
この記事はUMITRON Advent Calendar 2023 5日目の記事です
目次
まえがき
大まかな流れ
Amazon SageMaker Ground Truthを利用した学習データ作成
Amazon SageMaker組み込みアルゴリズムを利用した物体検出モデルの学習
Amazon SageMaker エンドポイントを利用した物体検出モデルのデプロイ
物体検出の実行
エンドポイントの停止
最後に
まえがき
こんにちは、UMITRONの細野です。
昨年に引き続き物体検出に関する記事です。
ウミトロンでは要件に応じていくつかの物体検出アルゴリズムが使われていますが、手軽に検証をしたいというときは、Amazon SageMaker組み込みの物体検出アルゴリズムがよく使われます。
物体検出アルゴリズムはSSD1なので、最新のアルゴリズムと比較すると精度が出にくい場面があるかもしれませんが、学習データの生成からモデルのデプロイまですべてウェブインタフェースででき、簡単に物体検出サービスを構築できます。
モデルの更新等の運用を楽にするという観点では、ウェブインタフェースを使うよりもSDKを使ってコードで管理した方が良い場合が多いですが、ウェブインタフェースを使えば物体検出やAWSを使った開発に慣れていない方でも手軽に検証ができるというのは大きなメリットだと思うので、本記事では物体検出の推論実行部分以外はすべてコードの記述が不要なやり方を紹介します。
なので、本記事が参考になるかもしれない方は以下のような方です。
- 物体検出の知識はあまりないが、物体検出を使ったサービスを開発してみたい
- 物体検出の利用経験があるが、Amazon SageMakerを使ったことがない
大まかな流れ
本記事ではAmazon SageMakerを使った、物体検出モデル学習用のデータセット作成方法、そのデータを使って学習されたモデルのAPIサーバーとしてのデプロイ方法及びその呼び出し方法を紹介します。
大まかな流れは以下の通りです。
- Amazon SageMaker Ground Truthを利用した学習データ作成
- Amazon SageMaker組み込みアルゴリズムを利用した物体検出モデルの学習
- Amazon SageMaker エンドポイントを利用した物体検出モデルのデプロイ
- 物体検出の実行
物体検出モデルのデプロイについて、本記事ではリアルタイム推論2を用いた方法を紹介します。リアルタイム推論では低レイテンシーで利用可能なAPIサーバをホスティングできます。
余談ですがAmazon SageMakerでは、不定期にリクエストが発生するアプリケーションに適しているサーバレス推論3や、大きなデータの処理に適している非同期推論4等といったその他のデプロイ方法も選択できます。
以降、各手順について解説していきます。
Amazon SageMaker Ground Truthを利用した学習データ作成
本記事では、学習データのラベリングを自分たちでやる方法を紹介します。
Amazon Mechanical Turkを利用してクラウドソーシングすることも可能ですが、費用がかかったり機密情報は扱えなかったりする点に注意が必要です。
ラベリングワークフォースの作成
ラベリングを自分でやるために、ラベリングワークフォースを事前に作成しておく必要があります。
手順は以下の通りです。
-
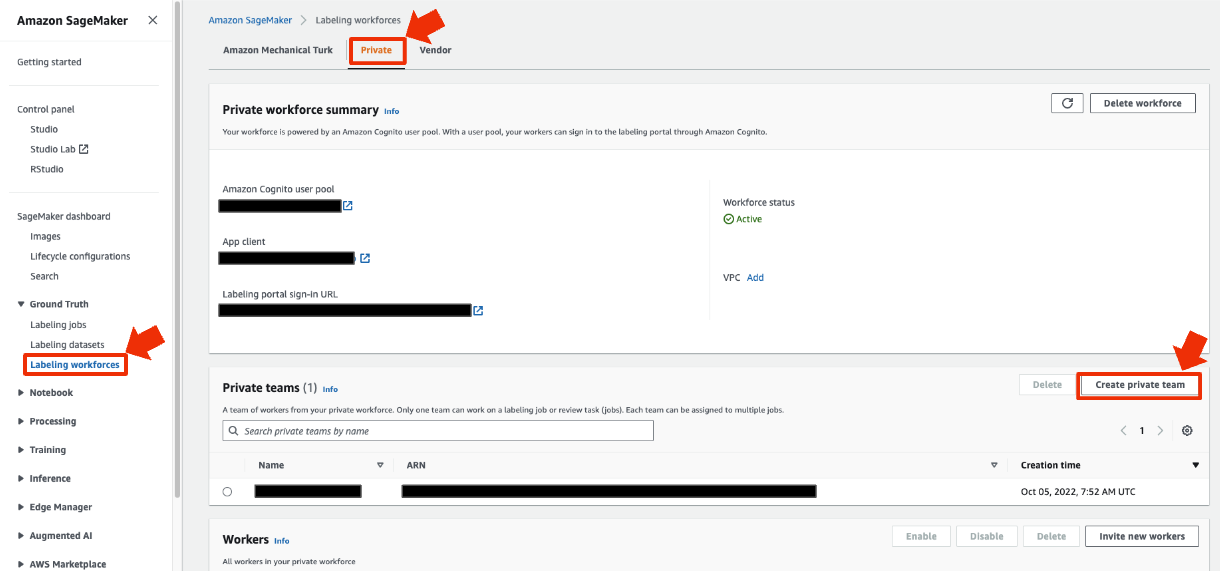
SageMaker→Ground Truth→laveling workforces→Private→Create private teamを選択します
-
チーム名を決めてチームを作成します(チーム名以外はデフォルトのまま)

