はじめに
Optuna は、オープンソースのハイパーパラメータ自動最適化ツールです。この記事では、Optuna と Chainer を用いて、実際に深層学習(ディープラーニング)のハイパーパラメータ最適化を行う方法を説明します。Optuna の examples にはさまざまなフレームワークでの例が載っていますが、ドキュメントとして説明はされていないようなので、私なりにアレンジを加えたものを紹介します。
内容としては:
- ハイパーパラメータとは何か?
- Optuna でシンプルな最適化
- Optuna + Chainer で深層学習のハイパーパラメータ最適化
のようになっています。
対象とする読者は以下です:
- Chainer などの深層学習フレームワークに慣れ親しんでいる方
- Optuna のチュートリアルは触ったものの、そこから深層学習のハイパーパラメータ自動最適化に活用する方法がわからない方
反対に、対象と しない 読者は以下です:
- Optuna のチュートリアル をまだやっていない方 → まずはそちらやることをオススメします。
- Optuna の examples を読んで理解できる方 → それらを超える内容はほぼありません。
- 機械学習の基礎的な概念・Python の基本的な文法を知らない方 → この記事では説明しないので、ほかで習得してから読んでください。
また、この記事で解説するコードの完全なものは GitHub のリポジトリ にあります。
ハイパーパラメータとは何か?
深層学習の場合、ハイパーパラメータとは例えば層の数や活性化関数の種類など、学習の過程で変化しないパラメータを指します。実際に学習を行うときはそれらを決めた上で、それぞれの層が持っている重みやバイアスなどのパラメータを最適化することで学習を行うわけですが、層の数や活性化関数の種類は学習の過程で最適化されるわけではなく、あらかじめ人間が手で与える必要がありました。したがって、学習の過程で最適化されるパラメータ(層が持っている重みやバイアス)と区別するために、層の数や活性化関数の種類のことを ハイパーパラメータ と呼びます。以下に、深層学習におけるパラメータの例とハイパーパラメータの例を示します。
深層学習におけるパラメータの例:
- 層の重み
- 層のバイアス
深層学習におけるハイパーパラメータの例:
- 層の数
- 活性化関数の種類(ReLU や Sigmoid など)
- 最適化方法の種類(Adam や SGD など)
- 最適化方法のパラメータ(学習率など)
深層学習では誤差逆伝播を用いて勾配(loss のパラメータによる微分)を計算しパラメータのアップデートを行います。対してハイパーパラメータでは層の数や活性化関数の種類など、それを変えるとモデルの性質がドラスティックに変わるため微分が簡単に行えなそうなものが多いです。そういった意味でも、これらのハイパーパラメータは学習時に最適化することが難しく、学習を始める前に決めうちにならざるを得ないという背景もあります。
ハイパーパラメータ最適化のプロセス
人手によるハイパーパラメータ更新の例を以下に示します。例ではふたつの学習を同時に走らせていますが、学習が終わるごとに人手によるチェックが入るため、ハイパーパラメータを試せる数に限りがあり、またスケールもしません。例えば 100 個 GPU を用意して 100 セットのハイパーパラメータで同時に学習させることを考えてください。それらの学習が終わった際に、次にみるべきハイパーパラメータを即座に判断できるでしょうか?
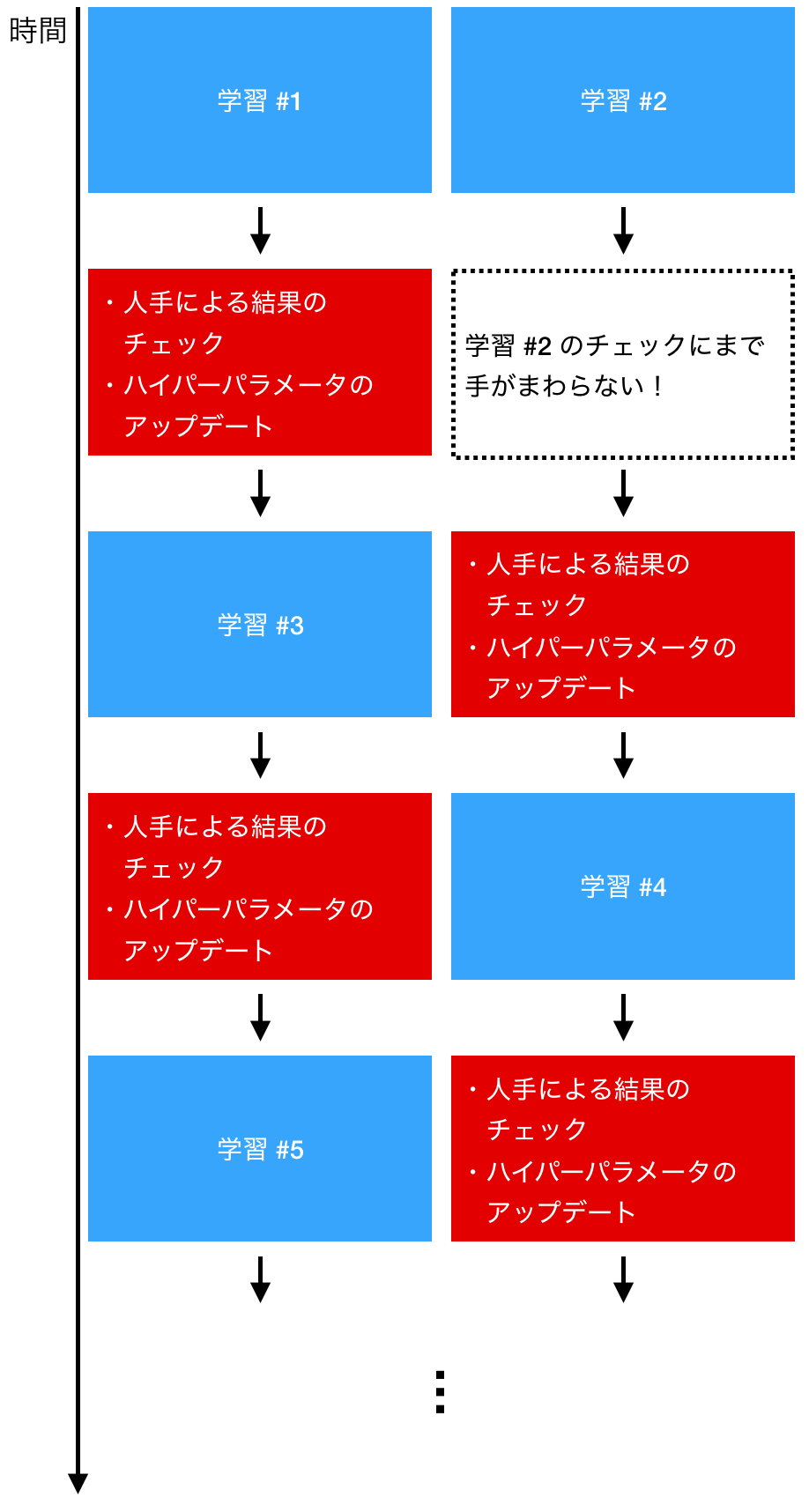
一方で、Optuna などのハイパーパラメータ自動最適化ツールを使った場合の例をいかに示します。人手が入る時間は限られているため、学習が効率的に回せていることが見て取れます。また、この方法であれば、 100 セットのハイパーパラメータで同時に学習させたとしても、学習回数はそれに応じてスケールしていきます。詳しくは後で述べますが、結果を評価する際も、スジのよいハイパーパラメータだけを見ればよいため、評価を行うコストも実はそこまで高くありません。
