はじめに
2chは言わずと知れた匿名掲示板であり、膨大な情報量を誇る。
ただ、スレッドのレス一つ一つに目を通していては、全体像をつかむのに莫大な時間を要してしまう。
そこで、これらの情報をWordCloudで可視化し、簡単に全体像をつかめないかと試みた。

上記は”FFRK”でスレッド検索した結果のうち、直近約8カ月分のレス内容をWordCloudで出力したもの。
シンクロ奥義が実装されて約1年たつが、いまだに覚醒奥義のほうが多く話題に上っていることが分かる。また、キャラとしてFFRKオリキャラのデシ・ウララ以外に、バッツ、エッジ、クラウド、モグなどが比較的に話題に出ている。といったことが予想できる。
スクレイピングも自然言語処理も初学者だが、こんな感じで自分なりに形になったので記していきたい。
今回は前編として、Webスクレイピングでスレッド情報からレス内容までの収集を行なう。
全体の流れ
- 「ログ速」をスクレイピングして対象スレッドのURLを抽出 ← 今回解説
- 2chスレッドをスクレイピングしてレスを抽出 ← 今回解説
- 抽出したレス内容をMecabで形態素解析
- WordCloudで出力
コード全文
クリックして全文を表示(スクレイピング以外の処理含む)
# ライブラリのインポート
import requests, bs4
import re
import time
import pandas as pd
from urllib.parse import urljoin
# フォントをColabローカルにインストール
from google.colab import drive
drive.mount("/content/gdrive")
# 事前に自分のGoogleDriveのマイドライブのトップにfontというフォルダを作っておき、その中に所望のフォントファイルを入れておく
# フォルダごとColabローカルにコピー
!cp -a "gdrive/My Drive/font/" "/usr/share/fonts/"
# ------------------------------------------------------------------------
# 下準備
log_database = [] # スレッドの情報を格納するリスト
base_url = "https://www.logsoku.com/search?q=FFRK&p="
# Webスクレイピングの実施
for i in range(1,4): # どのページまでさかのぼるか(ここでは仮で4ページ目まで)
logs_url = base_url+str(i)
# スクレイピング処理本体
res = requests.get(logs_url)
soup = bs4.BeautifulSoup(res.text, "html.parser")
# 検索結果が見つからなかった時の処理
if soup.find(class_="search_not_found"):break
# スレッド情報が格納されたテーブル・行の取得
thread_table = soup.find(id="search_result_threads")
thread_rows = thread_table.find_all("tr")
# 各行に対する処理
for thread_row in thread_rows:
tmp_dict = {}
tags = thread_row.find_all(class_=["thread","date","length"])
# 中身の整理
for tag in tags:
if "thread" in str(tag):
tmp_dict["title"] = tag.get("title")
tmp_dict["link"] = tag.get("href")
elif "date" in str(tag):
tmp_dict["date"] = tag.text
elif "length" in str(tag):
tmp_dict["length"] = tag.text
# レス数が50を超えるもののみデータベースに加算
if tmp_dict["length"].isdecimal() and int(tmp_dict["length"]) > 50:
log_database.append(tmp_dict)
time.sleep(1)
# DataFrameへ変換
thread_df = pd.DataFrame(log_database)
# ------------------------------------------------------------------------
# 過去ログからレス取得
log_url_base = "http://nozomi.2ch.sc/test/read.cgi/"
res_database = []
for thread in log_database:
# 過去ログ一覧から板名と掲示板No.を取り出し、過去ログのURLを生成
board_and_code_match = re.search("[a-zA-Z0-9_]*?/[0-9]*?/$",thread["link"])
board_and_code = board_and_code_match.group()
thread_url = urljoin(log_url_base, board_and_code)
# 過去ログページからhtml抽出
res = requests.get(thread_url)
soup = bs4.BeautifulSoup(res.text, "html5lib")
tmp_dict = {}
# dtタグに日付などの情報
# ddタグにコメントが格納されている
dddt = soup.find_all(["dd","dt"])
for tag in dddt[::-1]: # 後ろから抽出していく
# dtタグから日付のみを抽出
if "<dt>" in str(tag):
date_result = re.search(r"\d*/\d*/\d*",tag.text) # "(←の'"'は気にしないqiitaの表示異常回避のため)
if date_result:
date_str = date_result.group()
tmp_dict["date"] = date_str
# ddタグからレス内容を抽出
if "<dd>" in str(tag):
tmp_dict["comment"] = re.sub("\n","",tag.text)
# tmp_dictに格納した内容をres_databaseに転記
if "date" in tmp_dict and "comment" in tmp_dict:
tmp_dict["thread_title"] = thread["title"]
res_database.append(tmp_dict)
tmp_dict = {}
