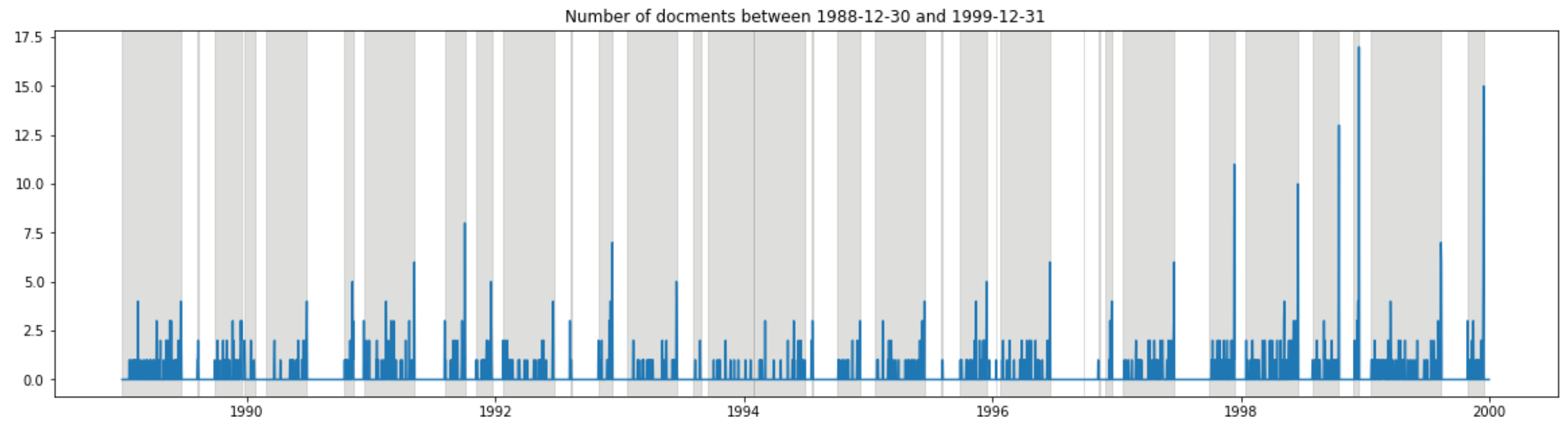
start_day = "1988-12-30"; end_day = "1999-12-31"
plot_daily_data(data_daily, start_day, end_day)
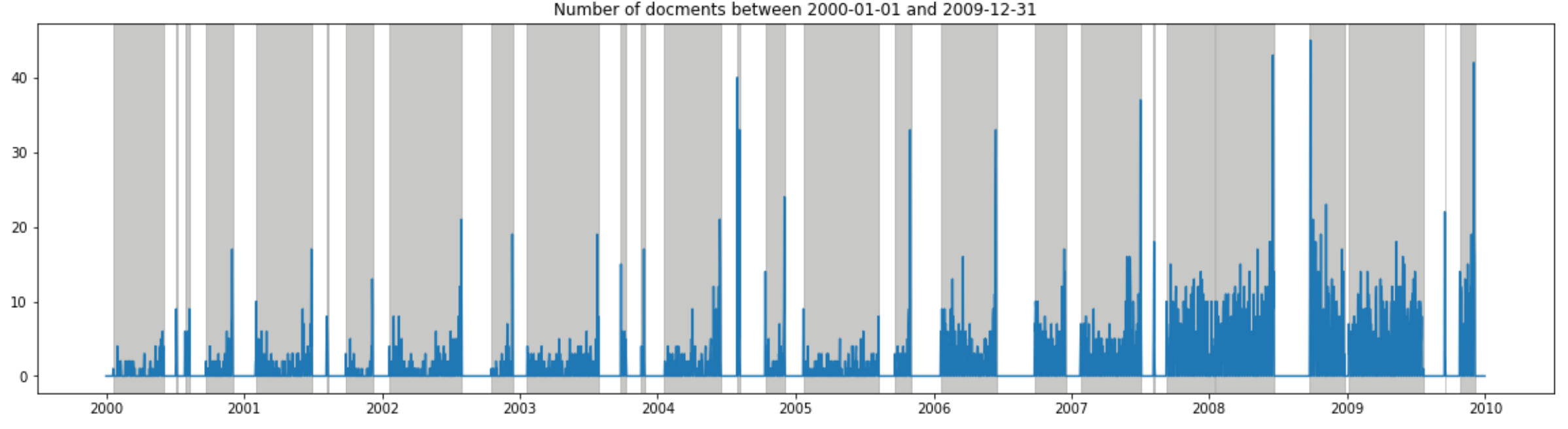
start_day = "2000-01-01"; end_day = "2009-12-31"
plot_daily_data(data_daily, start_day, end_day)
start_day = "2010-01-01"; end_day = "2019-12-31"
plot_daily_data(data_daily, start_day, end_day)
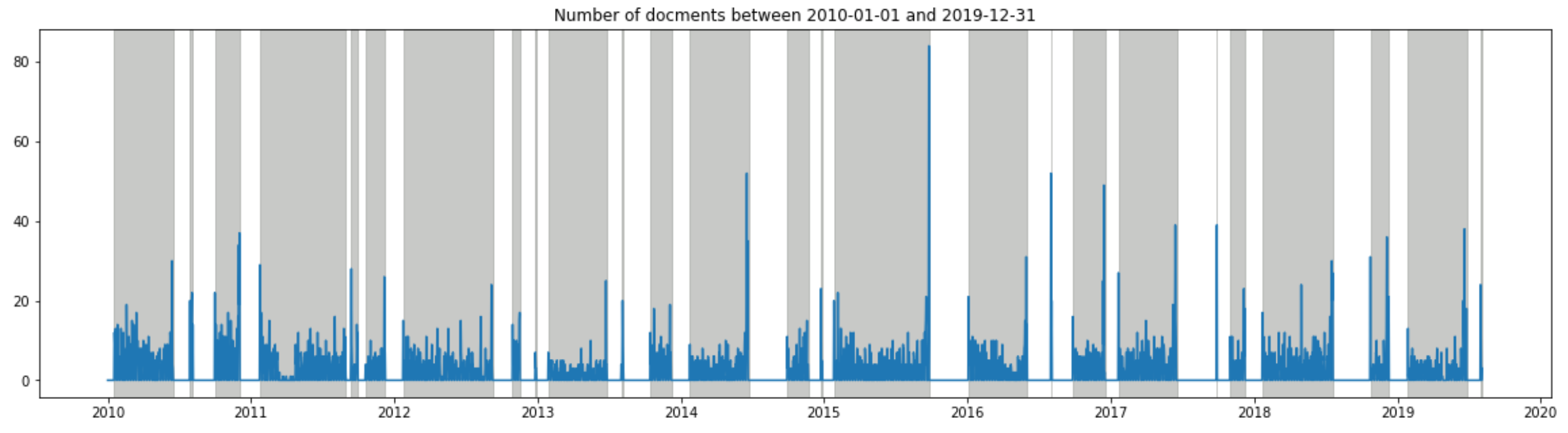
質問主意書は国会会期中のみ提出可能ということで、毎回、国会の会期末(=グレーの一番右端)になると提出数が増えるということが良く分かります。それにしても、3分割してグラフを出しましたが、左側のスケールが段々増えているのが、昨今、質問主意書がよく利用されているのを如実に表しています…。
