概要
業務分析する際に、予定工数、実績工数、進捗状況などの分析が非常に重要です。
しかしそのような分析を行うには、お使いのタスク管理ツールのデータを抽出し、分析環境に統合する必要があります。
多くの場合、分析基盤へのデータ統合が手間のかかる作業となっていますが、この記事では出来るだけ省エネで分析の前処理を実現する方法を書いていきます。
今回はJIRAのデータをBigQueryにtroccoを使ってデータを統合し、Googleデータポータル(旧Data Studio)で可視化するまでを行ってみます。
[troccoの使い方まとめ(CRM・広告・データベース他)]
(https://qiita.com/hiro_koba_jp/items/2b2caa040804e402bda7)

ゴール
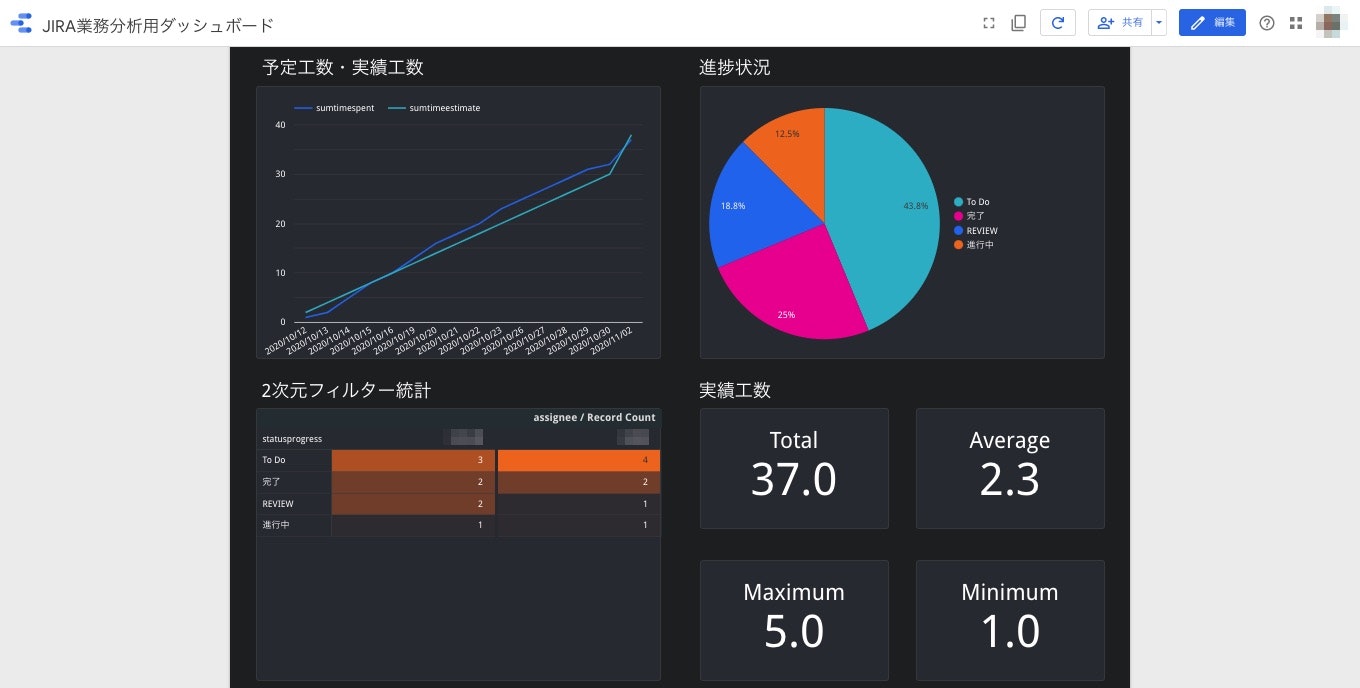
このようなJIRAのデータから

こんなのを30分くらいで作り上げます(当然、作ったあとは自動で最新値が更新されるようにします)
こんな人におすすめ
- JIRAのデータを分析基盤・DWHに取り込みたい方
- 分析基盤・DWHにJIRAのデータを毎回CSVエクスポートし取り込んでおり、時間の浪費に悩んでいる方
- 様々なデータ取得の作業に疲れている方
1. DWHと同期する手段の選定
1-1. DHWの選定
まずはデータをどこに集約するか、DHW(データウェアハウス)を選定します。
Google BigQueryAmazon RedshiftMySQL-
PostgreSQLなど
今回はGoogle BigQueryを利用することにします。
1-2. JIRAのデータをBigQueryに転送する4つの方法
