概要
Salesforce(セールスフォース)はいまや世界中で利用されているCRM(顧客関係管理)ツールであり、売上データを分析する際に、Salseforceのデータと他のデータを紐付けての分析は非常に重要になってきます。
Salesforceには登録された顧客のデータを分析するためにそれらの可視化、エクスポートを行うレポート機能がある程度標準の機能として備わっています。ですが何千、何万という単位のデータをリアルタイムで分析したい場合や、Salesforce以外のサービスで集積しているデータと絡めた高度な分析を行いたいといった場合には別途DWH(データウェアハウス)へデータを統合、Looker・TableauといったBIツールでデータの可視化・分析を行うという流れが有効ではないでしょうか。そしてこのようなデータ統合に役立つのがETLツールと呼ばれるサービスです。
今回はtrocco®(トロッコ)という分析基盤向けデータ統合サービスを使い、SalesforceのデータをGoogle BigQueryへ統合し、同じくGoogleが提供するGoogleデータポータルというBIツールを用いてデータの可視化を行います。
なお今回データの転送手段として使用するtrocco®は、Salesforceの他にも、様々な広告・CRM・DBなどのデータソースに対応しています。
trocco®の使い方まとめ(CRM・広告・データベース他)

ゴール
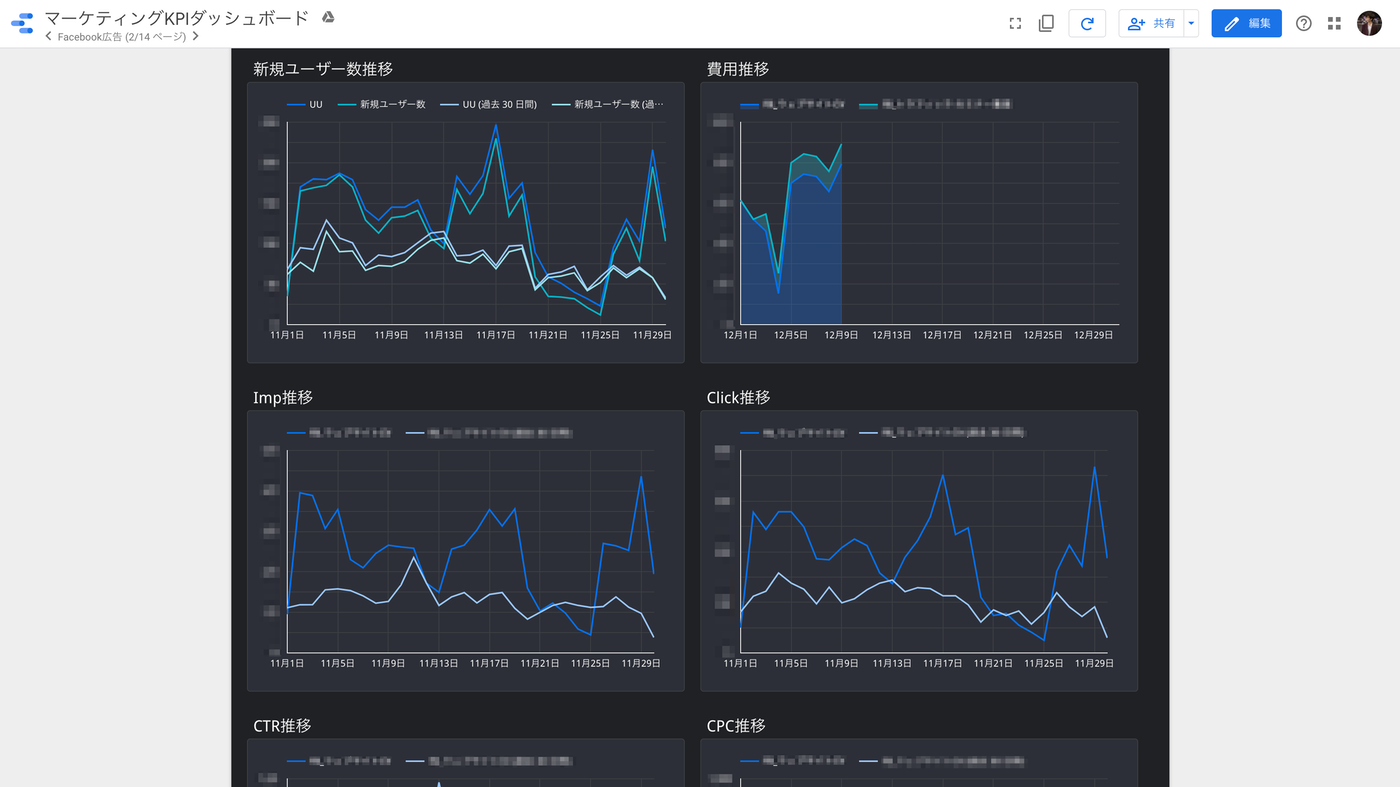
今回はサンプルとしてSalesforceに登録された顧客データをGoogle BigQueryへ転送し、このようなグラフに可視化することを目標にします。
