
はじめに
以前、これをKJ法のラベルピックアップを楽にするため、共起ネットワークのコミュニティ抽出を利用したテキスト分類を実行しました。
とても簡単にラベルがピックアップできるようになり、KJ法を行う上で助けとなりました。
強い共起関係を持つグループを把握することができるコミュニティ抽出は、最終的に志を抽象化して関連付けるKJ法と親和性が高いということもあるのだと思います。
大量のテキストデータを分類したいという場合、他にも様々な方法があります。
これまで、テキストを形態素解析し、BoWやTF-IDF、Word2Vec等でベクトル化、次元圧縮によるグルーピングに試みましたが、なかなかしっくり来たことがありません。
私の愚薄さによるところが大きいと思いますが、「教師なし学習」というのはむつかしいですね。
今回も、どうなることやらという感は否めませんが、以前から興味があったLDAを試行してみることにしました。
用語の説明
トピックモデル
ニュース記事や口コミなどのテキストデータを分析すると、政治やスポーツやレストランなどのトピックが見つかります。
トピックモデルは、テキスト全体から各テキストのトピック(話題)を抽出する手法です。
LDA
LDA、トピックモデルの一種です。
LDAは、テキスト全体でK個のトピックがあると仮定し、各文書はそのK個のトピックから一部を選んだ混合比率で生成されると仮定します。また、各単語はその混合比率に従って出現すると仮定します。
pyLDAvis
pyLDAvisは、トピックモデルをインタラクティブに可視化するPythonライブラリです。
pyLDAvisでは、LDAの結果が2つのグラフで表示されます。ひとつは、各トピックのテキスト全体における重要度を円の大きさで示したグラフ。もうひとつは、選択したトピックにおける単語の出現頻度を棒グラフで示したグラフです。
実行したこと
pyLDAvis実行結果
以下をUIで設定できるようにしています。
vector_type: BoW か TF-IDF のいずれかを選択
num_topics: 仮定するトピックス数を指定
mds: mmds か tsne のいずれかを選択
以下は、BoW、トピックス数5、mmdsで実行し、トピック1を選択した時の表示です。
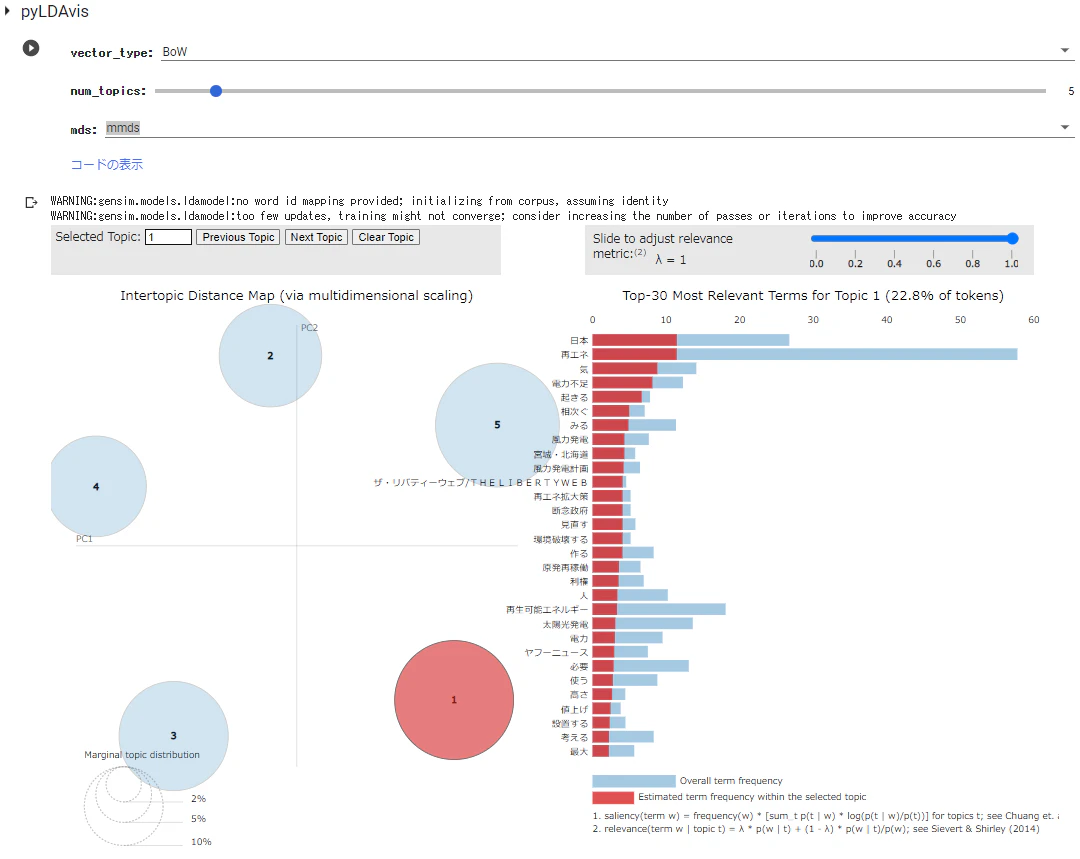
トピック2を選択した時は以下です。
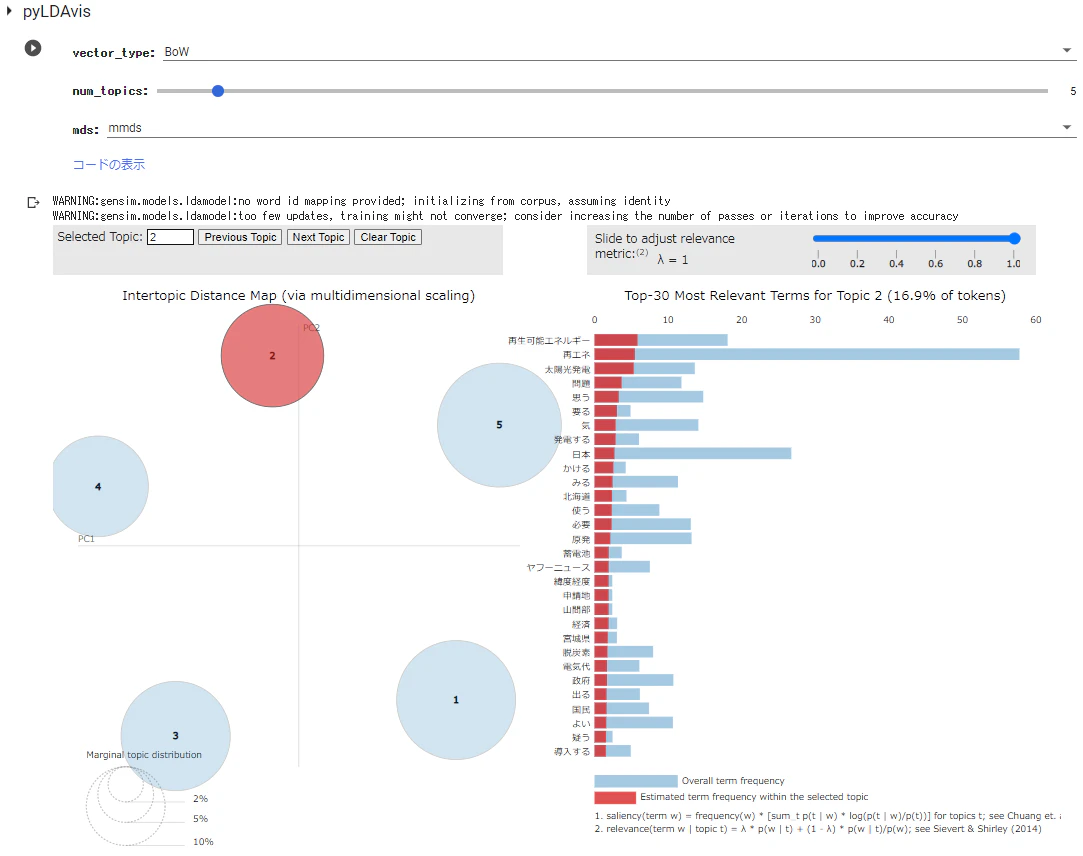
それぞれのトピックにおいて、テキストがどのような単語で構成されているかがわかります。
ただ、適用したデータにおいては、どのトピックも多くの単語が万遍なく・・・という状況でしたので、各トピックを要約するのはむつかしそうです。
TF-IDFでも実行してみましたが、同じく要約はむつかしく思えました。
元々、再エネというキーワードでピックアップしたtweetという時点で、トピック=再エネ と言われれば、それまでかもしれません。より多岐にわたるバリエーションのデータで適用した方がよさそうです。
ちなみに、
λ は単語のトピックに対する関連度(relevance)を表す指標です。関連度は、単語のトピック内での出現頻度と、全体での出現頻度のバランスを考えたものです。
- λ=1 だと、単語はトピック内での出現頻度だけでソートされますので、そのトピックによく出てくる単語が上位に表示されます。しかし、その単語が他のトピックでもよく出てくる場合は、そのトピックを特徴づける単語とは言えません。