time.sleep(1) # お約束
# DataFrameへ変換
res_df = pd.DataFrame(res_database)
# ------------------------------------------------------------------------
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# wordcloudのインストール
!pip install wordcloud
# レスをすべて結合
sentences = ",".join(res_df["comment"])
sentences_sep = []
n = 10000
for i in range(0,len(sentences), n):
sentences_sep.append(sentences[i:i + n])
# レスをn(=1000)レス毎に区切り、カンマで結合
# 区切る目的はのちのmecabが多すぎる文字量に対応できないため
sentences_sep = []
n = 1000
for i in range(0, len(res_df["comment"]), n):
sentences_sep.append(",".join(res_df["comment"][i: i + n]))
# ------------------------------------------------------------------------
import MeCab
# mecab-ipadic-neologd辞書が格納されたパスを指定
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
# 上記パス(/usr/~)は下記コマンドで取得
# !echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
# Taggerオブジェクトの生成
mecab = MeCab.Tagger(path)
# 区切ったレス群ごとに形態素解析を実行
chasen_list = [mecab.parse(sentence) for sentence in sentences_sep]
word_list = []
# chasen_listを1行まで分解
# ex. 鉄巨人 名詞,固有名詞,一般,*,*,*,鉄巨人,テツキョジン,テツキョジン)
for chasen in chasen_list:
for line in chasen.splitlines():
if len(line) <= 1: break
speech = line.split()[-1]
if "名詞" in speech:
if (not "非自立" in speech) and (not "代名詞" in speech) and (not "数" in speech):
word_list.append(line.split()[0])
word_line = ",".join(word_list)
# ------------------------------------------------------------------------
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 事前にColabローカルにフォントインストールしておく必要あり
f_path = "BIZ-UDGothicB.ttc"
stop_words = ["https","imgur","net","jpg","com","そう"]
wordcloud = WordCloud(
font_path=f_path,
width=1024, height=640, # default width=400, height=200
background_color="white", # default=”black”
stopwords=set(stop_words),
max_words=350, # default=200
max_font_size=200, #default=4
min_font_size=5, #default=4
collocations = False #default = True
).generate(word_line)
plt.figure(figsize=(18,15))
plt.imshow(wordcloud)
plt.axis("off") #メモリの非表示
plt.show()
環境 ~Google Colaboratory~
GoogleColaboratoryを使用
GoogleColaboratoryは、Googleアカウントさえあれば、誰でも使えるブラウザ上のPythonの実行環境。
強力なGPUを使用可能なため機械学習の場面で多く用いられるが、スクレイピングだけならライブラリのインストールも不要なので、気軽にスクレイピングしてみたい場合にもおすすめ。
(次回説明予定のMecabやWordCloud等では追加インストールが必要)
GoogleColaboratoryの使い方は下記の記事を参照
⇒ Google Colabの使い方まとめ
(試していないが、ライブラリのインストールなどやれば別にColabでなくとも可だと思う)
解説
スクレイピングの基本
requests.get()でWebページのオブジェクトを取得し、それをbs4.BeautifulSoup()でHTML解析している。スクレイピングの入り口。
”html.parser"はパーサーの指定。ログ速では”html.parser"(よく使われるやつ)で問題ないが、2chでは"html5lib"というパーサーを使用する。
("html.parser"ではなぜか解析に失敗するため)
# スクレイピング処理本体
res = requests.get(logs_url)
soup = bs4.BeautifulSoup(res.text, "html.parser")
お約束
スクレイピングでWebサイトに複数回アクセスする場合、サーバーに負荷がかからないよう、繰り返しの合間にtime.sleep(1)を挟む。
【「ログ速」からスレッド一覧をスクレイピングする】
「ログ速」から任意のキーワードを含むスレッド(現行スレッド含む)を検索し、その結果を抽出する。
ログ速:https://www.logsoku.com/
スクレイピングするURLの取得
上記サイトで試しに検索をしてみると、こんな感じのURLに。
「FFRK」で検索:https://www.logsoku.com/search?q=FFRK
2ページ目以降:https://www.logsoku.com/search?q=FFRK&p=2
検索結果のURLから、下記のようなことが分かった。
・https://www.logsoku.com/search?にq=<検索ワード>をくっつけたURLが検索結果のページ(qはquestのq?)
