概要
S3からRedshiftにデータを転送する方法は様々ありますが、コーディングや環境構築が必要になるケースが殆どだと思います。
また運用のことを考えるとジョブ管理や通知・再実行のことを考える必要があり、そこそこの規模のシステムを構える必要が出てきてしまいます。
そこで、今回はコーディング・環境構築不要で、運用サポート機能も充実しているtroccoを使って、S3のデータをRedshiftに転送する方法をご紹介します。
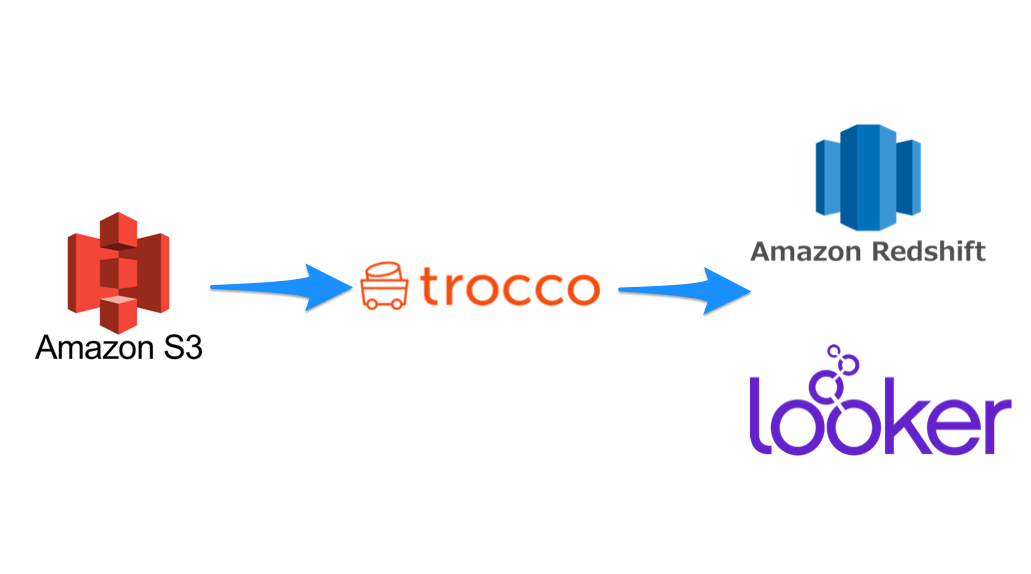
ゴール
S3にある広告データから
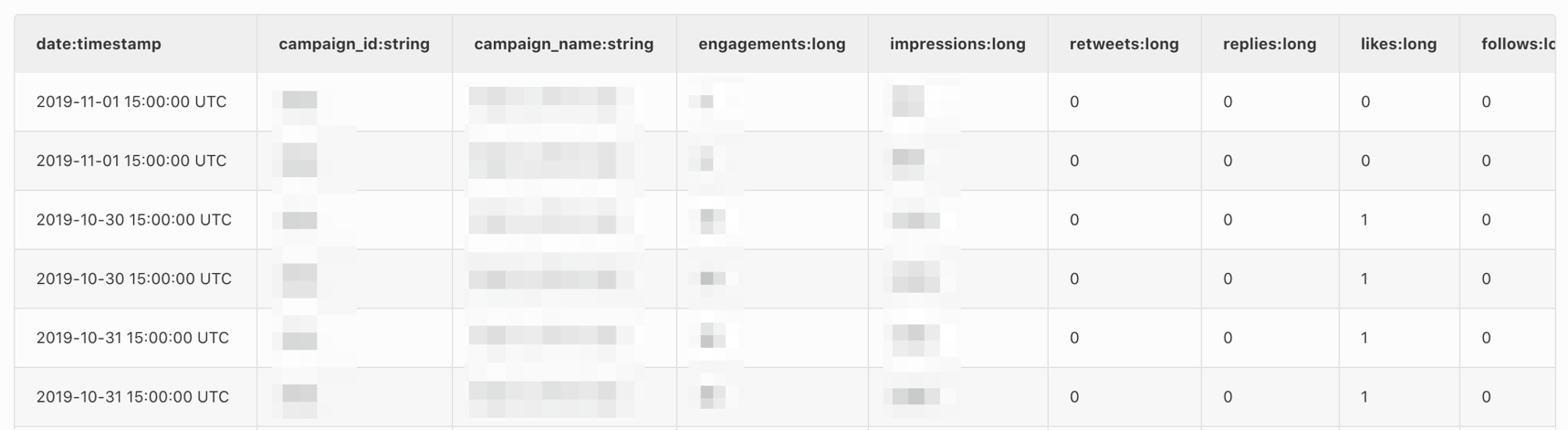
このようにRedshiftにデータ統合するまでを30分程度でやっていきます(作成後には最新値が自動で同期されるようにします)
こんな人におすすめ
- S3のデータをツールで可視化したい方
- S3のデータを分析基盤・DWH(データウェアハウス)に取り込む予定の方
- データ分析の前準備に疲れてしまった方
1. DWHと同期する手段の選定
1-1. DWHの選定
まずはデータをどこに集約するか、DWHを選定します。
Amazon RedshiftGoogle BigQueryMySQL-
PostgreSQLなど