BigQueryにデータを集約することが決まったので、次は転送するための手段を検討していきます。
1. JIRAのデータをCSV形式でエクスポートし、手動でBigQueryにアップロードする。
2. JIRAとBigQueryの各APIを、プログラムを書いて連携する。
3. Embulkを利用し、自分で環境を構築する
4. troccoを利用し、画面上で設定する。
1. は単発の実行であればよいのですが、定期的な取り込み用途だと毎回同じ作業を繰り返すことになり、非効率な作業になりがちです。
2. はAPIのキャッチアップ工数+プログラムを書く工数+環境構築工数が発生する他、エラー対応などの運用工数も継続的に発生します。
3. も2と同じくEmbulkはある程度の専門知識が必要になり、自前で環境構築・運用を行う手間が発生します。加えてエラーの内容が少し専門的です。
そこで今回はEmblukの課題も解決してくれて、プログラムを書かずに画面上の設定で作業が完結する、**4.のtrocco**というSaaSを利用します。
2. troccoでJIRA→BigQueryの転送自動化
2-0. 事前準備
troccoのアカウントおよびJIRAのアカウントが必要です。
無料トライアルも実施しているので、事前に申し込み・登録しておいてください!
(申込時に、この記事を見た旨を記載して頂ければご案内がスムーズです)
2-1. 転送元・転送先を決定
troccoにアクセスし、ダッシュボードから「転送設定を作成」ボタンを押します。
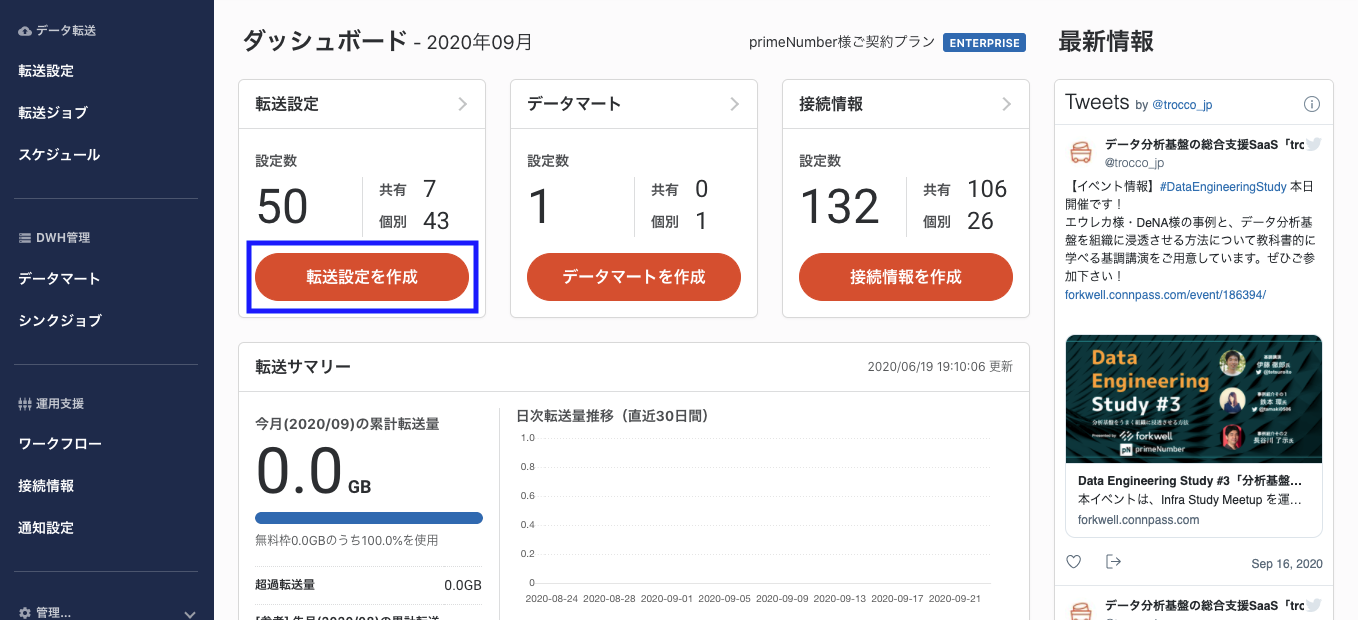
転送元にJIRA、転送先にGoogle BigQueryを選択し、「この内容で作成」ボタンを押します。

