Stable Diffusion
画像生成AIを使ってみましょう
Stable Diffusionのインストールと起動
環境
- Windows11のWSL2上のUbuntu 22.04.2 LTS
- GPUはNVIDIA RTX3060 12GB
- あらかじめUbuntu上にPython環境を構築しておくこと
NVIDIA GPUのドライバをWindows上にインストール
- https://www.nvidia.co.jp/Download/index.aspx?lang=jp
- Game ReadyとStudio、どっちでもOK。Studioの方が安定してる??
NVIDIA CUDA ToolkitをUbuntu上にインストール
-
WSL上のUbuntu上でnvidia-cuda-toolkitをインストール -> https://developer.nvidia.com/cuda-downloads
(Operating System: Linux, Architecture: x86_64, Distribution: WSL-Ubuntu, Version: 2.0, Installer Type: どれでも) -
インストールされているか確認する
nvidia-smi
- nvccも
nvcc --version
Stable Diffusion WebUI の設定
- ユーザーの home ディレクトリで git clone コマンドを実行する
cd
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- webui-user.sh の編集(xformers を有効にするために、webui-user.sh 内の COMMANDLINE_ARGS の先頭の # を消して有効にして、xformers のオプションを入力する
export COMMANDLINE_ARGS="--xformers"
とりあえず適当な学習済みモデルのダウンロード
- 以下のコマンドを入力
cd ~/stable-diffusion-webui/models/Stable-diffusion/
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.safetensors