質問主意書の提出数をヒストグラムに。綺麗な右肩下がりのグラフになっています。
plt.hist(data_daily[data_daily > 0], bins=50)
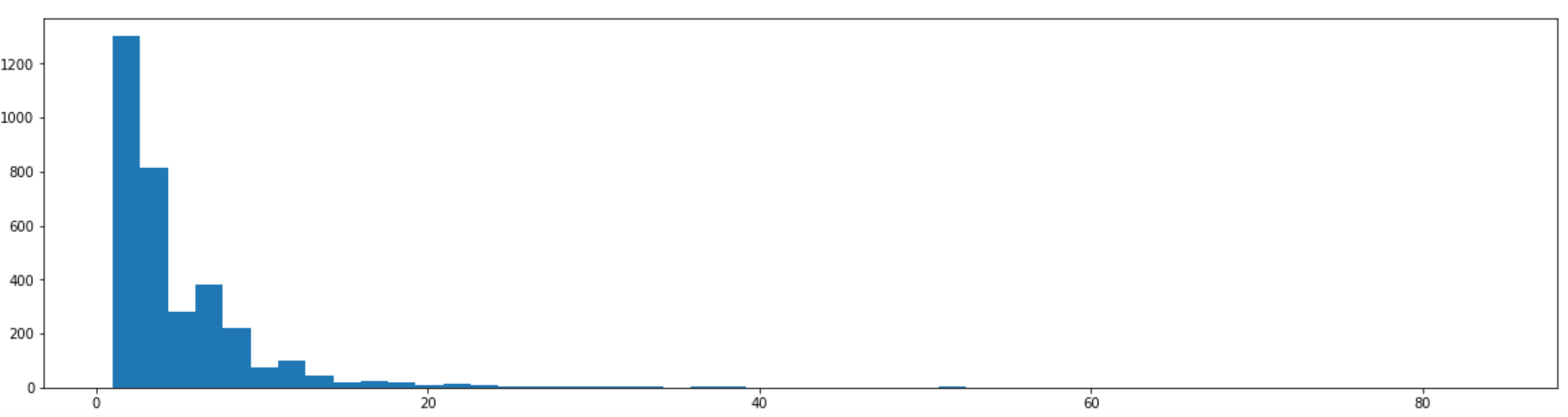
最大値は2015年9月25日の84!この日に何があったかは後述…。
data_daily.max()
doc_num 84.0
dtype: float64
data.groupby('date').size().idxmax()
Timestamp('2015-09-25 00:00:00')
名前ごと
どの国会議員が質問主意書をよく提出しているのかを見ていきたいと思います。まずはデータに載っている国会議員の数は、789です。このデータでは連名を「赤嶺政賢高橋千鶴子吉井英勝」と雑に扱っている点にはご留意ください。
len(data.name.unique())
789
さて、気になるトップ30人はこちらです!
