背景
とあるTwitterのBot作成で、どーしても、電車の運行情報が必要となった。
どこからか、無料で特定の路線のみの運行情報を引っ張って来れないかな〜と色々考えた結果、
yahoo路線からスクレイピングするのが最適解だと分かった。
運行状況を配信しているapiやらサイトやら
色々調べて、現在、路線の運行情報を配信しているのは
- [鉄道遅延情報のjson] (https://rti-giken.jp/fhc/api/train_tetsudo/) (json形式で、遅延などが生じている路線を集計して、返してくれる)
- 駅すぱあとのapi (優秀そう!でも有料有料)
- [yahoo路線の運行状況] (https://transit.yahoo.co.jp/traininfo/top) (一番馴染みのあるやつ、でもapiない!!!)
結局の話、無料でやるならば、[鉄道遅延情報のjson] (https://rti-giken.jp/fhc/api/train_tetsudo/)か[yahoo路線の運行状況] (https://transit.yahoo.co.jp/traininfo/top)になってくる。
前者の場合、全国の遅延している路線情報が返ってくる。あとは情報の更新が10分ごと...朝の通勤ラッシュでは10分でさえも命とり。
後者のyahoo路線、実は中身が駅すぱあとだったりする....笑(意外と知られていない)
路線ごとに運行情報もあるし、正確かつリアルタイムで早い!じゃあ
apiがないんだったらスクレイピングしてしまえ!
yahoo路線の運行情報をスクレイピング
スクレイピングの「す」もやったことのない筆者がスクレイピングをやってみる。
どうやら**「BeautifulSoup」**ってのを使うらしい...
すばっらしいスープを見せてもらおうじゃないかっ!
BeautifulSoupってなーに??
BeautifulSoupはHTMLやXMLファイルからデータを取得するPythonのライブラリ。
どうやら、取ってきたHTMLから、パーサーってものを使ってHTMLの要素を検索できたりする。
細かいことは分からないから、早速やってみよう!
レッツ!スクレイピング!
今回スクレイピングしたいサイトはこちら!
[yahoo路線 東海道線の運行状況] (https://transit.yahoo.co.jp/traininfo/detail/27/0/)
まずは、ページのhtmlを覗いてみよう
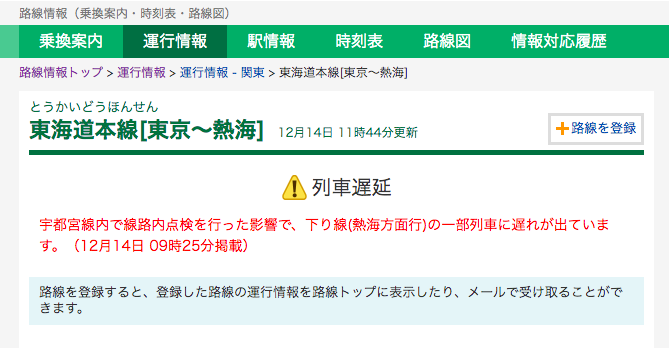
遅延時のHTMLを見てみると、ddタグのtroubleクラスがある
<div id="mdServiceStatus">
<dl>
<dt>
<span class="icnAlertLarge">[!]</span>列車遅延</dt>
<dd class="trouble">
<p>宇都宮線内で線路内点検を行った影響で、下り線(熱海方面行)の一部列車に遅れが出ています。 <span>(12月14日 09時25分掲載)</span></p>
</dd>
</dl>
</div><!--/#mdServiceStatus-->
一方で、通常時のHTMLを覗いてみるとddタグのnormalクラスがある
<div class="elmServiceStatus">
<dl>
<dt><span class="icnNormalLarge">[○]</span>平常運転</dt>
<dd class="normal">
<p>現在、事故・遅延に関する情報はありません。</p>
</dd>
</dl>
</div>
つまり
遅延時: troubleクラスのddタグ
通常時: normalクラスのddタグ
このddタグを元に、遅延か、通常運転かを判別ができそう!
さっそくやってみよう!
インストール
まずはpipでBeautifulSoupを入れる
$ pip install beautifulsoup4
コード
import requests
from bs4 import BeautifulSoup
# 東海道線の運行状況のURL
ToukaidouLine_URL = 'https://transit.yahoo.co.jp/traininfo/detail/27/0/'
# Requestsを利用してWebページを取得する
ToukaidouLine_Requests = requests.get(ToukaidouLine_URL)
# BeautifulSoupを利用してWebページを解析する
ToukaidouLine_Soup = BeautifulSoup(ToukaidouLine_Requests.text, 'html.parser')
# .findでtroubleクラスのddタグを探す
if ToukaidouLine_Soup.find('dd',class_='trouble'):
message = '東海道線は遅延しています'
else:
message = '東海道線は通常運転です'
print(message)
実行結果
東海道線は遅延しています
感想
めっちゃ簡単じゃない??webページから情報を持ってこれるのは夢広がる!
後日談:yahooの人に見せたら、「グレーゾーンだね」と言われたのは内緒