きっかけ
Python,機械学習の勉強を始めて、はや二ヶ月。
そろそろ、その成果をアウトプットしたいと思い、その題材を探していたところ、友達と天皇賞(春)を本気で予想することになった。そこで、まさに思い付いたのが、機械学習での競馬予測である。
目標
今回は3位以内(複勝)に入る馬を予測すること。
流れ
1.スクレイピングをして、過去のレース情報と馬の過去戦績を収集する。
2.データの前処理
3.モデルの構築
4.GridSearchCVによってモデルの調整
1.スクレイピングをして、過去のレース情報と馬の過去戦績を収集する
1.1 過去のレース情報を取得
競馬のサイトはたくさんあるんですが、今回は以下のサイトのデータベースにあるレース情報をスクレイピングをしました。
https://www.netkeiba.com/
受験時代の名残か、やはり何かを研究する際は過去の情報が、一番役に立つということが染み込んでいる私は、天皇賞(春)の過去レース結果14年分をデータとして取得することにした。
netkeiba.comではそれぞれのレースに規則的にrace-idが割り振られているので、天皇賞(春)の過去14年分のrace_idをrace_id_listに入れた。
以下参照(race/以下がrace_idです)
https://db.netkeiba.com/race/201908030311/
import pandas as pd
import time
import re
import requests
from bs4 import BeautifulSoup
def scrape_race_results(race_id_list):
race_results={}
for race_id in race_id_list:
url='https://db.netkeiba.com/race/'+race_id
html=requests.get(url)
html.encoding='EUC-JP'
soup=BeautifulSoup(html.text,'html.parser')
df=pd.read_html(url)[0]
