2022/10/01:久々に実行すると、エラー(KeyError: 'documentSentiment')が出ました。Google Cloud Platform(GCP)の無料枠の期限が切れたからのようです。動作がおかしい時はGCPの状況を確認しましょう。
2021/12/30:記事の「最後に」の後に「後日談」を追加
はじめに
前回の記事で、アンケート自由記述内容の感情分析(ネガポジ分析)を取り上げました。
前回は、asariというライブラリを使いましたが、今回はGoogle Natural Language APIで感情分析を行ってみました。
これは、イイです。
これまで試したものは、ネガポジ判定結果のなかに「?」がつくケースが比較的多く見られたのですが、Google Natural Language APIによる感情分析の判定結果は、ほとんど違和感を感じませんでした。
以下、前回のasariと今回のGoogle Natural Language APIの感情分析の結果をいくつかに比較抜粋します。
数値はネガポジ感情を―1~+1であらわしたもので、プラスがポジ、マイナスがネガです。
判定にすこしムリがあるなと感じた箇所を赤字にしています。
Google Natural Language の感情分析は優秀ですね。
| userID | comment | asari | Google NL |
|---|---|---|---|
| U074 | もう少し薄くして欲しいです | -0.27 | -0.9 |
| U039 | 配線のコネクターを小さくして欲しい。 | -0.41 | -0.7 |
| U134 | 少しだけ価格が高い。 | 0.67 | -0.9 |
| U137 | カバーが硬いです。取る時に苦労する。 | 0.72 | -0.8 |
| U179 | 調整をもう少し細かくできるようにしてほしい。 | 0.59 | -0.7 |
| U137 | カバーが硬いです。取る時に苦労する。 | 0.72 | -0.8 |
| U250 | 調整が難しい場合があるので、簡単にできればよいです。 | 0.99 | 0 |
| U011 | 環境(雨・日差し・雪・汚れ等)に影響されず、〇〇式に負けない安価な□□をご提案願います。 | -0.10 | 0.3 |
| U285 | 露出ケースホワイト色があるとよい。 | 0.86 | 0.5 |
| U238 | 基本的には満足しております。 | 0.98 | 0.9 |
コードは、前回の記事の一部を変更するだけです。
実行条件など
- Google colabで実行
- **手元の表形式データ(アンケート自由記述結果)**で実行
※使用したデータは開示できませんが、データ形式は以下です。カラムはUserID、comment、csの3つ。commentは自由記述回答、csは満足度(1~6)です。
| userID | comment | cs |
|---|---|---|
| U001 | 総合的には満足してますが、○○が細かく調整できたらもっと使いやすいと思います。 | 4 |
| U002 | ○○ボタンが押しにくいです。 | 2 |
| U003 | 特にありません。 | 3 |
| U004 | 既存品と取付位置が合わないことがつらいです。 | 1 |
語彙のベクトル化について
Userの訴えかけを語彙傾向で分けるためには、語彙をベクトル化しないといけません。
この記事では、TF-IDFによる方法を扱っています。
各Userの声、形態素の結果、グループ分け(クラスタ分け)の結果をデータフレームに格納、csvデータに変換し、ローカルファイルに出力するようにしています。
グループ分けした結果は、EXCELで並べ替えるなどして見たほうがよいでしょう。
備忘
- コード操作を不要にするため、ファイル指定やフォームなど、GoogleColabの機能を活用。
- 品詞は名詞・動詞・形容詞(動詞と形容詞は基礎型)を抽出対象とした。
ライブラリインストール&インポート
#日本語フォントをインストール
!apt-get -y install fonts-ipafont-gothic
#Mecabのインストール
!pip install mecab-python3==0.996.5
#matplotlib日本語化
!pip install japanize-matplotlib
#ライブラリインポート
from pathlib import Path
import pandas as pd
import re
import MeCab
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
APIキーの設定
#@title Google_NL APIキー(各自で取得したAPIキー['APIキー']を設定してください) { run: "auto" }
key = '**********' #@param {type:"raw"}
Google Natural laugage の設定およびAPIキーの獲得は以下の動画がとてもわかりやすいです。https://www.youtube.com/watch?v=OuXq0urpXxY
ファイル選択
#@title csvファイル(UTF-8)を指定してください
from google.colab import files
#print('csvファイル(UTF-8)を指定してください')
uploaded = files.upload()
