はじめに
私が所属する部署では、開発業務の中でOpenSearchのような全文検索エンジンを触れる機会がありますが、私自身「そもそもOpenSearchって何ができるのか?」といったような漠然としたイメージを持っていました。この機会に改めて知識を整理し、その全体像を掴むことを目的として記事を書いてみました。
- そもそもどういう概念なのか? (What?)
- どのような特徴や利点があるのか? (Why?)
- 業務でどう活用されているのか? (Use Case)
- どうやって手元で動かすのか? (How?)
という観点を元に記載しています。
対象読者
- OpenSearchやElasticsearchといった用語を聞いたことがあるが、よく分からない方
- アプリケーションに検索機能やログ分析基盤を導入したいと考えているエンジニア初学者
OpenSearchとは何か?
OpenSearchを一言で表すなら、高性能な検索・分析エンジンです。
(詳細は公式サイトを参照ください)
理解しやすくするため、これを「大規模な図書館のシステム」に例えてみます。
例えば、蔵書数が数百万冊に及ぶ図書館で目的の本を探す際、優秀な司書や検索システムがあれば、キーワードを伝えるだけで即座に本の場所を特定できます。
OpenSearchは、まさにこの役割をデジタルの世界で担います。ウェブサイトの記事、アプリケーションの利用ログ、ECサイトの商品データといった、多種多様で大量のデータの中から、必要な情報を瞬時に検索します。
さらに、OpenSearchの役割は検索に留まらず、蓄積されたデータを集計・分析し、「今週最もアクセスの多かったページ」といったインサイトをグラフなどで視覚的に提示する、高性能な分析基盤でもあるのです。
① 主要な機能例:「全文検索」
一般的なリレーショナルデータベースでは、テーブルのカラムに完全一致する値を指定して検索することが基本です。
しかし、OpenSearchは「全文検索」という強力な検索手法を採用しています。これは、データ(ドキュメント)の中身全体を単語単位で解析し、「転置インデックス(Inverted Index)」を作成する仕組みです。転置インデックスとは、書籍の巻末にある索引のように、「どの単語がどのドキュメントに出現するか」を記録したものです。
この転置インデックスを持つことにより、「"A"と"B"というキーワードを含むドキュメント」といった曖昧な条件でも、データ全体から関連性の高い情報を高速に検索できます。
② Elasticsearchとの関係性
「OpenSearchはElasticsearchと何が違うの??」と感じる方もいるかもしれません。(自分もまさにそう思っていました。笑)それもそのはず、OpenSearchはもともとElasticsearchから派生したプロジェクトです。
背景として、Elasticsearchがライセンスポリシーを変更したことをきっかけに、AWSが中心となり、完全なオープンソースソフトウェアとして誰でも自由に利用・改変できることを目指し、Elasticsearchのコードベースからフォーク(分岐)してOpenSearchプロジェクトが発足しました。
参考記事 ↓
そのため、両者はコアとなるアーキテクチャやAPIにおいて多くの共通点を持ちますが、現在はそれぞれが独自のコミュニティで開発を進め、異なる進化を遂げています。
