新年あけましてメリークリスマス!!!!!!!!!
今日は2023年1月3日。これはKLab Engineer Advent Calendar 2022の21+13日目の記事です。年末年始は寝てばかりでクリスマスらしいことができなかったので、体感ではまだクリスマス前です。
21日からコロナでダウンしてたんですが、やっと回復してきたと思ったら今度は家族にうつしてしまった…(みんなごめん
— はま (@hmkz_) December 26, 2022
Advent Calendarはもう少しお待ちください
2020年7月にKLabに転職してから、機械学習グループの立ち上げメンバーの一人として色々なことをしてきました。この記事ではそれを振り返ってみます。
KLab機械学習グループとは
機械学習を使ってゲーム開発を支援したり、運用を効率化したり、アナリティクスチーム単独では難しいような分析をしたり、最近ではゲーム内で機械学習を活用して新しいゲーム体験の創出にも挑戦したりと、あらゆるゲームタイトルと職種を横断的に支援するグループです。私が入社する以前から機械学習をしていたメンバーとともに、2021年1月に正式な部署として立ち上げました。現在はマネージャー2名、エンジニア5名(兼任含む)で活動しています。
モバイルゲームは機械学習の理想的な実践の場
モバイルゲーム会社には豊富なデータがあり、機械学習で解決できる様々な課題を抱えています。ゲーム開発においては、グラフィックス、サウンド、テキスト、レベルデザインなどを大量に制作します。近年、モバイルゲームの表現力向上はめざましく、制作の効率化がとても重要になってきています。リリースしたゲームは何年も運用され、日々テラバイト級のログが溜まっていきます。それを分析して今後の施策を考えたり、不正利用を検知したりします。さらに、スマホはセンサーの塊です。タッチパネル、マイク、カメラ、GPS、加速度センサーやジャイロセンサーなどなど。最近はAR(拡張現実)アプリなどで、複数のセンサーデータを活用してゲーム表現を豊かにする機会が増えてきています。ゲームはある意味で失敗が許される、試行錯誤しやすい環境なのもいいところです。機械学習モデルも、一定の品質に達したら見切り発車して実運用のなかでブラッシュアップしていくことができます。
一方で、モバイルゲームには特有の制約があり、既存の機械学習をそのまま使うだけでなく、独自の手法を研究開発することも求められます。ゲームの世界観にマッチしたアセットを生成するために、基盤モデルに対してファインチューニングを行ったり、独自のモデルを構築してスクラッチから学習したりします。アクセスログを用いたアソシエーション分析や異常検知といった定番のタスクでも、ゲームのストア商品やイベント施策は1回限りであることが多く、高精度化には様々な工夫が必要になります。ゲーム中に機械学習を動作させる場合にはさらに大変です。スマホという非力なデバイスで、計算リソースはゲーム自体の処理にほぼ使い果たしているなかで、リアルタイムに機械学習を処理しなければなりません。通信遅延やアプリの中断も頻繁に起こります。こういった様々な制約に対処するために、KLabでは独自の機械学習アルゴリズムを研究しています。