また、今回はデータベースに関する専門的な知識がない方でもデータ分析が行えるようほぼコーディングせずに分析基盤を構築し、またデータおよびグラフの更新も自動化します。
こんな人におすすめ
- Salesforceのデータ分析機能では不満
- CRM上の営業データと、広告や売上などを紐付けて分析したい方
- Salesforceのデータを分析基盤・DWHに取り込みたい方
0. DWHと、同期する手段の選定
0-1. DWHの選定
まずはデータをどこに集約するか、DWH(データウェアハウス)を選定します。
Google BigQuery
Amazon Redshift
MySQLやPostgreSQL
今回はBigQueryを利用することにします。
0-2. SalesforceのデータをBigQueryに転送する3つの方法
BigQueryにデータを集約することが決まったので、次は転送するための手段を検討していきます。
1.SalesforceデータをCSV形式でエクスポートし、手動でBigQueryにアップロードする
2.SalesforceとBigQueryの各APIを、プログラムを書いて連携する
3.Embulkを利用し、自分で環境を構築する
4.troccoを利用し、画面上で設定する
1は単発の実行であればよいのですが、定期的な取り込み用途だと毎回同じ作業を繰り返すことになり、非効率な作業になりがちです
2はAPIのキャッチアップ工数+プログラムを書く工数+環境構築工数が発生する他、エラー対応などの運用工数も継続的に発生します