今回はAmazon Redshiftを利用することにします。
1-2.転送手段の選定
Redshiftにデータを集約することが決まったところで、次は転送するための手段を選びます。
1. GUI・CLIでS3バケットからデータをダウンロードし、手動でRedshiftにアップロードする。
2. S3とRedshiftの各APIを、自前でプログラムを書いて連携させる。
3. Embulkを利用し、自前で環境を構築する。
4. troccoを利用し、画面上で設定する。
1. は単発の実行であれば良いものの、定期的に取り込む必要がある場合はタイムロスが多く、非効率な作業になりがちです。
2. はAPIのキャッチアップ工数+プログラムを書く工数+環境構築工数が発生する他、エラー対応などの運用工数も継続的に発生します。
3. も2と同じくEmbulkはある程度の専門知識が必要になり、自前で環境構築・運用を行う手間が発生します。エラーの内容が専門的で、詰まると大幅に時間を浪費してしまいます。
そこで、Embulkの課題も解決してくれて、プログラムを書かずに画面上の設定で作業が完結する、**4.**のtroccoというSaaSを利用します。
2. troccoでS3→Redshiftの転送自動化
2-0. 事前準備
troccoのアカウントおよびAWSのアカウントが必要です。
無料トライアルも実施しているので、前もって申し込み・登録をしておいてください!
https://trocco.io/lp/index.html
(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内できます)
2-1. 転送元・転送先を決定
troccoにアクセスし、ダッシュボードから「転送設定を作成」のボタンを押します。

転送元にS3、転送先にRedshiftを選択し、転送設定作成ボタンを押します。

すると、設定画面になるので、転送に必要な情報を入力していきます。
2-2. S3との連携設定
転送設定の名前とメモを入力します。
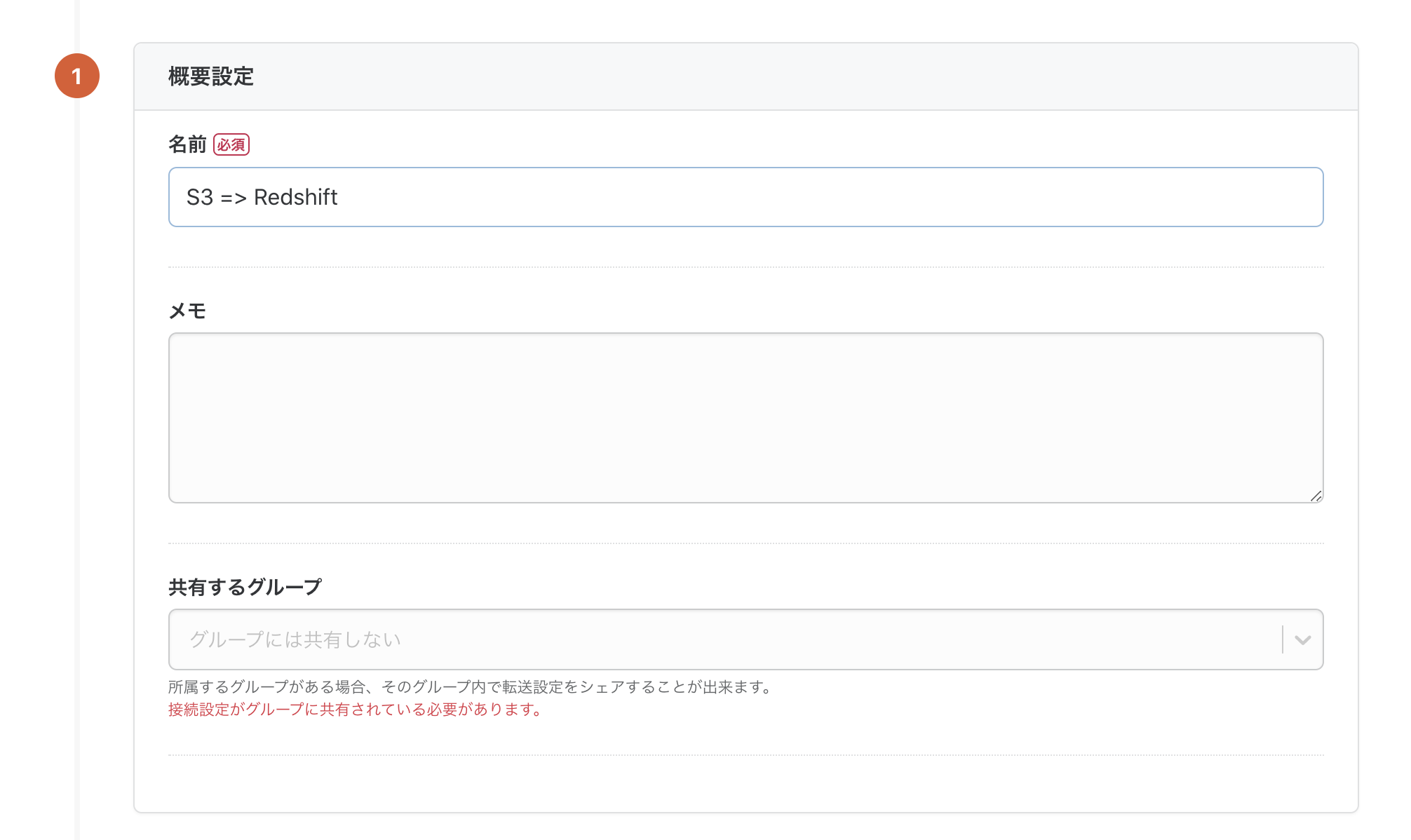
転送設定の名前を決めたら、「転送元の設定」内の「接続情報を追加」ボタンを押し、S3の接続情報の設定を行います。
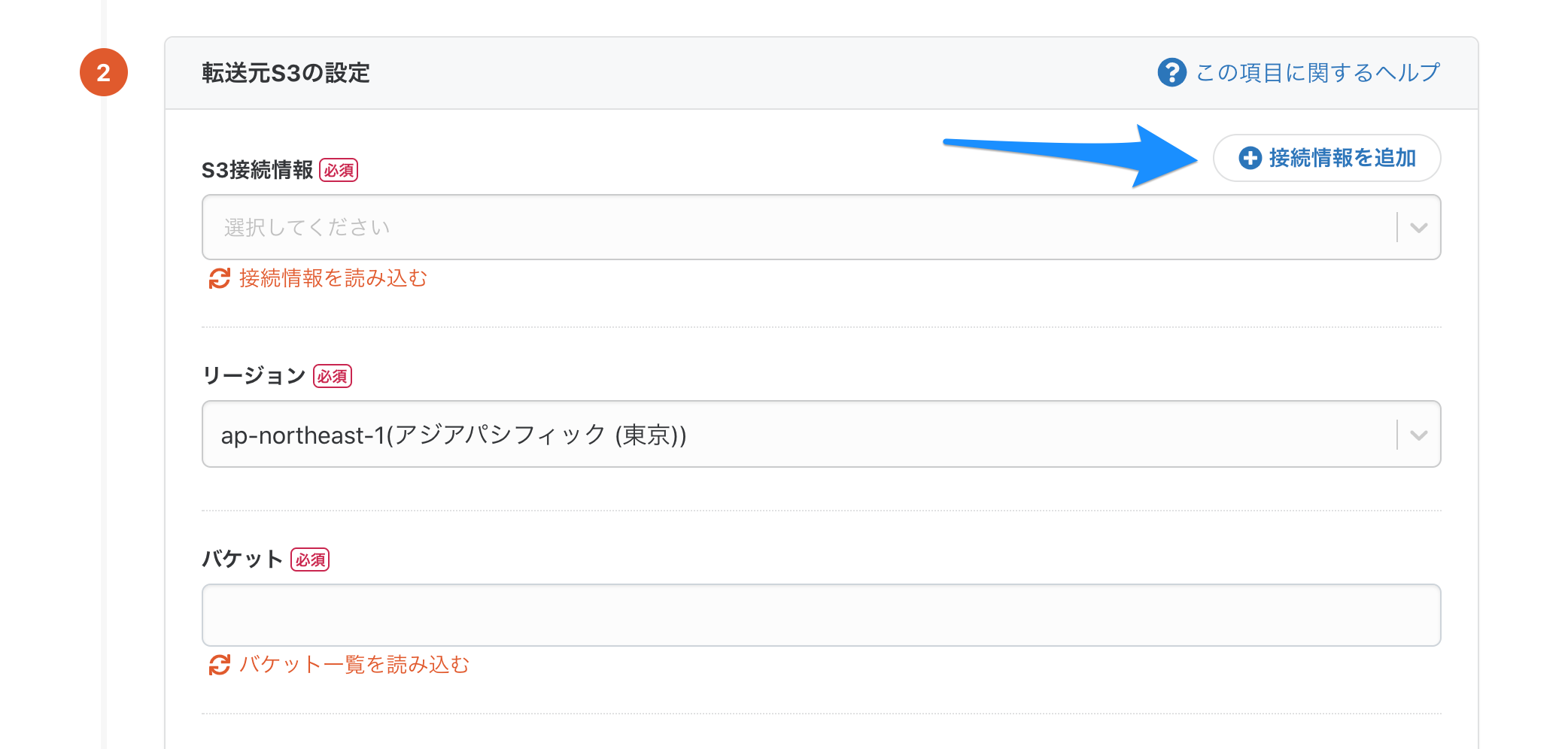
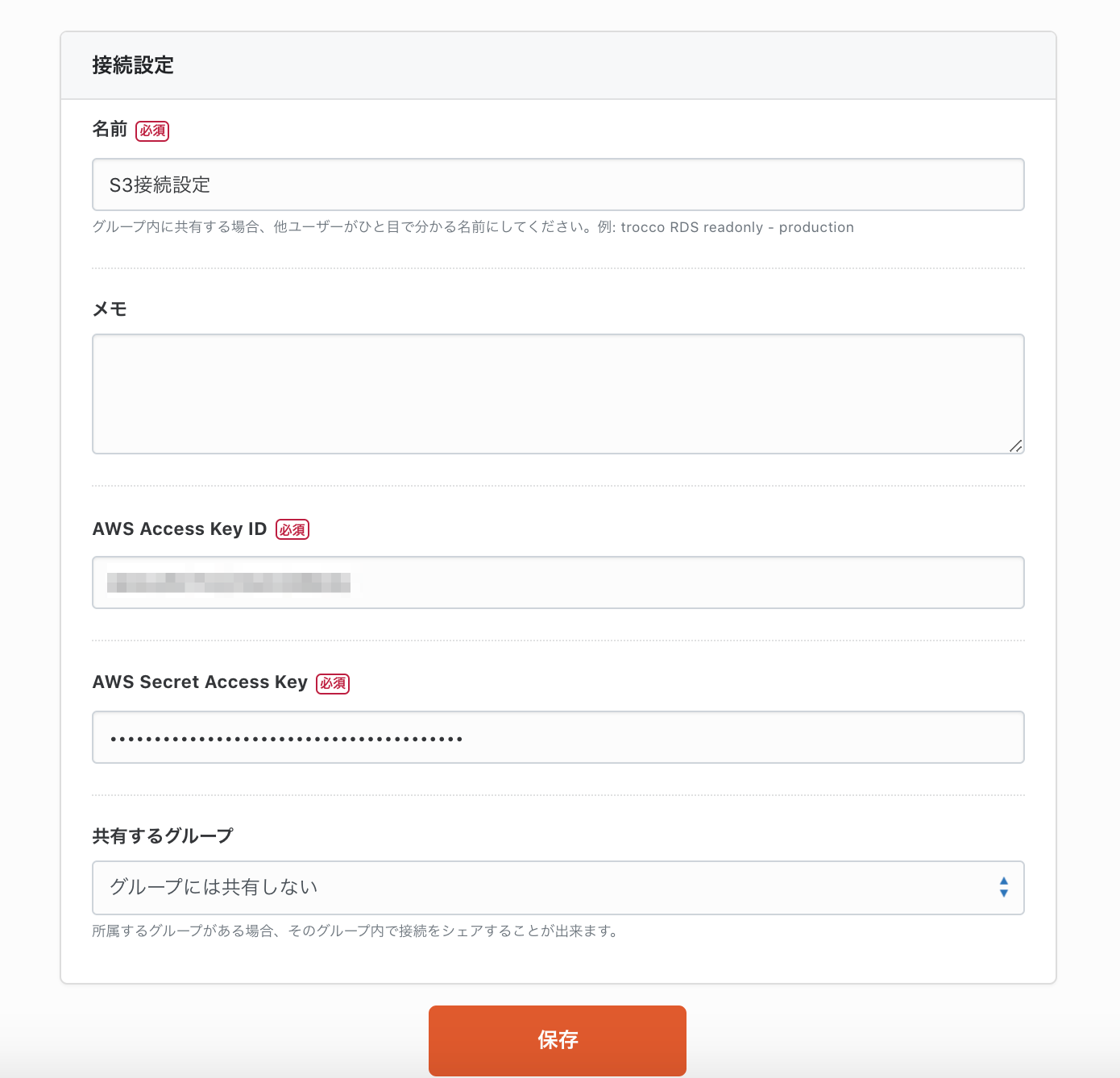
接続設定の名前・AWSのアクセスキーID・シークレットアクセスキーを入力して保存します。
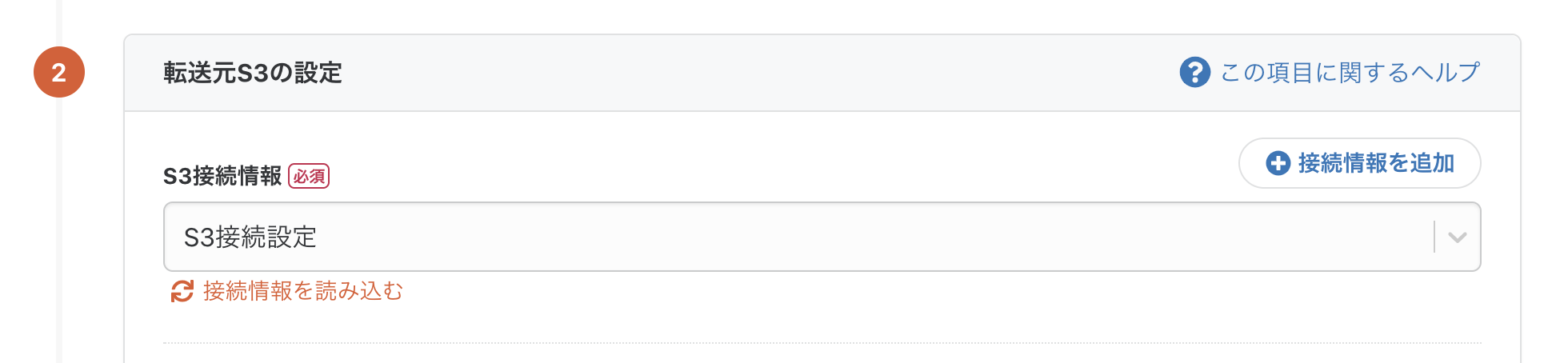