-
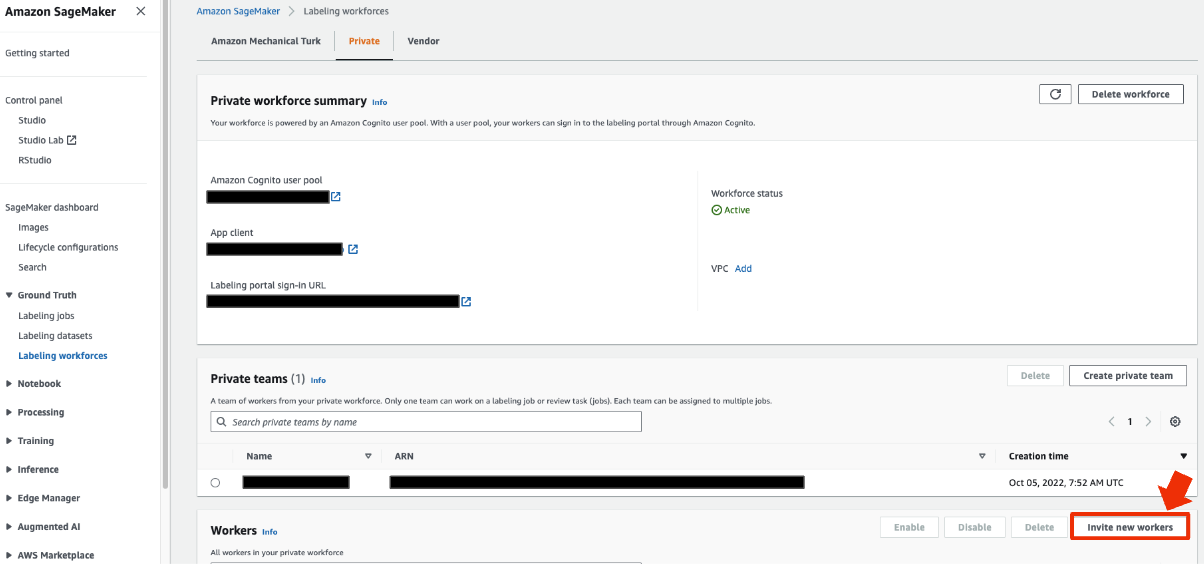
Labeling workforcesの画面に戻り invite new workersを選択します
-
ラベリングを実施する人のメールアドレスを入力し invite new workersを選択します

