これは PolarDB などのデータベースに関する Tips を記事投稿しよう by Alibaba Cloud Advent Calendar 2023 16 日目の遡り登録エントリです。
数日前までこのカレンダーを見ていたときには「ベクトル検索を試してみる」っぽい仮タイトルの記事を登録しようとしていた人がいたはずだったのですが、一昨日(12/21)見たらなくなっていたので、急遽代わり(?)に登録してみました。
これを「Tips」と呼んで良い…のか…?(まあいいか)
Alibaba Cloud でベクトル検索(with LangChain)
LangChain から Vector store として使えるサービスとしては、主に
がありますが、ここでは PolarDB for PostgreSQL 14 で pgvector 0.5.0 を有効化して試してみます。
pgvector とは
PostgreSQL でベクトル計算とベクトルデータの保存・検索をするための拡張機能(Extension)です。
詳細説明については、すでに PostgreSQL Advent Calendar 2023 の記事として書きましたのでそちらを参照してください。
作って試したもの
実はすでに作って試して JAWS-UG 名古屋で発表し(て見事にスベっ)た構成を、Docker コンテナの pgvector から PolarDB for PostgreSQL に置き換えただけです。
人工無能(無脳)とは?
いまどきの ChatGPT のように「会話が成立する AI チャット」ではなく、人が入力した文章やキーワードをおうむ返ししたり、過去に人が入力した文章やキーワードの中から関係ありそうなものを選んで返してくる、微妙な会話を楽しむための(?)チャットです。
インターネット以前のパソコン通信時代に流行りました。