#日付のデータもスクレイピング
text=soup.find('div',attrs={'class':'data_intro'}).find_all('p')[1].text
info=re.findall(r'\w+',text)[0]
race_date_list=[info]*len(df.index)
#horse_id,jockey_idのスクレイピング
html=requests.get(url)
html.encoding='EUC-JP'
soup=BeautifulSoup(html.text,'html.parser')
#horse_id
horse_id_list=[]
hr_list=soup.find('table',attrs={'summary':'レース結果'})
hr_list=hr_list.find_all('a',attrs={'href':re.compile(r'^/horse')})
for a in hr_list:
horse_id=re.findall(r'\d+',a['href'])
horse_id_list.append(horse_id[0])
#jockey_id
jockey_id_list=[]
jc_list=soup.find('table',attrs={'summary':'レース結果'})
jc_list=jc_list.find_all('a',attrs={'href':re.compile(r'^/jockey')})
for a in jc_list:
jockey_id=re.findall(r'\d+',a['href'])
jockey_id_list.append(jockey_id[0])
df['horse_id']=horse_id_list
df['jockey_id']=jockey_id_list
df['日付']=race_date_list
race_results[race_id]=df
#スクレイピングを行う際、コンピューターに負荷をかけないためにtime.sleep()を使用する
time.sleep(1)
