この記事はエイチーム引越し侍 / エイチームコネクトの社員による、Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2021 19日目の記事です。
はじめに
去年のアドカレで Darts というカンタン時系列データ予測のライブラリを触ってみた記事を書きましたが、
同じように AutoML 界隈で気になっていた PyCaret の記事を弊社のアドカレの11日目に @m-otsuka くんが書いてくれていたので、これに続けとばかりに、PyCaret ネタでいきます。
PyCaret の使い方については、ほぼ @m-otsuka の記事の内容と同様なので詳細な説明はそちらを参照ください。わかりやすく丁寧に書いてくれていると思います。
この記事では、PyCaret でさらっと作ったモデルと、Google の Cloud AutoML Tables で同じようにさくっと作ったものと、どっちが強いのか、使い勝手がどうかというあたりに焦点を当てたいと思います。
学習データと環境
前述の記事と同様、Kaggle の House Prices - Advanced Regression Techniques のデータセットを用いています。
実行環境は以下の通りです。
・PyCaret 2.3.5
・Google Colaboratory
・Google Cloud AutoML Tables
PyCaret モデル作成
下準備
!pip install pycaret
!pip install catboost
import numpy as np
import pandas as pd
from pycaret.regression import *
from pycaret.utils import enable_colab
enable_colab()
enable_colab() については、google colab のときは実行せよ、と PyCaret の公式に書いてあったけど、実行した場合としなかった場合での違いが分からなかった…
学習データの取り込み。KaggleのCSVファイルをColabにアップロードした上で読み込みます。
train_df = pd.read_csv('train.csv')
@m_otsuka の記事の提案どおり、SalePrice の自然対数をとったものを目的変数とした。
train_df['SalePrice'] = np.log(train_df['SalePrice'])
exp = setup(
data = train_df, # 訓練用データ
target = 'SalePrice', # 目的変数
session_id=1234, # seedとして用いられている値、再現性を保つために指定
)
setup()の際に、各カラムの型を PyCaret が推定するので、それが合ってるかを確認して、全てOKなら Enter を押せ、という指示が出るが、
今回のようにカラム数が多いと以下のように途中省略されてしまい、確認ができない…
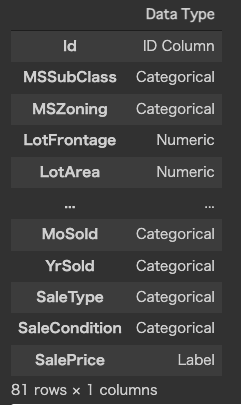
Pandas のdisplay.max_rowsの値を大きくしてみたりしたけど効果はなし…
どなたか解決策が分かる方、ご教示いただけると大変うれしいです。
各種モデルの比較
PyCaret のキモ。
