この記事はエイチーム引越し侍 / エイチームコネクトの社員による、Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2020 21日目の記事です。
クリスマスも近づいてきてアドカレもいよいよ終盤ですね!
はじめに
最近 RNN を学んだばかりの初学者ですが、実務において時系列データの予測がしたいと常々思っていたところ、
今年(の6月にバージョン 0.1.0 が)出た Darts という Python ライブラリが非常に便利そうだったので、実際のデータを元に使ってみた、という記事です。
Darts とは
Darts の特徴は、
時系列データの分析・予測で用いる、様々なアルゴリズムを統一的なAPIで簡単に使えるようにしているところです。
現在のバージョン 0.5.0 (2020/10/28リリース) で使える予測モデルは以下です。
Exponential smoothing
ARIMA & auto-ARIMA
Facebook Prophet
Theta method
FFT (Fast Fourier Transform)
Recurrent neural networks (vanilla RNNs, GRU, and LSTM variants)
Temporal convolutional network
Transformer
N-BEATS
基本的な使い方の流れ
基本的な使い方の流れは以下の通りです。
pip install darts する。
CSV等からデータを読み込んで pandas の dataframe 型にする。
dataframe を Darts の Timeseries 型に変換。
<モデル名>()という関数を呼んでモデル作成。
fit()に timeseries を渡したら、
あとはpredict()するだけ。
違う予測モデルを使いたければ、モデル作成時の呼び出し関数名を変えるだけ。
fit()、predict()は一緒。
すごく簡単。
なお、Google Colaboratory で動かしているので別の環境だと挙動が違うかもしれません。
今回の目的
今回は、弊社のとあるサイトのユーザのとあるアクション数のデイリーの2年間分 (2018-11-01 〜 2020-11-30) のデータから直近の1ヶ月(2020年11月)の数値を予測するということをやってみます。(数値は偽装してます)
今月の着地予想、とかで使いたいやつです。
前処理
まずは darts を install
pip install darts[all]
依存パッケージのバージョン周りで ERROR や Warning が若干でるけど今のところ動作に影響はなし。
必要なものを import
import darts
from darts import TimeSeries
import pandas as pd
import matplotlib.pyplot as plt
csv からデータを読み込む。
df = pd.read_csv('action.csv', index_col='date', parse_dates=True)
この action.csv は日付(date)と件数(count)の2カラムのみです。
index_col を指定することで日付を index とする 1列のみのデータとしています。
count
date
2018-11-01 3820
2018-11-02 3863
2018-11-03 4102
2018-11-04 4312
2018-11-05 4409
... ...
761 rows x 1 columns
グラフにするとこんな感じです。(一部のみ)
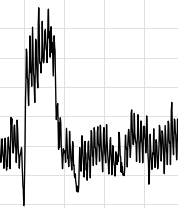
季節要因が大きそうな感じです。
Darts の TimeSeries に変換
ts = TimeSeries(df)
学習データと検証データに分けます。(2020/10/31 よりも後ろ、つまり 2020年11月分を検証に使う)
train, val = ts.split_after(pd.Timestamp('20201031'))
これで準備は完了です。
予測
それぞれのモデルで予測していきます。