return race_results
results=scrape_race_results(race_id_list)
# indexにそれそれのrace_idを入れる
for key in results.keys():
results[key].index=[key]*len(results[key])
results1=pd.concat([results[key] for key in results.keys()],sort=False)
↓
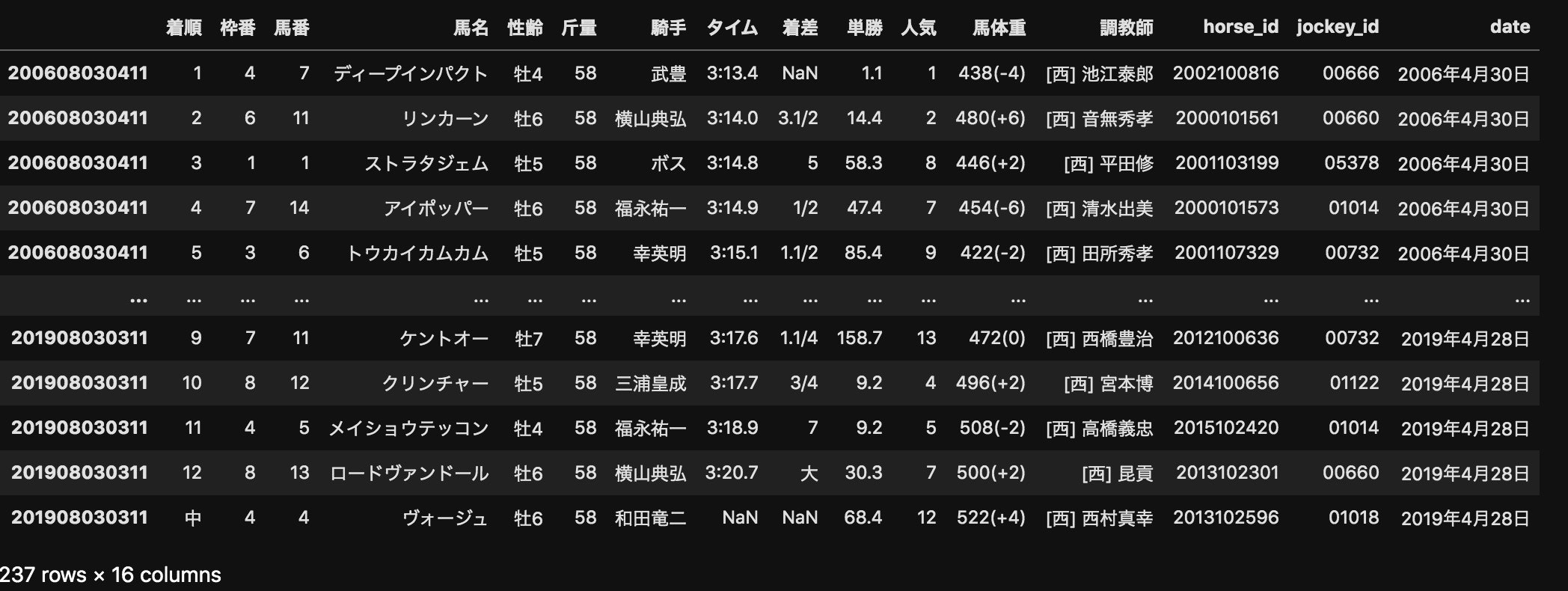
これで過去14年分の天皇賞(春)のデータをresults1というデータフレームに入れることができた。
ちなみに、pd.read_htmlは本当に便利でした。
1.2 馬の過去戦績を取得
netkeiba.comにはそれぞれの馬の過去レースの結果がまとめられているので、次はそこからスクレイピングをしようと思います。
以下参照(horse/以下がhorse_idです)
https://db.netkeiba.com/horse/2015105075/
horse_id_list=results1['horse_id'].unique()
def scrape_horse_results(horse_id_list):
horse_results={}
for horse_id in horse_id_list:
url='https://db.netkeiba.com/horse/'+horse_id
df=pd.read_html(url)[3]
if df.columns[0]=='受賞歴':
df=pd.read_html(url)[4]
horse_results[horse_id]=df
time.sleep(1)
return horse_results
horse_results=scrape_horse_results(horse_id_list)
for key in horse_results.keys():
horse_results[key].index=[key]*len(horse_results[key])