setup()してcompare_models()するだけで、いろいろなモデルでの精度を比較できる。
top5 = compare_models(sort = 'RMSE', n_select=5)
| Model | MAE | MSE | RMSE | R2 | RMSLE | MAPE | TT (Sec) | |
|---|---|---|---|---|---|---|---|---|
| catboost | CatBoost Regressor | 0.0844 | 0.0159 | 0.1244 | 0.8999 | 0.0096 | 0.0070 | 9.573 |
| gbr | Gradient Boosting Regressor | 0.0935 | 0.0183 | 0.1330 | 0.8860 | 0.0103 | 0.0078 | 0.798 |
| lightgbm | Light Gradient Boosting Machine | 0.0946 | 0.0192 | 0.1372 | 0.8798 | 0.0106 | 0.0079 | 0.247 |
| br | Bayesian Ridge | 0.0898 | 0.0217 | 0.1412 | 0.8548 | 0.0108 | 0.0075 | 0.234 |
| ridge | Ridge Regression | 0.0919 | 0.0226 | 0.1452 | 0.8498 | 0.0111 | 0.0077 | 0.060 |
| rf | Random Forest Regressor | 0.0994 | 0.0217 | 0.1456 | 0.8645 | 0.0112 | 0.0083 | 2.434 |
| omp | Orthogonal Matching Pursuit | 0.0952 | 0.0292 | 0.1606 | 0.8051 | 0.0122 | 0.0080 | 0.040 |
| (以下略) | ||||||||
| この段階では、catboost が最も成績が良いようです。 |
チューニング
PyCaret ではここからハイパーパラメータの最適化をしたり、様々なアンサンブル学習を試すことがカンタンにできます。
前述の記事では、今回のケースでは、デフォルトのハイパーパラメータのチューニングtune_model()は効かず、bagging や boosting、stacking なども試した結果、
compare_models()でトップ5個のモデルの blending が最も成績が良かったようなので、それでいきます。
blend_top5 = blend_models(estimator_list = top5, optimize = 'RMSE')
予測
モデルができたらテストデータを読み込んで予測します。
# テスト用データ読み込み
test_df = pd.read_csv('test.csv')
# 予測実行
predict = predict_model(blend, data = test_df)
# 予測された価格は自然対数なので exp() で真値に戻す
predict['SalePrice'] = np.exp(predict['Label'])
# Kaggle提出用に必要なカラムのみ取り出す
submission = predict[['Id','SalePrice']]