Stable Diffusion WebUIの実行(初回はインストールも)
cd ~/stable-diffusion-webui
./webui.sh
- 表示されたアドレスをコピーしてブラウザで開く
- ブラウザ上で画像が生成できる!
画像の生成
好みの画像を生成してみよう。そのためには、生成した画像に適した学習済みモデル等が必要。
生成した画像に適した学習済みモデルをダウンロードしてくる
例として、リアル系で有名なモデル(Realistic_Vision)を適用してみる。
-
モデルを配布しているWebサイト(例:https://huggingface.co/)にアクセスし、検索欄からRealistic_Vision_V2.0を探して、ダウンロード。(safetensorsと記載のあるものが安全っぽい)
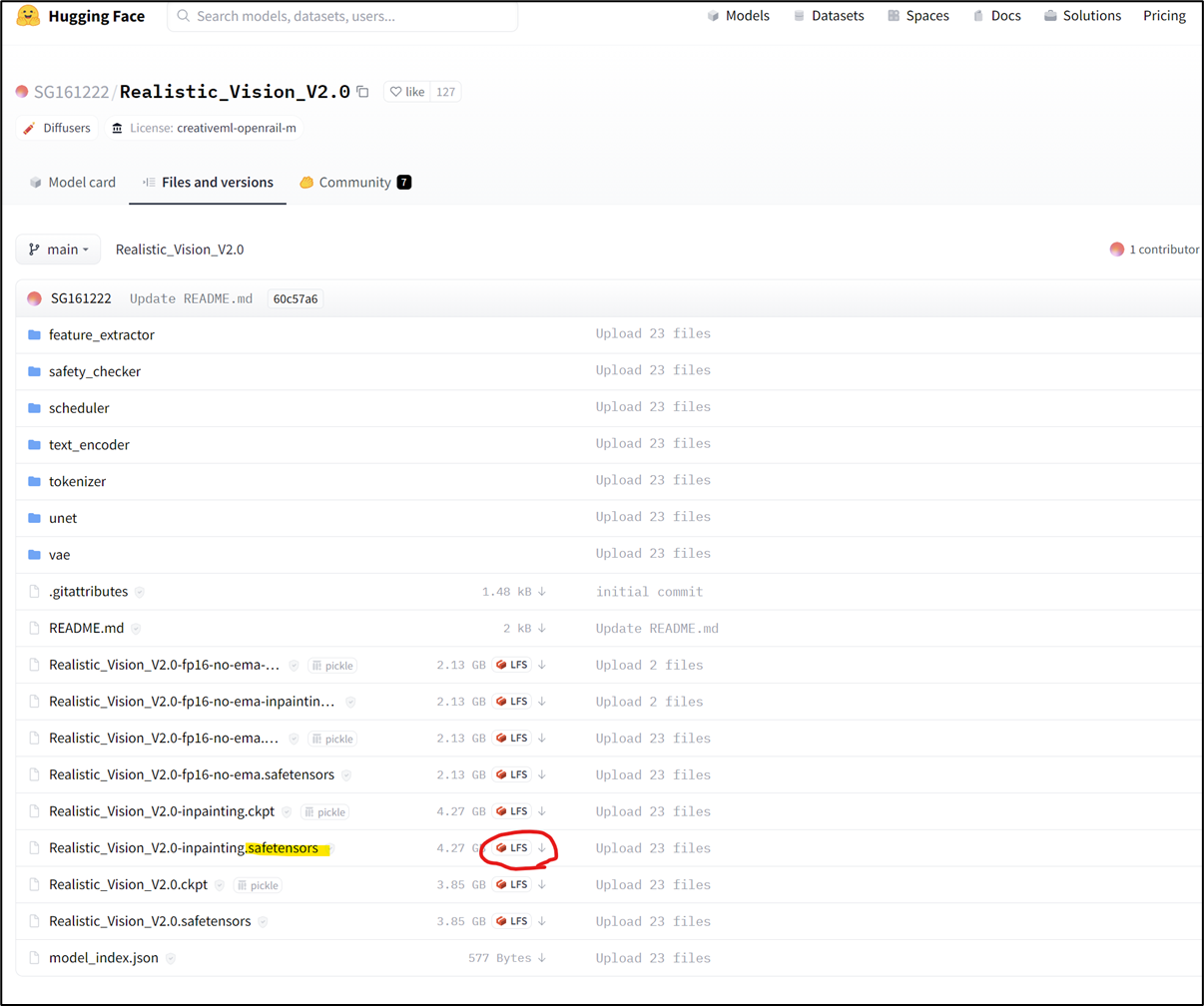
-
ダウンロードしたファイルを、~/stable-diffusion-webui/models/Stable-diffusion/に移動する