※ライブラリのインストールとインポートが完了すると、[ ファイル選択 ]がうながされますので、クリックし、ファイルを指定します。(キャプチャ画像は、これは読込み後の画面キャプチャです。)
##Option:CS_High/Low_Level & ストップワード指定
※CS_Level設定について
このレベル設定は、例えば6段階評価の場合、4以上を[満足]、3以下を[不満足]とする等のシキイの設定です。一部の可視化は、ここでの設定に沿いWord Cloudに反映します。
#@title CS_High/Low設定(上:設定以上をCS高/下:設定以下をCS低) { run: "auto" }
CS_High_level_x_or_More = 4 #@param {type:"number"}
CS_Low__level_x_or_Less = 3 #@param {type:"number"}

#@title ストップワード設定
stop_words = ["-", ".", ")", "(", "し", "い", "ある", "おる", "せる", "ない", "いる", "する", "の", "よう", "なる", "それ", "そこ", "これ", "こう", "ため", "そう", "れる", "られる"]
モジュール構築
#@title データフレーム格納&欠損値削除
if len(uploaded.keys()) != 1:
print("アップロードは1ファイルにのみ限ります")
else:
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
df.dropna(subset=['comment'], inplace=True)
df.head()
#@title 形態素解析(一般名詞・動詞:基礎型・形容詞:基礎型)&カンマ・スペース区切りをデータフレームに格納
#形態素解析(一般名詞・動詞・形容詞(動詞と形容詞は基礎型)を抽出対象とした)
#スペース区切り分かち書き
def mecab_analysis(text):
t = MeCab.Tagger('-Ochasen')
node = t.parseToNode(text)
words = []
while node:
if node.surface != "": # ヘッダとフッタを除外
word_type = node.feature.split(',')[0]
sub_type = node.feature.split(',')[1]
features_ = node.feature.split(',')
#品詞を選択
if word_type in ["名詞"]:
# if sub_type in ['一般']:
word = node.surface
words.append(word)
#動詞、形容詞[基礎型]を抽出(名詞のみを抽出したい場合は以下コードを除く)
elif word_type in ['動詞','形容詞'] and not (features_[6] in stop_words):
words.append(features_[6])
node = node.next
if node is None:
break
return " ".join(words)
#カンマ区切り分かち書き
def mecab_analysis2(text):
t = MeCab.Tagger('-Ochasen')
node = t.parseToNode(text)
words2 = []
while(node):
if node.surface != "": # ヘッダとフッタを除外
word_type = node.feature.split(',')[0]
sub_type = node.feature.split(',')[1]
features_ = node.feature.split(',')
if word_type in ['名詞']: #名詞をリストに追加する
# if sub_type in ['一般']:
words2.append(node.surface)
#動詞、形容詞[基礎型]を抽出(名詞のみを抽出したい場合は以下コードを除く)
elif word_type in ['動詞','形容詞'] and not (features_[6] in stop_words):
words2.append(features_[6])
node = node.next
if node is None:
break
return words2
#形態素結果をリスト化し、データフレームdf1に結果を列追加する
df['words'] = df['comment'].apply(mecab_analysis)
df['words2'] = df['comment'].apply(mecab_analysis2)
#表示
df
#@title 形態素結果を層別しデータフレームに格納
#全データをデータフレームに格納
all_words =' '.join(df['words'])
df_all = pd.Series(all_words)
#CSが高いuserの声(words)をデータフレームに格納
drop_index = df.index[df['cs'] <=CS_Low__level_x_or_Less]
#条件にマッチしたIndexを削除
df_high = df.drop(drop_index)