-
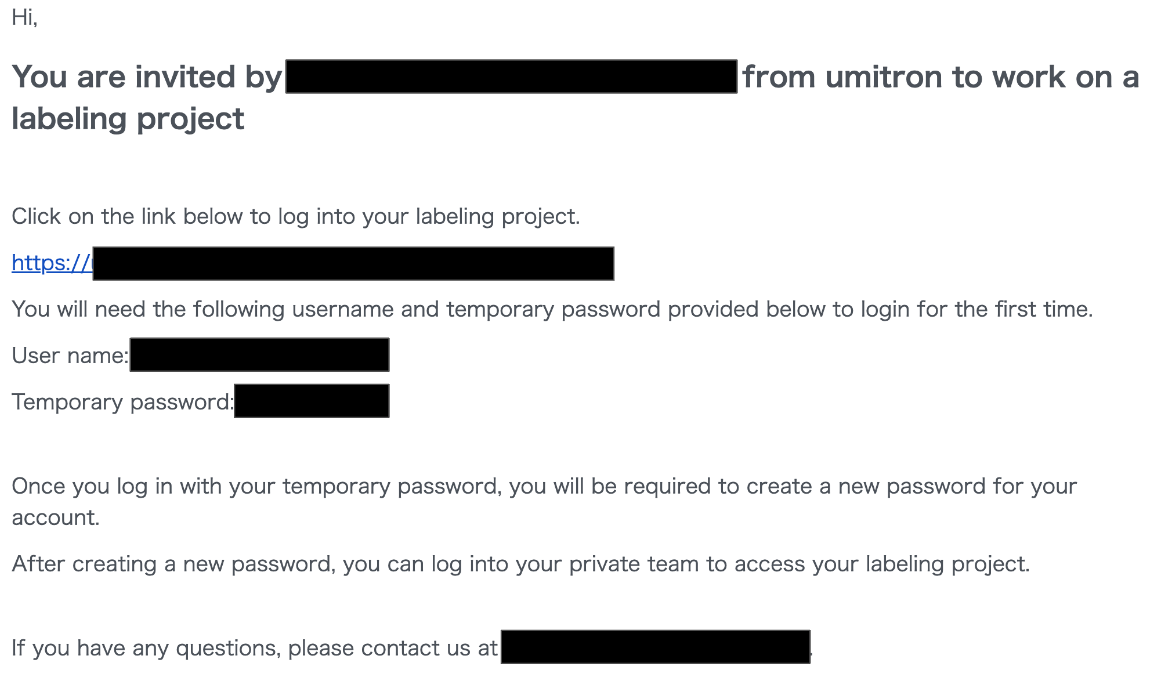
登録したワーカに以下のような内容のメールが届くので、メール内のリンクからworker portalにログインしパスワードの設定をしておきます。このときworker portalログイン用のURLを保存しておくと便利です。
学習データの画像をS3にアップロード
Amaon S3の好きな場所に画像データアップロードします
- Amazon S3→画像をアップロードするフォルダに移動→Upload

- ドラッグ&ドロップ等で画像を選択してアップロード

ラベリングジョブの作成
- SageMaker→labeling jobs→create labeling jobを選択します

- Job overviewの各項目を設定します。Input data setupはautomated data setupを選択し、S3 location for input datasetsには先程画像をアップロードしたフォルダのパスを入力してください。また、Data typeはImageを選択してください。IAM RoleはAmazonSageMakerfullAcessを持つものを指定してください。その後、complete data setupをクリックします

- Data setupが成功すると下の画像のような表示になります

- Task typeをbounding boxに変更し、nextをクリックします

- Worker typesがprivateになっていることを確認し、先程作成したチームをprivate teamsに設定してください。Task timeout(一枚の画像のアノテーションに掛けられる時間)とtask expiration time(全データのアノテーションを完了させる期限)は適宜調整してください

- Bounding box labeling toolの設定を行います。ここではlabelsのみ設定しています。ラベリングを実施するメンバーにタスク内容を詳細に説明したい場合は、ここに正解の例やルールの記述をすることができます。設定後createをクリックして完了です

ラベリング
- Worker potalにログインするとタスクが追加されているので、start workingでラベリングを開始します

- ラベリングしていきます(本記事で使用している魚の画像はすべてDeepFishデータセット5のものです)

- 完了してしばらくするとラベリングジョブのステータスがcompleteになります

Amazon SageMaker組み込みアルゴリズムを利用した物体検出モデルの学習
トレーニングジョブの作成
- SageMaker→trainging jobs→create training jobを選択します