文章のベクトル化(Embedding)には AWS の Titan Embeddings G1 - Text を使います。
また、コードを動かす環境は AWS の EC2(パブリックアクセスあり)を想定しています。
コードは Alibaba Cloud の ECS で実行することも可能です(要アクセスキー・シークレットアクセスキー設定)。
AWS 側の準備
先の GitHub リポジトリの README のとおりに設定します。
- Bedrock モデル有効化
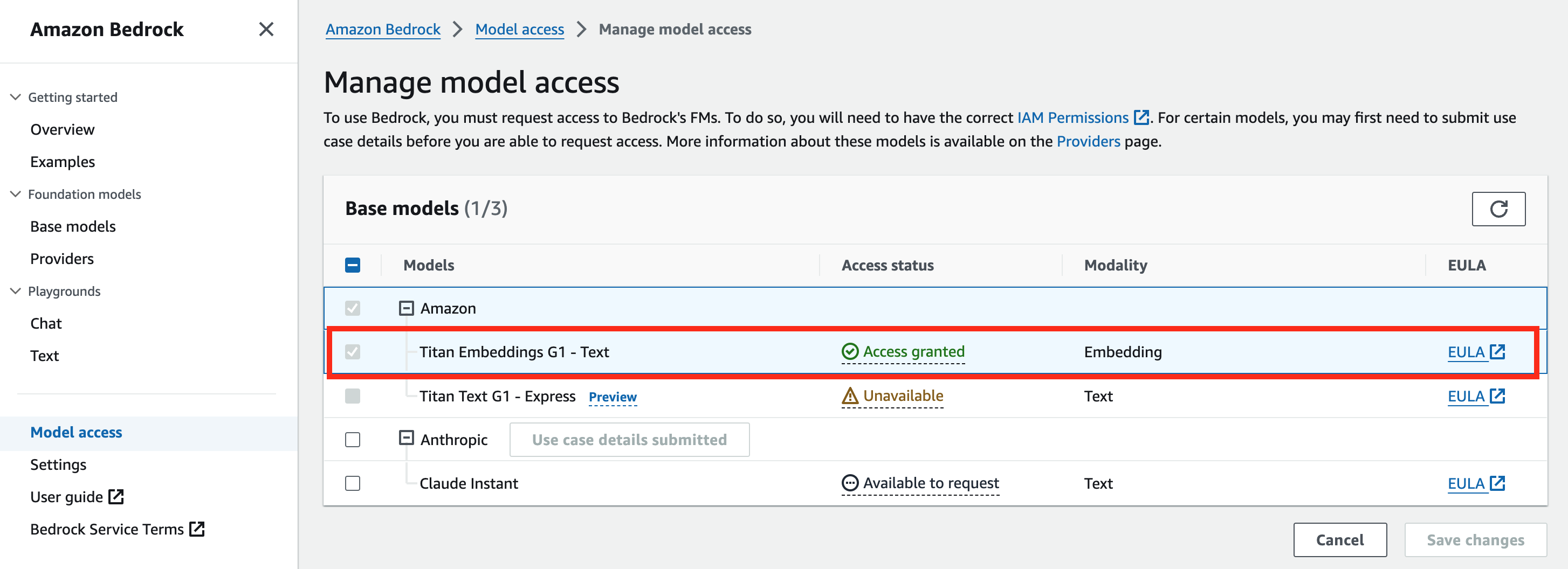
- 以下のポリシーを持つ IAM Role を作成し、コードを動かす環境の EC2 に付与
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}
- コードを動かす環境の EC2 に GitHub のコードを展開
コードは Python 3.10 で動作します。