3も2と同じくEmbulkはある程度の専門知識が必要になり、自前で環境構築・運用を行う手間が発生します。加えてエラーの内容が少し専門的なので、困っている人もいたりします。
そこで今回はEmbulkの課題も解決してくれて、プログラムを書かずに画面上の設定で作業が完結する、4のtrocco®️というSaaSを利用します。
1. trocco®での設定
1-0. 事前準備
まず事前準備として今回のデータ転送に使用するtrocco®のアカウントが必要になります。
trocco®にはフリープランがあります。クレジットカードなどの登録は不要で、即日アカウント発行されるので、申し込みをしておきましょう。
https://trocco.io/lp/inquiry_free.html
またデータ元となるSalesforceのアカウントや、データの転送先となるGoogle BigQueryとGoogleデータポータルを利用するGoogleアカウントなども前もってご用意ください。
1-1. 転送元・転送先の決定
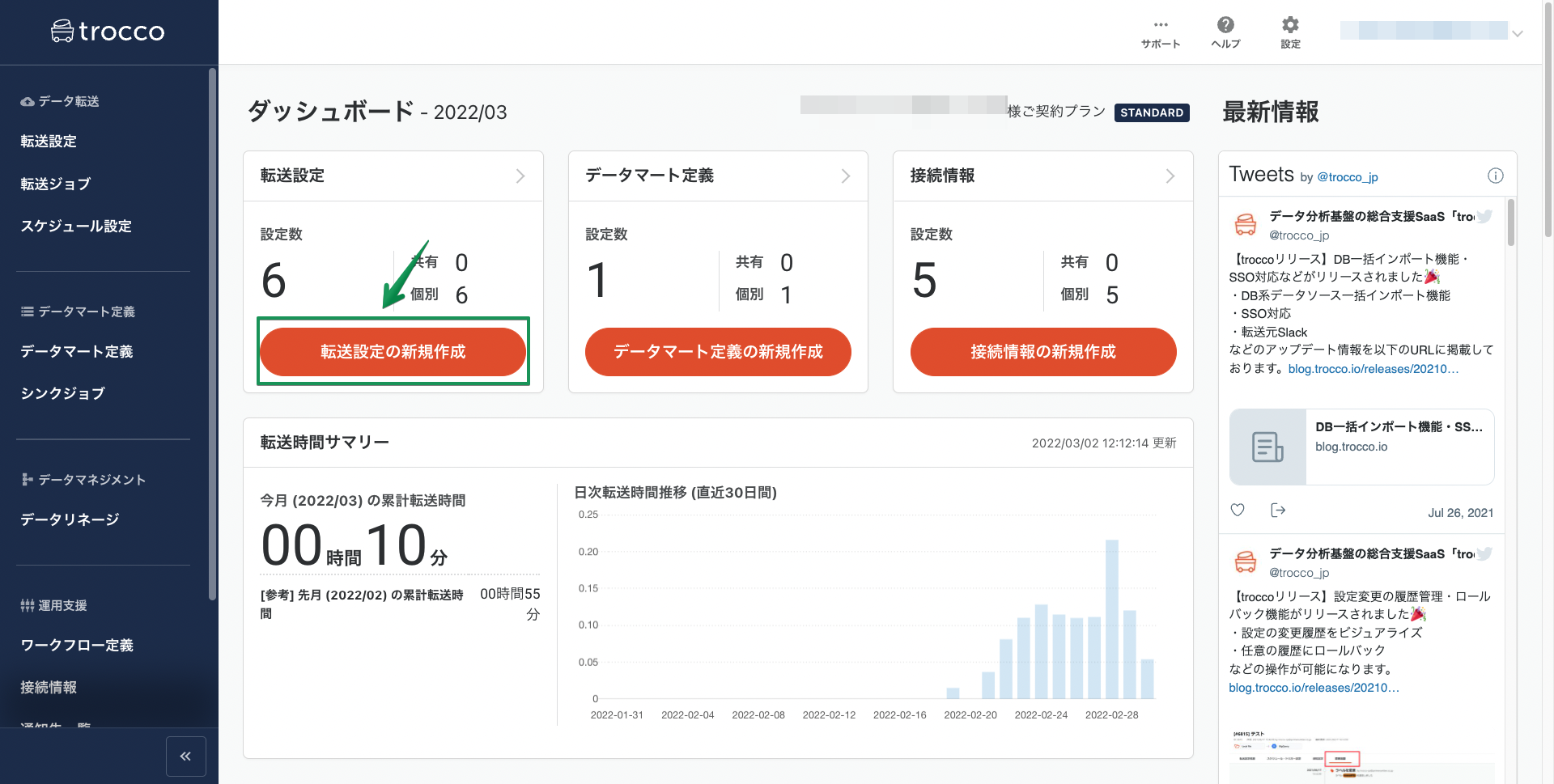
trocco®にアクセスして、ダッシュボードから「転送設定を作成」ボタンを押します。
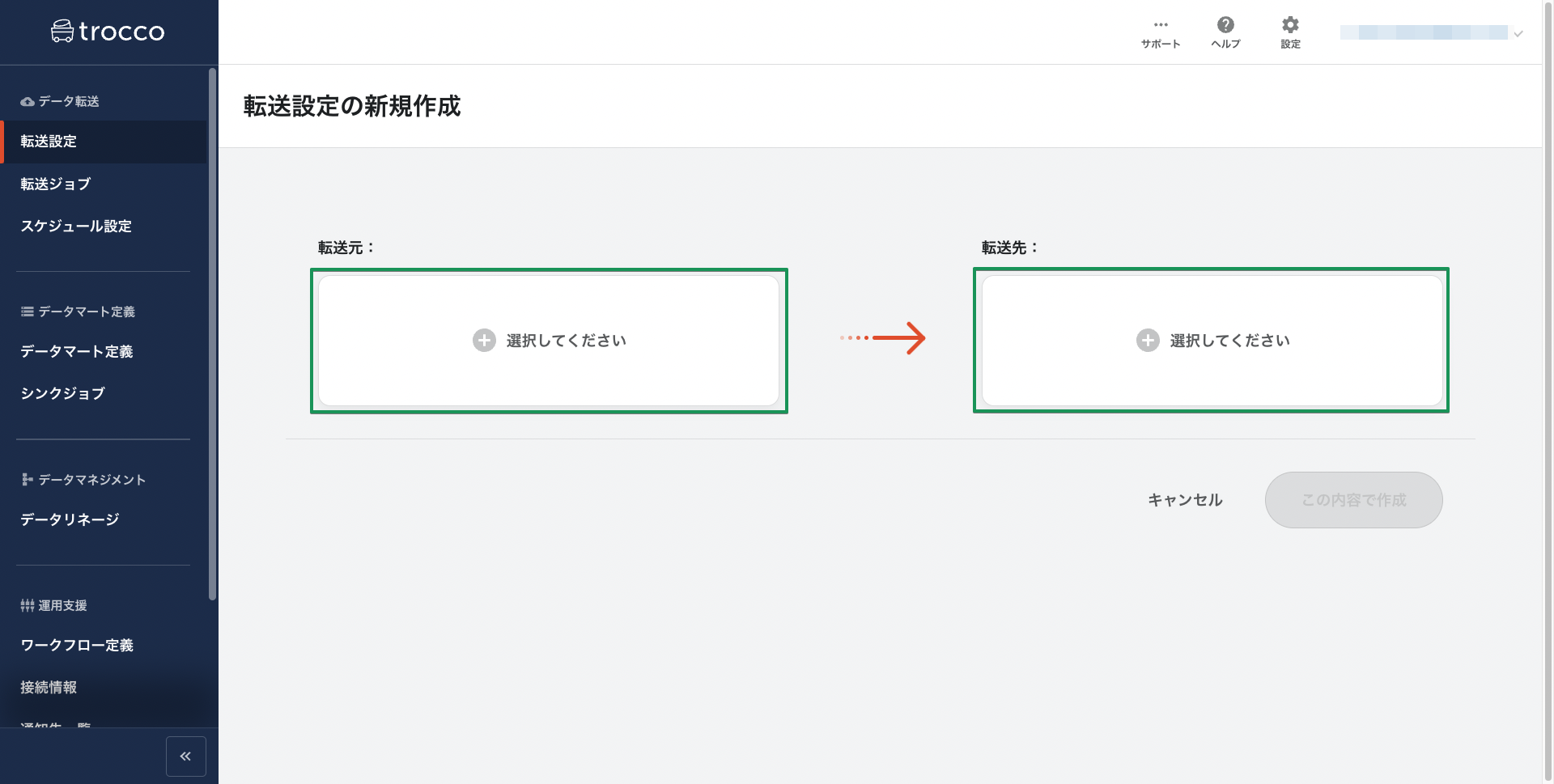
転送元と転送先となるツールを選択する画面になります。
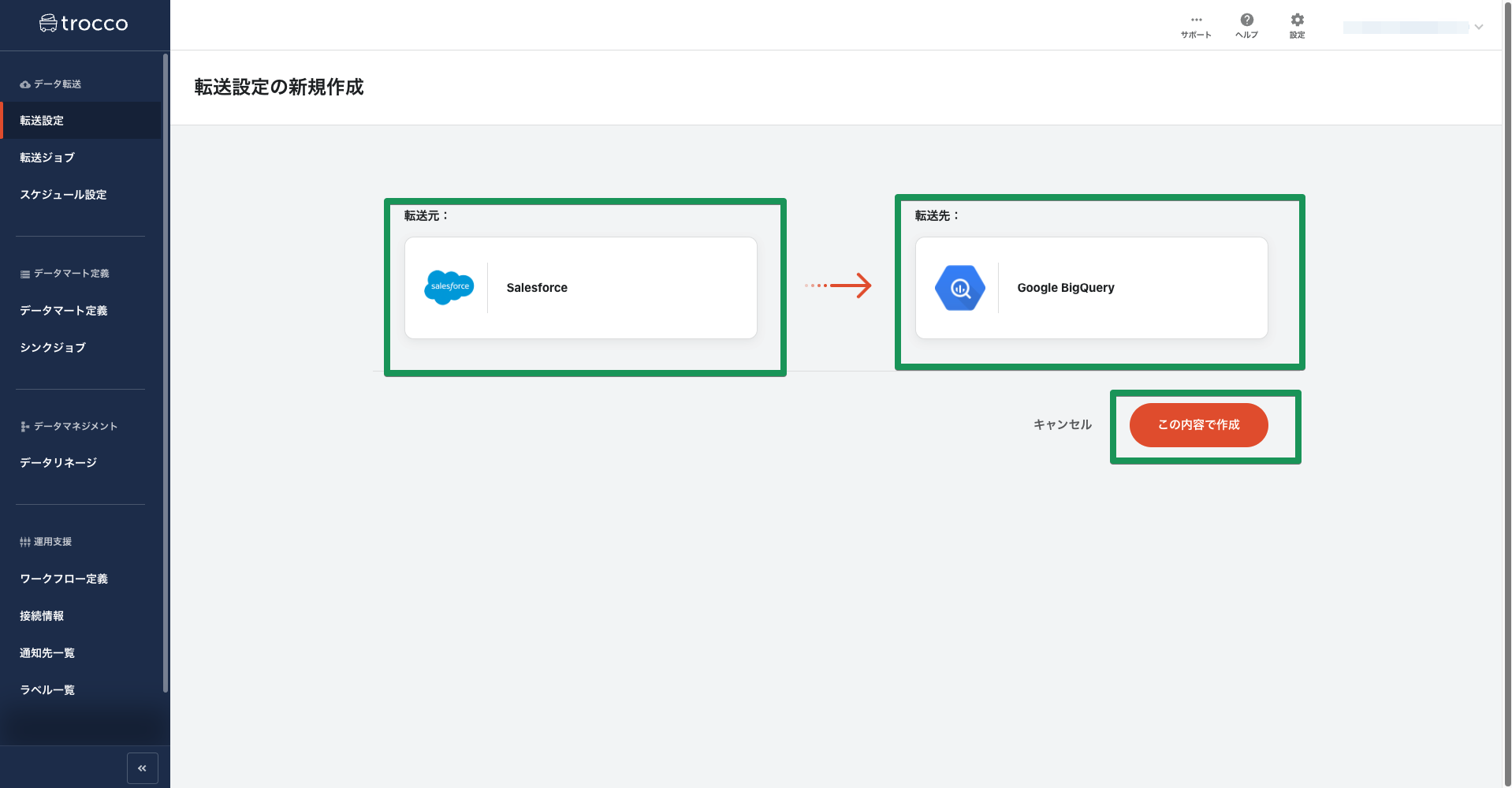
trocco®は多くのサービスをサポートしています。今回は転送元に「Salesforce」、転送先には「Google BigQuery」をそれぞれ選択し、「この内容で作成」ボタンを押します。