OpenSearchの主な特徴
OpenSearchが多くのシステムで採用される理由となっている、主要な特徴をさらに詳しく見ていきましょう。
特徴1. 高速な全文検索
前述の通り、転置インデックスを活用することで、大規模なデータセットに対しても極めて高速な検索性能を発揮します。
特徴2. 柔軟なデータ構造
構造化されたデータ(例:数値、日付)だけでなく、ブログ記事のような非構造化テキストデータ、JSONドキュメント、地理空間データなど、スキーマレスで多様な形式のデータをそのまま受け入れてインデックス化できます。この柔軟性は、変化の速い現代のデータ要件に対応する上で大きな利点となります。
特徴3. オープンソース(Apache 2.0 License)
OpenSearchはApache 2.0 Licenseのもとで提供されており、誰でも無料で利用、改修、再配布が可能です。活発なコミュニティによって支えられ、継続的な機能改善やセキュリティアップデートが行われています。
特徴4. 高いスケーラビリティ
OpenSearchは、分散システムとして設計されています。データ量やリクエストが増加した際に、サーバー(ノード)を追加するだけでシステム全体の性能をリニアに向上させることが可能です。これにより、小規模な構成から始めて、事業の成長に合わせて大規模システムにまで拡張できます。
特徴5. 強力な可視化機能
OpenSearchにはOpenSearch Dashboardsという、強力な可視化・分析ツールがバンドルされています。このツールを使うことで、OpenSearchに蓄積されたデータをクエリし、その結果をリアルタイムに更新されるダッシュボード(グラフ、表、地図など)として作成できます。(具体的な画面は後述のローカル環境構築時に記載します)
単なる数値の羅列を視覚的に表現することで、データに隠された傾向や異常値を直感的に把握し、迅速な意思決定を支援します。
OpenSearchの具体的な活用事例
これらの特徴を持つOpenSearchは、実際にどのような領域で活用されているのでしょうか。
-
ECサイトにおける商品検索
ユーザーが入力したキーワードに対し、関連性の高い商品を高速に表示します。同義語展開(例:「PC」で「パソコン」も検索)など、高度な検索体験を提供するために利用されます。 -
地理空間データの分析
位置情報(緯度経度)を含むデータを活用し、特定のエリア内にある店舗の検索や、顧客の地理的分布の可視化、物流ルートの最適化といった分析を行います。
【実践1】ローカル環境でOpenSearchを起動してみる
概要を掴んだ上で、Dockerを使用してローカル環境でOpenSearchを実際に起動してみましょう。
準備するもの
-
Docker Desktop
- ご自身のPC(Windows/Mac)にインストールされていない場合は、公式サイトからダウンロードしてインストールしてください。
手順
-
任意の場所に作業用フォルダを作成します(例:
opensearch-project)。 -
作成したフォルダ内に
