R言語 Advent Calendar 2025の6日目の記事です。
時系列分析に躓く
統計検定準1級の学習をしていて、時系列分析の項目でほとほと嫌になりました。AR,MA,ARMA,ARIMA,SARIMA…何が違うねん!
覚えることが嫌になったんで、これをどんなふうに使うかを考えてみました。
AR(1)モデルは以下の式で表されます。
$Y_t = \phi_1 Y_{t-1} + \epsilon_t$
これをよく見てみると…これって1時点前までのデータから未来予測できるってことじゃん!
時系列分析が株価予測や天気予報などに使われていることにようやく気付いたのです(←遅い)。こういうことに気づけないから、自学自習はつらいっす。
月次データで売上予測する3つのポイント
じゃあ勤務先の売上予測してみようと思い、さっそくやってみました。2012年12月~2025年10月の月次売上データから今後1年間の売上予測してみます。なお、売上自体は公開データですが、念のため変数変換し、匿名データにしています。
月次データなので、周期12のSARIMAモデルが適用されるのではないか、との憶測を前提条件とするとポイントは以下の3つです。
-
ts()でデータを時系列(今回の場合は月次)データとして登録 -
auto.arima()でモデル選定(SARIMAモデルなのか確認) -
forecast()で予測
ts()で月次データ登録
他のことにも使えるよう、ymとvalueの2列あれば未来予測できるRコードを作ります。
rm(list = ls())
library(conflicted)
library(tidyverse)
library(forecast)
library(tseries)
library(showtext)
conflicts_prefer(dplyr::filter)
# Google Fontsから日本語フォントを追加
font_add_google("Noto Sans JP", "notosans")
showtext_auto()
target_fy <- 2025 # 予測対象年度(2025年度)
vec_title <- c("売上")
# csvファイルの読み込み(ファイル名を指定)
file_path <- c("income.csv") # ファイルパスを調整
data <- read_csv(file_path) |>
mutate(ym = ymd(ym))
start_ymd <- slice(data, 1) |> pull(ym)
end_ymd <- slice(data, nrow(data)) |> pull(ym)
start_ym <- year(start_ymd) * 100 + month(start_ymd)
end_ym <- year(end_ymd) * 100 + month(end_ymd)
ts_data <- ts(data$value,
start = c(year(start_ymd), month(start_ymd)),
frequency = 12)
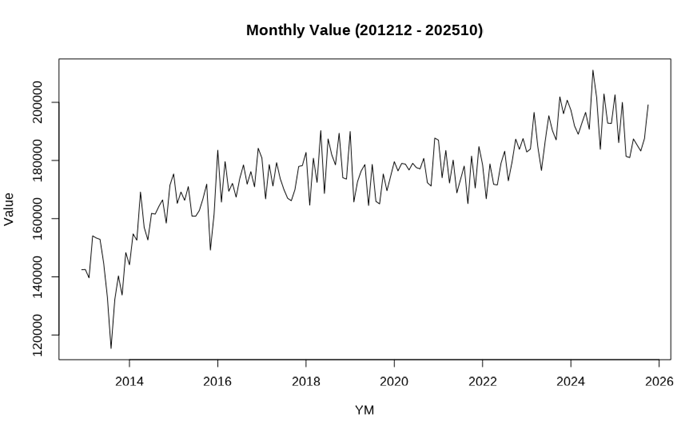
# データのプロット(視覚確認)
plot(ts_data, main = str_c("Monthly Value (", start_ym, " - ", end_ym, ")"),
ylab = "Value", xlab = "YM")
auto.arima()の威力
ここから実際には定常性チェックをしなければならないのですが、今回は説明しません。なぜなら、forecast::auto.arima()関数一発で、AR,MA,ARMA,ARIMA,SARIMAのうち、どれが最も適切なモデルかを判定してくれるのです!なんと便利!