# csv へ吐き出す
submission.to_csv('submission.csv')
ここまでで RMSE の 1位 catboost と 2位 blend_top5 で予測した結果を Kaggle に提出したスコアが以下。
| model | Kaggleスコア |
|---|---|
| catboost | 0.13633 |
| blend_top5 | 0.13334 |
学習時には catboost の方が RMSE が良かったが、提出データでは blend_top5 が勝っている。
そういうことはままあると思うので、トレーニングデータだけで精度を判断しちゃいけないなと自戒。
Cloud AutoML Table でのモデル作成
次は Google の AutoML でやってみる。
今回は表形式のデータなので Tables で。
データセット作成
まずはデータセットを作る。
Tables の「新しいデータセット」の作成で、ローカルPCからCSVのアップロードで作る。
データのインポートが完了すると、各列において、データ型と null許容の可否 が自動判定される。
カラムのデータ型は PyCaret と同様だが、Tables には Nullable かどうかもあり、ここをちゃんと見ておかないと、モデルの作り直し(トレーニングのやり直し)になるので注意。今回それによってやり直しが発生した。
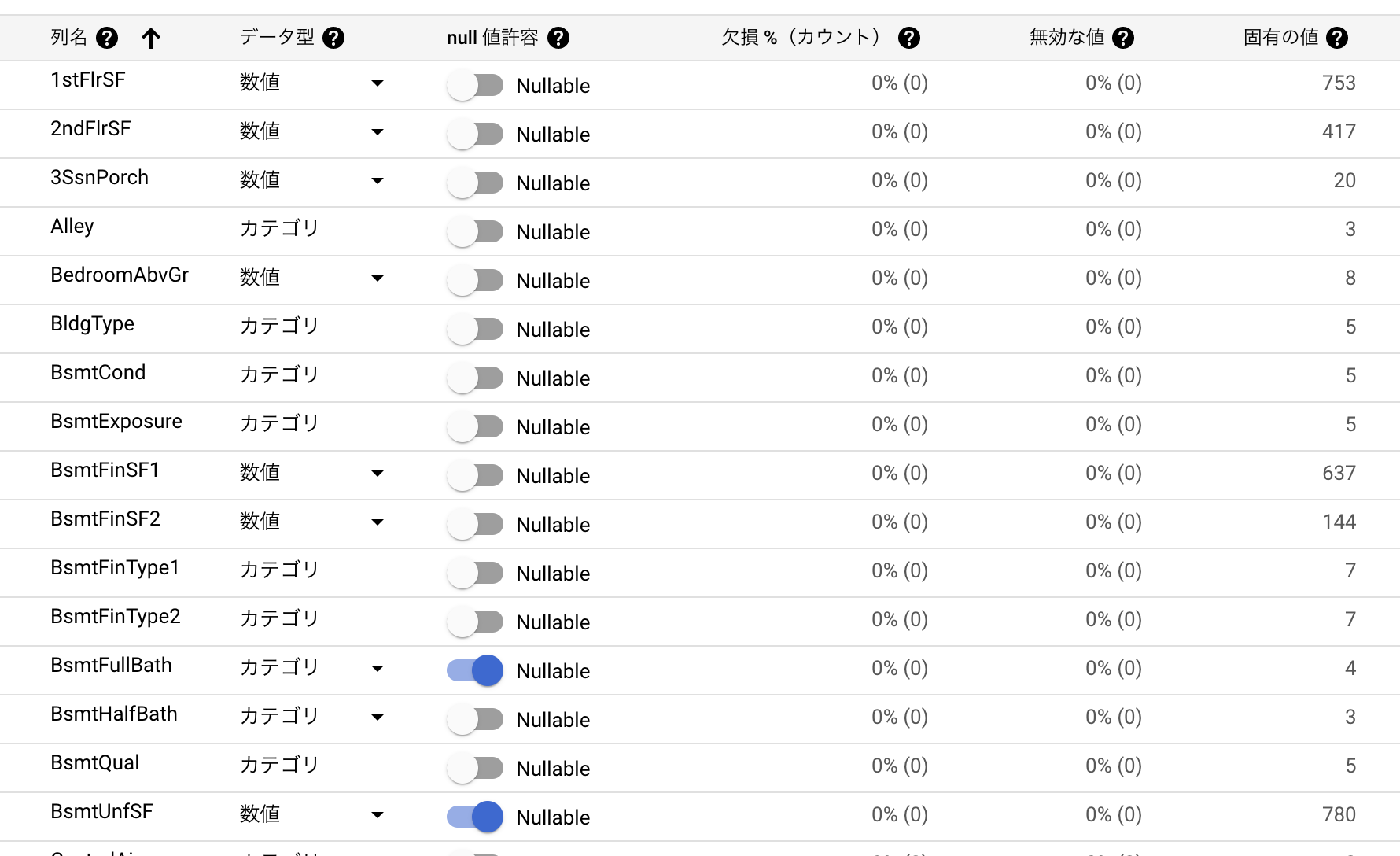
トレーニング
データ型の確認が終わったら、ターゲット列として今回は SalePrice を選択して、「モデルトレーニング」ボタンで開始。
予算は最小の 1ノード時間 で入力。
下の方の詳細オプションを開くと、最適化の目標を RMSE だけじゃなくて、MAE や RMSLE を選択できるようになっている。
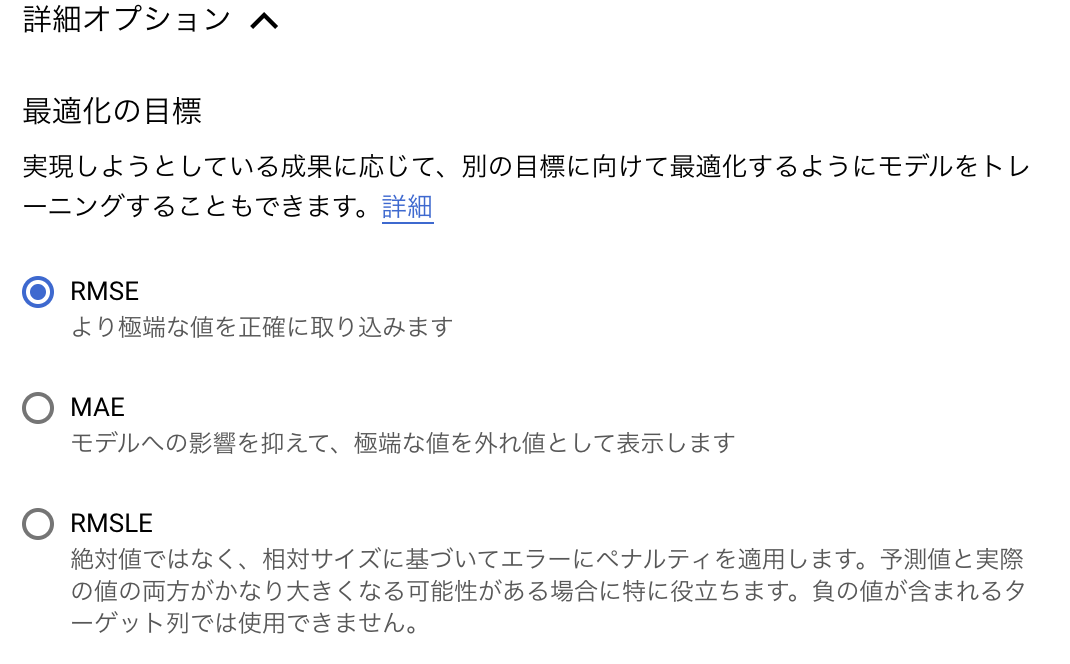
毎回、このトレーニングに 1時間強かかる。(予算をもっと入れていればその分の時間)
試行錯誤段階では、やり直すたびに1時間かかるのでちょっと萎える。
評価
トレーニングが終わると、PyCaret のcompare_models()で出ていたようなのと同様な評価項目が表示される。
あと、特徴量の重要度もグラフで表示されている。
PyCaret であれば、evaluate_model()で特徴量の重要度を含め詳細なモデルの情報が見られる。AutoML Tables が Auto であるがゆえにかゆいところに手が届かなくてもどかしいところ。そこは PyCaret は AutoML ながら頑張っているところだと思う。
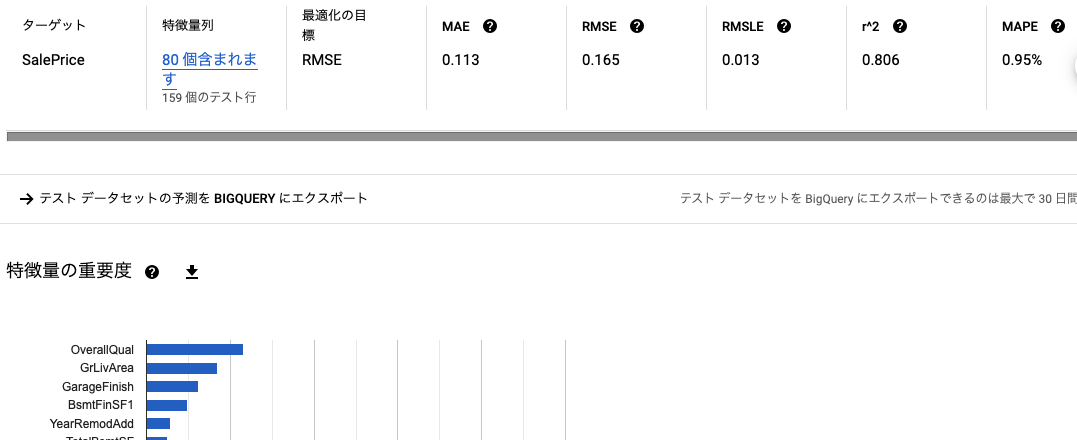
テスト
モデルができあがると、予測をすることができるようになる。
バッチ予測 と オンライン予測 があって、オンライン予測はクラウド上の実行環境にモデルをデプロイしないといけないので、今回はバッチ予測で。
バッチ予測では、入力データを、BigQuery か Cloud Storage のCSVファイルを選択できる。
今回は test.csv を Cloud Storage においてそれを読み込ませた。
結果も、BigQuery か CloudStorage にファイルとして出力できるが、今回はファイルで。