horse_results=pd.concat([horse_results[key] \
for key in horse_results.keys()],sort=False)
↓
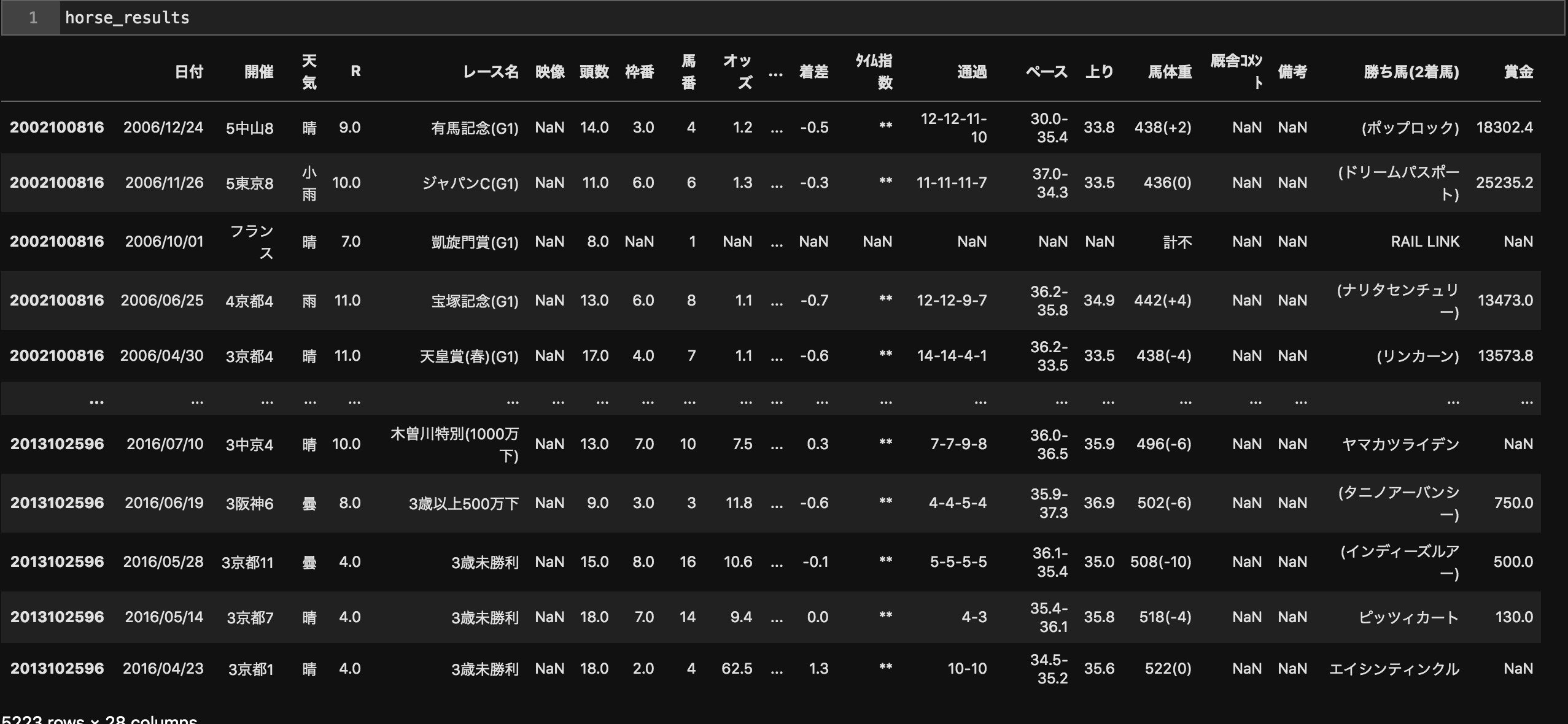
こんな感じにデータを取得することができました。
2.データの前処理
まず過去レースの情報が入ったresults1について前処理を行おうと思います。
# 前処理の関数を定義
def preprocessing(results):
# .copy()でresults自体が変わることを防ぐ
df=results.copy()
#着順が数字以外の物を取り除く
df=df[~(df['着順'].astype(str).str.contains('\D'))]
df['着順']=df['着順'].astype(int)
#性齢の性と年齢に分ける
df['性']=df['性齢'].map(lambda x:str(x)[0])
df['年齢']=df['性齢'].map(lambda x:str(x)[1:]).astype(int)
#馬体重を体重と体重変化に分ける
df['体重']=df['馬体重'].str.split('(',expand=True)[0].astype(int)
df['体重変化']=df['馬体重'].str.split('(',expand=True)[1].str[:-1].astype(int)
#データをfloatに変換
df['単勝']=df['単勝'].astype(float)
#日付のデータをdatetime型に変換
df['date']=pd.to_datetime(df['日付'],format='%Y年%m月%d日')
#不要な列の削除
df.drop(['タイム','着差','調教師','性齢','馬体重','日付'],axis=1,inplace=True)
return df
↓
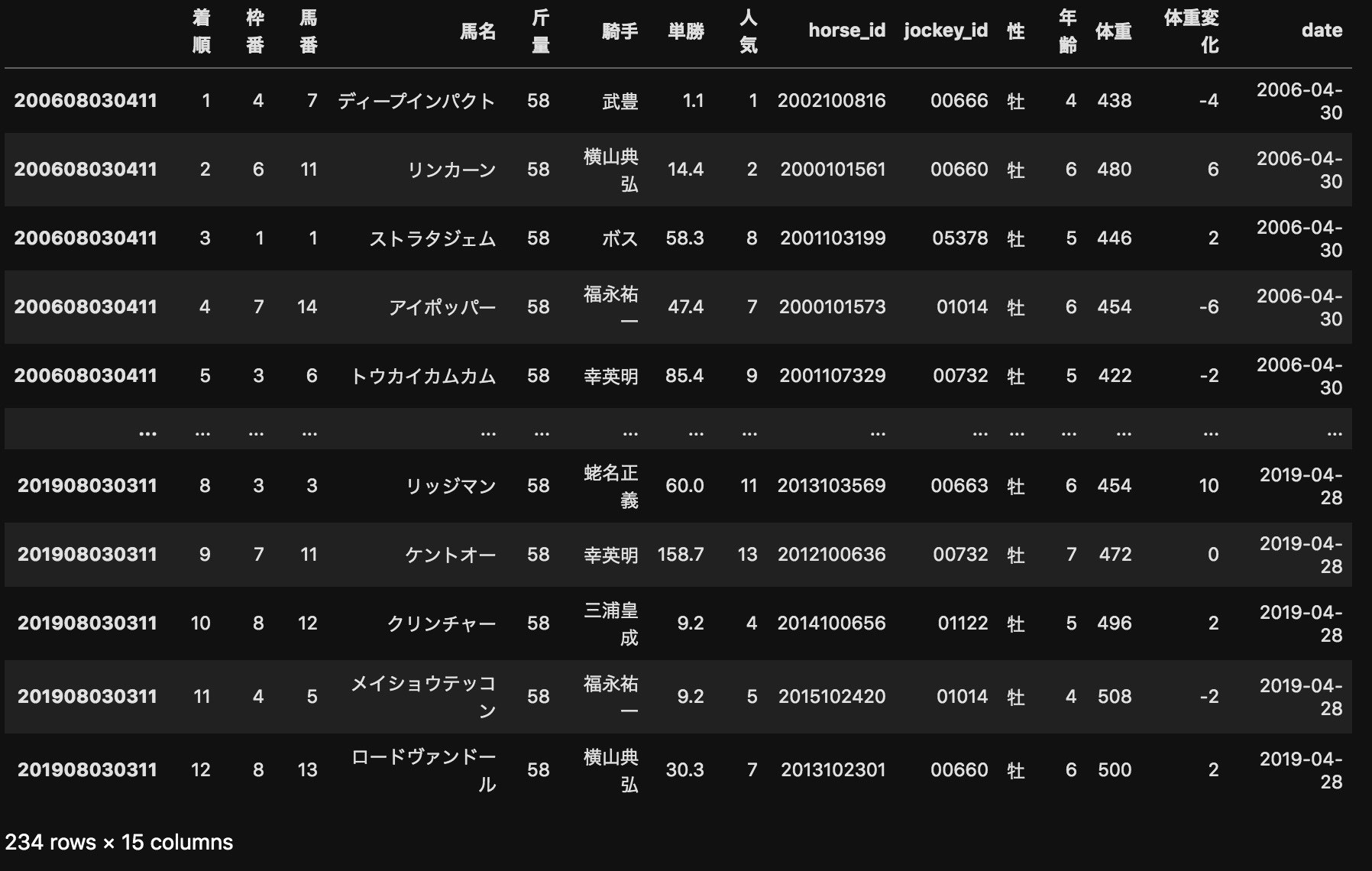
次は馬の過去戦績データの前処理を行っていこうと思います。
