2022/10/01 国語研長単位がVer2.9→3.2にVer.upし、コード記述変更しないとインストールできなくなったのでpip変更/なぜかnlplotの共起ネットワークが以前のコードでは描画されなくなったので、コード変更
2022/09/02 nanデータがあるとエラーが出るので、前処理前にドロップを追加

はじめに
自然言語処理は、もっぱらmecabさんのお世話になっていましたが、GiNZA推しの テキストアナリティクス入門 を読んで以降、遅ればせながら「これからはGiNZA」と心に誓っております。
「GiNZA」は、巷では以下のように説明されています。
”自然言語処理ライブラリ「spaCy」をフレームワークとして・・・オープンソース形態素解析器「SudachiPy」を内部に組み込み、「GiNZA日本語UDモデル」も利用可能・・・”
・・・なかなかどうして、ライブラリやモデルがいろいろ出てきて少しややこしいので、説明を見てスルーしてしまっていた方も多いのではないでしょうか?
GiNZAって何? というのは、以下のリクルートの記事を読むと何となく理解できます。
ざっくり要約させていただくと、
- 従来の日本語の自然言語処理は、エンジニア自身が形態素解析・文節係り受け解析など複数機能ライブラリを組み込み、統合=敷居が高い、日本語の自然言語処理技術=形態素解析によるアプローチが中心 という課題あった。
- そこで、自然言語処理の応用の容易化を目指し、Megagon Labsが公開した日本語自然言語処理のソースライブラリが「GiNZA」。同じく公開されている国立国語研究所との共同研究成果である日本語テキストを高精度で解析できる「GiNZA日本語Universal Dependenciesモデル」も利用できるってことで、使うっきゃない。
先に申し上げると、むつかしいことはよくわからなくても大丈夫です。
GiNZAは、所定のライブラリをインストールすれば、だれでも実行でき 「簡単に使えて、高い精度も得られる」 というものなので、日本語の自然言語処理がしたいという方は、ぜひGiNZAを!ということで、この記事では GiNZA適用事例 をアップしたいと思います。
GiNZAを使ってみたいと思える内容になっているかはわかりませんが、記事の内容は GiNZAに「国語研長単位モデル」を適用し、テキスト処理した単語を「自然言語可視化ライブラリ NLPLOT」に与えて、頻出語グラフと共起ネットワークを描いてみる という内容です。
実行したこと
GoogleColabで実行するためのライブラリのインストール
以下のライブラリや辞書をインストールしました。
!pip install sudachipy sudachidict_core
!pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
#!pip install ja_gsdluw deplacy -f https://github.com/megagonlabs/UD_Japanese-GSD/releases/tag/r2.9-NE
!pip install https://github.com/megagonlabs/UD_Japanese-GSD/releases/download/r2.9-NE/ja_gsdluw-3.2.0-py3-none-any.whl
!pip install pyyaml==5.4.1
pyyamlもGiNZAのVer.指定インストールについては、以下の記事を参考にさせていただきました。
import pkg_resources, imp
imp.reload(pkg_resources)
このおまじないがないと、pyyamlもGiNZAもインストール後にランタイムの再起動が求められますが、このおまじないの実行により、インストールするだけ(=ランタイムの再起動は不要)になります。
pip install nlplot
pip install pyvis
!apt-get -y install fonts-ipafont-gothic
データ読込み
まず、データの読込みです。
データの読込みにおいては、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','Upload']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
import pandas as pd
from google.colab import files
# データの読み込み
if dataset =='Upload':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
display(df)

次に、テキスト処理するカラムを指定します。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラムの名称は? { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
テキスト処理
つぎは、テキスト処理です。
テキストから不要語を取りのぞく前処理を行った後、テキスト処理を実行して単語に分解、指定した品詞の単語を取り出し、stop_wordsに指定した単語があれば除外します。
その後、行毎に取り出した単語をデータフレームに格納しています。
品詞とstop_wordsの指定は、GoogleColabのフォーム機能を利用しています。
フォーム機能を利用するとコード操作が不要となりますので、とても便利です。
#@title 使用する品詞とストップワードの指定
#@markdown ※include_pos:使用する品詞,stopwords:表示させない単語 ← それぞれ任意に追加と削除が可能
include_pos = ('NOUN', 'PROPN', 'VERB', 'ADJ')#@param {type:"raw"}
stop_words = ('する', 'ある', 'ない', 'いう', 'もの', 'こと', 'よう', 'なる', 'ほう', 'いる', 'くる', 'お', 'つ', 'とき','ところ', '為', '他', '物', '時', '中', '方', '目', '回', '事', '点', 'ため') #@param {type:"raw"}
#@title テキスト処理実行
import spacy
import pandas as pd
import re
# 意見に空行がある場合は削除
df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
df.dropna(subset=[column_name], inplace=True)
# テキストデータの前処理
def text_preprocessing(text):
# 改行コード、タブ、スペース削除
text = ''.join(text.split())
# URLの削除
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', text)
# メンション除去
text = re.sub(r'@([A-Za-z0-9_]+)', '', text)
# 記号の削除
text = re.sub(r'[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥]', '', text)
return text
df[column_name] = df[column_name].map(text_preprocessing)
#モデルをja_gsdluw(国語研長単位)に
nlp = spacy.load("ja_gsdluw")
# 行毎に出現する単語をリストに追加
words_list=[] #行毎の単語リスト
for doc in nlp.pipe(df[column_name]):
sep_word=[token.lemma_ for token in doc if token.pos_ in include_pos and token.lemma_ not in stop_words]
words_list.append(sep_word)
#print(word_list)
#行毎の意見 → 単語に分解し、カラムに格納
df['separate_words']= [s for s in words_list]
# 参考:対象カラムに形態素解析実行、すべての形態素結果をseparateカラムに格納
#df['separate'] = [list(nlp(s)) for s in df[column_name]
以下は、テキスト処理を実行した後のデータフレームです。
左端の「テキスト」が元tweet。右端の「separate_words」が分かち書きした結果です。
指定した品詞のみ、長単位で処理された単語をリスト形式で格納しています。
先頭行データ「バカなやつだな・・・高く・・・」⇒「ばか,奴・・・高い・・・」と処理されています。
バカ→ばか、やつ→奴、高く→高い 等、単語抽出だけではなく、表記統一が図られていることがわかります。