- Job settingsを設定していきます。IAM roleは先程と同様にAmazonSageMakerFullAccessを持つものを設定してください。Algorithm sourceはAmazon SageMaker built-in algorithmを選択し、algorithmはVision - Object Detection (MxNet)を選択します。Input modeはFileです。

- Resource configurationのinstance typeはGPU搭載のもの(p2やg4dn)を選択してください。

- ハイパーパラメータの設定です。物体検出に慣れていない方は謎の項目だらけかもしれませんが、ほとんどデフォルトで大丈夫です。
必ず設定しなければならない項目は下の画像の赤枠で示したnum_classesとnum_traning_samplesです。それぞれ学習データに含まれるクラス(ラベルの種類)数と画像の総数を設定してください。
また、下の画像の緑枠で示したbase_networkとepochsとmini_batch_sizeは調整した方がいいかもしれない項目です。base_networkはresnet-50の方が少し精度がよくなるかもしれないので私はいつもこちらをまず試します。epochsは少ないと学習が十分にされない可能性がありますが、多いと学習時間がかかります。後ほど調整方法を解説します。mini_batch_sizeは初期値でいい場合が多いですが、今回のように学習データの数が少ないときは大きくても学習データの10分の1程度にしておいて方が良いです(num_training_sampleより大きな値にするとエラーが出ます)。また、num_training_sampleの数が数万枚等多い場合は512等デフォルトよりも大きな値にしてもいいかもしれません。

- Input data configurationを設定します。デフォルトから変更する箇所が多いですが、下の画像のように設定してください。赤枠で示したAugmentedManifestFile attribute namesの2つ目にはラベリングジョブのジョブ名を設定してください。緑枠で示したS3 locationにはラベリングジョブのoutput dataset locationのフォルダ以下に生成されているmanifest/output/outpu.manifestのS3 URIを記載してください。その後、add channelをクリックします。

- 追加したchannelのchannel nameはvalidationにして、その他はすべてtrainと同じものを記載してください(理想的には学習データとは別のvalidation用データを用意したほうがいいのですが、今回はお手軽版ということで省略させてください)。

- Output data configurationには、生成されたモデルファイルを置きたいフォルダを指定してください。Enable managed spot trainingを有効にすると、学習が長くなることがありますが、お安く学習をすることができます。最後にcreate training jobをクリックして学習スタートです。

トレーニング結果の確認
- SageMaker→trainging jobsから先程作成したトレーニングジョブのstatusがcompletedになっていることを確認し、クリックしてジョブの詳細ページにいきます

- ジョブの詳細ページのmonitorで様々な値のログを確認します。ここではトレーニングジョブの作成時に設定したepoch数を調整するために見る項目であるvalidation:mAPとtrain:cross_entropyについて少し説明します。
validation:mAPの縦軸はvalidationデータでどのくらい精度良く物体検出を表しており、高いほどよいです。今回は42枚という少ないデータ数だったので値があまり高くないですが、もっと多くの学習データを使い、かつうまく学習できていれば0.8程度になります(そもそも物体検出が難しいデータセットの場合も低い値になります)。横軸は学習時間でこれがepoch数に比例します。グラフを見ると学習が進むに連れて0.4付近に収束していることがわかります。この収束が不十分な場合はepoch数を増やして再度学習したほうが良いです。また、収束してからも長時間学習されている場合、次回同じようなデータで学習するときはepoch数を減らすことで、精度を保ちつつ学習時間を削減できます。
train:cross_entropyの縦軸は学習がどれくらいうまく行っているかを表す指標であり低いほどよいです。横軸は学習時間です。この値も学習が進むに連れて収束していくので、epoch数の過不足を確認できます。

Amazon SageMaker エンドポイントを利用した物体検出モデルのデプロイ
モデルの作成
- SageMaker→trainging jobs→先程作成したトレーニングジョブ→create modelを選択します

- Model nameのみ記載し、そのままcreate modelをクリックします

エンドポイントの作成
- SageMaker→models→先程作成したモデル→create endpointを選択

- Endpoint nameとendpoint configuration nameを入力し、create endpoint configurationをクリックします