ただ今回は、特徴量として日付,着順,賞金だけを使っていきたいと思います。
ここの処理は関数が複数になるので、クラスを定義しました。
class HorseResults1:
def __init__(self,horse_results):
self.horse_results=horse_results[['日付','着順','賞金']]
self.preprocessing()
#馬の過去レースの前処理をする関数
def preprocessing(self):
df=self.horse_results.copy()
#着順が数字以外の物を取り除く
df['着順']=pd.to_numeric(df['着順'],errors='coerce')
df=df.dropna(subset=['着順'])
df['着順']=df['着順'].astype(int)
#日付をdatetime型に変換
df['date']=pd.to_datetime(df['日付'])
df.drop(['日付'],axis=1,inplace=True)
#賞金の欠損値に0を代入して全て数値に変換
df['賞金'].fillna(0,inplace=True)
self.horse_results = df
#dateを指定して、それより前の3レースの着順と賞金の平均を求める関数
def average(self,horse_id_list,date):
target_df=self.horse_results.loc[horse_id_list]
filtered_df=target_df[target_df['date'] < date].\
sort_values('date',ascending=False).groupby(level=0).head(3)
average=filtered_df.groupby(level=0)[['着順','賞金']].mean()
return average.rename(columns={'着順':'着順平均(3)','賞金':'賞金平均(3)'})