再度転送設定画面に戻り、「接続情報を読み込む」ボタンを押すと、作成した接続情報が選択できるかと思います。
2-3. S3からのデータ抽出設定
これでS3との連携は完了です。
次に、S3の取得データを設定します。
まずは必須項目の「リージョン」「バケット」をセレクトボックスの中から選択します。
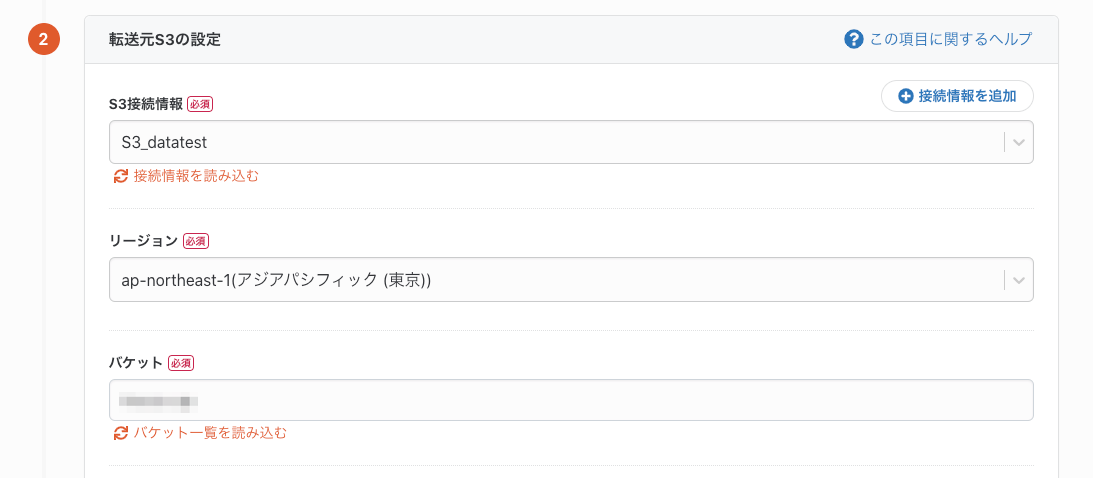
次に、パスプレフィックスやファイル形式などの項目を必要に応じて埋めていきます。
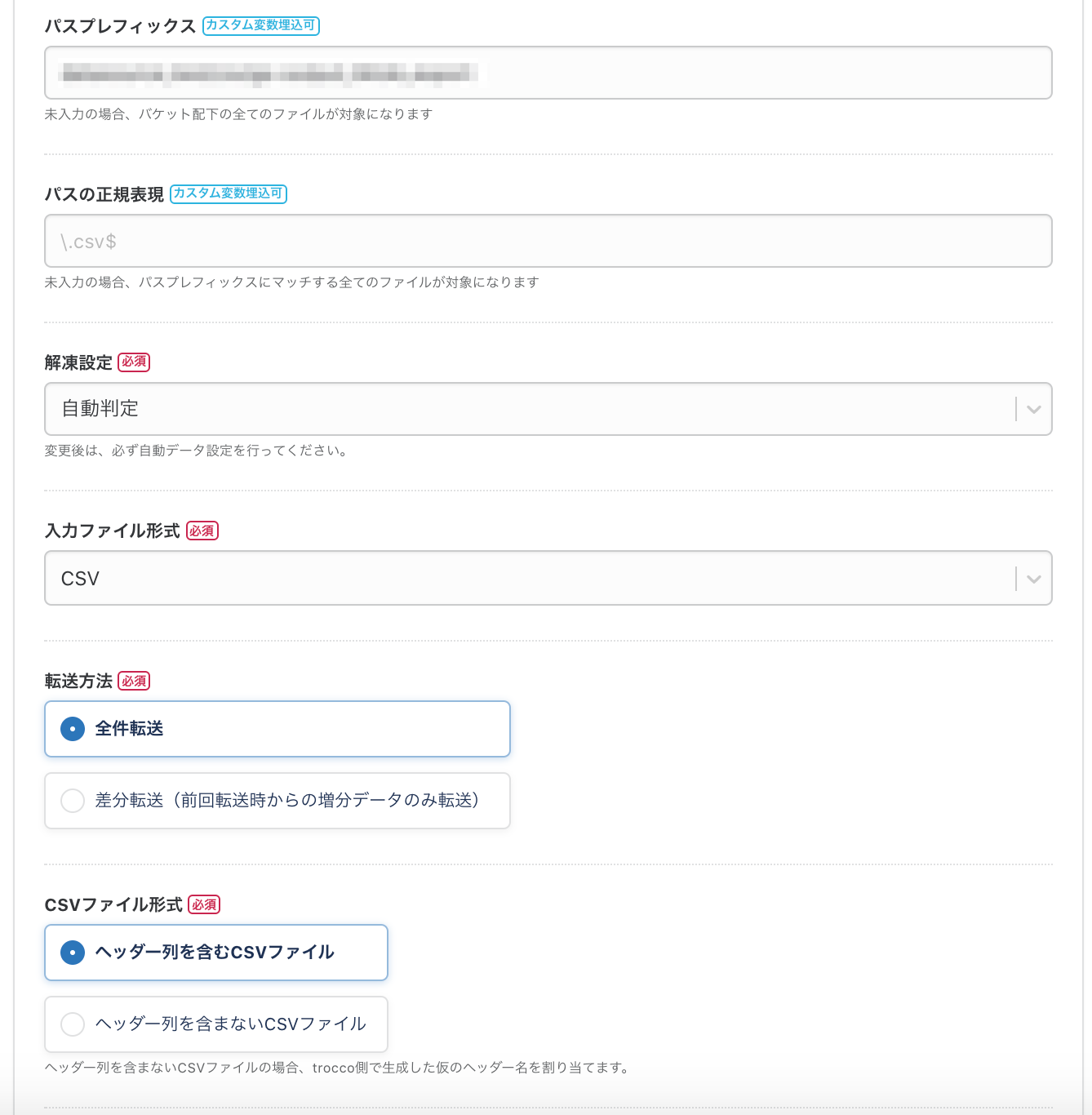
最後に接続確認が通るか確認します。
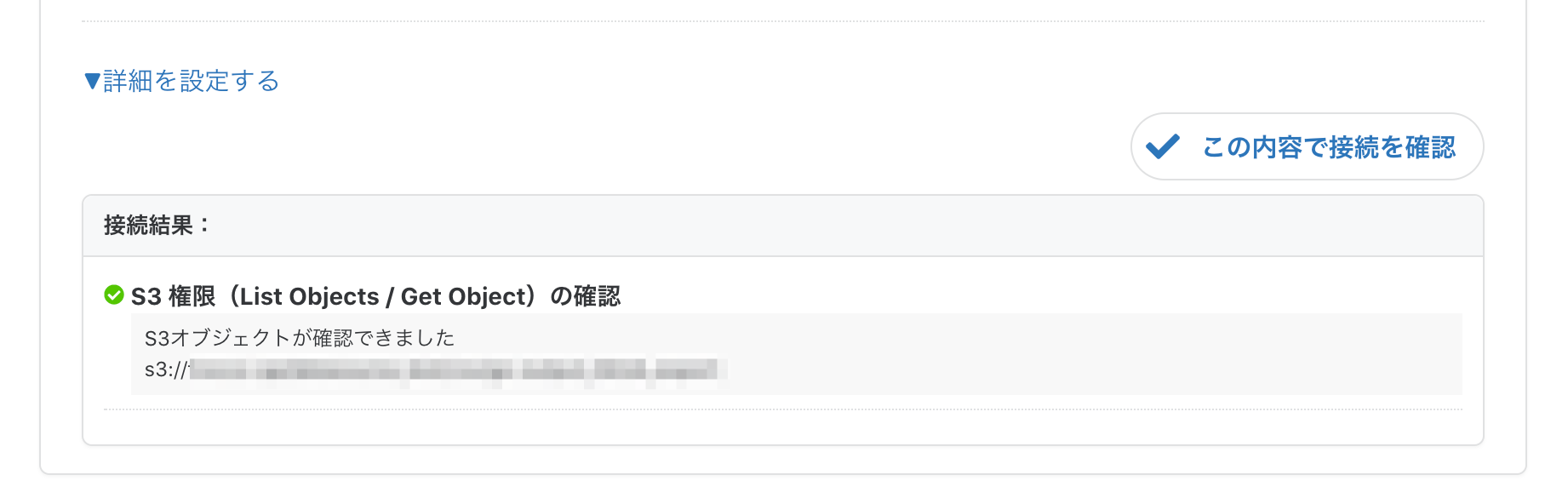
大丈夫ですね。以上でS3側の設定は完了です。
次は転送先のRedshiftの設定を行っていきましょう。
2-4. 転送先Redshiftの設定
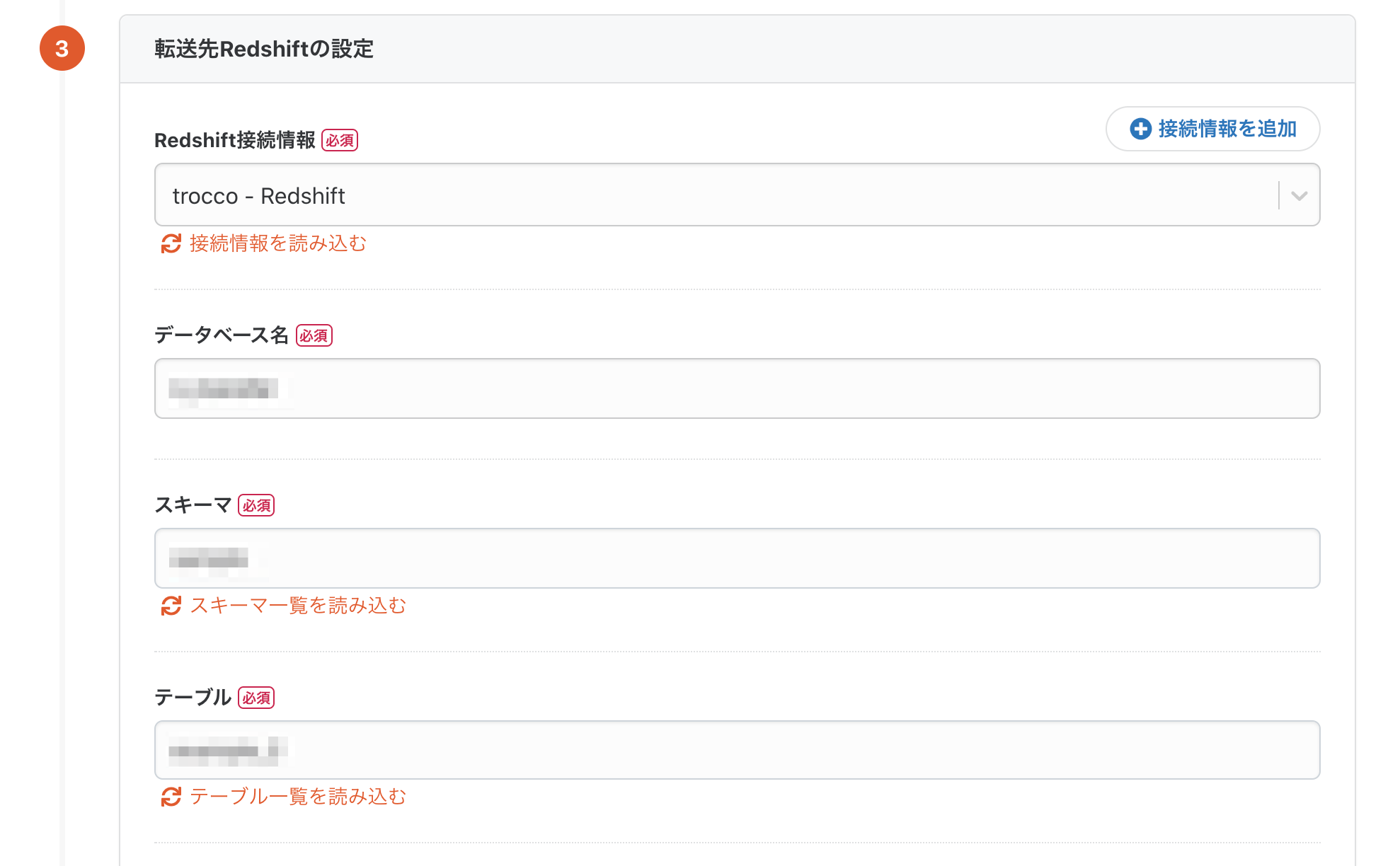
基本的には転送元と同じ要領です。
「接続情報を追加」ボタンからRedshiftの接続設定を行い、データベース・スキーマ・テーブルを入力します。
troccoでは一時データの保存にS3を利用するため、S3パケット・S3キープレフィックス・転送モードも必須項目です。これらも入力します。
