作るもの
本記事では、日本語文の感情分析をするAIモデル を作ります。
入力文に含まれる感情を、8つの基本感情 の軸で推定します。
こんな感じです。
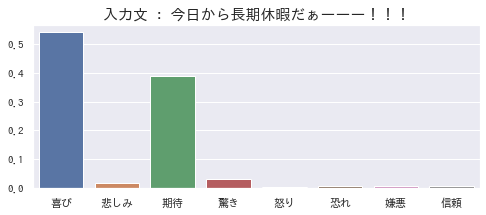
上記の棒グラフは、「今日から長期休暇だぁーーー!!!」という文章には「喜び」と「期待」の感情が含まれている、という推定結果を示したものです。
(夏季休暇を目前にして、「せっかくの休みで時間もあるし、あれもしたいし、これもしたいな♪」と喜びと期待に胸を躍らせていた私の気持ちが見透かされているようで怖いです……。)
概要
タイトルの通り、「Hugging Face」と「WRIMEデータセット」を用いて、8クラスのテキスト感情分類をしてみる、という内容です。
対象読者
- テキスト感情分類に興味がある方
- Hugging Face (Transformers)の初学者
- WRIMEデータセットについて知りたい方
内容目次
- 「Hugging Face」と「WRIMEデータセット」について
- WRIMEデータセットを使用する
- Transformersで感情分類モデルを訓練する
- いくつかの文章を入力して結果を見てみる
ソースコードは Notebook で公開しています。
本記事内では適宜省略している部分があります。詳しくはこちらをご覧ください。
Google Colaboratoryで開く場合はこちらから↓↓↓
Hugging Face (Transformers)
Hugging Face社が提供する、訓練済みモデルやデータセットを公開・共有するためのコミュニティです(こちら)。
また、Hugging Face社は、ディープラーニング関連のライブラリも提供しています。
Transformers が有名で、自然言語処理分野において活発に用いられています。上記コミュニティで公開されているモデルやデータセットを簡単に使用できますし、Tensorflow(Keras)とPytorch両方に対応しているので、一方しか使用経験がない方にも優しいです。
WRIMEデータセット
日本語の感情分析の研究用データセットです。GitHubで公開されています。
WRIMEという名前は、"dataset of Writers’ and Readers’ Intensities of eMotion for their Estimation." という意味のようです。
2つ、大きな特徴があります。
- 「主観感情」と「客観感情」のラベル
- 文章の書き手自身によるラベル(主観感情)と、書き手とは別の読み手によるラベル(客観感情)の両方が付与されています
- 客観感情ラベルは、読み手3名のラベルと、3名の平均ラベルがあります(合計4種類)
-
8種類 の感情の 強度_
- 感情の種類は、Robert Plutchik の、8つの基本感情 (喜び・悲しみ・期待・驚き・怒り・恐れ・嫌悪・信頼)となっています。
- 各感情に対して、強度を4段階(無、弱、中、強)でラベルが付与されています
1つ目の特徴に関して、私は主観感情と客観感情の区別を、そもそも意識したことがありませんでした。言われてみれば、これら2つは異なりますし、その違いは確かに重要ですよね。
実際、論文によると、主観感情と客観感情には差異がある(つまり、読み手は、文章から書き手の感情を正しく推察できていない)そうです。また、機械学習モデルは、主観感情より客観感情の方が高い精度で予測できたとのこと。主観感情には、文章だけでは推測できないものが含まれている、ということかもしれません。
2つ目の特徴に関して、極性(ポジティブorネガティブ)のデータセットは多いですが、数種類の感情ラベルのデータセットはあまり無いと思います。(日本語データセットでは他に私は知らないです。)ですので、こうして公開していることはとても有難いですね。
その他の情報は、以下の通りです。
- テキストは、SNSの投稿文章です。(おそらくTwitter)
- サンプル数
- Ver1:書き手80人、43,200件
- Ver2:書き手60人、35,000件(Ver1のサブセット)
- Ver2には、基本感情に加えて、感情極性(ポジネガ)がラベル付されています。
- ライセンスは、「研究用途のみ、再配布不可」となっています。
WRIMEデータセットの準備
それでは、本題に入っていきます!
