名寄せとは元々個人が複数持つ銀行口座を一元管理するための概念ですが、データを扱う人々の中では、揺らぎなく識別できる一意のIDが無く、バラツキのある文字列による名称などで識別するしかないデータにおいて、分野ごとに基となるマスターデータをあれこれ参照しながら、対象を一意に識別しようとする面倒な作業、といった意味で使われています。(たぶんw)干し草の中から針を探すような作業を機械の力を借りて無理くりやっている感があります。
OpenRefineには照合(Reconciliation)という機能があり、広い意味での名寄せと似ていますが、単純なマスター照合だけでなく、一致条件のチューニングや候補のスコアリング、マスターが持つ名前以外の属性情報の取得とカラム出力といったことも可能で、オープンな構造化データベースであるWikidataとはとりわけ緊密に連携できるようになっています。
連携のためのAPI仕様はW3C規格にもなっており、これに準拠した照合サービスとしてVIAF(バーチャル国際典拠ファイル)や世界中の企業情報(by opencorporates)などが一般公開されています。
前回PDFから抜き出したデータに対して、今回は主にこうした名寄せや照合を行ってみます。多少とも無理くりな作業の手助けになれば幸いです。
1 市町村名

1.1 不要カラムを非表示に
使わないカラムを非表示にして見やすくします。
対象カラムの▼から ビュー>右側をすべてたたむ
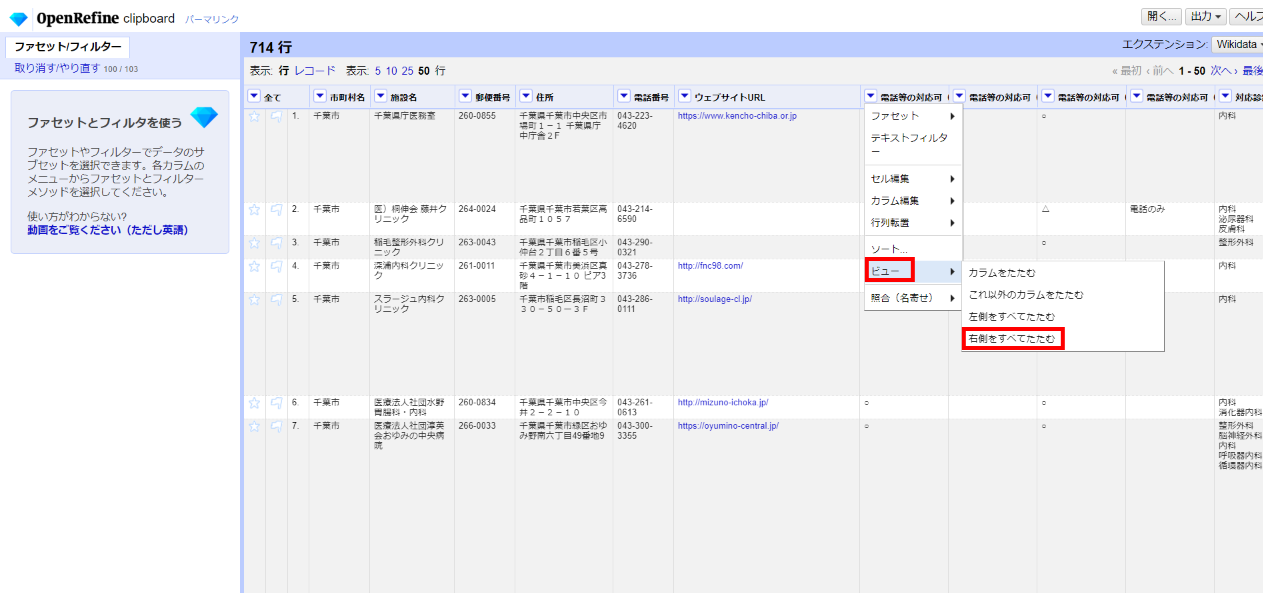
(たたんだカラムは見出し欄をクリックすると再表示できます。)
1.2 Wikidata照合
市町村名は見たところ正しそうですが、複数名で入力していると「が」「ガ」「ヶ」「ケ」などの表記揺れはよくあるのでWikidataと照合してみます。
「市町村名」カラムで 照合(名寄せ)>照合(reconcile)を開始 と選びます。
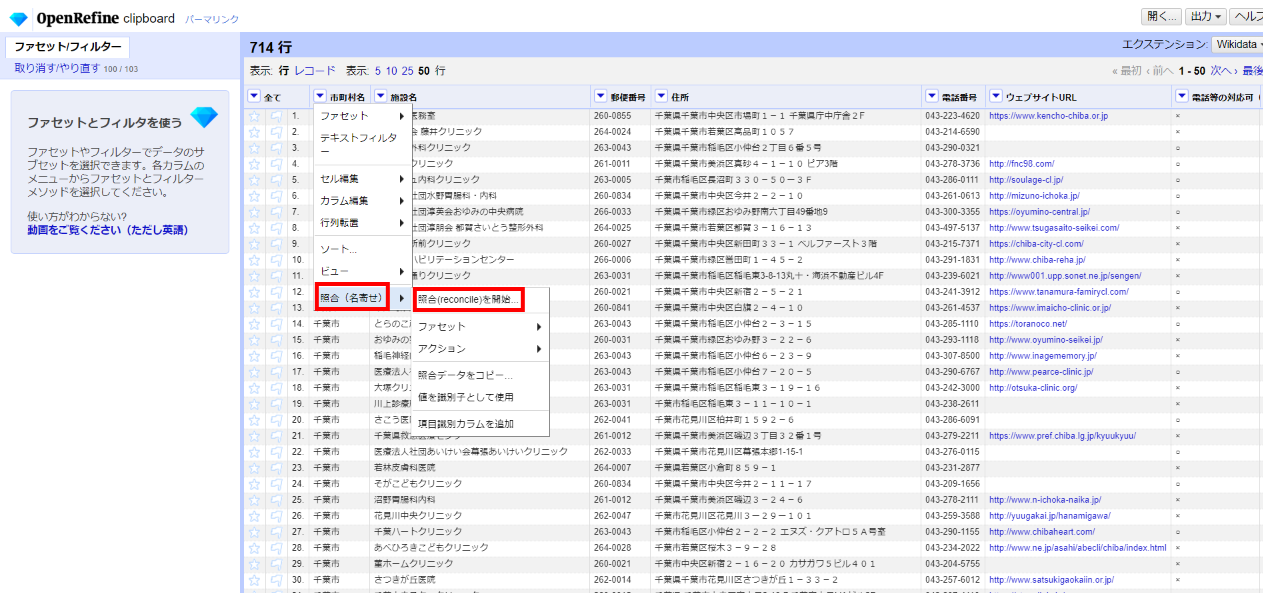
デフォルトでは英語のエンドポイントしか登録されていないので日本語用のエンドポイントを追加します。
「サービスを追加」をクリック
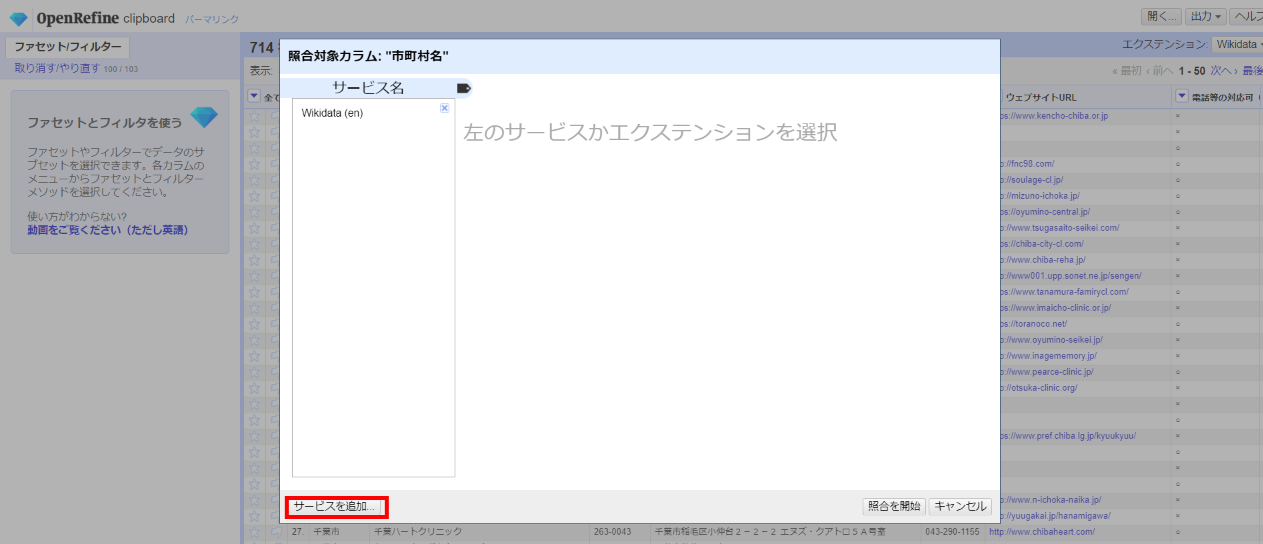
下記を設定して再度「サービスを追加」をクリック
https://tools.wmflabs.org/openrefine-wikidata/ja/api
https://wdreconcile.toolforge.org/ja/api(2020/7/11変更)
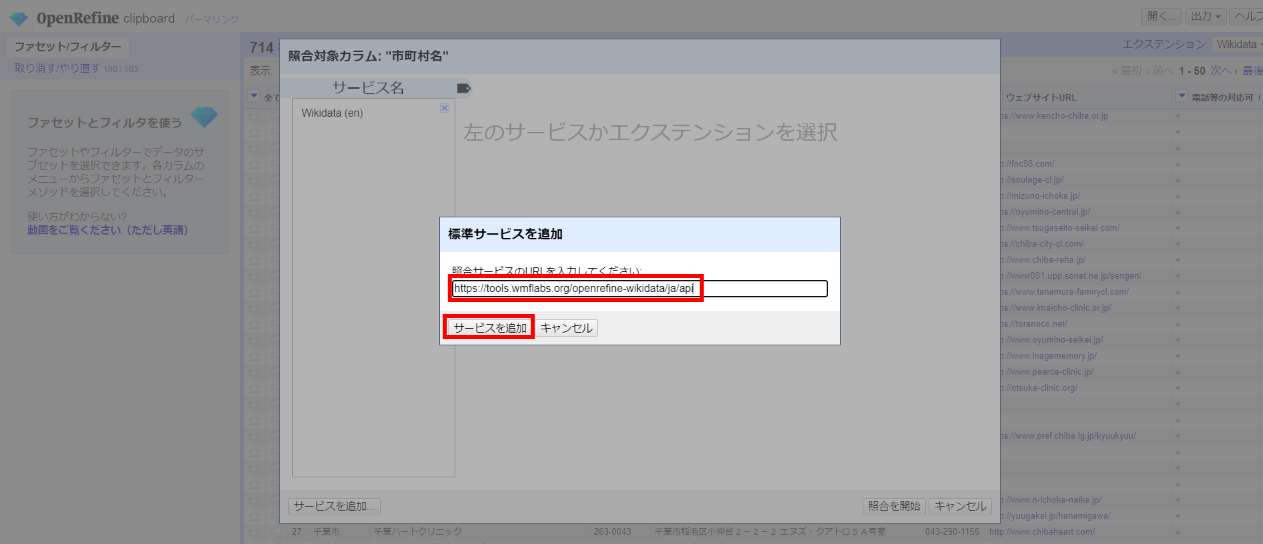
しばらく「処理中」の表示が出て下記に変わります。
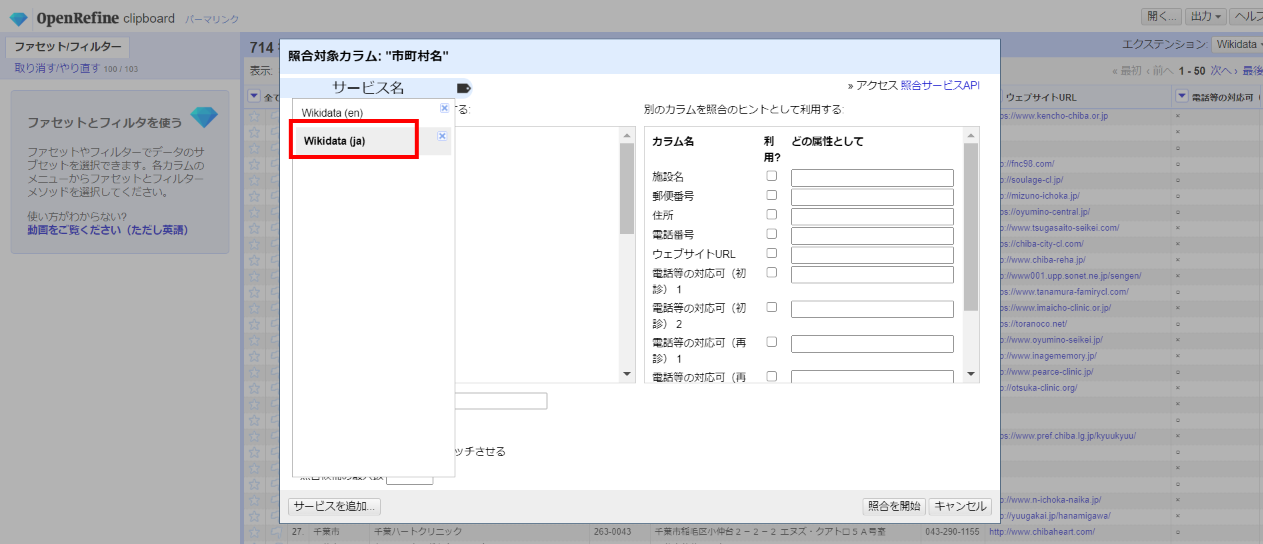
「Wikidata(ja)」を選びます。

ここでWikidataを照合するためのパラメータを調整します。
OpenRefineが提案する初期値として「◯日本の市」にチェックが付き、以下その他の候補が列挙されていますが、一覧には町や村も含まれるのでこのままだと市だけしかヒットしません。
Wikidataのオブジェクト(項目と呼びます)は上位クラス>クラス>インスタンス といった階層構造を持っており、例えば日本の行政区画をグラフ表示すると以下のような感じです。
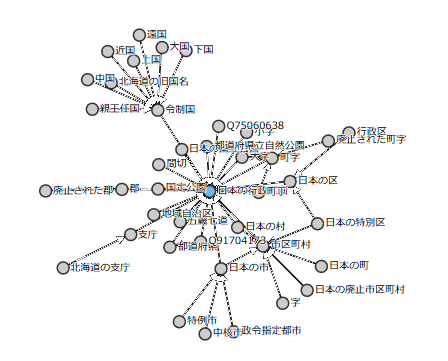
具体的にはこの中から「市区町村」というクラス(OpenRefineでは型と表現)を指定すると、今回の一覧にある市町村名は全て網羅され、市区町村と無関係なオブジェクトは名前が一致しても候補の対象外となるはずです。