all_high_words=' '.join(df_high['words'])
df_all_high_words = pd.Series(all_high_words)
#CSが低いuserの声(words)をデータフレームに格納
drop_index2 = df.index[df['cs'] >=CS_High_level_x_or_More]
#条件にマッチしたIndexを削除
df_low = df.drop(drop_index2)
all_low_words=' '.join(df_low['words'])
df_all_low_words = pd.Series(all_low_words)
print('CS高ユーザーの声(Words):')
print(df_all_high_words)
print('CS低ユーザーの声(Words):')
print(df_all_low_words)
#@title ワード出現回数カウント(表示する場合は#外す)
#カンマ区切り分かち書きしたワードをリスト化
words_list = df.words2.tolist()
words_list = sum(words_list,[])
from collections import Counter
#出現回数を集計し、最頻順にソートし、resultに格納
words_count = Counter(words_list)
result = words_count.most_common()
#出現回数結果を画面に出力
#for word, cnt in result:
# print(word, cnt)
満足度(CS)グラフ化
#@title CS満足度傾向_円グラフ & ヒストグラム
cs = pd.DataFrame(df['cs'].value_counts())
cs.plot.pie(subplots=True,autopct="%1.1f%%",startangle=90,counterclock=False)
plt.show()
plt.hist(df['cs'],bins=7)
# x軸とy軸のラベルをつける
plt.xlabel('CS')
plt.ylabel('Count')
plt.show()
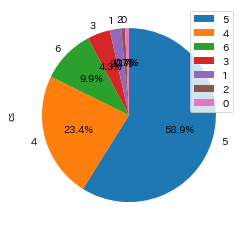

※これはアンケートデータにあった満足度を円グラフとヒストグラムで表現しただけ。
1~6段階で選択される値なのですが、0があります。これはおかしいですが、気にしない。
満足度(CS)は高い方に偏っています。
自由記述のグループ分け
#@title TF-IDFマトリクス作成&データフレーム格納
# ライブラリインポート
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDFのベクトル処理
vectorizer = TfidfVectorizer(use_idf=True)
tfidf = vectorizer.fit_transform(df['words'] )
# TF-IDF値を「センテンス×ワード」マトリクスをデータフレーム化
df_tfidf = pd.DataFrame(tfidf.toarray(), columns=vectorizer.get_feature_names(), index=df['words'])
#display(df_tfidf)
#@title **Option**:エルボー法(SSE値の低下がサチる場所を最適なクラスター数とみなす方法)
#ライブラリインポート
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
from sklearn.cluster import KMeans
X=df_tfidf
sc = preprocessing.StandardScaler()
sc.fit(X)
X_norm = sc.transform(X)
#print(type(X_norm))
distortions = []
for i in range(1,31): # 1~30クラスタまで一気に計算
km = KMeans(n_clusters=i,
init='k-means++', # k-means++法によりクラスタ中心を選択
n_init=10,
max_iter=300,
random_state=0)
km.fit(X) # クラスタリングの計算を実行
distortions.append(km.inertia_) # km.fitするとkm.inertia_が得られる
plt.plot(range(1,31),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
'''
#@title クラスター数(分けたいグループ数)設定 { run: "auto" }
num_clusters = 8 #@param {type:"number"}
#@title TF-IDF_k-meansによる各意見のグループ分け
# kmean_clustring
from sklearn.cluster import KMeans
# 設定クラスタ数で実行
clusters = KMeans(n_clusters=num_clusters).fit_predict(tfidf)
#データフレームにclusterを反映
df['cluster_tfidf'] = clusters
df
