
はじめに
機械学習や深層学習の進歩に伴い、テキストの感情分析は身近なものとなってきています。
ChatGPTにテキストと共に「ネガポジ分類して」と投げかけたら答えてくれますし、感情分析APIもいろんなものがあります。
これまで私は、実行が手軽で、ネガポジだけではなく感情の強さのスコアも示してくれる「Google Natural Language API」を利用(適用記事)してきましたが、APIの利用はコストがかかる。。。できればコストは気にせずにじゃんじゃんやりたい。。。でも、ある程度の判定結果を得るにはAPIに頼ったほうがいんじゃぁないか・・・
こんな風に思っておりましたが、先日の記事の経験から「なんかいけそう」「事前学習済モデルやるな」と感じるようになりました。
そこで、事前学習済モデルを利用した テキストデータを読み込むだけでできるネガポジ感情分析をやってみました。
Hugging Faceの感情分析について
Hugging faceは自然言語処理を扱えるエコシステムを提供する会社です。
Hugging Faceには、日本語の感情分析に適用できる事前学習済みモデルが公開されていますので、これを利用します。
感情分析モデルを使う手順
Hugging Faceの感情分析モデルを使う手順は以下です。
- Hugging Faceのライブラリ(transformers)をインストールする。
- 事前学習済みの感情分析モデル、トークナイザーに与える事前学習済みモデルをダウンロードする。
- モデルに与えるテキストを準備する。
- モデルにテキストを与えて、感情分類の結果を得る。
使用する事前学習済みモデル
- 事前学習済の感情分析モデル:bert-japanese-finetuned-sentiment
- トークナイザー 事前学習済モデル:東北大学 乾研究室の
bert-base-japanese-whole-word-masking
実行したこと
- Google Colabで実行しています。
- テキストデータは、Excel表形式にまとめられたアンケート等を想定し、csvデータとしています。適用データは、tweetデータ(csv)です。(※「再エネ」でtweet検索したつぶやきを ついすぽ でcsvにエクスポートしたデータです。)
- テキストデータを読み込み、最低限の正規処理を行い、ネガ・ポジ・ニュートラルのラベル化と確信度を示すスコアの表示、スコアの視覚化、ラベルとスコアを絞ったテキストのピックアップを行います。
- ネガポジ結果は PyGWalker でも視覚化 し、スコアの違いによるテキスト傾向を眺めました。
感情分析の実行内容
最初にライブラリをインストールし、インストール後、感情分析を行うテキストデータを読み込みます。
以下キャプチャのInitial settingは、どのデータを読み込むかのセッティングです。ここでは任意のtxtやcsvも読めるようにしています。
ここでは「再エネ」に関するtweetデータを指定して読み込んでいます。

以下は読み込んだデータの表示です。
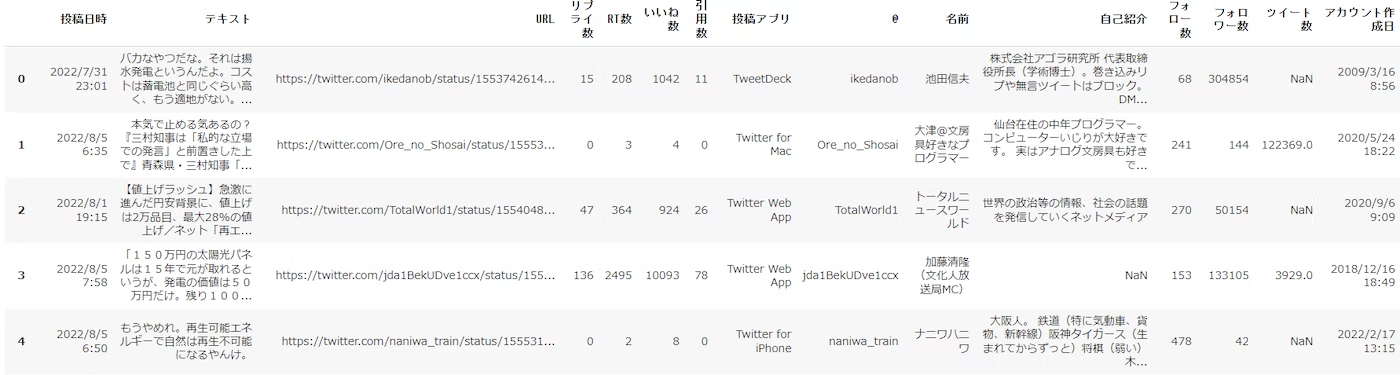
次に、テキスト分析したいデータカラム名を指定しています。

