
はじめに
前回記事で GiNZAに「国語研長単位モデル」を適用し、分かち書きしたデータをキーワードに原文検索を実行しました。
原文検索においては、キーワードの前後に現れる「周辺語」、2つのキーワードに紐づく「関連語」がわかると、よりテキスト理解の助けになります。
今回の記事は、この「周辺語」「関連語」の検索をWord2Vecで実行した記事です。
実行したこと
以下、以前の記事で実行した内容です。
今回は「頻出語グラフ」や「共起ネットワーク」に表示された単語をキーワードに「周辺語」「関連語」の検索を行います。
「共起ネットワーク」実行までの内容は、以前の記事を確認いただくとして、以下は「周辺語」「関連語」検索の内容についてのみを触れるようにします。
「周辺語」「関連語」検索
以下は、今回対象としたテキスト処理後のデータフレームの一部を表示したものです。
左端の「テキスト」カラムが原文、右端のー「separate_words」カラムが分ち書きした結果となっています。

まず、テキスト処理を実行したいデータフレームカラムの指定です。
GoogleColabのフォーム機能を利用し、フォームにカラム名の入力することにより指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、’テキスト’と入力しています。
#@title 意見カラムの名称は? { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
以下は、「周辺語」「関連語」検索を実行するコードです。
先の通り、df['separate_words']には、[’再エネ’,’原発再稼働’,’断念’・・・]等、行毎に分かち書きした結果が格納されています。
キーワードは 2つ設定できるようにしました。
- 指定したキーワードの前後に現れる「周辺語」を表示しています。(表示数指定可)
- 指定した2つのキーワードに紐づく「関連語」を表示しています。
#@title Keyword 前後に現れる **周辺語**、Keywordsから予想される **関連語** を表示
#@markdown **<font color= "Crimson">ガイド</font>:Number_of_serch_words_shown で 結果表示数を設定し、Keyword_A,B にキーワードを入力して実行してください。※入力するキーワードは、WordCloudや共起ネットワークに表示される単語表記としてください。**</font>
#@markdown **<font color= "Crimson">※入力するキーワードは、WordCloud や 共起ネットワーク に表示される単語の表記としてください。**</font>
Number_of_serch_words_shown = 7 #@param {type:"slider", min:5, max:15, step:1}
Keyword_A = '再エネ賦課金やめる' #@param {type:"raw"}
Keyword_B = '政府' #@param {type:"raw"}
from gensim.models import word2vec
import warnings
warnings.filterwarnings('ignore')
# size : 中間層のニューロン数・数値に応じて配列の大きさが変わる。数値が多いほど精度が良くなりやすいが、処理が重くなる。
# min_count : この値以下の出現回数の単語を無視
# window : 対象単語を中心とした前後の単語数
# iter : epochs数
# sg : skip-gramを使うかどうか 0:CBOW 1:skip-gram
import os
import hashlib
os.environ["PYTHONHASHSEED"] = "0"
def hashfxn(x):
return int(hashlib.md5(str(x).encode()).hexdigest(), 16)
#Keyword_A
model_ = word2vec.Word2Vec(df['separate_words'],
size=100,#alpha=0.025,
min_count=3,workers=1,
window=5,seed=42,
iter=20,batch_words=1000,hashfxn=hashfxn,
sg = 1) # sg=1:skip-gram使用
#ベクトル化したテキストの各語彙確認
#model_.wv.index2word
print('\n')
print('● [', Keyword_A,'] の前後に現れる 周辺語')
print('\n')
try:
for item, value in model_.wv.most_similar(positive=[Keyword_A], topn=Number_of_serch_words_shown):