このあたりを理解して適切なチューニングを行うにはWikidataのデータ構造をある程度把握する必要があるので興味があれば@yayamamoさんによるこちらの記事などを参考にしてください。
ここでは型の指定はせずに単純に名前だけで一致するものを探すことにします。
「◯型を問わずに照合する」をチェックして、照合候補の最大数を「3」として「照合を開始」
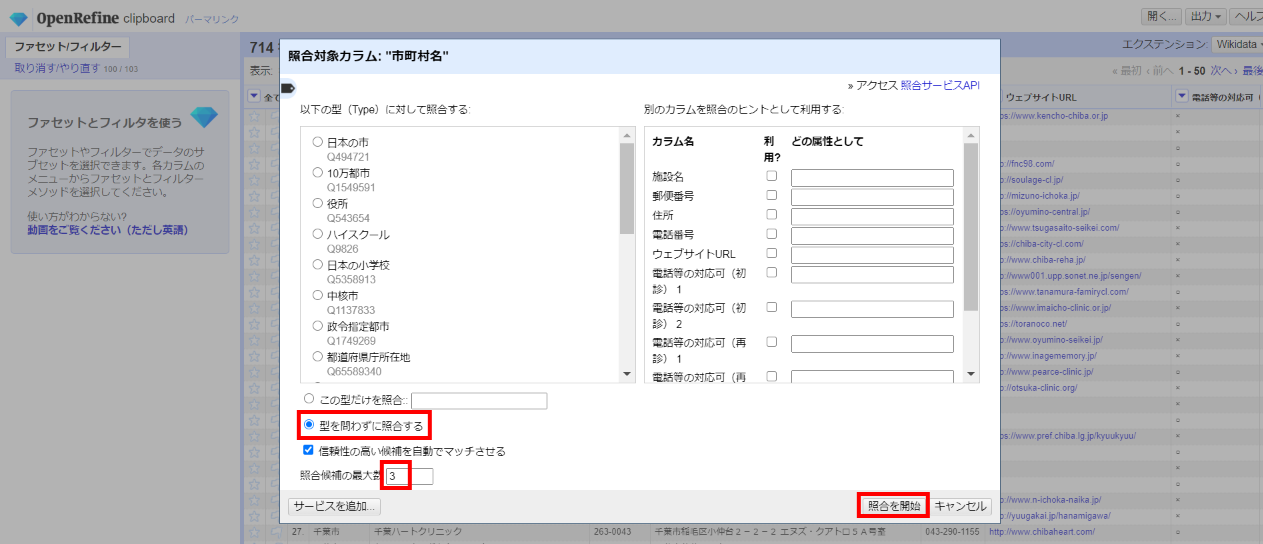
画面上部に黄色地の進捗状況が表示され、100%になったら照合完了です。

完了し、市町村名が青字(照合済を示します)になり、左サイドに照合判定ファセットが表示されました。「none」は存在しないか、似たものが複数あって一致を自動判定できなかったものを示します。多いですね。試しに選んでみましょう。
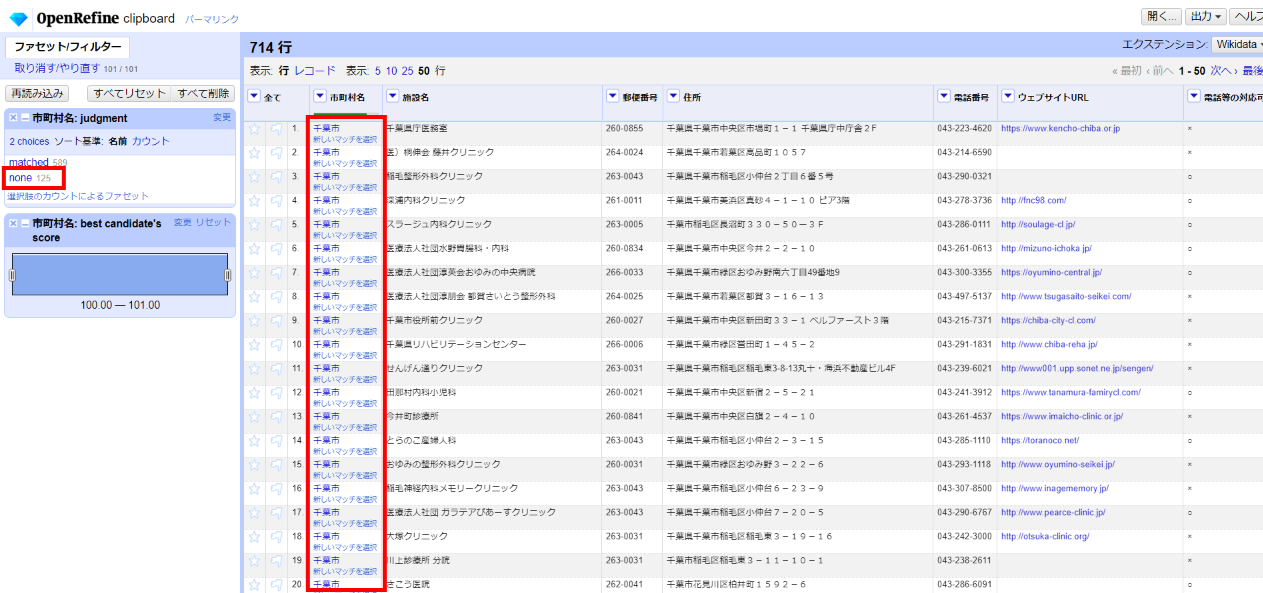
一致スコア順に候補が3つ並んでいます。正解以外にも、名称に「船橋市」が含まれるものが候補として並んでいます。
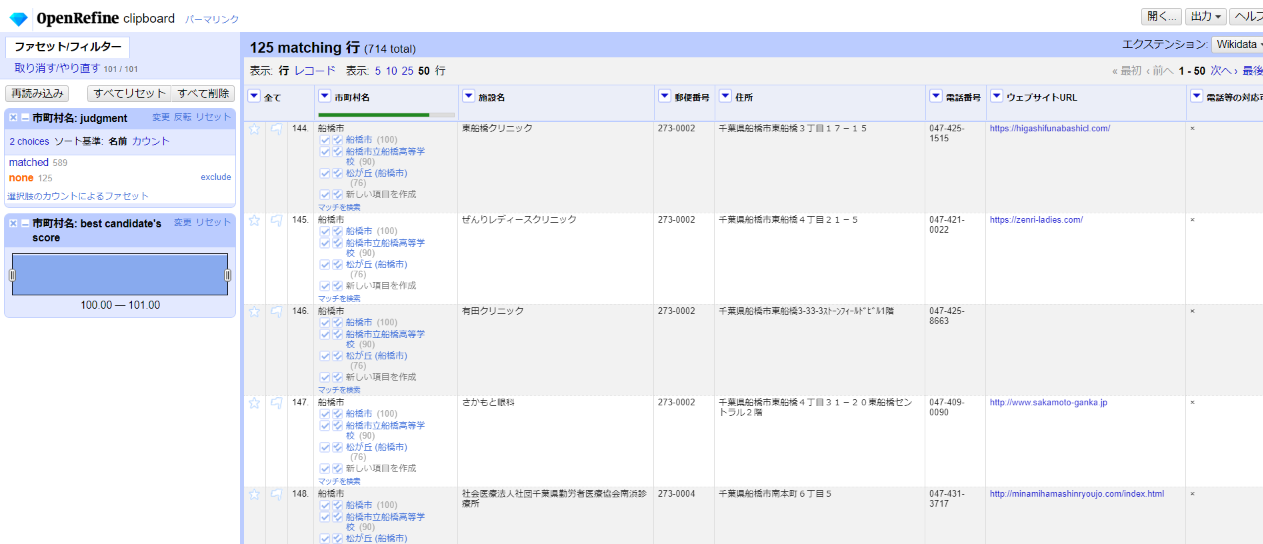
「船橋市」は全て先頭の100%一致が合っているのでチェックが2つ付いた□(この項目をこのセルと同じ全セルにマッチ)を選び、同様の一致に全て適用させます。
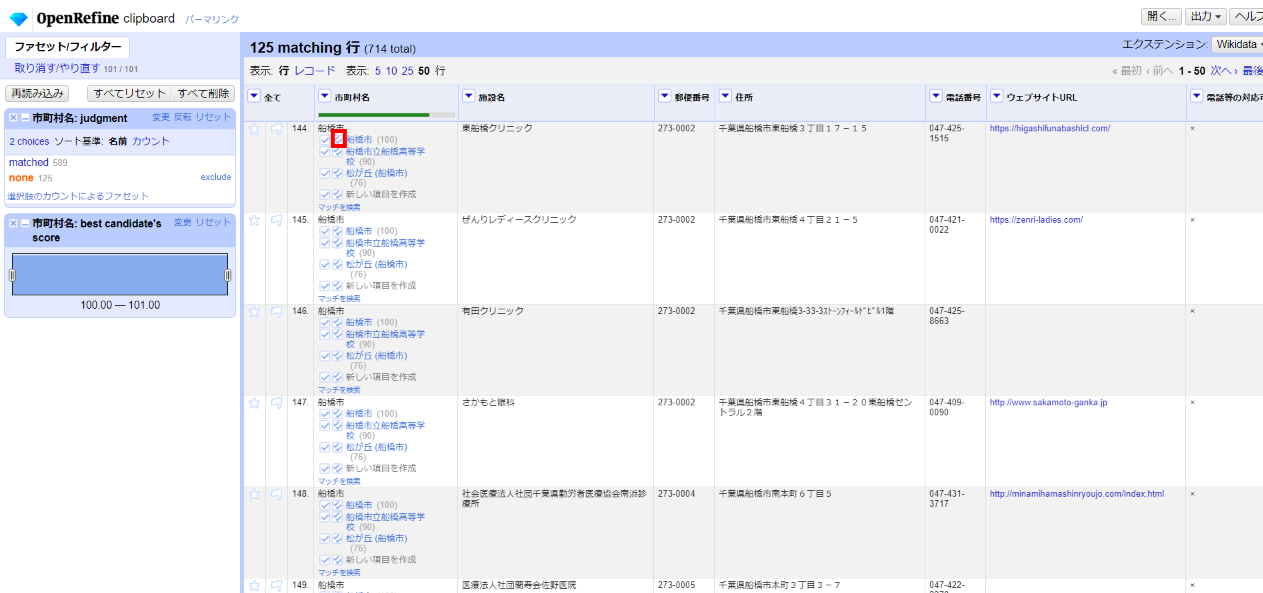
一気に数が減り、あと3つの自治体だけになりました。「神崎町」は100%一致が2件あるので1件目にマウスカーソルを当てるとWikidataの該当ページがプレビューされ、概要説明でこれが正しい町名であることが分かりますので、これをチェックします。
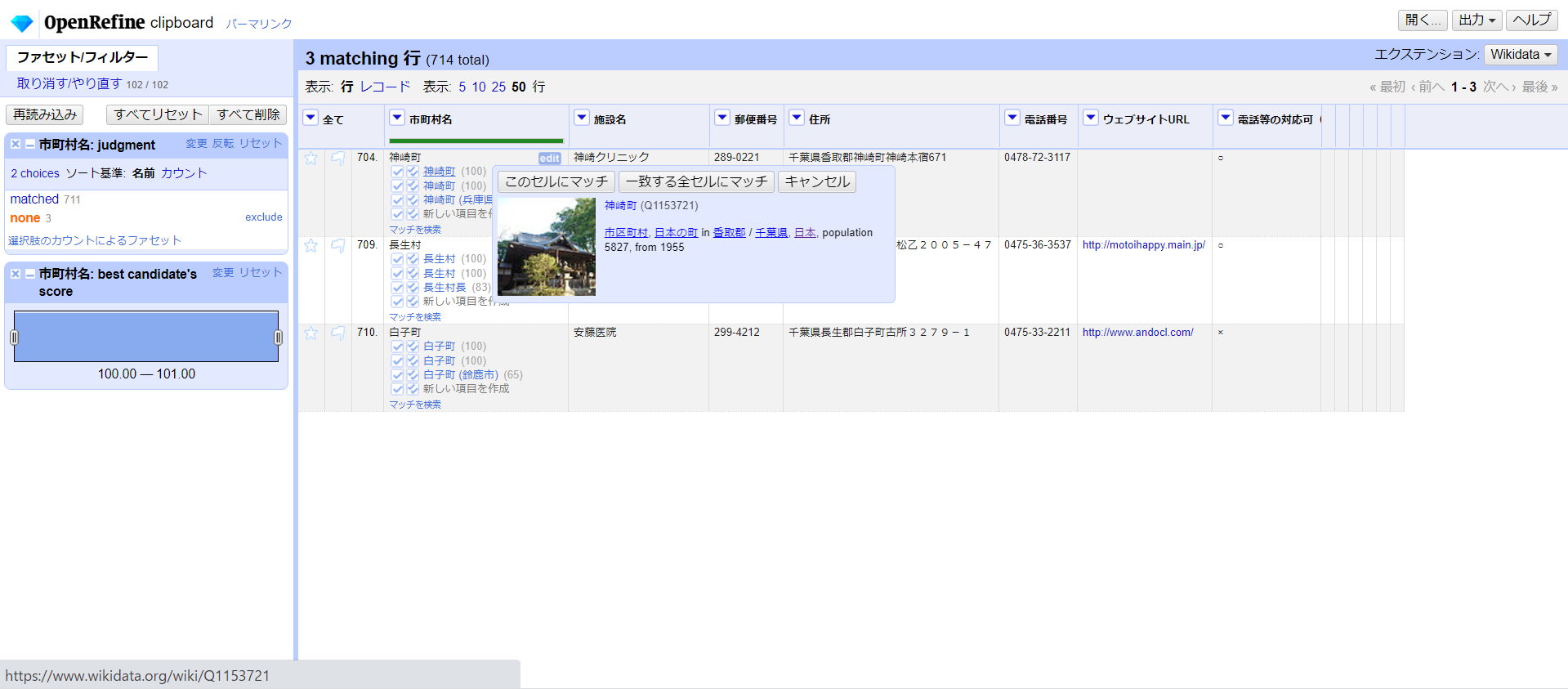
以下、「長生村」「白子町」も同様に処理します。
「none」が0件となり、つまり全て一致しました。
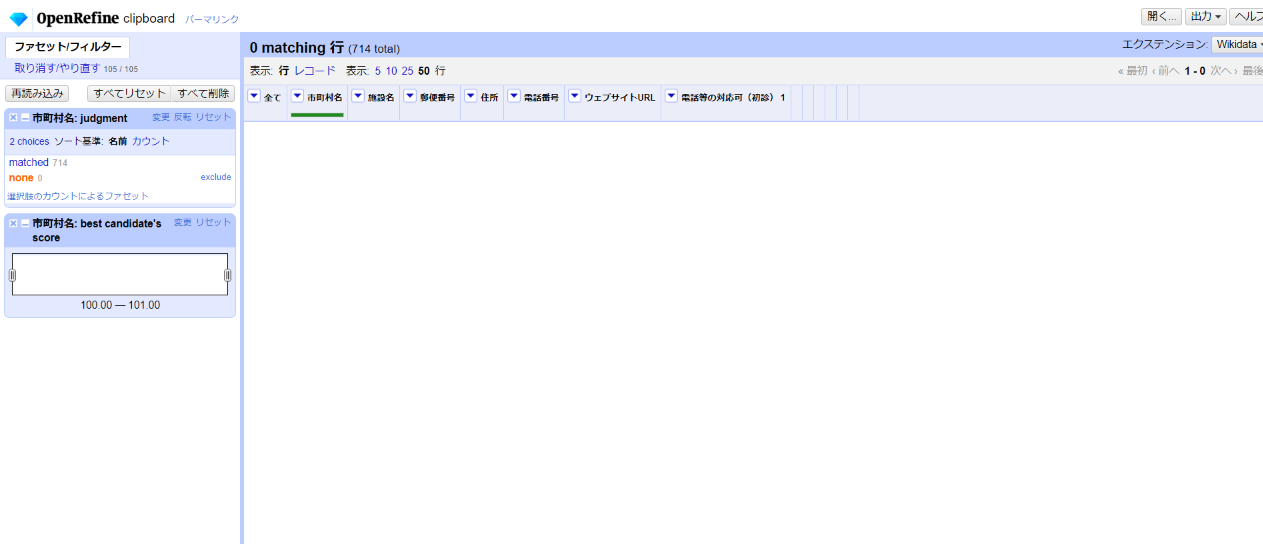
これで少なくともWikidataの持つ市町村名とは全て紐付けられ、かつ一致しているという検証ができました。
照合済みのセルはウィキデータのオブジェクト(項目)とリンクし、さらに内部にはそのオブジェクトを一意に識別するウィキデータのIDであるQ番号(千葉市なら「Q170616」)を保持しており、Q番号があればダイレクトにウィキデータ上のオブジェクトを識別可能になります。詳細は別の機会に。
市町村名判定ファセットをXで消して表示を戻します。
市町村名表記に誤りが無いことを検証できましたが、同時にWikidataと紐付けられたのでWikidataが持つ属性情報(プロパティと値の組み合わせからなる「文」)を参照できるようになりました。
「▼市町村名」の▼をクリックして カラム編集>照合値からカラムを作る と選びます。
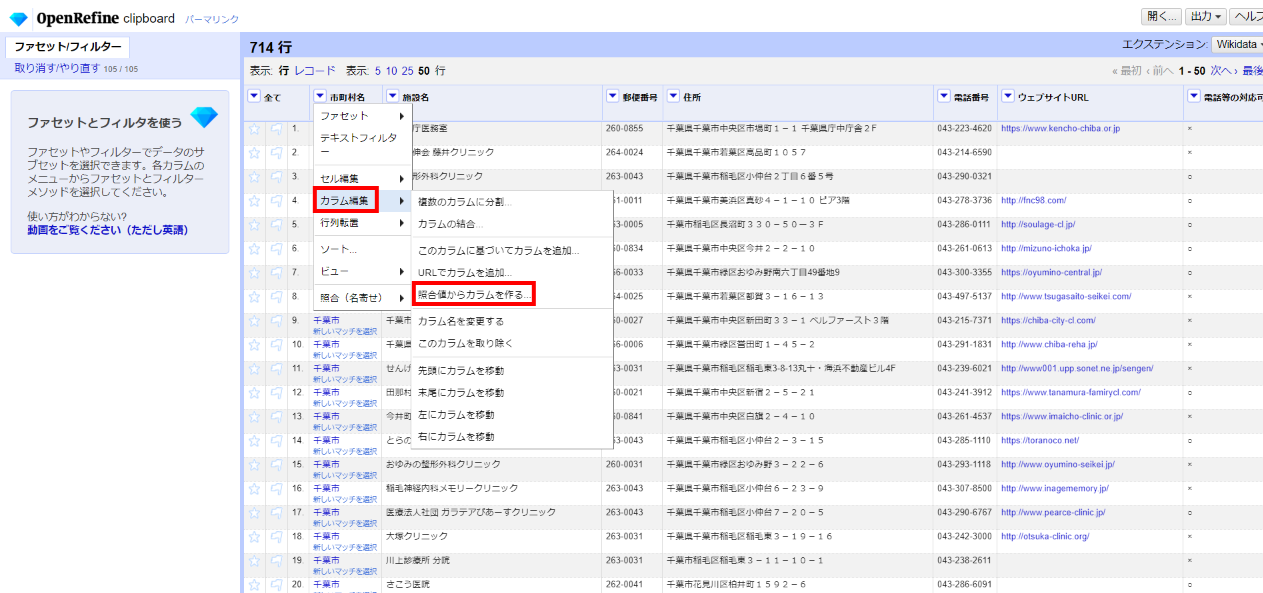
ここでWikidataのプロパティを指定して、その値を新たなカラムとして出力することができます。
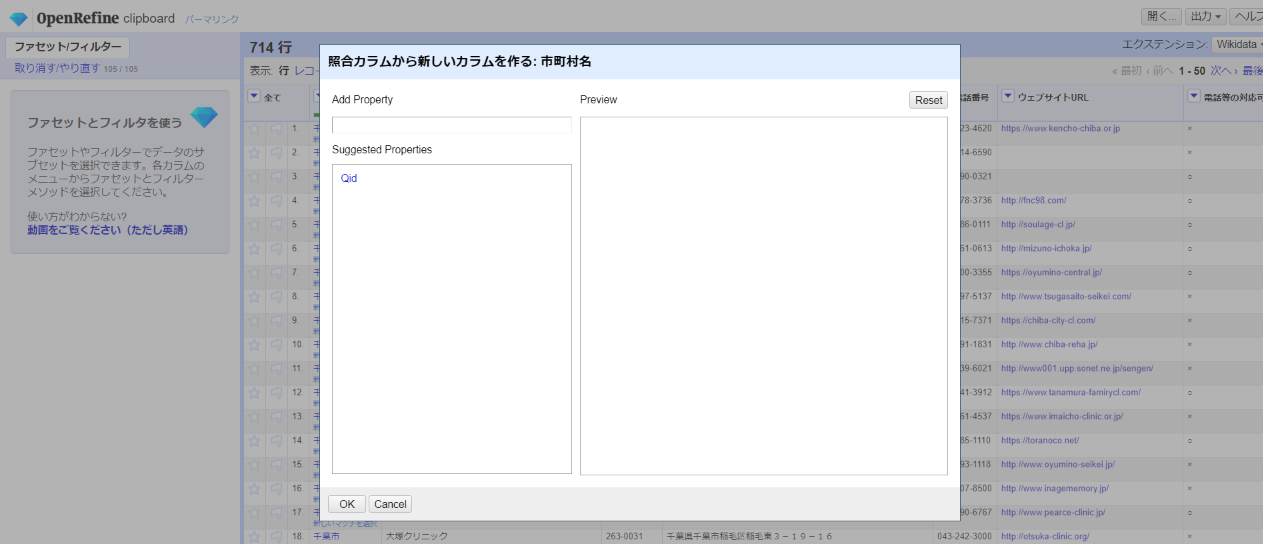
どのようなプロパティがあるのか、Wikidataの右上の検索窓で市町村の例として「千葉市」を検索してみます。
「千葉市」という項目のページを開くと、プロパティと値の組み合わせからなる「文」が多数登録されています。ここでは下の方にある「全国地方公共団体コード」というプロパティの値(千葉市なら「121002」)を取得します。
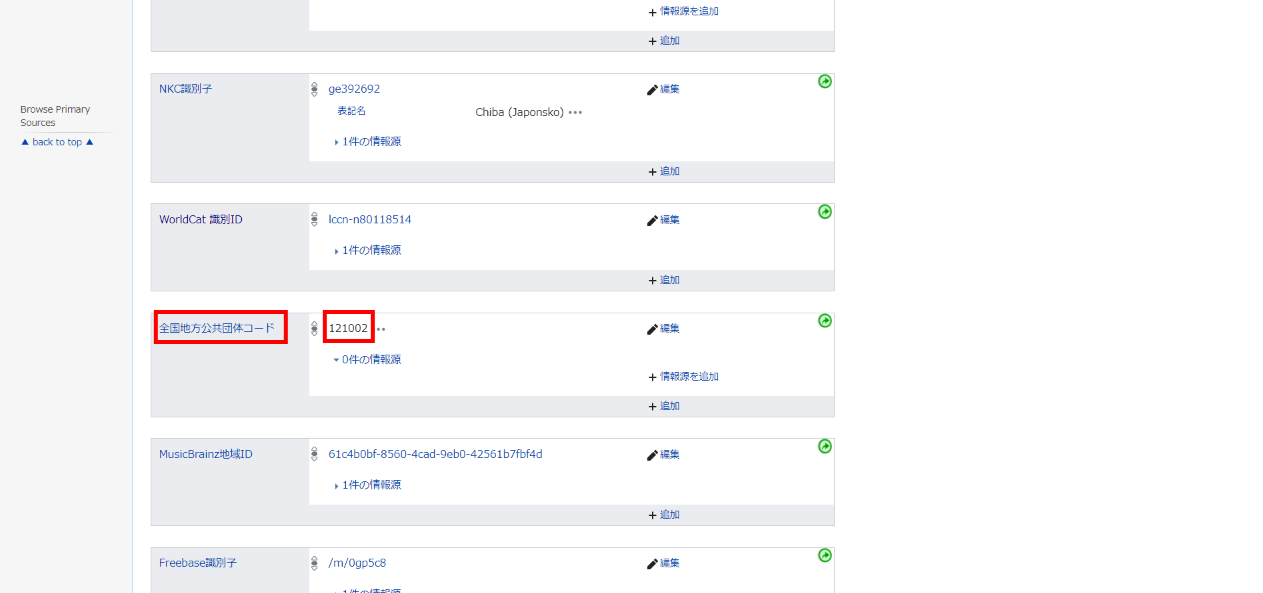