model <- auto.arima(ts_data)
# モデル概要表示
> summary(model)
Series: ts_data
ARIMA(2,1,1)(2,0,0)[12]
Coefficients:
ar1 ar2 ma1 sar1 sar2
-0.0937 -0.0371 -0.5892 0.2119 0.2615
s.e. 0.2150 0.1514 0.2033 0.0867 0.0930
sigma^2 = 56787870: log likelihood = -1592.45
AIC=3196.89 AICc=3197.46 BIC=3215.12
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 388.6184 7388.48 5944.486 0.09276953 3.471961 0.6495335 -0.006173289
ARIMA(2,1,1)(2,0,0)[12] モデルが適切との判定です。これは12か月周期のSARIMAモデルのことです。auto.arima()の数少ない欠点は、ARモデルもMAモデルもARMAモデルもすべてARIMA(p,d,q)という形で出力される点です。そこでモデル名が出力されるよう、if文を作成しました。
# ============================================
# モデル名を自動取得する関数
# ============================================
get_arima_model_name <- function(model, simplified = TRUE) {
order <- arimaorder(model)
p <- order["p"]
d <- order["d"]
q <- order["q"]
P <- order["P"]
D <- order["D"]
Q <- order["Q"]
freq <- order["Frequency"]
# ドリフト項の有無を確認
has_drift <- "drift" %in% names(coef(model))
# 季節成分の有無
has_seasonal <- !(P == 0 && D == 0 && Q == 0)
if (simplified) {
# 簡略化した名前で表示
if (has_seasonal) {
# 季節モデル → 常にSARIMA表記
model_name <- sprintf("SARIMA(%d,%d,%d)(%d,%d,%d)[%d]",
p, d, q, P, D, Q, freq)
} else if (d == 0 && p > 0 && q == 0) {
# AR(p)モデル
model_name <- sprintf("AR(%d)", p)
} else if (d == 0 && p == 0 && q > 0) {
# MA(q)モデル
model_name <- sprintf("MA(%d)", q)
} else if (d == 0 && p > 0 && q > 0) {
# ARMA(p,q)モデル
model_name <- sprintf("ARMA(%d,%d)", p, q)
} else {
# ARIMA(p,d,q)モデル
model_name <- sprintf("ARIMA(%d,%d,%d)", p, d, q)
}
} else {
# 常にARIMA/SARIMA形式で表示
if (has_seasonal) {
model_name <- sprintf("ARIMA(%d,%d,%d)(%d,%d,%d)[%d]",
p, d, q, P, D, Q, freq)
} else {
model_name <- sprintf("ARIMA(%d,%d,%d)", p, d, q)
}
}
# ドリフト項がある場合は追記
if (has_drift) {
model_name <- paste0(model_name, " with drift")
}
return(model_name)
}
model_name <- get_arima_model_name(model, simplified = TRUE)
print(paste("選択されたモデル:", model_name))
> [1] "選択されたモデル: SARIMA(2,1,1)(2,0,0)[12]"
forecast()で未来予測
SARIMAモデルと分かれば、あとはforecast()であっという間に予測ができます。plot()を実行すれば、予測折れ線グラフもあっという間に出力されます!なんと便利!
fc <- forecast(model, h = 12)
plot(fc)
