この記事はなに
2022年に大ヒットしたAIによる画像生成モデルStableDiffusion。
この度、Hugging FaceがStable Diffusionやその核となる拡散モデルについて解説を出しました🤗
ここでは、Unit1の「拡散モデル入門」02_diffusion_models_from_scratch.ipynbを参考にしつつ、
実際に簡単な学習を実装してみます。
拡散モデルとは
画像生成というタスクでは、はじめにノイズが与えられ、ここから徐々に欲しい画像へと近付けていきます。
これまでGANなど多くの手法が研究されています。

ノイズから綺麗な画像を得るのは大変難しいように見えます。
しかし綺麗な画像にノイズを加える操作であれば簡単ですね。
そこで、綺麗な画像と、それにノイズが乗った画像のペアを用意します。
ノイズのある画像からノイズ除去する方法を学習させるのが拡散モデルです。
お部屋にノイズを加えると、秩序あるものが拡散してぐちゃぐちゃになりますが、
ここで片付けして綺麗な状態に戻す方法を学ぶわけですね(?)
拡散モデルの学習手順
拡散モデルは以下を繰り返すことによって学習できます。
- 目標となる画像をいくつか読み込む。
- 画像に大小さまざまなノイズを加える。
- ノイズが乗った画像を入力し、モデルに元画像を推定させる。
- その出力が元の画像にどれだけ近いかを評価し、より良い評価が得られる方向に、モデルのパラメータを更新する。
文章で書くのは簡単ですが、本当にこの工程でうまく学習ができるのでしょうか?
そこで、上の手順をなぞって最小限の単純な拡散モデルを作成できるか試してみます。
実際に使用したコードの全文はこちらにあります。
0. 前準備
Pytorchを使います。Google Colaboratoryなどで実行すると良いでしょう。
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
1. 学習したい画像を読み込む
ここでは、一か八か、1か8の画像を生成してみましょう。torchvisionのMNISTのデータセットを用います。
dataset = torchvision.datasets.MNIST(root="/data", train=True, download=True, transform=torchvision.transforms.ToTensor())
# おっと、4が混ざりました。1か8か、あるいは4です。
# 好きな数字に変えても良いでしょう。
target_values = [1, 8, 4]
target_images = []
for data in dataset:
if data[1] in target_values:
target_images.append(data)
train_dataloader = DataLoader(target_images, batch_size=8, shuffle=True)
手書き数字データセット、字汚いな
1の画像が6742枚、8の画像が5851枚、4の画像が5842枚あります。
2. 画像にノイズを加える
学習させたい数字の画像は縦横28ピクセルで、各ピクセルは0~1の実数値です。
ノイズを加えてもおおよそ0~1に収まるように、元画像と0~1のノイズ画像の内分を、ノイズがかかった画像とみなします。
def corrupt(x, amount):
"""
x : 入力する画像(複数), x.shape = torch.Size([batch_size, 1, 28, 28])
amount : 各画像にどれだけノイズを入れるかの比率を入れたndarray, 0->そのまま, 1->完全にノイズ
"""
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
# ノイズが加わる様子を可視化
amount = torch.linspace(0, 1, x.shape[0])
noised_x = corrupt(x, amount)
_, axs = plt.subplots(2, 1, figsize=(12, 5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys');
元の画像にノイズをかけるとこんな感じです。右に行くほどノイズの割合が多いです。