今回 感情分析を行うtweetデータには、タブ・スペース・メンション・URL等が混在していますので、指定した stop_words の処理と共に最低限の前処理を行っています。
- 前処理は行わなくても実行はできます。前処理したほうがテキストが読みやすくなるので実施しました。
- stop_words は、”あらかじめ” 決めていたのではなく、結果を見た後に指定し、再実行しています。

次に、事前学習済モデルをパイプラインに与え、テキストを感情分類し、結果をデータフレームに格納します。以下の通りテキスト毎に感情分類結果(ネガポジLabelとscore)を得ることができています。

各tweetデータ毎の感情ラベルとスコアが得られましたので、まず箱ひげ図(+Swarm Plot)を描いてみました。

重ね合わせヒストグラムも描いてみました。

次に、指定した感情ラベル(ネガ/ポジ/ニュートラル)とScoreに該当するtweetデータをピックアップし、表示させました。
以下は、めっちゃネガティブなtweetをピックアップした結果です。

PyGWalker でもネガポジ結果を視覚化してみました。(PyGWalkerは以下の記事参照)
以下は、Field List の scoreをbin化したラベルをドラッグし、X-Axisにドロップ、LabelとscoreをY-Axisにドロップ、textをcolorにドロップして描いた、Label別のヒストグラムです。
マウスポインターを近づけると、scoreとtextが画面表示されます。これはLabel/score毎のテキストを探る際、とても便利!!です。

最後に感情分類したデータフレームをcsv保存できるようにしました。

所見
事前学習済みモデルを使うと、実行はとても簡単です。
GPUに頼ることなくできますしね。
感情分類の結果も「あてにしてよさそう」と思えましたので、私はこれで十分です。(笑)
アンケートで得たお客様の声の傾向をつかんだり、いろんな場面で重宝できそうです。
おもろいなぁ。
最後に余談ですが、
同様の内容を実行された既出記事では、daigo/bert-base-japanese-sentiment を事前学習済の感情分析モデルとされているものが多いように思いますが、私が確認した時点で Hugging face にアップされていません(=ダウンロードできません)でしたので、Kohei Takamiさんという方がアップされているkoheiduck/bert-japanese-finetuned-sentiment を使わせていただきました。私は大満足です。
リンク先で、以下のように、入力したテキストの感情計算[Compute]ができます。

実行コード
ライブラリのインストール
!pip install transformers['ja']
!pip install sentencepiece
!pip install ipadic
テキストデータ読込み
データの読込みは、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Initial Settings { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','蜘蛛の糸','Upload_csv','Upload_txt']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
#@markdown **<font color= "Crimson">ガイド</font>:Upload 選択 ⇒ [ファイル選択]ボタンをクリックしてください。サンプルデータの場合は自動で読み込みます。**
import pandas as pd
import numpy as np
pd.set_option('display.unicode.east_asian_width', True)
from google.colab import files
import codecs
import warnings
warnings.simplefilter('ignore')
# データの読み込み
if dataset =='Upload_csv':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
elif dataset =='Upload_txt':
files = files.upload()
filename = list(files.keys())[0]
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
elif dataset == "蜘蛛の糸":
#蜘蛛の糸のテキストデータ(zipファイル)をダウンロード
!curl -O "https://www.aozora.gr.jp/cards/000879/files/92_ruby_164.zip"
#zipファイルを解凍
!unzip 92_ruby_164.zip
#文章切り出し(=注釈削除 [冒頭削除:tail -n +**][末尾削除:head -n -**] 任意設定要)
!tail -n +18 kumono_ito.txt | head -n -15 > kumono_ito_data.txt
#テキストファイル読み込み
text_file = open('/content/kumono_ito_data.txt',encoding = 'shift_jis')
def main():
# Shift_JIS ファイルのパス
shiftjis_path = 'kumono_ito_data.txt'
# UTF-8 ファイルのパス
filename = 'kumono_ito_utf.txt'
# 文字コードを utf-8 に変換して保存
fin = codecs.open(shiftjis_path, "r", "shift_jis")
fout_utf = codecs.open(filename, "w", "utf-8")
for row in fin:
fout_utf.write(row)
fin.close()
fout_utf.close()
if __name__ == '__main__':
main()
filename = 'kumono_ito_utf.txt'
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
#pd.set_option('display.max_colwidth', None)
#display(df.style.set_properties(**{'text-align': 'left'}))
df.head()