また、モバイルゲームは非常に変化の速い業界です。KLabでは、2週間に1度のペースで新規コンテンツをリリースしているゲームタイトルを複数運用しています。他社からも日々新作がリリースされ、ユーザーを取り巻く環境も変わっていきます。これに追従するスピードで研究開発し、運用現場が「いま」必要とするものをタイムリーに届けなければなりません。
ゲーム業界にはこれだけチャレンジングな課題が眠っており、魅力的な研究開発環境が整っているのですが、そのことはまだ世間にはあまり知られていないのではないでしょうか。これまでKLabでは、GDCやCEDECなどのゲーム系カンファレンスを主体に自社の取り組みを発信してきました。しかし世界中で機械学習人材の獲得競争が激化しています。業界内でのプレゼンスだけでなく、世の中のあらゆる業種と比べても機械学習人材にとって魅力的な職場として世間に認知してもらえるように、これからはゲーム業界の外からも注目されるような成果をコンスタントに発信していきたいと考えています。
ResDevOps
「機械学習の研究~開発~運用までを少人数・短期間で行う」という非常に欲張りな要望に応えられるチームを作るために、KLabに入社してから機械学習グループのあり方を探ってきました。研究要素を含む機械学習チームの組織運営については、あまり体系化された資料が見つからなかったので、一般的なMLOpsやDevOpsの資料で紹介されるベストプラクティスを参考にしつつも、かなり自己流にアレンジしたものになっています。そのプラクティスをまとめたものを最近は ResDevOps とよぶことにしています1。
ResDevOpsの基本的な考え方をまとめたものが以下の図です。

図の左側は、世間一般でよくある研究の進め方です。このようにウォーターフォールで進めると、研究チームと開発・運用チームの間でのタイムラグや目標の違いによって、現場のニーズにフィットした成果をタイムリーに提供することが難しくなりがちです。
- 4月、年度初めだ。今年の研究テーマを決めよう。成果の受取先があるか分からないけれど、学会でトレンドのテーマならきっとどこかで役に立つだろう…
- 10月、SOTAを超えようと試行錯誤しているうちに、ハイパラてんこ盛りモデルになってしまった!実務で使いにくそうだけど、査読に通すためにはしょうがない……論文採択!やっぱりこれでよかったんだ!
- 12月、そろそろ技術の応用先を探さないと。現場のニーズと違うけど、今更カスタマイズする時間もないし、このまま使ってもらおう。コードがぐちゃぐちゃで引き継げない?エンジニアにスクラッチから書き直してもらうか…
- 3月、やっと再実装できた。え?サービス変更で不要になった?使われないのは残念だけど、論文は出たからまぁいいか(1に戻る)
