はじめに
KDDI エンジニア&デザイナー Advent Calendar 2024の最終日の記事になります。
ChatGPT 1は、まるで人間のように自然な返答をしてくれるチャットツールで、2022年に登場以降、世界中で爆発的に広まりました。その中身は、大量の言語データで学習させた大規模言語モデル(Large Language Model:LLM)で構成されています。ChatGPTは、GPTと呼ばれるLLMがベースとなっており、年々驚くべき進化を遂げています。
回答性能や回答時間の改善はもちろんですが、特にマルチモーダル対応という大きな飛躍がありました。人間が「読む」だけでなく「見る」「聞く」といった複数の感覚で情報を処理しているのと同様、テキストだけでなく画像や音声なども入力できるようになったのです。このようなLLMは、マルチモーダルLLMと呼ばれています。これによって、防犯・自動車・スポーツ・教育・医療など、応用範囲が大きく広がりました 234。
最近では、1枚の画像だけでなく、動画を入力できるLLMも登場してきました。例えば、GPT-4o(OpenAI社) 5、LLaVA-NeXT-Video(ByteDance社) 6、Gemini 1.5 Pro(Google社) 7は、動画を入力できる代表的なLLMです。動画を入力できるようになったことで、時間的な情報を扱えるようになり、応用の幅がさらに広がりました。例えば、監視カメラ映像からの異常検知 8、車載カメラ映像からの道路状況理解、スポーツ映像からの実況生成等々、様々な分野での応用が期待できます。
図1は、GPT-4oで実際に動画を入力したときの例を示します。「曲がりくねった道路」、「緑豊かな草地や林」といった静的な状況はもちろんですが、「走行中」、「右に曲がっている」、「運転中」といった画像だけでは捉えにくい動的な状況まで認識できています。
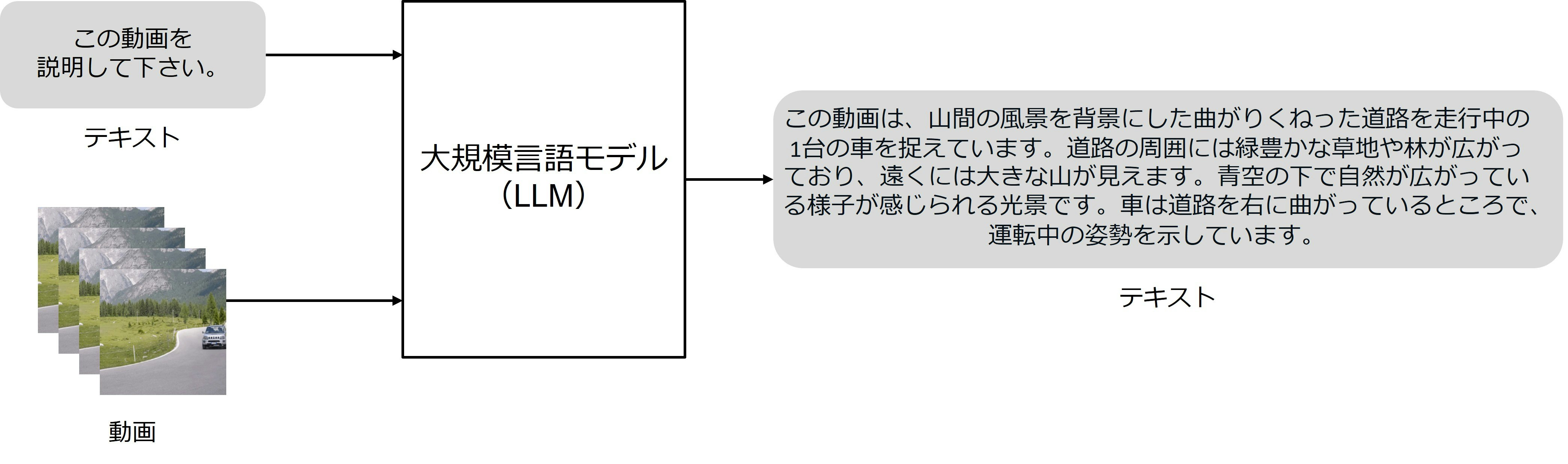