問題設定
客観感情の平均ラベル を用いて、8クラスの分類タスク として扱っていきたいと思います。
Q. なぜ、客観感情の平均ラベル?
A. 主観感情は、書き手個人の性格や表現癖に依存している 可能性があります。そのため、客観感情(読み手が付与したラベル)、かつ、その平均値を用いることで、個人に依存しないより一般的なラベルとなり、推定結果の納得感が高くなることが期待されます。
Q. なぜ、8クラスの分類タスク?
A. WRIMTEデータセットの本来の用途としては感情強度を推定するタスクです。しかしながら、感情強度=0のサンプルが多い ため、やや扱いづらいです。そこで、今回は簡素化して、「相対的にどの感情が強いか?」というタスク(=分類タスク)として扱いたいと思います。
データセットの読み込み
それでは、WRIMEデータセットをダウンロードしていきましょう。
今回は、極性ラベルは不要なので、 Ver1 を使うことにします。
! wget https://github.com/ids-cv/wrime/raw/master/wrime-ver1.tsv
pandas.DataFrameとして読み込みます。
import pandas as pd
df_wrime = pd.read_table('wrime-ver1.tsv')
df_wrime.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 43200 entries, 0 to 43199
Data columns (total 44 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Sentence 43200 non-null object
1 UserID 43200 non-null int64
2 Datetime 43200 non-null object
3 Train/Dev/Test 43200 non-null object
4 Writer_Joy 43200 non-null int64
〜
11 Writer_Trust 43200 non-null int64
12 Reader1_Joy 43200 non-null int64
〜
19 Reader1_Trust 43200 non-null int64
20 Reader2_Joy 43200 non-null int64
〜
35 Reader3_Trust 43200 non-null int64
36 Avg. Readers_Joy 43200 non-null int64
〜
43 Avg. Readers_Trust 43200 non-null int64
dtypes: int64(41), object(3)
memory usage: 14.5+ MB
列数が多いので一部省略しています。
上述の通り、「主観感情(Writer_*)」「客観感情3名分(Reader{1,2,3}_*)」「客観感情の平均(Readers_*)」の三種類があることがわかります。また、各感情のラベルは、異なる列に分かれて格納されています。
前処理
感情強度が低いサンプルを除外
いずれの感情も強度が低いサンプルは、今回の問題設定(分類タスク)においては、悪影響を及ぼす可能性があるので、データセットから除外します。
感情強度は、無、弱、中、強で、ぞれぞれ0〜3で表されています。いずれの感情強度も1以下(無or弱)のサンプルを除外していきます。
# Plutchikの8つの基本感情
emotion_names = ['Joy', 'Sadness', 'Anticipation', 'Surprise', 'Anger',
# 客観感情の平均("Avg. Readers_*") の値をlist化し、新しい列として定義する
df_wrime['readers_emotion_intensities'] = df_wrime.apply(lambda x: [x['Avg. Readers_' + name] for name in emotion_names], axis=1)
# 感情強度が低いサンプルは除外する
# (readers_emotion_intensities の max が2以上のサンプルのみを対象とする)
is_target = df_wrime['readers_emotion_intensities'].map(lambda x: max(x) >= 2)
df_wrime_target = df_wrime[is_target]
訓練・テスト用に分割
Train/Dev/Testの列に基づいて、訓練とテスト用にデータセットを分割しておきます。
# train / test に分割する
df_groups = df_wrime_target.groupby('Train/Dev/Test')
df_train = df_groups.get_group('train')
df_test = pd.concat([df_groups.get_group('dev'), df_groups.get_group('test')])
print('train :', len(df_train)) # train : 17104
print('test :', len(df_test)) # test : 1133
Transformersで感情分類モデルを訓練する
環境構築
まずは、Transformersをインストールします。
# HuggingFace Transformers のインストール
# - transformers : 主たるモジュール(モデルやトークナイザ)
# - datasets : HuggingFaceで、データセットを扱うためのモジュール
# cf. https://huggingface.co/docs/transformers/installation
! pip install transformers datasets
# 東北大学の日本語用BERT使用に必要なパッケージをインストール
! pip install fugashi ipadic
訓練済みモデルの読み込み
訓練済みモデルには、東北大学の乾研究室が公開しているモデルを使用します。
いくつか種類がありますが、bert-base-japanese-whole-word-maskingを使用します。
(参考)
「Whole Word Masking」は、事前訓練の方法の一種です。
BERTの事前学習では、入力文の一部を隠し(マスクし)、隠された部分を周囲の情報から推定する問題を解きます。「Whole Word Masking」は、その際のマスクの方法が、従来の方法と少し異なるのです。一般的に「Whole Word Masking」により精度が向上するようです。
分類タスク用のモデルを作りたいので、AutoModelForSequenceClassificationを使用します。