subdata = data.groupby('name').filter(lambda x: len(x) >= 100)
len(subdata.name.unique())
30 #上位30人までを抽出
plot_value = subdata.groupby('name').size().sort_values(ascending=False)
plot_index = subdata.groupby('name').size().sort_values(ascending=False).index
rcParams['figure.figsize'] = 20,5
plt.bar(plot_index, plot_value)
plt.xticks(plot_index, rotation=90, fontproperties=font_prop)
for i, v in enumerate(plot_value):
plt.text(i - 0.5, v + 5, str(v), color='blue')
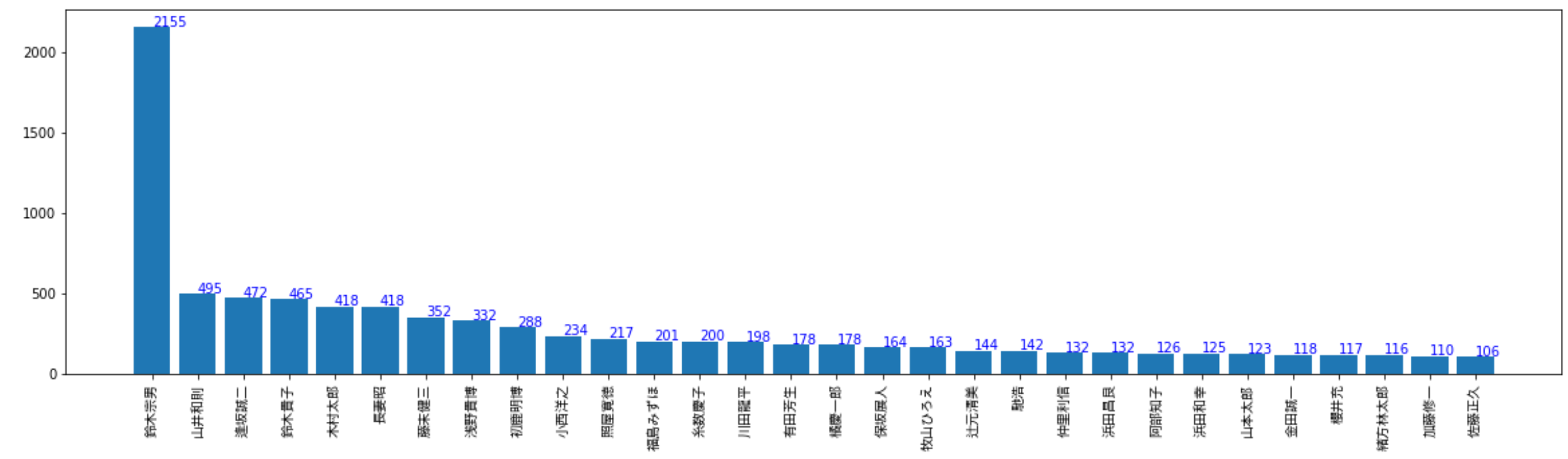
2位以下を大きく引き離してトップになったのは鈴木宗男氏。その数2155…。Wikipediaにもばっちり記載があります。
”提出の多い例として、「質問主意書のキング」とも呼ばれ野党時代に1900の質問主意書を提出した新党大地の鈴木宗男が挙げられる。宗男は2010年(平成22年)に失職となり国会を去ったが、その後は同じ新党大地で後継者となった浅野貴博に質問主意書の提出を継続させた。さらに2013年(平成25年)6月に宗男の長女の鈴木貴子が繰り上げ当選すると、以降は貴子を通じて質問主意書による攻勢をかけている。”
鈴木宗男
質問主意書の役割が大きく変わったのは鈴木宗男氏の存在が大きいとされています。NHKの記事でも触れられています。ということで、鈴木宗男氏の質問主意書の数を見ていきたいと思います。
muneo_daily = convert_to_daily(data[data['name']=="鈴木宗男"].reset_index(drop=True))
rcParams['figure.figsize'] = 20,5
plt.plot(data_daily)
plt.plot(muneo_daily)
for i in range(data_diet_open.shape[0]):
plt.axvspan(data_diet_open.start[i],data_diet_open.end[i], color=sns.xkcd_rgb['grey'], alpha=0.4)
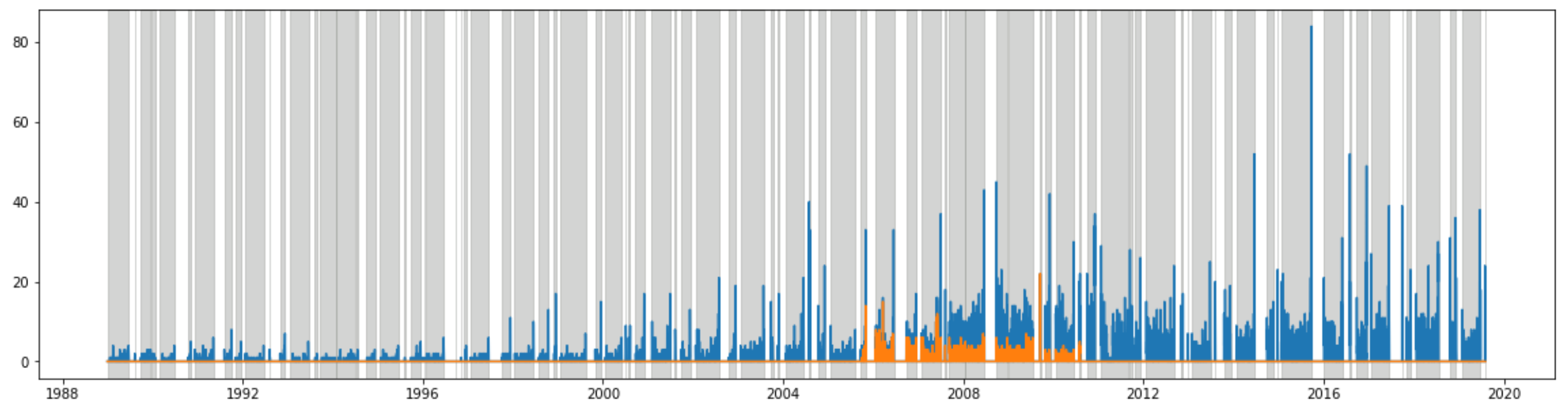 オレンジ色が鈴木宗男氏の質問主意書の提出数です。鈴木宗男氏が質問主意書を提出していた時期を拡大してみると、
オレンジ色が鈴木宗男氏の質問主意書の提出数です。鈴木宗男氏が質問主意書を提出していた時期を拡大してみると、
start_day = "2005-10-03"; end_day = "2010-08-04"
subdata = data_diet_open[(data_diet_open['end'] >= start_day) & (data_diet_open['end'] <= end_day)].sort_values(by='diet_time').reset_index(drop=True)
plt.plot(data_daily.loc[start_day:end_day])
plt.plot(muneo_daily.loc[start_day:end_day])
plt.title("Number of docments between " + start_day + " and " + end_day)
for i in range(subdata.shape[0]):
plt.axvspan(subdata.start[i],subdata.end[i], color=sns.xkcd_rgb['grey'], alpha=0.5)
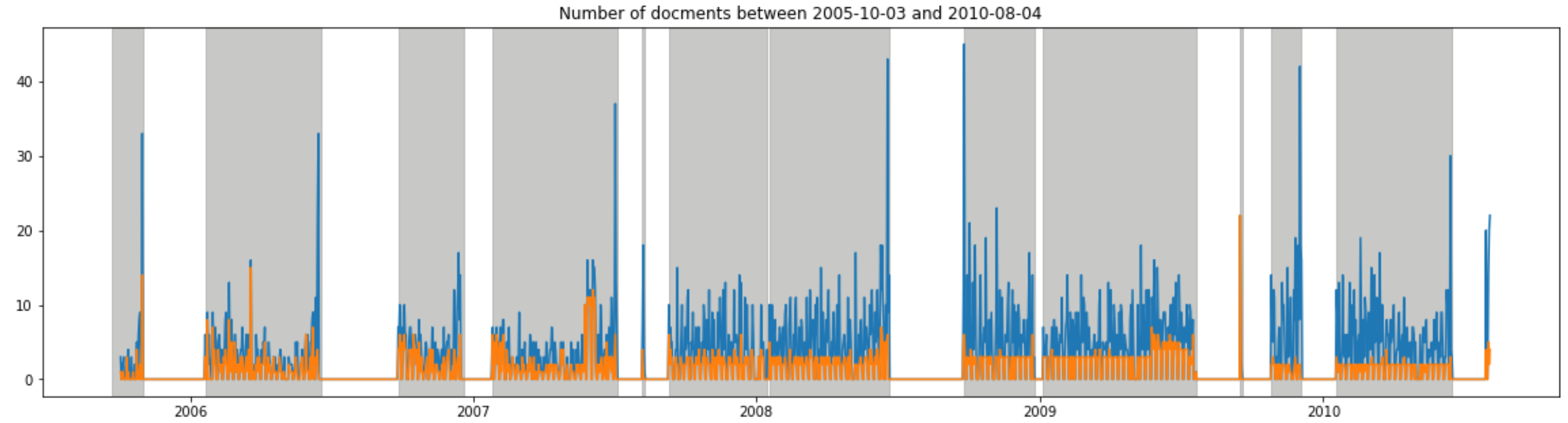 2006年から2007年にかけては、提出された質問主意書のほとんどが鈴木宗男氏になっているのが分かります。
2006年から2007年にかけては、提出された質問主意書のほとんどが鈴木宗男氏になっているのが分かります。
日付と提出者ごと
今度は一日あたりの提出が多い議員を探していきたいと思います。