3. ノイズを除去するモデル
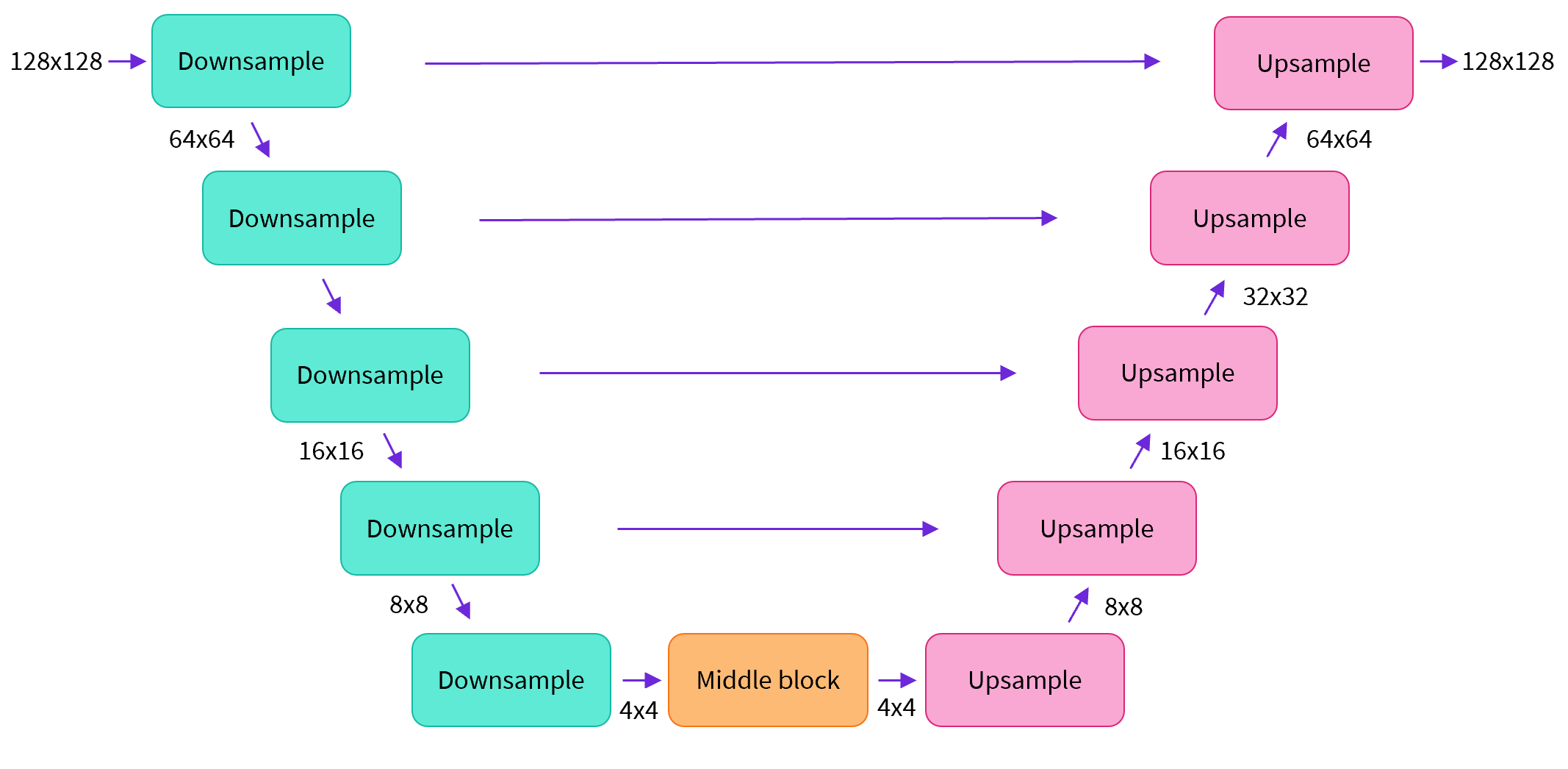
上のような形をしたUNetと呼ばれるものがよく使われるらしいです。ここでは最も簡単に実装します。
入力画像を畳み込み層とプーリングによって小さくしていき、その後アップサンプリングと畳み込み層によって広げていきます。
また、途中にスキップ接続も入れます。パラメータ数は31万ほどになります。
class BasicUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layer1 = nn.Conv2d(in_channels, 32, kernel_size=5, padding=2)
self.down_layer2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)
self.down_layer3 = nn.Conv2d(64, 64, kernel_size=5, padding=2)
self.up_layer1 = nn.Conv2d(64, 64, kernel_size=5, padding=2)
self.up_layer2 = nn.Conv2d(64, 32, kernel_size=5, padding=2)
self.up_layer3 = nn.Conv2d(32, out_channels, kernel_size=5, padding=2)
self.act = nn.SiLU()
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
x1 = self.act(self.down_layer1(x))
x2 = self.downscale(x1)
x2 = self.act(self.down_layer2(x2))
x3 = self.downscale(x2)
x3 = self.act(self.down_layer3(x3))
y = self.act(self.up_layer1(x3))
y = self.upscale(y) + x2
y = self.act(self.up_layer2(y))
y = self.upscale(y) + x1
y = self.act(self.up_layer3(y))
return y
4. モデルを学習させる
画像にノイズを加え、元画像を推論させます。
推論結果と元画像の誤差を元にして逆誤差伝播によりパラメータを更新していけば、
ノイズが乗った画像からノイズを除去するモデルが得られるでしょう。
Google Colaboratory環境にて、バッチサイズ128で5周すると7分半かかりました。
(MNISTの0~9のデータセット全体を使うと、3~4倍時間がかかって大変なので減らしました)
batch_size = 128
train_dataloader = DataLoader(target_images, batch_size=batch_size, shuffle=True)
max_epochs = 5
net = BasicUNet()
net.to(device)
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
history = []
for epoch in range(max_epochs):
for x, y in train_dataloader:
x = x.to(device)
# どれくらいノイズを入れるかは乱数で決める
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x, noise_amount)
pred = net(noisy_x)
loss = loss_func(pred, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
history.append(loss.item())
avg_loss = sum(history[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
plt.plot(history)
plt.ylim(0, 0.1)
順調に誤差が減っていきます。
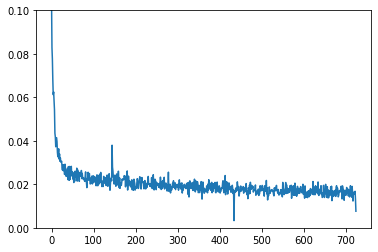
epoch数を増やしても良さそうですが、ここでは最低限の簡単な例を示しているだけなので、今日のところはこの辺で勘弁してやりましょう。
学習結果
学習が済んだモデルに、元画像にノイズを加えたものを入力してみます。