すると、設定画面になるので、設定画面から必要な情報を入力していきます。
2-2. JIRAとの連携設定
転送設定の名前とメモを入力します。

転送設定の名前とメモを入力したら、「転送元の設定」内の「接続情報を追加」ボタンを押し、JIRAの接続情報の設定を行います。
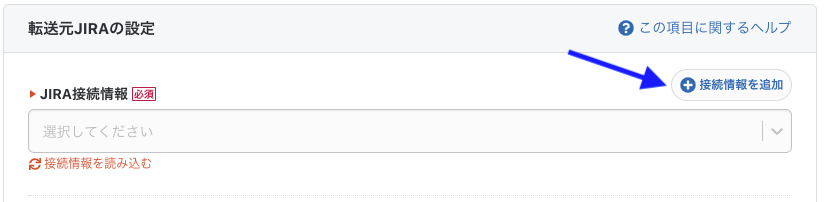
データを取得したいJIRAの情報を入力し、接続情報を作成します。

2-3. JIRAからのデータ抽出設定
これでJIRAとの連携は完了です。
次に、JIRAの取得データを設定します。

このとき、カスタム変数を使うことでジョブ実行時に指定の値を置き換えることもできます。
以上でJIRA側の設定は完了です。
次は転送先のBigQueryの設定を行っていきましょう。
2-4. 転送先BigQueryの設定
転送元JIRAと同じ要領で設定していきます。
データセットとテーブルは好きな名前を入力していきます。自動生成オプションを有効にすれば、データセット・テーブルが自動作成されます。
また、カスタム変数を使うことにより、ジョブ実行時に指定の値に置き換えることができます。
BigQueryデータセットのロケーションを指定することができます。デフォルトはUSリージョンです。
東京リージョンを指定する場合はasia-northeast1を入力して下さい。

これで入力は完了です。「保存して自動データ設定・プレビューへ」をクリックし、確認作業に進みましょう。
2-5. データのプレビュー
転送元のデータがプレビューされます。ここではJIRAから取り込んだデータが表示されています。
問題なければ、「設定を完了する」を押し、スケジュールや通知設定に進みます。

2-6. スケジュール設定
「スケジュール・トリガー設定」タブを開きます。

以下のように実行スケジュールを設定することで、転送を自動化することが出来ます。

2-7. 通知設定
今回の自動同期には、必須の設定ではないですが、通知タイプ・通知条件・通知先を選択し設定を保存することで、EmailまたはSlackに通知を行うことが出来ます。

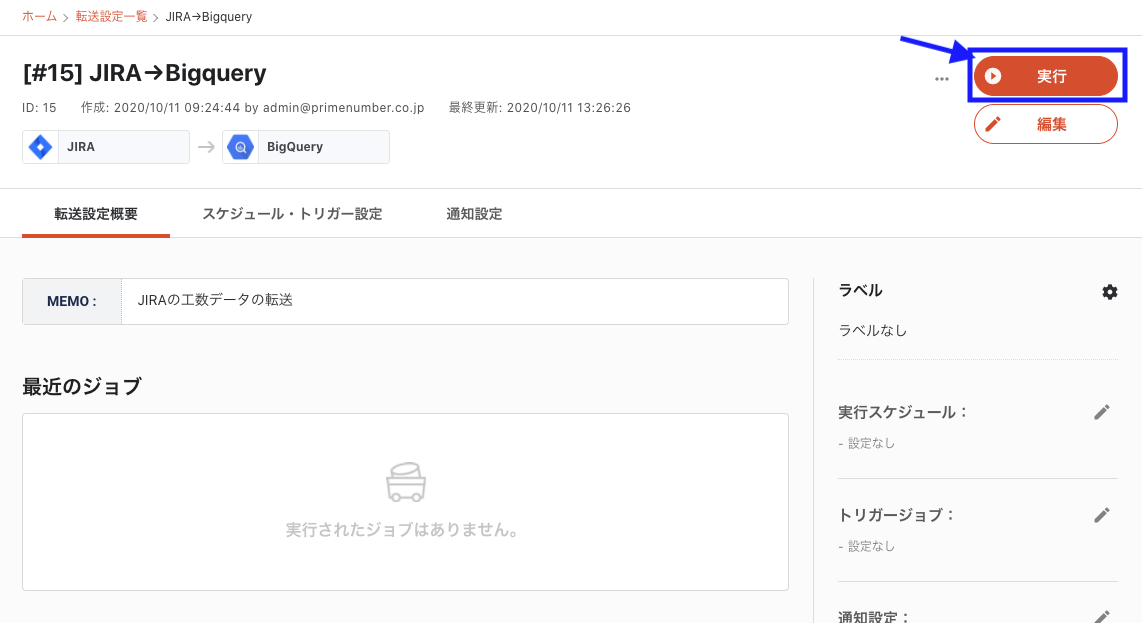
また、必要な時のみ実行したい場合は、手動で行うことも出来ます。
その場合は、転送設定詳細画面から「実行」ボタンを押して進めていきます。
3. BigQueryの設定
特に設定することありません。データが溜まっているので、今すぐに分析・可視化を行うことが出来ます。
念の為、データをプレビューして確認してみます。