OpenRefineの画面に戻って「Add Property」欄に「全国地方公共団体コード」と入力します。
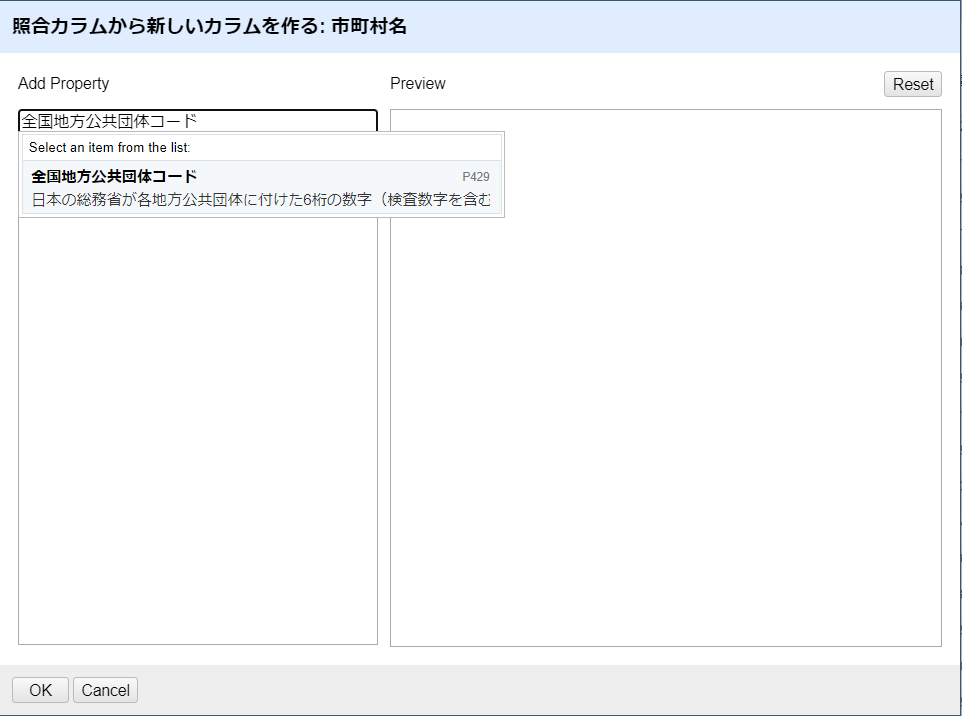
その直下にWikidataが持つ類似名のプロパティの候補が表示されるのでこれを選択します。
しばらく待つと右側に取得した値がプレビュー表示されるので「OK」。
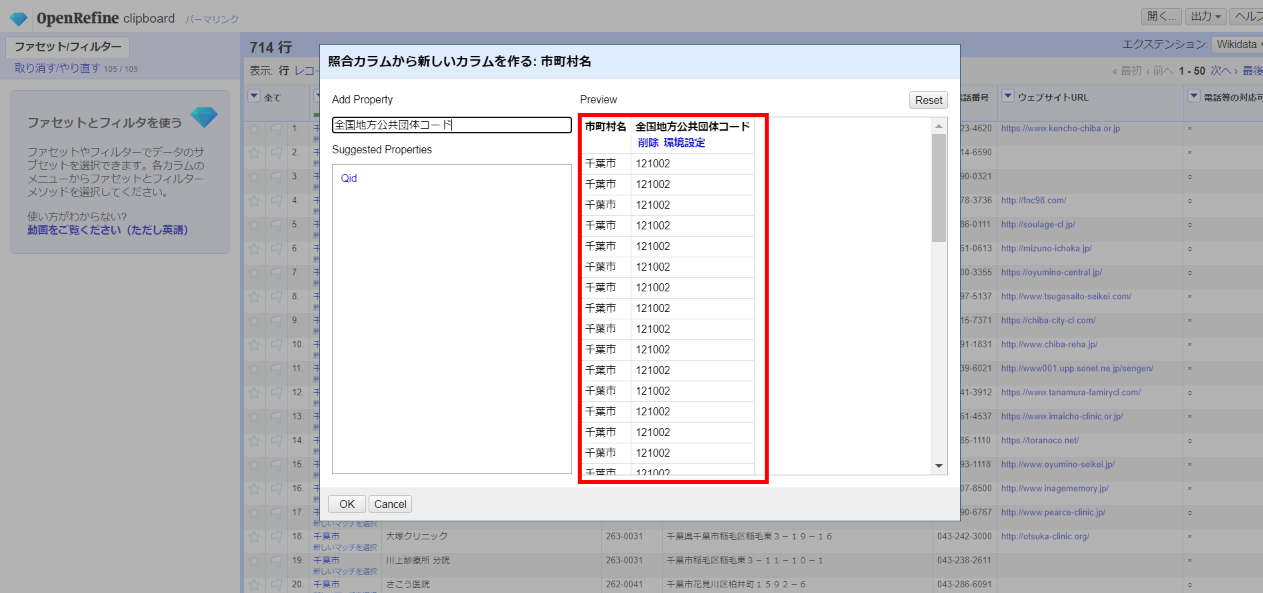
照合と同じようにWikidataを参照して、さらに「全国地方公共団体コード」カラムが作成され値が設定されました。千葉市だけでなく、一覧にある町村名全てに対応するものが取得・設定されます。
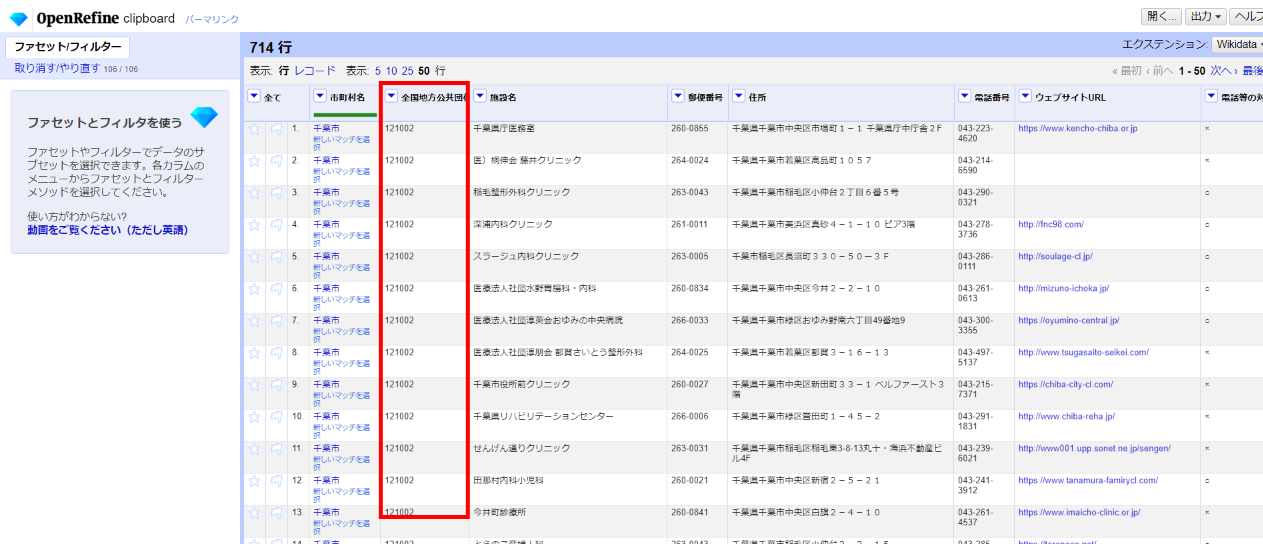
このようにOpenRefineを使うとデータのクレンジングだけでなく、外部から取得したデータで充実(エンリッチ)させることも可能です。
ここで取得した「全国地方公共団体コード」は後で病院の法人名を名寄せする際の補助情報として使用します。
2 施設名(病院名)
2.1 方針検討
これまで病院名を注意して見たことはなかったのですが、一覧を眺めつつ少し調べてみると
1)法人格の種類(例:医))
2)法人名(例:桐伸会)
3)病院名(例:藤井クリニック)
という3つの内容が渾然一体となってかなりフリーダムな表記を生み出している模様です。
おおよその傾向としては大きめの「病院」では上記3点が表記され、それ以外の「診療所」では病院名だけが表記されているように見えたので、法人名があるものはそれを、無いものは病院名で名寄せしてみることにします。
その際、法人格の種類を機械的に整備するのは至難に思えたため、逆に法人格の種類を削って名寄せする方針としました。
2.2 施設名をコピーして法人格の種類を除去
「▼施設名」の▼をクリックして テキストフィルター を選び、左サイドの施設名フィルターで「□正規表現」をチェックして該当しそうな文字を列挙してみると
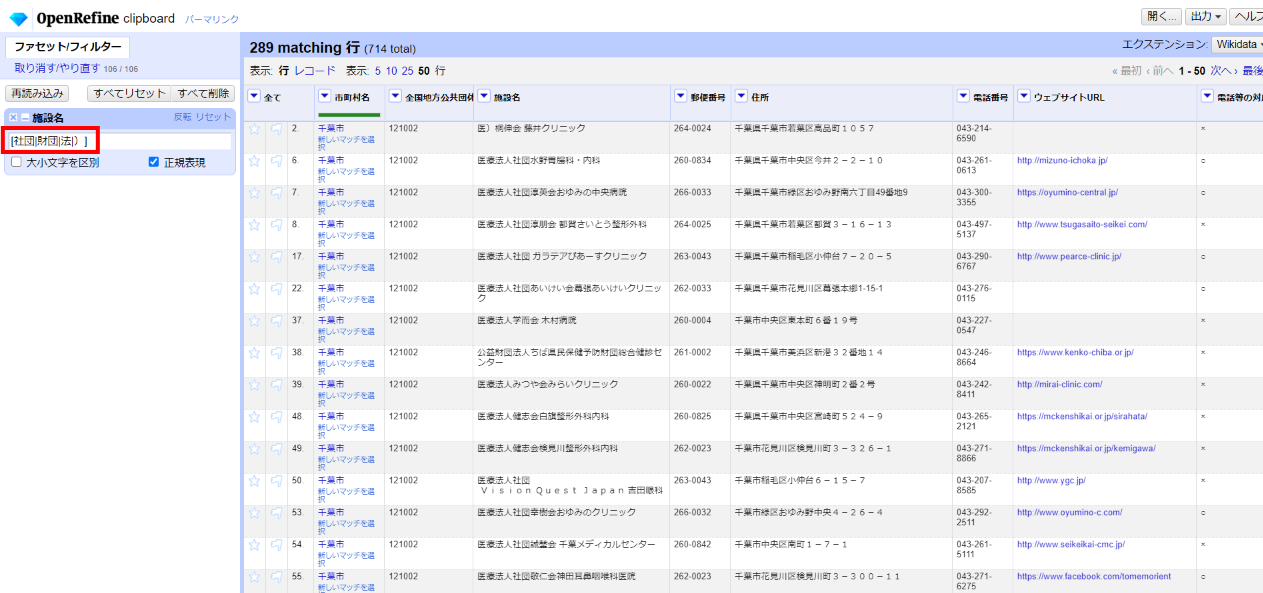
[社団|財団|法|)]
でおおよそ法人の種類が表記された行を抽出できました。
2.3 法人名と病院名を分割
正確ではありませんが、法人名と病院名が併記されている場合にはだいたい半角スペースで区切られているので、これを元に法人名と病院名のカラムを追加します。
2.3.1 フィルターを外す
施設名フィルターをXでいったん閉じて
「▼施設名」の▼をクリックして カラム編集>複数のカラムに分割 と選び
区切り文字に「 」(半角スペース)を設定し、「□このカラムを取り除く」のチェックを外して「OK」。
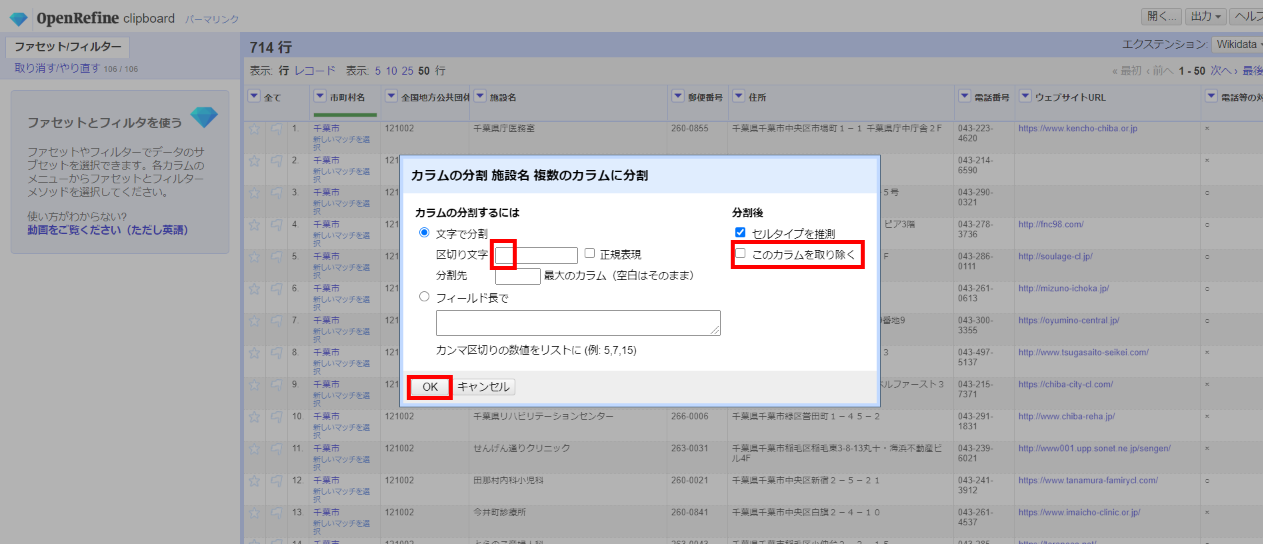
「施設名6」までできちゃいましたw
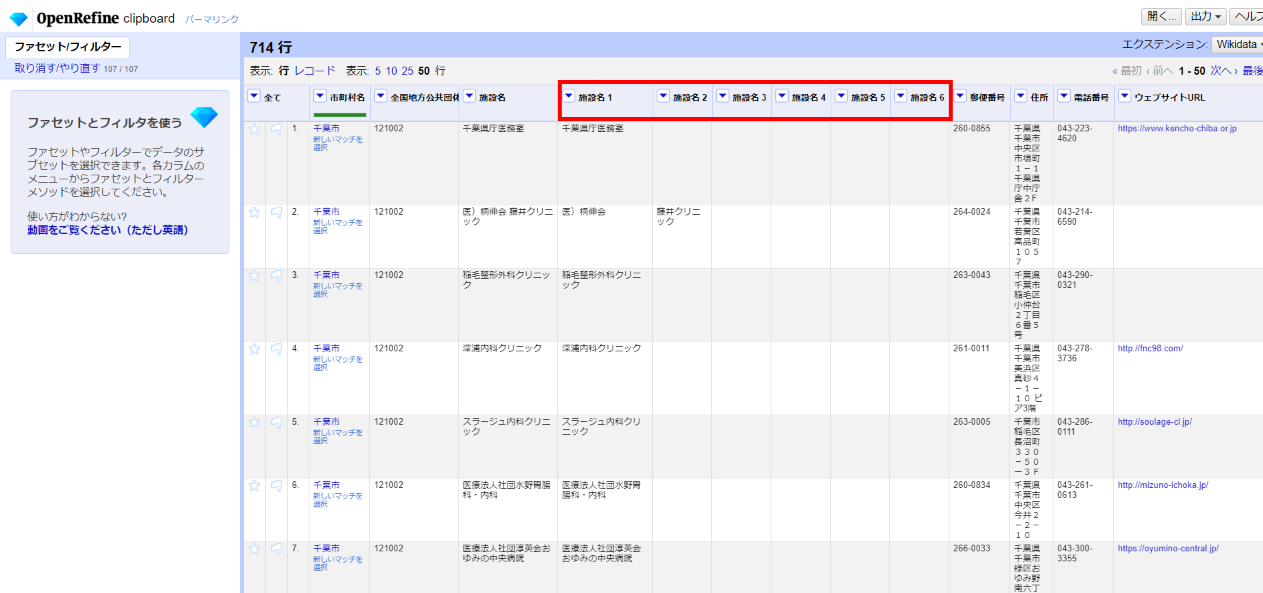
半角スペースを多用しているものがあったようなので、値を集約します。
まずカラム名を「カラム編集>カラム名を変更する」で下記のように変更して分かりやすくします。
施設名1 -> 法人名
施設名2 -> 病院名
2.3.2 手作業で値を移動
次に、後ろのカラムから順に整形して、値を集約します。
「▼施設名6」で▼をクリックして ファセット>テキストファセット と選びます。
有効な値が2件ありました。施設名6ファセットでまず1件目を選びます。
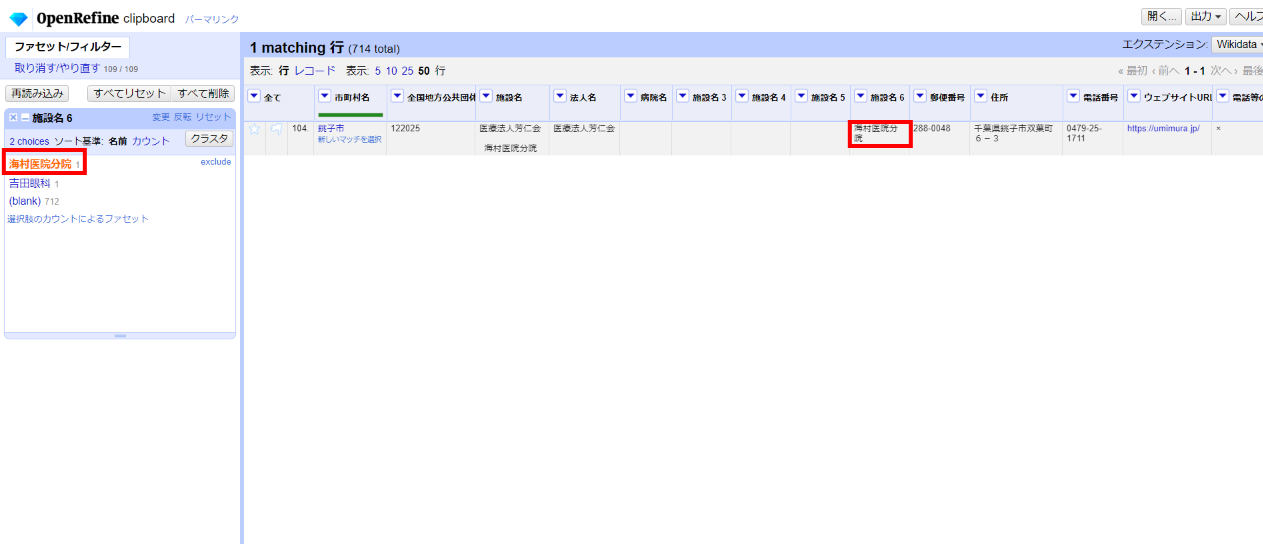
「施設名6」の値を「病院名」カラムへ手動で移します。
2件目は「施設名6」の値を「病院名」カラムへ、それ以外を「法人名」カラムへ移します。