TF-IDFについて
TF-IDF は文書に含まれる単語がどれだけ重要かを示す手法の一つで、TF (= Term Frequency: 単語の出現頻度)と IDF (Inverse Document Frequency: 逆文書類度)の2つを使って計算します。
クラスタリング(k-means法)について
数値化(TF-IDF)した各意見のクラスタリングを行います。クラスタリングは、scikit-learn の KMeans(非階層的クラスタ分析)を使用します。KMeans(非階層的クラスタリング)では、設定したクラスタ数にしたがって、近い属性のデータをグループ化します。
参考として適性なクラスター数を導く手法(エルボー法)の結果を表示します。横軸:クラスタ数、縦軸:SSE(残差平方和)としたグラフで、クラスタ数を増やしてもSSEがほとんど改善しない点のクラスタ数を選ぶというものです。
適切な点が見いだせない場合も含め、クラスター数は任意に設定できるようにしています。「クラスター数設定」で設定します。
感情分析
#@title Google NLインスタンス
import requests
def g_nlp(text):
#text = '吾輩は猫である。名前はまだない。'
url = f'https://language.googleapis.com/v1/documents:analyzeSentiment?key={key}'
header = {'Content-Type':'application/json'}
body = {
'document': {
'type':'PLAIN_TEXT',
'language':'JA',
'content':text
}
}
res = requests.post(url, headers=header, json=body)
result = res.json()
return result
#@title Google NL感情分析結果をデータフレームに反映
#各セリフのポジティブな感情のスコア
df["G_NL_sentiment"] = df.comment.map(lambda x : g_nlp(x)['documentSentiment']['score'])
df

#@title Google NL感情分析値(G_NLP_senti)ヒストグラム
plt.hist(df['G_NL_sentiment'],bins=10)
# x軸とy軸のラベルをつける
plt.xlabel('G_NL_sentiment')
plt.ylabel('Frequency')
plt.show()
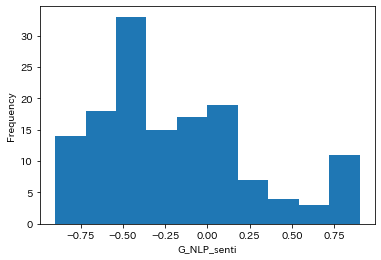
※0がニュートラル、プラスがポジティブ、マイナスがネガティブとなります。
ネガティブ側に偏った分布となりました。
ネガ意見が圧倒的に多いってことになります。
#@title Google NL感情分析値の統計量(表示する場合は#を外す)
#df['GG_NL_sentiment'].describe()
#@title G_NL_sentiment - CS 相関
sns.jointplot(data=df, x="G_NL_sentiment", y="cs", kind="reg",
line_kws={"color":"red"})
plt.show()
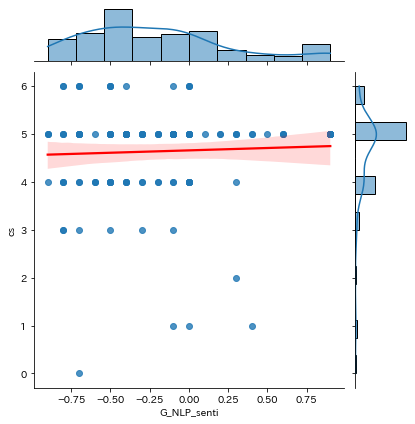
感情(Sentiment)と満足度(CS)に、まったく相関はみられませんでした。
私が扱ったデータの場合、満足度別に自由記述を見ても意味がないということになります。
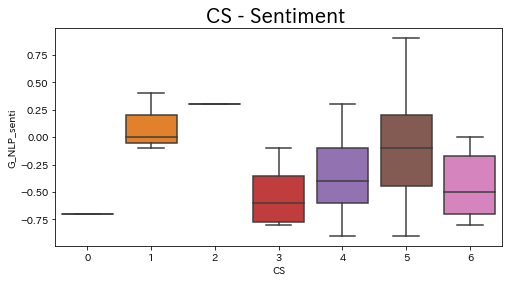
#@title Google NL 箱ひげ図
#CS - G_NL_sentiment 箱ひげ図
plt.figure(figsize=(8,4))
sns.boxplot(data=df,x=df['cs'],y=df['G_NL_sentiment'])
plt.title('CS - Sentiment ', fontsize=20) # グラフタイトル
plt.xlabel("CS")
plt.ylabel("G_NL_sentiment")
#plt.ylim([0,45]) # y軸範囲
plt.show()
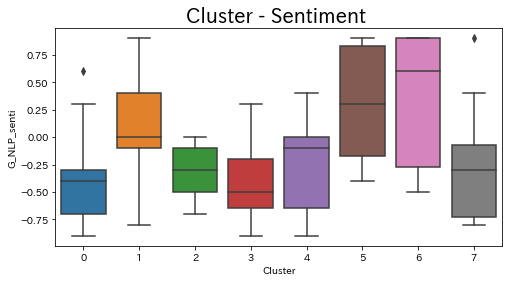
#Cluster - Sentiment 箱ひげ図
plt.figure(figsize=(8,4))
sns.boxplot(data=df,x=df['cluster_tfidf'],y=df['G_NL_sentiment'])
plt.title('Cluster - Sentiment ', fontsize=20) # グラフタイトル
plt.xlabel("Cluster")
plt.ylabel("G_NL_sentiment")
#plt.ylim([0,45]) # y軸範囲
plt.show()
Word Cloud
- ワードクラウドは、文章中で出現頻度が高い語を複数選び出し、その頻度に応じた大きさで図示する手法です。
- 表示するワードクラウドは全6種。①ワード出現回数ベース/②TF-IDFベース(全データ)/③TF-IDFベース(CS高データ)/④TF-IDFベース(CS低データ)/⑤TF-IDFベース(ポジティブデータ)/⑥TF-IDFベース(ネガティブデータ)