2-1. Salesforceからの転送設定
まずは右上の「接続情報を追加」ボタンを押します。
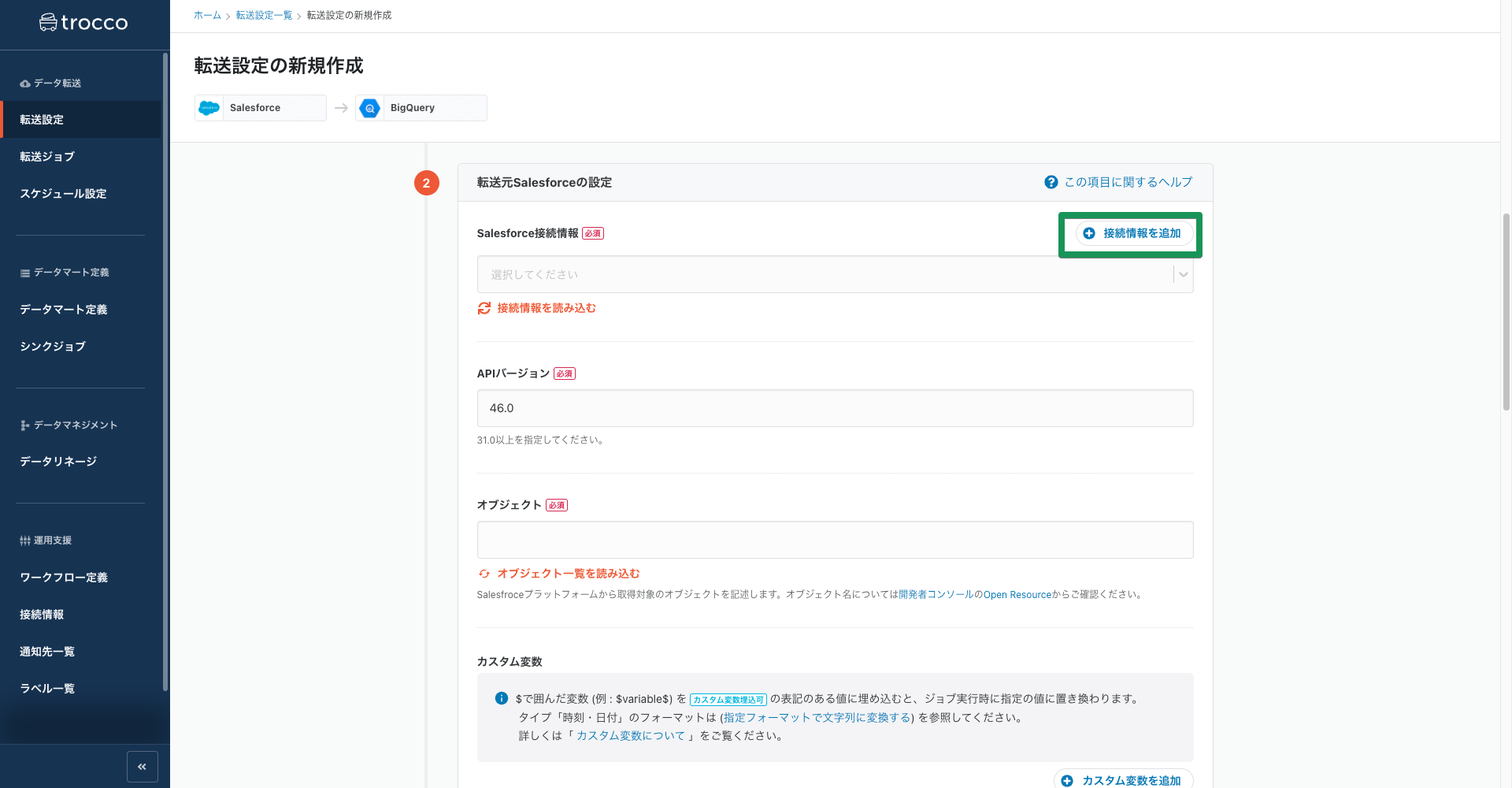
別のタブでSalesforceへの接続情報を入力する画面が開きます。SalesforceアカウントのユーザーIDやパスワード、trocco®がSalesforceにアクセスするために必要なセキュリティトークンを入力します。
なおセキュリティトークンの作成手順についてはこちらのヘルプを参考になります。
転送設定画面に戻り、「接続情報を読み込む」ボタンを押すと右の▽マークから入力した接続情報を読み込めます。
※トップページの「接続情報」タブから事前に接続設定を済ませておくことも可能です。
接続情報が読み込めたらオブジェクトを選択します。このように接続したSalesforceアカウントで取得可能なオブジェクトが一覧で表示されるためその中から選択するだけで済みます。
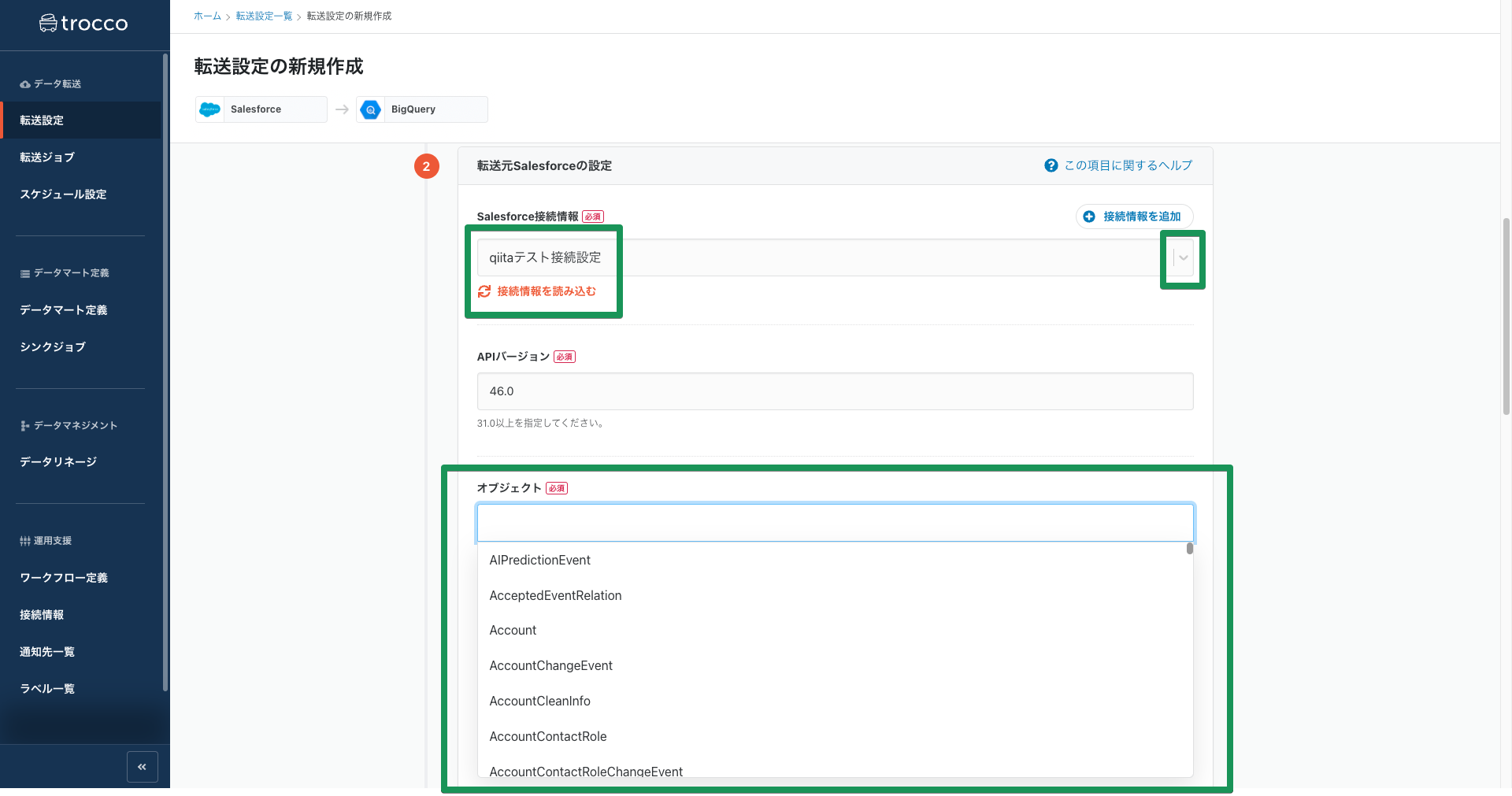
また取得するデータが文字列であるか、数値であるかといったデータ型の設定についても型推測機能の結果を使用することで簡単に済ませることが可能です。
2-2. Google BigQueryへの転送設定
転送元のSalesforceと同じく接続情報の設定をしていきます。Google BigQueryについても「接続情報を追加」ボタンから別のタブで接続情報の設定画面を開きます。Google BigQueryを利用するGoogleアカウントの認証を行います。
