
はじめに
機械学習や深層学習の進歩に伴い、テキストの感情分析は身近なものとなってきています。
これまで感情分析に、いくつかの手法で試みましたが、BERTは「ちょっと時間かかりそうだから時間ある時にしよ」と後回しにしてましたが、以下の記事を見てやってみたいという衝動にかられました。
感情分析といえば、ネガか、ポジか、ニュートラルかというのが定石的と思いますが、なんと、8クラスの感情分類?!
喜び・悲しみ・期待・驚き・怒り・恐れ・嫌悪・信頼 に分類できる?!、すごいですね。
これは、ネガポジだけの分類ではありませんので、分析対象文書全体の感情の奥行きに近いような傾向が見えるかもしれませんし、特定の感情に絞った声や反応を取り出すこともできそうです。
この記事では、コードを実装したGoogleColabのNotebookをアップして下さってますし、Notebookに記された説明もとても丁寧でわかりやすいです。(私はそもそも理解が浅いので)BERTによる感情分析コードの流れを理解する助けになりました。
早速、この記事に沿って実行した訓練モデルに身近なテキストデータを与えて弄ってみました。
BERTによる感情分析
BERTを感情分析タスクに使用する場合、一般的には、事前に学習されたモデルをファインチューニングすることによって、感情分類器を作成します。
ファインチューニングは、学習済みのモデルを、特定のタスクに合わせて調整することです。たとえば、テキストの感情分析をしたい場合、BERTを感情分析に適した形に調整します。それによって、より正確に感情を判断することができます。
・・・といいましても、
モデルだ、学習だ、チューニングだと色々出てくるからややこしいですね。
例えるならば、
BERTさんという賢い奴がおるんや。彼に東北大学の乾研究室の教材を渡してな、WRIMEっていう感情データセットをまとめてもらおうと思てますねん。
まとめてもろたらな、そのまとめは他のテキストデータの感情分析でも使えるようになりますさかいに。
といったところでしょうか。
分類器の作成までは、元記事を参考にさせていただいています。
例えでいう”まとめてもらうまで”は、GPUで処理する必要があり、何度も分類器作成まで回すのは大変ですので、保存したモデルを読み出すようにし、これに分析したいテキストを適用しました。
実行したこと
感情分析の実行内容
訓練モデルの構築は、先の記事の通り実行させていただき、モデル構築後に以下を実行しました。
まず、モデルの保存です。GoogleDriveマウント後、モデル保存を実行しました。

次に、保存したモデルを読み込んでいます。これで、繰り返し実行する場合は、先の「モデルの保存」はスキップできます。

次は、感情分析の分類器にかけたいテキストデータの読込みです。
以下キャプチャのInitial settingは、どのデータを読み込むかについてのセッティングです。ここでは任意のtxtやcsvも読めるようにしています。
今回、ここでは「再エネ」に関するtweetデータを指定して読み込んでいます。

以下は読み込んだデータの表示です。
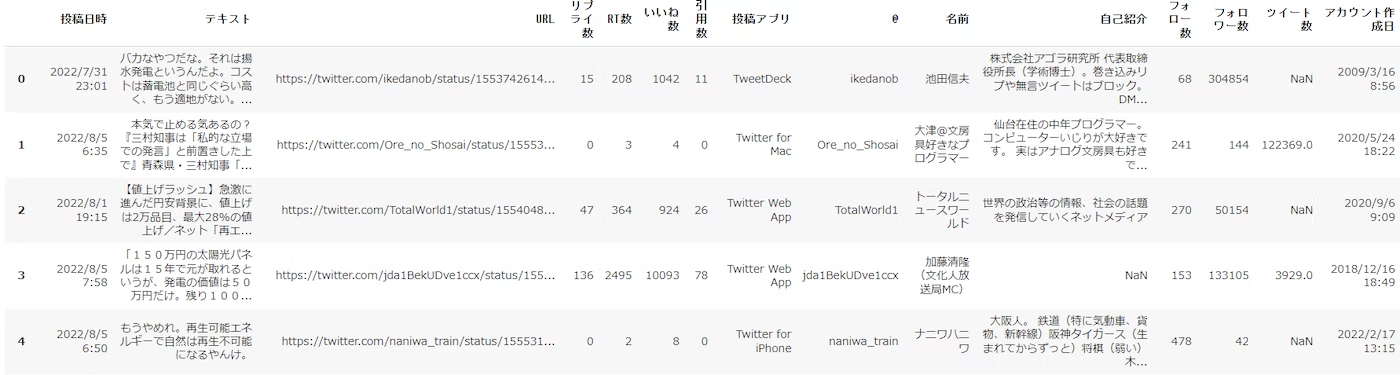
次に、テキスト分析したいデータカラム名を指定しています。