※語の表示数はmax_words, Word Cloudの表示サイズはwidth, heightで設定できます
#@title Word Cloud by word_count(All Data):🔲型 → #maskの#外すと🍩型に
#wordcloud取込用にresultを辞書型ヘ変換
dic_result = dict(result)
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
from wordcloud import WordCloud
#画像データダウンロード(biwakoの画像リンクもあり。変更する場合は#調整)
import requests
url = "https://github.com/hima2b4/Word-Cloud/raw/main/donuts.png"
#url = "https://github.com/hima2b4/Word-Cloud/raw/main/biwa.png"
file_name = "donuts.png"
#file_name = "biwa.png"
response = requests.get(url)
image = response.content
with open(file_name, "wb") as f:
f.write(image)
#ライブラリインポート
from PIL import Image
import numpy as np
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
custom_mask = np.array(Image.open('donuts.png'))
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).fit_words(dic_result)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
#@title Word Cloud with TF-IDF(All DATA):🔲型 → #maskの#外すと🍩型に
# TF-IDF計算
tfidf_vec2 = vectorizer.fit_transform(df_all).toarray()[0]
# TF-IDFを辞書化
tfidf_dict2 = dict(zip(vectorizer.get_feature_names(), tfidf_vec2))
# 値が正のkeyだけ残す
tfidf_dict2 = {k: v for k, v in tfidf_dict2.items() if v > 0}
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).generate_from_frequencies(tfidf_dict2)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
#@title Word Cloud with High CS Data (TF-IDF):🔲型 → #maskの#外すと🍩型に
tfidf_vec = vectorizer.fit_transform(df_all_high_words).toarray()[0]
# TF-IDFを辞書化
tfidf_dict = dict(zip(vectorizer.get_feature_names(), tfidf_vec))
# 値が正のkeyだけ残す
tfidf_dict = {k: v for k, v in tfidf_dict.items() if v > 0}
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).generate_from_frequencies(tfidf_dict)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
#@title Word Cloud with Low CS Data (TF-IDF):🔲型 → #maskの#外すと🍩型に
tfidf_vec = vectorizer.fit_transform(df_all_low_words).toarray()[0]
# TF-IDFを辞書化
tfidf_dict = dict(zip(vectorizer.get_feature_names(), tfidf_vec))
# 値が正のkeyだけ残す
tfidf_dict = {k: v for k, v in tfidf_dict.items() if v > 0}
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).generate_from_frequencies(tfidf_dict)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
G_NL_sentimentをながめて、エイヤーで>0.4をPositiveに、≦0.4をNegativeとし、以下、Word Cloudに反映しました。
※ニュートラルは0なので、本来は0をシキイとすべきなのかもしれませんが、「弱いPositiveはNegativeにしちゃえ」というノリで、0.4に設定したということです。