print('\t✓',item, '\t',str("{:.2f}".format(value)))
except:
pass
print('\n')
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
#Keyword_B
print('\n')
print('● [', Keyword_B,'] の前後に現れる 周辺語')
print('\n')
try:
for item, value in model_.wv.most_similar(positive=[Keyword_B], topn=Number_of_serch_words_shown):
print('\t✓',item, '\t',str("{:.2f}".format(value)))
except:
pass
print('\n')
print('---------------------------------------------------------------------------------------------------------------------------------------------------------------')
#Keyword_A+B
model = word2vec.Word2Vec(df['separate_words'],
size=100,#alpha=0.025,
min_count=3,workers=1,
window=5,seed=42,
iter=20,batch_words=1000,hashfxn=hashfxn,
sg = 0) # sg=0:CBOW使用
print('\n')
print('● [', Keyword_A ,'] と [', Keyword_B ,'] に紐づく関連語')
print('\n')
try:
for item, value in model.wv.most_similar(positive=[Keyword_A,Keyword_B], topn=Number_of_serch_words_shown):
print('\t✓',item, '\t',str("{:.2f}".format(value)))
except:
pass
print('\n')
※smaller 'batch_words' というメッセージが出ていましたので、batch_words=1000 を追加。
※結果再現性確保コード追加。
※異常キーワード入力時は処理をスルー。
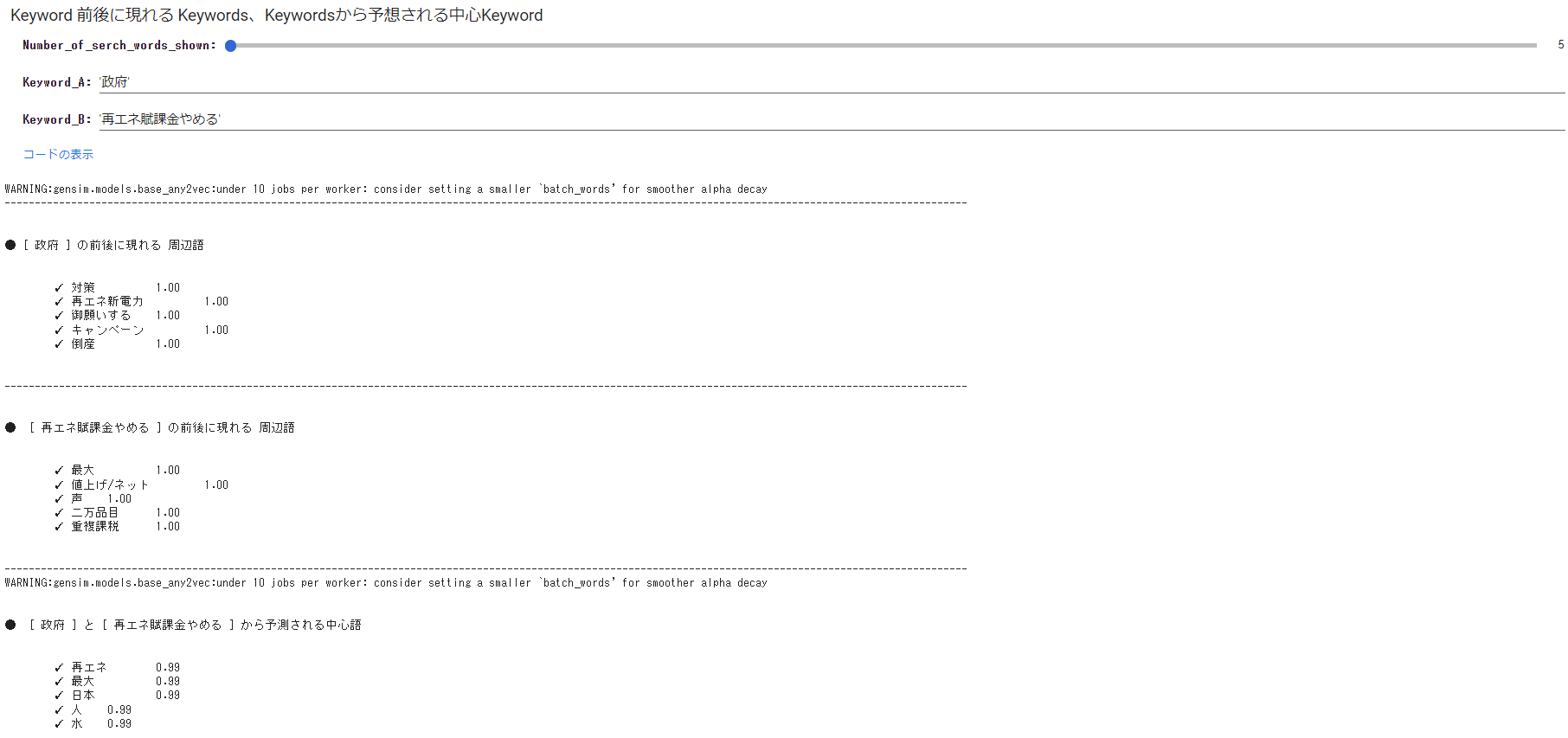
最後に
「政府」をキーワードに周辺語を探ると「倒産」「声」「対策」「焼け石」「再エネ新電力」「水」などが出てきました。
勝手想定ですが、”再エネ新電力の倒産が相次ぎ、政府の対策は焼け石に水”・・・といったところでしょうか。
ここでの「水」とはなんでしょう?
原文検索すると、
- 「佐賀県でマイクロ水力発電が稼働しました。水道管を流れる水で水車を回し発電。。。」
- 「自然破壊しまくり中国パネルだらけで将来産廃の山になり死んだ土地となる?土壌は崩壊され水も汚される」
- 「電気料金値上げに「焼け石に水」政府のポイント付与まずは年1万2000円超の「再エネ賦課金やめろ」の声」
などがありました。
「再エネ賦課金やめる」をキーワードに周辺語を探ると「値上げ/ネット」「重複課税」「 ガソリン」などが出てきました。
こちらは電気代やガソリン値上げによる負担と重複課税に対する不満が垣間見えます。
「政府」「再エネ賦課金やめる」をキーワードに紐づく関連語を探ると「再エネ」「日本」「脱炭素」「考える」などが出てきました。
ここでの「水」とはなんでしょう?
脱炭素で原文検索すると、
- 報道では「脱炭素の切り札」という言葉が頻繁に使われるけれど、(中略)再エネも原発も蓄電池もEVも送電網の強化も省エネも水素も炭素回収も全部必要になる。
- ロシアは石油やガスが高騰しているから大儲け(中略)ドイツは脱炭素、再エネ100%やなかったんや。これが国際政治の現実だ。日本はタダの金儲けのダシよ。風力発電に騙されたらアカン
- 原発政策への回帰は再エネ事業を通じた敵国の侵略を防ぐ事に繋がる。原発再稼働は日本を取り戻すためにも必要である。
- 「脱炭素」は嘘だらけ杉山大志2050年にCO2をゼロにしようとするとコストは国家予算に匹敵するものになる。これは実行不可能であり、(中略)イノベーションによってコストが低減することが大前提である。
- 北海道の再エネから首都圏に電気を送る「海底送電線」敷設へコストをかけてリスクを増やす「脱炭素」の愚
- SDGS、脱炭素、再生可能エネルギー、グローバリズムなど外国からの主義主張を真面目に取り入れてるのは日本だけ⁉️
このように、原文検索と組み合わせて実行すると、テキスト理解の助けになりそうです。
word2vecは動作もサクサク(データ数に依存すると思います)と軽快なので、いい感じです。
参考