docker-compose.ymlのファイルを作成し、以下の内容をコピペして保存します。(下記はあくまで一例です)docker-compose.ymlversion: '3' services: opensearch-node1: image: opensearchproject/opensearch:latest container_name: opensearch-node1 environment: - cluster.name=opensearch-cluster - node.name=opensearch-node1 - discovery.seed_hosts=opensearch-node1 - cluster.initial_cluster_manager_nodes=opensearch-node1 - bootstrap.memory_lock=true - "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m" - "DISABLE_INSTALL_DEMO_CONFIG=true" # Prevents execution of bundled demo script which installs demo certificates and security configurations to OpenSearch - "DISABLE_SECURITY_PLUGIN=true" # Disables Security plugin ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 volumes: - opensearch-data1:/usr/share/opensearch/data ports: - 9200:9200 - 9600:9600 networks: - opensearch-net opensearch-dashboards: image: opensearchproject/opensearch-dashboards:latest container_name: opensearch-dashboards ports: - 5601:5601 expose: - "5601" environment: - 'OPENSEARCH_HOSTS=["http://opensearch-node1:9200"]' - "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true" # disables security dashboards plugin in OpenSearch Dashboards depends_on: - opensearch-node1 networks: - opensearch-net volumes: opensearch-data1: networks: opensearch-net: -
以下のコマンドを実行し、コンテナを起動します
docker-compose up -d -
無事に起動が完了したら、ymlで指定している通りにWebブラウザで
http://localhost:5601にアクセスします(起動には数分かかる場合があります) -
OpenSearch Dashboardsのログイン画面が表示されます🎉
セキュリティプラグインが無効化されているため、認証なしでアクセス可能です。手元のlocal環境で学習用として使用してください
サンプルデータによる動作確認