ExponentialSmoothing
まずは、時系列データの分析・予測の例としていろいろなところでも(Dartsの公式でも)使われている AirPassengers.csv での予測で精度が良かった ExponentialSmoothing から。
from darts.models import ExponentialSmoothing
model = ExponentialSmoothing()
model.fit(train) # fit() に学習データ(train)を渡す
prediction = model.predict(len(val)) # predict() には何個先まで(今回であれば11月の日付分 = len(val))予測するかの数を渡す
これで終了。あっけない。
グラフで描画してみます。(グラフが見やすいように10月からのデータにします)
ts_after10 = ts.drop_before(pd.Timestamp('20201001'))
fig = plt.figure(figsize=(12, 5))
ts_after10.plot(label='actual')
prediction.plot(label='forecast', color='red')
plt.legend()
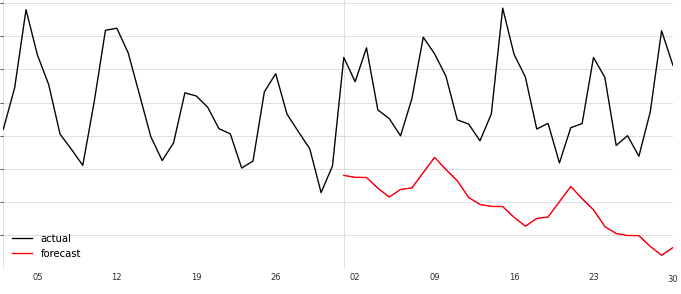
黒線が10月1日から11月末までの実績値。赤線が 11月1日からの予測値。
だいぶ低迷する予測になっちゃってます。なんでだろう…
ARIMA
気を取り直して、次、ARIMAモデルです。
from darts.models import ARIMA
model = ARIMA()
model.fit(train)
prediction = model.predict(len(val))
fig = plt.figure(figsize=(12, 5))
ts_after10.plot(label='actual')
prediction.plot(label='forecast', color='red')
plt.legend()
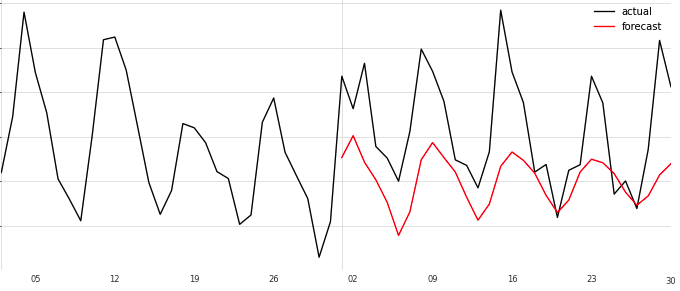
ExponentialSmoothing のときと、モデル作成時のモデル名以外は全く一緒です。
(モデル作成時に引数でいろいろ渡すこともできます)
ちょっと予測のグラフが実績のグラフの形に近づきました。
Prophet
次は、簡単おまかせで良い精度がでると評判の Facebook の Prophet です。
from darts.models import Prophet
model = Prophet()
model.fit(train)
prediction = model.predict(len(val))
# グラフ描画のコードは一緒なので省略
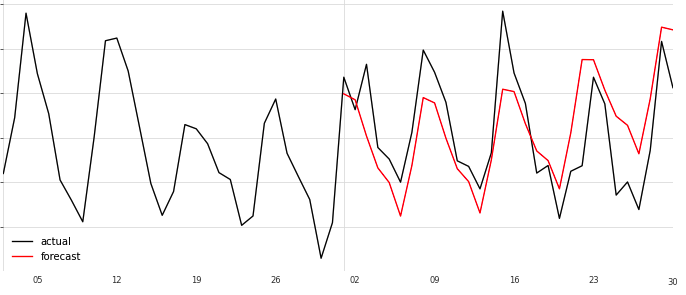
いままでと比べるとだいぶ実績値に近づいた形に見えます。
ちなみに、「yearly seasonality」が無効だから、yearly_seasonality=Trueにして実行せよ、daily_seasonality もね、という INFO メッセージが出力されたので、
model = Prophet(yearly_seasonality=True, daily_seasonality=True)
としてみたけど、結果のグラフは変わらなかった。
RNN(LSTM)
次は RNN(LSTM)。
RNN でやる場合は、なんとなく正規化しておいた方がいいんじゃないかと思い、darts を使って正規化してみます。(ここでは、正規化=値を 0〜1 の間にすること、を指しています)
from darts.dataprocessing.transformers import Scaler
scaler = Scaler()
train_tr = scaler.fit_transform(train)
val_tr = scaler.transform(val)
ts_tr = scaler.transform(ts)