次に、テキスト処理するカラムを指定です。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラム名の入力 { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
以下は、テキストに含まれるタブ、メンション、URL等の処理です。
#@title テキスト処理
#from collections import Counter
#import spacy
import pandas as pd
import re
#import time
#from tqdm import tqdm
# 口コミに含まれている空行を削除
#df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
#df.dropna(subset=[column_name], inplace=True)
stop_words = 'ザ・リバティWeb', 'Yahooニュース','TheLibertyWeb','Yahoo!ニュース','日本経済新聞' #@param {type:"raw"}
# テキストデータの前処理
def text_preprocessing(text):
# 改行コード、タブ、スペース削除
text = ''.join(text.split())
# URLの削除
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', text)
# メンション除去
text = re.sub(r'@([A-Za-z0-9_]+)', '', text)
# 記号の削除
text = re.sub(r'[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥]', '', text)
# stop_wordsを'|'で連結して正規表現パターンを作る
pattern = '|'.join(stop_words)
# re.sub()でパターンにマッチする部分を空文字に置換する
text = re.sub(pattern, '', text)
return text
df[column_name] = df[column_name].map(text_preprocessing)
# 口コミに含まれている空行を削除
df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
df.dropna(subset=[column_name], inplace=True)
#df.head()
テキストの感情ラベルとスコア推定
#@title テキストの感情ラベルとスコアをデータフレームに格納
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer,BertTokenizer, BertForSequenceClassification
from tqdm import tqdm # tqdmをインポート
# 事前学習モデルセット → パイプラインへ
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
classifier = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
# corpus_list(データフレームに格納したテキストをリスト化)
corpus_list = df[column_name].to_list()
# 結果を表形式で出力
result_df = pd.DataFrame(columns=['text', 'label','score'])
for corpus in tqdm(corpus_list):
result = classifier(corpus)[0]
result_df = result_df.append({'text' : corpus , 'label' : result['label'], 'score' : round(result['score'], 4)} , ignore_index=True)
result_df.head()
感情ラベルとスコアの視覚化
#@title Box & Swarm-plot
import seaborn as sns
sns.boxplot(data=result_df,y='score',x='label',color='w');
sns.swarmplot(data=result_df,y='score',x='label');
#@title Stratified histogram by category_seaborn
Column_name = 'score'#@param {type:"raw"}
Category_column_name = 'label'#@param {type:"raw"}
bins_number_slider = 10 #@param {type:"slider", min:5, max:20, step:1}
import seaborn as sns
sns.set_style('whitegrid') #style指定
sns.set(font='IPAexGothic')
sns.histplot(x= Column_name, hue= Category_column_name, bins = bins_number_slider, kde=True, data=result_df);
感情ラベルとスコア範囲指定 →テキストピックアップ
#@title テキストピックアップ
label = 'NEGATIVE' #@param ['NEGATIVE','NEUTRAL','POSITIVE']
display_record_number_slider = 10 #@param {type:"slider", min:3, max:30, step:1}
score_lower_slider = 0.7 #@param {type:"slider", min:0, max:1, step:0.1}
score_upper_slider = 1.0 #@param {type:"slider", min:0, max:1, step:0.1}
bool_index = (result_df['label']==label) & (result_df['score'] >= score_lower_slider) & (result_df['score'] <= score_upper_slider)
filtered_df = result_df[bool_index]
filtered_df = filtered_df.sort_values(by='score', ascending=False)
pd.set_option('display.max_colwidth', None)
#display(filtered_df[0:display_record_number_slider])
filtered_df_=filtered_df[0:display_record_number_slider]
left_aligned_df = filtered_df_.style.set_properties(**{'text-align': 'left'})
display(left_aligned_df)
#@title csv出力(☑ =実行)
csv_output = False #@param {type:"boolean"}
#csv出力
if csv_output == True:
df.to_csv('8senti_data.csv',encoding='utf_8_sig',index=False)
from google.colab import files
files.download('8senti_data.csv')
PyGWalkerのコードは、以下の記事を確認してください。
参考