ローカルリポジトリにcloneしたら、
pip install -r requirements.txt
でパッケージをインストールします。
venvを使って環境を切り替えられるようにしておくと良いでしょう。
PolarDB for PostgreSQL の準備
クラスタを作成します。
事前に VPC・vSwitch を作成しておきます(途中で新規作成することも可能)。
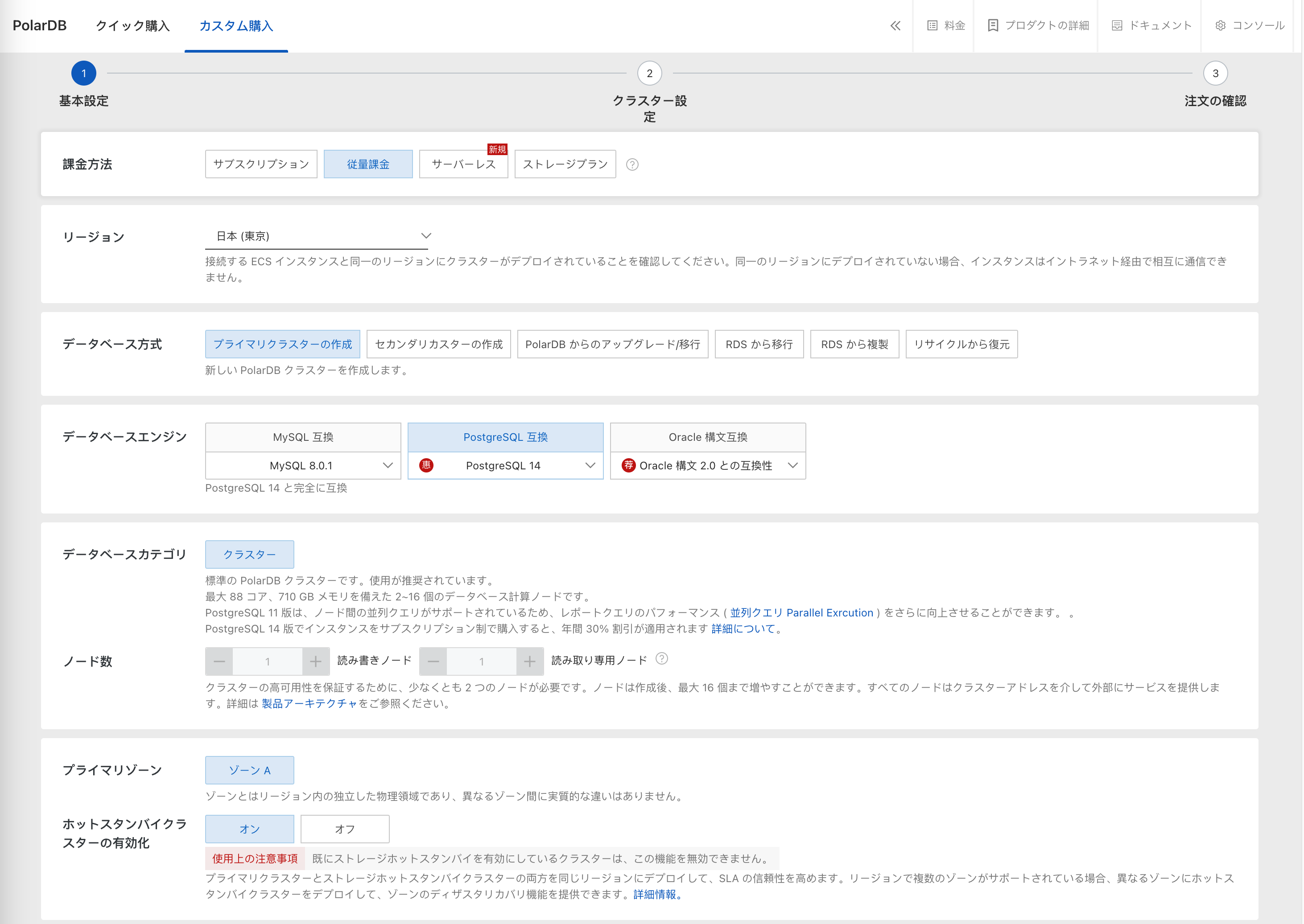
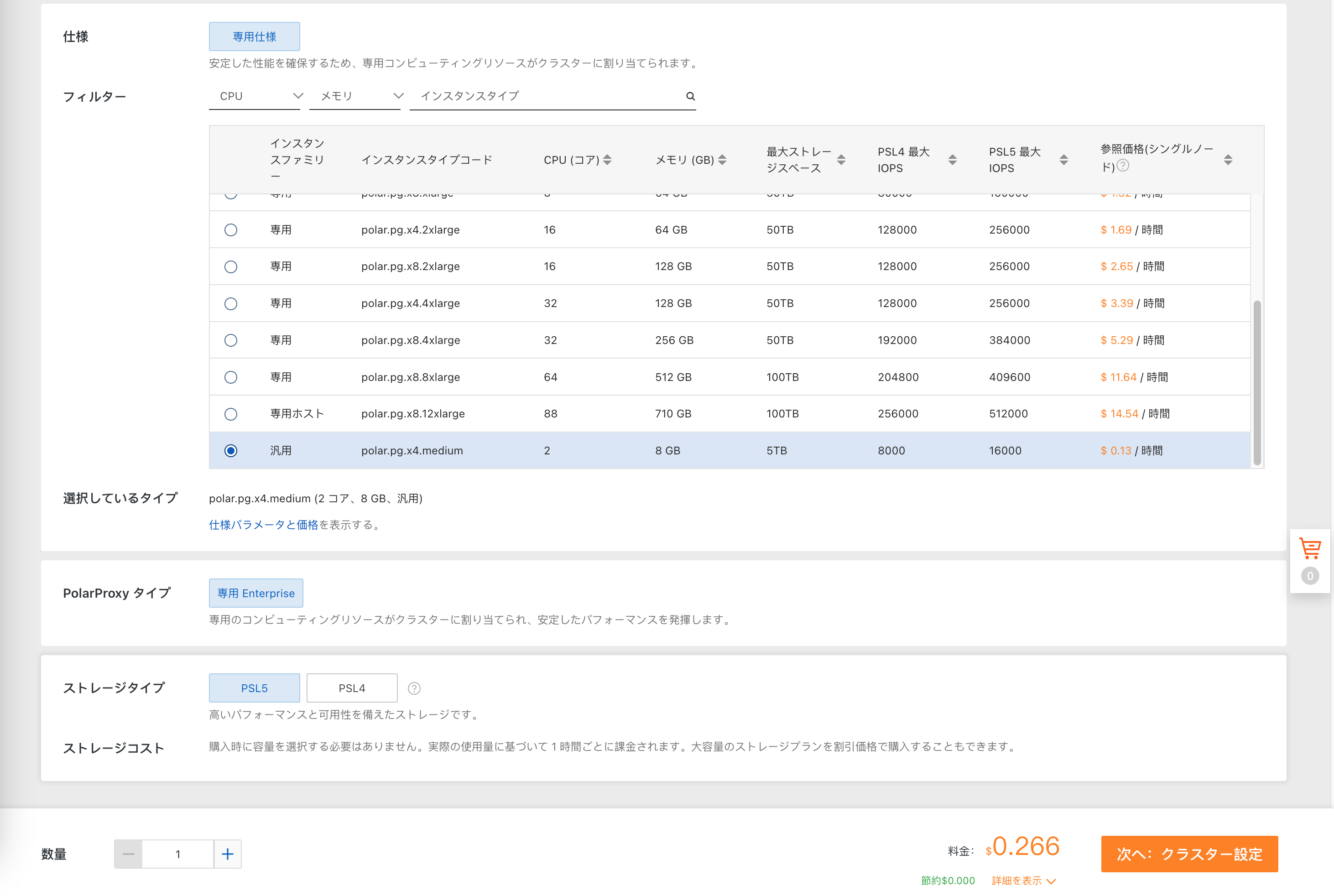
プロダクト環境で使うときは TDE を有効化します。
クラスタ作成後、プライマリエンドポイント(またはクラスターのエンドポイント)のパブリックネットワークアドレスを申請します。
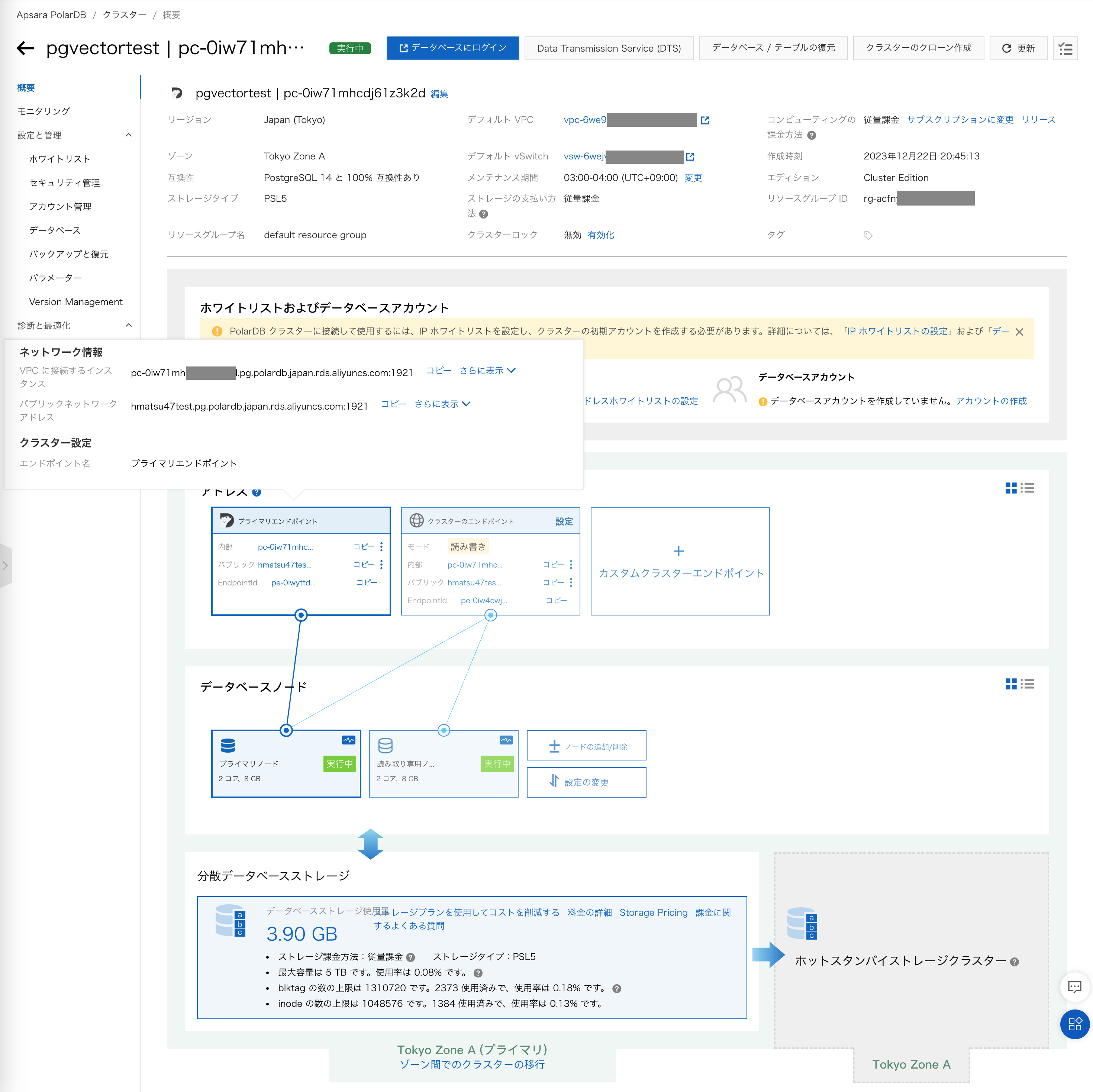