plot()関数で視覚化はできるのですが、やはり予測値をデータフレーム化したいのが人情です。そこでデータフレームを作成し、グラフはデータフレームをもとにggplotで作成してみました。なお、forecast()はズバリの予測値だけでなく80%や95%予測区間も算出してくれるので、それもデータフレーム化、チャート化します。
df_fc <- dplyr::tibble(
ym = seq(from = ym(end_ym) + months(1), by = "month", length.out = 12),
value = fc$mean,
Lo_80 = fc$lower[, "80%"],
Hi_80 = fc$upper[, "80%"],
Lo_95 = fc$lower[, "95%"],
Hi_95 = fc$upper[, "95%"],
Type = "Forecast")
df_historical <- data |>
mutate(Type = "Historical")
df_forecast <- df_fc |>
select(ym, value, Lo_80, Hi_80, Lo_95, Hi_95, Type)
g1 <- ggplot() +
# 95% prediction interval (wider, lighter)
geom_ribbon(data = df_forecast,
aes(x = ym, ymin = Lo_95, ymax = Hi_95),
fill = "steelblue", alpha = 0.2) +
# 80% prediction interval (narrower, slightly darker)
geom_ribbon(data = df_forecast,
aes(x = ym, ymin = Lo_80, ymax = Hi_80),
fill = "steelblue", alpha = 0.3) +
# Historical data line
geom_line(data = df_historical,
aes(x = ym, y = value, color = "実績値"),
linewidth = 0.8) +
# Forecast line
geom_line(data = df_forecast,
aes(x = ym, y = value, color = "予測値"),
linewidth = 0.8) +
# Point at connection
geom_point(data = df_forecast,
aes(x = ym, y = value),
color = "tomato", size = 1.5) +
# Styling
scale_color_manual(values = c("実績値" = "black", "予測値" = "tomato"),
name = "") +
scale_x_datetime(date_breaks = "1 year", date_labels = "%Y") +
scale_y_continuous(labels = scales::comma) +
labs(title = str_c(vec_title, "の時系列予測 (", start_ym, " - ", end_ym + 100, ")"),
subtitle = str_c(model_name, "モデルによる予測、80%・95%予測区間付き"),
x = "年月",
y = "値") +
theme_minimal(base_family = "notosans") +
theme(
plot.title = element_text(size = 14, face = "bold"),
plot.subtitle = element_text(size = 10, color = "gray40"),
legend.position = "bottom",
panel.grid.minor = element_blank()
)
g1
ggsave(str_c(vec_title,"_forecast_timeseries_full.pdf"),
plot = g1, width = 12, height = 6)
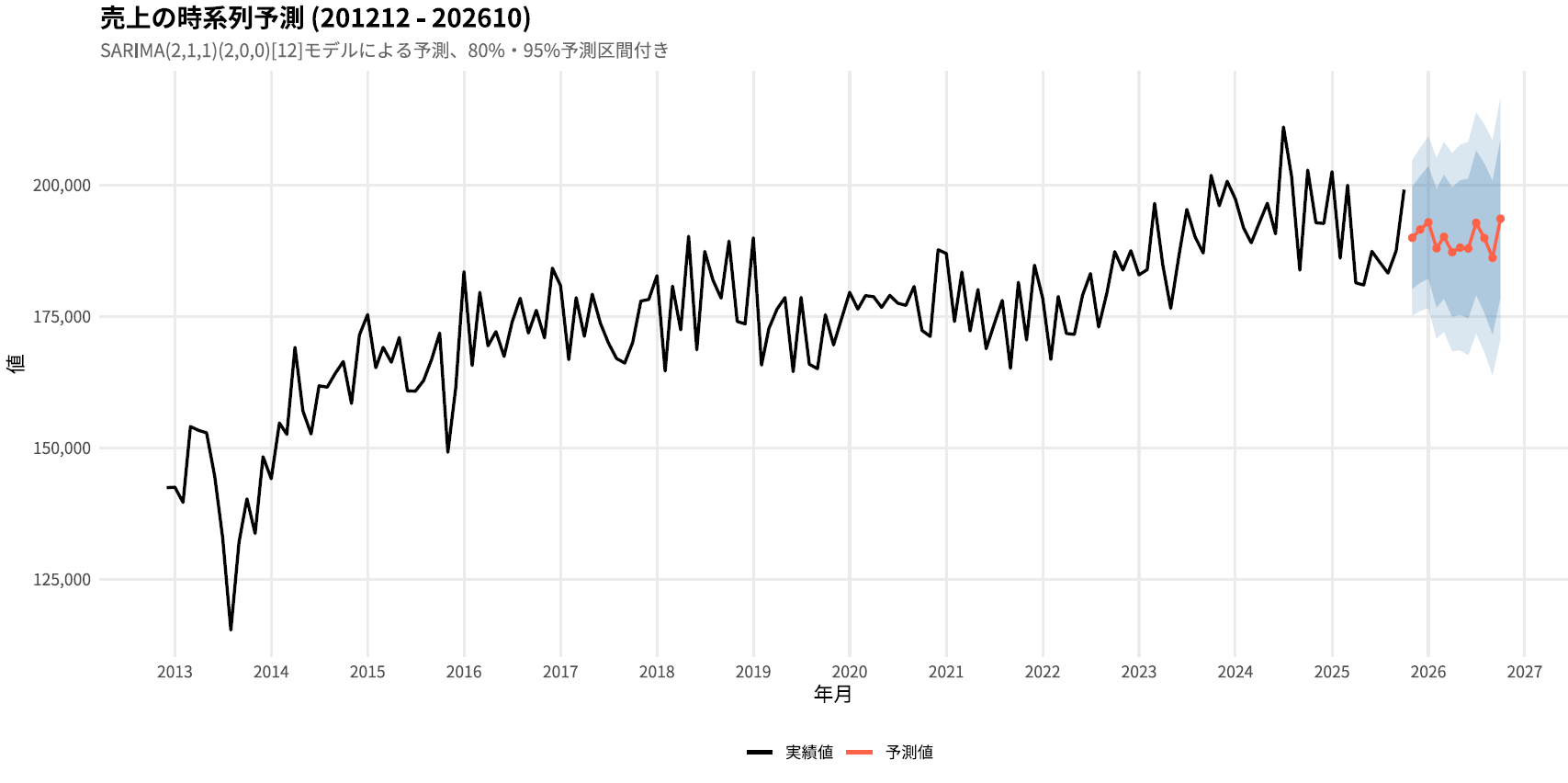
網掛け部分は80%、95%予測区間です。
SARIMAモデルの優秀性
SARIMAモデルの優れた点は、1世紀前から考え方自体はあり、実用化されてからも半世紀以上経っている古典的な手法にもかかわらず、今日まで利用されていることです。なんでこんなこと知らなかったんだ!バカバカバカ!(←自分への叱咤激励)。
今日日(きょうび)は他にも時系列分析モデルがあります。アドカレ期間に間に合えば、それぞれのモデル比較記事を書きたいです!(願望)