想像してみてください: お気に入りのソーシャルメディアをスクロールしていると、絵のように美しくて素晴らしい風景画像に出くわします。興味をそそられたあなたは、仲間からの反応を期待して、その場所に関する質問を入力します。すると、仲間に代わって機械が風景と場所をそのまま識別し、詳細な説明に加えて、近くのアトラクションまで提案してくれました。
このシナリオはサイエンスフィクションではなく、さまざまなモダリティ(様式)を組み合わせることでAIの世界を拡張する マルチモーダルLLM (以下、M-LLMと記載します)の可能性を示しています。

M-LLMはマルチモーダル情報をシームレスに統合し、テキスト、画像、音声などを含む多様な形式のデータを処理して世界を把握できるようにします。M-LLMの中核は、さまざまなデータ型を取り込むことができる汎用性の高いニューラルネットワークで構成され、それによってさまざまなモダリティにわたるインサイトを得ることができます。
マルチモーダルLLM
M-LLMは、実際のさまざまなタスクで顕著な能力を発揮します。たとえば、画像に関連するキャプションの生成に優れ、SNS上のエンゲージメントを高める詳細説明を提供します。風光明媚な山岳風景の写真を提示されると、M-LLMは「澄み渡る青空の向こうに広がる、雪を冠した山々の息をのむような眺め」という魅力的なキャプションを生成するかもしれません。
さらに、M-LLMはビジュアルコンテンツに関する質問に適切に答え、画像認識やシーン(状況)理解などのタスクを補助します。M-LLMは 、 「この街並みにどんなランドマークが見えるか」という質問に対して、エッフェル塔、自由の女神、シドニー・オペラハウスなどの著名なランドマークを正確に特定し、リストアップするかもしれません。
このブログ記事では、特にテキストとビジュアルの統合に焦点を当て、M-LLMの仕組みを掘り下げ、その複雑なアーキテクチャをわかりやすく説明します。さらに、画像の説明キャプション生成、ビジュアルコンテンツへの質問回答などのタスクにいかに優れているかを見ていきます。これから説明する内容は次のとおりです。
1: 具体的なタスクの例
- Visual Question Answering (VQA)
- 画像キャプション生成
2: 様々な領域へのM-LLMの適用
3: マルチモーダルLLMのアルゴリズム
- LENS: ビジョンモデルとLLMを組み合わせたフレームワーク