from_pretrained()で、使用する訓練済みモデルと、クラス数を指定します。すると、訓練済みモデルをHuggingFaceのサーバからダウンロードし、指定したクラス数に応じたモデルを生成してくれます。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 使用するモデルを指定して、トークナイザとモデルを読み込む
checkpoint = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=8)
データを入力形式に変換
以下のように、データの形式をTransformers用に変換していきます。
- pandas.DataFrame から datasets.Dataset に変換
- Tokenizerを適用(モデル入力のための前処理)
from datasets import Dataset
# 1. Transformers用のデータセット形式に変換
# pandas.DataFrame -> datasets.Dataset
target_columns = ['Sentence', 'readers_emotion_intensities']
train_dataset = Dataset.from_pandas(df_train[target_columns])
test_dataset = Dataset.from_pandas(df_test[target_columns])
# 2. Tokenizerを適用(モデル入力のための前処理)
def tokenize_function(batch):
"""Tokenizerを適用 (感情強度の正規化も同時に実施する)."""
tokenized_batch = tokenizer(batch['Sentence'], truncation=True, padding='max_length')
tokenized_batch['labels'] = [x / np.sum(x) for x in batch['readers_emotion_intensities']] # 総和=1に正規化
return tokenized_batch
train_tokenized_dataset = train_dataset.map(tokenize_function, batched=True)
test_tokenized_dataset = test_dataset.map(tokenize_function, batched=True)
訓練を実行
Transformers のTrainerを用いて訓練します。
自分自身で訓練用のコードを書かないでよいので、とても便利です。
また、バッチサイズやエポック数などの訓練時の設定は、TrainingArgumentsを用いて指定します。
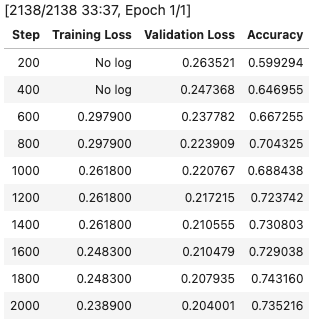
ここでは、バッチサイズ=8、エポック数=1としています。
もう少しエポック数(学習回数)を増やした方がよいかもしれないですが、それなりに時間がかかりそうだったので1エポックとしました。(1エポックでも、Google ColaboratoryでGPUを使用して、30分程度かかりました。)
from transformers import TrainingArguments, Trainer
from datasets import load_metric
# 評価指標を定義
# https://huggingface.co/docs/transformers/training
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
label_ids = np.argmax(labels, axis=-1)
return metric.compute(predictions=predictions, references=label_ids)
# 訓練時の設定
# https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/trainer#transformers.TrainingArguments
training_args = TrainingArguments(
output_dir="test_trainer",
per_device_train_batch_size=8,
num_train_epochs=1.0,
evaluation_strategy="steps", eval_steps=200) # 200ステップ毎にテストデータで評価する
# Trainerを生成
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized_dataset,
eval_dataset=test_tokenized_dataset,
compute_metrics=compute_metrics,
)
# 訓練を実行
trainer.train()
文章を入力して結果を見てみる
文章を入力して、モデルを実行するスクリプトを作成します。
得られた出力を、わかりやすいように棒グラフとして描画します。
注意点としては、Transformersのモデルの出力は、logit(Softmaxを適用する前の値)である点です。今回は確率分布を見たいので、別途Softmaxを適用する必要があります。
# ソフトマックス関数
# https://www.delftstack.com/ja/howto/numpy/numpy-softmax/
def np_softmax(x):
f_x = np.exp(x) / np.sum(np.exp(x))
return f_x
def analyze_emotion(text, show_fig=False):
# 推論モードを有効化
model.eval()
# 入力データ変換 + 推論
tokens = tokenizer(text, truncation=True, return_tensors="pt")
tokens.to(model.device)
preds = model(**tokens)
prob = np_softmax(preds.logits.cpu().detach().numpy()[0])
out_dict = {n: p for n, p in zip(emotion_names_jp, prob)}
# 棒グラフを描画
if show_fig:
plt.figure(figsize=(8, 3))
df = pd.DataFrame(out_dict.items(), columns=['name', 'prob'])
sns.barplot(x='name', y='prob', data=df)
plt.title('入力文 : ' + text, fontsize=15)
else:
print(out_dict)