#@title ネガポジ区分(G_NL_sentimentでネガポジ区分したい値を指定:Default=0.4) { run: "auto" }
Thresh_hold = 0.4 #@param {type:"slider", min:0, max:0.5, step:0.1}
#ポジの声(words)をデータフレームに格納
drop_index3 = df.index[df['G_NL_sentiment'] <=Thresh_hold]
#条件にマッチしたIndexを削除
df_posi = df.drop(drop_index3)
all_posi_words=' '.join(df_posi['words'])
df_all_posi_words = pd.Series(all_posi_words)
#ネガの声(words)をデータフレームに格納
drop_index4 = df.index[df['G_NL_sentiment'] >Thresh_hold]
#条件にマッチしたIndexを削除
df_nega = df.drop(drop_index4)
all_nega_words=' '.join(df_nega['words'])
df_all_nega_words = pd.Series(all_nega_words)
print('ポジの声(Words):')
print(df_all_posi_words)
print('ネガの声(Words):')
print(df_all_nega_words)

※ネガポジをSentment_netのどの値で区分するかは、上記のように任意に設定できます。
#@title Word Cloud with Positive Data (TF-IDF):🔲型 → #maskの#外すと🍩型に
tfidf_vec = vectorizer.fit_transform(df_all_posi_words).toarray()[0]
# TF-IDFを辞書化
tfidf_dict = dict(zip(vectorizer.get_feature_names(), tfidf_vec))
# 値が正のkeyだけ残す
tfidf_dict = {k: v for k, v in tfidf_dict.items() if v > 0}
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).generate_from_frequencies(tfidf_dict)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
#@title Word Cloud with Negative Data (TF-IDF):🔲型 → #maskの#外すと🍩型に
tfidf_vec = vectorizer.fit_transform(df_all_nega_words).toarray()[0]
# TF-IDFを辞書化
tfidf_dict = dict(zip(vectorizer.get_feature_names(), tfidf_vec))
# 値が正のkeyだけ残す
tfidf_dict = {k: v for k, v in tfidf_dict.items() if v > 0}
#Word Cloudで画像生成(#max_words, width, heightは任意設定)
wordcloud = WordCloud(background_color='white',
max_words=125,
#mask=custom_mask,
font_path='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
width=800,
height=500,
).generate_from_frequencies(tfidf_dict)
#生成した画像の表示
plt.figure(figsize=(15,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
Word Cloudはお見せすることができませんが、これは感情分析でネガ判定された自由記述によるWord Cloudを描きました。
調整や設定、取付けなどに関し、誤りにくく、簡単にでき、わかる等、改善が望まれていることが垣間見える内容となっていました。
※満足度が低いデータのWord Cloudよりも、User訴えがよく見える結果となりました。今回私が扱ったデータの場合、感情分析をベースに自由記述を分析したほうがよさそうです。
結果出力
#@title データフレームをcsvに変換し、ローカルファイルに保存
from google.colab import files
filename = 'sentiment&cluster.csv'
df.to_csv(filename, encoding = 'utf-8-sig')
files.download(filename)

※分析結果を反映した sentiment&cluster.csv を出力します。
最後に
自由記述で分析したネガポジ傾向とアンケートの満足度傾向にまったく相関がなかったというのは意外でした。
「満足度が高いUserの自由記述内容はポジティブ」、「満足度が低いUserの自由記述内容はネガティブ」という傾向はなく、
- 自由記述内容はネガティブなのに満足度が高いUser がおられる
- 自由記述内容はポジティブなのに満足度が低いUser がおられる