※トップページの「接続情報」タブから事前に接続設定を済ませておくことも可能です。
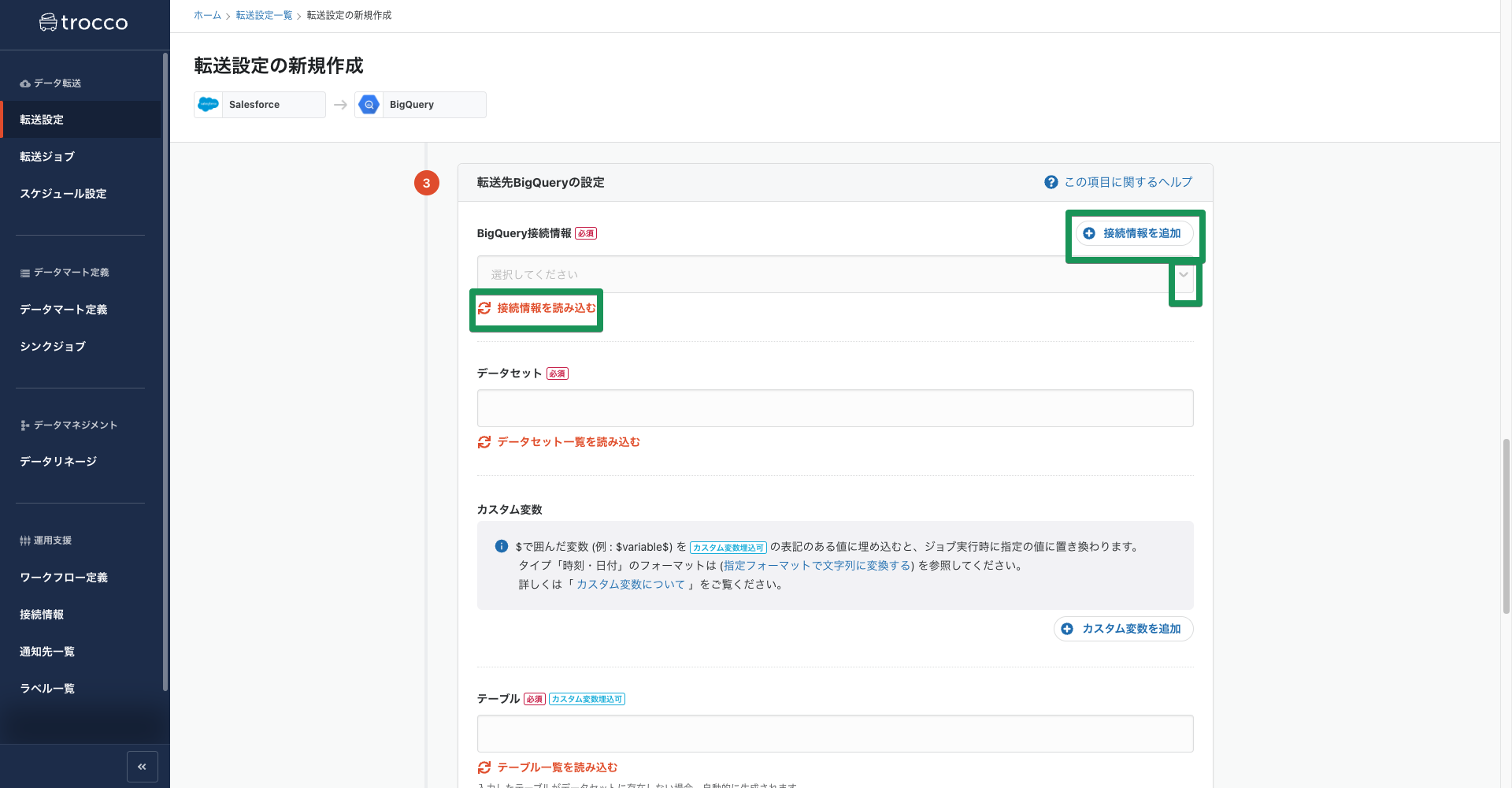
Salesforceの設定と同様に接続情報を読み込み、データセット、テーブルの名前をそれぞれ入力します。
(事前にGoogle BigQuery側で作成しておきましょう)
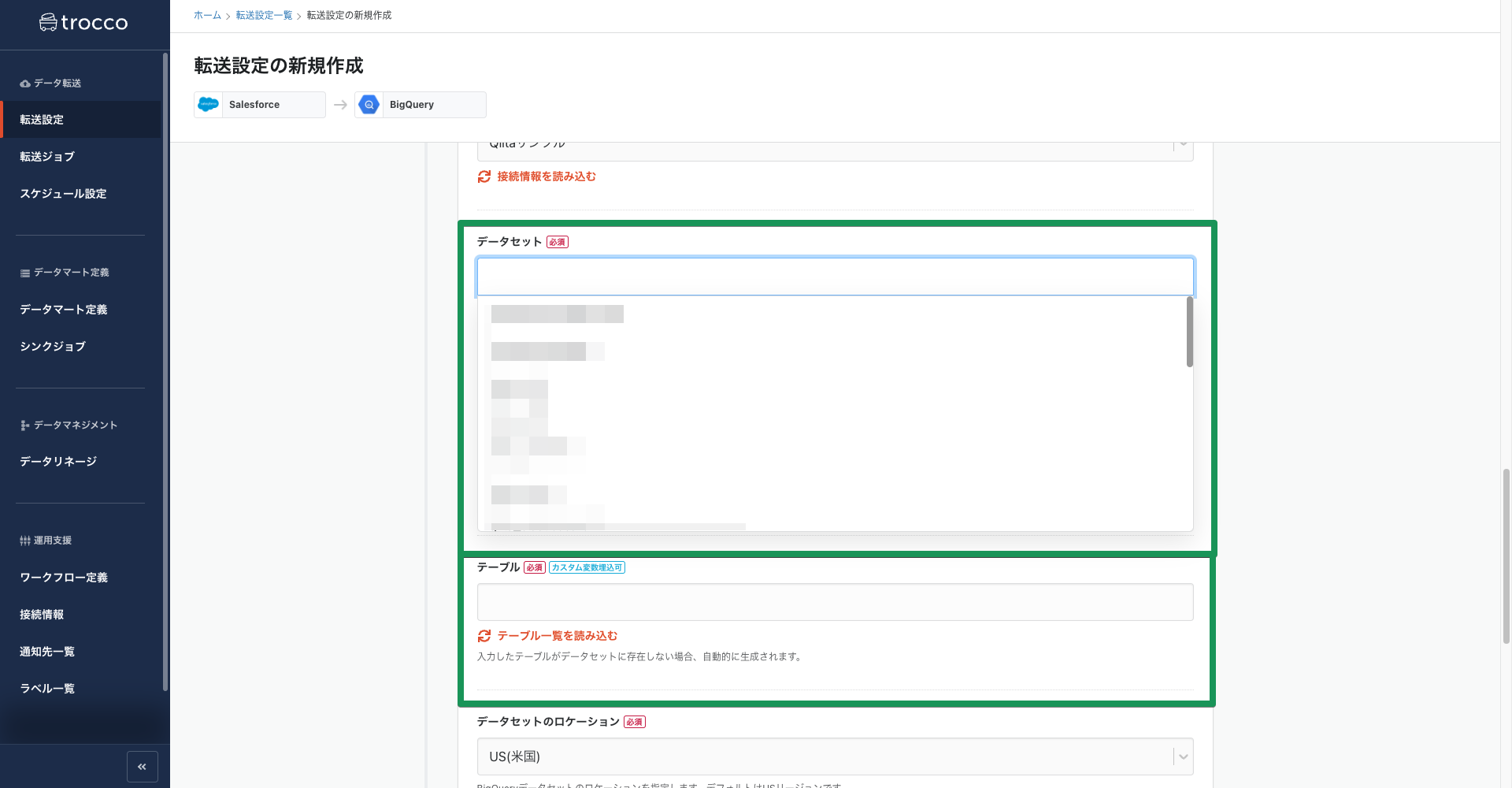
入力が済んだらページ最後の「次のSTEPへ」ボタンを押します。
2-3. データのプレビュー・詳細設定
設定にしたがって転送のレビューが作成されます。
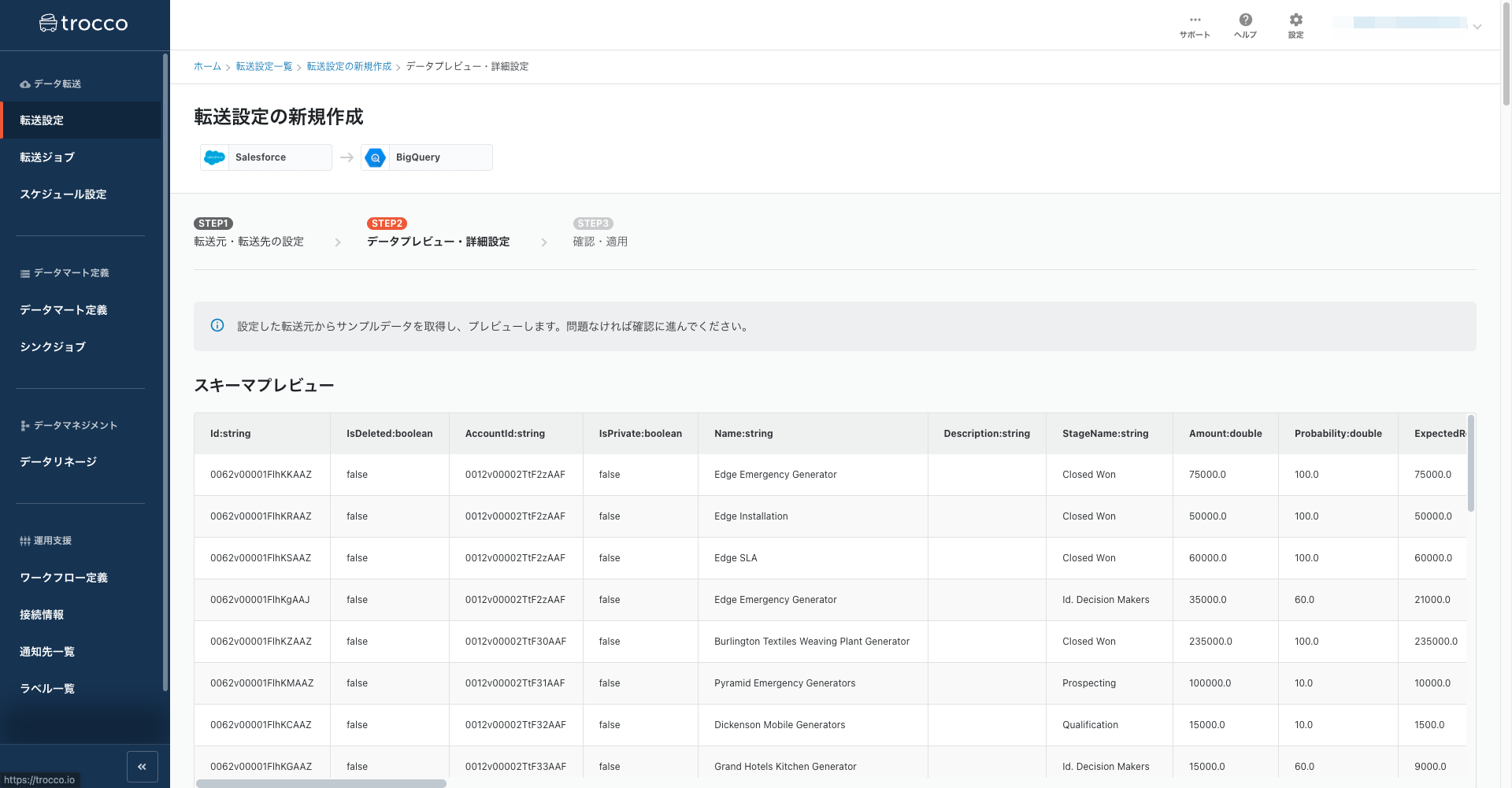
プレビュー画面では転送元からどのようにデータが取得されるのかが確認できます。
取得したいデータがプレビュー画面に表示されなければ再度転送元と転送先の設定に戻り、設定を修正します。
問題なく取得できているようなのでプレビュー画面下部の「確認画面へ」ボタンを押します。
なおプレビュー画面下部の詳細設定では転送の際に特定のデータをマスキング処理する、転送時刻のカラムを追加するといったデータの加工設定ができます。
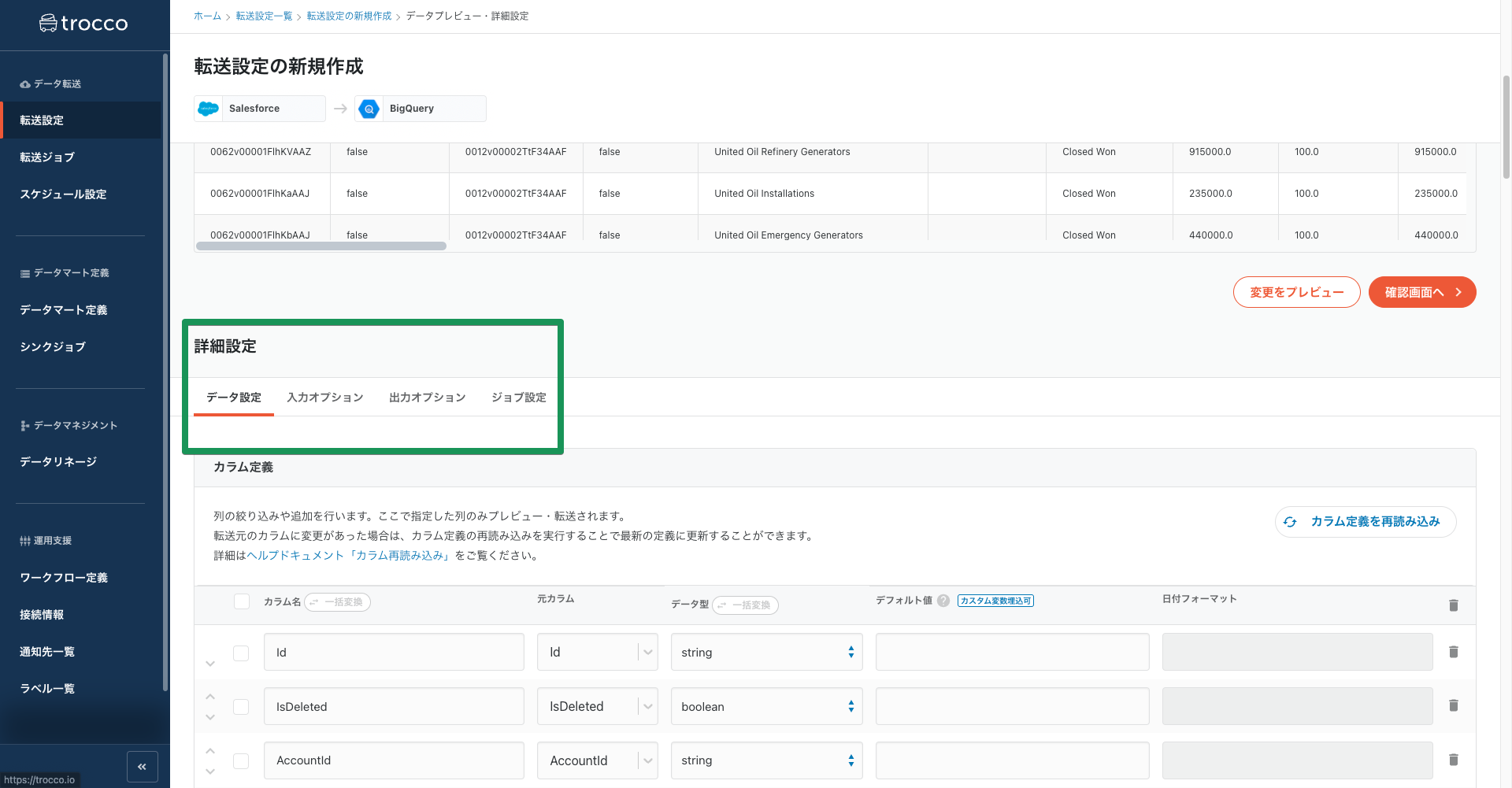
2-4. 確認・適用
転送設定の内容が確認できます。過去に作成した転送設定の内容を編集した際にはこの画面でその差分がハイライト表示され、確認をすることが可能です。
今回は設定の新規作成なので、特に確認することはありません。右下の「保存して適用」ボタンを押します。
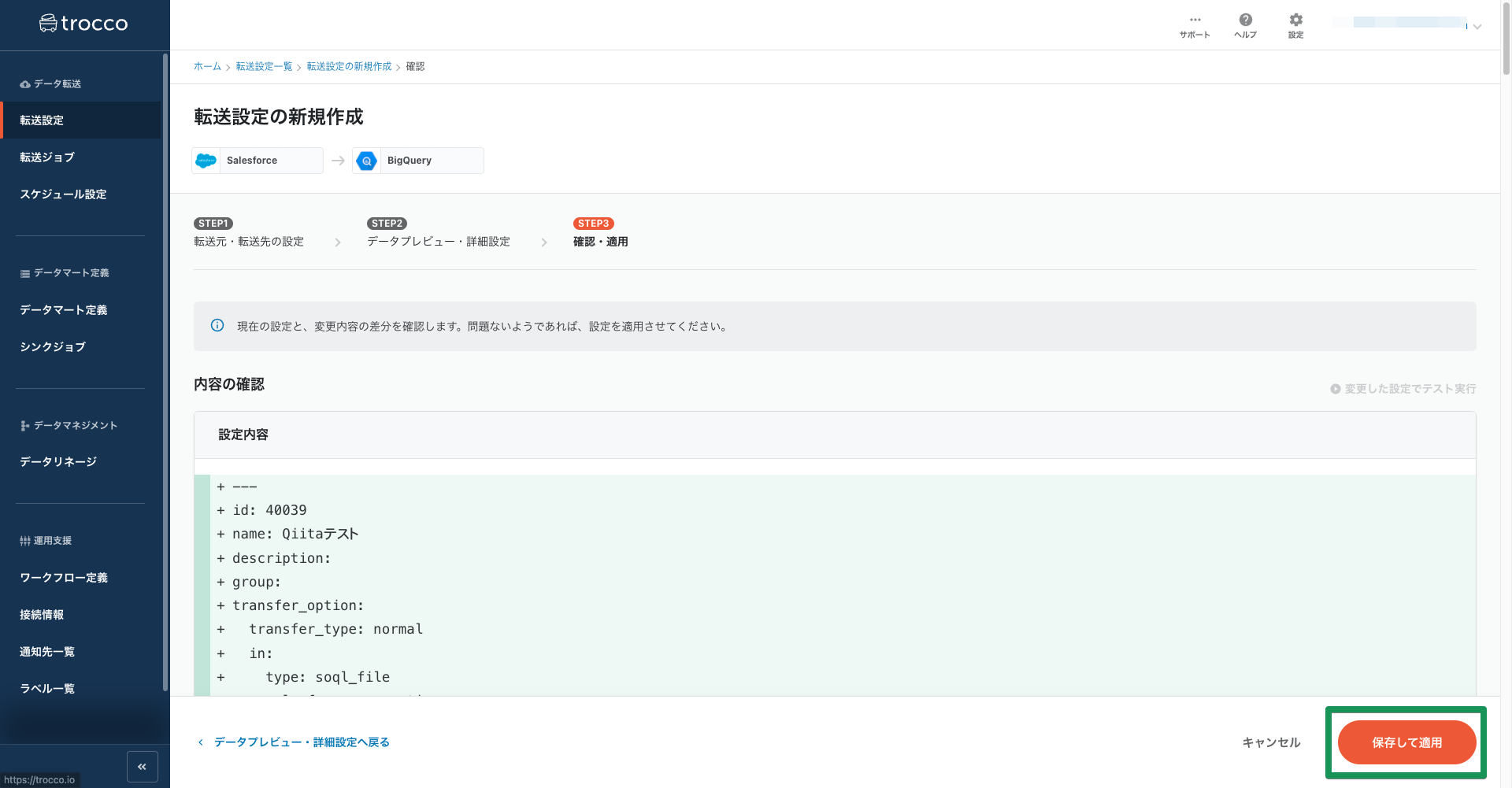