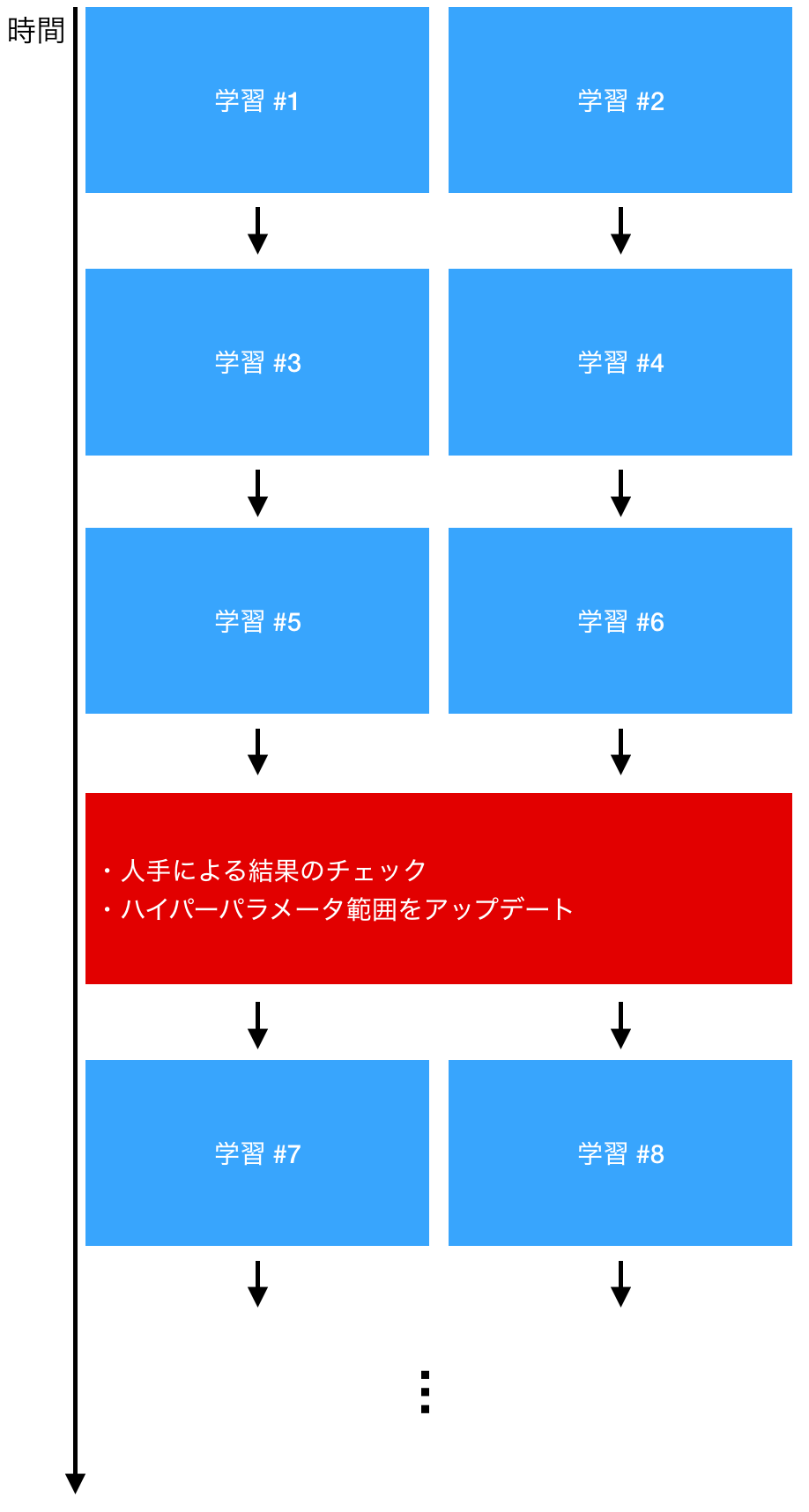
以上より、ハイパーパラメータ自動最適化ツールを使ったほうがより効率的に機械学習プロセスを回せそうであることがわかりました。当然、実際にはすべての点で自動最適化が勝っているわけではありません。ハイパーパラメータ自動最適化ツールとはいえ、どのハイパーパラメータを最適化するかをあらかじめ指定する必要があります(ハイパーパラメータ自動最適化ツールのハイパーパラメータ!)が、そういった制約から完全に自由である、人手による最適化が勝る可能性もゼロではないからです。
とはいえ、人手では試せる回数も限られたものになりますので、ハイパーパラメータ自動最適化ツールより性能がよいハイパーパラメータを見つけられたとしてもそれは「たまたま」かもしれません。実務上ではこういった「たまたま」に頼るよりは、試行回数をできるだけ増やしてなるべくうまくいく確率を統計的に増やしていくことが求められると思います。また、近年ではハイパーパラメータ自動最適化を含む領域として AutoML という対象が盛んに研究されており、こういった方向性は今後より一層強まっていくと予想できます。
Optuna でシンプルな最適化
ではいよいよ Optuna で最適化を行っていきましょう。いきなり深層学習の最適化を行ってもわかりにくいので、まずはシンプルな例からいきましょう。
問題として、サインウェーブのフィッティングを考えます。範囲 $[0, 2 \pi]$ をとる $x$ に対して、
y = \sin x
である $y$ を予測するモデルを、まずは多項式で立てます。
この際のハイパーパラメータとしては、多項式の次数を選びます。次数が 2 だったら 2 次関数で $\sin$ をフィッティングするということですね。
全体像
まずはコードの main 関数を示します。それぞれの関数やメソッドの中身はまだ説明していませんので、ここでは大まかなながれをつかんでいただければ十分です。流れとしては:
- データを作る
- ハイパーパラメータ最適化(
study)のための設定をする - 実際に最適化計算を行う
- もっともよかった結果を可視化する
といった流れとなっています。
from pathlib import Path
import optuna
STUDY_NAME = 'poly'
N_TRIALS = 10
MODEL_DIRECTORY = Path('models/poly')
def main():
# Generate dataset
prepare_dataset()
# Prepare study
if not MODEL_DIRECTORY.exists():
MODEL_DIRECTORY.mkdir(parents=True)
study = optuna.create_study(
study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db",
load_if_exists=True)
# Optimize
study.optimize(objective, n_trials=N_TRIALS)
# Visualize the best result
print('=== Best Trial ===')
print(study.best_trial)
evaluate_results(study.best_trial)
if __name__ == '__main__':
main()
study というのが今考えているタスクに対するハイパーパラメータ自動最適化の計算ワンセットを指していて、ハイパーパラメータをひとつセットして学習を 1 回行うことは trial と呼ばれています。trial がたくさんあつまってひとつの study をつくっているイメージですね。