ResDevOpsはこのようなギャップを乗り越えるためのプラクティスです。図の右側のように、研究 (Res) をDevOpsのイテレーションと同じ2週間のスプリント単位で回し、同じペースで動けるようにします。研究成果の受取先となるチームとスプリント毎のミーティングで協調し、研究のワークフローを自動化してDevOps側のCI/CDと接続し、継続的に研究成果を運用現場に届けます。そして最新の研究成果について即座に開発・運用からフィードバックを受け、研究内容を反復的に改善していきます。ResDevOpsにおける研究は、典型的には以下のように進みます。
- 研究をスタートする前に、成果の受入先となるプロジェクトを具体的に定め、ヒアリングを行って「いつまでにどんなアウトカムが必要か、そのために何を作り、それをどう運用して、どの程度の事業価値を生み出すか」について現時点での見通しを明確化します。既存のツールを組み合わせて実際に現場で運用できるMinimum Viable Productを最速で提供し、これを研究のベースラインとします。(たとえば、機械学習APIを呼ぶだけで作れるモデルに最低限のUIを被せたツールなど)
- 研究スプリントは、一般的なアジャイル開発のプラクティスにしたがって行います。2週間ごとに今回のスプリントで研究した成果を取り入れた新バージョンをリリースし、開発・運用チームから使用した感想をもらい、フィードバックに基づいて次のスプリントで研究する内容を計画します。
- 成果を滞りなく届けるために、技術の中身だけでなくコード品質やドキュメントも継続的に改善していきます。研究用のコードであっても、適切な設計とコーディング規約に基づいて実装し、型やテスト、コメントをつけます。コードや学習データをバージョン管理するのはもちろん、動作環境や実験設定もコード化してバージョン管理し、すべての実験をいつでもワンコマンドで再現できるようにします。ワークフローを自動化してDevOps側のCI/CDと接続し、成果が運用現場まで自動的にデプロイされるようにします。
- 研究成果が一定の水準に達したところで、カンファレンスで発表したり、論文を書いたりします。ユーザー向けに用意したドキュメントがすでにあるため、それを転用してスライドや論文を作ることができます。技術のコア部分のコードを切り出せば、再現実験用のコードを公開することもできます(そうできるように設計しておきます)。ゲームの運用中に発表できるため、ゲームの宣伝にもなります。
このように、ResDevOpsでは、2週間のスプリントを反復単位として事業貢献と学術貢献を並行して行っていきます。とはいえ、研究とは本来とても時間のかかるものですから、いくらアジャイル開発を真似たところで短期間に成果を出すのは難しいものです。研究成果創出までのリードタイムを短縮するために、複数人が並行して1つのアルゴリズムを改善できるようにしています。具体的には、GitHub Flowにしたがって研究アイデアを実装・検証します。各自が検証したい研究アイデアごとにfeatureブランチを切り、アルゴリズムを実装し、実験します。実験で改善が確認できたら、mainブランチにマージします。下の図は1つの研究プロジェクトにおける2021年4月3週目のコミット履歴です。わずか1週間に4つもの研究アイデアが実装・検証され、mainブランチに取り入れられていることが読み取れます。