- IDEFICS:最新のオープンなビジュアル言語モデル
- GPT-4 (Vision): ビジョン機能を搭載したGPTモデル
具体的なタスクの例
Visual Question Answering(VQA)
Visual Question Answering (VQA)はAIにおけるタスクで、画像とその画像に関する自然言語の質問をモデルに提示し、モデルが正確な回答を生成するというものです。このタスクでは、モデルが画像の視覚的内容と質問の言語的文脈の両方を理解し、関連する応答を提供する必要があります。
M-LLMは、テキストモダリティとビジュアルモダリティの両方から情報を処理し、融合する能力があるため、VQAに取り組むのに適しています。高度なディープラーニングアーキテクチャを活用することで、画像と質問を同時に分析し、両方のモダリティから関連する特徴量を抽出・統合することで、一貫した理解を構築できます。このため、M-LLMはビジュアルコンテンツに関する幅広い質問に対して、状況に応じた正確な回答を提供できます。
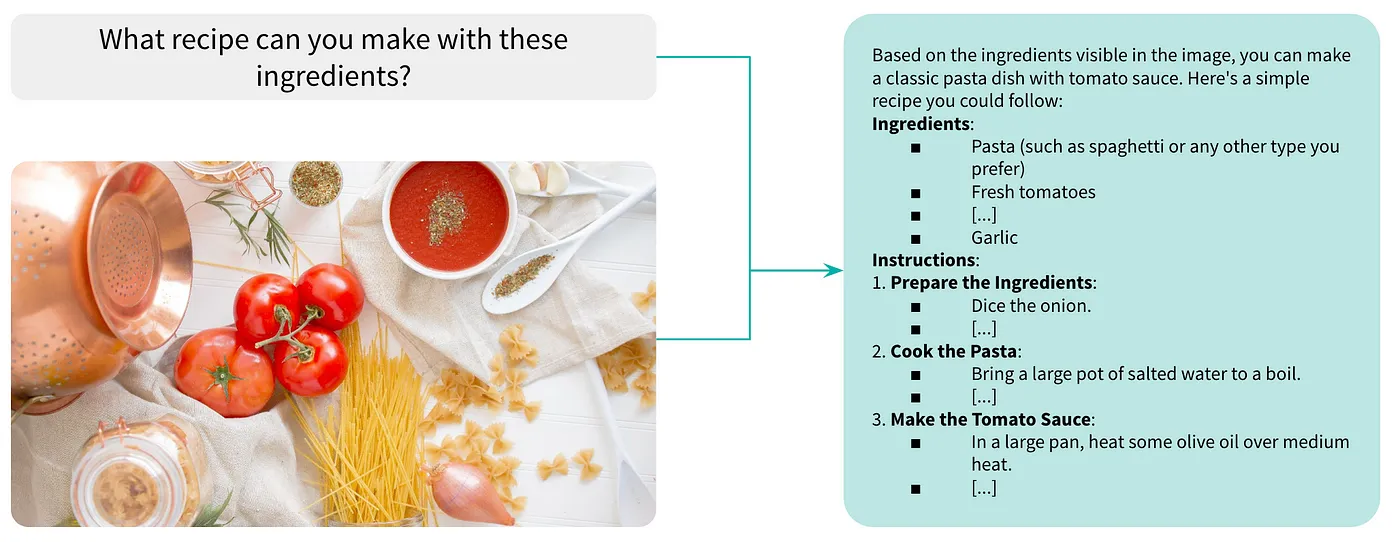
Heather Ford on Unsplashの画像を使用したVQAの例
例えば、パスタ、トマト、タマネギ、ニンニクなどの食材を並べたキッチンカウンターのイメージをM-LLMに提示し 、 「 これらの食材でどんなレシピが作れるか ? 」 と質問することを想像してみてください。M-LLMは食材と一般的なレシピを関連付け、料理に関連する視覚パターンを理解し、モデルがトレーニング段階で学んだ調理法に基づいて応答を生成し、このタスクを成し遂げます。
画像キャプション生成
画像キャプション生成(Image captioning) は、画像のテキスト説明やキャプションを自動的に生成するプロセスを指します。M-LLMは画像とテキストの入力を融合して、一貫性のある説明文を生成できます。
例として、M-LLMを使ったアート画像のキャプション生成について考えてみましょう。このシナリオでは、20世紀半ばの夕暮れ時、車のある大通りを描いた絵画のキャプションを生成するタスクが与えられます。テキストとビジュアルの膨大なコーパスに基づいて事前に訓練されたこのモデルは、まず絵画の視覚的特徴を分析し、地平線上に低く沈む太陽、にぎやかな通りを横切る暖かく黄金色の光、向かいの車の影、建物のシルエットなどの要素を認識しています。昼から夜へと変化するノスタルジーと静けさを呼び覚ましてくれますね。