今回のケースでは、1,400件ほどのテストデータがあるが、だいたい数分くらいで結果ファイルができあがっていた。
入力データに不備がある等でエラーが発生した行は、errors.csv ファイルの方に吐かれ、結果ファイルには含まれない。
そのため、エラーがあるとそのまま Kaggle に提出しても、行数が足りない、というエラーになって受け付けてもらえない。
そのためエラーが 0 個になるまで対処しないといけないんだけど、それに結構時間がかかった。
最初のエラー行は300程度、対象のカラムは4つで、理由は、Nullable じゃないのに空文字列なのと、数値カラムに 'NA' という文字列が入っていること。
PyCaret ではどちらも問題がなくて気にしてなかったのだが、AutoML Tables の方が厳格な感じ。
Nullable に対しては再度データセットの定義を変更してトレーニングしなおし。何度もやるとつらみ。
NA文字列の問題は、Null は空文字で入れろという AutoML Tables の公式のドキュメントにしたがって、テストデータを変更した。
無事にすべての行の結果が出たら Kaggle に提出。
スコア比較
| model | Kaggleスコア |
|---|---|
| PyCaret (catboost) | 0.13633 |
| PyCaret (blend_top5) | 0.13334 |
| AutoML Tables | 0.13059 |
AutoML Tables に負けた・・・
(なんとなく自分でコードを書いた方に愛着が・・・![]() )
)
このままでは引き下がれん、ということで…
スコアをあげるためにやってみたこと
PyCaret 側
- SalePrice の自然対数を取らずに最適化を RMSLE にしてやってみた(各メソッドの引数で
optimize='RMSLE'とする) - tune_model() の n_iter の数をデフォルトの 10 よりも大きくしてハイパーパラメータのチューニングを試みた
(これについては後で詳細を)
PyCaret 側だけいじるのもフェアじゃないので、AutoML Tables 側も思いつくものを。
AutoML Tables 側
- 最適化の目標を RMSE から RMSLE にしてみた(上述した詳細オプションで選択)
- PyCaret でやってたように、SalePrice の自然対数をとってトレーニングしてみた
ハイパーパラメータ最適化(tune_model)
tune_model()をデフォルトのまま使っても RMSE の値はむしろ悪くなってしまった。
n_iterの値がデフォルトで 10 のため、これを 100 にしてみたいが、
tune_model(catboost, n_iter = 100, optimize = 'RMSE')
この処理が1時間たっても終わらず…
セッションが切れちゃうので諦める。
n_iter = 20 にしてやってみたけど、RMSE をはじめ、R2 等も全て同じ値。
それなのに実行時間は 3倍かかった。(5,6分程度が 17分強)
n_iter が 10 や 20 程度だとtune_model()した方が精度が悪い。
といって 100 にすると Colab 環境だといつ終わるか分からない。
途方にくれたけど、遅いのは catboost だからだった。
試しに、lightgbm でやってみると、n_iter = 100 で 3分、200 で 6分。