データの作成
ではデータを作りましょう。 $x$ として $[0, 2 \pi]$ の範囲をとる一様乱数を作り、それに $\sin$ を作用させます。また、機械学習で使うデータでは (サンプルサイズ, 特徴量次元) の 2 次元配列になっていることが多いので、今回は特徴量次元を 1 として、 (DATA_SIZE, 1) 次元の配列として x と y を作ります。
import numpy as np
DATA_SIZE = 1000
DATASET_DIRECTORY = Path(f"./data/dataset_{DATA_SIZE}")
def generate_data(size=1000):
"""Generate training data.
Args:
length: int
The sample size of the data.
Returns:
x_train: numpy.ndarray
The input data for training.
y_train: numpy.ndarray
The output data for training.
x_valid: numpy.ndarray
The input data for validation.
y_valid: numpy.ndarray
The output data for validation.
"""
x = np.random.rand(size, 1).astype(np.float32) * 2 * np.pi
y = np.sin(x)
n_train = int(size * 0.8)
return x[:n_train], y[:n_train], x[n_train:], y[n_train:]
最後のところでは、データを train dataset と validation dataset に 8:2 の割合で分割しています。最適化計算のたびにデータを作るとデータが計算に時間がかかるばかりかデータも変わってしまうので、データがまだ作られていなかったらデータを作って保存する関数も別途作っておきます。
def prepare_dataset():
"""Prepare dataset for optimization."""
if not DATASET_DIRECTORY.exists():
DATASET_DIRECTORY.mkdir(parents=True)
x_train, y_train, x_valid, y_valid = generate_data(DATA_SIZE)
np.save(DATASET_DIRECTORY / 'x_train.npy', x_train)
np.save(DATASET_DIRECTORY / 'y_train.npy', y_train)
np.save(DATASET_DIRECTORY / 'x_valid.npy', x_valid)
np.save(DATASET_DIRECTORY / 'y_valid.npy', y_valid)
目的関数
次はいよいよ Optuna に直接関係する部分の実装です。Optuna では最小化したい目的関数(Objective function)を定義し、ハイパーパラメータを変化させながら目的関数の値を評価することで、ハイパーパラメータ自動最適化を行います。
import pickle
from sklearn.linear_model import Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
def objective(trial):
"""Objective function to make optimization for Optuna.