図1:GPT-4oで実際に動画を入力して推論させた例
本記事では、このような動画を入力できるLLMについて紹介します。まずは、画像を入力できるLLM(以下、画像入力LLM)の仕組みを説明してから、動画を入力できるLLM(以下、動画入力LLM)の仕組みを説明し、その後動画入力LLMの実装例についても紹介します。
画像を入力できるLLM
動画入力LLMの前に、画像入力LLMを説明します。本記事では、代表的なモデルであるLLaVA(Microsoft社) 9を例に挙げて説明します。図2に、LLaVAの構成を示します。テキストと画像が入力され、テキストが出力されます。
モデル:モデルはLLMがベースになります。LLMではテキストを単語や文字のように分割した「トークン」という単位で処理します。テキストは直接LLMに入力することができます。一方、画像はそのままだとLLMに入力できません。まず、画像を「画像エンコーダ」によって特徴量に変換します。そして、特徴量を「コネクタ」によってトークンに変換し、LLMに入力できるようにします。画像エンコーダには、CLIP 10というモデルが用いられます。コネクタには、シンプルな線形層のようなものが用いられます。画像エンコーダやLLMにはあらかじめ学習させたモデルを用いることで、事前知識を効率的に活用することができます。
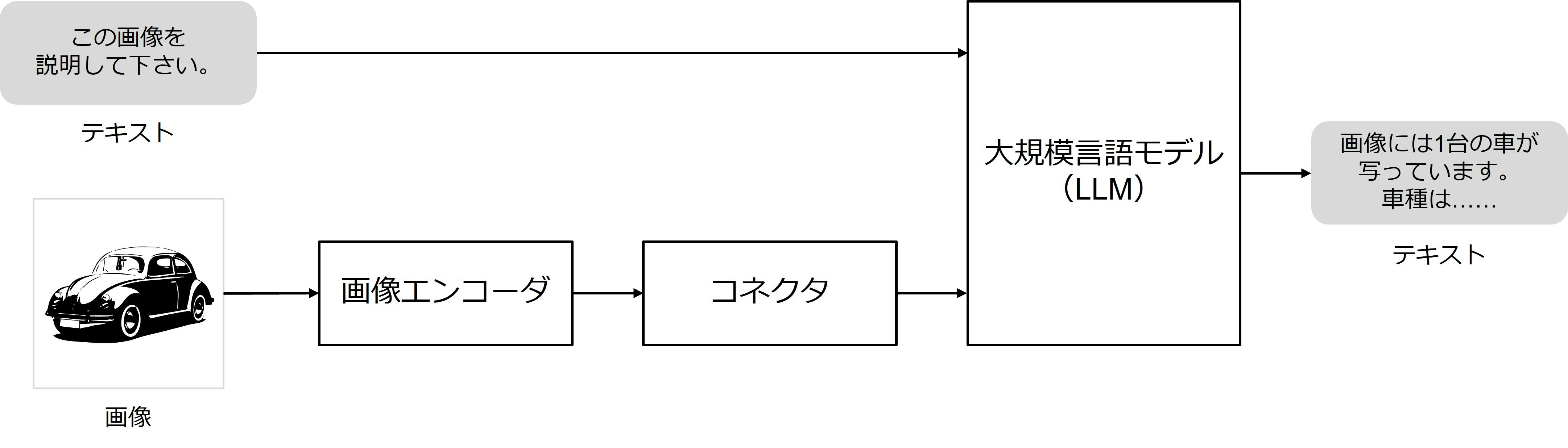
図2:LLaVAの構成
画像エンコーダ:図3に、画像エンコーダの処理を示します。画像エンコーダでは、まず画像をパッチという単位に分割します。この例だと、2x2で4分割し、さらに元の画像を含めた5つのパッチになります。これらをエンコードすることで、LLMに入力するためのトークンを得ます。
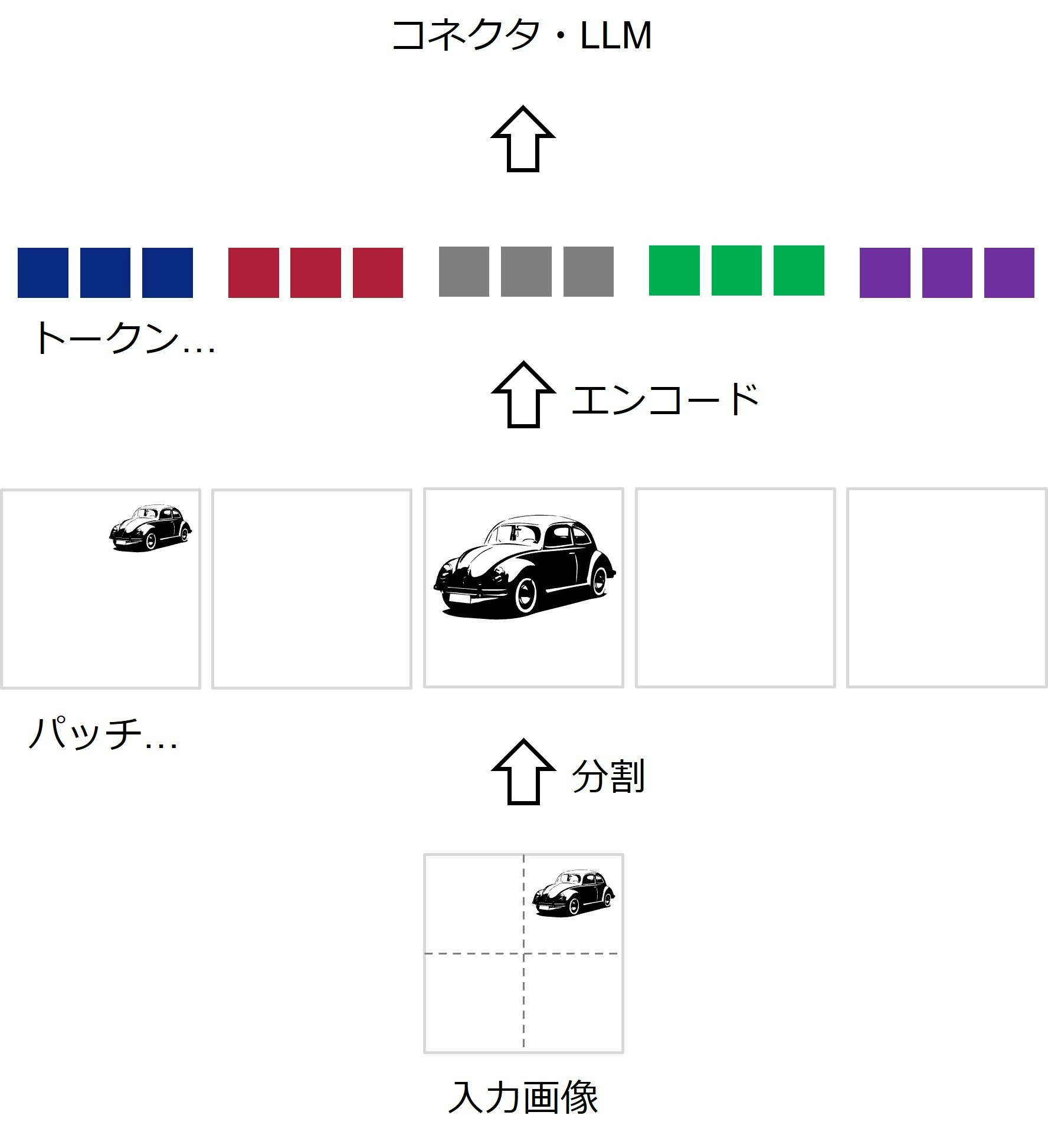