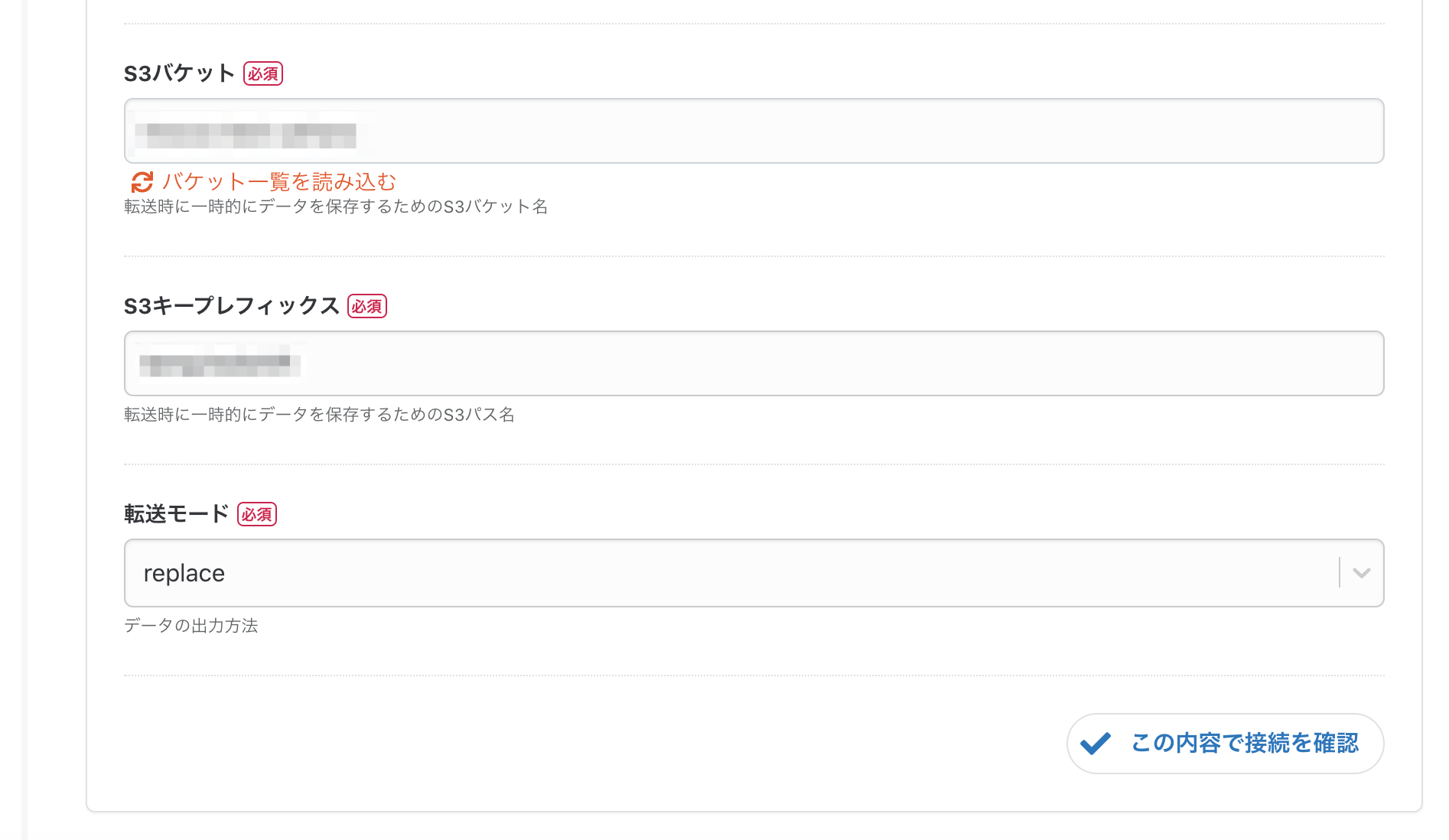
最後に、接続確認が問題なく通るか確認します。

これで入力は完了です。「保存して自動データ設定・プレビューへ」をクリックし、確認作業に進みましょう。
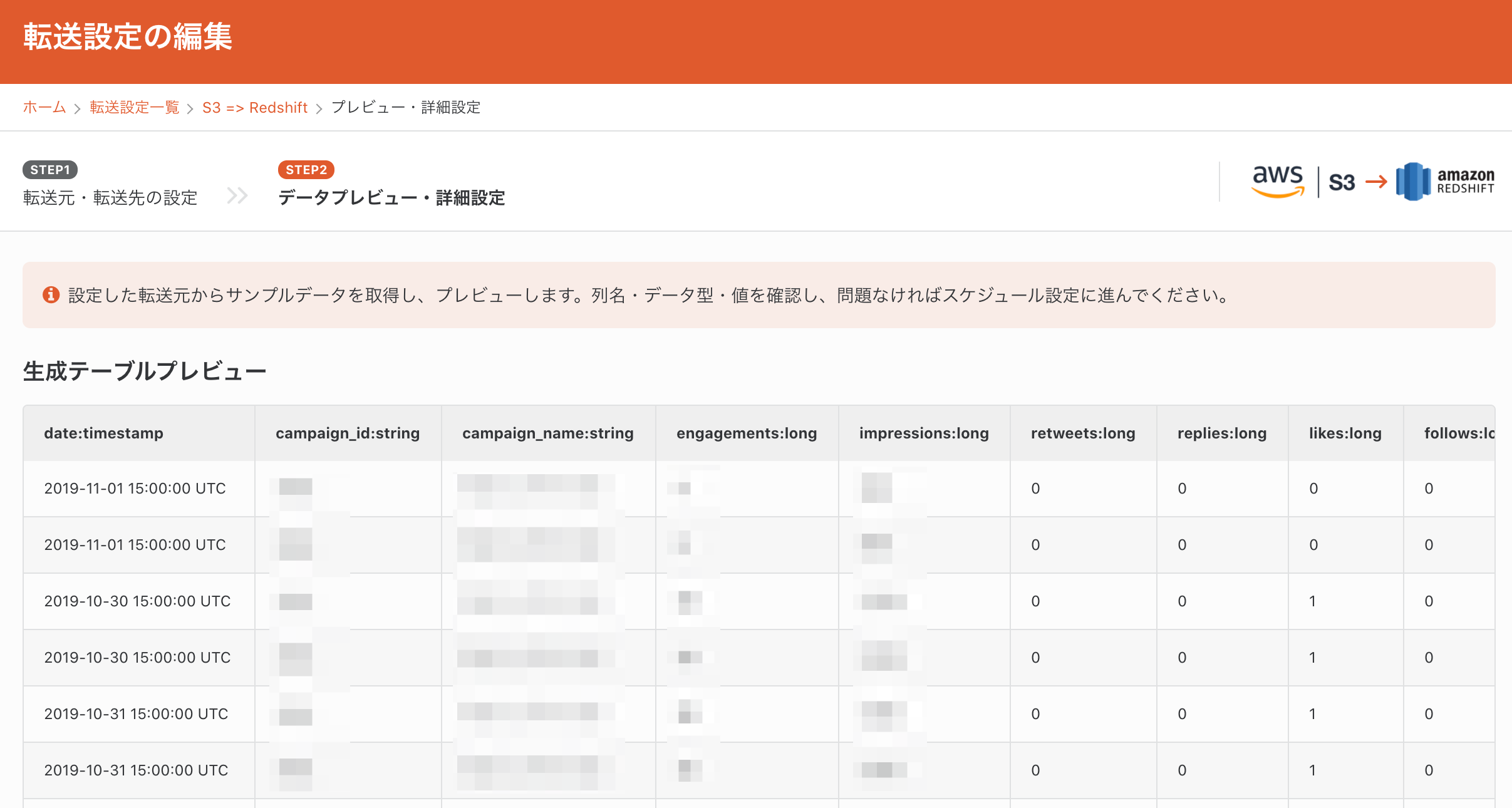
2-5. データのプレビュー
少し待つと、転送元のデータがプレビューされます。S3から取り込んだデータが表示されているのが確認できると思います。
問題なければ、「設定を完了する」を押して、スケジュールや通知設定に進みます。
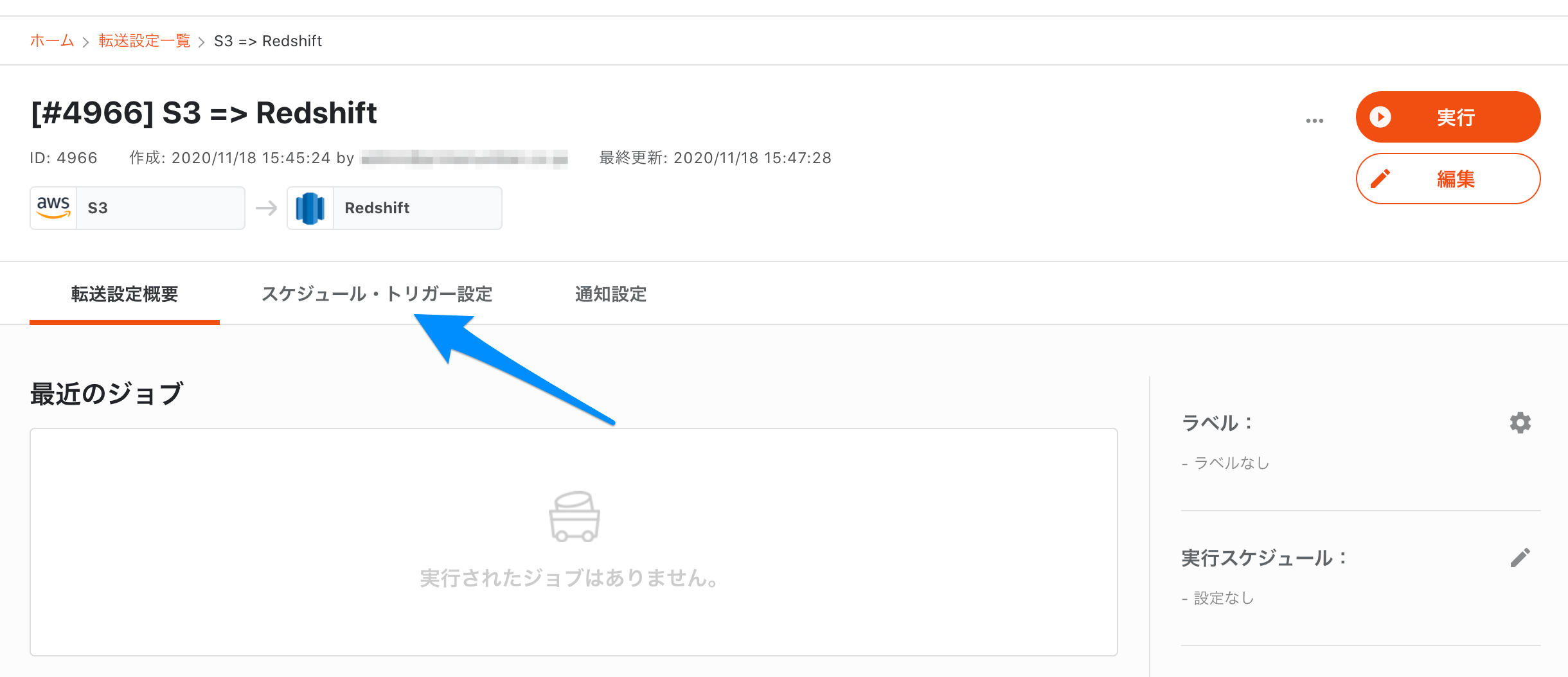
2-6. スケジュール設定
「スケジュール・トリガー設定」タブを開きます。
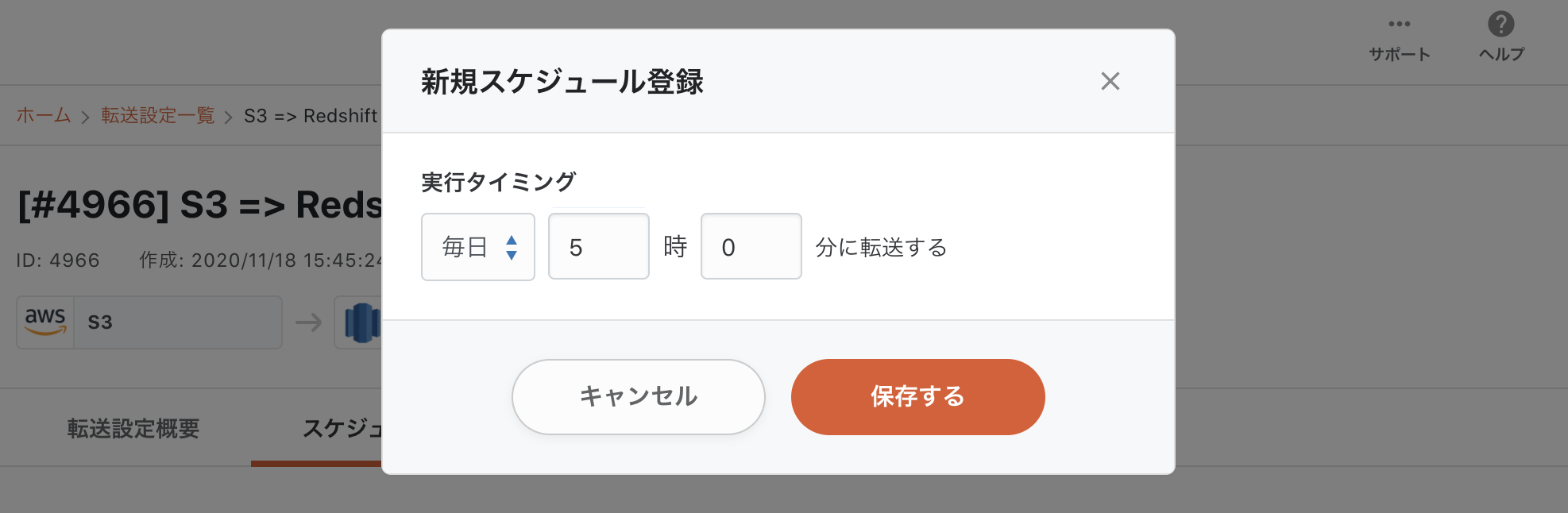
以下のように実行スケジュールを設定することで、転送を自動化することが出来ます。
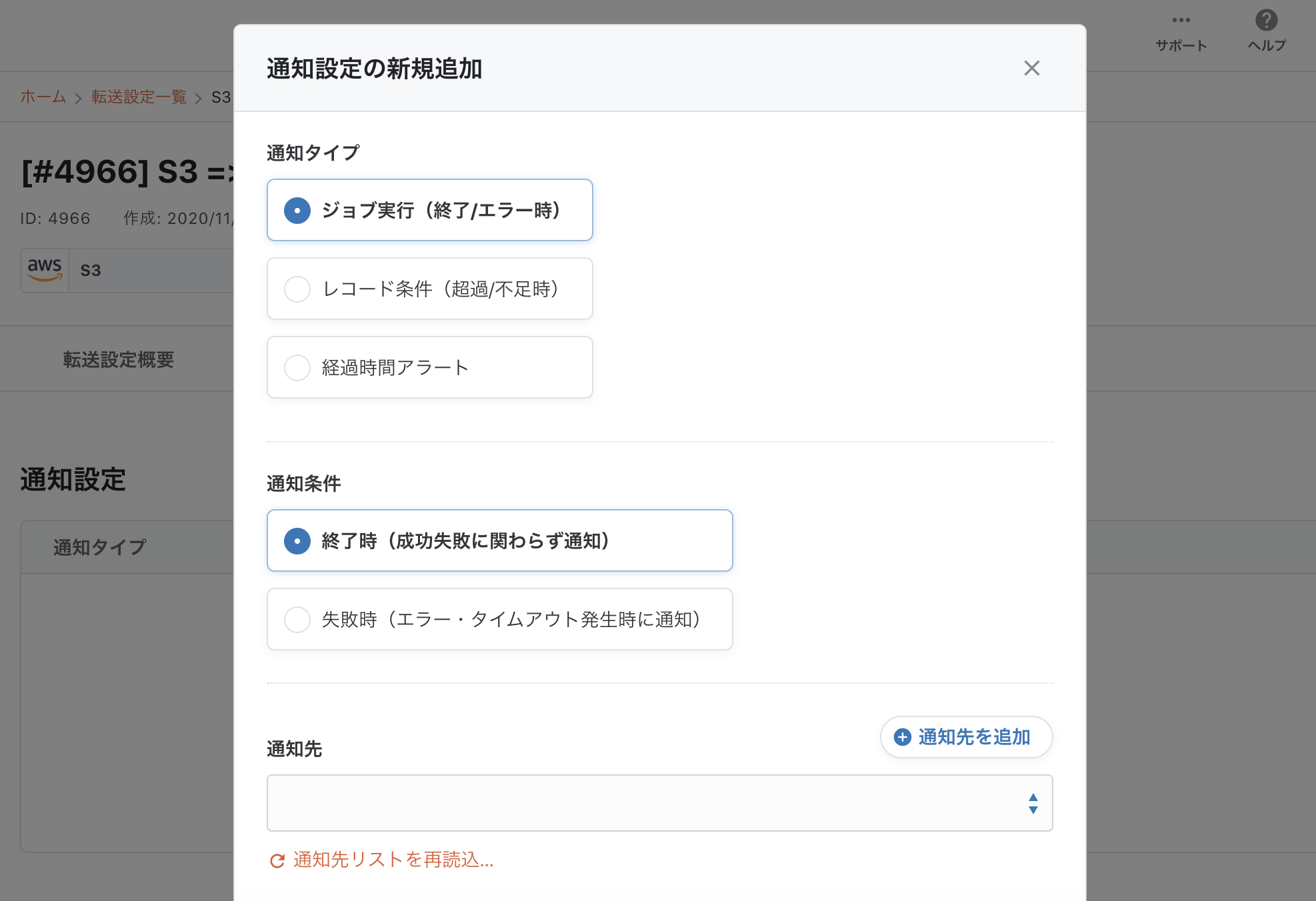
2-7. 通知設定
必須の設定ではないですが、通知タイプ・通知条件・通知先を選択し設定を保存することで、EmailやSlackに通知を行うことが出来ます。