4. Googleデータポータル(旧データスタジオ)で可視化
BigQueryの画面から、「エクスポート > データポータル」を選択します。
すると、以下のようなData Portalの画面に遷移します。
試しに、予定工数と実績工数の日次推移を可視化してみましょう。

すると、以下のようなグラフが出来上がります。
この画面はデータポータルの「エクスプローラ」という機能になります。
「エクスプローラ」は定期的に閲覧するデータの変化の原因をアドホックに分析する際に使うイメージです。

データポータルのトップ画面から、「レポート」を作成し、
上述の通りに予定工数と実績工数以外の進捗状況などのグラフ作成を行うと、今回のゴールのJIRAの業務分析用ダッシュボードが出来上がります。
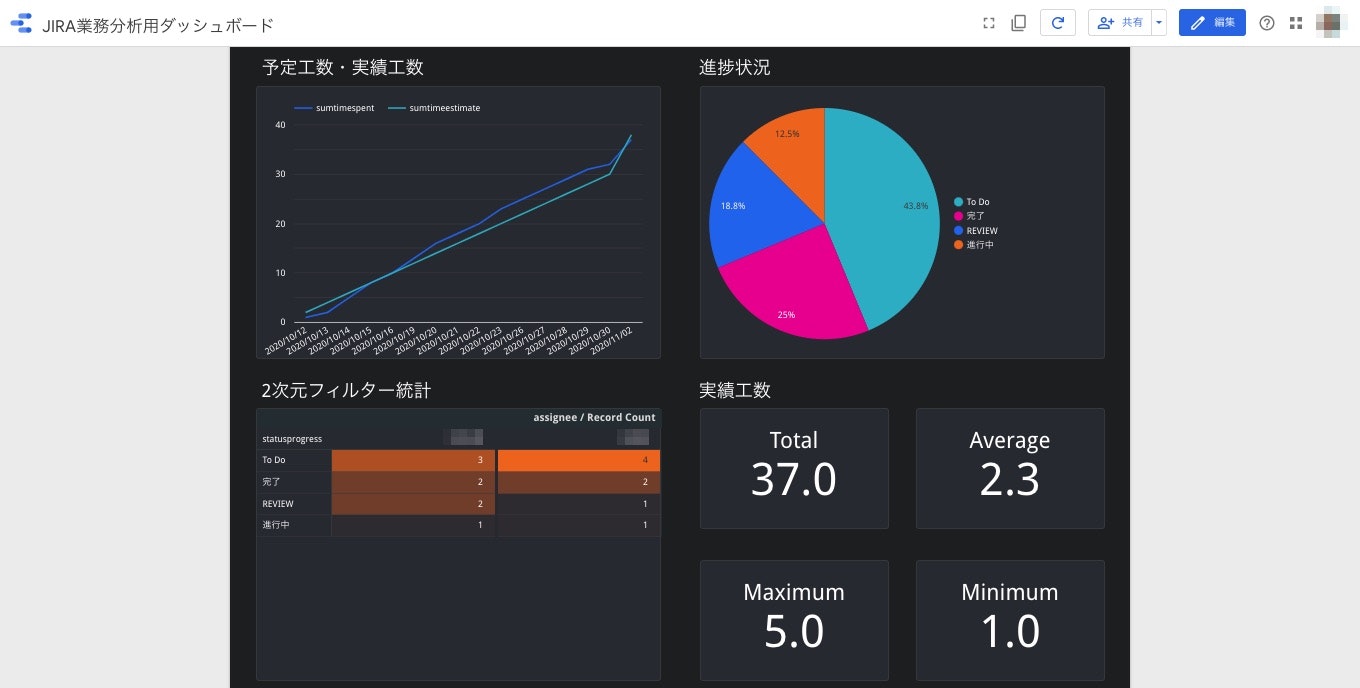
まとめ
いかがでしたでしょうか。troccoを使うと管理画面を触ることなく、簡単にJIRAのデータを取得し、DWH(BigQuery)に貯めることが出来ました。
また、BigQueryにデータを貯めると、データポータルというGoogleの無料ダッシュボードですぐに可視化することが出来ます。
実際に弊社サービスのtroccoにおいても、セールスのデータやマーケティングKPI等をこのような流れで収集・分析しています。
実際に試してみたい場合は、無料トライアルを実施しているので、この機会にぜひ一度お試しください。
(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内できます)
[troccoの使い方まとめ(CRM・広告・データベース他)]
(https://qiita.com/hiro_koba_jp/items/2b2caa040804e402bda7)