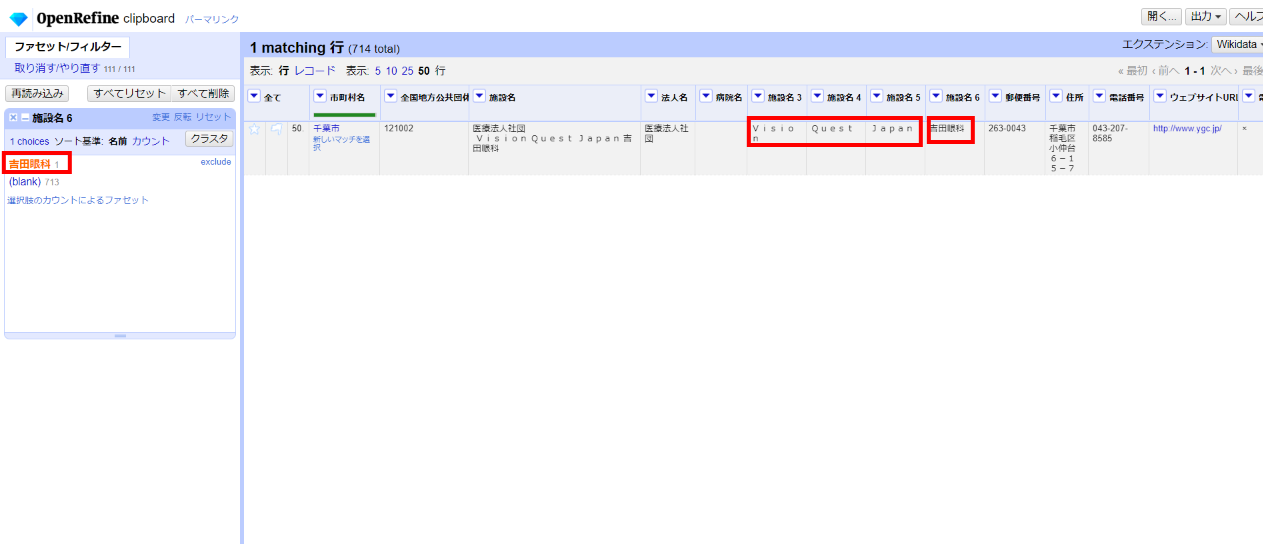
「施設6」の値は全てブランクになったので「カラム編集>このカラムを取り除く」で削除します。
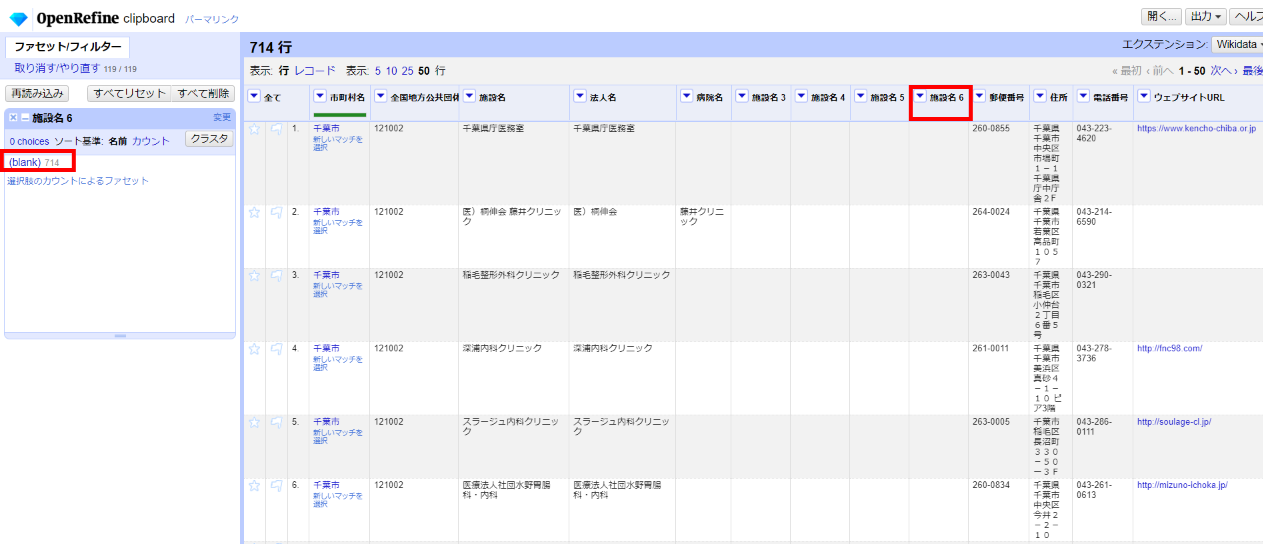
以下同様に名前を「法人名」か「病院名」へ寄せて「施設3」まで取り除きます。
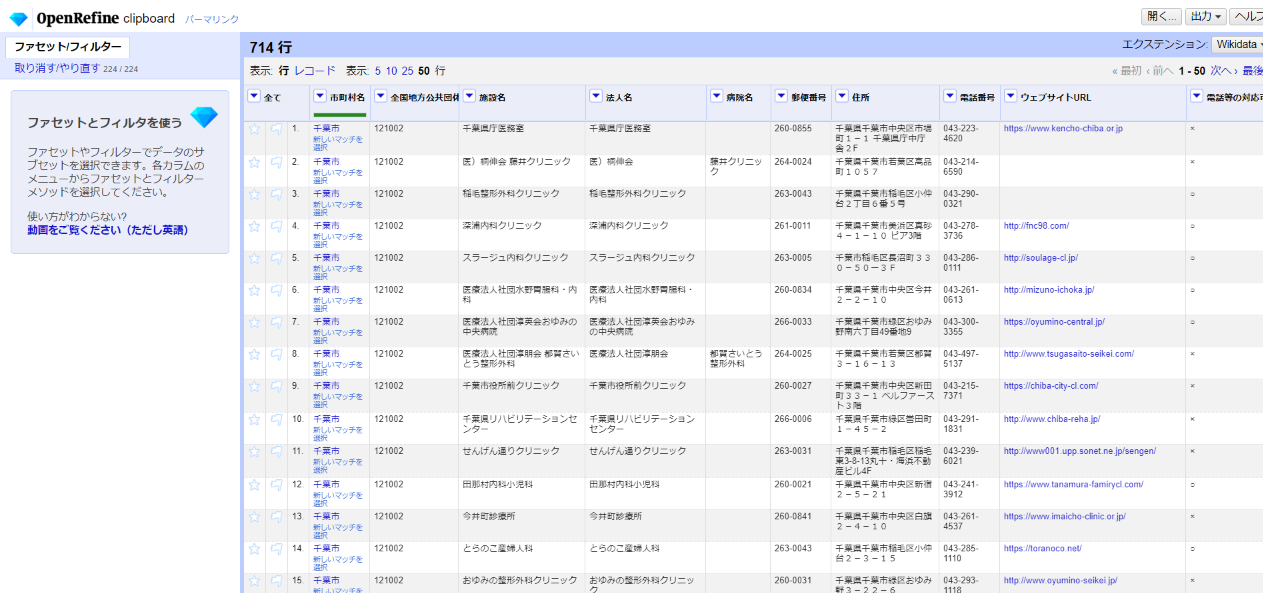
2.3.3 法人名の整形
次に「法人名」カラムから雑多な表記の法人種別を取り除いて法人名だけに整形します。
「▼法人名」の▼をクリックして テキストフィルター を選び、左サイドの法人名フィルターで「□正規表現」をチェックします。
[社団|財団|法|)]
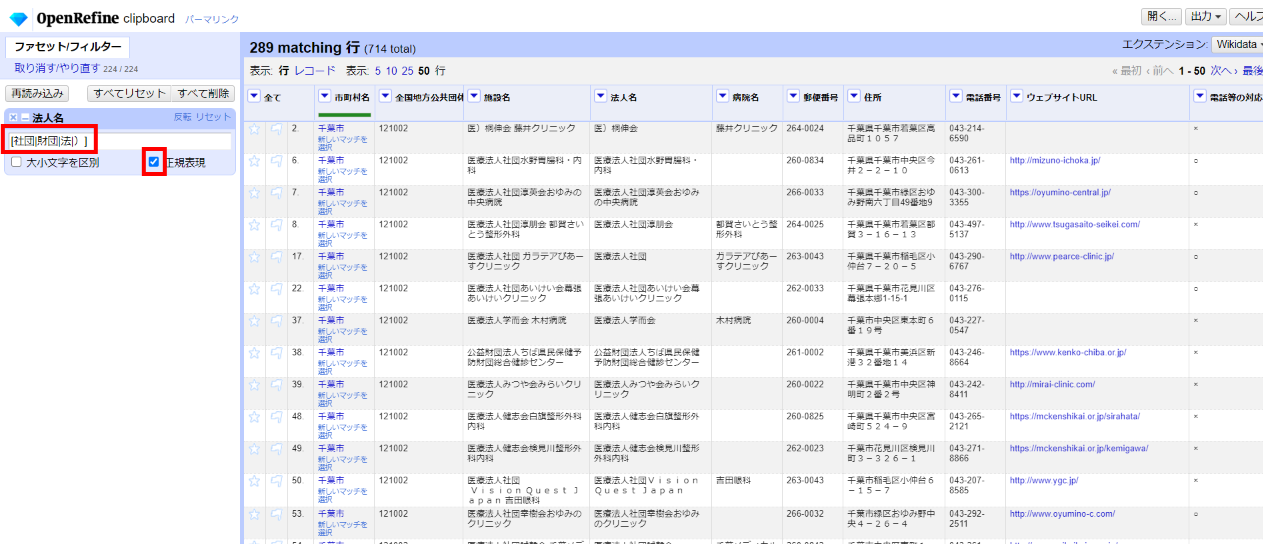
ここから、法人種別に相当する文字列を出現するパターンごとに空("")に置き換えていきます。
「▼法人名」の▼をクリックして カラム編集>変換 を選び、下記の式を順に入力してプレビューで確認しながら繰り返し実行します。
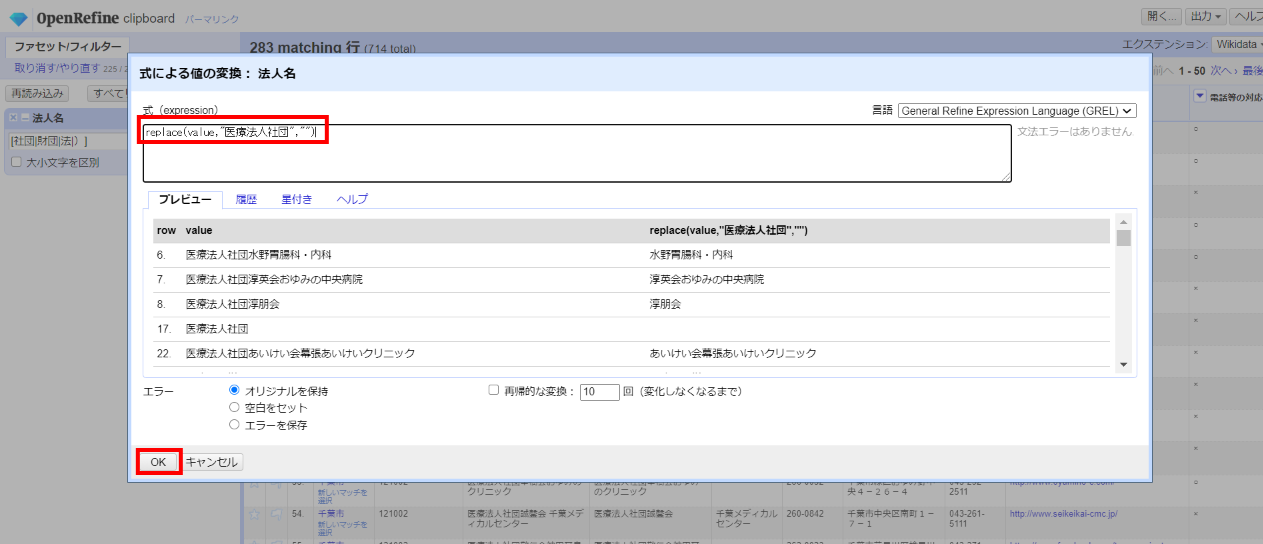
replace(value,"医)","")
replace(value,"医療法人社団","")
replace(value,"医療法人","")
replace(value,"公益財団法人","")
replace(value,"独立行政法人","")
replace(value,"一般社団法人","")
replace(value,"医療社団法人","")
replace(value,"財団","")
replace(value,"社団","")
replace(value,"(医社)","")
replace(value,"国立研究開発法人","")
replace(value,"社会福祉法人","")
replace(value,"社会","")
replace(value,"学校法人","")
replace(value,"国立大学法人","")
replace(value,"医社)","")
replace(value,"一般法人","")
少し残りましたが法人種別は無さそうなのでここまでにします。
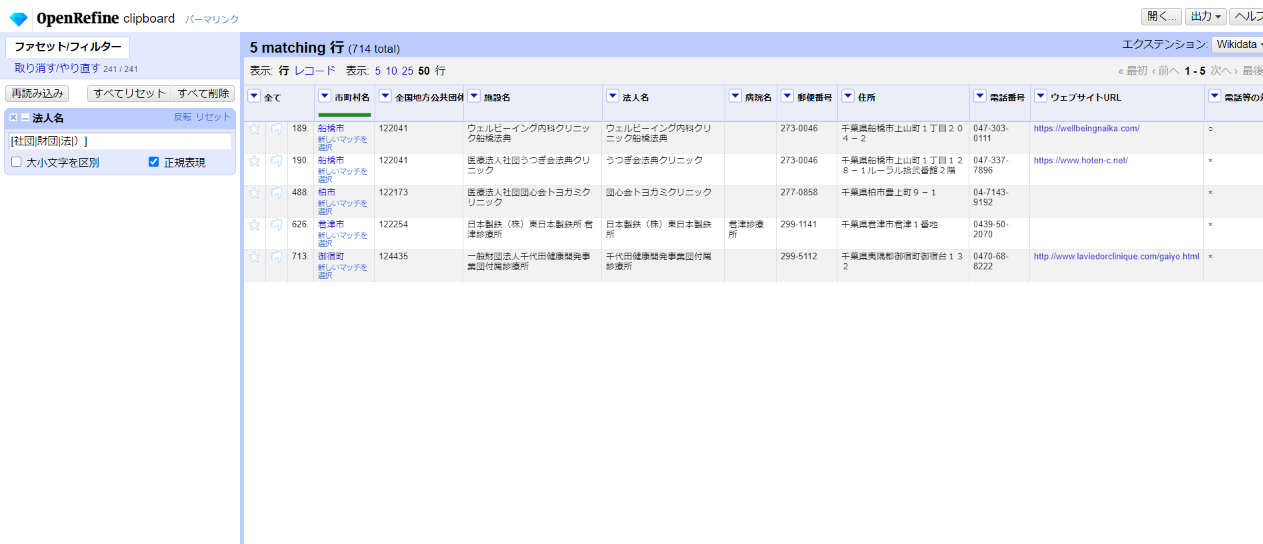
ファセットを全て解除して
「▼法人名」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) を選び、さらに左サイドの法人名ファセットで「true」(法人名が空白)を選びます。
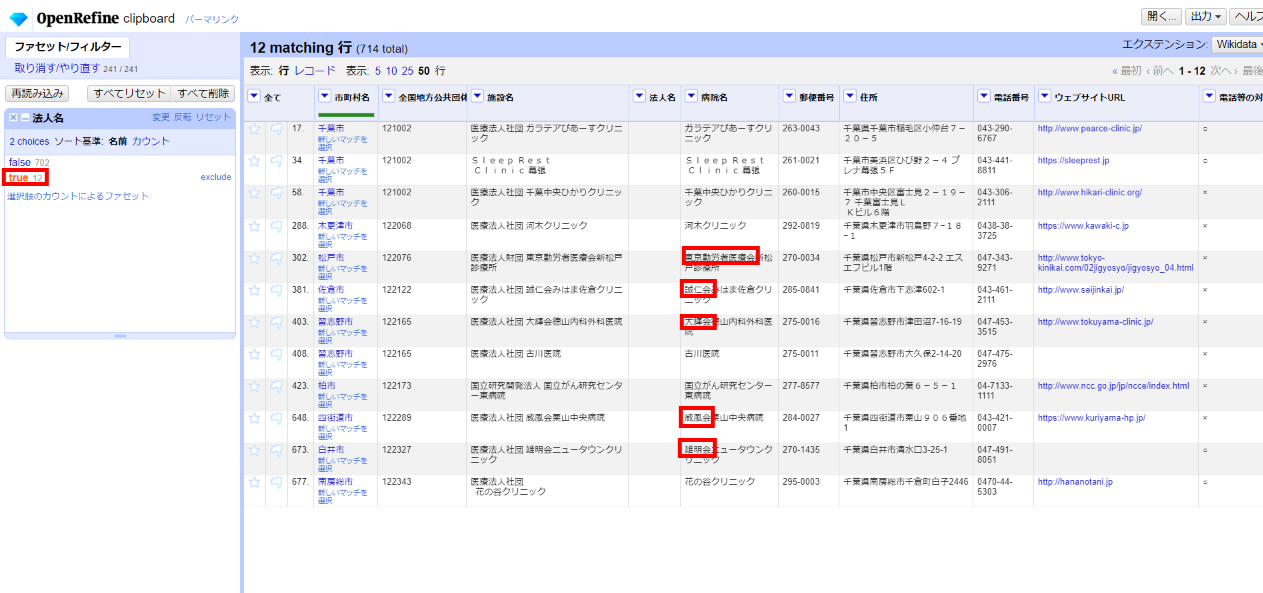
5件ほど法人名らしいものが付いているものがあるので切り取って法人名カラムに移します。
法人名と病院名が区切れていないものが結構ありそうなので改めて「法人名」を確認します。
文字列末尾が「会」で無いものを探すことにします。
ファセットを解除して
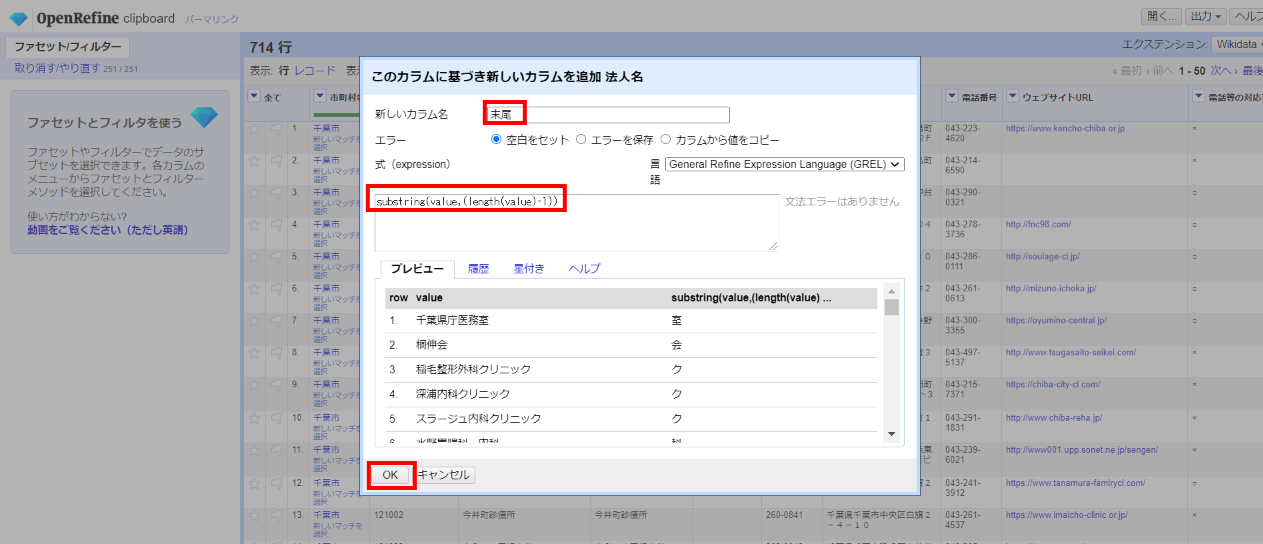
「▼法人名」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 を選び、下記のようにを入力して「OK」。
カラム名:末尾
式:substring(value,(length(value)-1))
「▼末尾」の▼をクリックして ファセット>テキストファセット を選び、左サイドのファセットで「会」を選んで、さらに「反転」させます。
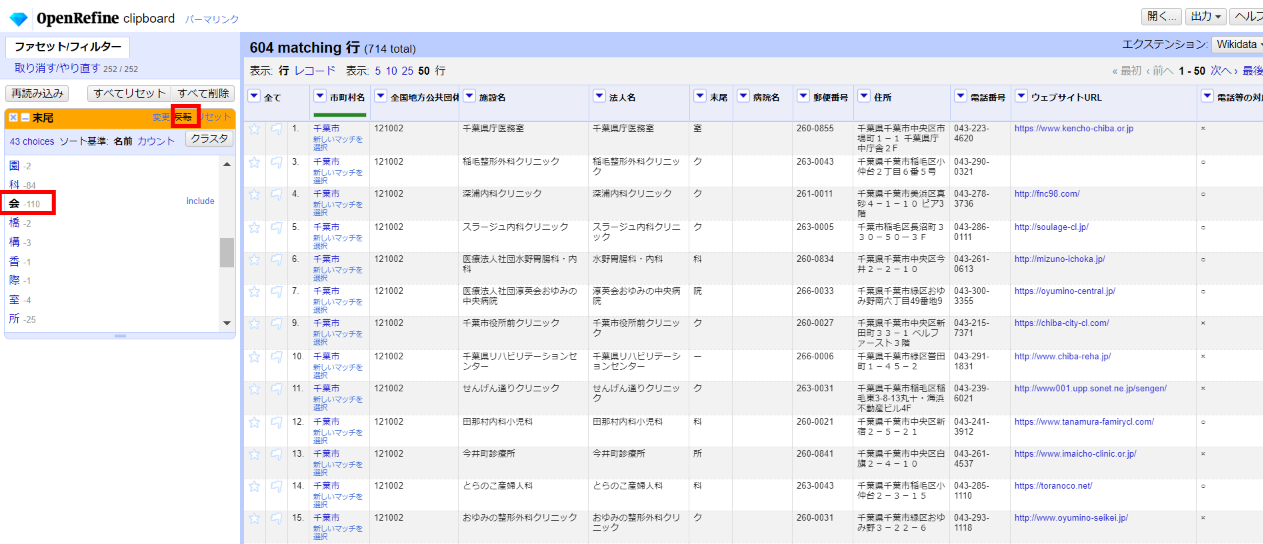