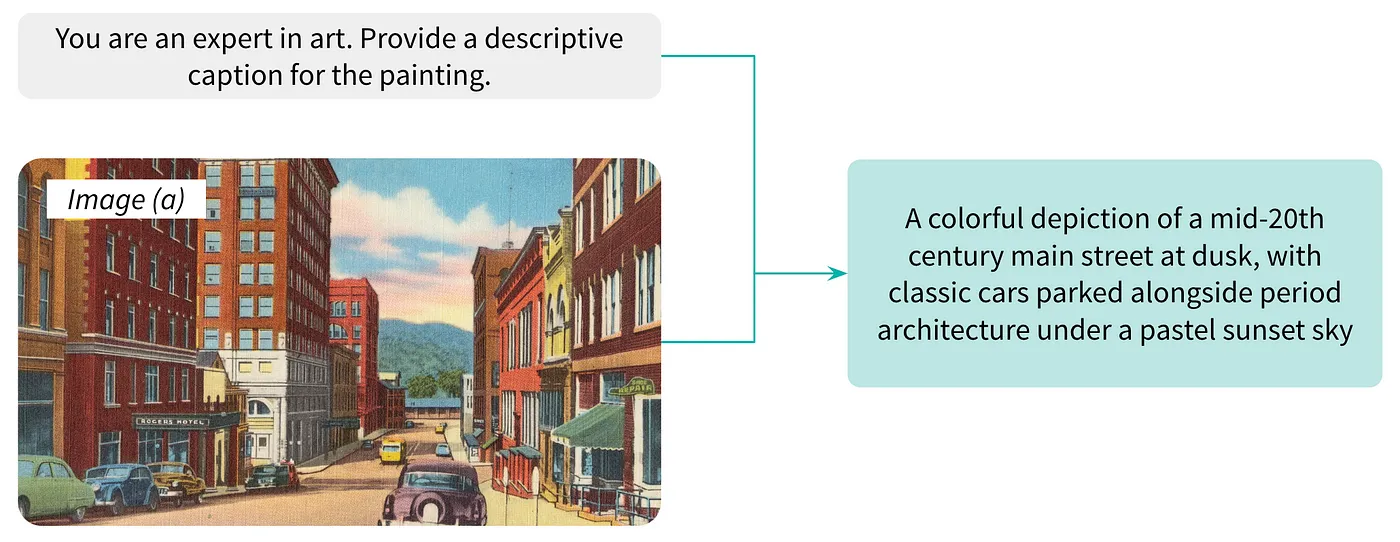
Boston Public Library の画像を使用したキャプション例(Unsplash)
M-LLMは絵画の本質をカプセル化したキャプションを生成します。このキャプションは、作品の視覚的な内容を説明するだけでなく、喚起するムードや雰囲気も伝えており、M-LLMがアートイメージに対してリッチで文脈に即した記述を生成する能力があることを示しています。
様々な領域へのM-LLMの適用
M-LLMは、さまざまな業界への適用に関して、大きな可能性があります。
-
医療診断: 医療領域では、M-LLMを搭載したVQAが医療画像を分析し、診断、治療の選択肢、または患者の状態に関する質問に答えることで、医療従事者を支援できます。例えば、患者の脳のMRIスキャンで「腫瘍はどこにあるのか 」 「 このスキャンに基づくと、どんな治療方法が適しているのか」といった具体的な質問に答えることができ、放射線科医や腫瘍内科医が正確な診断や治療を決定するのに役立ちます
-
Eコマース: M-LLMはEコマースプラットフォームで商品説明を改善するために使用できます。たとえば、ECサイト上のドレスの画像を分析し 、 「レースのディテールがエレガントなブラックカクテルドレス、イブニングイベントに最適です」といった説明文を生成することで、潜在的な購入者に商品の特徴や使用シナリオに関する詳細で魅力的な情報を提供し、ショッピング体験や購入の可能性を向上させることができます
-
バーチャルパーソナルアシスタント:M-LLMを利用することで、バーチャルパーソナルアシスタントの性能と有用性をさらに向上させ、より複雑なコマンドの処理・実行が可能になります。画像のキャプションとVQAを組み合わせることで、画像の説明だけでなく、画像に関する質問に答えるなど、視覚障害者に対する包括的な支援も提供できます。例えば、視覚に障害を持つユーザーが自分が受け取った画像の内容をバーチャルアシスタントに尋ねると、アシスタントは画像の説明と関連する質問に答えるなどです
マルチモーダルLLMのアルゴリズム
VQAや画像キャプション生成に取り組むために、数多くのM-LLMが開発されています。このセクションでは、3つの異なるアプローチについて説明します。
LENS: ビジョンモデルとLLMを組み合わせたフレームワーク