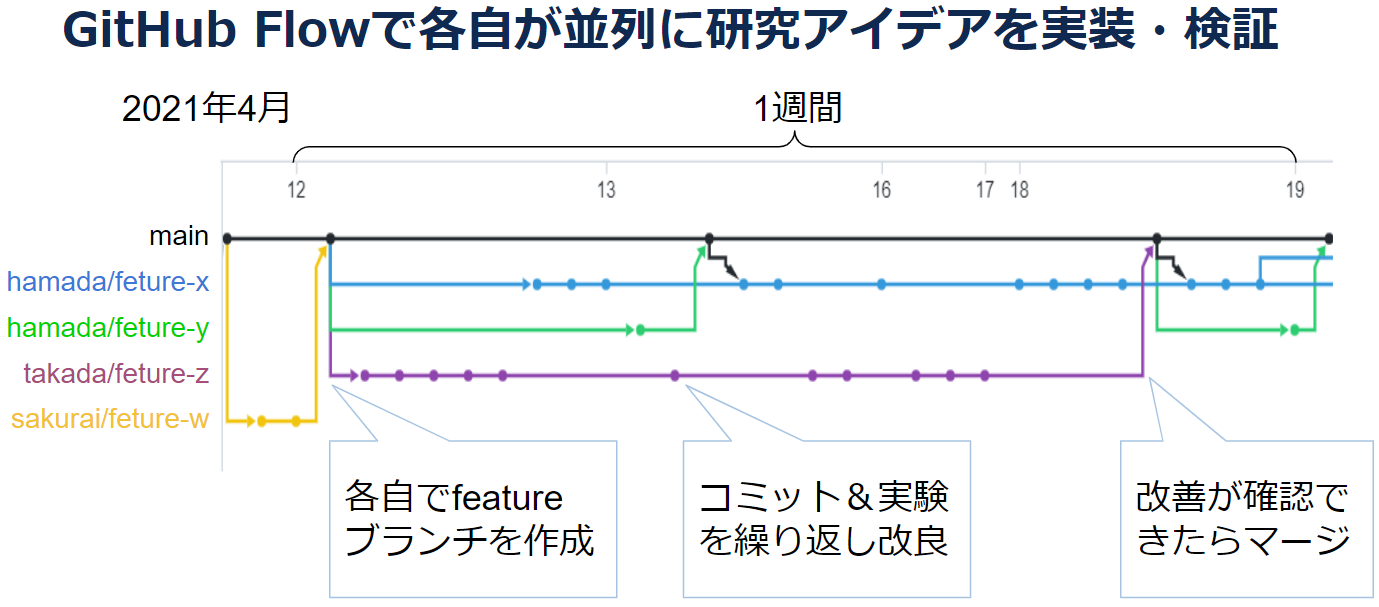
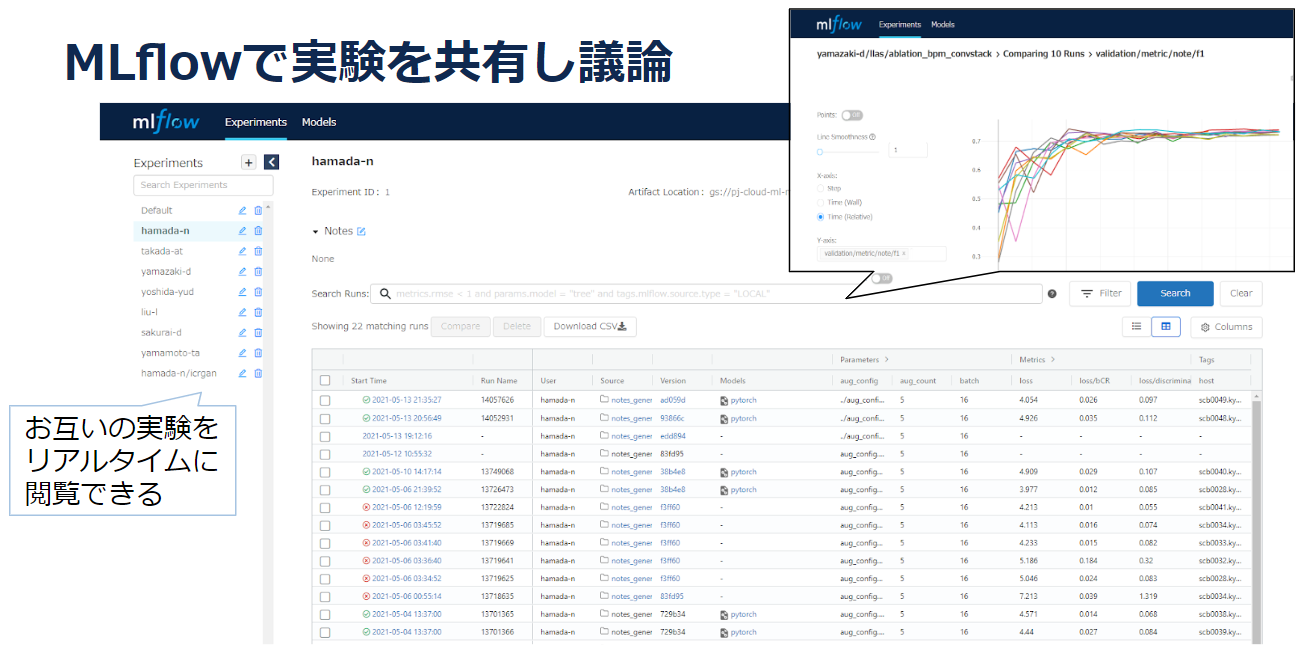
実験はMLflowで共有します。Pull Requestでは、コードレビューのみでなく実験結果もレビューします。こうすることで、それぞれの改善によってどれだけ性能が向上したのか、性能検証の実験設定に問題がないかがダブルチェックできます。すべての改善の影響がトレーサブルになっていることで、のちのち論文を執筆する際にも比較実験のセクションをスムーズにまとめることができます。
1回の実験にマルチGPUで何時間もかかるような大規模モデルを扱うこともしばしばあります。そのような場合でも気軽に十分な試行回数の実験を行えるように、学習基盤としてスパコンとクラウドを併用しています。九州大学と共同研究でスパコンITOのGPUノードをお借りして、大規模実験はスパコンで行っています。
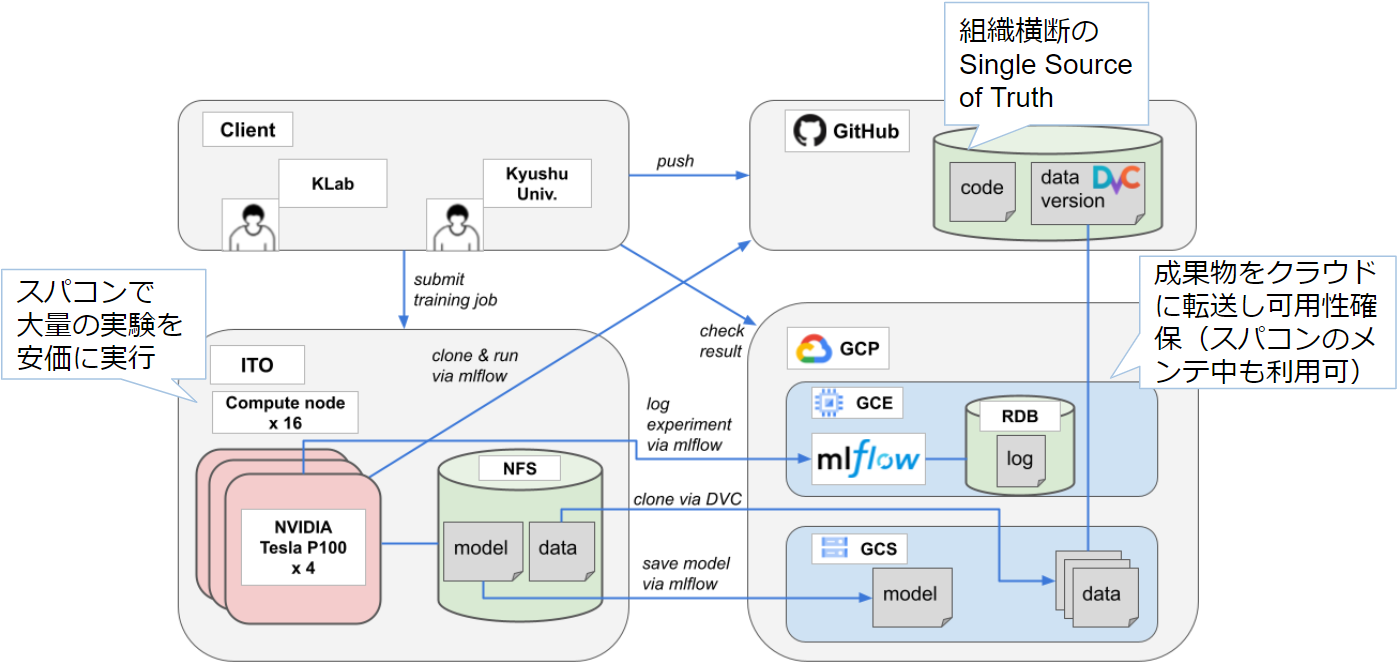
このスパコンとクラウドのハイブリッド学習基盤では、
- スパコンにジョブを投入すると、その実験設定に応じて、クラウドに保管されたコードや学習データの特定バージョンを自動的にスパコンに転送し、実行する仕組み
- 実験のログや訓練済みモデルをリアルタイムにクラウドに転送し、実験の進捗をクラウド上でモニタリングできる仕組み
を構築しています。このようにして、スパコンのスループットとコストパフォーマンス、クラウドの可用性と運用性をいいとこどりすることにより、少人数・低予算でハイスピードな研究開発を実現しています。実際のところどの程度ResDevOpsを実践できているかを示す例として、2021年の共同研究で計測したメトリクスを紹介します。
| 指標 | 定義 | 値 |
|---|---|---|
| $A$. 研究期間 | 2021年4月~2021年12月 | 9か月 |
| $B$. 実働人数 | 1度以上コミットしたユーザーの数 | 6人 |
| $C$. 検証した研究アイデアの数 | MLflow Experimentsの数 | 234件 |
| $D$. 実験の試行回数 | 投入したジョブの数 | 5,807件 |
| $E$. のべ計算時間 | ノード数 x GPU数 x ジョブ実行時間 | 82,500GPU時間 |
| $F$. 採用された改善の数 | mainにマージされたブランチの数 | 115件 |
| $G$. 研究成果の提供回数 | モデルのデプロイ回数 | 13件 |