法人名末尾が「会」以外のものが表示されました。ここからさらに法人名に「会」を含むものを探します。
「▼法人名」の▼をクリックして テキストフィルターを選び、左サイドのフィルターで「会」を入力します。
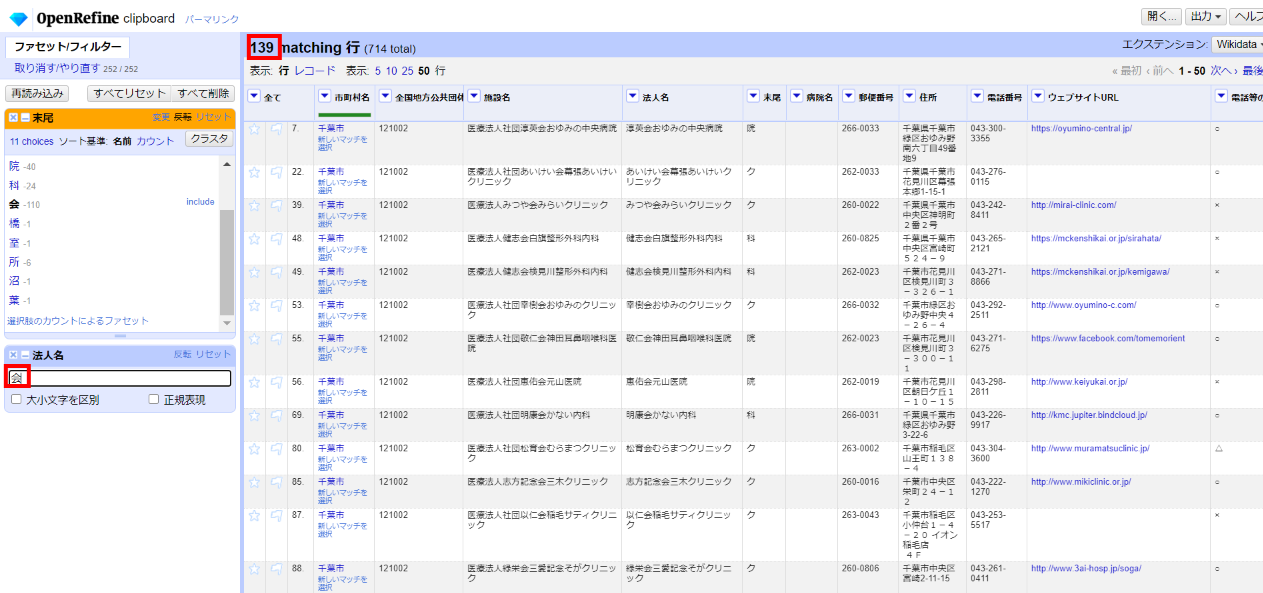
139件と結構あるので一括して分割した上で、法人名、病院名それぞれのカラムに移します。
「▼法人名」の▼をクリックして カラム編集>複数のカラムに分割 を選びます。
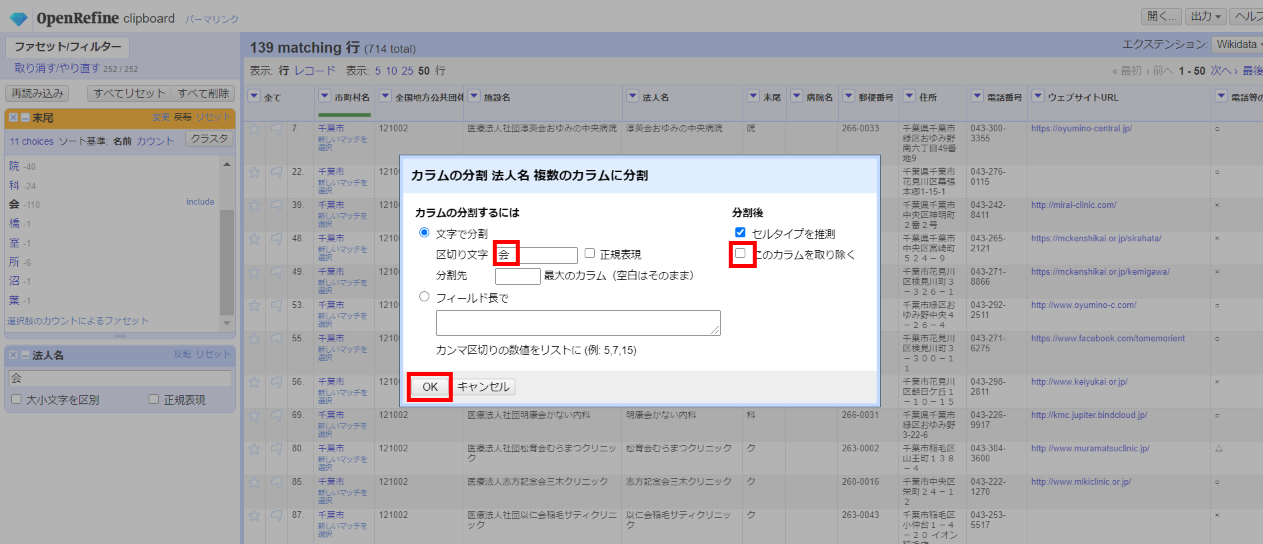
区切り文字に「会」を設定し、「□このカラムを取り除く」のチェックを外して「OK」。
「法人名2」で ファセット>テキストファセット から値を確認すると
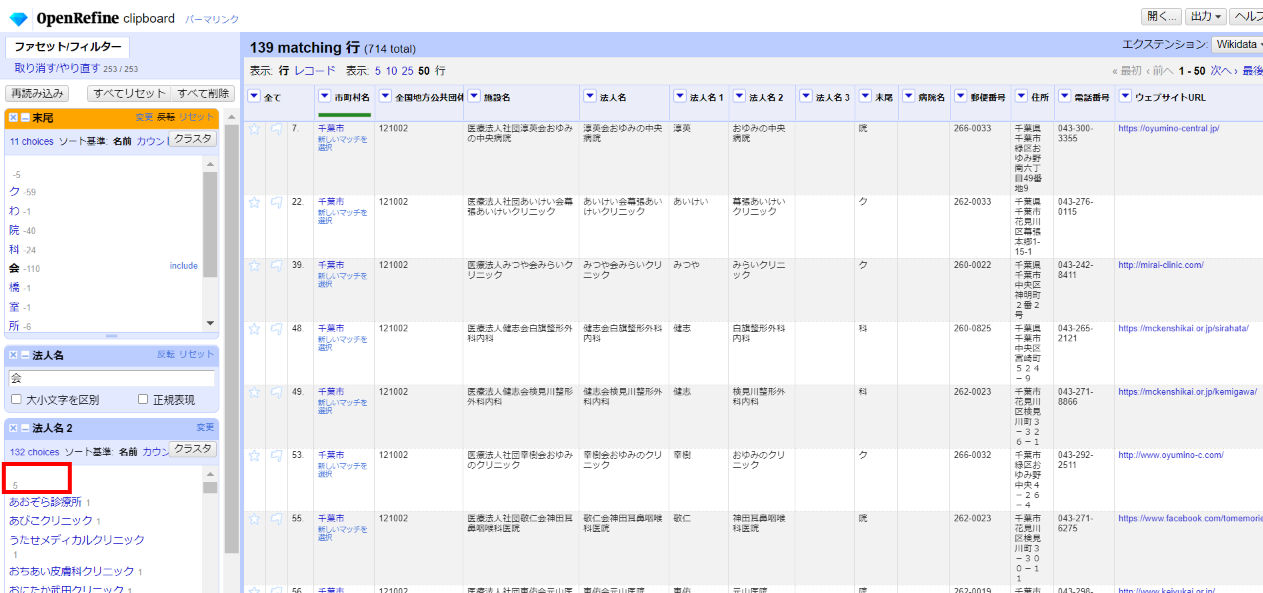
半角スペース5件があるのでこれを空白にします。
「病院名」カラムで、ファセット>カスタムファセット>空白ファセット(null/空白) を選び、左サイドで「true」を指定します。
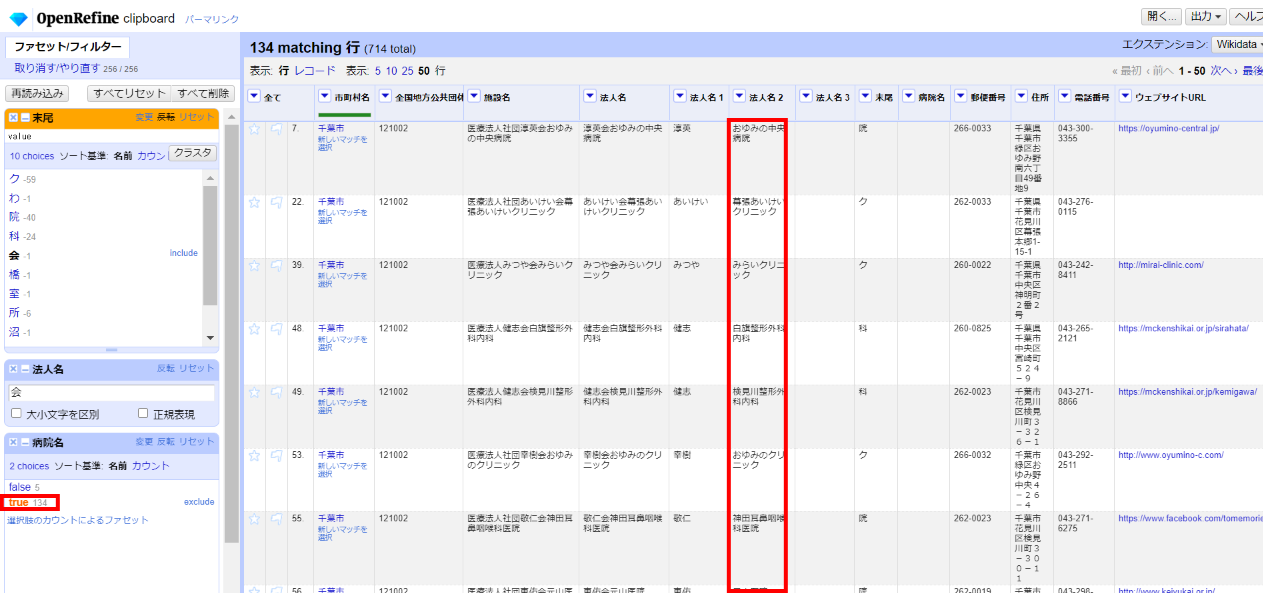
「法人名2」を「病院名」に移します。
「▼病院名」の▼をクリックして セル編集>変換 と選んで、式に下記を指定して「OK」。
cells["法人名 2"].value
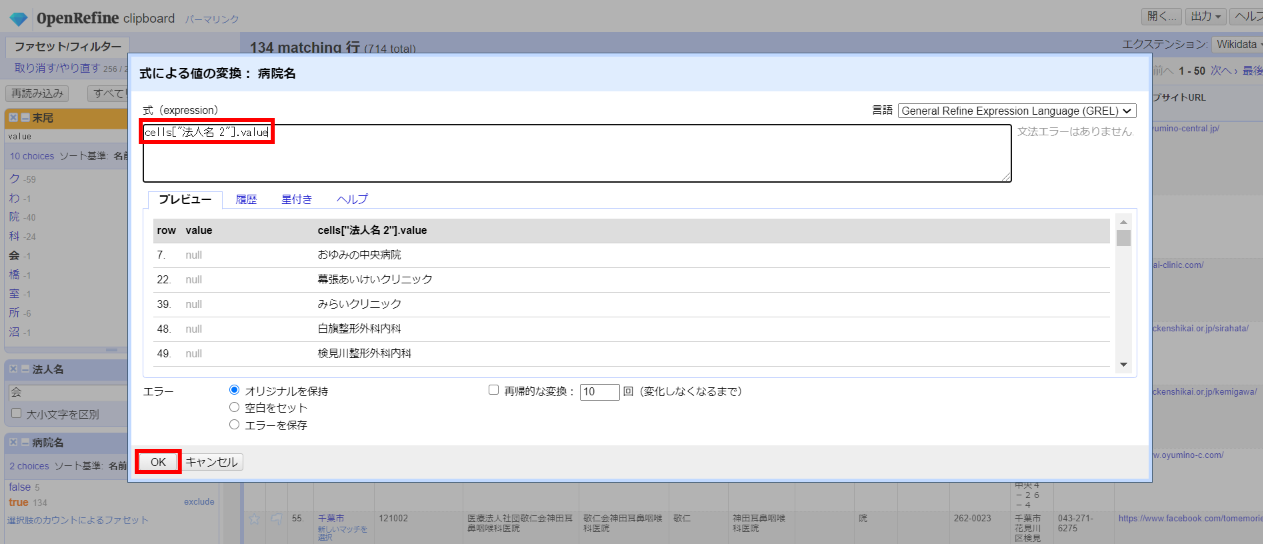
左サイドで病院名の空白ファセットを解除します。
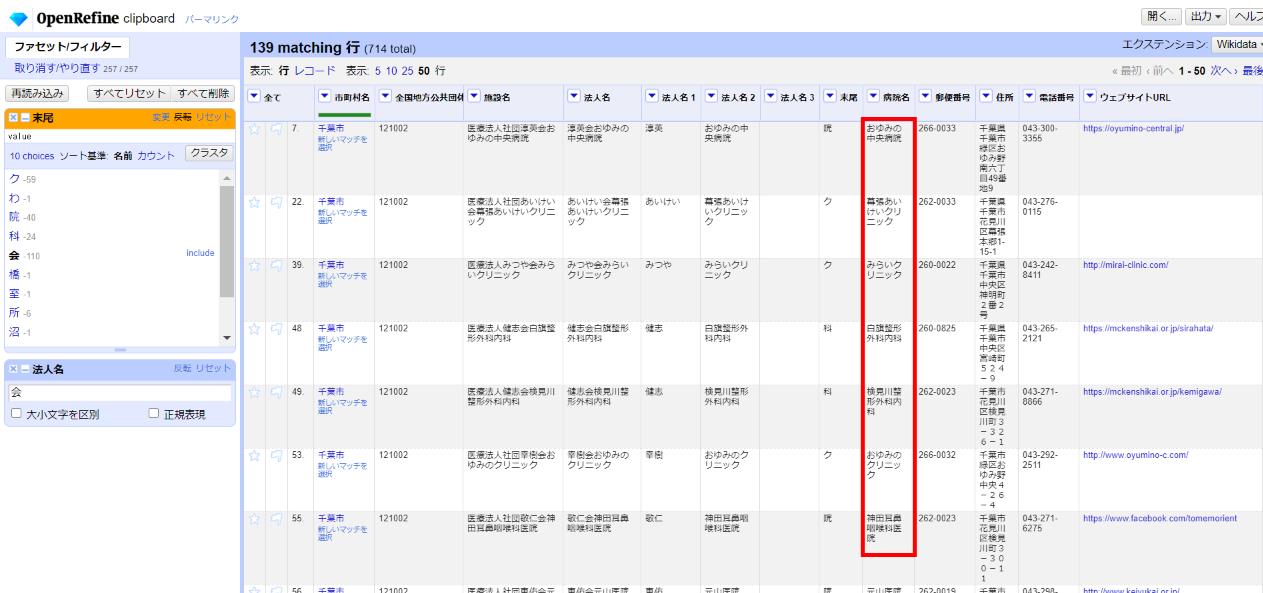
「法人名2」が「病院名」にコピーされました。
「法人名2」を カラム編集>カラムを取り除く で削除します。
「法人名1」に「会」を除いた法人名が入っているので、改めて「会」を追加します。
「▼法人名1」の▼をクリックして セル編集>変換 と選んで、式に下記を指定して「OK」。
value+"会"
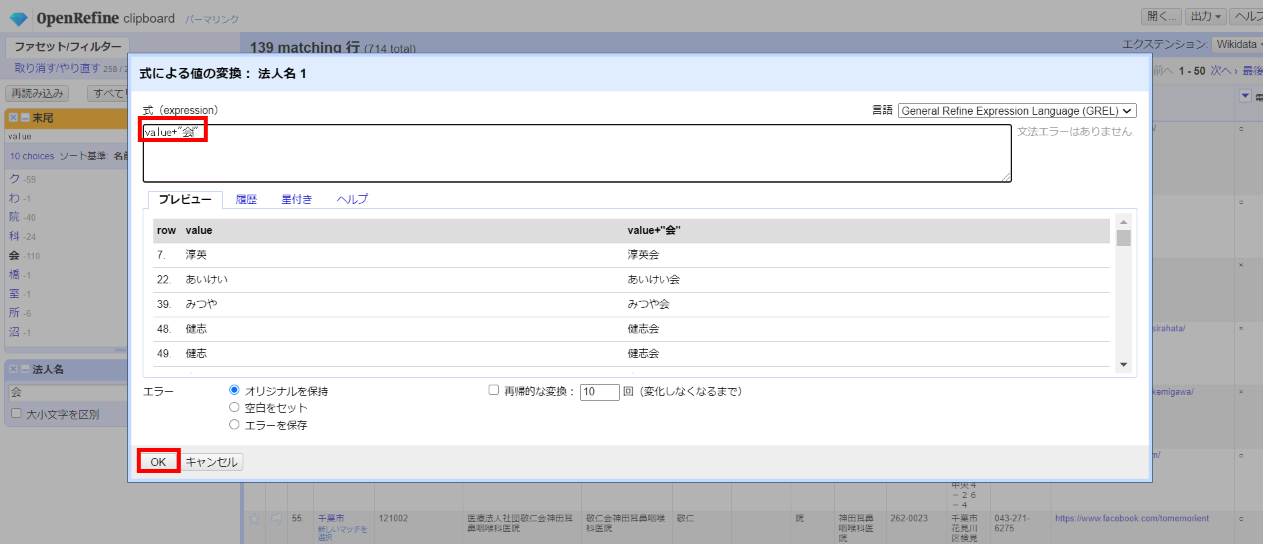
この値を「法人名」カラムに上書きします。
「▼法人名」の▼をクリックして セル編集>変換 と選んで、式に下記を指定して「OK」。
cells["法人名 1"].value
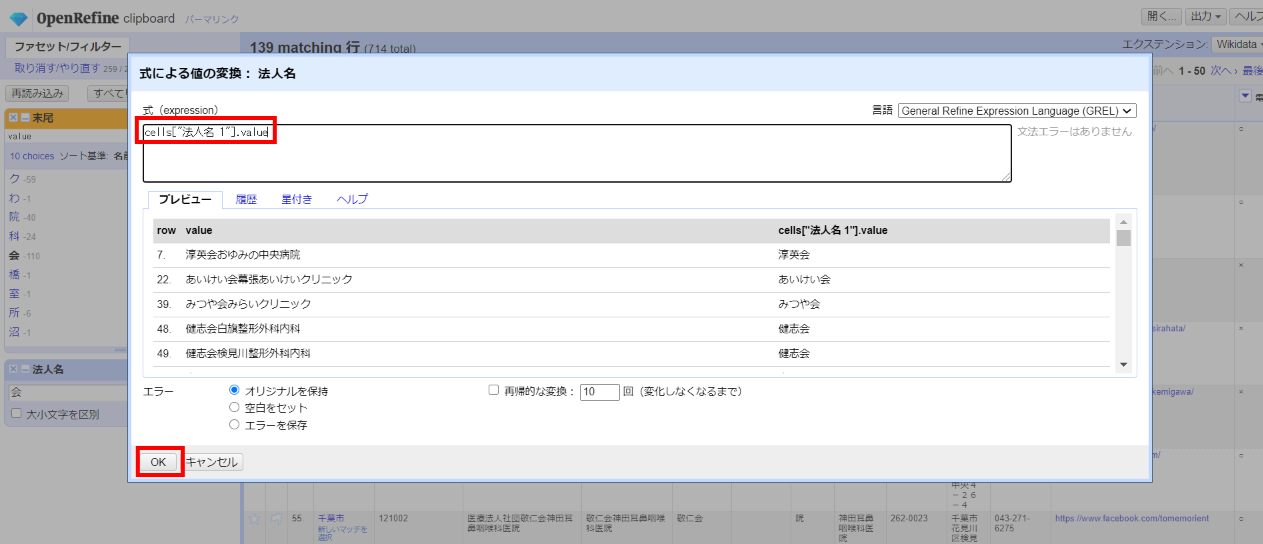
移し終わったので「法人1」を削除します。
「▼法人名1」の▼をクリックして カラム編集>このカラムを取り除く と選んで「OK」。
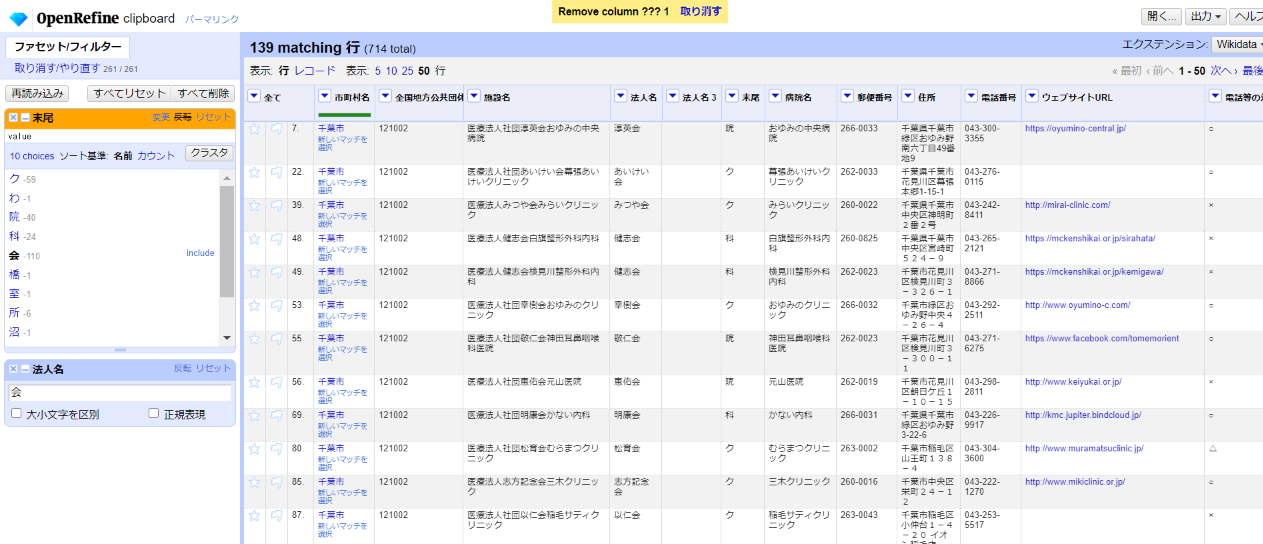
おっと「法人名3」が残っているのに気づきました。
「▼法人名3」の▼をクリックして ファセット>テキストファセット と選んで左サイドの法人名3ファセットで1件目を選びます。
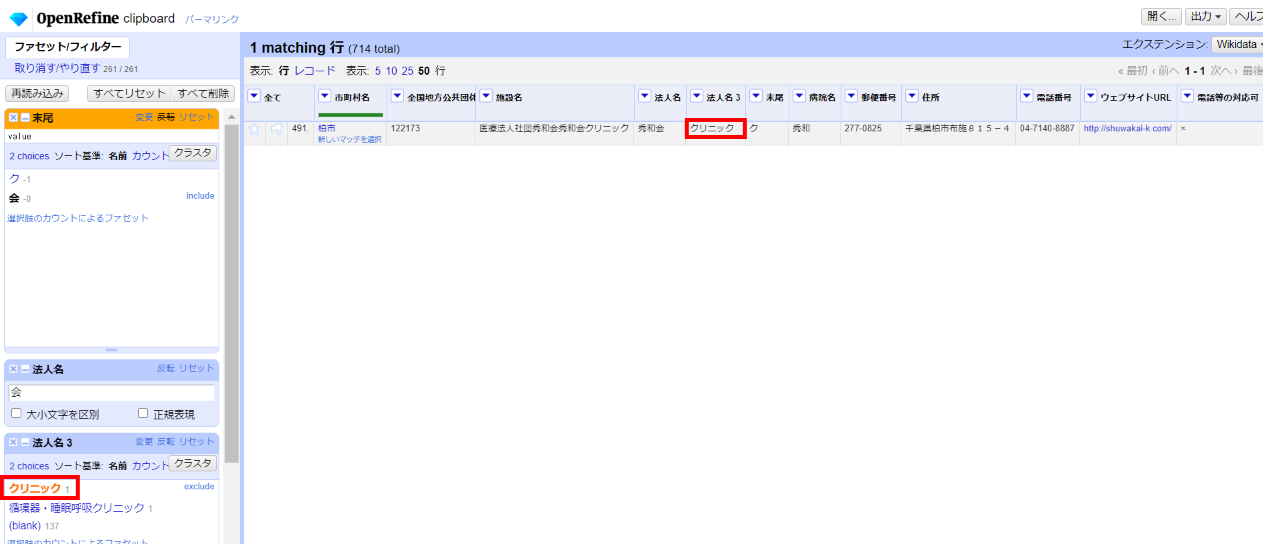
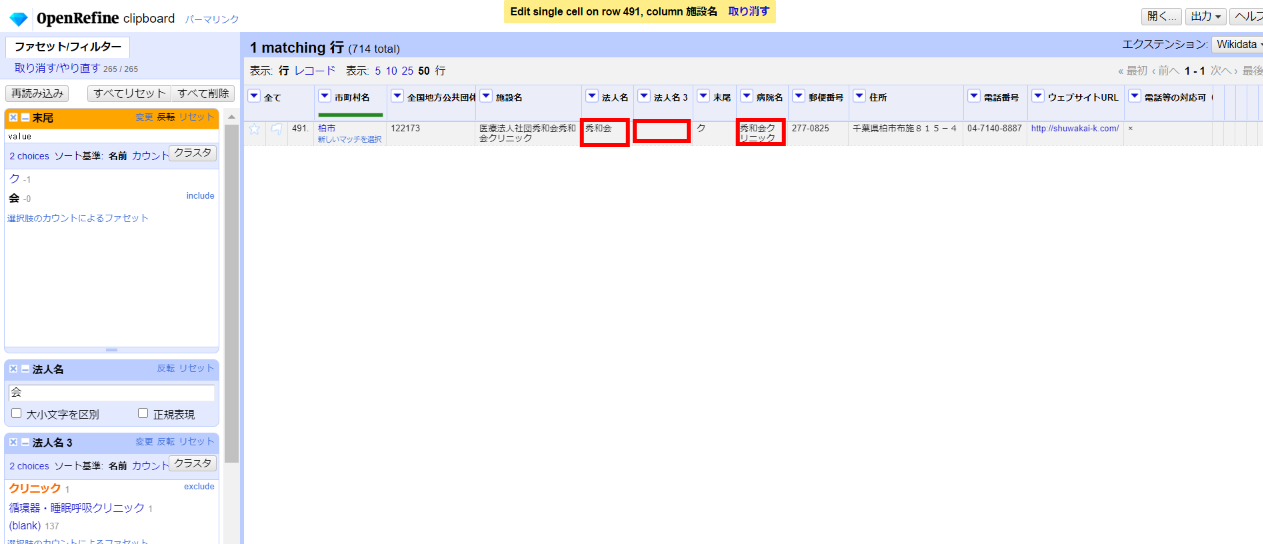
「医療法人社団秀和会秀和会クリニック」となっています。病院名が「クリニック」だけだと格好が付かないので法人名が2回繰り返されることになったんでしょうね。各カラムを整形し直します。
2件目を選びます。
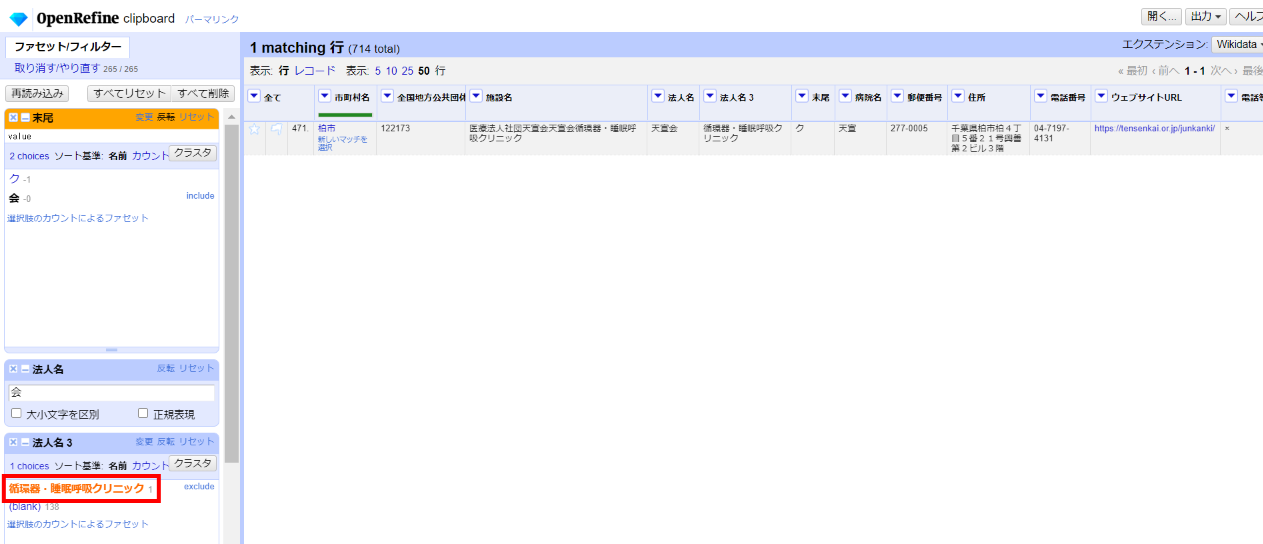
これも同じ理由のようですね。同様に整形します。
0件になったので「法人名3」カラムをカラム編集から削除します。
「末尾」カラムももう使用しないので削除します。
左サイドのファセット/フィルターを全て解除します。
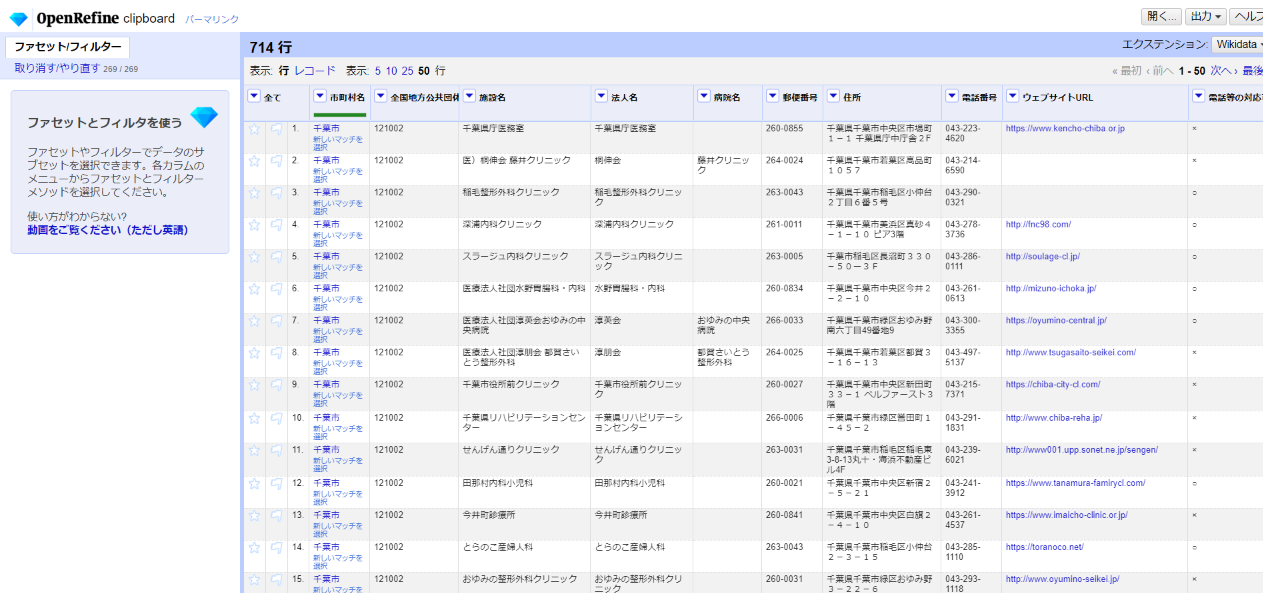