#元のレース結果のデータフレームに過去3レースの着順と賞金の平均をとったデータフレームをマージ
def merge(self,results,date):
df=results[results['date']==date]
horse_id_list=df['horse_id']
merged_df=df.merge(self.average(horse_id_list,date),left_on='horse_id',right_index=True,how='left')
return merged_df
def merge_all(self,results):
date_list1=results['date'].drop_duplicates().tolist()
merged_df=pd.concat([self.merge(results, date) for date in date_list1 ])
return merged_df
↓
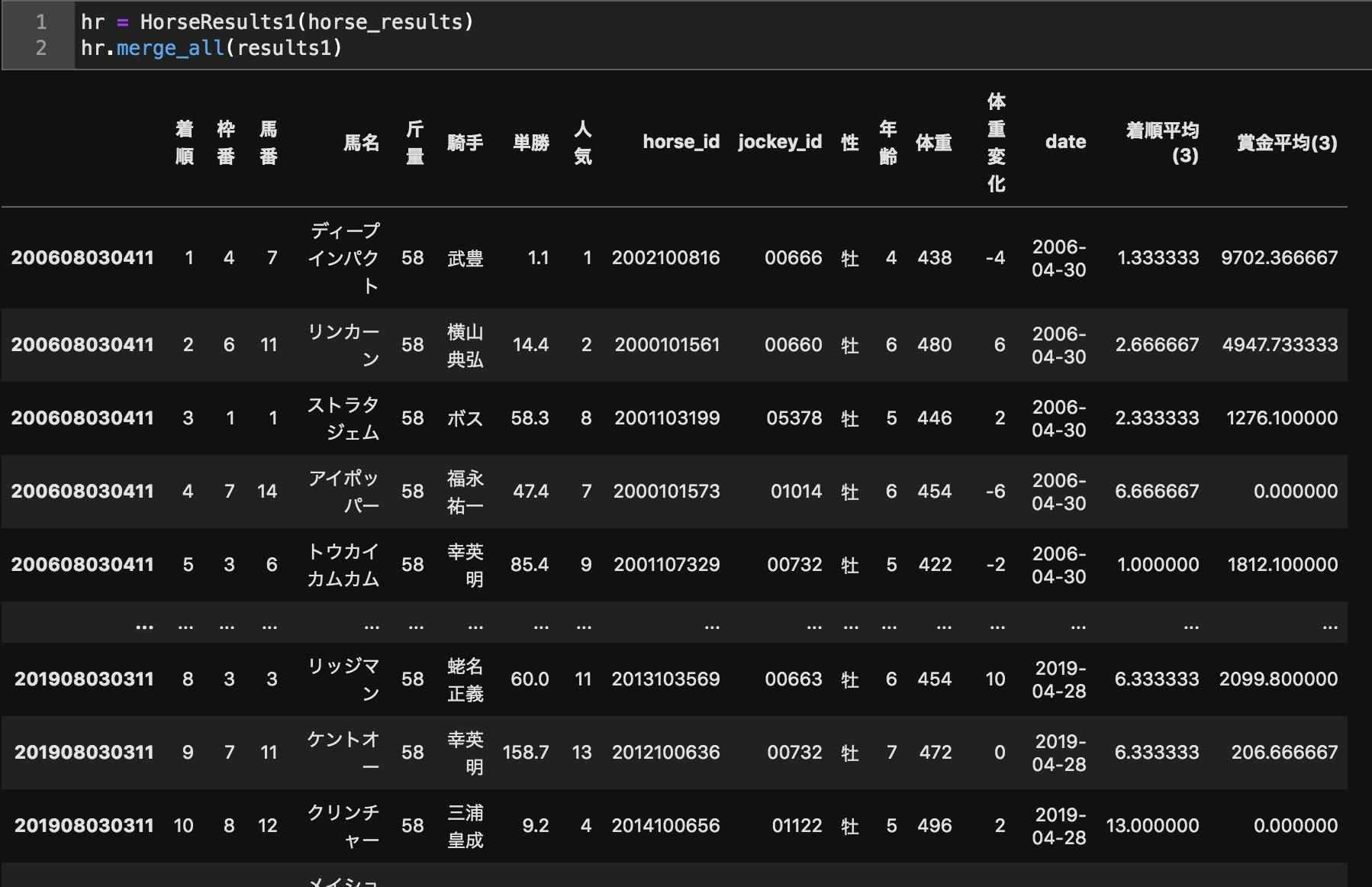
これでデータの前処理は終了です。
3.モデルの構築
モデルの選択肢は悩みましたが、RandomForestを使用したいと思います。
また今回の目的変数ですが、二値分類にするために、3位以内を1,それ以外を0にして分類しました。
とりあえず、何もパラメータを調整しないで予測してみたいと思います。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
results1['rank']=results1['着順'].map(lambda x:1 if x <4 else 0)
X=results1.drop(['着順','馬名','jockey_id','horse_id','rank','date'],axis=1)
y=results1['rank']
X=pd.get_dummies(X)
# shuffle=Trueだと時系列が意味不明なことになるので、shuffle=Falseにします
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,shuffle = False)