最初のアプローチは LENS (Large Language Models ENhanced to See)と呼ばれるフレームワークで構成されています。LENSは Contextual AI と スタンフォード大学によって提案されました。最先端のビジョンモジュールとLLMの力を組み合わせ、包括的なマルチモーダルの理解を可能にします。
LENSは主に2つのステップで動作します。
- CLIP (Contrastive Language-Image Pre-training)や BLIP (Bootstrapping Language-Image Pre-training)などの既存のビジョンモジュールを使用して、リッチなテキスト情報を抽出します。このテキスト情報には、タグ、属性、キャプションが含まれます
- テキストは推論モジュール(Frozen LLM:凍結LLM)に送られ、ビジョンモジュールが生成したテキストとプロンプトに基づいて回答を生成します
LENSの動作を以下の図に示します。
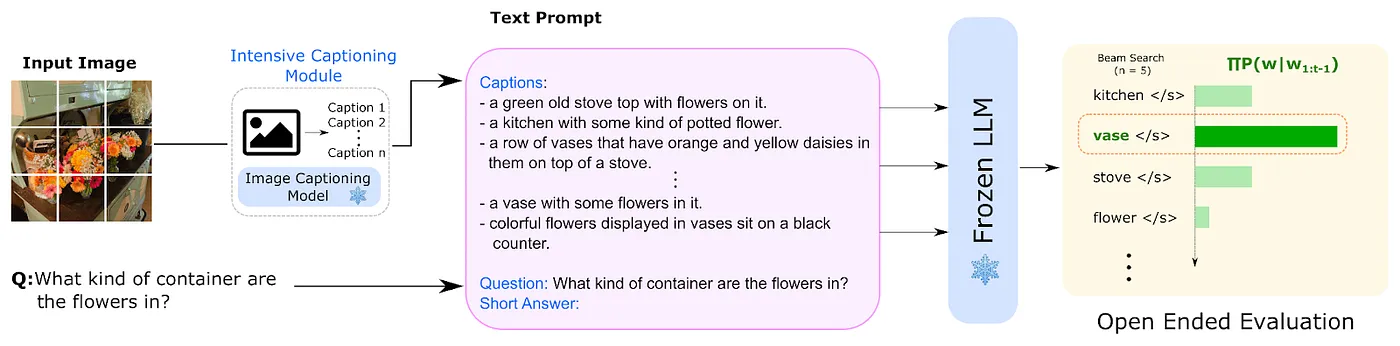
オープンエンドな質問に回答するLENSの仕組み(出典: LENS GitHubリポジトリ)
LENSは画像とテキストの両方を扱うように明示的に訓練されていないにも関わらず、ゼロショットアプローチでFlamingoやBLIP-2のような一般的なマルチモーダルモデルに匹敵する性能が際立っています。
制約の1つとして、特にVQAのテスト中に観察されたのですが、最初のモジュール(つまりCLIPとBLIP)のキャプション出力に大きく依存する点があります。例えば、 画像 (b) に対して「何匹の猫が写っているか」と問い合わせると、CLIPとBLIPによって生成されたキャプションは「3匹の猫がいる」「5匹の猫がいる」と異なっていたため、2番目のモジュール(凍結LLM)は答えを提供できませんでした。

バスケットに入った4匹の猫(Jari Hytönen on Unsplash)
LENSは様々な言語モデルに適用可能であり、追加の事前訓練なしにオーディオ分類や動画アクション推論のようなさまざまなモダリティへの適用可能性があります。このような拡張性と柔軟性により、タスク解決を大きく前進させることができます。
IDEFICS:最新のオープンなビジュアル言語モデル