ここではhmatsu47testという名前で申請しています。
IP ホワイトリストには、EC2 のパブリック IP アドレスを追加指定します。
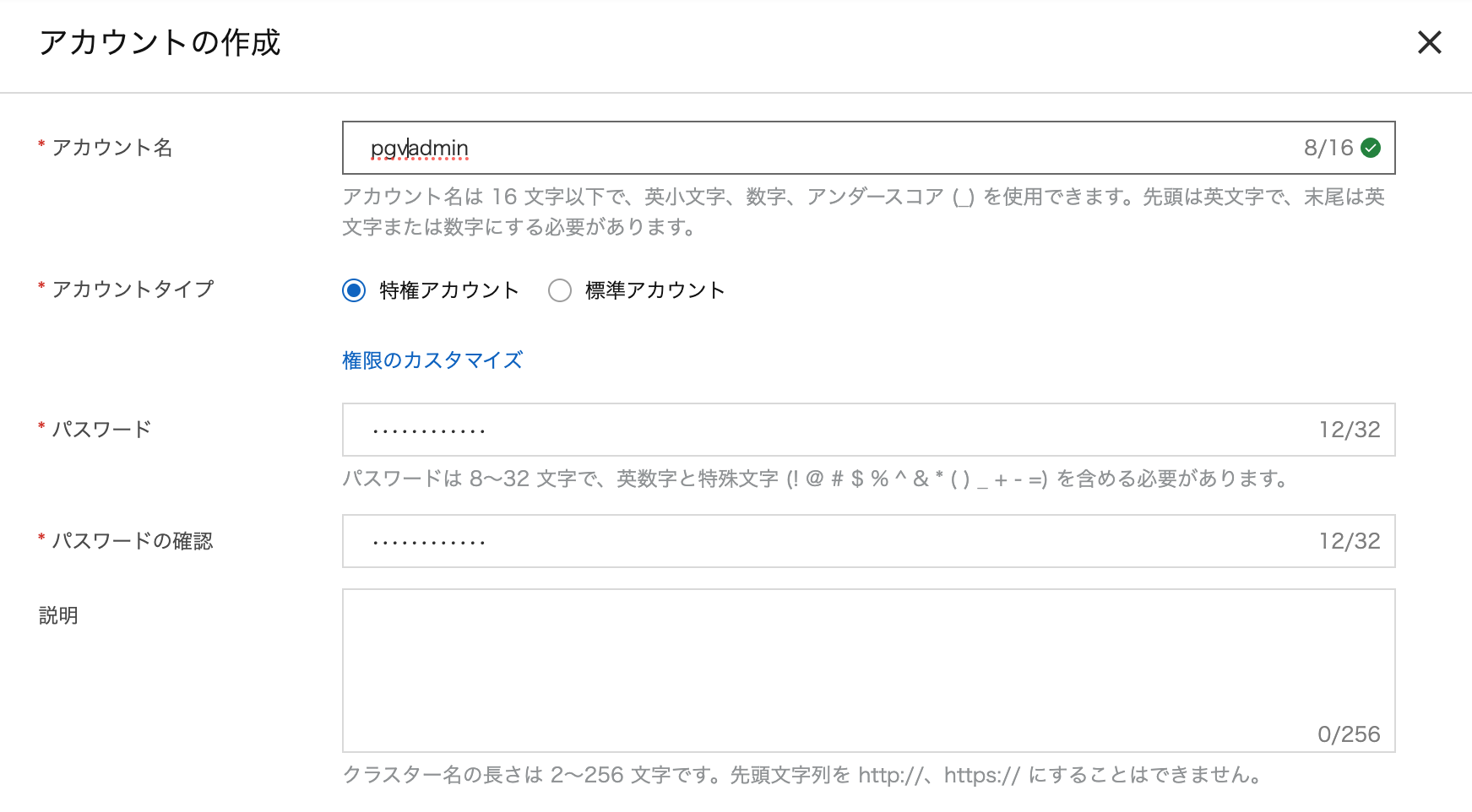
アカウントを作成します。
まず管理者用の特権アカウント(ここではpgvadmin)、次にアプリケーションからのアクセスに使う標準アカウント(同pgvuser)を作成します。

続いてアプリケーションから使うデータベースを作成します(ここではpgvtest)。
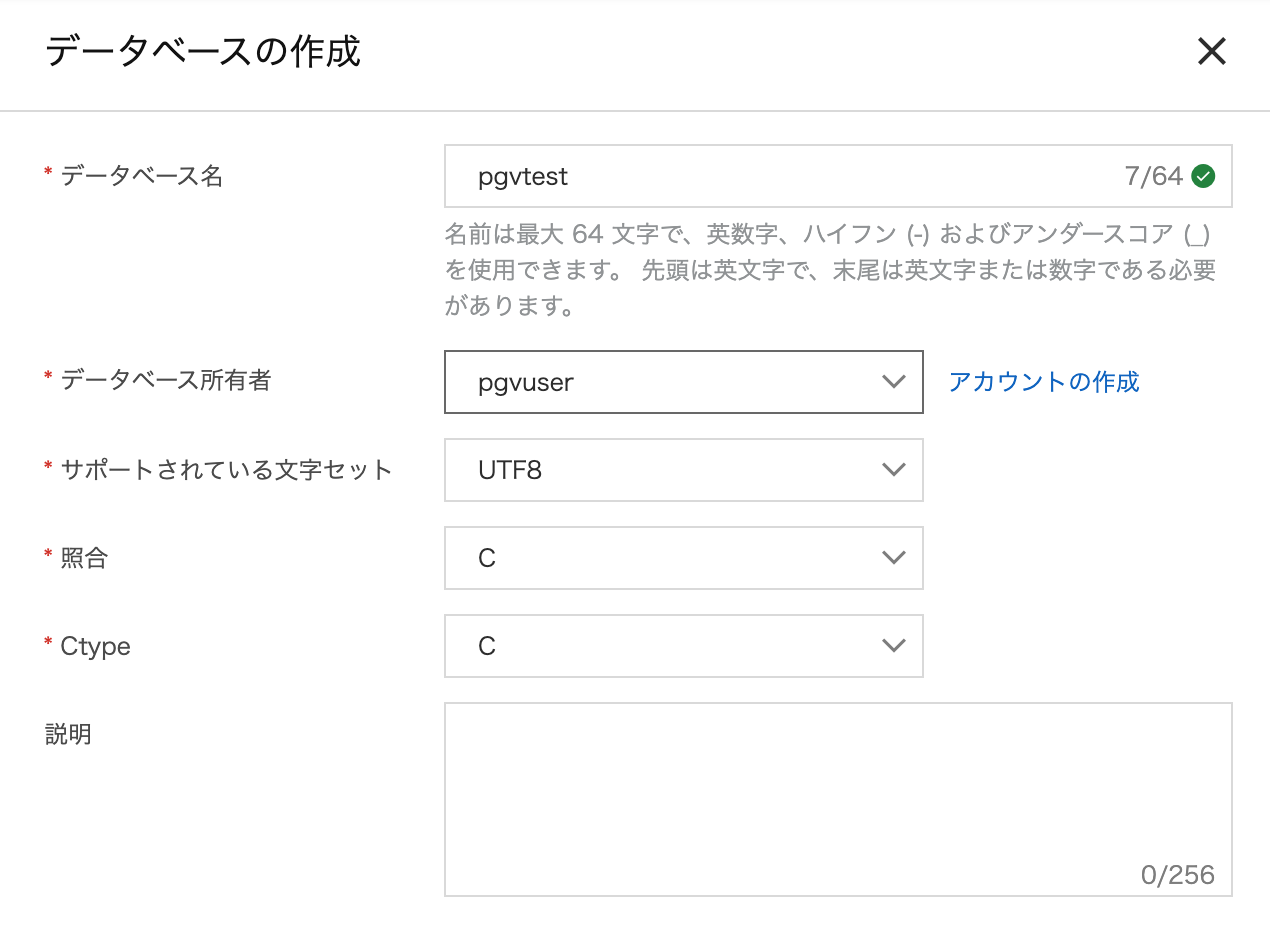
データベース所有者には先ほどの標準アカウントを指定します。
プロダクト環境で使うときは必ず SSL(TLS)での接続を有効化します。
EC2 のコードで.envファイルを書き換える
PolarDB 側の設定に合わせて内容を書き換えます。
PGVECTOR_DRIVER=psycopg2
PGVECTOR_HOST=hmatsu47test.pg.polardb.japan.rds.aliyuncs.com
PGVECTOR_PORT=1921
PGVECTOR_DATABASE=pgvtest
PGVECTOR_USER=pgvuser
PGVECTOR_PASSWORD=【設定した標準アカウントのパスワード】
psqlコマンドで PolarDB for PostgreSQL に接続し、vector拡張機能を有効化する
特権アカウントで接続して作業します。
$ psql -h hmatsu47test.pg.polardb.japan.rds.aliyuncs.com -p 1921 -U pgvadmin -d pgvtest
Password for user pgvadmin:
psql (14.10, server 14.9)
Type "help" for help.