それぞれの指標は、途中参加したメンバーや失敗したジョブなども含むため実態より若干上振れているはずですが、誤差は2割以内だと思います。このプロジェクトでは、研究アイデアを平均$\frac{C}{AB} \approx 4.3$件/人月のペースで実装し検証することができています。どのメンバーも複数のプロジェクトを掛け持ちしているので、実際の1人あたり生産性はこの数倍と考えればかなりのハイペースではないでしょうか。実験では深層生成モデルをスクラッチから訓練しているので、1試行に平均$\frac{E}{D} \approx 14$GPU時間を要しています(4GPU並列で計算しているので実時間では3.5時間程度です)。従量課金であれば試行回数を「節約」してしまいたくなる規模ですが、スパコンITOを活用して研究アイデア1つあたり$\frac{D}{C} \approx 25$試行ずつ実験しています。このおかげで統計的な過誤に惑わされることなく、着実に改善を積み上げることができたと思います。改善は$\frac{F}{AB} \approx 2.1$件/人月のペースで取り入れられています。これは検証したアイデア(4.3件/人月)の半数が性能改善に繋がった……なんていう甘い話ではなく、大半はリファクタリングやドキュメントの改善です。体感では性能の改善とコード品質の改善の比率は3:7くらいだった気がしますが、両者を分けて計測できるようにするのは今後の課題です。研究成果は$\frac{G}{A} \approx 1.5$回/月のペースで運用現場まで届けることができています。これは共同研究の立ち上げ時期も含めた全期間平均ですので、終盤はほぼ2週間ごとにリリースできていました。
モバイルゲームの機械学習エンジニアの技術スタック
ResDevOpsを実現するために、機械学習グループは「チームとして」どんな能力を備えているべきかをまとめたものが下記のリストになります。決して1人で何でも屋になれというつもりではなく、理想的にはリサーチャー・MLエンジニア・インフラエンジニア・Webエンジニア・Unityエンジニアくらいで分業すべき内容だと思います。とはいえ、KLabの機械学習グループはまだ規模が小さいこともあり、明確にポジションを分けてはいません。2~3人でチームを組んだときに大部分がカバーできるように心がけています。ツールとインフラに関しては、目安として機械学習グループで現在使われているものの一例をカッコ書きにしていますが、現時点では各自好きなものを使う方針でとくに縛りはないです。もう少しグループが大きくなってきたら、いずれ標準化や分業を進めるべき時期が来ると思います。
- 業務知識とソフトスキル
- ゲームとユーザーを好きであること。直接ゲームを作る立場ではなくてもエンターテイナーの一員であり、最終成果物は「ユーザー体験」であるという意識を常に忘れずに仕事に取り組むことができる。
- ゲーム会社における三大職種である企画・開発・制作の役割や組織構成、仕事内容を理解している。当事者とのヒアリングを通して、ワークフローのボトルネックを特定し全体最適な改善策を考えられる。
- それぞれの職種の価値観を理解して共感し、迎合や押し売りを排し、真に相手のためになるコミュニケーションがとれる。在宅勤務のPull型のコミュニケーション環境でも周囲を把握できるように、自分から情報を取りに行く積極性をもつ。