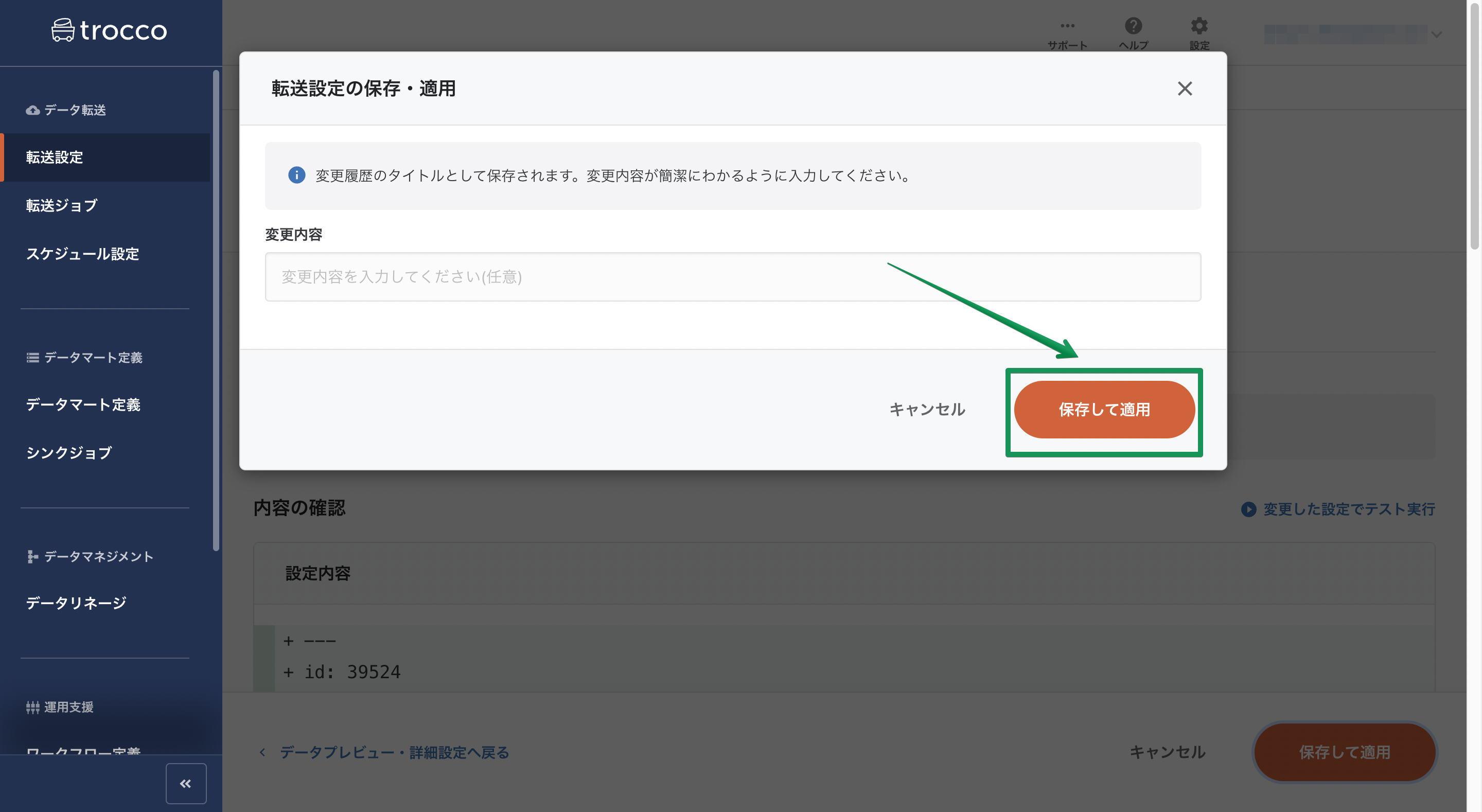
trocco®には既存の転送設定を変更した際、変更後も過去の設定内容の履歴を保存して転送設定の変更によって転送が失敗するようになった際などにその履歴から設定を復元するロールバック機能があります。
trocco®を共有して使用し、チームでデータ分析にあたる場合などは、転送設定の変更についてこの画面で簡単なメモを残しておきましょう。
2-5. スケジュール・通知設定
転送設定の詳細設定画面に移動します。まず「転送設定概要」タブでは設定の内容が大まかに確認できます。
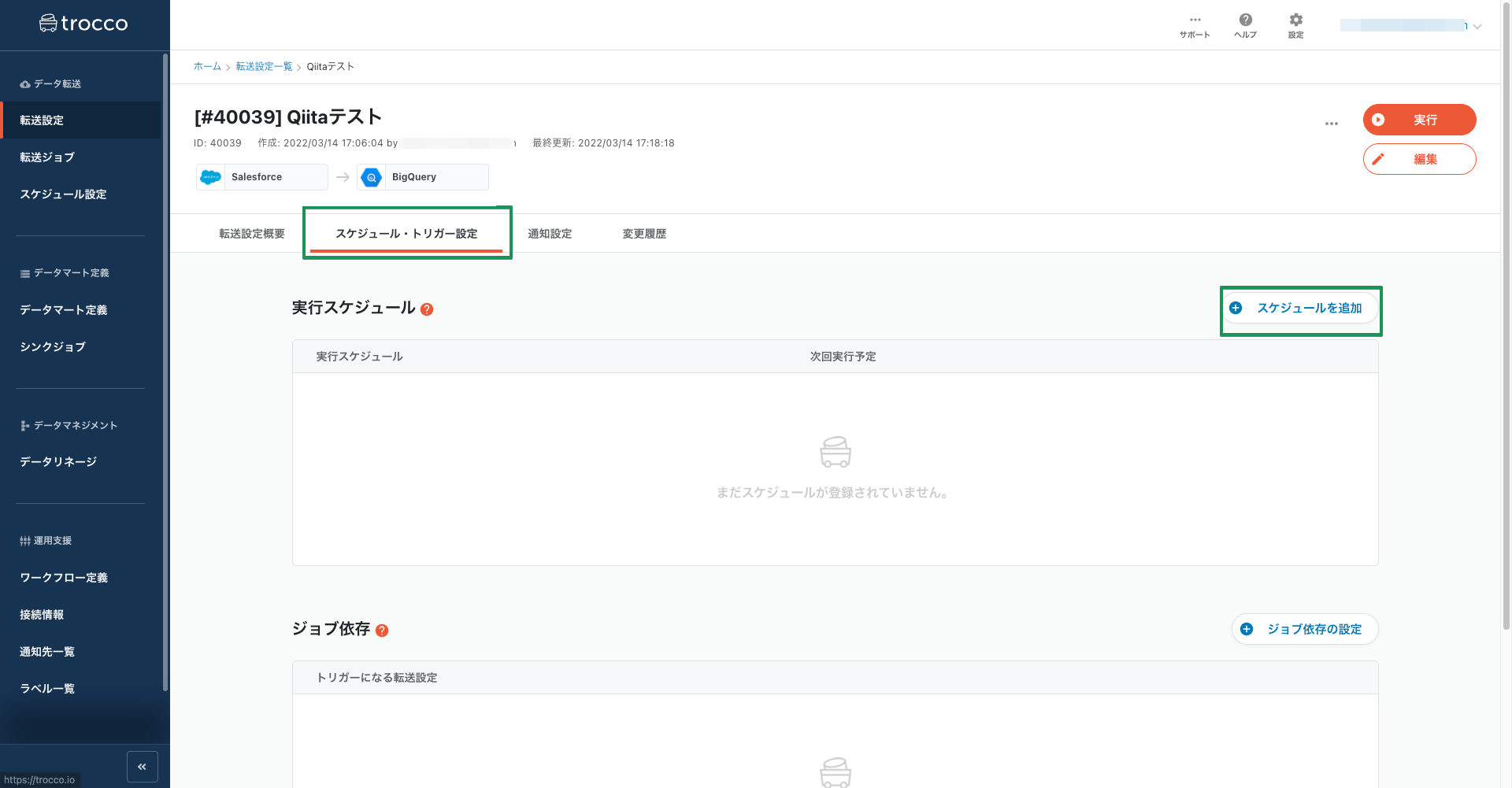
trocco®にはデータの転送を定期的に自動で行う「スケジュール・トリガー機能」があります。今回はデータが変更される都度人の手でデータを更新しなくともグラフが最新の状態に更新されるようにしてきますので、「スケジュール・トリガー設定」タブを開いて定期的な転送スケジュールの設定を行いましょう。
「スケジュールを追加」ボタンを押すと、設定のモーダルが出てくるので、希望に応じて実行スケジュールを設定し、転送の自動化を行います。(今回は毎日0時に転送を行うよう設定しました。)
2-7. データ転送ジョブの実行
設定は以上で終わりです。データの転送は以後自動的に行われますが、今回はこのまま右上の「実行」ボタンから手動で転送を実行します。
転送の実行に際し、その目的などをメモとして残しておくことができます。特に書くことがなければ再び「実行」ボタンを押します。