・p=<ページ数>で検索結果の各ページに直接アクセスできる(pはpageのp?)
・p=1でも1ページ目を表示できる。
・検索結果がないページもアクセスできてしまう
上記から、アクセスするページのURLはfor文を回して取得できそう。
有効でない検索ページについても、幸い、ページ自体にはアクセス可能。検索結果がないページでは"search_not_found"というクラスがあるので、これを判定に使用する。
base_url = "https://www.logsoku.com/search?q=FFRK&p="
for i in range(1,100):
logs_url = base_url+str(i)
# スクレイピングの実行
res = requests.get(logs_url)
soup = bs4.BeautifulSoup(res.text, "html.parser")
# 検索結果が見つからなかった時の処理
if soup.find(class_="search_not_found"):break
:
(各ページに対する処理)
:
各検索ページに対してのスクレイピング
実際にスクレイピングを行なう前に、対象ページのHTMLを眺めて、どのように処理を行なうのか考える。
そのとき役に立つのが各ブラウザに備わっている**「開発ツール」。ブラウザでF12を押すと起動する。
その状態で「ページから要素を選択」**をクリックすると、Webページの任意の場所をカーソルに目を合わせた時、HTML内のどこを指しているか分かるようになる。
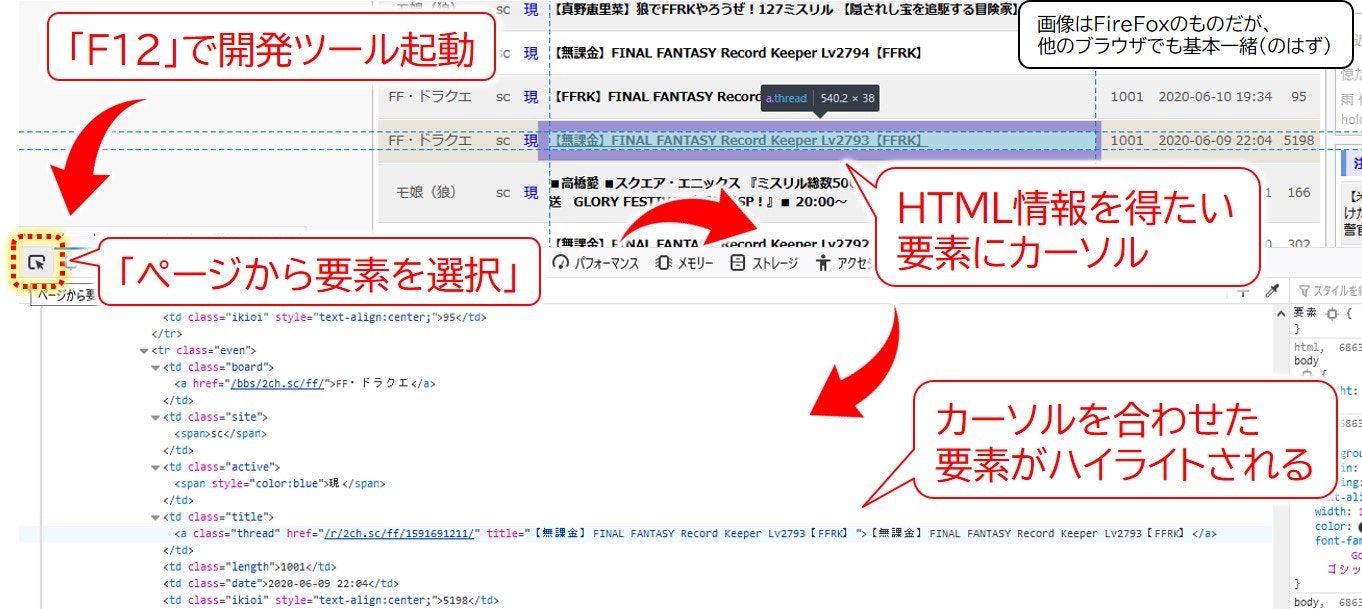
開発ツールで2chのスレッドを眺めていて、以下の点が分かった。
・必要な情報はすべてdiv#search_result_threads以下に格納されている。
・1スレッドの情報は各trタグの中で格納されている
・スレッドのタイトルおよびリンクはtrタグの中のa.thredの中に格納されている。
・スレッドのレス数はtrタグの中のtd.lengthに格納されている
・スレッドの更新日時はtrタグの中のtd.dateに格納されている。
これらを踏まえ、以下のようにしてスクレイピング実施。
レス数が50未満のスレッドは重複などの可能性が高いので、省いた。
抽出結果は辞書型に格納しておくと分かりやすいし、後述のDataFrame形式に変換するときにも楽できる。
# スレッド情報が格納されたテーブル・行の取得
thread_table = soup.find(id="search_result_threads")
thread_rows = thread_table.find_all("tr")
# 各行に対する処理
for thread_row in thread_rows:
tmp_dict = {}
tags = thread_row.find_all(class_=["thread","date","length"])
# 中身の整理
for tag in tags:
if "thread" in str(tag):
tmp_dict["title"] = tag.get("title")
tmp_dict["link"] = tag.get("href")
elif "date" in str(tag):
tmp_dict["date"] = tag.text
elif "length" in str(tag):
tmp_dict["length"] = tag.text
# レス数が50を超えるもののみデータベースに加算
if tmp_dict["length"].isdecimal() and int(tmp_dict["length"]) > 50:
log_database.append(tmp_dict)
time.sleep(1)
とりあえず、これで検索した2chスレッド情報を取得することができた。
あとで取り回しがしやすいよう、pandasのDataFrame形式に変換しておく。
thread_df = pd.DataFrame(log_database) # 変換
表示
thread_df
 まず、スレッド一覧を抽出することができた。
まず、スレッド一覧を抽出することができた。