- スクリプト型のゲームAIのデザインパターン(ルールベース、ステートモデル、ユーティリティベース、ビヘイビアツリー、GOAP、HTN、様々な環境クエリシステムやメタAIなど)をひととおり理解しており、それらに機械学習を組み合わせてより良いゲーム体験を生み出す方法を考案でき、ゲームAIエンジニアと協調して実装できる。
- 機械学習を使うことで初めて可能になるような、他の職種では気づくことのできない新しいゲーム性を探求し、自らデモを作って周囲を動かし、製品化にこぎつけられる。
- 国内外のゲーム市場・ゲーム開発技術・AI技術の最新動向にキャッチアップし、自社のAI技術に関する中長期的な開発方針を考え、経営層に提言することができる。
- 自分が身につけたノウハウを言語化・体系化し、他人にも短時間で再現できるように要点をまとめて伝達できる。
- 機械学習理論
- 教科書的な手法とその数理的背景をひととおり身につけている。
- 理系学部教養レベルの線形代数・微分積分・確率統計を理解し、使いこなせる。
- 英語論文を読んで日本語文献と大差ない速度で理解し、実装できる。
- 有意水準や効果量、各種バイアスなどを考慮して、適切な実験計画を立てることができ、結果を適切に図表化して報告できる。
- 機械学習モデルの背後にある数理を理解し、数式レベルでモデルの挙動について仮設を立て、検証し、性能を改善できる。
- ツールとインフラ
- 機械学習ライブラリを使用して、既存手法を利用したり独自の手法を実装したりできる (PyTorch, TensorFlow, scikit-learn, pandas)
- データウェアハウスを使用して、大規模なデータを検索し、加工できる (BigQuery)
- 適切なクラス設計を行い、コーディング標準に準拠して、静的型とテストとドキュメントの付いた、メンテナンス性の高いコードを書ける (flake8, black, isort, mypy, pytest)
- バージョン管理ツールを使用して、標準化されたブランチ戦略で共同開発できる (Git, GitHub, GitHub Flow)
- コンテナやパッケージマネージャー等を使用して、再現性のある仮想環境を構築し、他人に配布できる (Terraform, Docker, Singularity, Pyenv, Conda)
- 実験管理ツールを使用して、標準化された方法で実験結果をシェアできる (MLflow, DVC)
- CLIツールを構築して、自動化されたワークフローに組み込むことがきる (argparse, Click)
- クラウドの各種サービスをコスト最適性や運用性を考慮して使い分け、機械学習のWeb APIを公開できる (GCP/AWSのAI系サービスやFaaS, FastAPI, GraphQL)
- Webフレームワークを使用して、非エンジニアでも直感的に操作できるWebシステムを構築できる (Django, Nuxt.js)
- ゲームエンジンを使って機械学習を組み込んだゲームのデモを制作できる (Unity, Barracuda, Native Plugin)