これで「法人名」と「病院名」の分割はあらかたできましたが、微調整が残っているので改めて値を確認します。
「▼法人名」の▼をクリックして ファセット>テキストファセット と選びます。
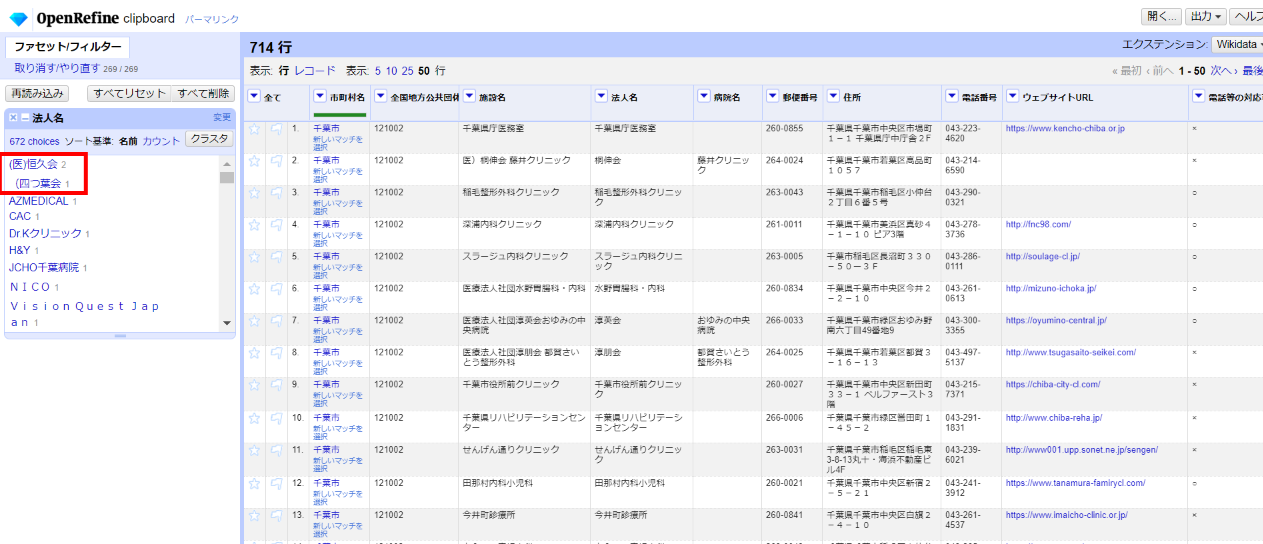
上から2件にゴミが残っているので左サイドのファセット上で整形します。
おや、ファセット内1件目の件数が2件となっています。いやな予感がします。「法人名:病院名」が「1:n」のケースでしょうか。見なかったことにして先に進みますw
「▼病院名」の▼をクリックして ファセット>テキストファセット と選びます。
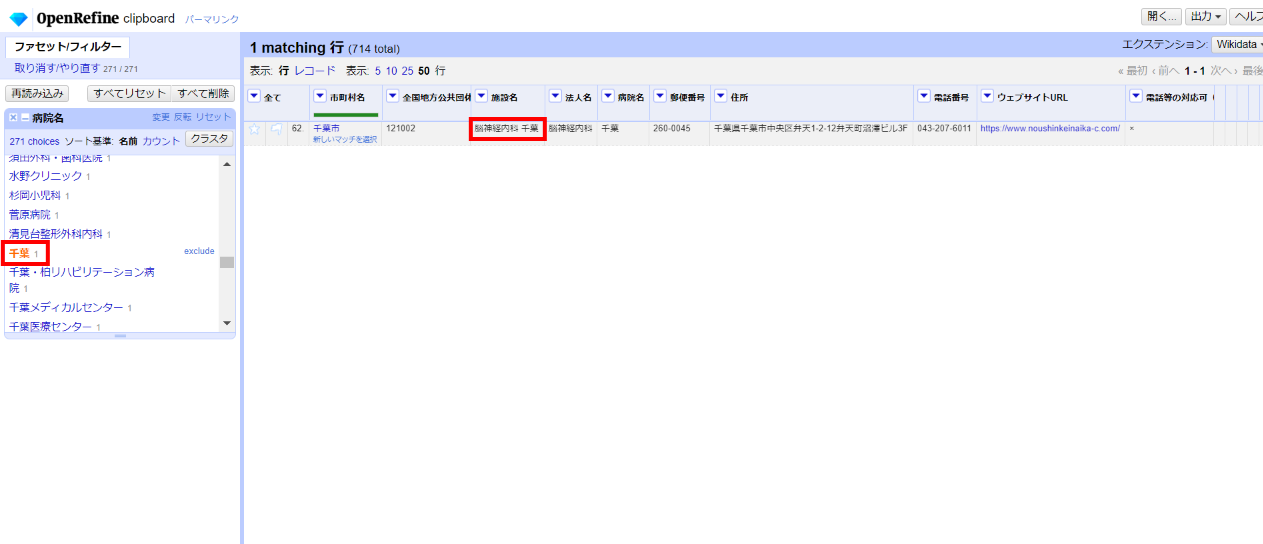
左サイドのファセットをブラウズすると「千葉」という病院名がありました。
選んでみると施設名が「脳神経内科 千葉」となっています。これは分割しない方が良さそうですね。法人名の方に寄せておきます。
さらに見ていくと「病院」と「分院」というのがありました。これはダメですね。選んでみると
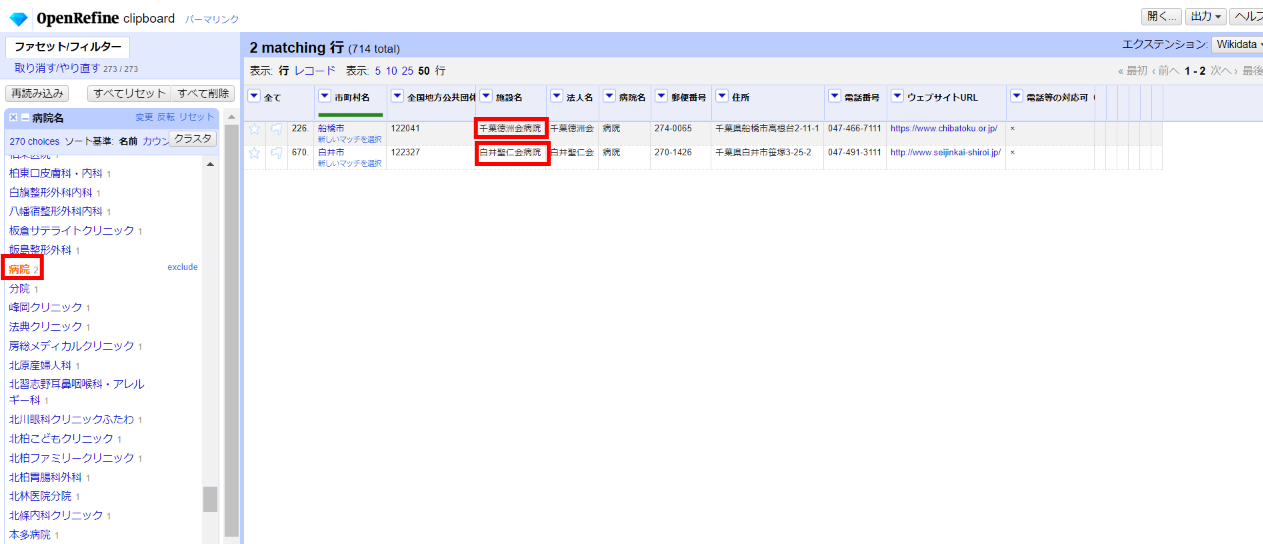
どこまでが法人名で病院名なのか、一瞥しては分かりません。それぞれウェブサイトで確認すると
「医療法人沖縄徳洲会千葉徳洲会病院」
「医療法人社団聖仁会白井聖仁会病院」
らしいので、それぞれ整形します。
「分院」を選ぶと施設名が「川上診療所 分院」となっており、これは分割できないとみるべきでしょうね。
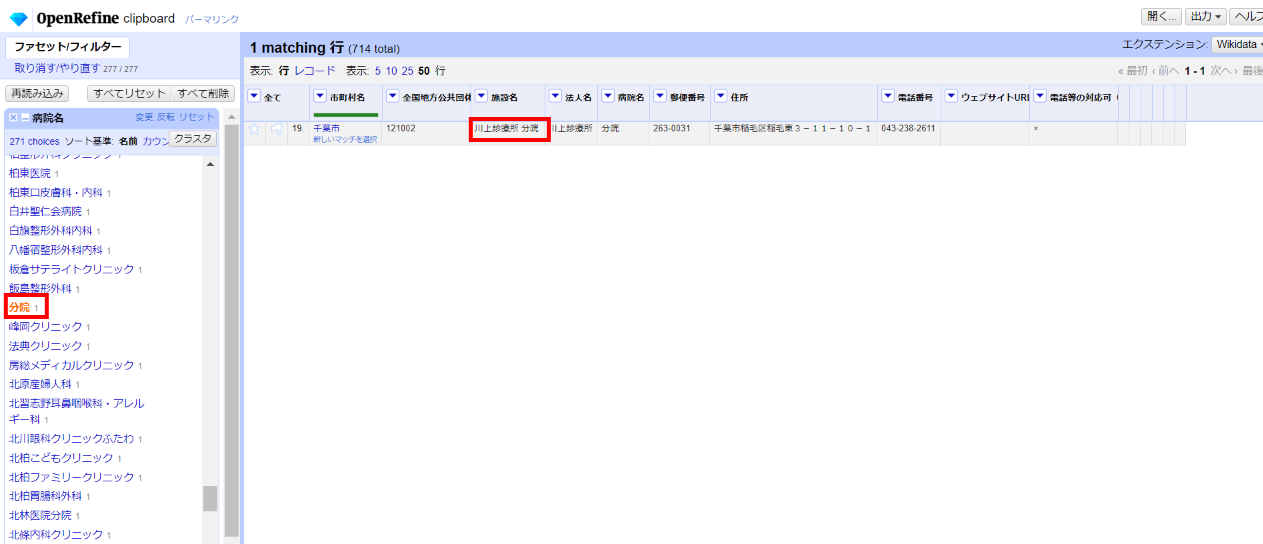
法人名の方に寄せて整形します。
改めて「▼法人名」の▼をクリックして ファセット>テキストファセット と選んで左サイドのフェセットで値を確認してみます。
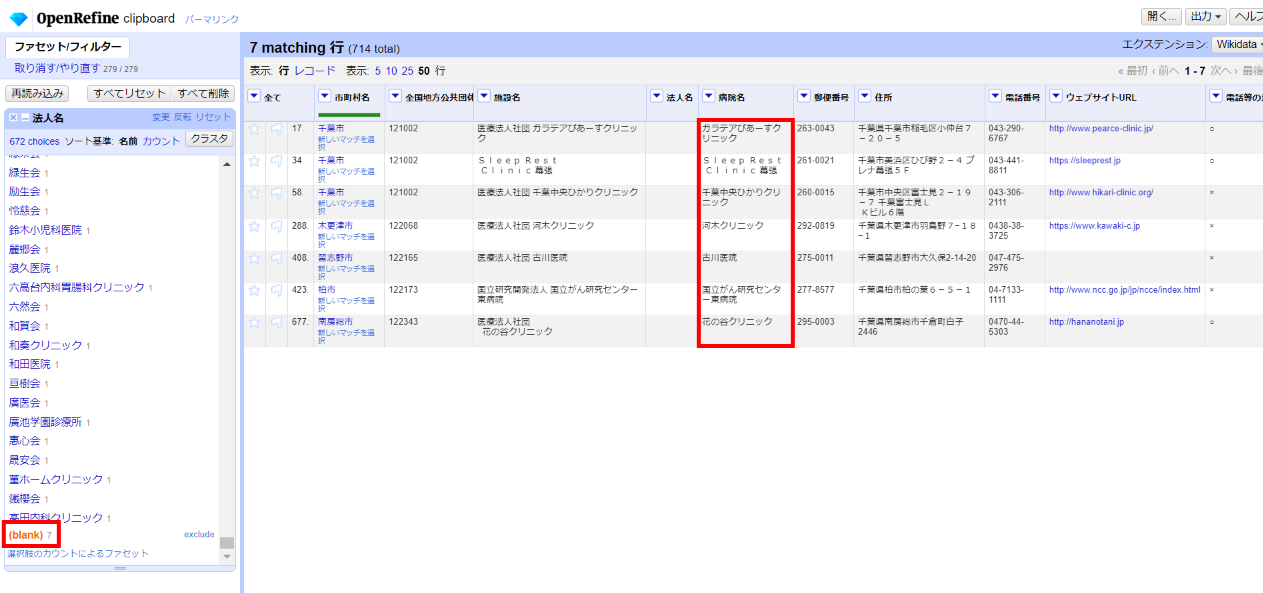
空白が7件あり、いずれも「病院名」に寄せられています。
このままでも間違いではありませんが、一括処理のためにはカラムが寄せられていたほうが処理しやすいので、カラム編集で下記式を使って値を「法人名」カラムにコピーし、、もとの値を空白にします。
cells["病院名"].value
改行コードの混在をチェックします。
「▼法人名」の▼をクリックして テキストフィルター と選んで左サイドのフェセットで「\n」と入力し「□正規表現」をチェックします。
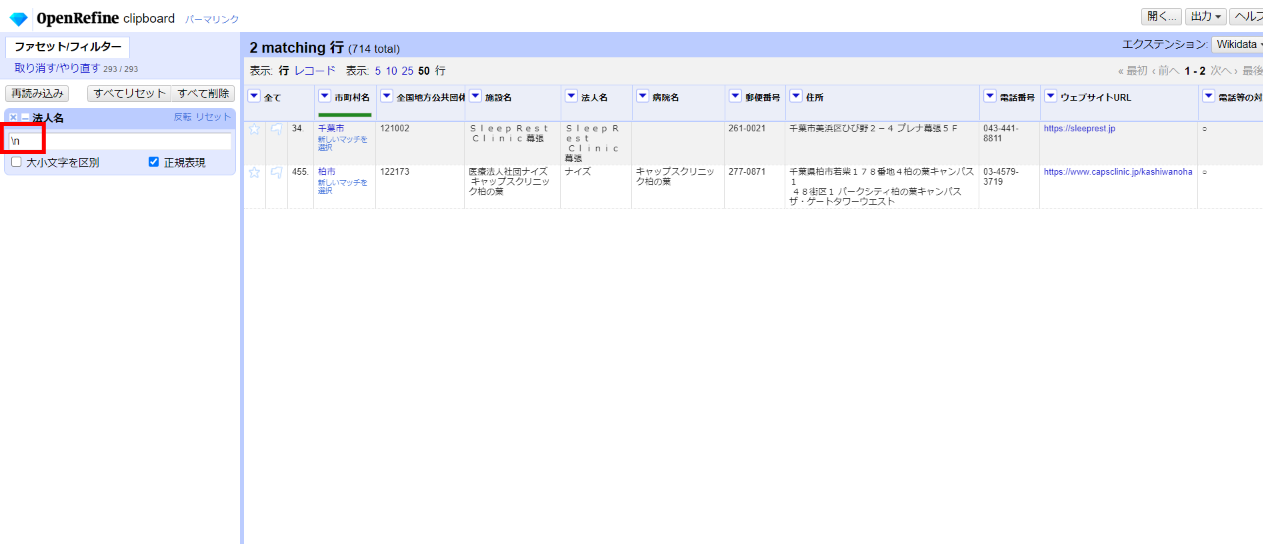
2件ありました。件数が少ないので手動で整形します。
これで「法人名」と「病院名」の分割結果について、一通りチェック完了です。
左サイドのファセット/フィルターを解除します。
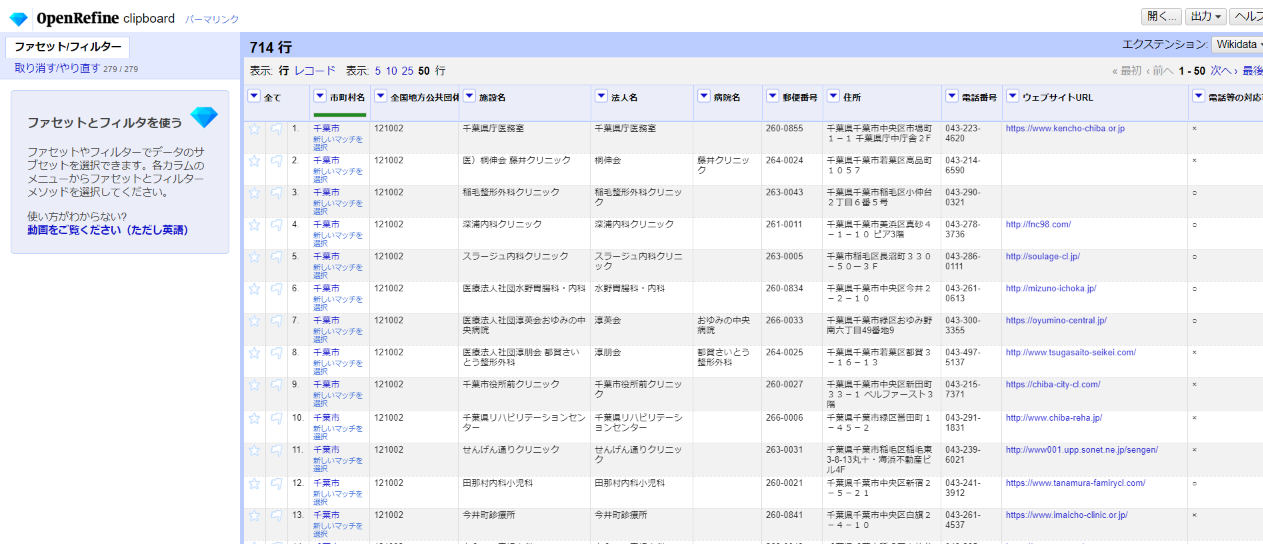
「施設名」カラムが元々あった名前で、「法人名」カラムが法人格の種類を取り除いたものです。
3 国税庁の法人番号APIで名寄せ
ここまで法人名の整形を頑張ってきたのは、国税庁の法人番号システム Web-APIを利用して名寄せをするためです。このサービスはAPIキーの申込みが必要ですが、申込書を書いて送れば、個人であれ法人であれ、特に問題なければ2週間くらいでAPIキーが郵送されてきます。
大量アクセスは避けるようにとは書いてありますが、特に明確な数値は定められていません。とはいえ節度をもって利用するべきでしょう。またこのAPIを利用してサービスを構築する場合などはクレジット表記が求められています。
3.1 API仕様
こちらの
24ページあたりに法人名で情報を取得するやり方が記載されています。