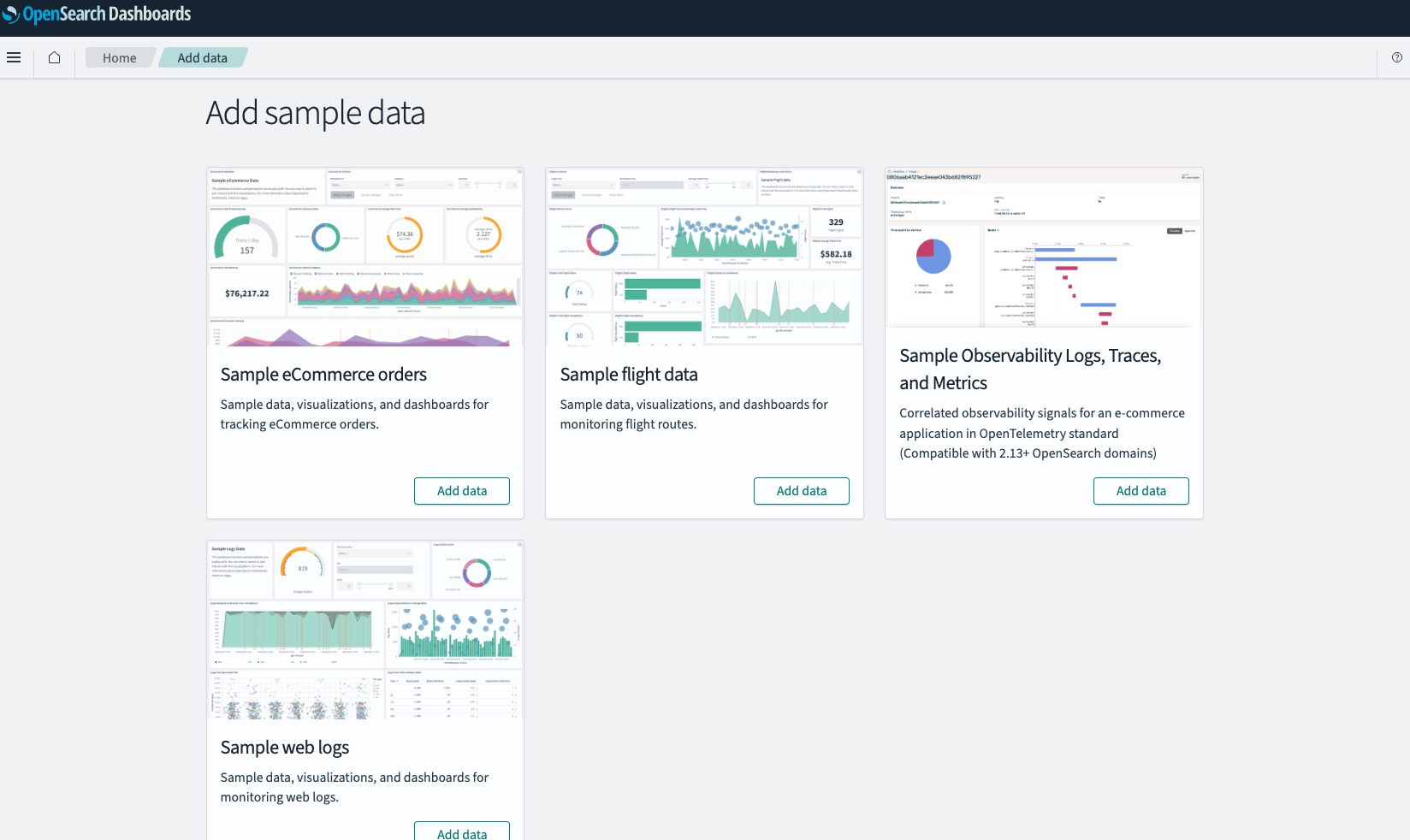
ログイン後、OpenSearch Dashboardsの機能を体験するために、サンプルデータをインポートしてみましょう。
-
ホーム画面にある "Sample flight data" や "Sample eCommerce data" など、任意のデータセットの "Add data" ボタンをクリックします。
-
データがインポートされた後、左側のナビゲーションメニューから "Dashboard" を選択し、対応するダッシュボード(例:
[Flights] Global Flight Dashboard)を開きます。
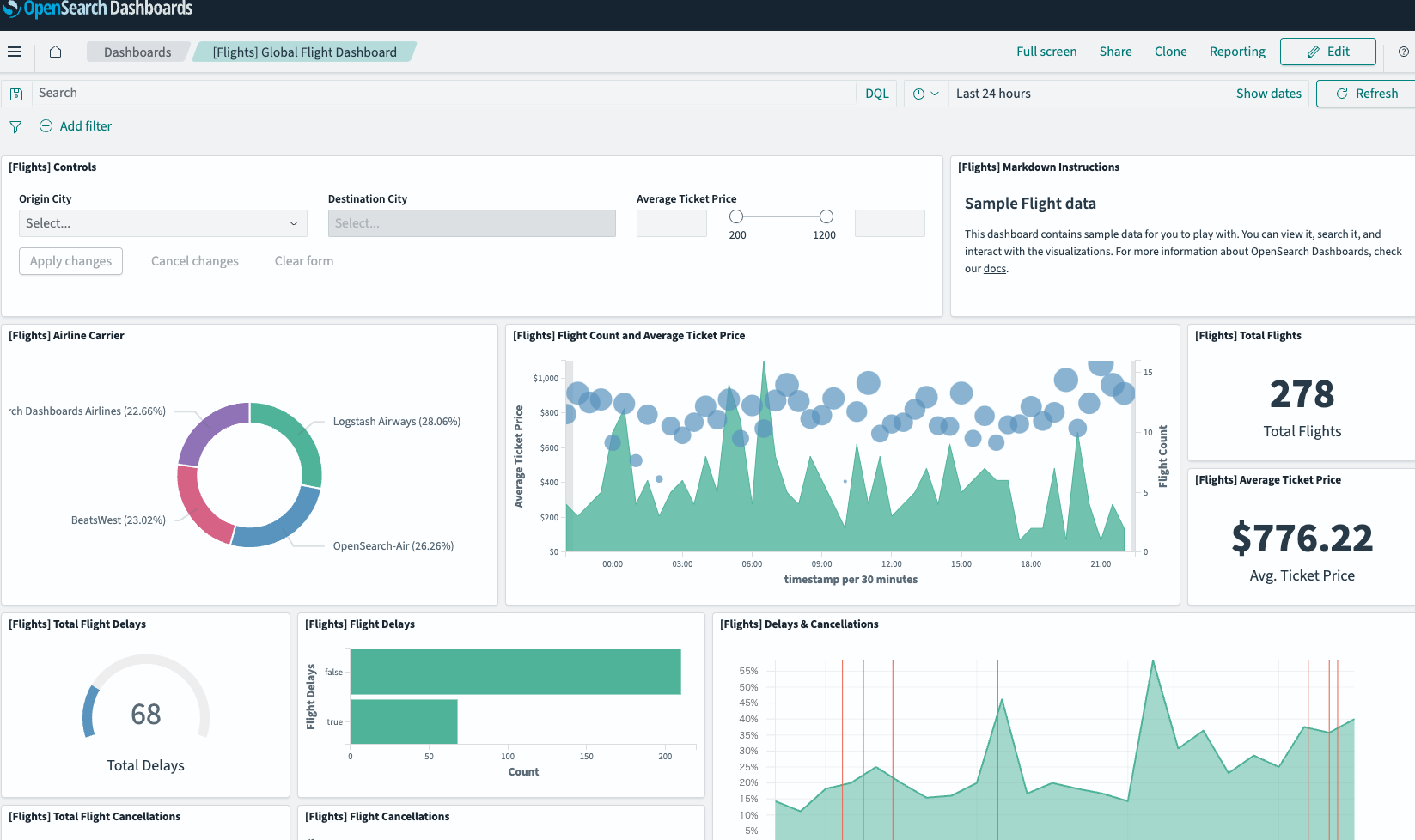
インタラクティブなグラフや地図で構成されたダッシュボードが表示され、OpenSearchとDashboardsの強力な可視化機能を体感できるはずです。
【実践2】Dev Toolsでデータを登録・検索してみる
OpenSearch Dashboardsには、APIリクエストを直接送信できる「Dev Tools」という便利な機能があります。これを使って、データの登録(Indexing)から検索(Search)までの一連の流れを体験してみます。
1:左側のナビゲーションメニューから Management > Dev Tools を選択します
2:まずはOpenSearchクラスタが正常に動作しているか確認するため下記コマンドを実行
GET /
右側にクラスタ名やバージョン情報が表示されればOKです。
3: インデックスの作成
my-first-index という名前のデータの入れ物(インデックス)を作成します。
PUT /my-first-index
4: ドキュメントの登録
作成したインデックスに、ID 1 として最初のデータを登録します
PUT /my-first-index/_doc/1
{
"user": {
"name": "Taro Yamada",
"email": "taro@example.com"
},
"post_date": "2025-07-14T10:00:00Z",
"message": "はじめてのOpenSearch!これはとても便利です。"
}
5: データの検索
先ほど登録したデータを検索してみます
GET /my-first-index/_search
"hits" の中に、先ほど登録したドキュメントが含まれていることが確認できます。

このように、APIを通じてJSON形式のデータを柔軟に登録し、即座に検索可能となるのがOpenSearchの強力な点です。
まとめ
本記事では、検索・分析エンジンであるOpenSearchの基本的な概念から、そのアーキテクチャ上の特徴、そしてローカルでの起動方法までを触れて紹介しました。
今回の記事を書く中で、OpenSearchは単なる検索ツールではなく、膨大なデータから価値ある洞察を引き出すための強力なプラットフォームであることを改めて認識できました。
今回ご紹介した内容はOpenSearchの機能のほんの入り口に過ぎません。引き続き私も、個人開発などでローカル起動したOpenSearchを触りながら、さらに理解を深めていきたいと思います。
最後までお読みいただきありがとうございました!