Args:
trial: optuna.trial.Trial
Returns:
loss: float
Loss value for the trial
"""
# Suggest hyperparameters
polynomial_degree = trial.suggest_int('polynomial_degree', 1, 10)
print('--')
print(f"Trial: {trial.number}")
print('Current hyperparameters:')
print(f" Polynomial degree: {polynomial_degree}")
print('--')
# Generate the model
model = make_pipeline(PolynomialFeatures(polynomial_degree), Ridge())
# Load dataset
x_train = np.load(DATASET_DIRECTORY / 'x_train.npy')
y_train = np.load(DATASET_DIRECTORY / 'y_train.npy')
x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy')
y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy')
# Train
model.fit(x_train, y_train)
# Save model
with open(MODEL_DIRECTORY / f"model_{trial.number}.pickle", 'wb') as f:
pickle.dump(model, f)
# Evaluate loss
loss = np.mean((model.predict(x_valid) - y_valid)**2)
return loss
ちょっと関数としては長いですが、やっていることはそんなに多くありません。順番に説明していきましょう。
まずは引数ですが、これは optuna.trial.Trial クラスのオブジェクトです。Optuna の最適化プロセスでは、この Trial オブジェクトを作っては objective 関数に渡して評価して……というのを繰り返します。つまりこの引数は Optuna によって自動で与えられるため、ユーザ自らこのオブジェクトを作って objective 関数を呼ぶことはあまりないと思います。
この中で特に重要なのが
# Suggest hyperparameters
polynomial_degree = trial.suggest_int('polynomial_degree', 1, 10)
の部分でしょう。ここでひとつの trial を行うためのハイパーパラメータを 1 セット(ここでは polynomial_degree のみ)を生成しています。polynomial_degree (多項式の次数)は整数値をとるため、 suggest_int メソッドを使ってハイパーパラメータを生成しています。引数の 'polynomial_degree' はパラメータの名前(結果の表示などで必要です)、そのあとの 1 と 10 はハイパーパラメータのとりうる最小値と最大値です。つまり、1 次関数 〜 10 次関数の間でフィッティングを試みようとしているということです。
他の部分はデータを読み込んだり、sklearn の model を作成してデータにフィッティングし保存したりしている部分です。最後に
# Evaluate loss
loss = np.mean((model.predict(x_valid) - y_valid)**2)
return loss
の部分ですが、validation dataset に対してモデルによる推定を行い、正解との平均二乗誤差(loss)を計算してそれを return しています。Optuna での最適化に使う目的関数の返り値は、必ず最小化したい値でなければいけません。
結果の可視化
結果の可視化の部分も軽く触れておきます。この関数は、引数として与えられた trial に対応するモデルのデータを読み込んで、validation dataset に対する結果をプロットするものです。
import matplotlib.pyplot as plt
def evaluate_results(trial):
"""Evaluate the optimization results.
Args:
study: optuna.trial.Trial
Returns:
None
"""
# Load model
trial_number = trial.number
with open(
MODEL_DIRECTORY / f"model_{trial_number}.pickle", 'rb') as f:
model = pickle.load(f)
# Load data
x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy')
y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy')
# Plot
plt.plot(x_valid, y_valid, '.', label='answer')
plt.plot(x_valid, model.predict(x_valid), '.', label='prediction')
plt.legend()
plt.show()
main 関数ふたたび
ここでふたたび main 関数の部分を示します。
def main():
# Generate dataset
prepare_dataset()
# Prepare study
if not MODEL_DIRECTORY.exists():
MODEL_DIRECTORY.mkdir(parents=True)
study = optuna.create_study(
study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db",
load_if_exists=True)
# Optimize
study.optimize(objective, n_trials=N_TRIALS)
# Visualize the best result
print('=== Best Trial ===')
print(study.best_trial)
evaluate_results(study.best_trial)
Optuna を直接使っている部分は study = optuna.create_study 以下なので、そこを説明します。
まず study の作成部分ですが、
study = optuna.create_study(
study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db",
load_if_exists=True)
このようになっています。 storage=f"sqlite:///{STUDY_NAME}.cb" となっていますが、これは変数が展開されて storage=f"sqlite:///poly.cb" となります。この部分で study のデータをどこに保存するかを指定しています。ここでは SQLite を使っているため、インストールしてデータベースサーバを立ち上げた上で実行する必要があります。また、 load_if_exists=True としているので、すでに DB が存在していた場合はそのデータを読み込んで、最適化を再開します。
もし SQLite 関連でうまくいかない場合は、該当する場所を
study = optuna.create_study(
study_name=STUDY_NAME)
のように書き換えてください。データが保存されませんが、SQLite のインストールなどは不要になります。
実際にハイパーパラメータの自動最適化を実行している部分は
study.optimize(objective, n_trials=N_TRIALS)
です。目的関数として上で定義した objective を与えており、それに基づいて N_TRIALS に指定した回数だけ trial を行い、study を終了します。
実行
全体のコードは こちら にありますので、git clone などでダウンロードした上で、ターミナル上で
$ python3 poly.py
とすれば、data/dataset_1000 にデータセットが作成され、モデルのパラメータが models/poly に保存されながら以下のような結果がターミナルに表示されるはずです。
[I 2019-05-27 04:41:29,531] A new study created with name: poly
--
Trial: 0
Current hyperparameters:
Polynomial degree: 8
--
[I 2019-05-27 04:41:29,654] Finished trial#0 resulted in value: 0.0005262039485387504. Current best value is 0.0005262039485387504 with parameters: {'polynomial_degree': 8}.
--
Trial: 1
Current hyperparameters:
Polynomial degree: 2
--
[I 2019-05-27 04:41:29,754] Finished trial#1 resulted in value: 0.19891643524169922. Current best value is 0.0005262039485387504 with parameters: {'polynomial_degree': 8}.
...
[I 2019-05-27 04:41:30,626] Finished trial#9 resulted in value: 0.004659125581383705. Current best value is 5.815048280055635e-05 with parameters: {'polynomial_degree': 5}.