次に「再エネ」のtweetデータに訓練モデルを適用し、8つの感情スコアをデータフレームに格納しました。

各tweetデータ毎の8つの感情値が得られましたので、まず箱ひげ図を描いてみました。
- 「再エネ」に関するtweetは、期待の高さが突出しています。
- 次いで「恐れ」「嫌悪」「驚き」となっています。
- 「信頼」は低いですねぇ。「喜び」も高いとはいえないでしょう。

次に相関行列を描いてみました。 - 正の相関が高いのは、「怒り」と「嫌悪」、「喜び」と「信頼」です。
- 負の相関が高いのは、「期待」と「恐れ」、「期待」と「嫌悪」です。

Pair-plotも描きました。 - 何れかの感情が大きくなると、もう一方は減る傾向にあるものが目立ちます。
- ただ、0付近の打点も多いので単純な負の相関という感じではありません。

次にそれぞれのtweetがどのような感情傾向にあるかを折れ線グラフで見てみました。横軸はテキストのIDです。
値が大きい「期待」は、(見た目的に)振られてしまうのをさけるため非表示とし、他の感情との相関が低い「驚き」も非表示にしたのが以下のグラフです。
いくつかの感情が入り交じった複雑なtweetもありますが、多くのtweetは特定の感情で説明できそうです。(一つの感情が他の感情よりも飛び抜けて大きいデータが多い)

指定した感情と感情値に該当するtweet(テキスト)を表示させました。
以下は「期待」の値が高いtweetを表示させたものです。

「再エネ」で抽出したtweetデータのなかには、広告表記がいりまじったデータもあり「再エネと関係ないな」というものもありますが、「たしかに「期待」が感じられるな」というtweetがピックアップできているのは素直にすごいなと思います。
最後に感情分類したデータフレームをcsv保存できるようにしました。