NLPLOTによる頻出語グラフ
次に、頻出単語のグラフ化です。
これはNLPLOT で描かせています。
表示する頻出語数はスライドバーで変更できるようにしています。(GoogleColabのフォーム機能)
#@title NLPLOTによる頻出語グラフ
Number_of_words_shown = 30 #@param {type:"slider", min:20, max:50, step:1}
import nlplot
npt = nlplot.NLPlot(df, target_col='separate_words')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定できる
#stopwords = npt.get_stopword(top_n=0, min_freq=0)
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=Number_of_words_shown,
#stopwords=stopwords,
)

共起ネットワーク
最後に、共起ネットワークです。
これもNLPLOTで描かせています。
NLPLOT の共起ネットワークは、min_edge_frequencyでプロットするノードの数を制限することができます。(指定数以下のエッジ(辺)しか存在しないノードはプロット対象から除外することができるとのこと)
GoogleColabのフォーム機能を利用し、min_edge_frequencyをスライドバーで変更できるようにしています。
#@title 共起ネットワーク
#@markdown **<font color= "Crimson">ガイド</font>:ネットワーク表示の濃淡は min_edge_frequency で変更できます。表示にみにくさを感じた場合は値を大きく、より細かく表示したい場合は値を小さくしてください。**
min_edge_frequency = 1 #@param {type:"slider", min:1, max:20, step:1}
import nlplot
import plotly
from plotly.subplots import make_subplots
from plotly.offline import iplot
npt = nlplot.NLPlot(df, target_col='separate_words')
npt.build_graph(
#stopwords=stopwords,
min_edge_frequency=min_edge_frequency)
# The number of nodes and edges to which this output is plotted.
# If this number is too large, plotting will take a long time, so adjust the [min_edge_frequency] well.
# >> node_size:70, edge_size:166
fig_co_network = npt.co_network(
title='Co-occurrence network',
sizing=100,
node_size='adjacency_frequency',
color_palette='hls',
width=1100,
height=700,
save=False
)
iplot(fig_co_network)
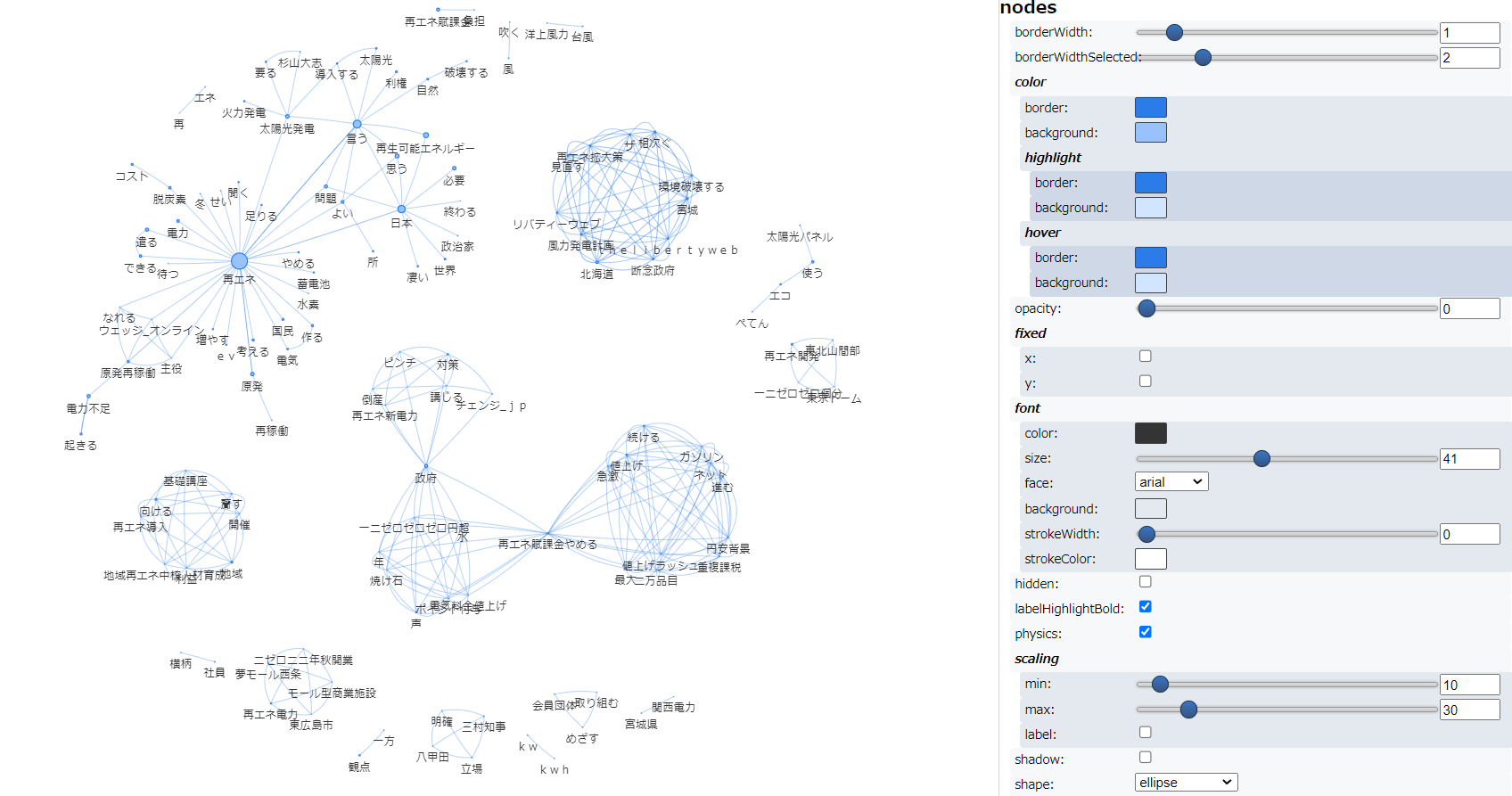
以下は、min_edge_frequency = 2 で実行したのネットワーク図です。ノードの色は、networkxのcommunitiesで計算したコミュニティを表しているようです。ノードの色・大きさ含め、わかりやすく、視認性・可読性はとてもよいです。