=== Best Trial ===
FrozenTrial(number=2, state=<TrialState.COMPLETE: 1>, value=5.815048280055635e-05, datetime_start=datetime.datetime(2019, 5, 27, 4, 41, 29, 755017), datetime_complete=datetime.datetime(2019, 5, 27, 4, 41, 29, 843021), params={'polynomial_degree': 5}, distributions={'polynomial_degree': IntUniformDistribution(low=1, high=10)}, user_attrs={}, system_attrs={'_number': 2}, intermediate_values={}, params_in_internal_repr={'polynomial_degree': 5.0}, trial_id=3)
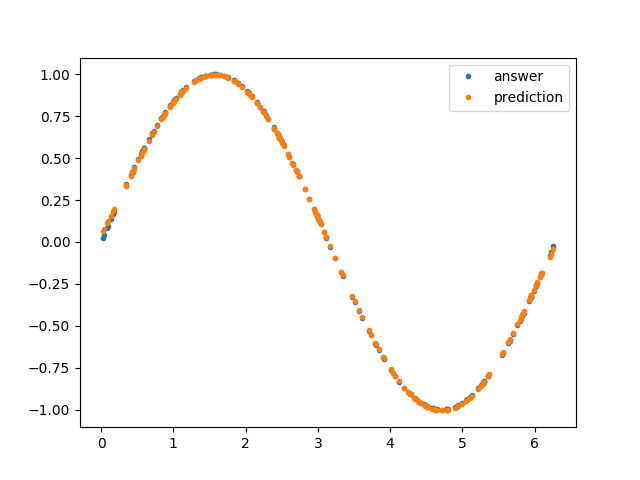
最適化が終わったら、試した中でもっともスコアがよかった(best_trial)ときのハイパーパラメータが表示されます。試されたハイパーパラメータとその結果はすべてデータベースに保存されているため、スコアの高い順に n 個データをとってくるなども簡単にでき、結果として人手によるチェックのコストを下げてくれています。私が実行したところによると、 'polynomial_degree': 5 のときに validation dataset に対する loss が 5.815048280055635e-05 で最小になったようです。また、それを用いた結果の可視化として下のようなグラフも表示されるはずです。
Optuna + Chainer で深層学習のハイパーパラメータ最適化
では Chainer で多層パーセプトロン(MLP)を作って、そのハイパーパラメータを Optuna で自動最適化してみましょう。タスクは先ほどと同様、$\sin$ のフィッティングとします。また、ハイパーパラメータとしては:
- 層の数
- 層を構成するユニットの個数
- 活性化関数
を選びました。
全体像
全体像自体もあまり変わりませんが、 main 関数まわりをまず示します。
import optuna
STUDY_NAME = 'mlp'
N_TRIALS = 100
PRUNER_INTERVAL = 100
def main():
# Generate dataset
prepare_dataset()
# Prepare study
study = optuna.create_study(
study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db",
load_if_exists=True, pruner=optuna.pruners.MedianPruner())
# Optimize
study.optimize(objective, n_trials=N_TRIALS)
# Visualize the best result
print('=== Best Trial ===')
print(study.best_trial)
evaluate_results(study.best_trial)
if __name__ == '__main__':
main()
ここで重要な変更はひとつだけで、
study = optuna.create_study(
study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db",
load_if_exists=True, pruner=optuna.pruners.MedianPruner())
のところです。新しい引数として pruner=optuna.pruners.MedianPruner() を与えていますが、これは pruning (枝刈り)と呼ばれる、途中で明らかにダメそうな学習を早めに打ち切る機能です。人手でハイパーパラメータチューニングをするときも、10 epoch くらい走らせてみてダメそうだったら学習を止めて別のハイパーパラメータを試しますよね。それを機械がやってくれるということです。ただし、 pruning を行うには学習器自体にも設定が必要で、それは後述します。
目的関数
データ生成の部分はまったく同じなので、目的関数から見ていきましょう。
from pathlib import Path
import chainer as ch
import optuna
PRUNER_INTERVAL = 100
EPOCH = 1000
DATA_SIZE = 5000
BATCH_SIZE = 100
GPU_ID = -1 # Set value >= 0 to use GPU (-1: CPU mode)
DATASET_DIRECTORY = Path(f"./data/dataset_{DATA_SIZE}")
MODEL_DIRECTORY = Path('models/mlp')
def objective(trial):
"""Objective function to make optimization for Optuna.