200 の方が RMSE の値があがっている。
主要どころを他のも試してみる。
gbr = create_model('gbr')
gbr_tuned = tune_model(gbr, n_iter = 100, optimize = 'RMSE')
lightgbm = create_model('lightgbm')
lightgbm_tuned = tune_model(lightgbm, n_iter = 200, optimize = 'RMSE')
こんな感じで各モデルで実行し、以下の表にまとめてみました。
| tune無 | n_iter=10 | 100 | 200 | |||||
|---|---|---|---|---|---|---|---|---|
| Model | RMSE | RMSE | 処理時間 | RMSE | 処理時間 | RMSE | 処理時間 | |
| catboost | CatBoost Regressor | 0.1244 | 0.1326 | 5分 | - | - | ||
| gbr | Gradient Boosting Regressor | 0.133 | 0.1431 | 1分 | 0.1258 | 8分 | - | |
| lightgbm | Light Gradient Boosting Machine | 0.1372 | 0.1543 | 0分 | 0.1543 | 2分 | 0.1357 | 3分 |
| br | Bayesian Ridge | 0.1412 | 0.1414 | 0分 | 0.1411 | 3分 | 0.1411 | 6分 |
| ridge | Ridge Regression | 0.1452 | 0.1408 | 0分 | 0.1407 | 1分 | 0.1407 | 2分 |
| rf | Random Forest Regressor | 0.1456 | 0.1637 | 3分 | - | - | ||
| omp | Orthogonal Matching Pursuit | 0.1606 | 0.1505 | 0分 | 0.1489 | 0分 | 0.1489 | 1分 |
太字 が tuneしない状態から改善したもの、イタリック体 が悪化したものです。
n_iter=10だと悪化するmodelが多く、n_iter=100だと改善するものが多くなりますが、lightgbm はまだ悪化したままですし、catboost、rf はこちらの環境では処理完了まで待てませんでした。n_iter=200になると、実行できたものはすべt改善されていますが、br,ridge,ompにおいては、すでに 100 で改善が頭打ちになっており、時間がかかるだけになっています。
時間が限られいていると、どのあたりが最適なのかは見極めが難しそうではあります。
最後に、それぞれのモデルで得られた最善のものを集めて blending しました。
blend_tuned = blend_models(estimator_list = [catboost,gbr_tuned,lightgbm_tuned,br_tuned,ridge_tuned,omp_tuned,rf], optimize='RMSE')
これが最強になるはず…
と期待したのですが、最初のさくっと作った AutoML Tables のスコアを越せず…
