2017/11/11
記事を最新の状態に反映しました。
「以前試してみたけど微妙だったー」って方ももう一度試してみてください。
Googleがクラウド自然言語API(WebAPI)を公開しました。
ニュース記事
Google、クラウド自然言語APIを公開―英語、日本語、スペイン語に対応
Google、日本語もサポートのクラウド自然言語APIとスピーチAPIを一般向けにβ公開
グーグル、自然言語処理APIと音声認識APIをオープンベータに
公式Blogのアナウンス
Introducing Cloud Natural Language API, Speech API open beta and our West Coast region expansion
本記事ではどのようなAPIが実装されたのかの紹介と、今後このような変更があるんじゃないのかなという筆者の想像を記載しています。
なお筆者はGoogleAPIは詳しいですが自然言語や機械学習は詳しくないのでおかしいこと書いていたらご指摘ください。
デモが用意されているので試してみよう
公式ページを開きます。
枠線の中を使ってAPIを動かせます。
適当な文言を入れてANALYZEボタンを押してみましょう。
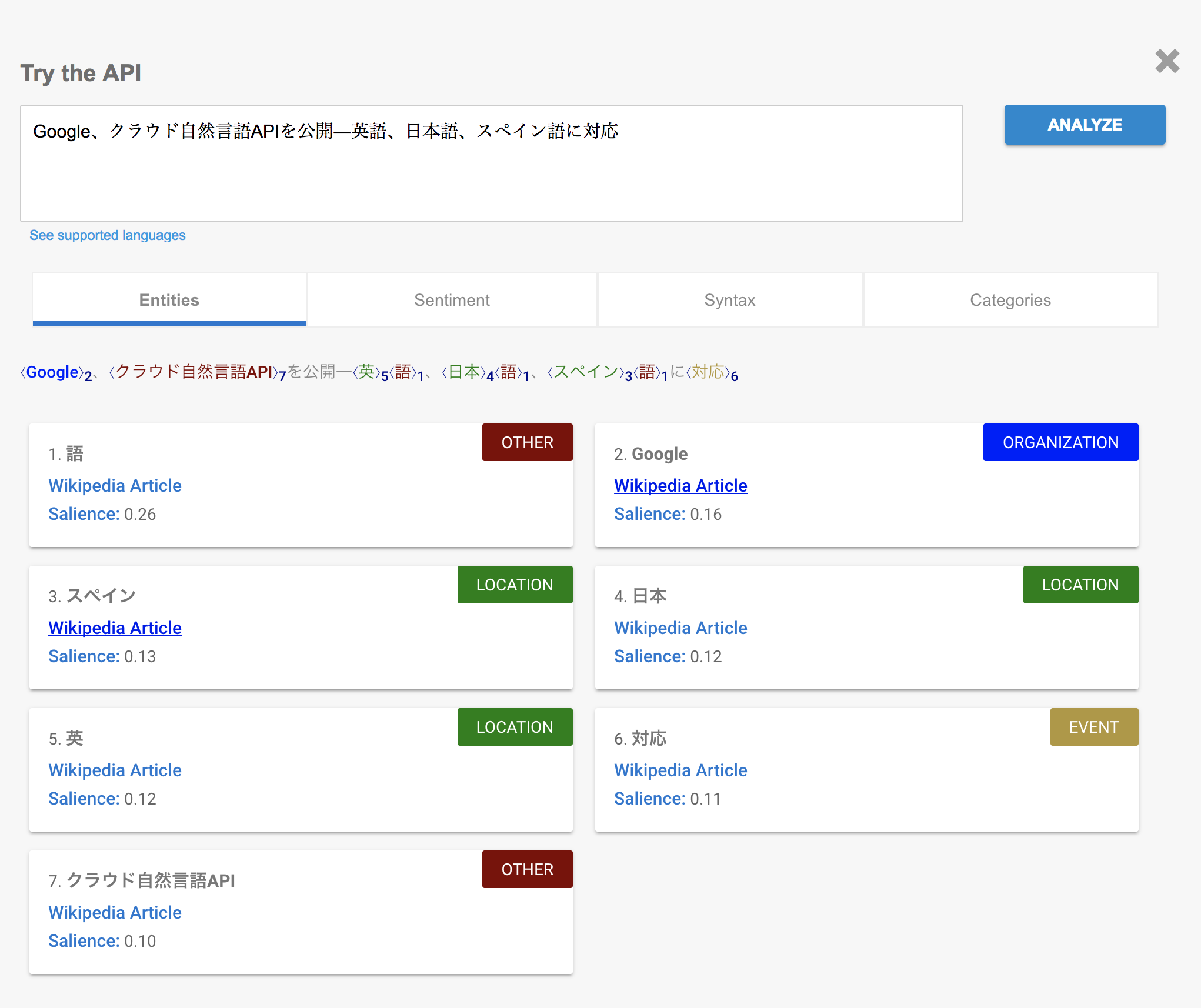
APIの種類と対応言語
APIの種類としては5種類あります。
- Entities(エンティティ分析)
- EntitiesSentiment(エンティティ感情分析)
- Sentiment(感情分析)
- Syntax(構文解析)
- ClassifyText(コンテンツ分類)v1beta
言語も現在(2017/11/11時点)は10種類あります。
- 英語
- 日本語
- スペイン語
- 中国語(簡体)
- 中国語(繁体)
- フランス語
- ドイツ語
- イタリア語
- 韓国語
- ポルトガル語
対応のマトリクスです。
| API | 英語 | 日本語 | スペイン語 | 中国語(簡体) | 中国語(繁体) | フランス語 | ドイツ語 | イタリア語 | 韓国語 | ポルトガル語 |
|---|---|---|---|---|---|---|---|---|---|---|
| Entities | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| EntitiesSentiment | ○ | × | × | × | × | × | × | × | × | × |
| Sentiment | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| Syntax | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| ClassifyText | ○ | × | × | × | × | × | × | × | × | × |
APIに関する全体的な話
API発行に必要なプロジェクトの作成等は本記事では省略します。
以下のリファレンスページを見たり「プロジェクトの作成 google API」などで検索すればたくさん出てきます。
Authenticating to a Cloud API Service
その他
クラウド自然言語APIもGoogleWebAPIの一種です。
実際に使用する際はこちらの記事
GoogleのWebAPI設計とWebAPI設計のベストプラクティスを比較してみるも見てみてください。
Entities(エンティティ分析)
Method: documents.analyzeEntities
POST https://language.googleapis.com/v1/documents:analyzeEntities
{
"document": {
"type": "PLAIN_TEXT",
"content": "Google、クラウド自然言語APIを公開―英語、日本語、スペイン語に対応"
},
"encodingType": "UTF8"
}
{
"entities": [
{
"salience": 0.26294392,
"mentions": [
{
"text": {
"content": "語",
"beginOffset": 51
},
"type": "COMMON"
},
{
"text": {
"content": "語",
"beginOffset": 63
},
"type": "COMMON"
},
{
"text": {
"content": "語",
"beginOffset": 81
},
"type": "COMMON"
}
],
"type": "OTHER",
"name": "語",
"metadata": {}
},
{
"salience": 0.16206388,
"mentions": [
{
"text": {
"content": "Google",
"beginOffset": 0
},
"type": "PROPER"
}
],
"type": "ORGANIZATION",
"name": "Google",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
}
},
{
"salience": 0.12708838,
"mentions": [
{
"text": {
"content": "スペイン",
"beginOffset": 69
},
"type": "PROPER"
}
],
"type": "LOCATION",
"name": "スペイン",
"metadata": {
"mid": "/m/06nm1",
"wikipedia_url": "https://en.wikipedia.org/wiki/Spanish_language"
}
},
{
"salience": 0.12228117,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 57
},
"type": "PROPER"
}
],
"type": "LOCATION",
"name": "日本",