所見
アンケートで得たお客様の声などは、なんとなく眺めていてもなんとなくしかわかりませんが、これを利用すると、
- 『「喜び」の声はこれらです。』等、感情ごとの声が取り出したり、ランキングを示したりできる。
- 頻出語との関係性を探れば、感情と語の関係を掴むことができたり、特定の感情を高める語が掴めたりする。
- ある感情を左右する別の感情を掴むことができるかもしれない。
などにつなげることができそうです。
これは、おもろいなぁ。
あらためて@izaki_shinさんに感謝いたします。ありがとうございます。
備考
- 訓練モデルの構築は、GPUでも約20分程度かかりました。GPU設定せずに実行した時のプログレス表示は70時間近く。。。となっていました。繰り返し実行する可能性がある場合はモデル保存したほうがよさそう。
- 自然言語処理を実行するにあたって形態素解析などが必要ないってのは魅力。
- 最近、ChatGPTに教えを乞う機会が増えました。Pythonで何ができるかってのはある程度知っていないと乞えませんので、この手の知識はいりますが、どうコードを組み立るかは乞えるから。。。この面の学習意欲は下がり気味・・・^^;。
実行コード
WRIMEデータセットで感情分析の分類器を整備されるまでの手続きは、以下のURLを確認くださいね。
上記URLのコード実行の後、以下のコードを実行することで、この記事で実行した内容となります。
ライブラリのインストールとインポート
!pip install pandas-bokeh
!pip install japanize-matplotlib
!pip install japanize-matplotlib
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer
from datasets import Dataset, load_metric
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
sns.set(font='IPAexGothic')
モデルの保存
#@title Google Driveマウント
from google.colab import drive
drive.mount('/content/drive')
モデルを /content/drive/My Drive/ に 8senti_model.pth というファイル名で保存しています。
#@title モデル保存
import torch
import shutil
# モデル保存
torch.save(model.state_dict(), '8senti_model.pth')
# Colabの作業ディレクトリからGoogle Driveにモデルを保存
source = '8senti_model.pth'
destination = '/content/drive/My Drive/'
shutil.copy(source, destination)
保存したモデルの読込み
#@title Google Driveマウント
from google.colab import drive
drive.mount('/content/drive')
GPUで学習しGPUで読む場合と、GPUで学習してCPUで読む場合はコード記述が異なるようです・・・以下は、GPUで学習してCPUで読むコードとしています。
#@title モデル読込み
import torch
# Plutchikの8つの基本感情
emotion_names = ['Joy', 'Sadness', 'Anticipation', 'Surprise', 'Anger', 'Fear', 'Disgust', 'Trust']
emotion_names_jp = ['喜び', '悲しみ', '期待', '驚き', '怒り', '恐れ', '嫌悪', '信頼'] # 日本語版
num_labels = len(emotion_names)
# Google Driveからモデルを読み込み
model_path = '/content/drive/My Drive/8senti_model.pth'
checkpoint = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_labels)
#model.load_state_dict(torch.load(model_path)) #GPUで読む場合
model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu'))) #CPUで読む場合
モデルが読込めれば、以下実行できるはずです。
#@title サンプル入力文で8つの感情をグラフ表示 { run: "auto" }
#@markdown **<font color= "Crimson">ガイド</font>:以下のドロップダウンからグラフ表示したい入力文を選んでください。**</font>
text = '今日から長期休暇だぁーーー!!!' #@param ['今日から長期休暇だぁーーー!!!', 'この書類にはコーヒーかかってなくて良かった…。不幸中の幸いだ。', 'なんで自分だけこんな目に遭うんだ……','君ならきっとやってくれると思っていたよ!', 'え、今日って休校だったの?', '明日のプレゼンうまくできるかなぁ…', 'あぁー、イライラするっ!!']
# https://www.delftstack.com/ja/howto/numpy/numpy-softmax/
def np_softmax(x):
f_x = np.exp(x) / np.sum(np.exp(x))
return f_x
def analyze_emotion(text, show_fig=False, ret_prob=False):
# 推論モードを有効か
model.eval()
# 入力データ変換 + 推論
tokens = tokenizer(text, truncation=True, return_tensors="pt")
tokens.to(model.device)
preds = model(**tokens)
prob = np_softmax(preds.logits.cpu().detach().numpy()[0])
out_dict = {n: p for n, p in zip(emotion_names_jp, prob)}
# 棒グラフを描画
if show_fig:
plt.figure(figsize=(8, 3))
df = pd.DataFrame(out_dict.items(), columns=['name', 'prob'])
sns.barplot(x='name', y='prob', data=df)
plt.title('入力文 : ' + text, fontsize=15)
if ret_prob:
return out_dict
# 動作確認
analyze_emotion(text, show_fig=True)
データ読込み
まず、データの読込みです。
データの読込みにおいては、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Initial Settings { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','蜘蛛の糸','Upload_csv','Upload_txt']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
#@markdown **<font color= "Crimson">ガイド</font>:Upload 選択 ⇒ [ファイル選択]ボタンをクリックしてください。サンプルデータの場合は自動で読み込みます。**
import pandas as pd
import numpy as np
pd.set_option('display.unicode.east_asian_width', True)
from google.colab import files
import codecs
import warnings
warnings.simplefilter('ignore')
# データの読み込み
if dataset =='Upload_csv':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
elif dataset =='Upload_txt':
files = files.upload()
filename = list(files.keys())[0]
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
elif dataset == "蜘蛛の糸":
#蜘蛛の糸のテキストデータ(zipファイル)をダウンロード
!curl -O "https://www.aozora.gr.jp/cards/000879/files/92_ruby_164.zip"
#zipファイルを解凍
!unzip 92_ruby_164.zip
#文章切り出し(=注釈削除 [冒頭削除:tail -n +**][末尾削除:head -n -**] 任意設定要)
!tail -n +18 kumono_ito.txt | head -n -15 > kumono_ito_data.txt
#テキストファイル読み込み
text_file = open('/content/kumono_ito_data.txt',encoding = 'shift_jis')
def main():
# Shift_JIS ファイルのパス
shiftjis_path = 'kumono_ito_data.txt'
# UTF-8 ファイルのパス
filename = 'kumono_ito_utf.txt'
# 文字コードを utf-8 に変換して保存
fin = codecs.open(shiftjis_path, "r", "shift_jis")
fout_utf = codecs.open(filename, "w", "utf-8")
for row in fin:
fout_utf.write(row)
fin.close()
fout_utf.close()
if __name__ == '__main__':
main()
filename = 'kumono_ito_utf.txt'
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
lines = [l.strip() for l in lines]
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
df = pd.DataFrame(sentences, columns = ['テキスト'], index=None)
#空白をNaNに置き換え
df['テキスト'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['テキスト'], inplace=True)
#pd.set_option('display.max_colwidth', None)
#display(df.style.set_properties(**{'text-align': 'left'}))
df.head()