ドキュメントによると Scaler は scikit-learn のラッパークラスで、デフォルトでは MinMaxScaler(feature_range=(0, 1))として動くようです。
LSTM のモデルを作ります。
from darts.models import RNNModel
model = RNNModel(
model='LSTM',
output_length=1, # 出力(=予測)のタイムステップ数
hidden_size=25, # RNNにおける隠れ状態の数
n_rnn_layers=3, # RNNの隠れ層の数
input_length=12, # Number of previous time stamps taken into account.(?分からなかった…)
dropout=0.4,
batch_size=16,
n_epochs=400,
optimizer_kwargs={'lr': 1e-3},
log_tensorboard=True,
random_state=42
)
model.fit(train_tr, val_training_series=val_tr, verbose=True)
モデルの作成時に渡しているハイパーパラメータはほぼ公式ドキュメントの例のままですが、隠れ層の数n_rnn_layersだけ増やしてます。デフォルトの 1 から増やすことで学習時間がかかりますが、精度はあがりました。それ以外のパラメータは、今回はいじっても精度があげることはできませんでした。
fit()にそれなりに時間がかかるので、verboseを True にしておくことで途中経過が見えて安心です。
学習が終わったら予測してグラフを描画してみます。
prediction = model.predict(len(val))
fig = plt.figure(figsize=(12, 5))
ts_tr_after10 = ts_tr.drop_before(pd.Timestamp('20201001'))
ts_tr_after10.plot(label='actual')
prediction.plot(label='forecast', color='red')
plt.legend()
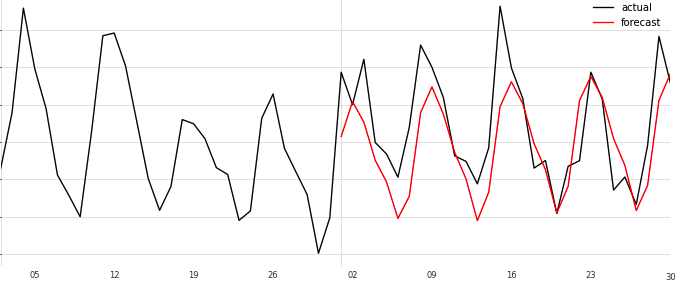
Prophet といい勝負をしていそうです。
差分データにする
ここまでやってきて、ふと、そういえば時系列データの分析をする際には定常性のあるデータに変換すべしということを思い出しました。
ので、前日との差分の時系列データにしてみます。
差分にするのは簡単。
df_diff = df.diff(1).dropna()
dataframe に対して diff() で引数で指定した数字の分だけズラした時刻との差分の配列にしてくれる。便利。
(dropna()は NaN になっている行を削除してくれる)
count
date
2018-11-02 43.0
2018-11-03 239.0
2018-11-04 210.0
2018-11-05 97.0
2018-11-06 -95.0
... ...
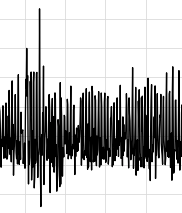
最初の方に示したグラフと同期間です。前と比べると定常っぽい、かな…
これでいってみます。
timeseries にして、学習データと検証データに分割。
ts_diff = TimeSeries(df_diff)
train_df, val_df = ts_diff.split_after(pd.Timestamp('20201031'))
このtrain_dfに対して同様に各モデルで予測してみる。
やりかたはさっきと全く一緒。
model = <model名>()
model.fit(train_df)
prediction = model.predict(len(val_df))
ExponentialSmoothing
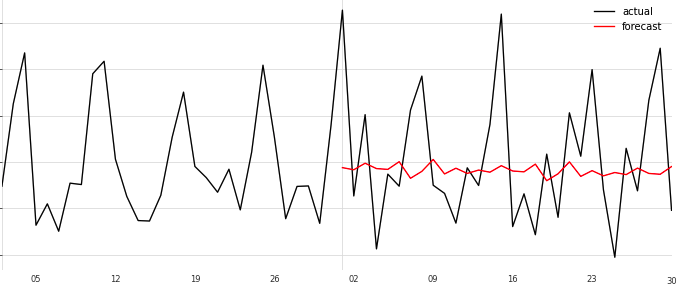
低迷はしなくなったけど、全然変化がない…なんか相性が悪いのか…
ConvergenceWarning: Optimization failed to converge. Check mle_retvals.