subdata = data.groupby(['name','date']).filter(lambda x: len(x) >= 15)
pd.DataFrame(subdata.groupby(['name','date']).size().sort_values(ascending=False))
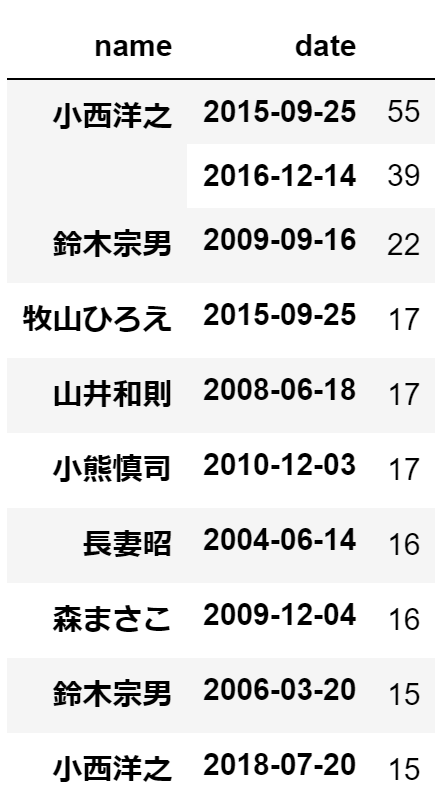
トップは2015年9月25日に55本提出した小西洋之氏でした。さすがは「国会のクイズ王」の異名を持つだけのことはありますね。ちなみに小西洋之氏のこの日提出した質問主意書のタイトルはこちら。

似たようなタイトルが続いていますが、特に39と40は何とかならなかったのでしょうか…。これだけ質問主意書のコストが叫ばれているのに…、間違い探しのよう…。
39.日米同盟に基づく在日米軍の海軍基地の米国における価値に関する質問主意書
40.日米同盟に基づく在日米軍の空軍基地の米国における価値に関する質問主意書
こちらに関しては、こんな記事も書かれていました。
「今回、55件という記録的な数を提出した小西議員の質問を見てみると、同じようなテーマでわずか1行半の質問を複数回に分けて質問しているケースがありました。主意書は同じテーマであれば箇条書きにして複数の質問をすることができます。内容も文言の解釈を問うものが多く、かつて予算委員会で安倍総理大臣から「クイズのような質問は生産的ではない」と言われた場面を思い出す、大局観に欠けた質問が並んでいる印象です。」
主意書の質問数
データのコラム名の解説のところでq_numbは後述と書きましたが、今回は質問主意書の数だけではなく、質問主意書に記載のある質問数もスクレイピングの際に抽出しています。例えば、こちらの主意書では、三つの質問を問うています。

漢数字部分が個別の質問になっているのです。ただ単に質問主意書の数ではなく、質問主意書の中の質問数を見た方が実際のコストを図れるのではないかというアイディアからです。
まずは質問数の一日の合計から見ていきます。
def convert_to_daily_qnum_sum(data):
time_index = pd.DataFrame(index=pd.date_range('19881230','20190805'))
doc_num_daily = data.groupby(['date'], as_index=False)['q_numb'].sum()
doc_num_daily.set_index('date', inplace=True)
data_daily = pd.concat([time_index, doc_num_daily], axis=1)
data_daily['q_numb'] = data_daily['q_numb'].fillna(0)
data_daily = data_daily["q_numb"]
return data_daily
convert_to_daily_qnum_sum(data).plot()
for i in range(data_diet_open.shape[0]):
plt.axvspan(data_diet_open.start[i],data_diet_open.end[i], color=sns.xkcd_rgb['grey'], alpha=0.4)
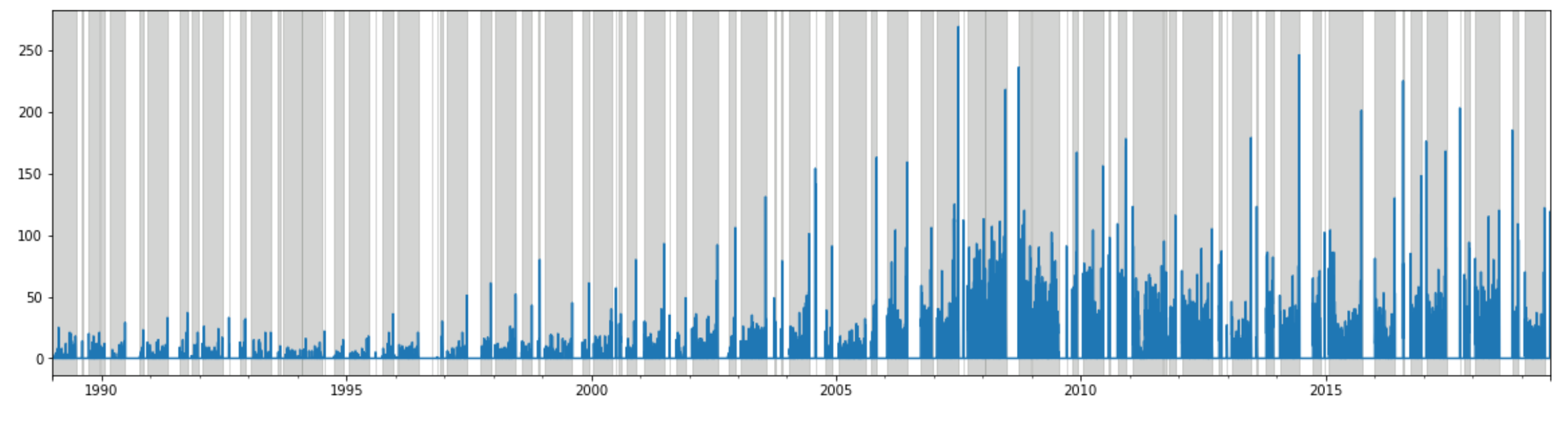 こちらも2000年以降右肩上がり。特に2007年あたりからは269(2007-07-03)の質問があるなど、大きく伸びており、その後も200を超える日が散見されます。なお、一日の平均質問数も見ていきます。
こちらも2000年以降右肩上がり。特に2007年あたりからは269(2007-07-03)の質問があるなど、大きく伸びており、その後も200を超える日が散見されます。なお、一日の平均質問数も見ていきます。
def convert_to_daily_qnum_mean(data):
time_index = pd.DataFrame(index=pd.date_range('19881230','20190805'))
doc_num_daily = data.groupby(['date'], as_index=False)['q_numb'].mean()
doc_num_daily.set_index('date', inplace=True)