pgvtest=> CREATE EXTENSION vector;
CREATE EXTENSION
pgvtest=> SELECT extversion FROM pg_extension WHERE extname = 'vector';
extversion
------------
0.5.0
(1 row)
pgvtest=> \q
アプリケーションを実行する
$ streamlit run app.py --server.port 8080
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
Network URL: http://172.31.XX.XX:8080
External URL: http://35.XX.XX.XX:8080
ブラウザで対象 URL を開きます。
この時点で DB を確認すると、
$ psql -h hmatsu47test.pg.polardb.japan.rds.aliyuncs.com -p 1921 -U pgvuser -d pgvtest
Password for user pgvuser:
psql (14.10, server 14.9)
Type "help" for help.
pgvtest=> \d
Did not find any relations.
何もありません。
何か文章を入力してみます。
入力した内容がそのままおうむ返しされてきました。
DB を確認します。
pgvtest=> \d
List of relations
Schema | Name | Type | Owner
--------+-------------------------+-------+---------
public | langchain_pg_collection | table | pgvuser
public | langchain_pg_embedding | table | pgvuser
(2 rows)
pgvtest=> SELECT * FROM langchain_pg_collection;
name | cmetadata | uuid
--------------+-----------+--------------------------------------
munou_goroku | null | 0aa32fd8-2f00-4d4c-b006-29fe541619c8
(1 row)
pgvtest=> \d langchain_pg_embedding
Table "public.langchain_pg_embedding"
Column | Type | Collation | Nullable | Default
---------------+-------------------+-----------+----------+---------
collection_id | uuid | | |
embedding | vector | | |
document | character varying | | |
cmetadata | json | | |
custom_id | character varying | | |
uuid | uuid | | not null |
Indexes:
"langchain_pg_embedding_pkey" PRIMARY KEY, btree (uuid)
Foreign-key constraints:
"langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
pgvtest=> SELECT collection_id, document, cmetadata, custom_id, uuid FROM langchain_pg_embedding;
collection_id | document | cmetadata | custom_id | uuid
--------------------------------------+--------------+-----------+--------------------------------------+--------------------------------------
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | こんばんは! | {} | 4499a717-a0c9-11ee-bbd5-0adb715db027 | 64682864-63a0-418c-b758-5078ee293ad9
(1 row)
テーブルが 2 つ作成されました。
langchain_pg_embeddingに、入力した文章が 1 行追加されたのがわかります。
embeddings列にベクトル化されたデータが入っていますが、画面には表示しづらいのでここでは表示を省略しました。
さらに別の文章を入力してみます。
先ほど入力された内容が返ってきましたね。
先ほどのテーブルを見てみます。
pgvtest=> SELECT collection_id, document, cmetadata, custom_id, uuid FROM langchain_pg_embedding;
collection_id | document | cmetadata | custom_id | uuid
--------------------------------------+------------------------+-----------+--------------------------------------+--------------------------------------
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | こんばんは! | {} | 4499a717-a0c9-11ee-bbd5-0adb715db027 | 64682864-63a0-418c-b758-5078ee293ad9
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | 今日は良い天気ですね! | {} | dc61ff4d-a0c9-11ee-aac9-0adb715db027 | 4c581b75-4109-45c7-8929-75b6318f0348
(2 rows)
2 行になりました。