2番目のアプローチは、 IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS)として知られるオープンソースのM-LLMです。Hugging FaceがリリースしたIDEFICSは、80Bスケールを初めて達成したオープンなビジュアル言語モデルです。IDEFICSは、DeepMindが2022年4月に開発したマルチモーダルモデル Flamingoのアーキテクチャに基づいて、インターリブされた画像とテキストのシーケンスを入力として扱うように調整されており、驚異的な精度でテキスト出力を生成します。
実際にIDEFICSは、Wikipedia、Public Multimodal Dataset、LAIONなどの情報源、特に新しく導入された OBELICS データセットを含む多様なデータに基づいて訓練されています。OBELICSは、2020年2月から2023年2月の間にCommon Crawlのダンプから抽出された、1億4,100万の英語文書、1,150億のテキストトークン、3億5,300万の画像を含む、オープンで膨大な、キュレーションされた画像テキストウェブ文書のコレクションです。これらのウェブ文書で訓練されたモデルは、画像とテキストのペアだけで訓練された視覚モデルや言語モデルと比較して、さまざまなベンチマークで優れた性能を発揮します。
同じウェブ文書から抽出した情報の比較を以下に示します。
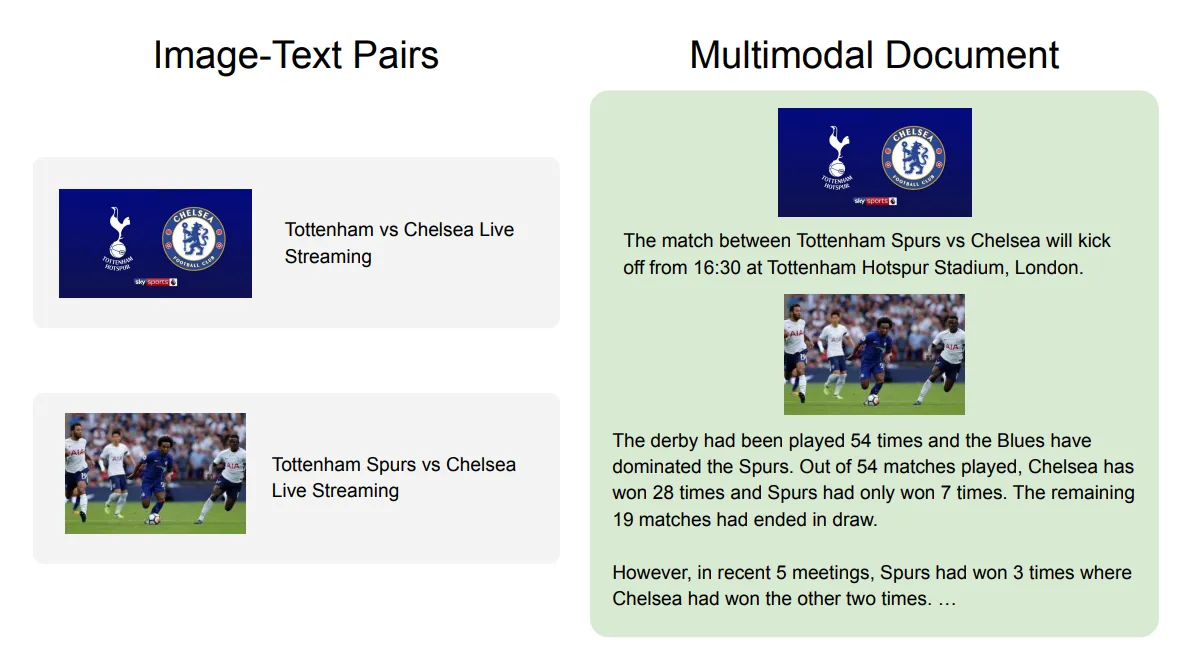
画像とテキストのペア(左)とインターリーブされた画像とテキスト文書(右)の比較。画像は OBELICS論文より
研究論文で説明されているように、画像とテキストのペアの場合、各画像に関連するテキストは短いか、文法的でないことが多いです。しかし、OBELICSの場合、抽出されたマルチモーダルウェブ文書は長い形式のテキストとページ上の画像を組み合わせています。
アーキテクチャ面では、IDEFICSは Flamingoに似た構造に従っています。Flamingoは画像や動画にインターリーブされたテキストを処理し、テキストを生成するM-LLMです。画像はビジョンエンコーダによってエンコードされ、固定数のトークンを出力する Perceiver Resampler によって処理されます。これらのトークンは、クロスアテンション層を通してFrozen(凍結)言語モデルの条件付けに使用されます。
Flamingoアーキテクチャの概要を以下の図に示します。