【2chのスレッドをスクレイピングする】
上記で取得したスレッド情報をもとに、スレッドの中身を抽出していく。
2chでは、以下のようにしてスレッドのURLを指定する。
「http://nozomi.2ch.sc/test/read.cgi/」+「板コード/」+「掲示板No./」
板コードと掲示板No.は、前述のスクレイピングで取得したリンクから正規表現re.search("[a-zA-Z0-9_]*?/[0-9]*?/$",thread["link"]を使用して抽出。
# 過去ログからレス取得
log_url_base = "http://nozomi.2ch.sc/test/read.cgi/"
res_database = []
for thread in log_database:
# 過去ログ一覧から板名と掲示板No.を取り出し、過去ログのURLを生成
board_and_code_match = re.search("[a-zA-Z0-9_]*?/[0-9]*?/$",thread["link"])
board_and_code = board_and_code_match.group() # 正規表現オブジェクトから結果を変換
thread_url = urljoin(log_url_base, board_and_code)
:
(各スレッドに対する処理)
:
レス内容・投稿日の取得
ログ速と同様にブラウザの開発ツール(F12)を活用して、スクレイピングするページの傾向を調査する。
2chではこんな傾向がつかめた。
・ddタグとdtタグのセットで一つのレス。
・dd,dtタグはレス以外の場所では使用されてなさそう
・ddタグの中には、レス日時の他、コテやIDといった情報も含まれる。
・dtタグの中に、レス内容が格納されている。
これらを踏まえ、以下のようにしてスクレイピングを行なった。前述したようにパーサーは"html5lib"を使用する。
# 過去ログページからhtml抽出
res = requests.get(thread_url)
soup = bs4.BeautifulSoup(res.text, "html5lib") # 2chではhtml5libを使用
tmp_dict = {}
# dtタグに日付などの情報
# ddタグにレス内容が格納されている
dddt = soup.find_all(["dd","dt"])
for tag in dddt[::-1]: # 後ろから抽出していく
# dtタグから日付のみを抽出
if "<dt>" in str(tag):
date_result = re.search(r"\d*/\d*/\d*",tag.text) # "(←の'"'は気にしないqiitaの表示異常回避のため)
if date_result:
date_str = date_result.group()
tmp_dict["date"] = date_str
# ddタグからレス内容を抽出
if "<dd>" in str(tag):
tmp_dict["comment"] = re.sub("\n","",tag.text)
# tmp_dictに格納した内容をres_databaseに転記
if "date" in tmp_dict and "comment" in tmp_dict:
tmp_dict["thread_title"] = thread["title"]
res_database.append(tmp_dict)
tmp_dict = {}
time.sleep(1) # お約束
流れとして、まずddタグとdtタグをごちゃまぜで抽出し、一つ一つ分解してdtタグかddタグかの判定を行なって、それぞれ辞書型に格納していった。
(実際、まとめて抽出したddタグとdtタグは規則的に並んでおり判定は不要。しかし、一応別パターンが発生した場合に対応できるよう判定を挟んでみた)
DataFrameへ変換
res_df = pd.DataFrame(res_database)
表示
res_df

無事2chのレス内容と投稿日の情報を抽出することができた。
今後の予定
次回、抽出した内容を形態素解析を行なったのち、WordCloudに出力していく。