図3:LLaVAにおける画像エンコーダの処理
ファインチューニング:学習済みモデルをコネクタでつなげるだけでも、汎用的な知識を身に着けたモデルとして使用することができるのですが、利用用途ごとに特化したモデルを作りたいという場合も多いと思います。そこで、新たな学習データを用意して、モデルをファインチューニングするといったこともよく行われます。
補足:なお、LLMの直後に「コネクタ」と「画像デコーダ」を付けることで、画像を出力することも可能になります。画像デコーダには、拡散モデルがよく用いられます。拡散モデルの詳細は過去記事 11で紹介しているので、よければご覧ください。
動画を入力できるLLM
次に、動画入力LLMを説明します。なお、事前知識として、動画は時間的に並んだ複数の画像で構成され、各画像はフレームと呼ばれます。本記事では、代表的なモデルであるLLaVA-NeXT-Videoを例に挙げて説明します。図4に、LLaVA-NeXT-Videoの構成を示します。テキストと動画が入力され、テキストが出力されます。図2と比較すると分かる通り、「画像エンコーダ」が「動画エンコーダ」になっているだけで、基本的な構成は画像入力LLMと同じです。
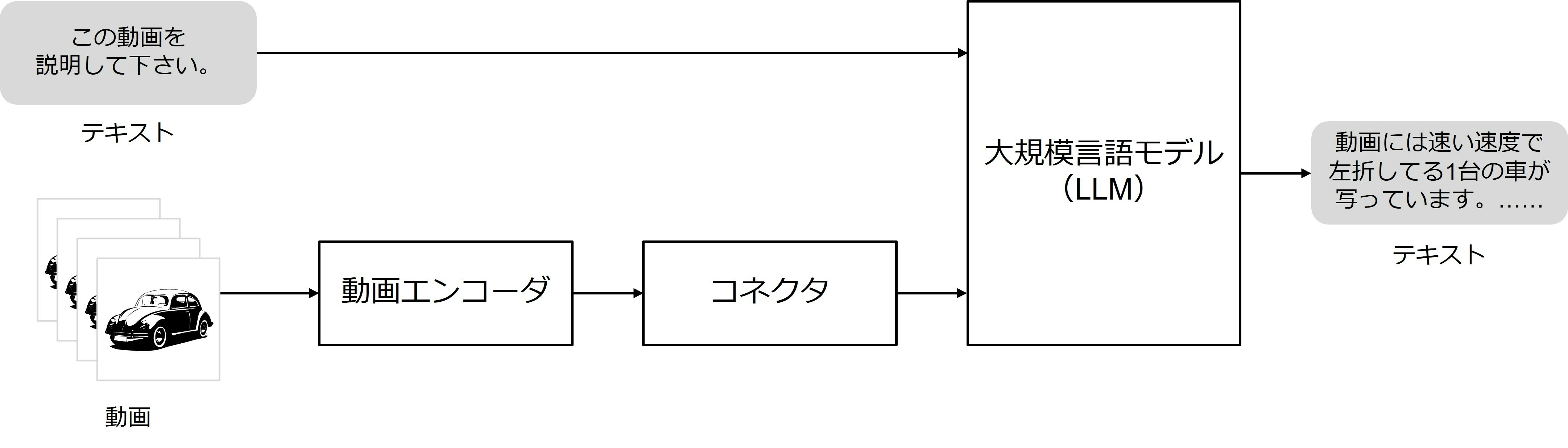
図4:LLaVA-NeXT-Videoの構成
図5に、動画エンコーダの処理を示します。図3に示すような画像エンコーダと同じように、各フレームに対してパッチ分割とエンコードを行います。得られたトークンをフレーム数分だけつなげて、LLMに入力することも不可能ではありませんが、LLMに入力できるトークン数は限られています。そこで、各フレーム・パッチの情報を最大限保持しつつ、トークン数をいかに削減するかが重要になります。LLaVA-NeXT-Videoでは、空間的プーリングによって、各フレームにおいて代表的なトークンのみを残すことで、上記の問題を改善しています。具体的には、2パッチごとに平均プーリングを適用し、1つのトークンにまとめ上げます。