Args:
trial: optuna.trial.Trial
Returns:
loss: float
Loss value for the trial
"""
# Generate model
classifier = generate_model(trial)
# Create dataset
x_train = np.load(DATASET_DIRECTORY / 'x_train.npy')
y_train = np.load(DATASET_DIRECTORY / 'y_train.npy')
x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy')
y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy')
# Prepare training
train_iter = ch.iterators.SerialIterator(
ch.datasets.TupleDataset(x_train, y_train),
batch_size=BATCH_SIZE, shuffle=True)
valid_iter = ch.iterators.SerialIterator(
ch.datasets.TupleDataset(x_valid, y_valid),
batch_size=BATCH_SIZE, shuffle=False, repeat=False)
optimizer = ch.optimizers.Adam()
optimizer.setup(classifier)
updater = ch.training.StandardUpdater(train_iter, optimizer, device=GPU_ID)
stop_trigger = ch.training.triggers.EarlyStoppingTrigger(
monitor='validation/main/loss', check_trigger=(100, 'epoch'),
max_trigger=(EPOCH, 'epoch'))
trainer = ch.training.Trainer(
updater, stop_trigger,
out=MODEL_DIRECTORY/f"model_{trial.number}")
log_report_extension = ch.training.extensions.LogReport(
trigger=(100, 'epoch'), log_name=None)
trainer.extend(log_report_extension)
trainer.extend(ch.training.extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss']))
trainer.extend(ch.training.extensions.snapshot(
filename='snapshot_epoch_{.updater.epoch}'))
trainer.extend(ch.training.extensions.Evaluator(valid_iter, classifier))
trainer.extend(ch.training.extensions.ProgressBar())
trainer.extend(
optuna.integration.ChainerPruningExtension(
trial, 'validation/main/loss', (PRUNER_INTERVAL, 'epoch')))
# Train
trainer.run()
loss = log_report_extension.log[-1]['validation/main/loss']
return loss
処理は長くなっていますが、やっていることは多項式のときとそう変わりません。Chainer に慣れ親しんでいる方なら見慣れた処理が多いと思います(Updater や Trainer を使わずに Chainer をやっている方は、もったいないのでこのタイミングでそれらの使い方をおさえておきましょう)。ただ唯一
trainer.extend(
optuna.integration.ChainerPruningExtension(
trial, 'validation/main/loss', (PRUNER_INTERVAL, 'epoch')))
のところは Optuna に由来する部分で、これが例の pruning のための設定その 2 です。いま PRUNER_INTERVAL = 100 としているので、 100 epoch おきに学習をとめるかどうか判断するという設定になっています。別途 stop_trigger として early stopping の設定もしていますので、
- 望みのなさそうなハイパーパラメータでの学習は早めに止める(pruning)
- 望みがありそうなハイパーパラメータでの学習でも、学習が停滞したら止める(early stopping)
の 2 重の構えになっています。したがって、最大のエポック数 EPOCH = 5000 としていますが、私がためした限りでは 5000 epoch フルに学習が走った trial はありませんでした。適切なタイミングで学習を(自動的に)止めるのも、より多くのハイパーパラメータを試すための重要なファクターになっています。
モデルの生成
上の目的関数のところで、モデルの生成部分は
# Generate model
classifier = generate_model(trial)
と、別の関数に置き換えてあっさり終わってしまっていました。実はこの部分こそが Optuna で深層学習をやるための重要な部分です。ハイパーパラメータ自動最適化ツールで深層学習を行いたい場合、もっとも重要なことは
- モデル生成をできるだけ柔軟にできるようにする
ことです。ハイパーパラメータ自動最適化ツールではハイパーパラメータを何か選んできてそれをもとにモデルを作るわけですが、裏を返せばモデル生成をパラメトリックに行える必要があります。ではそれを気にしながらモデル生成部分のコードを見ていきましょう。
def generate_model(trial):
"""Generate MLP model.
Args:
trial: optuna.trial.Trial
Returns:
classifier: chainer.links.Classifier
"""
# Suggest hyperparameters
layer_number = trial.suggest_int('layer_number', 2, 5)
activation_name = trial.suggest_categorical(
'activation_name', ['relu', 'sigmoid'])
unit_numbers = [
trial.suggest_int(f"unit_number_layer{i}", 10, 100)
for i in range(layer_number - 1)] + [1]
dropout_ratio = trial.suggest_uniform('dropout_ratio', 0.0, 0.2)
print('--')
print(f"Trial: {trial.number}")
print('Current hyperparameters:')
print(f" The number of layers: {layer_number}")
print(f" Activation function: {activation_name}")
print(f" The number of units for each layer: {unit_numbers}")
print(f" The ratio for dropout: {dropout_ratio}")
print('--')
# Generate the model
model = MLP(
unit_numbers, activation_name=activation_name,
dropout_ratio=dropout_ratio)
classifier = ch.links.Classifier(
model, lossfun=ch.functions.mean_squared_error)
classifier.compute_accuracy = False
return classifier
モデル生成部分はこのようになっており、前半部分は trial.suggest_*** でそれぞれに合った型のハイパーパラメータを生成しています。 unit_numbers (各層を構成するユニットの個数)は int の配列ですが、 layer_number (層の数)によって配列の長さ(=ハイパーパラメータの個数)が動的に変わります。こういった、ハイパーパラメータの数が動的に変化するような問題に対しても最適化を行える柔軟性が Optuna の長所のひとつだと思います1。また、今回は MLP の出力(y)の特徴量次元は 1 なので、 unit_numbers の末尾に 1 を付け足しています。このようにして作成されたハイパーパラメータは、たとえば
Current hyperparameters:
The number of layers: 4
Activation function: sigmoid
The number of units for each layer: [36, 99, 87, 1]
The ratio for dropout: 0.6906857740018953
のようになっています。
ハイパーパラメータが無事生成できたところで、モデルの具体的な生成の実装に移っていきます。モデルの実装は以下のようになっています。
class MLP(ch.ChainList):
"""Multi Layer Perceptron."""
def __init__(
self, unit_numbers, activation_name, dropout_ratio):
"""Initialize MLP object.
Args:
unit_numbers: list of int
List of the number of units for each layer.
activation_name: str
The name of the activation function applied to layers except
for the last one (The activation of the last layer is always
identity).
dropout_ratio: float
The ratio of dropout. Dropout is applied to all layers.
Returns:
None
"""
super().__init__(*[
ch.links.Linear(unit_number)
for unit_number in unit_numbers])
self.activations = [
self._create_activation_function(activation_name)
for _ in self[:-1]] \
+ [ch.functions.identity] # The last one is identity
self.dropout_ratio = dropout_ratio
def _create_activation_function(self, activation_name):
"""Create activation function.
Args:
activation_name: str
The name of the activation function.
Returns:
activation_function: chainer.FunctionNode
Chainer FunctionNode object corresponding to the input name.
"""
if activation_name == 'relu':
return ch.functions.relu
elif activation_name == 'sigmoid':
return ch.functions.sigmoid
elif activation_name == 'identity':
return ch.functions.identity
else:
raise ValueError(f"Unknown function name {activation_name}")
def __call__(self, x):
"""Execute the NN's forward computation.