さらに別の文章を入力してみます。

先に 2 つ入力していた文章のうち、意味的に近そうなほうが返ってきました。
テーブルを見てみます。
pgvtest=> SELECT collection_id, document, cmetadata, custom_id, uuid FROM langchain_pg_embedding;
collection_id | document | cmetadata | custom_id | uuid
--------------------------------------+------------------------+-----------+--------------------------------------+--------------------------------------
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | こんばんは! | {} | 4499a717-a0c9-11ee-bbd5-0adb715db027 | 64682864-63a0-418c-b758-5078ee293ad9
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | 今日は良い天気ですね! | {} | dc61ff4d-a0c9-11ee-aac9-0adb715db027 | 4c581b75-4109-45c7-8929-75b6318f0348
0aa32fd8-2f00-4d4c-b006-29fe541619c8 | 明日は晴れますかね? | {} | 2d34fc70-a0ca-11ee-95c6-0adb715db027 | 2d540208-218c-48f2-9204-a9a9ae0cd2db
(3 rows)
3 行になりました。
見づらいですが、一応ベクトル化されたデータだけ見てみると…
pgvtest=> SELECT embedding FROM langchain_pg_embedding;
(中略)
[1.234375,-0.032470703,-0.28515625,0.22070312,0.25585938,-0.69921875,…
[1.40625,0.765625,-0.104003906,0.10644531,0.296875,-0.26953125,…
[2.34375,0.73828125,-0.22167969,-0.29101562,0.65234375,0.33789062,…
(3 rows)
というような感じで各行 1536 個の配列がベクトルデータとして入っています。
何をしているのか?
Python のコードを見てみます。
13 行目から 20 行目、
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", ""),
)
で DB(PolarDB for PostgreSQL)への接続文字列を定義しています。
.envから変数を取得可能な場合はその値が入ります。
なければ 2 つ目のパラメータとして指定した値を(デフォルト値として)使います。
48 行目から 59 行目、
# ベクターストアから応答を取得
bedrock_client = boto3.client('bedrock-runtime', region_name="ap-northeast-1")
embeddings = BedrockEmbeddings(
client=bedrock_client,
model_id="amazon.titan-embed-text-v1"
)
store = PGVector(
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,
embedding_function=embeddings,
)
docs = store.similarity_search_with_score(trimed_prompt)
で入力文字列に近いレコードをベクトル検索し、
60 行目から 73 行目、
count = len(docs)
add_flag = True
if count == 0:
# ベクターストアに文章がなければおうむ返しする
response = trimed_prompt
else:
# 近い文章を返す
response = docs[0][0].page_content
if trimed_prompt == response:
# すでに登録済みの文章と同じならベクターストアに登録しない
add_flag = False
if add_flag:
# ベクターストアに入力を追加
store.add_documents([Document(page_content=trimed_prompt)])
で
- 検索結果が 0 件なら入力文字列をそのままおうむ返し
- 近い文書があればそれを返す
- それが入力文字列と違う場合は DB にレコードを追加
- このとき入力文字列を Titan Embeddings T1 - Text でベクトル化
- それが入力文字列と違う場合は DB にレコードを追加
しています。
LangChain を使っているので SQL 文は完全に隠蔽されています。
実際にどのような SQL 文でベクトル検索できるのか?については、前掲の記事を参照してください。
なお、pgvector を使う場合、デフォルトで<->、つまりユークリッド距離(L2 距離)による最近傍探索が行われるようです(その際、IVFFlat・HNSW インデックスは使いません)。
RAG として使うには
similarity_search_with_score()で返ってきたものをそのまま表示するのではなく、RetrievalQA.from_chain_type()などのパラメータとしてストアのretrieverを渡し、
- AWS の Bedrock であれば Anthropic Claude 2.1
- OpenAI であれば ChatGPT(3.5/4 など)
などの LLM のプロンプトとして入力文字列(や履歴など)とあわせて送ります。
2024/3/5 追記:
現状は(というかアドベントカレンダーの時点ですでに)RetrievalQA.from_chain_type()などのレガシーな記法ではなく、LCEL の使用が推奨されています。
- LangChain の新記法「LangChain Expression Language (LCEL)」入門(oshima_123 さん)