PyTorch全盛の今ですが、TensorFlowが2.0になりkerasが統合されたなら試してみなきゃ!ということで試してみました第2弾です。第1弾はこちら。
今回は tf.data.Datasetの構築 をしてみよう!ということで、今後メモリに入りきらないデータの学習やData Augmentationをバリバリ使いたいなあというのがモチベーションです。
こちらの公式を参考にしています。
ソースは GITHUB で公開しています。Google Colaboratory で実行可能です。
import
Google Colaboratory ではまだデフォルトのTensorFlowは1.xなので、2.0に変更してインポート(近々デフォルトがアップデートされる予定のようです。)
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
Data
Google Colaboratory の sample_dataフォルダ に用意されている MNIST_small(csvファイル)を使います。
最初の列がラベルになっていて、残りは28*28=784列になっているようなので、reshapeなどしてとりあえずndarrayにしておきます。
mnist_train_small = pd.read_csv('sample_data/mnist_train_small.csv', header=None)
mnist_test = pd.read_csv('sample_data/mnist_test.csv', header=None)
y_train = mnist_train_small.iloc[:, 0].to_numpy()
x_train = mnist_train_small.drop(columns=0).to_numpy().reshape(-1,28,28)
y_test = mnist_test.iloc[:, 0].to_numpy()
x_test = mnist_test.drop(columns=0).to_numpy().reshape(-1,28,28)
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.imshow(x_train[0])
plt.colorbar()
plt.show()

/255 します。
x_train, x_test = x_train / 255.0, x_test / 255.0
MNISTの画像を確認
plt.figure(figsize=(8,8))
for i in range(4*4):
plt.subplot(4,4,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(y_train[i])
plt.show()

Dataset
いよいよメインの tf.data.Datasetの構築 です。
tf.data.Dataset.from_tensor_slices で (image, label)のペアのデータセット を作ります。
データがメモリに収まらない場合のために、cacheメソッドでキャッシュファイルを使用してみました。(今回は不要ですが)
バッチサイズ、シャッフル、リピートを指定しておきます。
バリデーションデータについても Dataset オブジェクトにしてバッチサイズを指定しておきます。(学習時のバリデーションに必要ですが、バリデーションになぜ必要なのか正直良く分かりません。)
image_label_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
ds = image_label_ds.cache(filename='./cache.tf-data')
ds = ds.apply(
tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))
AUTOTUNE = tf.data.experimental.AUTOTUNE
BATCH_SIZE = 32
ds = ds.batch(BATCH_SIZE).prefetch(1)
ds_valid = tf.data.Dataset.from_tensor_slices((x_test, y_test))
ds_valid = ds_valid.batch(BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)
Model
第1弾と同じく、CNNですらない、シンプルなモデルで試します。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
Train
学習します。
学習データ、バリデーションデータに Datasetオブジェクトを指定しています。
steps_per_epochは 学習データ/バッチサイズ にしています。
history = model.fit(ds, epochs=10, steps_per_epoch=625, workers=0, validation_data=ds_valid)
Train for 625 steps, validate for 313 steps
Epoch 1/10
625/625 [==============================] - 3s 5ms/step - loss: 0.4385 - accuracy: 0.8737 - val_loss: 0.2224 - val_accuracy: 0.9370
Epoch 2/10
625/625 [==============================] - 2s 4ms/step - loss: 0.2197 - accuracy: 0.9366 - val_loss: 0.1707 - val_accuracy: 0.9512
Epoch 3/10
625/625 [==============================] - 2s 4ms/step - loss: 0.1646 - accuracy: 0.9517 - val_loss: 0.1521 - val_accuracy: 0.9566
Epoch 4/10
625/625 [==============================] - 2s 4ms/step - loss: 0.1354 - accuracy: 0.9612 - val_loss: 0.1284 - val_accuracy: 0.9599
Epoch 5/10
625/625 [==============================] - 2s 4ms/step - loss: 0.1089 - accuracy: 0.9676 - val_loss: 0.1299 - val_accuracy: 0.9615
Epoch 6/10
625/625 [==============================] - 2s 4ms/step - loss: 0.0942 - accuracy: 0.9720 - val_loss: 0.1095 - val_accuracy: 0.9668
Epoch 7/10
625/625 [==============================] - 2s 4ms/step - loss: 0.0790 - accuracy: 0.9761 - val_loss: 0.1143 - val_accuracy: 0.9668
Epoch 8/10
625/625 [==============================] - 2s 4ms/step - loss: 0.0680 - accuracy: 0.9800 - val_loss: 0.1037 - val_accuracy: 0.9676
Epoch 9/10
625/625 [==============================] - 2s 4ms/step - loss: 0.0580 - accuracy: 0.9823 - val_loss: 0.1073 - val_accuracy: 0.9695
Epoch 10/10
625/625 [==============================] - 2s 4ms/step - loss: 0.0545 - accuracy: 0.9827 - val_loss: 0.1002 - val_accuracy: 0.9710
学習の推移を確認
plt.plot(history.history["accuracy"], label="train", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="test", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()

Test
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)
10000/10000 [==============================] - 1s 67us/sample - loss: 0.1004 - accuracy: 0.9710
結果をいくつか確認しましょう。
import numpy as np
plt.figure(figsize=(16,16))
for i in range(10):
plt.subplot(1, 10, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_test[i], cmap=plt.cm.binary)
plt.xlabel(y_test[i])
plt.show()
print(np.argmax(model.predict(x_test[0:10]), axis=1))
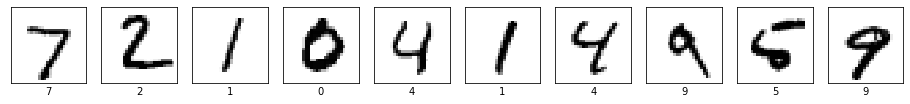
[7 2 1 0 4 1 4 9 5 9]
10個全部あってます。
混合行列で確認
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test,np.argmax(preds,axis=1))
plt.figure(figsize=(16,8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.show()

次回は DataAugumentation か 学習済みモデルの転移学習 か TensorflowHUB のどれやろうかな。