Args:
x: numpy.ndarray or cupy.ndarray
Input of the NN.
Returns:
y: numpy.ndarray or cupy.ndarray
Output of the NN.
"""
h = x
for i, link in enumerate(self):
h = link(h)
if i + 1 != len(self):
h = ch.functions.dropout(h, ratio=self.dropout_ratio)
h = self.activations[i](h)
return h
ChainList クラスを継承して MLP クラスを定義しました。 ChainList は層の数がわかっていなくても定義が書けるので、このような場合には重宝します。重要なメソッドをひとつひとつ見ていきます。まずはオブジェクトの初期化部分ですが、
def __init__(
self, unit_numbers, activation_name, dropout_ratio):
"""Initialize MLP object.
Args:
unit_numbers: list of int
List of the number of units for each layer.
activation_name: str
The name of the activation function applied to layers except
for the last one (The activation of the last layer is always
identity).
dropout_ratio: float
The ratio of dropout. Dropout is applied to all layers.
Returns:
None
"""
super().__init__(*[
ch.links.Linear(unit_number)
for unit_number in unit_numbers])
self.activations = [
self._create_activation_function(activation_name)
for _ in self[:-1]] \
+ [ch.functions.identity] # The last one is identity
self.dropout_ratio = dropout_ratio
のようになっています。unit_numbers の長さの分だけ chainer.links.Linear オブジェクト(重みとバイアス)が生成されていることがわかると思います。また、 self.activations では各層の活性化関数を定義しているのですが、出力層のみ chainer.functions.identity (恒等写像=何もしない関数)、ほかはハイパーパラメータとして与えられた activation_name をとるようにしています。
ネットワークの foward 部分は、以下のようになっています。こちらでは層の数だけループを回して、線形変換とドロップアウト、活性化関数の適用を行っています。ただし、出力層にはドロップアウトを適用しないようにしています。
def __call__(self, x):
"""Execute the NN's forward computation.
Args:
x: numpy.ndarray or cupy.ndarray
Input of the NN.
Returns:
y: numpy.ndarray or cupy.ndarray
Output of the NN.
"""
h = x
for i, link in enumerate(self):
h = link(h)
if i + 1 != len(self):
h = ch.functions.dropout(h, ratio=self.dropout_ratio)
h = self.activations[i](h)
return h
結果の可視化
残るは結果の可視化の部分です。こちらも多項式のときと同様、指定された trial に対応するモデルをロードして推測させ、答えと比較しています。
def evaluate_results(trial):
"""Evaluate the optimization results.
Args:
study: optuna.trial.Trial
Returns:
None
"""
# Load model
trial_number = trial.number
unit_numbers = []
for i in range(100):
param_key = f"unit_number_layer{i}"
if param_key not in trial.params:
break
unit_numbers.append(trial.params[param_key])
model = MLP(
unit_numbers + [1], trial.params['activation_name'],
trial.params['dropout_ratio'])
snapshots = glob.glob(str(MODEL_DIRECTORY / f"model_{trial_number}" / '*'))
latest_snapshot = max(
snapshots, key=os.path.getctime) # The latest snapshot of the trial
print(f"Loading: {latest_snapshot}")
ch.serializers.load_npz(
latest_snapshot, model, path='updater/model:main/predictor/')
# Load data
x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy')
y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy')
# Plot
plt.plot(x_valid, y_valid, '.', label='answer')
with ch.using_config('train', False):
predict = model(x_valid).data
plt.plot(x_valid, predict, '.', label='prediction')
plt.legend()
plt.show()
まず予備知識として、 trial.params は例えば {'activation_name': 'sigmoid', 'dropout_ratio': 0.1948279849856978, 'layer_number': 5, 'unit_number_layer0': 77, 'unit_number_layer1': 56, 'unit_number_layer2': 51, 'unit_number_layer3': 80} のような辞書型のオブジェクトとしてその trial のハイパーパラメータを保持しています。したがって、これらのハイパーパラメータを使ってモデルを再構成し、(ハイパーでない)パラメータを読み込めばいいわけです。パラメータの読み込みでは、その trial のもっとも新しい snapshot を見つけてきてそれを読み込んでいます。
ちょっとややこしいのが unit_numbers を読み込んでいるところで、unit_numbers の長さが不定のため、ひとつひとつ読みながら配列に要素を追加していっています。このあたりが Optuna にがんばってほしいところで、配列などもハイパーパラメータとして扱えるようになればかなり取り回しがしやすくなると思います。
実行
全体のコードは こちら にありますので、git clone などでダウンロードした上で、ターミナル上で
$ python3 mlp.py
とすれば、モデルのパラメータが models/mlp に保存されながら以下のような結果がターミナルに表示されるはずです。
[I 2019-05-27 15:26:18,496] Using an existing study with name 'mlp' instead of creating a new one.
--
Trial: 0
Current hyperparameters:
The number of layers: 3
Activation function: sigmoid
The number of units for each layer: [83, 80, 1]
The ratio for dropout: 0.043383365517199284
--
epoch main/loss validation/main/loss
100 0.131512 0.123286
200 0.0594965 0.0570084
300 0.0364821 0.0299548
400 0.0196009 0.00784213
500 0.014053 0.00332701
600 0.0111817 0.0023173
700 0.00912656 0.00166577
800 0.00797004 0.00153381
900 0.006777 0.0012653
1000 0.00608755 0.00110705
1100 0.00560331 0.00109022
1200 0.00517723 0.00108871
1300 0.00489841 0.00112543
1400 0.00468537 0.00100757
1500 0.00446898 0.000979245
1600 0.00428505 0.000921101
1700 0.00424085 0.000983566
1800 0.00405002 0.000959924
1900 0.00384459 0.000955113
[I 2019-05-27 15:28:03,244] Finished trial#0 resulted in value: 0.0009551127247686964. Current best value is 0.0009551127247686964 with parameters: {'activation_name': 'sigmoid', 'dropout_ratio': 0.043383365517199284, 'layer_number': 3, 'unit_number_layer0': 83, 'unit_number_layer1': 80}.