"metadata": {}
},
{
"salience": 0.118508406,
"mentions": [
{
"text": {
"content": "英",
"beginOffset": 48
},
"type": "PROPER"
}
],
"type": "LOCATION",
"name": "英",
"metadata": {}
},
{
"salience": 0.107431576,
"mentions": [
{
"text": {
"content": "対応",
"beginOffset": 87
},
"type": "COMMON"
}
],
"type": "EVENT",
"name": "対応",
"metadata": {}
},
{
"salience": 0.099682674,
"mentions": [
{
"text": {
"content": "クラウド自然言語API",
"beginOffset": 9
},
"type": "COMMON"
}
],
"type": "OTHER",
"name": "クラウド自然言語API",
"metadata": {}
}
],
"language": "ja"
}
entities内のEntityが抽出できたエンティティですね。
ポイントだけ記載しておきます。
Entity.mentions
抽出出来た文字列の位置とか種類を表します。
Entity.salience
顕著性?というらしい。
文書全体に対する重要度みたいな項目らしいです。
上の例だと0〜1.0の範囲で全部0なので重要じゃないってことですかねぇ。
salienceが出るようになりました。
Entity.type
LOCATION(場所)やORGANIZATION(組織)として抽出されています。
※他にも人やイベントなんかもあるようです。type一覧
Entity.metadata
これがエンティティ分析した結果のデータですね。
今はWikipediaのURLしか出せないみたいです。
mid(Knowledge Graph MID)というのが増えたみたいです。
所感
Entity.mentionsはsが付いているようにこれから拡張される気がします。
今後どのように拡張されるかはわからないのですが、たとえば
「私はマクドナルドやモスバーガーやフレッシュネスバーガーによく行きます」
みたいなのを入れると、「ハンバーガー」「飲食店」みたいなのが出てくると可能性がすごく拡がりそうですよね。
検索エンジン作ってるGoogleさんならできるはず?期待しています。
EntitySentiment(エンティティ感情分析)
いつの間にか増えてました。
これは英語しか使えません。
Method: documents.analyzeEntitySentiment
POST https://language.googleapis.com/v1/documents:analyzeEntitySentiment
{
"document": {
"type": "PLAIN_TEXT",
"content": "A traffic accident occurred."
},
"encodingType": "UTF8"
}
{
"entities": [
{
"name": "traffic accident",
"sentiment": {
"magnitude": 0.20000000000000001,
"score": -0.20000000000000001
},
"salience": 1,
"mentions": [
{
"text": {
"content": "traffic accident",
"beginOffset": 2
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.20000000000000001,
"score": -0.20000000000000001
}
}
],
"type": "EVENT",
"metadata": {}
}
],
"language": "en"
}
所感
名前の通り、Entities(エンティティ分析) に感情解析をつけた感じですね。
Sentiment(感情解析)
Method: documents.analyzeSentiment
これは英語しか使えません。
日本語にも対応しました。
POST https://language.googleapis.com/v1/documents:analyzeSentiment
{
"document": {
"type": "PLAIN_TEXT",
"content": "今日はスポーツ観戦に行きました。しかし、残念ながら雨で中止になってしまいました。"
}
}
{
"documentSentiment": {
"magnitude": 0.9,
"score": 0
},
"language": "ja",
"sentences": [
{
"text": {
"content": "今日はスポーツ観戦に行きました。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.5,
"score": 0.5
}
},
{
"text": {
"content": "しかし、残念ながら雨で中止になってしまいました。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.3,
"score": -0.3
}
}
]
}
Sentiment.score / Sentiment.magnitude
scoreが感情の極性です。つまりマイナスなら負の感情。
magnitudeが絶対値です。
スポーツ観戦に行くのは正の感情で、残念ながら雨になったは負の感情と認識されていますね。
所感
最初に触ったときより精度がよくなってきた気がします。
文章単位の他に、文ごとに結果が返るようになりました。
Syntax(構文解析)
Method: documents.analyzeSyntax
POST https://language.googleapis.com/v1/documents:analyzeSyntax