data_daily = pd.concat([time_index, doc_num_daily], axis=1)
data_daily['q_numb'] = data_daily['q_numb'].fillna(0)
data_daily = data_daily["q_numb"]
return data_daily
convert_to_daily_qnum_mean(data).plot()
for i in range(data_diet_open.shape[0]):
plt.axvspan(data_diet_open.start[i],data_diet_open.end[i], color=sns.xkcd_rgb['grey'], alpha=0.4)

こちらはあまり目立った変化はないですね…。なお、一つの質問主意書の質問数が一番多かったのは山井和則氏の「雇用分野の国家戦略特区に関する質問主意書」で質問数は68!なんというか、「解雇ルール明確化の具体例を三つ挙げて下さい」、「そもそも特区では労働契約法十六条は適用外になりますか。」などなど、テストを受けているみたいな感覚になりました…。
Doc2Vec
分かち書き
データ探索が長くなってしまいましたが、ここからが本番です。まずは質問主意書の本文ごとに文章を単語に分割していきます(分かち書き)。例えば、「私は男である」であれば[私 は 男 で ある]というふうに、単語レベルに分割し、それぞれ半角スペースで区切っていきます。分かち書きで今回使用したのはMeCabになります。次の関数が分かち書きに使用したものになります。POS1で必要となる品詞のみを抽出できるようにしています。
import MeCab
def word_pos(text, POS1=['連体詞','名詞','副詞','動詞','接頭詞','接続詞',
'助動詞','助詞','形容詞','記号','感動詞','フィラー','その他']):
tagger = MeCab.Tagger('mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
tagger.parse('')
node = tagger.parseToNode(text)
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if wclass[6] == None:
if wclass[0] in POS1:
word_class.append((word,wclass[0],wclass[1],""))
else:
if wclass[0] in POS1:
word_class.append((word,wclass[0],wclass[1]))
node = node.next
word_class = pd.DataFrame(word_class, columns=['term', 'pos1', 'pos2'])
return word_class
質問主意書の本文の空白を消したのちに、名詞と形容詞のみを抽出し、さらにあまり意味をなさない、'接尾'、'非自立'、'数'を消去していきます。そして、dataにword_listとして格納
data.question = data.question.str.replace("\u3000", " ")
data_200.question = data_200.question.str.replace("\u3000", " ")
data['word_list'] = ""
for i in range(data.shape[0]):
each_data = word_pos(data.question[i], ["名詞","形容詞"])
each_data1 = each_data[each_data['pos2'] != '接尾']
each_data1 = each_data1[each_data1['pos2'] != '非自立']
each_data1 = each_data1[each_data1['pos2'] != '数']
data.loc[i,"word_list"] = " ".join(list(each_data1.term))
data_200['word_list'] = ""
for i in range(data_200.shape[0]):
each_data = word_pos(data_200.question[i], ["名詞","形容詞"])
each_data1 = each_data[each_data['pos2'] != '接尾']