というメッセージが出ていたので、このデータセットで ExponentialSmoothing だとなんらか最適化が収束しない問題がある模様…
チェックしろというmle_retvalsというのはmodel.model.mle_retvalsで中身が見れたけど、よく分からない。
ABNORMAL_TERMINATION_IN_LNSRCHとあったのでとりあえず異常終了したっぽい。
ARIMA
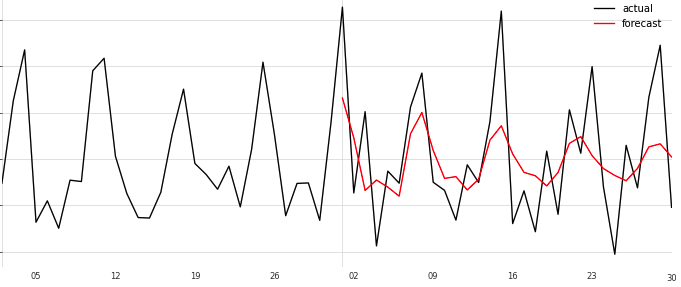
元のよりフィット感があがった気がするけどまだまだ全然捉えられてない感。
Prophet
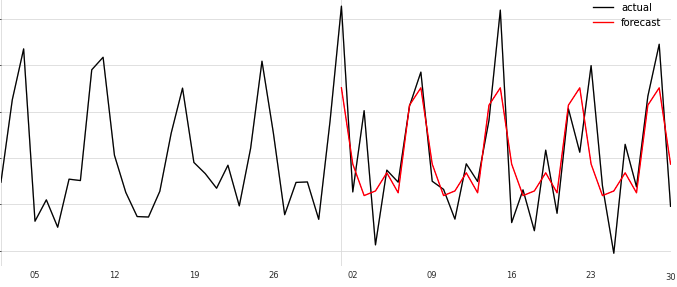
さすが。だいぶフィットしてきた。
LSTM
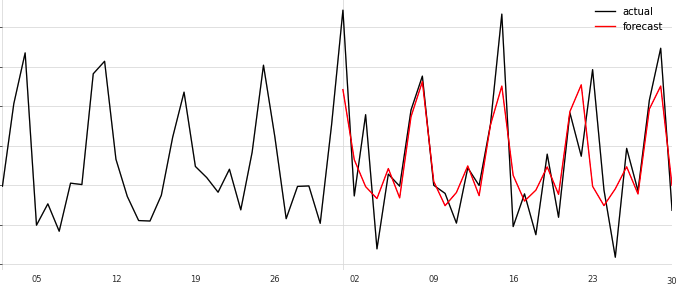
LSTM も負けてない。Prophet とほぼ同じグラフに見える。
どのモデルも差分データにしたことで、実績値のグラフに対してマッチ度はあがった気がする。
最初の目的にもどる
今回は、翌日の値を予測するのではなく、月の着地見込みが予測したいので、11月の合計値がどうなっているのかを見てみます。
差分による予測は日々の件数に直すために前日の実数に当日の差分を足していかないといけない。今回は Excel でグラフを書きたかったのでついでに Excel で実数に変換しちゃいました。
また、LSTM ではさらに、正規化してあったのを元の値に戻してあげないといけません。
戻すにはScalerを使います。
prediction_back = scaler.inverse_transform(prediction)