ジョブ失敗時だけでなく、転送レコード数を条件に指定し、レコードが少な過ぎた時にアラートを出すといったことが可能です。
また、必要な時のみ実行したい場合は、手動で転送を実行することも出来ます。
その場合は、転送設定詳細の「実行」ボタンを押して進めていきます。
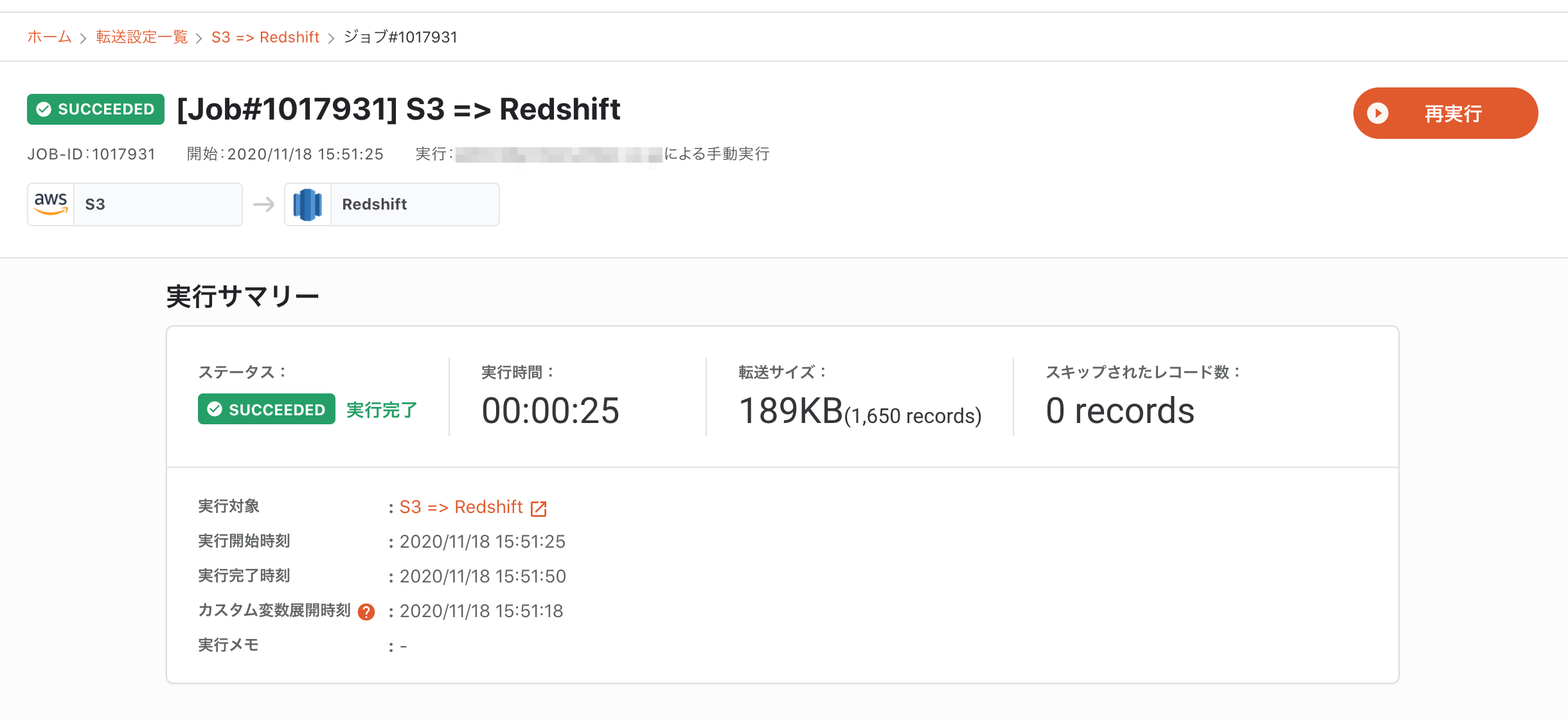
転送が完了しました。
3. Redshiftの設定
特に設定することはありません。データが溜まっているので、今すぐに分析・可視化を行うことが出来ます。
データをプレビューして確認してみます。

広告データがRedshiftに同期されていることが確認できました。
4. Lookerで可視化
それでは、これらのデータをLookerで分析してみます。
まずはRedshiftとLookerを接続します。
管理タブを開いて「Database」の「Connections」を開きます。
接続しているデータベース一覧が表示されています。ここで「Add Connection」→「Database Connection」から接続するデータベース情報を入力します。


Redshiftのデータベースに接続できたら、次はデータを可視化するために必要なLookMLプロジェクトを作成します。