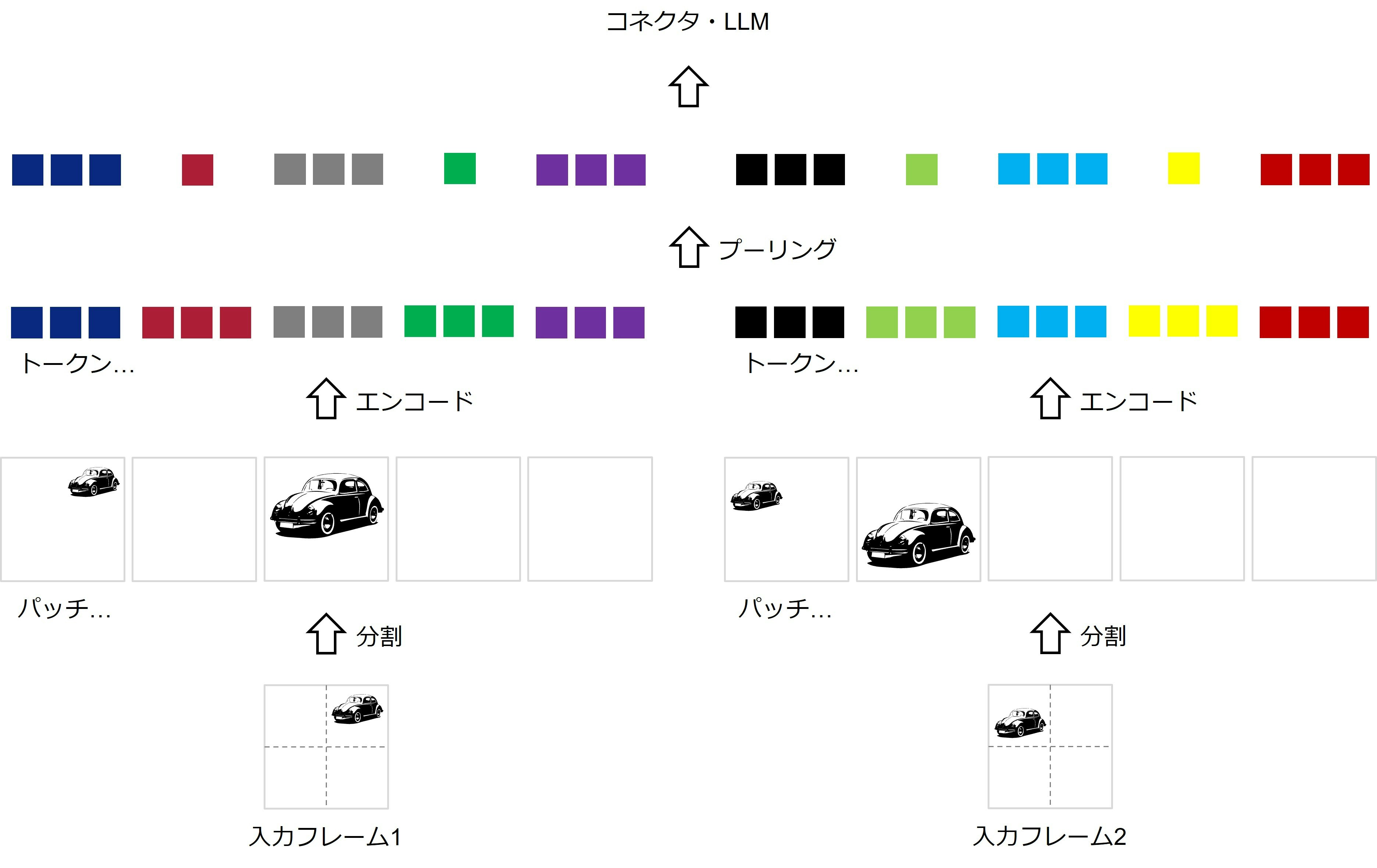
図5:LLaVA-NeXT-Videoにおける動画エンコーダの処理
動画を入力できるLLMの実装例
本記事では、前章で紹介したLLaVA-NeXT-Videoを使って、動画入力LLMの実装例を紹介します。今回は、Hugging Face 12というプラットフォームを使ってみたいと思います。Hugging Faceとは、機械学習向けのデータやモデルを共有するためのプラットフォームで、LLaVA-NeXT-Videoに限らず様々な学習済みのモデルが公開されています。
環境構築
OSはLinuxを想定しています。プログラム言語のPythonや深層学習フレームワークのPyTorchは既にインストール済みとします。また、GPUが1台必要です。
各種ライブラリをインストールします。transformersは、Hugging Face内の代表的なライブラリで、今回使用するLLaVA-NeXT-Videoが入っています。
$ pip install av
$ pip install transformers
$ pip install accelerate
$ pip install protobuf
$ pip install sentencepiece
実装
まず、ライブラリをインポートします。
import av
import torch
import numpy as np
from transformers import LlavaNextVideoForConditionalGeneration, LlavaNextVideoProcessor
次に、学習済みモデルを読み込みます。7Bは7 billionを示し、モデルのパラメータ数が70億個あるということを意味します。また、float型は一般的には32ビットなので、float16だと半分の精度になります。これによって、GPUメモリの使用量を削減したり、処理量を削減することができます。
model = LlavaNextVideoForConditionalGeneration.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf", torch_dtype=torch.float16, device_map="auto")
processor = LlavaNextVideoProcessor.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf")
次に、動画を読み込みます。video_pathは動画ファイルの場所で、自身の環境に合わせて変更します。read_video_pyavは動画を読み込む関数です。Hugging Faceに公開されている実装 13がそのまま使えるので参照してください。indicesは読み込むフレームのインデックスを指定しています。total_frames / 8なので、8フレームのうち1フレームだけに間引いています。
video_path = "./data/santa.mp4"
container = av.open(video_path)
total_frames = container.streams.video[0].frames
indices = np.arange(0, total_frames, total_frames / 8).astype(int)
video = read_video_pyav(container, indices)
次に、テキストを指定します。英語の方が望ましいですが、日本語でも大丈夫です。
text = " What is the content of this video?"