{
"document": {
"type": "PLAIN_TEXT",
"content": "Google、クラウド自然言語APIを公開―英語、日本語、スペイン語に対応"
},
"encodingType": "UTF8"
}
{
"tokens": [
{
"text": {
"content": "Google",
"beginOffset": 0
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "DOBJ"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "Google"
},
{
"text": {
"content": "、",
"beginOffset": 6
},
"dependencyEdge": {
"headTokenIndex": 0,
"label": "P"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PUNCT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "、"
},
{
"text": {
"content": "クラウド",
"beginOffset": 9
},
"dependencyEdge": {
"headTokenIndex": 3,
"label": "NN"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "クラウド"
},
{
"text": {
"content": "自然",
"beginOffset": 21
},
"dependencyEdge": {
"headTokenIndex": 4,
"label": "NN"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "自然"
},
{
"text": {
"content": "言語",
"beginOffset": 27
},
"dependencyEdge": {
"headTokenIndex": 5,
"label": "NN"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "言語"
},
{
"text": {
"content": "API",
"beginOffset": 33
},
"dependencyEdge": {
"headTokenIndex": 0,
"label": "CONJ"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "API"
},
{
"text": {
"content": "を",
"beginOffset": 36
},
"dependencyEdge": {
"headTokenIndex": 0,
"label": "PRT"
},
"partOfSpeech": {
"case": "ACCUSATIVE",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PRT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "を"
},
{
"text": {
"content": "公開",
"beginOffset": 39
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "NN"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "公開"
},
{
"text": {
"content": "―",
"beginOffset": 45
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "P"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PUNCT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "―"
},
{
"text": {
"content": "英",
"beginOffset": 48
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "ROOT"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "英"
},
{
"text": {
"content": "語",
"beginOffset": 51
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "SUFF"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "AFFIX",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "語"
},
{
"text": {
"content": "、",
"beginOffset": 54
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "P"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PUNCT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "、"
},
{
"text": {
"content": "日本",
"beginOffset": 57
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "CONJ"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "日本"
},
{
"text": {
"content": "語",
"beginOffset": 63