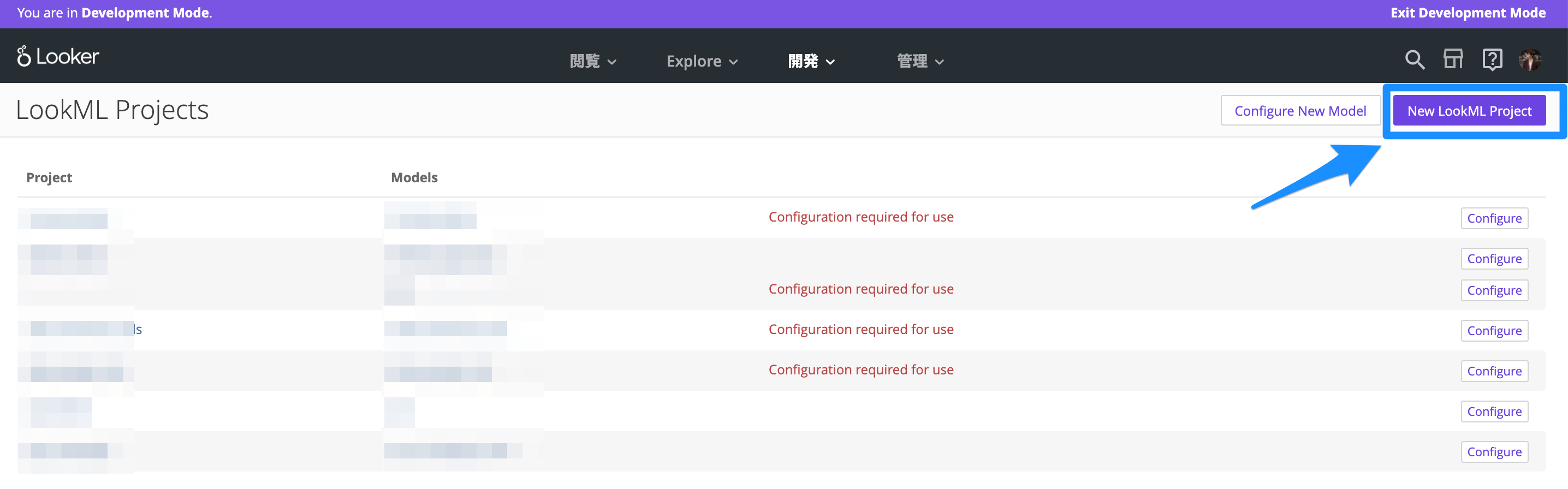
開発タブを開いて「LookMLプロジェクトの管理」に移動します。
「New LookML Project」からLookMLプロジェクトを作成します。
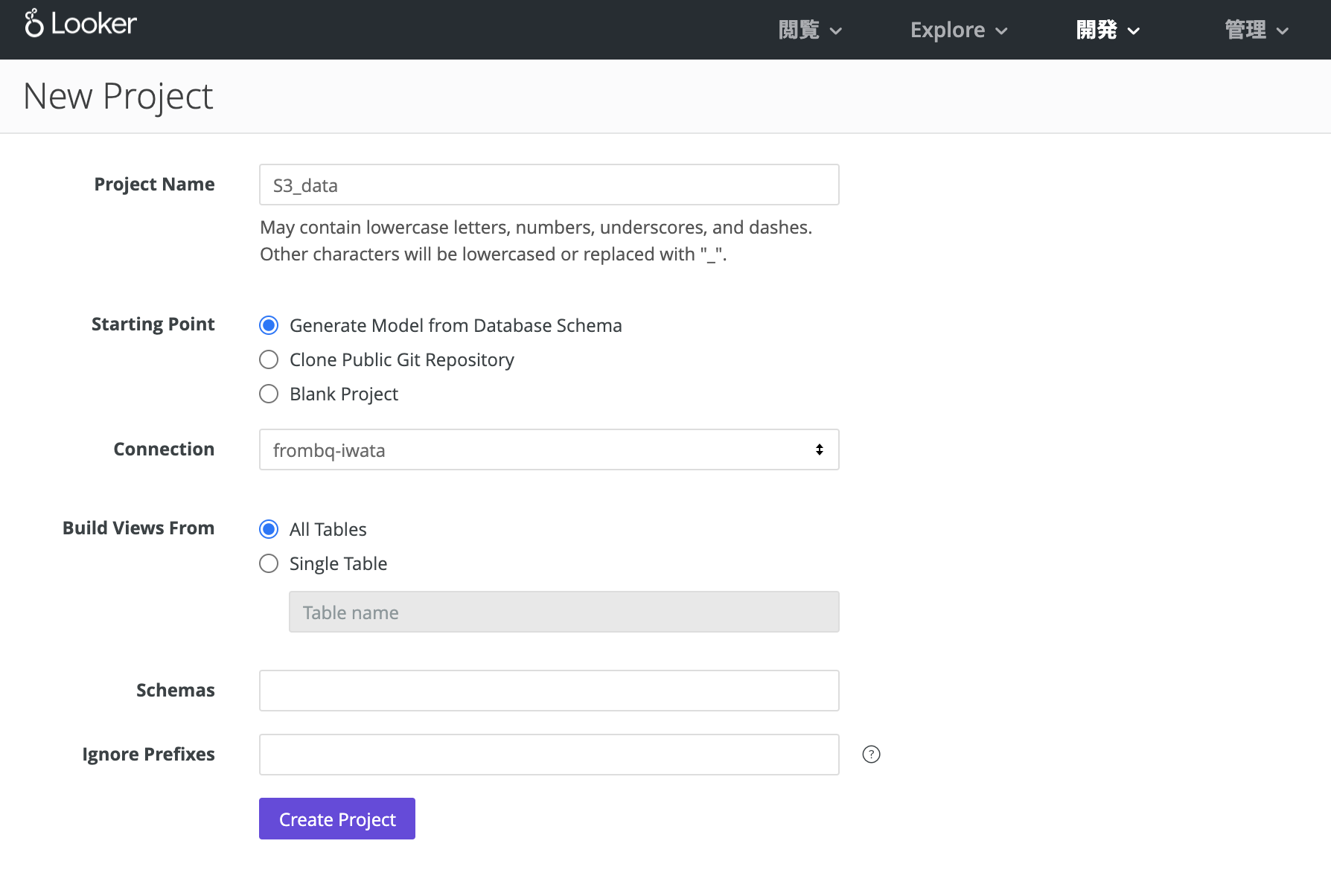
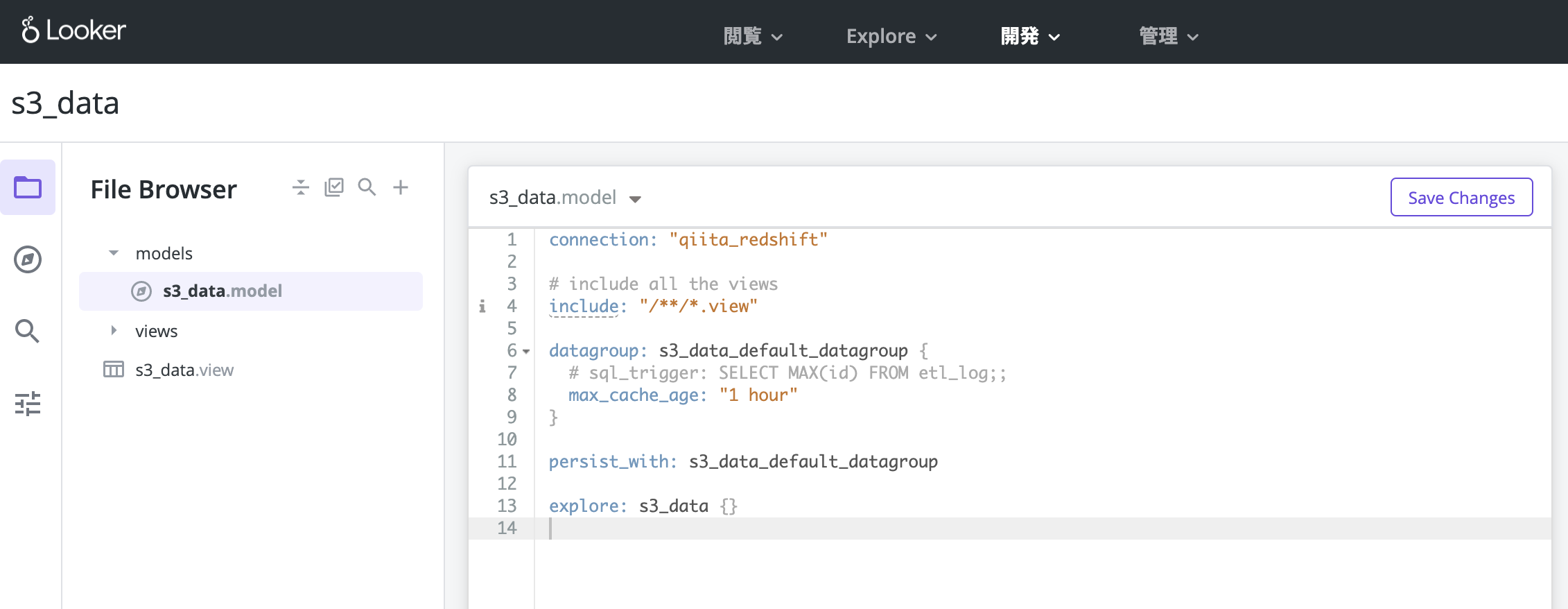
「Create Project」を押したら、エディタでmodelとviewを定義します。
後々必要になるので、modelの中ではexploreを設定しておきましょう。
(書き方が分からない場合はLookerの公式ドキュメントを参照してください)
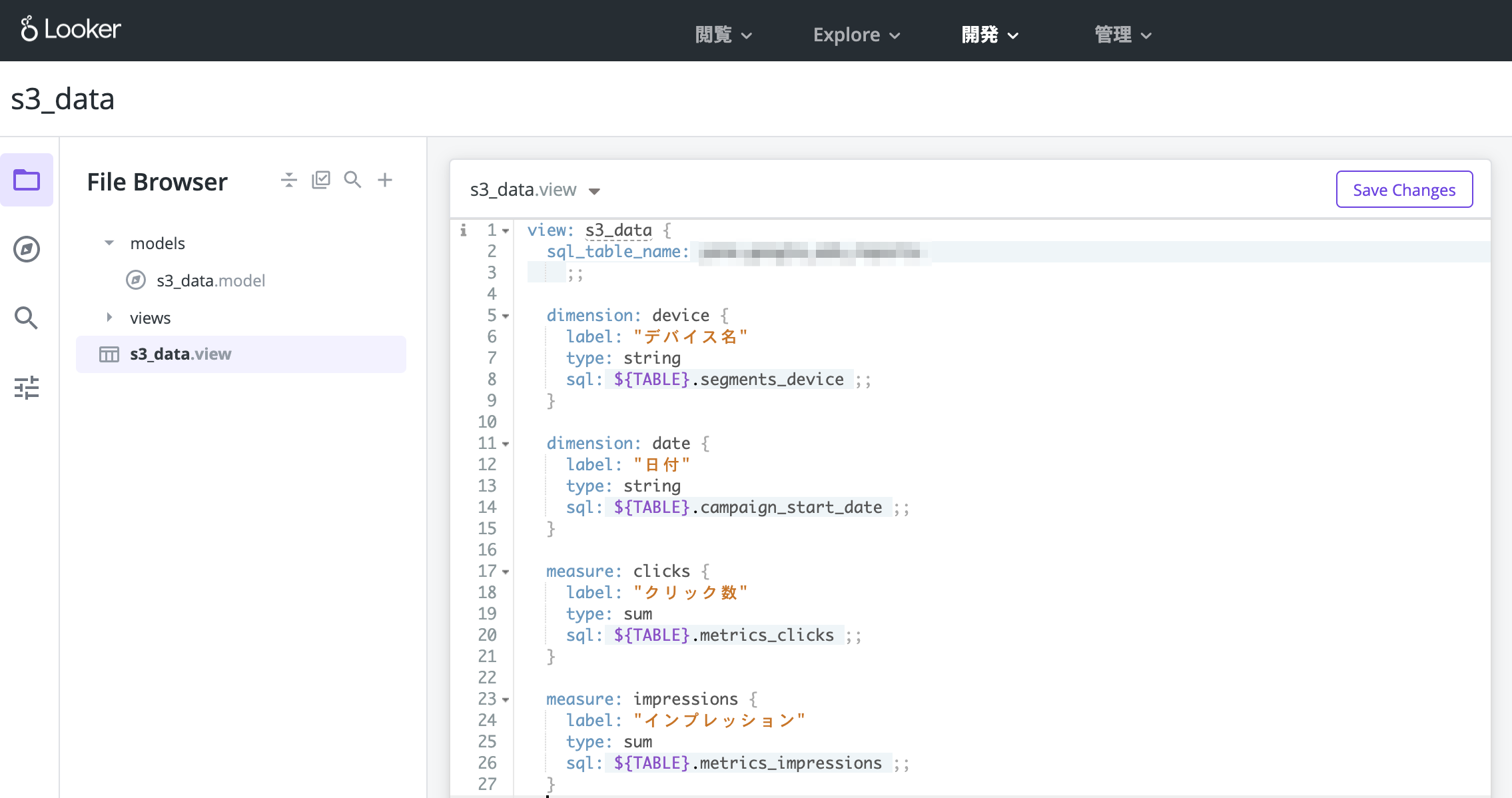
これで下準備が整いました。
トップページに戻って「New」からDashboardを作成します。

白紙のダッシュボードができました。ここに各種グラフを追加していきます。「新しいTILE」を押します。
先ほどのmodel内で定義したExploreを選択します。
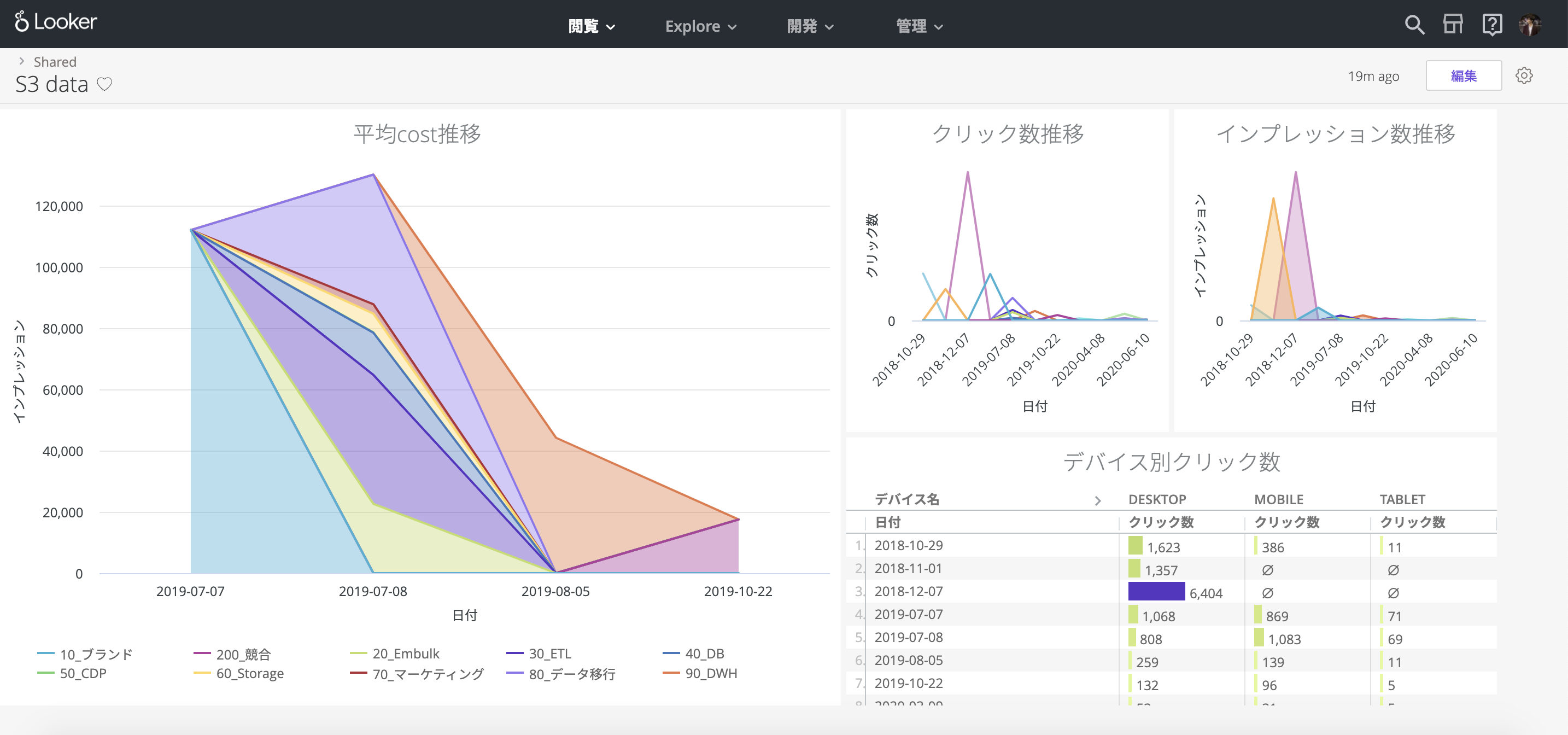
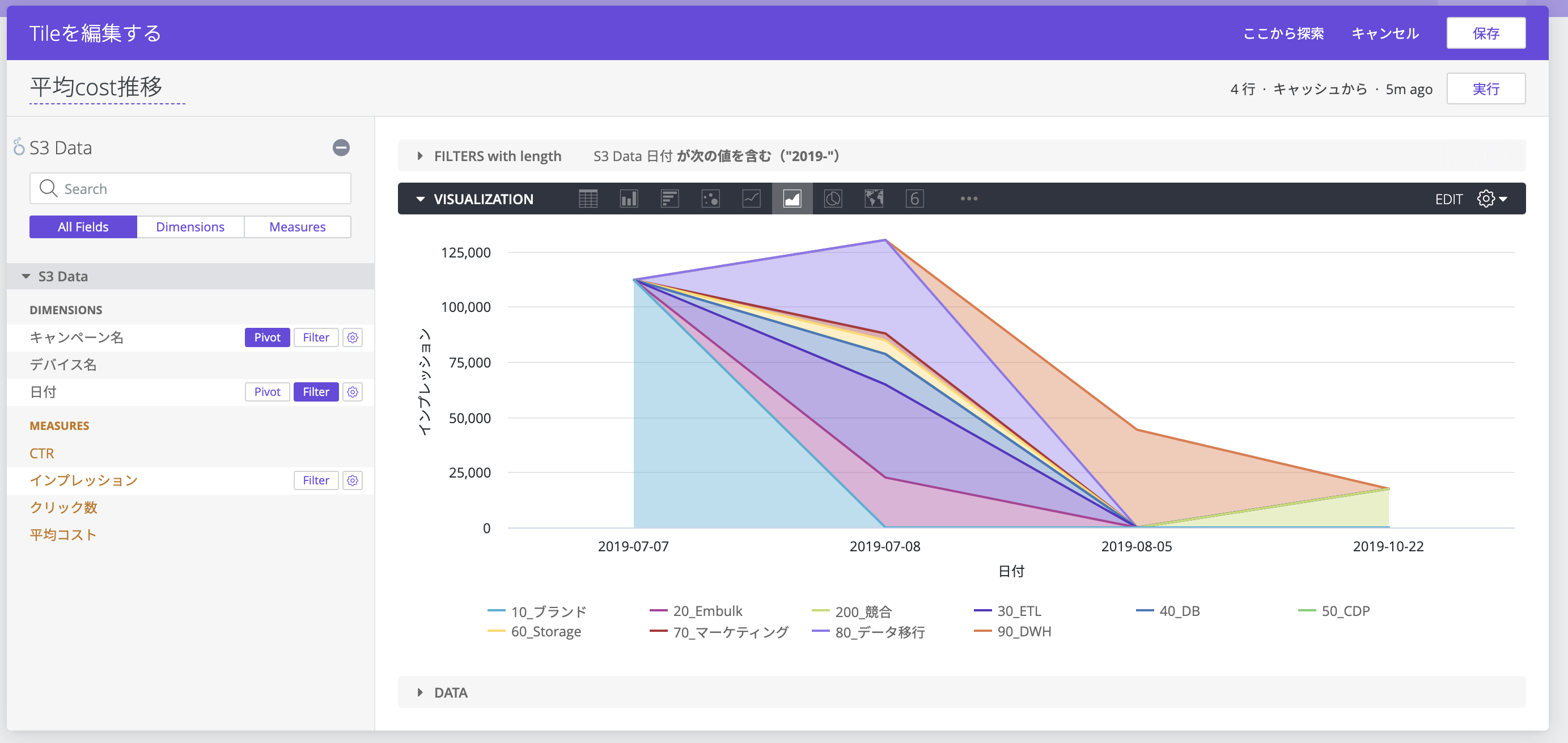