- λ=0 だと、単語は「リフト」という指標でソートされます。リフトとは、ある単語があるトピックに出現する確率を全体で出現する確率で割ったものです。つまり、そのトピックに特有な単語ほど高い値になります。しかし、その単語がそのトピックではあまり出てこない場合は、そのトピックを理解する助けになりません。
そこで、λ=0 から 1 まで変化させることで、出現頻度とリフトのバランスを取った関連度が計算されます。一般的には0.6程度が適切な値だと言われているようです。
最後に
うーん、「教師なし学習」によるテキスト分類に、またも打ち破れたり・・・という感じです。
これは LDA の問題ではなく、取り扱うデータ等の影響もあると思いますので、よいデータが見つかった時に再チャレンジしたいと思います。
pyLDAvis は、私がかなりお世話になっている自然言語ライブラリnlplot で 以前は実行できましたが、残念ながら現在はサポートされていません。
ただ、Google Colabで実行することはできますので、ご興味ある方はぜひ。
実行コード
GoogleColabで実行するためのライブラリのインストール
以下のライブラリや辞書をインストールしました。
!pip install sudachipy sudachidict_core
!pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
!pip install https://github.com/megagonlabs/UD_Japanese-GSD/releases/download/r2.9-NE/ja_gsdluw-3.2.0-py3-none-any.whl
import pkg_resources, imp
imp.reload(pkg_resources)
このおまじないがないと、GiNZAインストール後にランタイムの再起動が求められますが、このおまじないの実行により、インストールするだけ(=ランタイムの再起動は不要)になります。
!apt-get -y install fonts-ipafont-gothic
!pip install pyLDAvis==2.1.2
データ読込み
まず、データの読込みです。
データの読込みにおいては、GoogleColabのフォーム機能を利用し、データセットを選択できるようにしています。
選択肢は2つ。tweetサンプルデータ(tweet_data_sampleを選択)と、任意のcsvファイル(Uploadを選択)です。
※tweet_data_sampleは、Githubにアップしたこの記事の適用データです。
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'tweet_data_sample' #@param ['tweet_data_sample','Upload']
以下を実行すると、datasetの選択に沿ったデータが読み込まれ、読み込んだデータをデータフレームに反映し、表示します。
#@title データ読込み
import pandas as pd
from google.colab import files
# データの読み込み
if dataset =='Upload':
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target,encoding='utf-8')