},
"dependencyEdge": {
"headTokenIndex": 12,
"label": "SUFF"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "AFFIX",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "語"
},
{
"text": {
"content": "、",
"beginOffset": 66
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "P"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PUNCT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "、"
},
{
"text": {
"content": "スペイン",
"beginOffset": 69
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "CONJ"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "スペイン"
},
{
"text": {
"content": "語",
"beginOffset": 81
},
"dependencyEdge": {
"headTokenIndex": 15,
"label": "SUFF"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "AFFIX",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "語"
},
{
"text": {
"content": "に",
"beginOffset": 84
},
"dependencyEdge": {
"headTokenIndex": 9,
"label": "PRT"
},
"partOfSpeech": {
"case": "ADVERBIAL",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "PRT",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "に"
},
{
"text": {
"content": "対応",
"beginOffset": 87
},
"dependencyEdge": {
"headTokenIndex": 18,
"label": "ROOT"
},
"partOfSpeech": {
"case": "CASE_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"tag": "NOUN",
"tense": "TENSE_UNKNOWN",
"aspect": "ASPECT_UNKNOWN",
"proper": "NOT_PROPER",
"voice": "VOICE_UNKNOWN"
},
"lemma": "対応"
}
],
"language": "ja",
"sentences": [
{
"text": {
"content": "Google、クラウド自然言語APIを公開―英語、日本語、スペイン語に対応",
"beginOffset": 0
}
}
]
}
DependencyEdge
係り受け解析をあらわしている模様。
https://cloud.google.com/natural-language/docs/reference/rest/v1/Token#DependencyEdge
PartOfSpeech
形態素解析をあらわしている模様。
https://cloud.google.com/natural-language/docs/reference/rest/v1/Token#PartOfSpeech
所感
これは自然言語素人にはほとんどわからないですね。なので何も言えない。。。
口語が弱いとかはてブで見ましたが実際どうなんでしょう。良いかどうかすら判別できないorz
ClassifyText(コンテンツ分類)
v1betaです。また英語のみです。
Method: documents.classifyText
POST https://language.googleapis.com/v1beta2/documents:classifyText
{
"document": {
"type": "PLAIN_TEXT",
"content": "The Google Cloud Natural Language API supports a variety of languages. These languages are specified within a request using the optional language parameter. Language code parameters conform to ISO-639-1 or BCP-47 identifiers. If you do not specify a language parameter, then the language for the request is auto-detected by the Natural Language API."
}
}
{
"categories": [
{
"confidence": 0.63,
"name": "/Computers & Electronics"
}
]
}
所感
どういう類の文章なのかというがわかるようです。
雑多な文章を仕分けるときとかによさそうですね。
あとがき
この分野はやっぱり面白そうですよね。
Qiitaには機械学習関連のよさ気な記事がいっぱいあるので勉強を始めてみようと思います。
このへんですかね。
数学を避けてきた社会人プログラマが機械学習の勉強を始める際の最短経路
機械学習はじめの一歩に役立つ記事のまとめ
画像処理の数式を見て石になった時のための、金の針