DIMENSIONSとMEASURESを設定し、Tileに表示したいデータをプロットします。ここではキャンペーンごとのクリック数を分析しています。
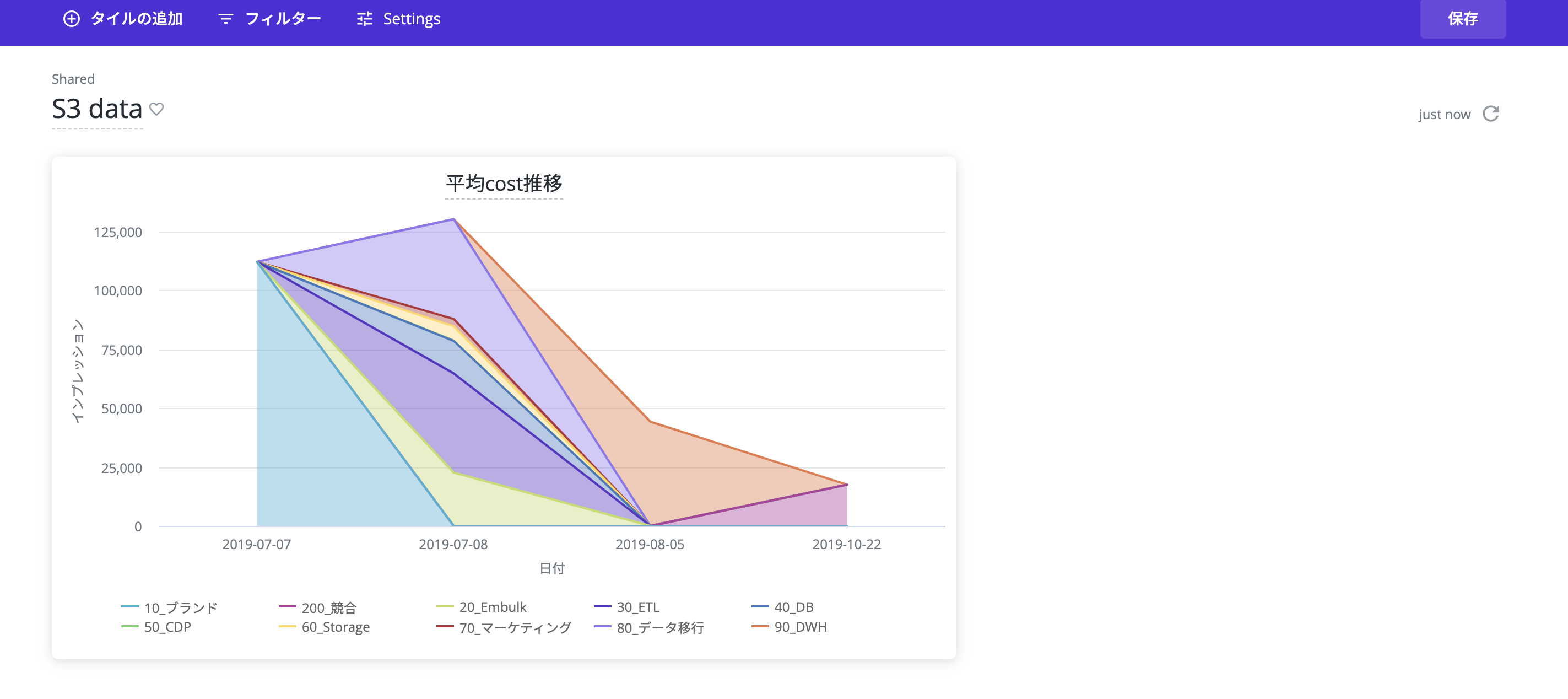
これで一つTileが完成しました。この調子で他のTileも作成すると、今回のゴールであるデータダッシュボードが出来上がります。
まとめ
いかがでしたでしょうか。troccoを使うとコーディング・環境構築を行うこと無く、簡単にS3のデータをDWH(Redshift)に貯めることが出来ました。
また、Redshiftにデータを貯めると、Lookerを使ってデータを可視化することが出来ます。
実際に弊社サービスのtroccoにおいても、マーケティングKPI等をこのような流れで収集・分析しています。
ぜひ広告データ分析の際にはご活用ください。
試してみたい場合は、無料トライアルを実施しているので、この機会にぜひ一度お試しください。
(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内できます)
その他にも様々な分析データをETL・転送した事例をまとめています。ご活用ください。
troccoの使い方まとめ(CRM・広告・データベース他)