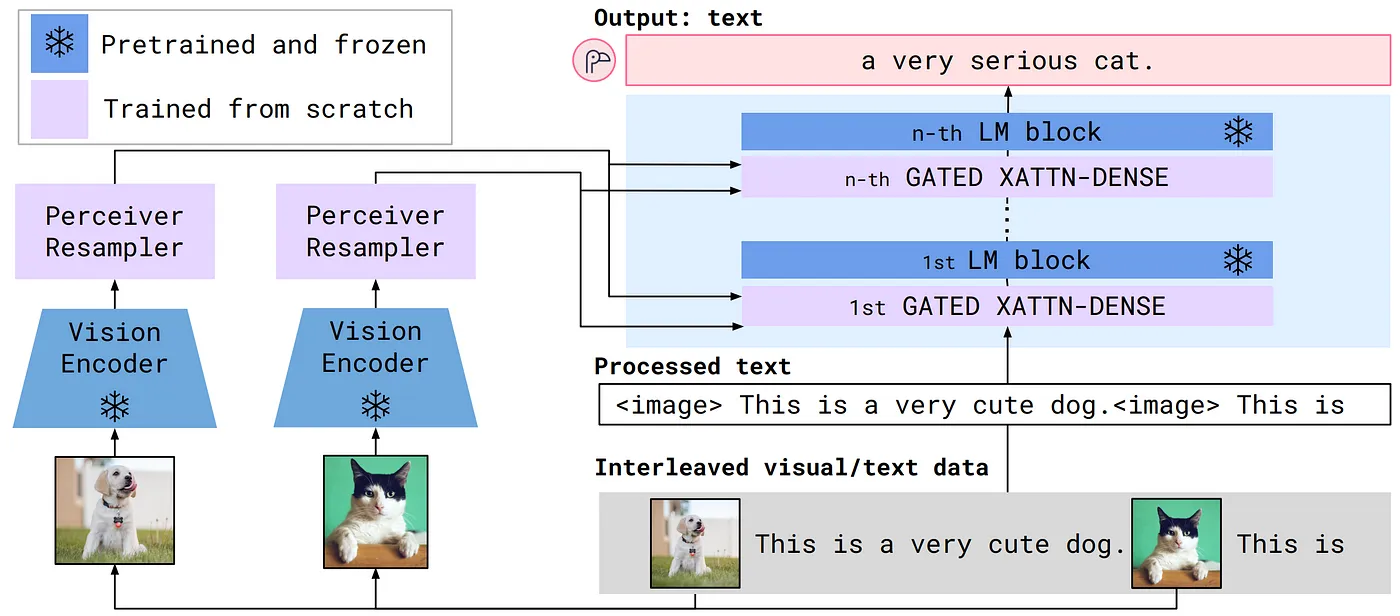
Flamingoアーキテクチャの概要(図は Flamingo論文から引用)
IDEFICSは上記のようなアプローチに基づいており、2つの主な事前学習済みコンポーネントを含んでいます。
- OpenCLIPとして知られる、画像の埋め込みを抽出するためのビジョンエンコーダ
- テキスト埋め込みを生成するためのLlama v1という言語モデル
IDEFICSには、800億個のパラメータを持つ大規模 バージョン と、90億個のパラメータを持つ小規模 バージョン の2つのバリエーションがあります。
IDEFICSのパフォーマンスは、特にVQAタスクで顕著であり、 Image (b) に関する「写真には何匹の猫がいる?」という質問に対して、IDEFICSは「4匹の猫がいる」と応答し、回答の正確さを示しました。
しかし、画像キャプションタスクでは、IDEFICSは比較的単純な記述を生成する傾向がありました。例えば、Image (a) には「建物や車が立ち並ぶ街の通り 」というシンプルなキャプションが付けられていました。
これらの説明は視覚的な内容を正確に伝えていますが、かなり簡潔で、著者や出版日などの追加の背景情報は含まれていませんでした。
GPT-4 (Vision): ビジョン機能を搭載したGPTモデル
3番目の方法は、GPT-4 (Turbo with Vision) として知られる商用LLMの利用です。GPT-4Vは、有名なGPT-4モデルに視覚解析機能を統合し、ユーザーが提供した画像の解析をモデルに指示することができます。これは、OpenAIのGPT-4機能の最新の進化版です。
GPT-4Vの詳細なアーキテクチャは非公開のままですが、いくつかの主要な側面が知られています。
- GPT-4Vの訓練は2022年に完了し、2023年3月にシステムの早期利用が可能となった
- GPT-4VはGPT-4と同様、さまざまなオンラインソースとライセンスされたデータベースのテキスト、および画像データを含む膨大なデータセットを活用し、文書内の次の単語を予測するトレーニングを行った
- 事前学習モデルは、人間が好む出力の生成を目的としたヒューマンフィードバック(RLHF)・強化学習で、さらに改良を加えた