rf=RandomForestClassifier(random_state=0)
rf.fit(X_train,y_train)
print(rf.score(X_train,y_train),rf.score(X_test,y_test))
>>> 1.0 0.8591549295774648
これは完全に過学習を起こしてる、、、
ということでパラメータのチューニングをしていこうと思います。
4.GridSearchCVによってモデルの調整
手動でパラメーターを調整しても良かったんですが、今回はデータ数が少ないという事もあって、GridSearchCVで調整しようと思います。
from sklearn.model_selection import GridSearchCV
params = {"n_estimators":[i for i in range(10,100,10)],"criterion":["gini","entropy"],"max_depth":[i for i in range(1,6,1)] \
, 'min_samples_split': [2, 4, 10,12,16], "random_state":[3],}
rf=GridSearchCV(RandomForestClassifier(),param_grid=params,cv=5)
rf.fit(X_train,y_train)
predictor=rf.best_estimator_
print(predictor.score(X_train,y_train),predictor.score(X_test,y_test))
# どのパラメーターのセットが一番精度が高いのか
print(rf.best_params_)
>>>0.8404907975460123 0.8169014084507042
>>>{'criterion': 'gini', 'max_depth': 4, 'min_samples_split': 4, 'n_estimators': 30, 'random_state': 3}
だいぶ改善されたので、今回はこのパラメーターで予測させることにします。
最後は予測したいレース情報をテストデータとして、予測させたいと思います。
(訓練データは当然、過去14年分のレースデータでモデルを作っている)
今回のテストデータはこちら↓
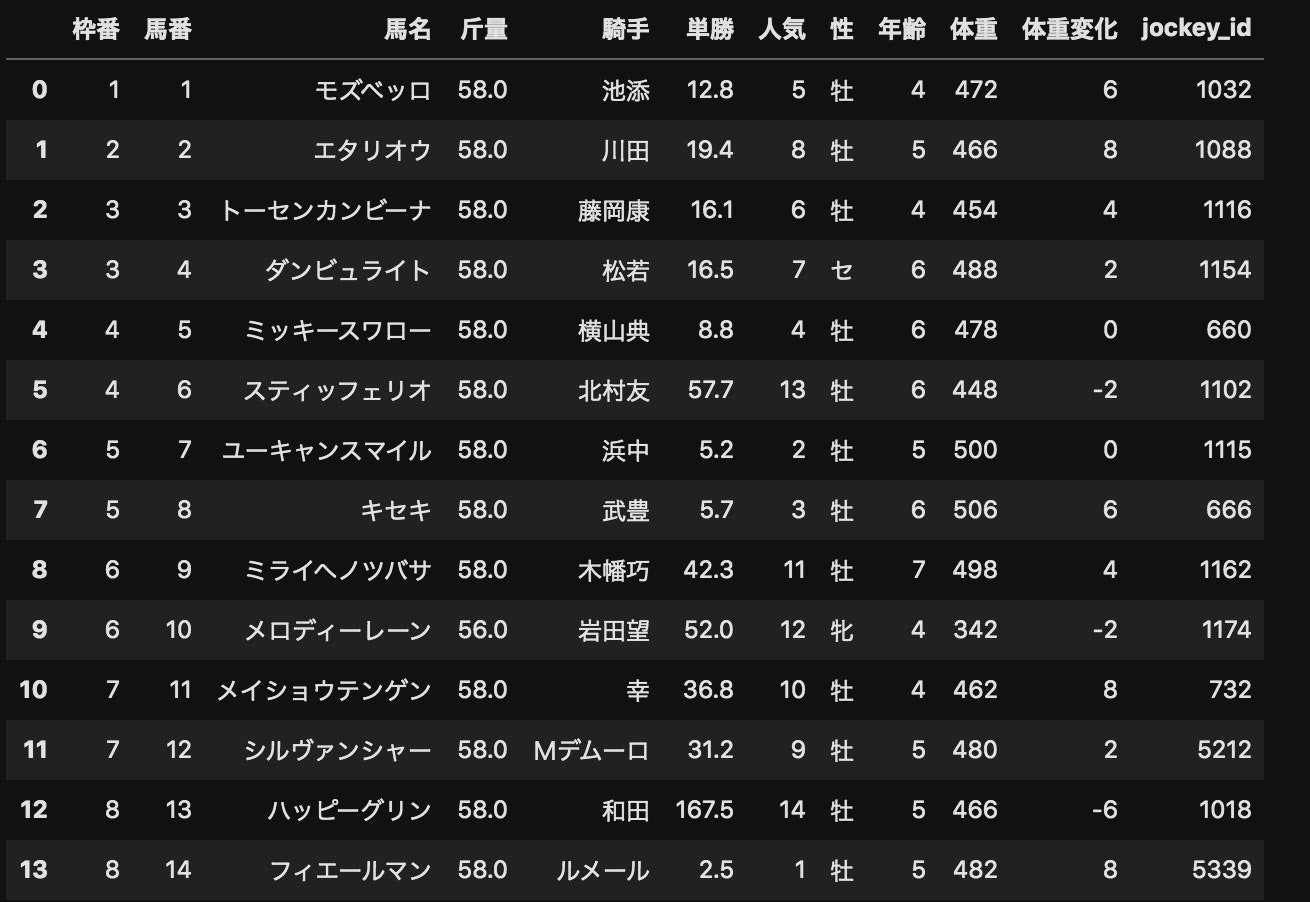
そして、今回のテストデータをモデル用に前処理したものがこちら↓
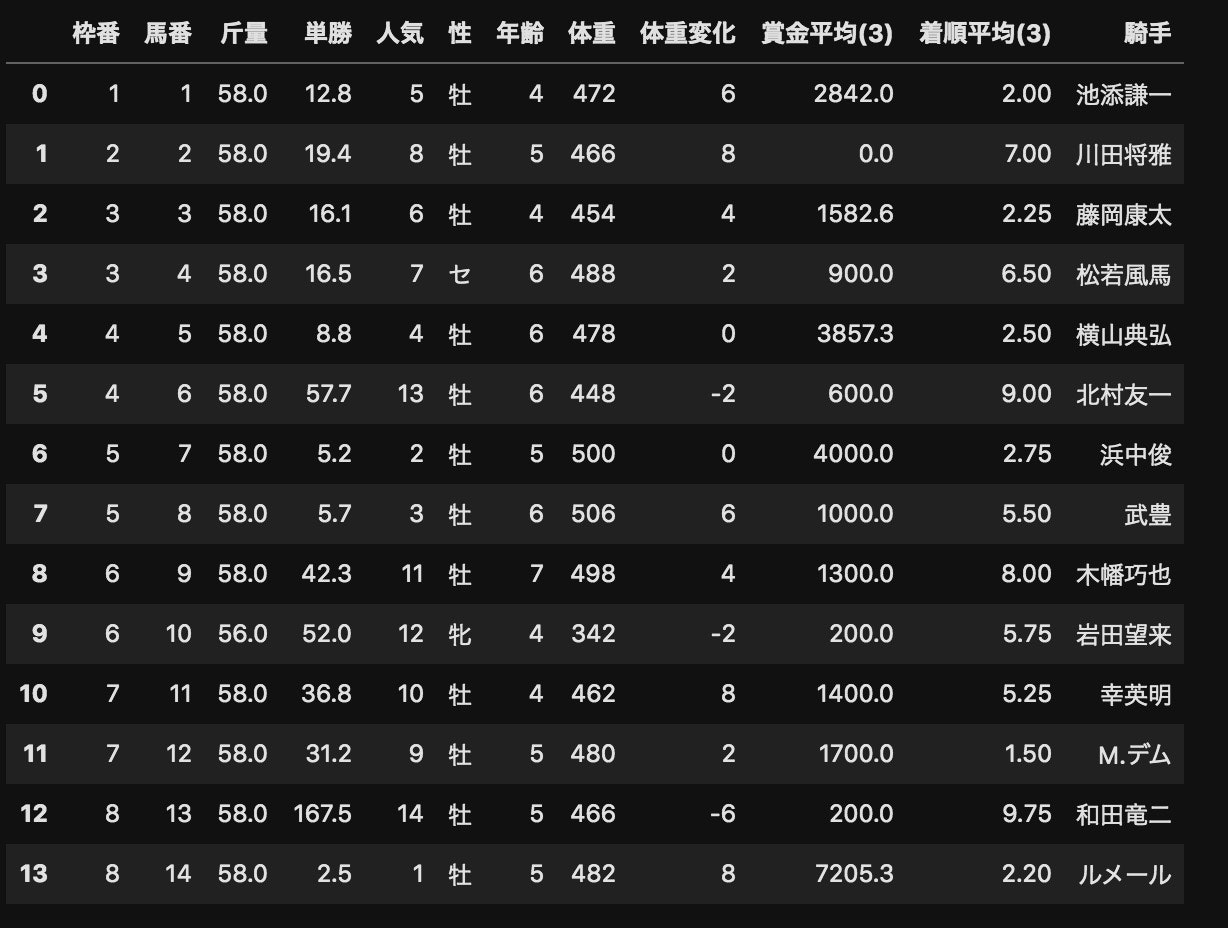
そして、予測の結果はこちら↓(予測結果は確率で表します)
[0.32896011 0.0862968 0.10283983 0.09204792 0.35276748 0.17534967
0.40209844 0.39491789 0.06362901 0.11197696 0.06662034 0.09132422
0.06267239 0.50179155]
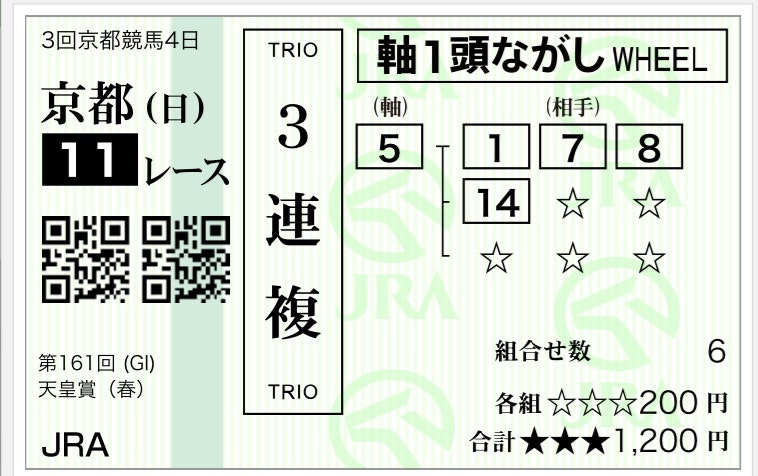
この結果を元に単勝オッズの割に勝つ確率が高いミッキースワロー軸で三連複を流しました。(実際の写真)
実際のレース結果
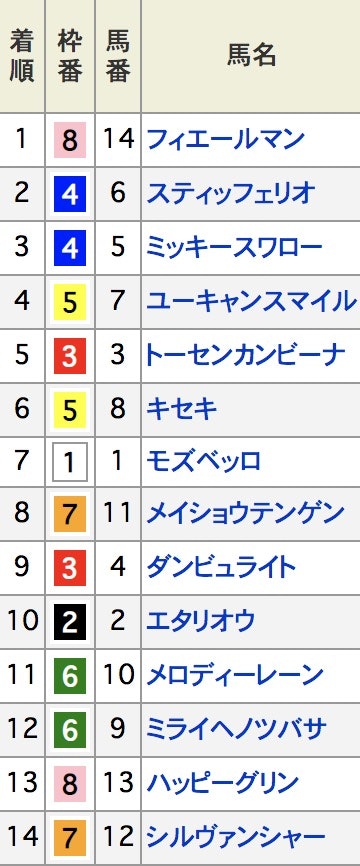 案の定、フィエールマンか、、、
でも、ミッキースワローが3位以内入ったので、良かった(というのも一応、ミッキースワローの複勝も買ってありました笑)
案の定、フィエールマンか、、、
でも、ミッキースワローが3位以内入ったので、良かった(というのも一応、ミッキースワローの複勝も買ってありました笑)
参考
今回この機械学習をやるにあたって下記のYouTubeの動画をとても参考にしました。
とても分かりやすく解説されているので、ありがたかったです。
https://www.youtube.com/channel/UCDzwXAWu1zIfJuPTTZyWthw
最後に
やはり、まだまだ知識が足りない事もあって、モデルとして不十分なところが多かったと思います。
ですので、もし記事を読んでいただいて、何かアドバイス等があれば教えていただけるとありがたい限りです。