--
Trial: 1
Current hyperparameters:
The number of layers: 5
Activation function: relu
The number of units for each layer: [53, 87, 75, 12, 1]
The ratio for dropout: 0.10755231083048578
--
epoch main/loss validation/main/loss
100 0.249045 0.225993
200 0.0869799 0.0862519
...
=== Best Trial ===
FrozenTrial(number=1, state=<TrialState.COMPLETE: 1>, value=0.00015463905489013997, datetime_start=datetime.datetime(2019, 5, 27, 7, 15, 22, 258062), datetime_complete=datetime.datetime(2019, 5, 27, 7, 16, 59, 707008), params={'activation_name': 'sigmoid', 'dropout_ratio': 0.0032366848483553535, 'layer_number': 3, 'unit_number_layer0': 41, 'unit_number_layer1': 18}, distributions={'activation_name': CategoricalDistribution(choices=('relu', 'sigmoid')), 'dropout_ratio': UniformDistribution(low=0.0, high=0.2), 'layer_number': IntUniformDistribution(low=2, high=5), 'unit_number_layer0': IntUniformDistribution(low=10, high=100), 'unit_number_layer1': IntUniformDistribution(low=10, high=100)}, user_attrs={}, system_attrs={'_number': 1}, intermediate_values={100: 0.0697100069373846, 200: 0.04887961223721504, 300: 0.036658125929534435, 400: 0.01331155956722796, 500: 0.001735480735078454, 600: 0.00048741648788563907, 700: 0.00028684467542916536, 800: 0.0001745481313264463, 900: 0.0001783440457074903, 1000: 0.00014417021156987175, 1100: 0.00017049246162059717, 1200: 0.00015490048099309206, 1300: 0.0001087129203369841, 1400: 0.00011426526543800719, 1500: 0.0001357111832476221, 1600: 0.00020704924827441573, 1700: 0.00016470269474666566}, params_in_internal_repr={'activation_name': 1.0, 'dropout_ratio': 0.0032366848483553535, 'layer_number': 3.0, 'unit_number_layer0': 41.0, 'unit_number_layer1': 18.0}, trial_id=2)
途中で
--
Trial: 98
Current hyperparameters:
The number of layers: 4
Activation function: sigmoid
The number of units for each layer: [22, 49, 60, 1]
The ratio for dropout: 0.8962421296002223
--
epoch main/loss validation/main/loss
Exception in main training loop: Trial was pruned at epoch 50.] 5.00%
Traceback (most recent call last):............................] 0.00%
File "/usr/local/var/pyenv/versions/3.7.3/lib/python3.7/site-packages/chainer/training/trainer.py", line 319, in runers/sec. Estimated time to finish: 0:01:00.705030.
entry.extension(self)
File "/usr/local/var/pyenv/versions/3.7.3/lib/python3.7/site-packages/optuna/integration/chainer.py", line 109, in __call__
raise optuna.structs.TrialPruned(message)
Will finalize trainer extensions and updater before reraising the exception.
[I 2019-05-27 05:59:31,203] Setting status of trial#98 as TrialState.PRUNED. Trial was pruned at epoch 50.
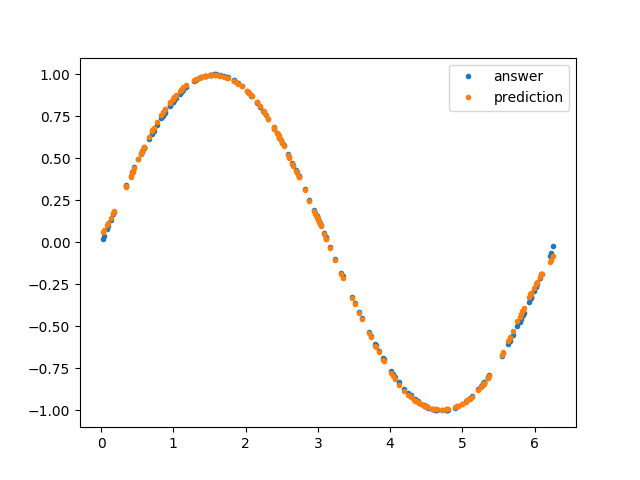
のような出力が出ていたら、その trial は Pruning されているということで、Pruning が動いていることも確認できると思います。最適化が終わったら(20 〜 30 分ほどかかるかもしれませんので、ログを眺めつつこの記事を読み返してみるのもいいかもしれません)、下のようなグラフも表示されるはずです(タスクが単純すぎたので、多項式よりよくなっているわけではないのが世知辛いですが)。
おわりに
この記事では、簡単なデータを作成して、その回帰問題に対して Optuna によるハイパーパラメータ最適化を行う方法を解説しました。Optuna は機械学習タスクのハイパーパラメータ最適化だけでなく、さまざまなブラックボックス最適化にもつかえるようなジェネラルなフレームワークだと思います。これを使いこなすことによって最適化タスクが格段に便利になることは確かだと思いますので、ぜひ使いこなして業務を効率化していきましょう!
-
ただし、実用上はユニットの数を層によってばらつかせることはあまりなく、中間層のユニット数は同じにすることが多いかもしれません。ここでは、Optuna のキャパシティを見るためにもあえて層ごとにユニット数を変えています。 ↩