PyCaret の中では最高位にはなりましたが…時間がかかった割には、という感じです…
今までで作成したそれぞれのモデルのKaggleスコアを以下にまとめました。
何もしない AutoML Tables の勝利。
が、逆に最適化目標を変えたり、下手に前処理したりすると結構ダメな結果にも。なんでやねん、という疑問が残るし、再試行にも時間がかかるのでちょっとした試行錯誤には向かない感じがする。まあ本格的な機械学習にはそもそも時間がかかるのでそういうもんといえばそうですが。。。
| SalePrice | 最適化目標 | model | スコア | 順位 | |
|---|---|---|---|---|---|
| PyCaret | 自然対数化 | RMSE | catboost | 0.13633 | 5位 |
| ↑ | ↑ | ↑ | blend_top5 | 0.13334 | 3位 |
| ↑ | ↑ | ↑ | blend_tuned | 0.13325 | 2位 |
| ↑ | 無し | RMSLE | catboost | 0.13855 | 8位 |
| ↑ | ↑ | ↑ | blend_top5 | 0.13885 | 10位 |
| ↑ | ↑ | ↑ | blend_tuned | 0.13648 | 6位 |
| ↑ | 無し | RMSE | catboost | 0.13767 | 7位 |
| ↑ | ↑ | ↑ | blend_top5 | 0.13864 | 9位 |
| ↑ | ↑ | ↑ | blend_tuned | 0.13504 | 4位 |
| AutoML | 無し | RMSE | 0.13059 | 1位 | |
| ↑ | 無し | RMSLE | 0.15466 | 11位 | |
| ↑ | 自然対数化 | RMSE | 0.15585 | 12位 |
結論
Google Cloud AutoML Tables すごい。
こちらは何もしていないのに…
素人がちょっと頑張ったくらいじゃあ勝てない…
とはいえ、再試行のたびに1時間以上待たされるのはつらいので、
最初は手元の JupyterLab なり GoogleColab なりで、PyCaret や何かしらのライブラリでちょろっと触って入力データのあたりがついたら、
Cloud AutoML にぶちこむのが大抵においては勝ちな気がする…
ただ、そこで満足できる結果なり精度なりが得られなかった場合に、Cloud AutoML だと改善するための情報がほとんど得られないのがつらい。
Cloud AutoML で済めば一番ラクで良いので、とりあえずぶちこんでみる。
そこからチューニングしていく場合は、Python でごにょごにょするしかないが、
それのあたりをつけるのに、PyCaret はありがたい存在なんじゃないかと思いました。
あとは、Cloud AutoML 周りは時間がかかるといっても、放っておいて終わったら通知がくるので良いですが、
GoogleColab だと、何かの実行のたびに数分待たされるとか、場合によっては数十分待つことになり、放っておくとセッションが切れちゃったりして、下手したらランタイムが破棄されて全部やり直しになったりするのが地味に痛い。ColabProに課金せよ、ということですね…
明日の当アドカレは、@Ingward さんの担当です! お楽しみに〜![]()