each_data1 = each_data1[each_data1['pos2'] != '非自立']
each_data1 = each_data1[each_data1['pos2'] != '数']
data_200.loc[i,"word_list"] = " ".join(list(each_data1.term))
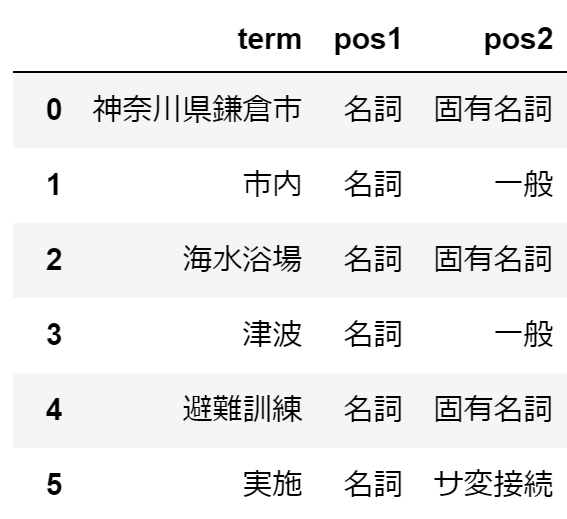
イメージを掴むために、一つだけ例示します。神奈川県鎌倉市では、市内の海水浴場において、津波避難訓練を実施するをword_posで処理すると、次のようになります。
Doc2Vec
ここでは、一つの質問主意書ごとに、本文を単語に分割し、リストに入れていきます。[([単語1,単語2,単語3],文書id),...]というイメージです。以下のコードのうち、wordsは文書に含まれる単語のリスト(単語の重複あり)、tagsは質問主意書の識別子(リストで指定.1つの質問主意書に複数のタグを付与できる)を指します。
docments = data.word_list
tagged_data = [TaggedDocument(words = data.split(),tags = [i]) for i,data in enumerate(docments)]
モデルの学習
model = Doc2Vec(documents=tagged_data, size=300, window=10, min_count=5, workers=4, seed=1, dm=1)
パラメータについては、
size:ベクトルの長さ
window:windowサイズ
min_count:カウントする最小単語数
workers:スレッド数
seed:乱数の固定
dm:dm=1とするとPV-DM、それ以外はDBoWで学習
となります。このほかにも学習率を指定するalphaやmin_alphaなどがありますが、いろいろと試し、定性的に評価したところ、先ほどのパラメータに落ち着きました。正直、gensimは損失を自動的に算出する関数がないので、この辺りは自分でモデリングできた方がだいぶんやりやすいだろうなと感じました。また、学習させる意味合いでこのようなコードを沢山見かけます。
for epoch in range(10):
print('iteration {0}'.format(epoch+1))
model.train(tagged_data, total_examples=model.corpus_count, epochs=model.iter)
model.alpha -= 0.0002 # decrease the learning rate
model.min_alpha = model.alpha # fix the learning rate, no decay
しかし、gensimの作成者によれば、これはバージョンの古いDoc2Vec用の学習コードであり、現在のバージョンだと、よほどの専門家でない限りはこのようにする必要はないとのことでした。
What does epochs mean in Doc2Vec and train when I have to manually run the iteration?
"An advanced user who needed to do some mid-training logging or analysis or adjustment might split the training over multiple train() calls, and very consciously manage the effective alpha parameters for each call. An extremely advanced user experimenting with further training on an already-trained model might also try it, aware of all of the murky quality/balance issues that might involve. But essentially, unless you already know specifically why you'd need to do so, and the benefits and risks, it's a bad idea."