- OpenAIは、視覚障害者向けのツールを開発するBe My Eyesのような組織を含む、様々なユーザーに早期アクセスを許可した。2023年3月から2023年8月にかけて実施されたこのパイロットプログラムは、GPT-4Vの責任ある展開戦略検討を目的としていた
テストでは、VQAタスクと画像キャプションタスクの両方で大きな進歩が見られました。このモデルは「何匹の猫が写っているか」といった質問に「4匹の猫、すべての子猫が屋外の木籠の中にいる」といった回答で正確に答えるなど、VQAで驚異的な精度を示しました。
画像のキャプションでは、 Image (a) に対して「夕暮れ時の20世紀半ばの大通りを色彩豊かに描写、パステル調の夕焼け空の下、古い建物と平行してクラシックカーが停まっている」とIDEFICSとは正反対の表現をしています。GPT-4Vは時折、詳細がない簡潔なタイトルのみを生成することもありました。画像の内容は常に正確に記述していましたが、著者、タイトル、年などコンテキスト情報の記述については、一貫性がない結果でした。
おわりに
M-LLMを用いたVQAや画像キャプションを取り巻く状況は活気に満ち、急速に進化しています。オープンソース、商用の両方で定期的に新しいモデルがリリースされ、この分野では、かつてないほどイノベーションと試行実験が急増しています。このダイナミズムは、M-LLMを活用したマルチモーダルな世界の把握とAIへの適用に対する、大きな可能性と幅広い関心を示しています。
さらに、M-LLMの能力が拡張し続けるにつれて、現在では マルチモーダルRAGなど、さらに強力で汎用性の高いシステムが出現しています。マルチモーダルRAGに代表されるモデルは、検索ベースの手法と生成ベースのアプローチを統合することで、VQAや画像キャプションだけでなく、さまざまなマルチモーダルタスクに変革をもたらすでしょう。革新的フレームワークの統合により、マルチモーダルAIはさらに進化していくと考えられます。
当記事で説明したアプローチの実践的なデモは、Dataikuのギャラリーで公開されているプロジェクトで確認できます。このブログ記事は、Camille Cochenerとの共著です。
Dataikuプロジェクトのマルチモーダルチャットボット
その他の技術コンテンツについて詳しく知る
LLMの量子化、AIアクセラレータとしての量子コンピュータ、パラメータ効率の良いLLMのファインチューニングなどに関する最新情報は、Data From the Trenchesの記事をご覧ください。