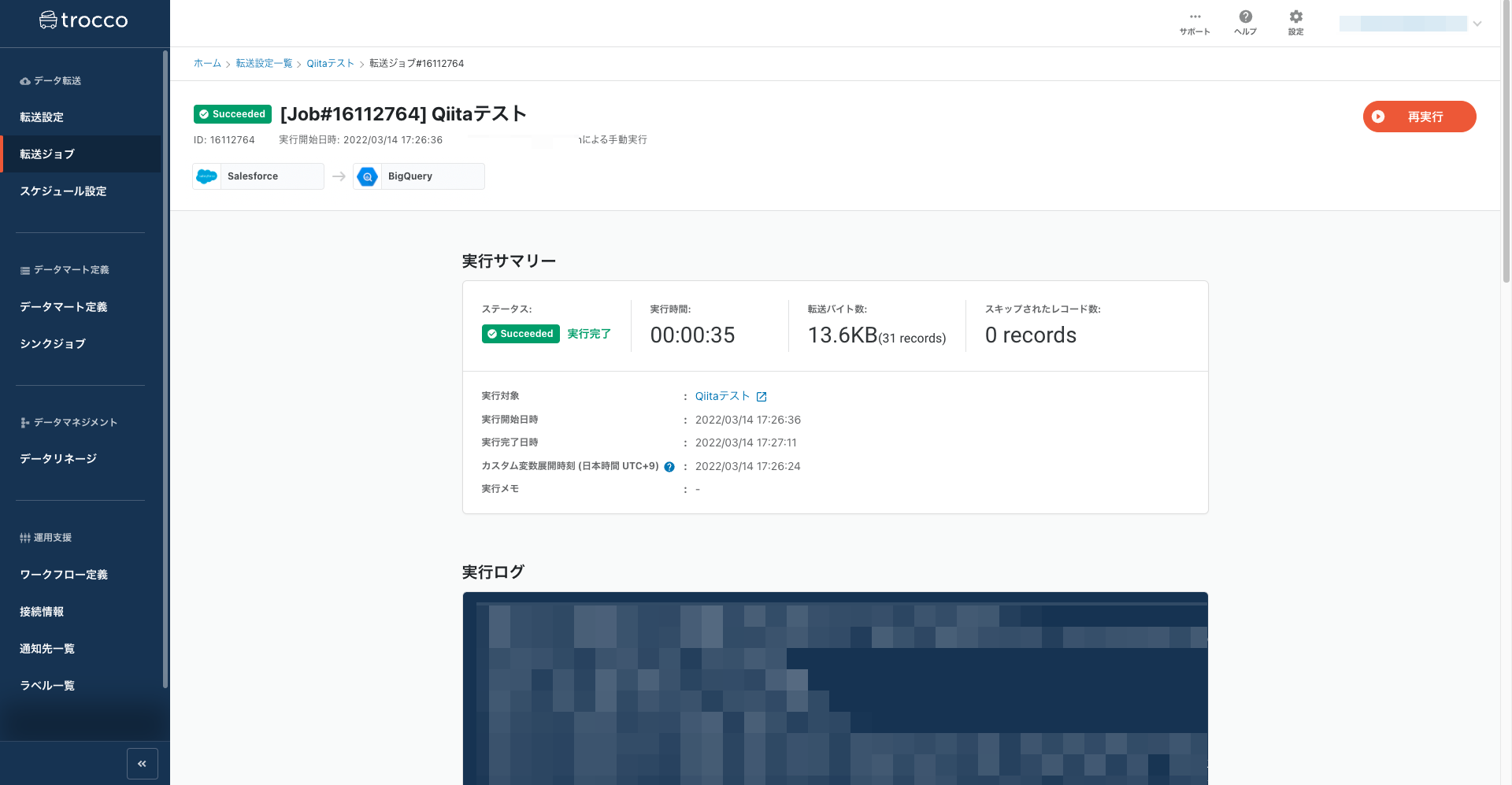
ジョブが実行されます。
しばらく待つとジョブが終了します。
3. Google BigQueryの設定
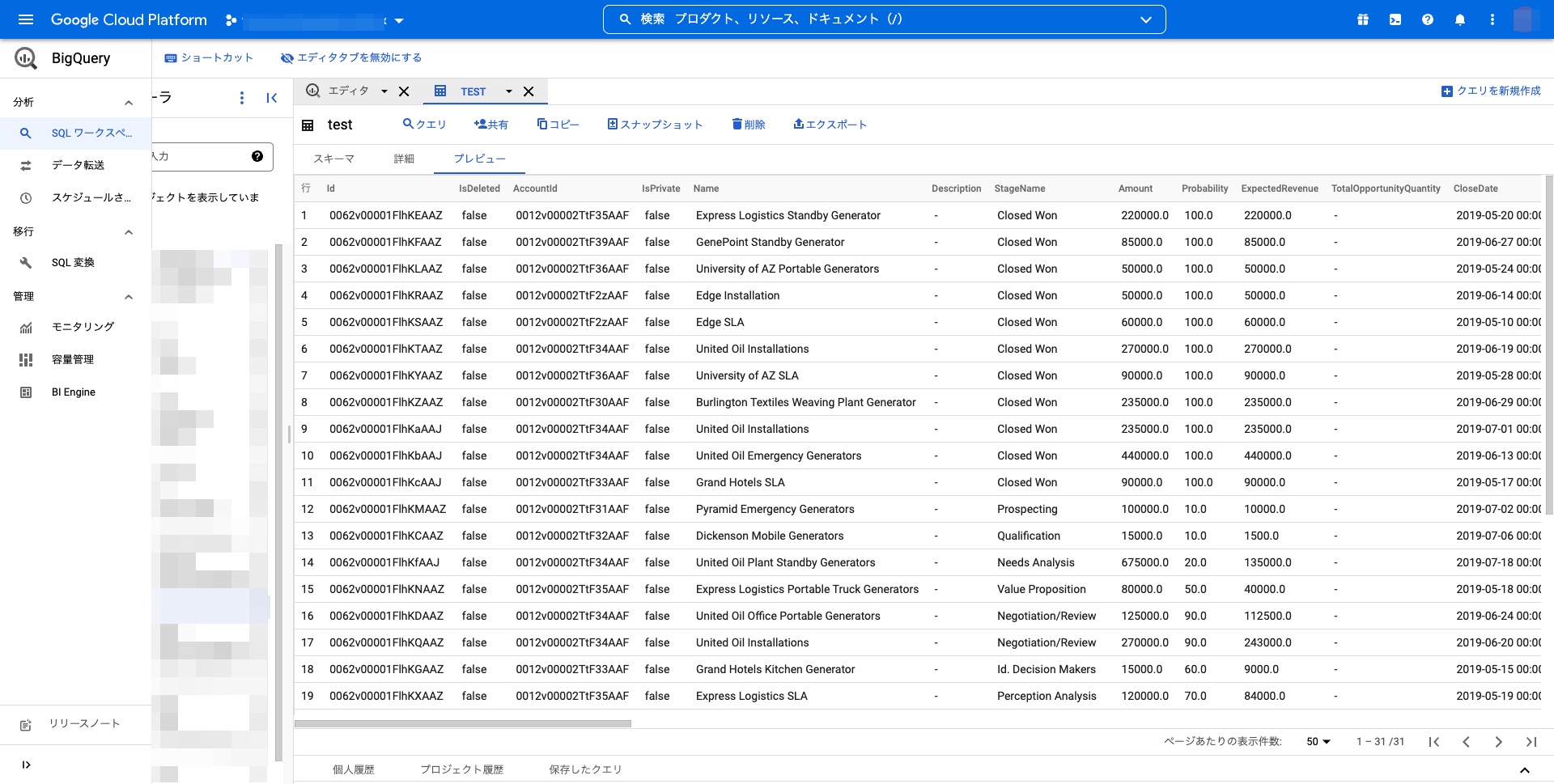
Google BigQuery側での操作は必要はありませんが、コンソール画面からプレビューで転送結果を確認すると、たしかにデータが転送されていることが確認できます。
4. Googleデータポータルでの可視化
最後にGoogleデータポータルを用いてデータの可視化を行います。まずはトップ画面の「新規」から新しいレポートを作成します。

データ元となるサービスを選択します。今回はGoogle BigQueryを選択します。

データの転送先となるプロジェクト、データセット、テーブルを選択してデータをデータポータルに読み込ませると、レポートの編集画面に移動します。
レポートの編集画面では画面右側に表示されるそれぞれのフィールドをディメンション・指標に追加してグラフを作っていきます。
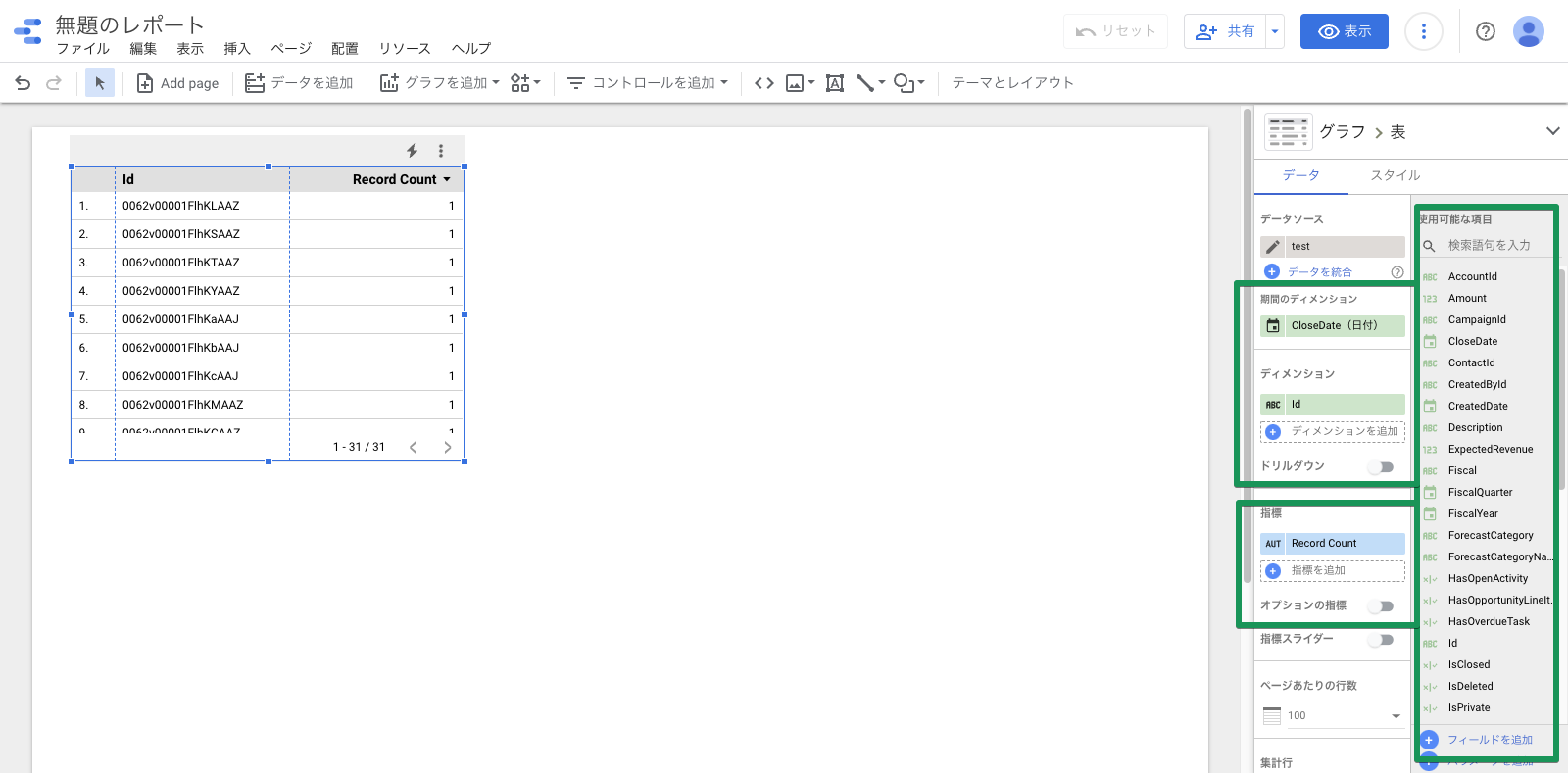
画面右上の「グラフ」には主なグラフがいくつか用意されています。適当なものを選択することで簡単にグラフを作成できます。
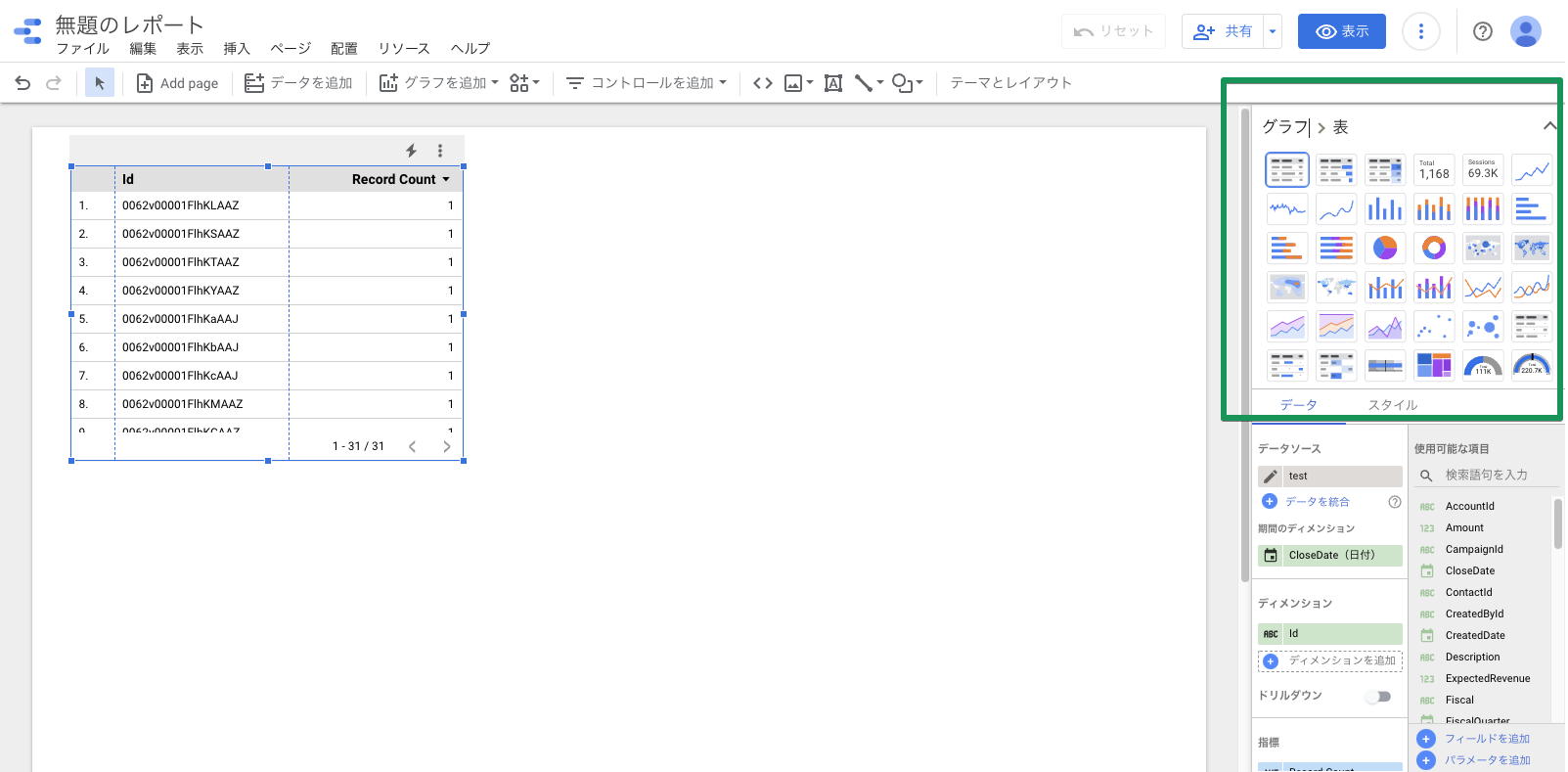
試しに、獲得しているリード数の日次推移を可視化してみましょう。
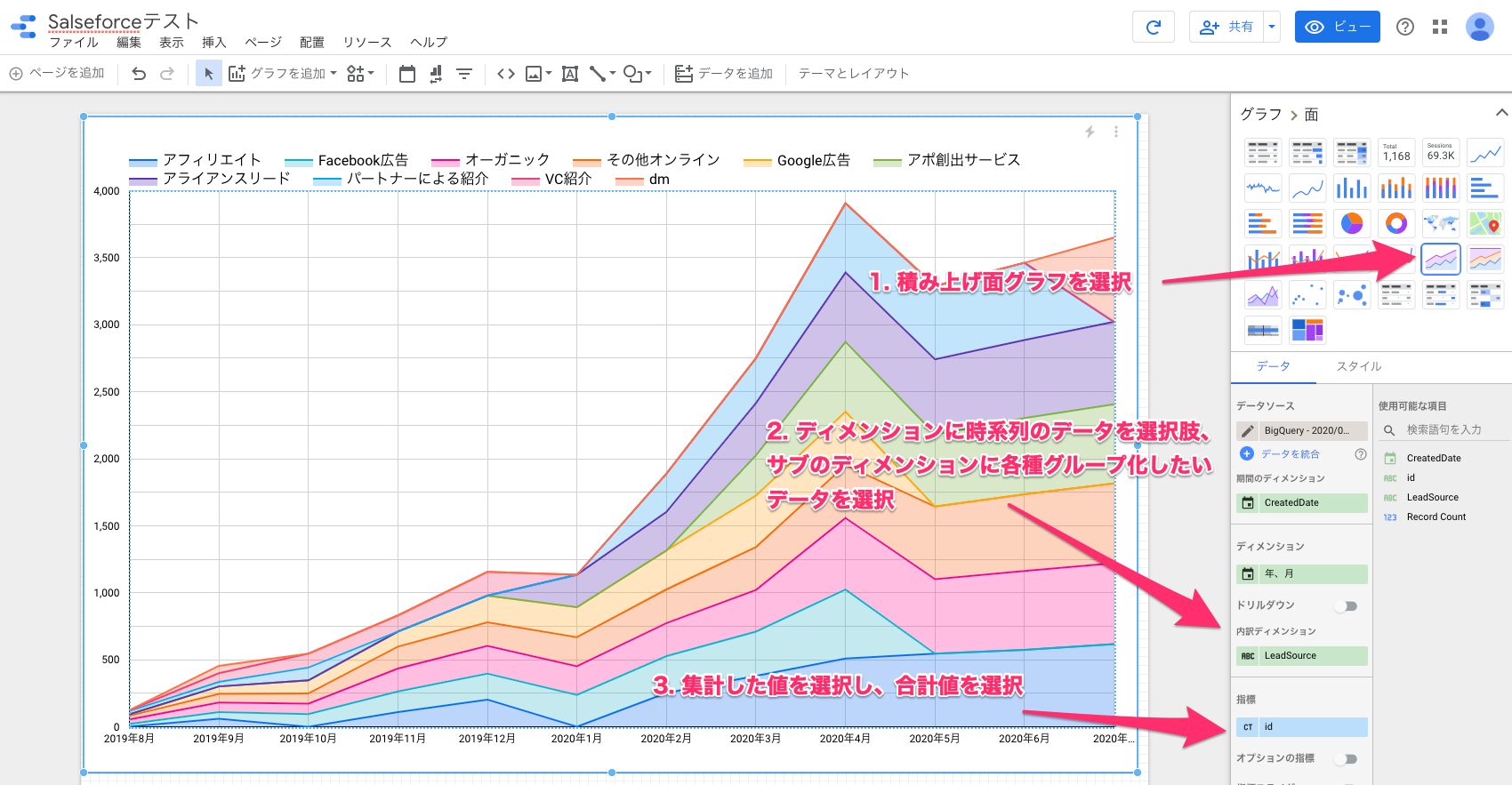
すると、以下のようなグラフが出来上がります。