cd /mnt/c/Users/(ユーザー名)/Download/(ダウンロードしたモデルファイル名) ~/stable-diffusion-webui/models/Stable-diffusion/
- 再度Stable Diffusionを起動する
cd ~/stable-diffusion-webui/
./webui.sh
- 表示されたアドレスをブラウザで開く
- 使われているモデルを確認する。画面左上に現在使っているモデルが表示される。今回入手したモデルが表示されていれば成功!
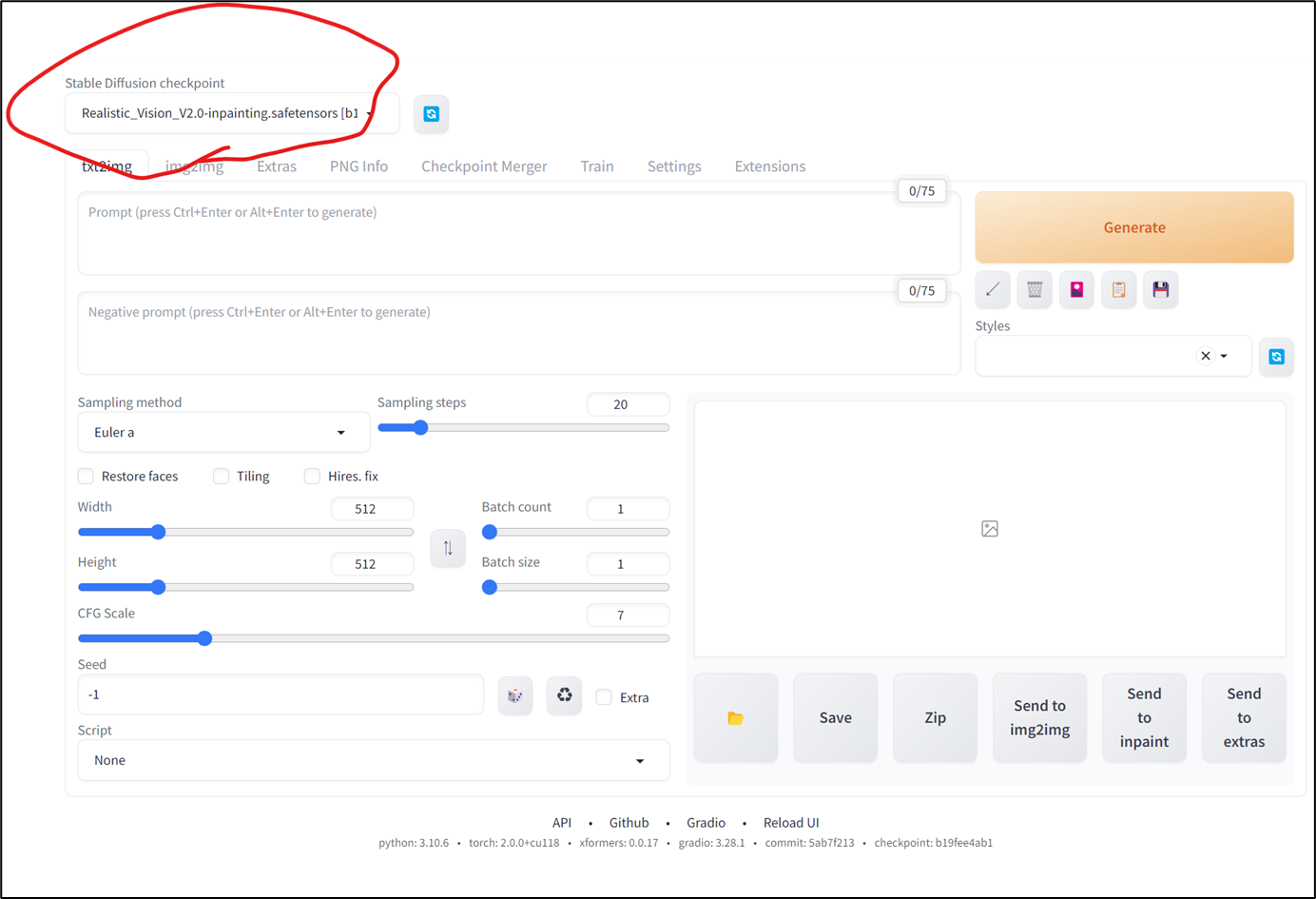
VAEを設定する
VAEとは、Variasional Auto Encorderの略で、潜在空間と画像を変換するアルゴリズムのこと。画像の質が変化する。
-
モデルと生成したい画像に適したVAEファイルをダウンロードしてくる。例えばここから。
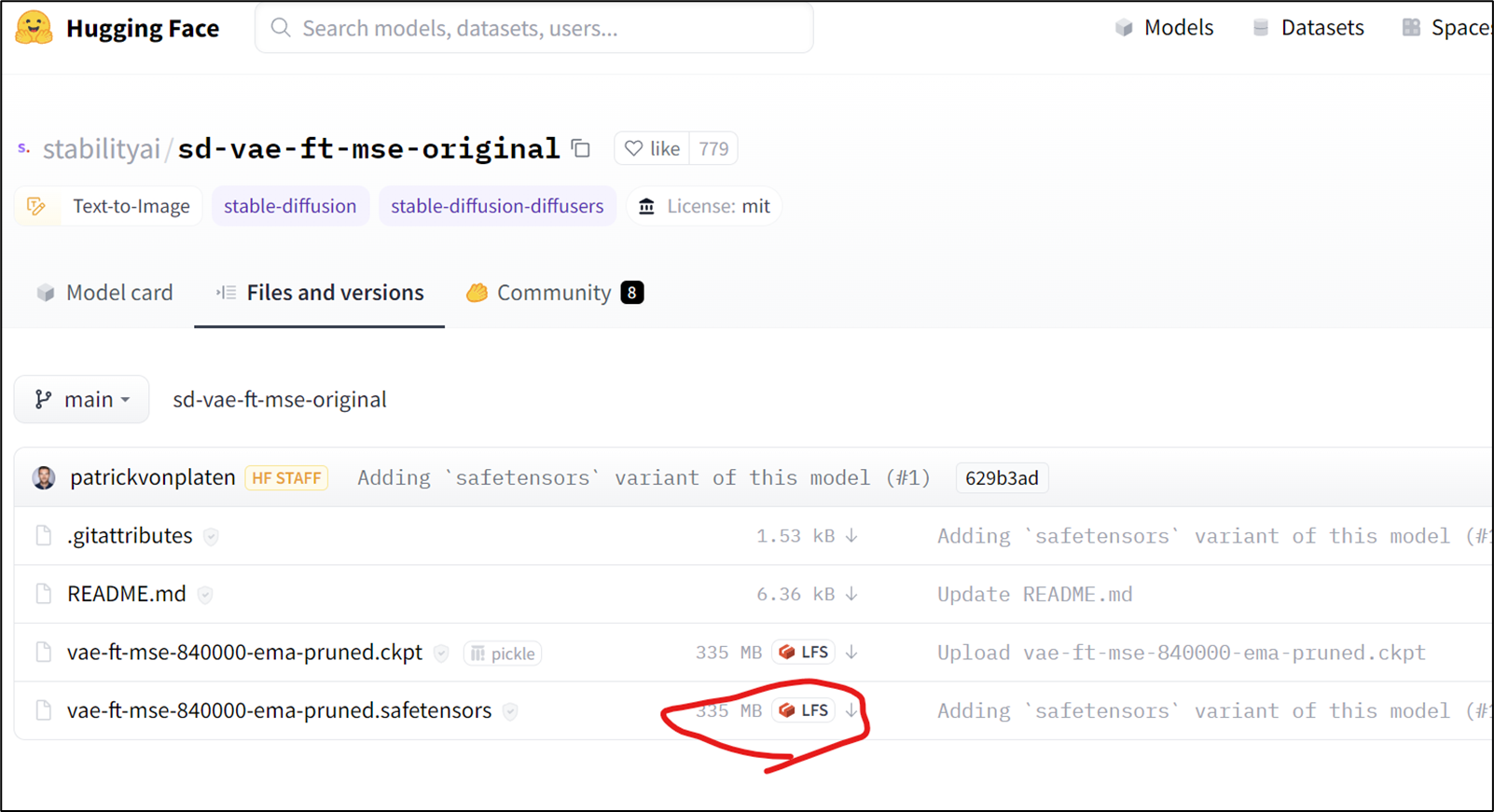
-
ダウンロードしてきたファイルを、~/stable-diffusion-webui/models/VAEに移動する