elif dataset == 'tweet_data_sample':
file_url ='https://raw.githubusercontent.com/hima2b4/Natural-language-processing/main/TwExport_20220806_152219.csv'
df = pd.read_csv(file_url,encoding='utf-8')
display(df)

次に、テキスト処理するカラムを指定します。
これもGoogleColabのフォーム機能を利用し、カラム名を入力することで指定できるようにしています。
今回のデータの場合、「テキスト」カラムが対象となりますので、テキストと入力しています。
#@title 意見カラム名の入力 { run: "auto" }
column_name = 'テキスト' #@param {type:"raw"}
テキスト処理
つぎは、テキスト処理です。
テキストから不要語を取りのぞく前処理を行った後、テキスト処理を実行して単語に分解、指定した品詞の単語を取り出し、stop_wordsに指定した単語があれば除外します。
その後、行毎に取り出した単語をデータフレームに格納しています。
品詞とstop_wordsの指定は、GoogleColabのフォーム機能を利用しています。
フォーム機能を利用するとコード操作が不要となりますので、とても便利です。
#@title 使用する品詞とストップワードの指定
#@markdown ※include_pos:使用する品詞,stopwords:表示させない単語 ← それぞれ任意に追加と削除が可能
include_pos = ('NOUN', 'PROPN', 'VERB', 'ADJ')#@param {type:"raw"}
stop_words = ('する', 'ある', 'ない', 'いう', 'もの', 'こと', 'よう', 'なる', 'ほう', 'いる', 'くる', 'お', 'つ', 'とき','ところ', '為', '他', '物', '時', '中', '方', '目', '回', '事', '点', 'ため') #@param {type:"raw"}
#@title テキスト処理実行
import spacy
import pandas as pd
import re
# 意見に空行がある場合は削除
df[column_name] = df[column_name].replace('\n+', '\n', regex=True)
# テキストデータの前処理
def text_preprocessing(text):
# 改行コード、タブ、スペース削除
text = ''.join(text.split())
# URLの削除
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', text)
# メンション除去
text = re.sub(r'@([A-Za-z0-9_]+)', '', text)
# 記号の削除
text = re.sub(r'[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”〈〉『』【】&*・()$#@。、?!`+¥]', '', text)
return text
df[column_name] = df[column_name].map(text_preprocessing)