# 使用例 : analyze_emotion('今日から長期休暇だぁーーー!!!')
それでは、実際にいくつか文章を入力して、結果をみていきます。
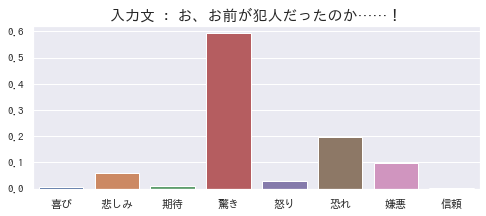
「驚き」が一番強いですが、それと同時に、犯罪行為に対する「恐れ」や「嫌悪」の感情を推定できています。もし犯人が友人や家族だったら、「悲しみ」も当然含まれるので、妥当な結果と思います。
ちなみに、最近「名探偵コナン」にハマっています。
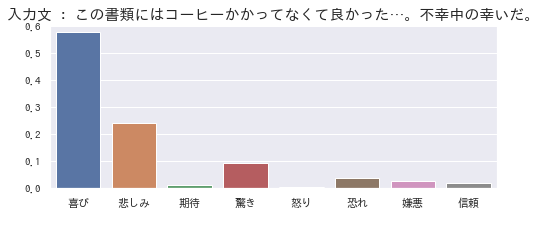
「喜び」は、安心した気持ちを示しているのかなと思います。
不幸中の幸いで全体的にはポジティブが強く出ていますが、コーヒーぶちまけた「悲しみ」も含まれているようです。突然の出来事に対する「驚き」も表れていますね。
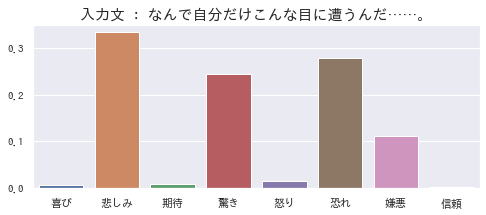
どんな目にあったのかは知らないですが、確かに、「悲しみ」「驚き」「恐れ」「嫌悪」が入り混じってそうですよね。その複雑な気持ちを、ちゃんと推定できているように見えます。
おわりに
HuggingFaceとWRIMEデータセットを用いて、感情推定モデルを作成しました。
異なる感情が混在するような文章でも、感情の分布をそれらしく推定できる ことを確認しました。
「感情の分布」の推定は、WRIMEデータセットに8種類の感情のラベルが付与されているからこそ出来たこと です。感情極性(ポジティブ・ネガティブ)のみのデータセットが多い中、こうしたデータセットはありがたいなぁと感じました。
また、HuggingFace Transformersを今回初めて使用しましたが、便利ですね…!
今回は分類タスクという最もベーシックな使い方を確認しましたが、また別の使い方も試していきたいなと思います。
最後までお読みいただき、ありがとうございました。
少しでも楽しんでいただけたり、参考になる部分があったりしましたら幸いです。
それでは!(*ˊᗜˋ)ノシ