cp /mnt/c/Users/(ユーザー名)/Downloads/(ダウンロードしたVAEファイル名) ~/stable-diffusion-webui/models/VAE/
- Stable diffusion Webuiを再起動したのち、Settings -> Stable Diffusion -> SD VAEから選択する
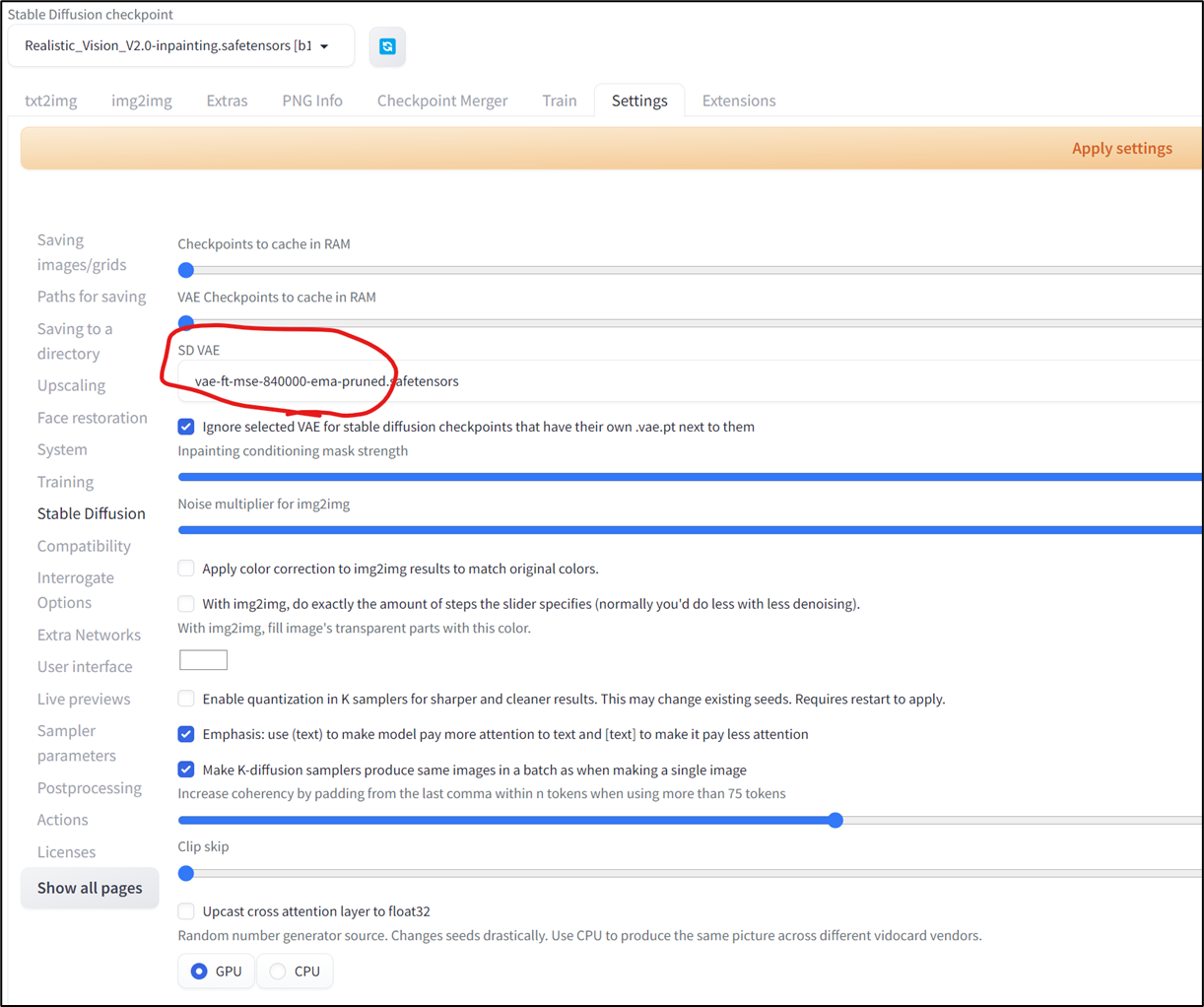
画像を生成してみる
- Prompt欄に、作成したい画像の情報を入力する
- Negative prompt欄に、作成したくない画像の情報を入力する
- 画像サイズの標準は512x512 pixels。例えば縦長が良ければ768 x 512 pixelsなど。サイズによって生成される画像が変化することに注意。Stable Diffusionのモデルは512x512で学習しているんだとか。なので、むやみに大きなサイズの画像を生成すると、変な画像ができあがる可能性大。
- 作成例:

これ以降は
- 毎回立ち上げ時には、以下を実行して、ブラウザで指定のIPアドレスを開けばWebUI上で画像を作成できます。
cd ~/stable-diffusion-webui/
./webui.sh