- High Performance Computing (HPC)の知識をもち、低遅延・広帯域なインターコネクトを活かした分散処理を実装できる (Slurm, RDMA, MPI, PyTorch Lightning)
- アカデミックスキル
- 常日頃から事実と意見を区別し、情報の1次ソースを参照して話す・聞く・読む・書く習慣が身についている。
- カンファレンスで登壇できる。ゲーム系会議と学術系会議の聴衆の関心の違いを理解し、それぞれにあわせた資料・トークを準備し、身振り・抑揚・言い回しにも配慮して魅力的に話すことができる。
- 難関国際会議に平均採択率の2倍以上の確率で論文を通すことができる。社内や国内会議で評価される成果と国際会議で評価される成果の違いを理解し、見せ方を変えることができる。
- 大学等の研究機関と共同研究できる。企業と大学のスケジュールや期待される成果などの違いを理解し、両者にとって有益な成果をタイムリーに出すことができる。
- 公募型の研究予算や計算機利用制度などを把握し、必要に応じて申請を通すことができる。
やってみた結果
なかなかの成果が出たような気がしています。
今日の発表のために成果まとめてて思ったけど、1年で機械学習グループ立ち上げて産学共同研究して、研究でもゲーム運用支援でも成果出てるのなかなか良いスタートかもしれないですわね。 https://t.co/Go1fkFPJvf pic.twitter.com/Qm7nI8ZL2Z
— はま (@hmkz_) April 8, 2022
ちなみに、このプロジェクトの研究成果をまとめた論文は人工知能の国際会議AAAI-23に採択されました。
現在進行中の機械学習プロジェクトは他にもたくさんあります。自動UIテストツール「ゴリラテスト」は人工知能学会で全国大会優秀賞をいただきました。こちらも現在開発中のゲームタイトルで運用を開始しています。近いうちに事業面での成果もお伝えできると思います。このゴリラテストは、高いエンジニアリングスキルと研究スキルを兼ね備えたチームだからこそ実現できたと思っています。UI自動テストツールを研究開発するためには、単に高いUI認識率を誇る機械学習アルゴリズムを作れればいいというものではありません。テストツールに不具合があってはテスト結果を信頼できないため、テストツールには非常に高い信頼性が求められます。その品質基準を通常のリサーチャーや機械学習エンジニアが達成することは容易ではありません。ゴリラテストの開発では、テストカバレッジを保証したり型検査やLinterなどの静的解析をするのはもちろんのこと、様々なスマホで自動化された実機テストを行い、機種依存の不具合までをチェックしています。このような開発を実践できるエンジニアリング力があってこそ、テストツールに組み込んだ機械学習が活きてきます。IBIS2022で発表した3Dモーション検索の研究でも、Vision Transformerの自己教師あり学習をこの分野で初めて導入してSOTAを更新しつつ、制作チーム向けのWeb UIも短期間で構築して開発中のゲームに間に合うように現場投入しています。