この画面はデータポータルの「エクスプローラ」という機能になります。
「エクスプローラ」は定期的に閲覧するデータの変化の原因をアドホックに分析する際に使うイメージです。
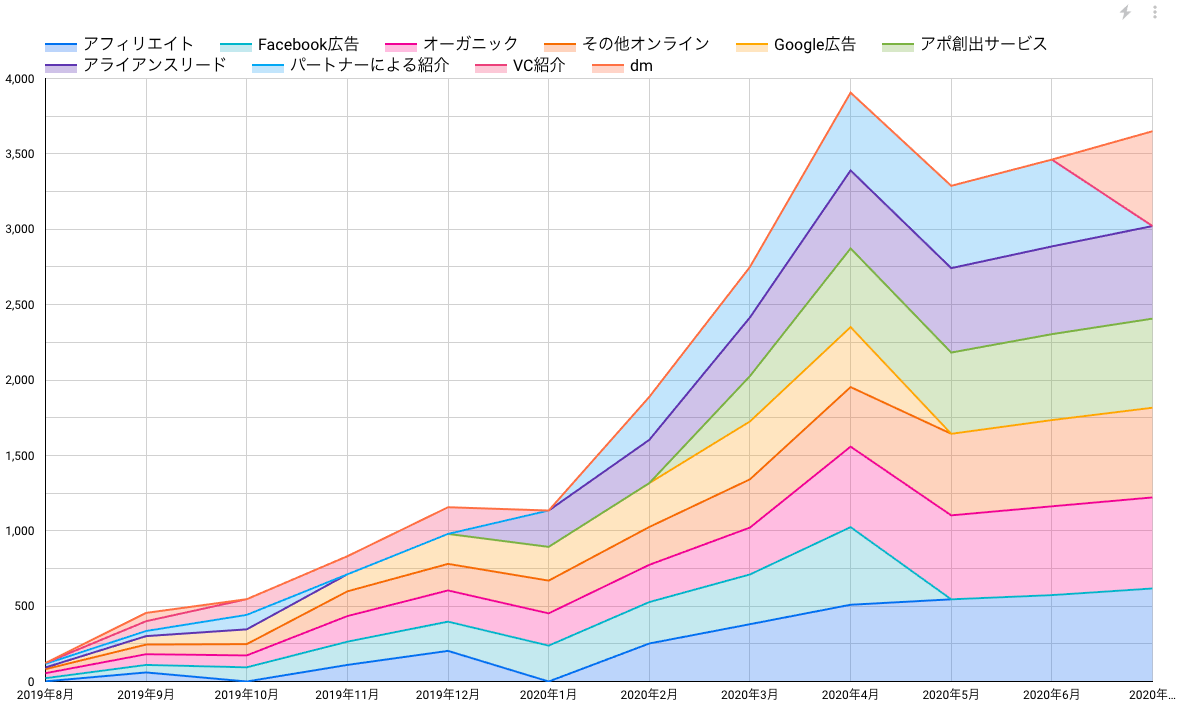
データポータルのトップ画面から、「レポート」を作成し、上述の通りグラフ作成を行うと、ダッシュボードが出来上がります。
今回はデータを貯めて、簡単な可視化までとしましたが、リード獲得チャネル毎の費用と売上を紐付けることによってROIも簡単に算出することが可能です。
まとめ
ほぼ画面上の設定のみでSalesforceのデータをGoogle BigQueryへ統合し、Googleデータポータルを用いてデータの可視化を行いました。またtrocco®の「スケジュール・トリガー機能」の設定を行ったため、以後はSalesforceに新しく追加されたデータはその設定に従って定期的にGoogle BigQueryへ転送され、また連携するGoogleデータポータルのレポートも自動更新機能によって常に最新の状態に維持されていくという流れになっています。
実際に弊社サービスのtrocco®においても、マーケティングKPI等はこのような流れで収集し・分析しています。
データ分析の際にはぜひご活用ください。
https://trocco.io/lp/index.html
実際にデータ統合を体験してみたい方は、フリープランがありますので、この機会にぜひ一度お試しください。
その他にも広告やデータベースなど、様々な分析データをETL・転送した事例をまとめました。
trocco®の使い方まとめ(CRM・広告・データベース他)