というのは新鮮な発見でした。
満足度だけで一喜一憂せず、潜在不満・潜在期待がいりまじった自由記述から読み取れる訴えにしっかり耳を傾けねばならんなと、あらためて感じました。
また、今回はサクサク動作するライブラリに絞りましたので、上記の発見含め、個人的には満足です。
※以下、取説ほど充実していませんが、このライブラリの使用説明は「このライブラリの説明」を見てください。
後日談(2021/12/30)
アンケートの自由記述の内容分析を進めるためには、個々の訴えにしっかり耳を傾けなければなりませんが、ランダムに読み進めるのは大変です。
読み進める前に、いくつかのグループに分けたり、ある尺度で表現したりできると、読み進めの助けになります。
ただ、疑問符がつくようなグループ分けや尺度表現では読み進めの障害となりますので、ある程度の精度も確保しなければなりません。
今回、分析対象としたアンケートは、満足度データが含まれていましたので、満足度の値を読み進めの尺度としてあてにしていましたが、自由記述の感情分析値と満足度にまったく相関はなく、いろんな模索の結果、まずはもっとも違和感がなかったGoogle Natural language APIによる感情分析値を読み進めの参考尺度とすることにしました。
これはdocumentSentimentの score として表示される、ネガポジを-1〜1の範囲で表現した値(小数第一位)です。
documentSentimentには、magnitudeという感情の強さを示す値もあり、最終的には、score(以下グラフのx軸)とmagnitudeの積(以下グラフのy軸)を求め、標準化した値が個人的に一番しっくりきた感があります。
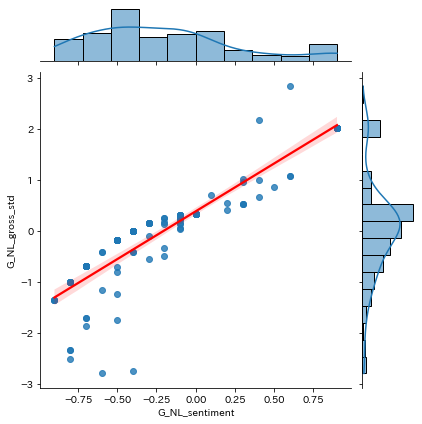
scoreとscore×magnitude の関係を見ると、score(ネガポジ)が大きくなるほど、感情の強さも大きくなる傾向にあります。
値と自由記述内容を対比させてみても、より自然で違和感がない状況になったように思います。
感情分析の結果:データサンプル
| UserID | comment | G_NL_sentiment | G_NL_magnitude | G_NL_gross_std |
|---|---|---|---|---|
| U0158 | ○○設定の際 ◆◆しにくいことかある。 改善か進まない。 | -0.8 | 1.7 | -2.501064748 |
| U0137 | △△のカバーが硬いです。取る時に苦労する。 | -0.8 | 1.6 | -2.334169277 |
| U0039 | 配線のコネクターを小さくして欲しい。 (点検口側の穴を***) | -0.7 | 1.4 | -1.708311262 |
| U0074 | もう少し薄くして欲しいです | -0.9 | 0.9 | -1.353658387 |
| U0134 | 少しだけ価格が高い。 | -0.9 | 0.9 | -1.353658387 |
| U0156 | ***調整が複雑で時間がかかる。 | -0.9 | 0.9 | -1.353658387 |
| U0244 | ■■から○○へ交換するときの施工性が悪いのが難点です。 | -0.8 | 0.8 | -0.999005512 |
| U0040 | ***を薄くできないしょうか。 | -0.7 | 0.7 | -0.686076505 |
| U0162 | ***調整などもう少し細かく出きるようにしていただきたい …他 | -0.7 | 0.7 | -0.686076505 |
| U0297 | ***の調整幅を細かくしてほしい。 | -0.7 | 0.7 | -0.686076505 |
| U0120 | 薄くて小さめの***がほしいです | -0.6 | 0.6 | -0.414871365 |
| U0019 | 特にありません。 | -0.5 | 0.5 | -0.185390093 |
| U0027 | 特にありません。 | -0.5 | 0.5 | -0.185390093 |
| U0107 | ***の耐久性を考慮してほしいです。 | -0.5 | 0.5 | -0.185390093 |
| U0127 | 特にありません。 | -0.5 | 0.5 | -0.185390093 |
| U0168 | 特になし。 | -0.4 | 0.4 | 0.002367312 |
| U0188 | 今のところ特に無し。 | -0.4 | 0.4 | 0.002367312 |
| U0198 | センサーエリアをもう少し細かく設定出来ればと思います。 | -0.4 | 0.4 | 0.002367312 |
| U0213 | 説明書をもっと詳しく。 | -0.4 | 0.4 | 0.002367312 |
| U0254 | 特になし。 | -0.4 | 0.4 | 0.002367312 |
| U0054 | 現時点で要望等は特にありません。 | -0.3 | 0.3 | 0.148400848 |
| U0131 | 自己判断、音声で異常をお知らせ機能。 | -0.3 | 0.3 | 0.148400848 |
| U0208 | 硫黄対策をしたいのですが何かありませんか? | -0.3 | 0.3 | 0.148400848 |
| U0265 | もう少し小さくはなりませんか? | -0.3 | 0.3 | 0.148400848 |