加えたノイズが少ないときには、よく復元できていますね。
一方で、ノイズが多いと除去しきれずにボヤッとしてしまいます。
右の2つに関しては、4を入力したはずなのに8や1が現れ、自我を見失っています。
完全なノイズを加えると欲しい綺麗な画像をうまく生成できないので、このモデルは学習に失敗しているのでしょうか?
いいえ、このモデルでもうまく生成することができるアイデアがあります。
完全なノイズを入力したときの出力は、欲しい画像の特徴を捉えている!
1番右のボヤッとした画像は、入力した1と8と4の画像たちを全て平均した意味のない画像なんじゃないかと疑う人がいるかもしれません。
そんなことはないです!以下が入力画像全ての平均をとったものです。
これと比較すると、先ほどの1番右のボヤッとした画像はかなりマシに見えてきますね。

サンプリング
完全なノイズを入力すると、ボヤッとしているけれど、ノイズを除去して1か8か4らしきものが現れます。
一方で、元画像に少しノイズがかかったくらいであれば、綺麗に復元することができます。
ノイズから元画像を推定する過程を繰り返し行うことで、綺麗な画像が得られる気がしませんか?
これが、最後に行うサンプリングという作業です。
注意点として、モデルはノイズを加えた画像を入力したときの、ノイズ除去の方法を学習したものです。
つまり、人為的にノイズを乗せた画像を入力する必要があります。
完全にランダムなノイズからスタートし、
- 推論によりノイズ除去した画像を得る
- 画像にいくらかノイズを混ぜる
を繰り返します。初めはたくさんノイズを加え、徐々にノイズを加える量を減らして最後は0にすると良いでしょう。
サンプリングの途中過程を見てみましょう。
n_steps = 5
x = torch.rand(8, 1, 28, 28).to(device)
step_history = [x.detach().cpu()]
pred_output_history = []
for i in range(n_steps):
with torch.no_grad():
pred = net(x)
pred_output_history.append(pred.detach().cpu())
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
step_history.append(x.detach().cpu())
_, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)
axs[0,0].set_title('x (model input)')
axs[0,1].set_title('model prediction')
for i in range(n_steps):
axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0, 1), cmap='Greys')
axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i])[0].clip(0, 1), cmap='Greys')
1番上の行の左の画像がスタートです。推論結果がその右です。
まだボヤッとしているので、再びノイズを加えます。上から2行目の左です。

推論して右へ、ノイズを加えて左下へを繰り返すと、最終的に1番右下になります。
1は綺麗に出力できていますが、他は微妙ですね。ステップ数を増やしてみましょう。
慎重に少しずつノイズから元画像を復元していくと、たとえ初期の推論に誤りがあったとしても、ノイズを乗せて打ち消し、修正していくことが望めます。
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
with torch.no_grad():
pred = net(x)
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')
40ステップかけてサンプリングをしました。

毎回良い出力が得られるとは限りませんが、無事に1と8と4が得られました!おめでとうございます!
1が多いのは、形が単純だからであることや、学習データに1の画像の枚数が多かったことが関係しているかもしれません。
より良い拡散モデルを得るためには
ここまで最小限の単純な拡散モデルを見てきました。当然ながら、このモデルには改良点が山ほどあります。
例えば、DDPM(Denoising Diffusion Probabilistic Models)という論文と比較すると
- 学習時に、どのタイミングで元画像にどれくらいのノイズを加えていけばよいか
- 学習に用いたネットワークの構造
- 誤差関数の設計や最適化手法
- サンプリングをどのように行うか
(今回は逐次的に1つ前の画像をもとに次の画像を計算しましたが、1つ前に限らずこれまで得られた画像も活用できるはずです)
3は学習をする部分でPytorchの関数を適宜変えることで改良ができます。
Stable Diffusionなどを大規模な拡散モデルのために開発されたdiffusersライブラリでは便利なAPIが提供されています。
特に、1を担当するのはScheduler、3やモデルの保存など細々とした処理の集合はPipelineを用います。
from diffusers import DDPMScheduler, UNet2DModel, DDPMPipeline
Hugging FaceのレポジトリのUnit1にある01_introduction_to_diffusers.ipynb
はこれらのデモになっています。ぜひ遊んでみてください。