- Endpoint configurationの作成が完了したらcreate endpointをクリックします

- 数分後にエンドポイントが作成されます

物体検出の実行
1. Pythonが実行できる環境にAWS SDK6とOpenCV7をインストールします。どちらもpipでインストールできます
$ pip install boto3
$ pip install opencv-python
2. コードを書きます。エンドポイントを呼び出す部分のサンプル関数を以下に記します
import boto3
import cv2
def detect(img, endpoint_name, aws_profile_name):
"""Detect pellets using SageMaker endpoint
Args:
img (np.array): Image data loaded with OpenCV
endpoint_name (str): SageMaker endpoint name
aws_profile_name (str): AWS profile name to access endpoint
Return:
dict: detection result json
{"prediction":[[class id, score, xmin, ymin, xmax, ymax],...]}
"""
_, buffer = cv2.imencode(".jpg", img)
session = boto3.session.Session(profile_name=aws_profile_name)
client = session.client("sagemaker-runtime")
response = client.invoke_endpoint(
EndpointName=endpoint_name,
Body=buffer.tobytes(),
ContentType="image/jpeg",
)
return json.loads(response["Body"].read())
実行結果です。42枚でしか学習していないですが結構検出できました。

エンドポイントの停止
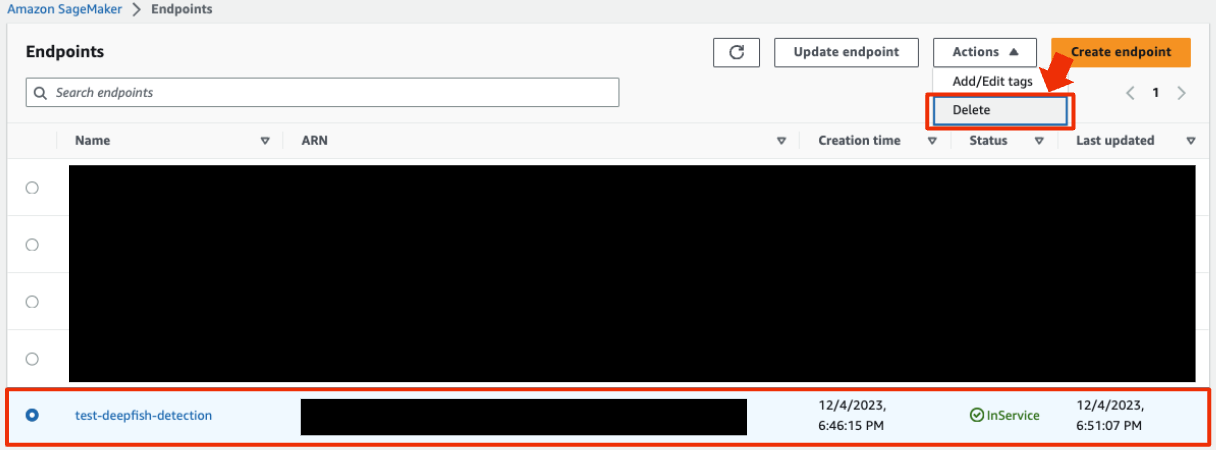
エンドポイントは起動している時間に対して料金が掛かるので、使っていないときはdeleteしましょう。エンドポイント設定を残残しておけばSageMaker→endpoints→create endpointから簡単に再作成できます。
- SageMaker→endpoints→先程作成したエンドポイント→deleteを選択します
最後に
本記事ではAmazon SageMakerを使った物体検出サーバの作成方法を紹介しました。
画像さえ収集できれば簡単に物体検出の検証ができますし、十分な精度が出るならそのままプロダクト用の物体検出サーバとして運用することもできるので、スピーディーに物体検出を使ったサービス開発ができる点も魅力的です。
本記事が、物体検出を使ったサービスを開発してみたい方の一助となれば幸いです。
ウミトロンでは一緒に働く仲間を募集しております。持続可能な水産養殖を地球に実装するというミッションの元で、私たちと一緒に水産養殖xテクノロジーに取り組みませんか?