#モデルをja_gsdluw(国語研長単位)に
nlp = spacy.load("ja_gsdluw")
# 行毎に出現する単語をリストに追加
words_list=[] #行毎の単語リスト
for doc in nlp.pipe(df[column_name]):
sep_word=[token.lemma_ for token in doc if token.pos_ in include_pos and token.lemma_ not in stop_words]
words_list.append(sep_word)
#print(word_list)
#行毎の意見 → 単語に分解し、カラムに格納
df['separate_words']= [s for s in words_list]
# 参考:対象カラムに形態素解析実行、すべての形態素結果をseparateカラムに格納
#df['separate'] = [list(nlp(s)) for s in df[column_name]
③ pyLDAvis
#@title pyLDAvis
vector_type = 'BoW' #@param ['BoW', 'TF-IDF']
num_topics = 5 #@param {type:"slider", min:2, max:50, step:1}
mds = 'mmds' #@param ['mmds', 'tsne']
from gensim.corpora.dictionary import Dictionary
from gensim.models import LdaModel
import warnings
warnings.filterwarnings('ignore')
# LDAの可視化
import pyLDAvis
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
# 分かち書きしたデータを作成する
sentences = df['separate_words']
# 単語と単語IDを対応させる辞書の作成
dictionary = Dictionary(sentences)
# LdaModelが読み込めるBoW形式に変換
corpus = [dictionary.doc2bow(text) for text in sentences]
# tfidf
tfidf = models.TfidfModel(corpus)
# corpus_tfidf
corpus_tfidf = tfidf[corpus]
if vector_type == 'TF-IDF':
lda = LdaModel(corpus_tfidf, num_topics = num_topics)
vis = pyLDAvis.gensim.prepare(lda, corpus_tfidf, dictionary, n_jobs = 1, mds = mds, sort_topics = False)
else:
lda = LdaModel(corpus, num_topics = num_topics)
vis = pyLDAvis.gensim.prepare(lda, corpus, dictionary, n_jobs = 1, mds = mds, sort_topics = False)
pyLDAvis.display(vis)
参考