また、ベクトルのサイズについても、gensimの作成者から興味深いコメントがなされています。今回のデータ量もギリギリという感じでしょうか。
what is the minimum dataset size needed for good performance with doc2vec?
In general, word2vec/paragraph-vector techniques benefit from a lot of data and variety of word-contexts. I wouldn't expect good results without at least tens-of-thousands of documents. Documents longer than a few words each work much better. Results may be harder to interpret if wildly-different-in-size or -kind documents are mixed in the same training – such as mixing tweets and books.
model.save("doc2vec.model") #モデルの保存
model = Doc2Vec.load('doc2vec.model') #モデルの呼び出し
類似の質問主意書
model.docvecs.most_similar()で類似の質問主意書が検索できます。
model.docvecs.most_similar(10531)
[(12348, 0.8008440732955933),
(10543, 0.7899609804153442),
(10534, 0.7879745960235596),
(12278, 0.7819333076477051),
(14764, 0.7807815074920654),
(13340, 0.7798347473144531),
(11314, 0.7743450403213501),
(14881, 0.7730422616004944),
(1828, 0.7719383835792542),
(14701, 0.7534374594688416)]
ということで、元のやつと、上位2つを表示
pd.set_option('display.max_colwidth', -1)
data.iloc[10531:10532,:6]

idx = model.docvecs.most_similar(10531)[0][0]
pd.set_option('display.max_colwidth', -1)
data.iloc[idx:idx+1,:6]

idx = model.docvecs.most_similar(10531)[1][0]
pd.set_option('display.max_colwidth', -1)
data.iloc[idx:idx+1,:6]

どれも残業問題、ワークライフバランスというトピックなので、まあまあの結果かなと思います。
新しい質問主意書との類似度
さて、ここからがようやく本題です。
「将来的な国会のあり方をイメージすると、何度も同じような質問が繰り返される時は人工知能ではじいてほしいな、と。そういう人工知能の活用とか、未来の国会のあり方、やれることはいっぱいある」(小泉進次郎氏)
をモデルの中にはない第200回国会の質問主意書を用いて、類似度を推定していきます。新たな文書をベクトルにするにはmodel.infer_vector()を用います。()には新たな文書と、何回モデルを回すかのstepを指定します。step数は、gensimの作成者の意見を踏まえて、20としました。
さらに、この新たな文書のベクトルはmodel.docvecs.most_similar(positive=[new_docvec], topn=1)で既存のモデルの中の文書との類似度を算出します。topnは上位いくつの文書を抽出するかというものになります。
list_most_sim_doc = []
list_most_sim_value = []
for i in range(data_200.shape[0]):
new_doc = data_200.loc[i,'word_list']
new_doc = new_doc.split(" ")
new_docvec = model.infer_vector(new_doc, steps=20)
most_sim_doc = model.docvecs.most_similar(positive=[new_docvec], topn=1)[0][0]