これでprediction_backが元のスケールの値になります。
今回、精度がそこそこ出てそうな Prophet と LSTM の元データと差分データのそれぞれの予測値の日々の累積を実績値と比較するためにグラフを描いてみると…
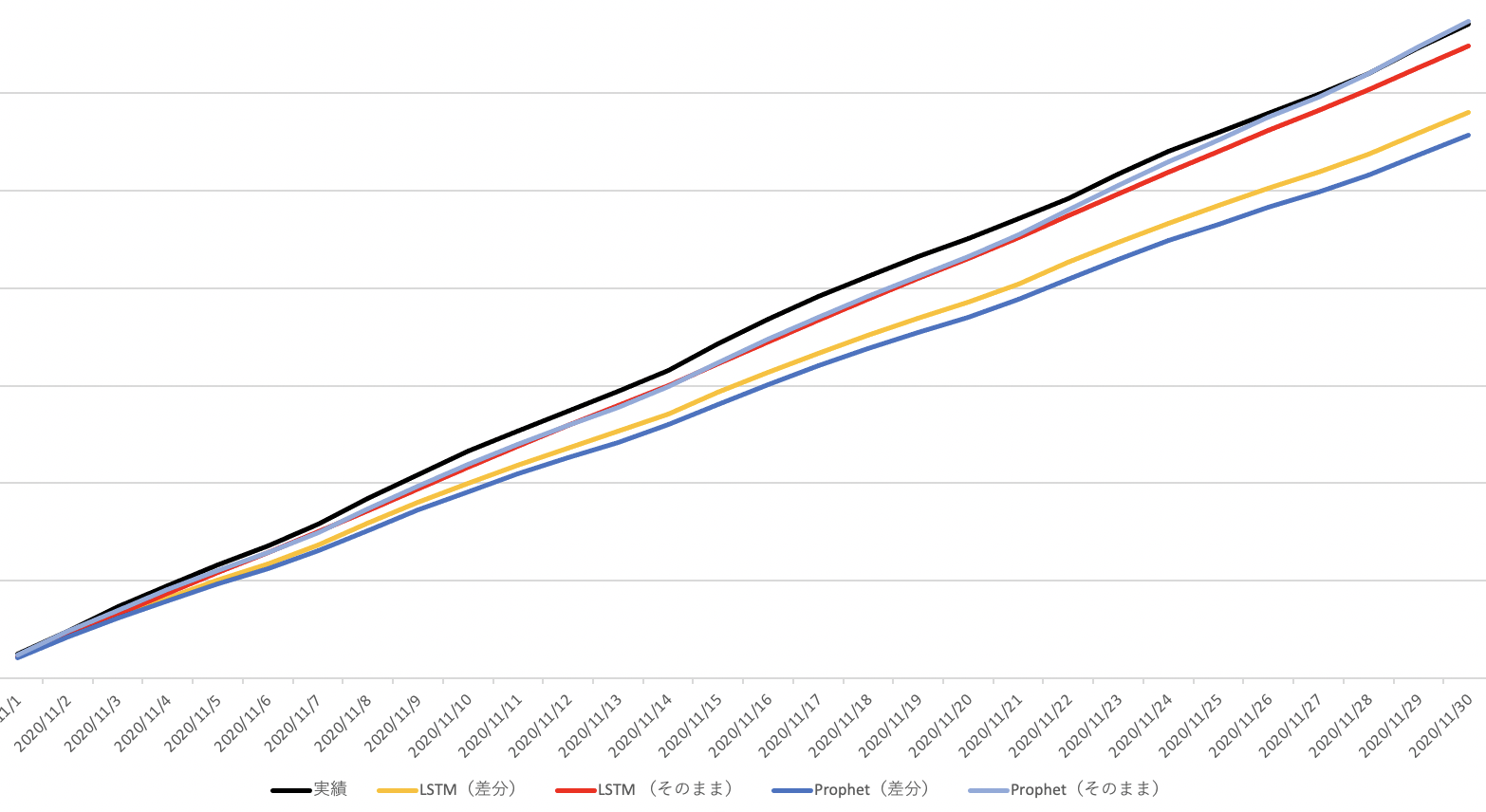
ちょっと見にくいですが、一番上の黒線が実績値。
すぐ下の水色が Prophet(元データそのままの予測)、
次の赤色が LSTM(元データそのまま予測)、
黄色が LSTM(差分データ予測)、
一番下の青色が Prophet(差分データ予測)となりました。
単純にグラフのマッチ度からいけば、差分による予測の方が精度が良いのかと思っていたので以外な結果です。
日々の変動は差分で定常化した方が精度が高いけど、月の着地をデイリーでみていくような大きな流れでは、元々のデータのままやったほうが表現できる、ということなのでしょうか…
まとめ
今回は Darts を使って、簡単な時系列データの予測を行ってみました。
どの予測モデルが優れているかとかではなく、どれが早くフィットしそうかが分かると、それをベースに詰めていくことができるので、簡単に各モデルを比較できるのはありがたいなと思いました。
ただ、LSTM で頑張ってもいいけど学習に時間かかるし、とりあえず Prophet でお手軽にやって精度が出たらラッキー!が結構当てはまってしまうのでは…という気も…
Darts は、最新バージョンでは自然言語処理界隈で話題の Transformer が使えるようになっていたりと、まだまだ進化していきそうなので今後活用していきたいと思います。
明日は @nao_70 アニキの記事です。お楽しみに!