| U0278 | 他社製品の分析商品開発及びコストダウン。 | -0.3 | 0.3 | 0.148400848 |
| U0031 | 海の近くの物件に使用すると早くて3~5年以内には故障してしまうので防水・防湿タイプ等をご検討していただきたい。 | -0.2 | 0.2 | 0.252710518 |
| U0035 | 各***共に××の調整幅を増やして頂きたい。 | -0.1 | 0.1 | 0.315296319 |
| U0228 | 防水性能を有したセンサーを発売してほしい。 | -0.1 | 0.1 | 0.315296319 |
| U0271 | コンパクトで、精度が高い***が欲しい。 | -0.1 | 0.1 | 0.315296319 |
| U0049 | ○○など横フリの調整が出来ない機種があるので、調整できるようにして頂きたい。 | 0 | 0.8 | 0.336158253 |
| U0144 | ○○と◆◆の互換性 | 0 | 0 | 0.336158253 |
| U0153 | ***のエリア調整が結構大変です。すぐに狂ってしまいます。 | 0 | 0.5 | 0.336158253 |
| U0195 | 防水性の高い***が欲しい 少し高くてもいいから\(^^)/ | 0 | 0 | 0.336158253 |
| U0250 | 調整が難しい場合があるので、簡単にできればよいです。 | 0 | 0 | 0.336158253 |
| U0011 | 環境(雨・日差し・雪・汚れ等)に影響されず、○○式に負けない安価な◆◆をご提案願います。 | 0.3 | 0.3 | 0.523915657 |
| U0038 | 総合的には満足しているが、**調整が細かく調整できたらもっと使いやすいと思います。 | 0.3 | 0.3 | 0.523915657 |
| U0138 | 有線接続を無線接続に出来れば楽になると思います。 | 0.4 | 0.4 | 0.669949194 |
| U0285 | **ケースホワイト色が有ると良い。 | 0.5 | 0.5 | 0.857706599 |
| U0301 | 今のままで不満はありませんが、今後も期待しております。 | 0.6 | 0.6 | 1.087187871 |
| U0183 | 安価で品質も良く安心できる。 | 0.9 | 0.9 | 2.025974893 |
| U0231 | とても使いやすいです。 | 0.9 | 0.9 | 2.025974893 |
| U0238 | 基本的には満足しております。 | 0.9 | 0.9 | 2.025974893 |
- グループ分け:User毎の自由記述の語彙傾向でグループ分けを行います。[ ベクトル計算:TF-IDF⇒クラスタリング:k-means ]
- 感情分析:User毎の自由記述の感情分析(ネガポジ分類)を行います。[ Google Natural Language API ]
- Word Cloud:出現頻度が高い語を複数選び出し、その頻度に応じた大きさで図示します。文書に含まれる語がどれだけ重要かを示すTF-IDFというベクトル計算を行った結果によるWord Cloudも図示します。(満足度別、ネガポジ別に図示します)
- 結果出力:語彙傾向によるグループ分け、感情分析の結果を反映したcsvを出力します。
前準備
- csvデータの表形式は以下としてください。
- カラム名は1列目を userID、2列目を comment(自由記述)、3列目を cs(満足度)としてください。3列目はなくても構いません。
- [注意] csvデータは文字コードを「UTF-8」としてください。
| userID | comment | cs |
|---|---|---|
| U001 | 総合的には満足してますが、○○が細かく調整できたらもっと使いやすいと思います。 | 4 |
| U002 | ○○ボタンが押しにくいです。 | 2 |
| U003 | 特にありません。 | 3 |
| U004 | 既存品と取付位置が合わないことがつらいです。 | 1 |
実行手順
- メニューバーの「ランタイム」から「すべてのセルを実行」をクリック。
- ライブラリインストール完了後、[ファイル選択]ボタンをクリックし、分析したい文書(csvファイル)を指定する。
注意:「ランタイム」⇒「すべてのセルを実行」でエラーとなる場合は、「ランタイム」⇒「ランタイムを再起動」してから、「すべてのセルを実行」してください。
このライブラリの使い方について
- テキスト分析は文書量が多いと目を通すだけでも大変です。このライブラリで文書全体把握につながる語彙の特徴やセンテンスのグルーピングができますので、初手として活用することで効率化できます。
- 満足度データがある場合、自由記述を満足度で区分することが多いが、自由記述から読み取れるネガポジと満足度は合わないことも多く、記述内容から心情を探る=感情の切り口から見た方がよいといえます。
- Word Cloudで文書全体の訴えをながめた上、ライブラリが行ったグループ分け毎に個々のテキストに目を通すとよいと思います。
その他
- グループ分けの数(クラスター数)は任意に設定できます。
- 満足度を数値化している場合、高い/低いランクを任意に設定できます。
- Word Cloudは、🍩型に変更することができます。
- [注意] k-means はアルゴリズム上、実行ごとに結果が変わることがあります。
参考サイト