以下は同じデータを テキストアナリティクス入門 で紹介されているコードで実行した結果です。
こちらは、フォントサイズ、共起表示など様々な表示変更が可能です。
好みはあると思いますが、どちらもすばらしいです。
最後に
GiNZA、国語研長単位モデル、 NLPLOT、いずれもすばらしいですね。
とくに国語研長単位モデル を知ってからは、WordCloudや共起ネットワークを見ることが以前よりも楽しくなりました。
日本語の単語の境界は、最小単位、短単位、長単位などの単位が規定されているそうで、いわゆる形態素の単位が短単位となるようです。
国語研長単位モデル を知るまでは、短単位が当たり前でした。
「日本経済新聞」ならば、日本-経済-新聞 です。つながりが見えていれば分解されてもわかりますが、「日本」だけが独立している場合は「日本経済新聞」を連想しませんし、「経済」だけが独立している場合も「日本経済新聞」は連想しませんので、はじめから「日本経済新聞」という単位で抽出された方がすっきりします。
「国語研長単位に基づくUD Japanese」という論文 にそれぞれの例が紹介されていました。例をみると違いがよくわかります。

また、
- 長単位は、文節境界を認定したのちに、文節内の短単位要素の結合により認定される。この文節は日本語において係り受けを付与するのに適した単位。
- 長単位はその用法(係り受けなどの文脈)に基づく「用法に基づく品詞」が付与される。品詞の観点からも、短単位よりも長単位のほうが UD が示す「構文的な語」に近い。
ともありました。
また別の論文では、短単位と長単位が目的とするところについて記載がありました。
現代日本語書き言葉均衡コーパス(BCCWJ)は「コーパスに基づく用例収集、各ジャンルの言語的特徴の解明に適した単位を設計する」方針の下、日本語研究で幅広く利用できるようにするため、①用例収集を目的とした短単位 と②言語的特徴の解明を目的とした長単位 を採用。
短単位は、言語の形態論的側面に着目、1単位あたりの字数は短く(少ない)、短い検索クエリで目的の用例を広く多く集めることに向いている。一方、長単位は、短単位では捉え難い複合語をカバーすることで、短単位よりも長い特定の語に着目した用例検索に向いている。また文節を自立部と付属部にわけることで認定するため、言語の構文的な機能に着目して規定された言語単位ともいえる。
目的に応じ、うまく使いわけることが大切な感じです。
このようなモデルが公開され、利用させていただくことができるというのは、本当にありがたいことです。
逆に 利用しない・できないというのは、あまりにもったいないことです。
方法さえわかれば誰もが利用できるものですから、みなで利用し普段の仕事をアップデートしましょうということで、この記事を締めくくりたいと思います。
参考