次に、テキスト処理するカラムを指定します。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラム名の入力 { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
テキストの感情スコアの表示・可視化・ピックアップ
#@title テキストの8つ感情スコアをデータフレームに格納
# corpus_list(前処理し、データフレームに格納したテキストをリスト化)
corpus_list = df[column_name].to_list()
df = pd.DataFrame([])
for text2 in corpus_list:
# 推論モードを有効か
model.eval()
# 入力データ変換 + 推論
tokens = tokenizer(text2, truncation=True, return_tensors="pt")
tokens.to(model.device)
preds = model(**tokens)
prob = np_softmax(preds.logits.cpu().detach().numpy()[0])
d = {'テキスト':text2, '喜び':prob[0], '悲しみ':prob[1],'期待':prob[2],
'驚き':prob[3], '怒り':prob[4], '恐れ':prob[5],'嫌悪':prob[6], '信頼':prob[7]}
data = pd.DataFrame(d.values(),index=d.keys()).T
df = df.append( data )
df = df.reset_index(drop=True)
#print(text2,prob)
df[['喜び','悲しみ','期待','驚き','怒り','恐れ','嫌悪','信頼']] = df[['喜び','悲しみ','期待','驚き','怒り','恐れ','嫌悪','信頼']].astype(float)
df
#@title Box-plot
import seaborn as sns
sns.boxplot(data=df);
#@title Pair-plot
sns.pairplot(df);
#@title Line-plot with rangetool
df_=df.drop('テキスト', axis=1)
df_ = df_.astype(float)
import pandas_bokeh
pandas_bokeh.output_notebook()
df_.plot_bokeh(figsize=(1000,400),rangetool=True)
#@title Heatmap of correlation matrix
df_corr = df_.corr()
#print(df_corr)
plt.rcParams["figure.figsize"] = (10, 8)
sns.heatmap(df_corr, vmax=1, vmin=-1, center=0, annot=True)
senti = '期待' #@param ['喜び','悲しみ','期待','驚き','怒り','恐れ','嫌悪','信頼']
display_record_number_slider = 10 #@param {type:"slider", min:3, max:30, step:1}
min_number_slider = 0.5 #@param {type:"slider", min:0, max:1, step:0.1}
max_number_slider = 1.0 #@param {type:"slider", min:0, max:1, step:0.1}
#bool_index = df[senti] >= number_slider
bool_index = (df[senti] >= min_number_slider) & (df[senti] <= max_number_slider)
filtered_df = df[bool_index]
filtered_df = filtered_df.sort_values(by=senti, ascending=False)
display(filtered_df[0:display_record_number_slider])
#@title csv出力(☑ =実行)
csv_output = False #@param {type:"boolean"}
#csv出力
if csv_output == True:
df.to_csv('8senti_data.csv',encoding='utf_8_sig',index=False)
from google.colab import files
files.download('8senti_data.csv')
参考