次に、テキストをテンプレートに合わせて辞書の形式に変換します。
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": text},
{"type": "video"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
次に、上記で得られたプロンプトと動画を、モデルに入力できる形式に変換します。.to(model.device)とすることで、データをCPUから指定したGPUのメモリに転送します。
inputs = processor(text=prompt, videos=video, return_tensors="pt").to(model.device)
そして、上記で作った入力からテキストを生成します。max_new_tokensは出力するトークン数の最大値です。
out = model.generate(**inputs, max_new_tokens=100)
print(processor.batch_decode(out, skip_special_tokens=True, clean_up_tokenization_spaces=True))
検証
入力動画は、図6に示すようなサンタクロースの動画にしました。

図6:入力動画の1フレーム目
まず、入力テキストを英語にした場合です。
"What is the content of this video?"
出力テキストは下記のようになりました。
"The video shows a jovial scene of a man dressed as Santa Claus, kneeling down in front of a beautifully decorated Christmas tree. He is holding a wrapped gift and appears to be in the process of opening it, possibly to reveal what's inside. The setting is festive and warm, with a cozy atmosphere, and the man's cheerful demeanor adds to the holiday spirit."
非常に高い状況認識能力を持っていることが分かります。サンタがプレゼントを開けようとしているという記述は、常識的に考えると少し気になります。ただ、その可能性もゼロではありませんね。
次に、入力テキストを日本語にした場合です。
「この動画の内容を説明して下さい。」
出力テキストは下記のようになりました。
「この動画は、クリスマス・クリスマスの伝統的なクリスマス・パーティーを描いたシーンです。クリスマス・クリスマスは、冬の夜に家の中で、彼の家族や友人たちと一緒に過ごすたいただけ」
一見すると、全体的にそれらしい説明ができているように見えます。ただ、彼(=おそらくサンタを指す)が家族や友人と過ごすという記述があり、少し違和感があります。また、重要なキーワードである「サンタ」が出てきません。クリスマスが2重になっていたり、日本語自体にも違和感があります。英語ではうまく説明できていることから、日本語との対応付けがうまくできていない可能性があります。例えば、さらに日本語の学習データを増やして、ファインチューニングする必要がありそうです。
まとめ
本記事では、動画を入力できるLLMについて紹介しました。非常に優れた状況認識能力を持っており、様々な分野への応用が期待されます。一方、動画を扱うということで、メモリ使用量の削減や処理量の削減が大きな課題となります。今後は、状況認識能力を保ちつつ、処理量等を削減するための研究開発が進んでいくと想定されます。
参考文献
-
LLaVA-NeXT-Video
https://github.com/LLaVA-VL/LLaVA-NeXT ↩ -
Gemini 1.5 Pro
https://deepmind.google/technologies/gemini/pro/ ↩ -
マルチモーダルLLMの活用方法と技術解説
https://zenn.dev/elith/articles/d21b97f52a7ab8 ↩ -
マルチモーダルとは?AIモデルでできることや分野別・企業の導入事例も紹介
https://aismiley.co.jp/ai_news/what-is-multimodal-ai-model/ ↩ -
マルチモーダルLLMを理解する
https://qiita.com/Dataiku/items/3e86c8012b2a7a7a3cf0 ↩ -
動画像異常検知入門
https://qiita.com/satolab/items/bad27b84fbabc8f05d34 ↩ -
LLaVA
https://llava-vl.github.io/ ↩ -
拡散モデル入門
https://qiita.com/hitottiez/items/18299e6af25c93b9f6c0 ↩ -
Hugging Face
https://huggingface.co/ ↩ -
LLaVA-NeXT-Video (Hugging Face)
https://huggingface.co/docs/transformers/main/model_doc/llava_next_video ↩