most_sim_value = model.docvecs.most_similar(positive=[new_docvec], topn=1)[0][1]
list_most_sim_doc.append(most_sim_doc)
list_most_sim_value.append(most_sim_value)
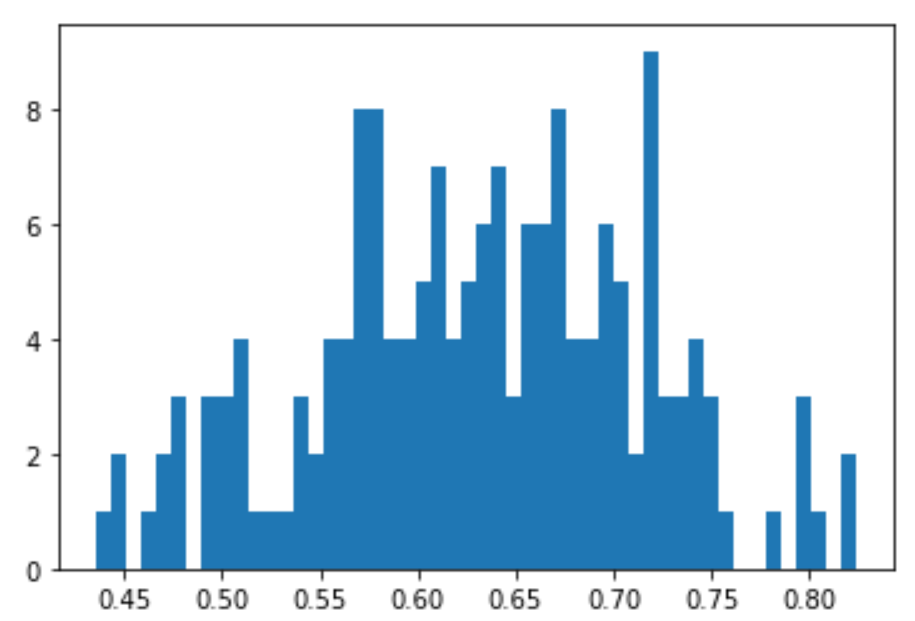
類似度の分布はこのとおり。1に近づくほど、近くなります。
plt.hist(list_most_sim_value, bins=50)
 ここで、既存のデータセットに、最も近い文書IDと類似度の値を結合。
ここで、既存のデータセットに、最も近い文書IDと類似度の値を結合。
new_doc_sim = pd.DataFrame({"sim_doc":list_most_sim_doc,"sim_value":list_most_sim_value})
data_200_sim = pd.concat([data_200, new_doc_sim], axis= 1)
類似度トップ3はこちら。どれも0.8を超えています。
pd.reset_option('^display.', silent=True)
data_200_sim = data_200_sim.sort_values(by='sim_value', ascending=False).reset_index(drop=True)
data_200_sim.head(3)
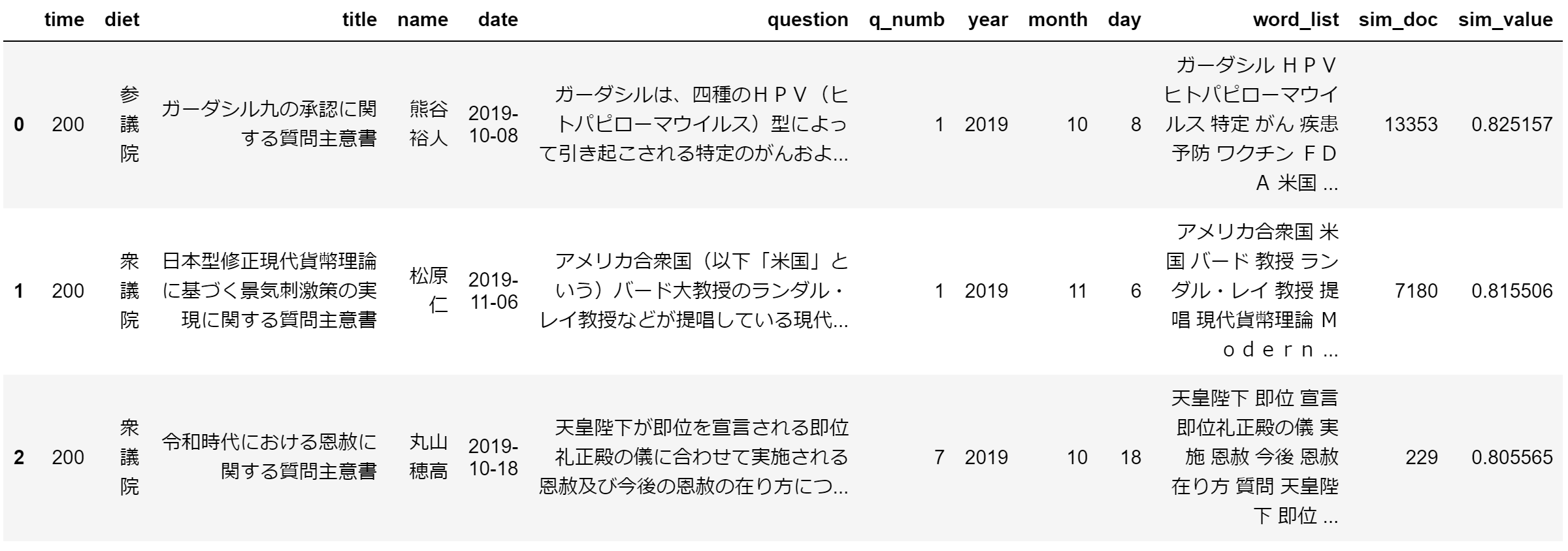
質問主意書の中身
その1
どんな内容なのか。第200回国会の文書その1。内容はガーダシルという薬がなぜ承認されないのかというもの。
idx=data_200_sim.index[1]
pd.set_option('display.max_colwidth', -1)
data_200_sim.iloc[idx:idx+1,:6]

次に、第200回国会の文書その1に、モデルの中での一番近い文書。長い…。内容はイレッサという薬の承認に関するもの。まずまずの結果。
idx=data_200_sim.index[0]
pd.set_option('display.max_colwidth', -1)
data_200_sim.iloc[idx:idx+1,:6]

その2
第200回国会の文書その2。長い…。内容はMMT理論に基づく景気刺激策。
idx=data_200_sim.index[0]
pd.set_option('display.max_colwidth', -1)
data_200_sim.iloc[idx:idx+1,:6]

次に、第200回国会の文書その2に、モデルの中での一番近い文書。もっと長い…。とりあえずの経済刺激策の内容。悪くはない結果。
idx=data_200_sim.index[0]
pd.set_option('display.max_colwidth', -1)
data_200_sim.iloc[idx:idx+1,:6]

その3
第200回国会の文書その3。内容は令和時代の恩赦について。
idx=data_200_sim.index[2]
pd.set_option('display.max_colwidth', -1)
data_200_sim.iloc[idx:idx+1,:6]

モデルの中のでの一番近い文書は、これまた令和時代の恩赦について。これもいい結果に。
idx=data_200_sim.sim_doc[2]
pd.set_option('display.max_colwidth', -1)
data.iloc[idx:idx+1,:6]

おわりに
途中データ探索が楽しくなってしまい、無駄に長く書いてしまいましたが、Doc2Vecをさらっと試してみた結果、第200回国会の質問主意書という新たな文書について、まあまあ上手く類似度を推定できたなのではないでしょうか。といいつつ、小泉進次郎氏が言うような、AIがパシッと質問を切るような世界は近くはない将来の出来事なのかなという印象です。
今回はデータ探索とDoc2Vecを使った類似度判定を試してみましたが、今後は政党のデータを交えつつ、クラスタリングを行ったり、本当に私がやってみたい、質問主意書の”質”の判定をやってみたいと思います。特に質問主意書の”質”については、単に質問主意書を多く出せばそれが成果となるという論調を変えていけれるのではないかと考えています。
私の手元にクローリング&スクレイピングを行ったデータセットがありますので、このデータを使って色々分析&解析したいという方がいらっしゃれば、何かしら共同でやっていけるのではないかと期待しています!