またResDevOpsを実践して気づいたこととして、アジャイル開発のプラクティスは学術面の成果創出にも良い影響を与えるという点があります。外部発表は数が多すぎて紹介しきれないので、件数だけまとめておきます。
| 機械学習グループによる外部発表(件) | 2020年(7月~) | 2021年 | 2022年 |
|---|---|---|---|
| ゲーム系カンファレンス | 1 | 3 | 1 |
| 学術系カンファレンス | 4 | 8 | 8 |
| 学術論文 | 2 | 3 | 4 |
| 大学等での講義 | 1 | 1 | 2 |
事業貢献をメインとする組織で、次々に研究成果を創出し、人数の数倍の外部発表をしているというケースは世の中を見渡しても珍しいのではないでしょうか。これができたのは、以下が大きな要因だったと感じます。
- スプリントミーティングで繰り返しユーザー(非専門家)に通じる伝え方を磨き上げられるため、外部発表する頃には聴衆に刺さるストーリーテリングができあがっている。
- GitHub Flowによって機能単位で効果検証が行われているため、自然にAblation Studyの実験結果が揃っている。
- 日ごろから再現性や可読性を担保しているため、再現実験用のコードとデータがわずかな手間で公開できる。
とくに意外だったのは、AAAI-23のような極めて学術色の強いカンファレンスでもこれらがプラスに働いたことです。普通に研究をしているとNovelty, Technical Soundness, Significanceといった研究の中身に注力しがちですが、これらは査読者の主観でブレやすい評価項目でもあります。一方、Clarity, Reproducibility, Resourcesといった研究の外側は客観評価しやすく、頑張った分だけ確実に得点を稼げます。ResDevOpsにしたがって研究を進めていれば、自然にこれらの評価項目で最高評価を連発できるため、大きなアドバンテージになります。一言でいえば、「業務で使いやすい成果は、学術コミュニティにとっても使いやすい」ということだと思います。
このように、研究をうまく開発・運用に近づけることができれば、むしろ相乗効果が働いて研究・開発・運用すべてを加速することができそうだというのが最近の考えです。とはいえ、現時点では多分に自己流や会社依存の面を含みますので、本当にこれでよかったのか、他社はどうやっているのか、今でもわからないことだらけです。ぜひこれを読んだ皆様からもアドバイスや経験談を聞いてみたいと思っています。
-
たまたま機械学習グループにおいて考案したために機械学習のためのプラクティスだと思われがちですが、ResDevOpsは機械学習やMLOpsとは関係がありません。MLOpsは機械学習 (ML) の運用 (Ops) に関するプラクティスです。一方、ResDevOpsは機械学習に限らない一般的な研究 (Res) を開発・運用 (DevOps) と連携するためのプラクティスです。 ↩