パラメータは概略以下の通りです。
id:APIキー(実際に試す場合は自分で取得してください)
name:法人名
mode:検索モード(1:前方一致検索/2:部分一致検索)
address:(県コードまたは市区町村コード)-> 法人名だけだと同名の法人が複数返される場合があります。
type:応答形式(01:CSV-シフトJIS,02:CSV-Unicode,12:XML-Unicode)
3.2 APIの動作確認
以下のようなURLパラメータで試してみます。
3.2.1 未発見応答
https://api.houjin-bangou.nta.go.jp/4/name?id=****&name=%E3%81%A1%E3%81%B0%E7%9C%8C%E6%B0%91%E4%BF%9D%E5%81%A5%E4%BA%88%E9%98%B2%E8%B2%A1%E5%9B%A3&mode=2&address=12&type=12
id:APIキー(伏せたものなのでこのまま実行しないでください)
name:千葉県庁医務室
mode:2(部分一致検索)
address:12(千葉県)
type:12(XML)
応答:
<corporations> <lastUpdateDate>2020-06-05</lastUpdateDate> <count>0</count> <divideNumber>1</divideNumber> <divideSize>1</divideSize> </corporations>
<count>:0件。これは法人名ではなさそうです。
<count>をパースすれば該当件数が拾えそうです。
3.2.2 発見応答
https://api.houjin-bangou.nta.go.jp/4/name?id=****&name=%E6%A1%90%E4%BC%B8%E4%BC%9A&mode=2&address=12&type=12
id:APIキー(伏せたものなのでこのまま実行しないでください)
name:桐伸会
mode:2(部分一致検索)
address:12(千葉県)
type:12(XML)
応答:
<corporations> <lastUpdateDate>2020-06-05</lastUpdateDate> <count>1</count> <divideNumber>1</divideNumber> <divideSize>1</divideSize> <corporation> <sequenceNumber>1</sequenceNumber> <corporateNumber>8040005014892</corporateNumber> <process>01</process> <correct>1</correct> <updateDate>2018-09-05</updateDate> <changeDate>2015-10-05</changeDate> <name>医療法人社団桐伸会</name> <nameImageId/> <kind>399</kind> <prefectureName>千葉県</prefectureName> <cityName>千葉市若葉区</cityName> <streetNumber>高品町1057番地</streetNumber> <addressImageId/> <prefectureCode>12</prefectureCode> <cityCode>104</cityCode> <postCode>2640024</postCode> <addressOutside/> <addressOutsideImageId/> <closeDate/> <closeCause/> <successorCorporateNumber/> <changeCause/> <assignmentDate>2015-10-05</assignmentDate> <latest>1</latest> <enName/> <enPrefectureName/> <enCityName/> <enAddressOutside/> <furigana>トウシンカイ</furigana> <hihyoji>0</hihyoji> </corporation> </corporations>
<count>:1件返されました。正しそうです。
<corporateNumber>:法人番号が拾えそうです。
<name>:法人種別の付いた法人登記名称が拾えそうです。
<prefectureName>:県名が拾えそうです。
<cityName>:住所前半が拾えそうです。
<streetNumber>:住所後半が拾えそうです。住所を全て結合すると、既にある住所とのチェックに使えそうです。建物名、階数、部屋番号などはありません。
<postCode>:郵便番号が拾えそうです。すでにある郵便番号とのチェックに使えそうです。
3.3 API呼び出し
3.3.1 前準備
3.3.1.1 市区町村コード
同名法人の取得を避けるために、市区町村コードをパラメータに追加すると良さそうなのですが、動作確認したところ政令市の千葉市だけは市のコード100ではなく、その下位レベルの区コード(若葉区なら102)が必要なようです。従って、千葉市だけは県コード(12:千葉県)だけで実施し、それ以外はそれぞれの市区町村コードで実施することにします。
3.3.1.2 法人名称
法人名称はURLエンコードしてから渡す仕様なのですが、OpenRefine側でのURLエンコードがどうにもうまく動かないため外部サービスを借りてURLエンコードした結果を「URLエンコード」カラムに入れました。残念。。
2020/7/11追記 下記でURLエンコードできるようです。
escape(value,'url')
また、英記号の社名も含め、全て全角に揃えておく必要があります。
その手順はおおまかに以下の通りです。
1)右上の「出力」ボタンから「タブ区切り(TSV)で出力」を選んで現在のプロジェクトをTSVに出力
2)TSVをエディタで開いてgoogle spread sheetに貼り付け、「URLエンコード」カラムを追加
3)法人名カラムの値を元に外部サービスでURLエンコード
4)「URLエンコード」に結果を貼り付け
5)google spread sheet全体をコピーしてOpenRefineにクリップボードから貼り付けて新規プロジェクトを作成
以下は新たなプロジェクトでの操作です。
3.3.2 千葉市
「▼市町村名」の▼をクリックして ファセット>テキスファセット と選び、左サイドのファセットウィンドウで「千葉市」を選ぶ。
千葉市分のみ99件表示されました。
「▼法人名」の▼をクリックして カラム編集>URLでカラムを追加 と選び、以下を設定して「OK」。
新しいカラム名:千葉市応答
フェッチ間隔の遅延:1000
エラー:「◯エラーを保存」をチェック
式:
"https://api.houjin-bangou.nta.go.jp/4/name?id=****&mode=2&type=12&address="+substring(cells["全国地方公共団体コード"].value,0,2)+"&name="+value

画面上部に黄色地の進捗率が表示されます。100%になったら完了です。

3.3.3 千葉市以外
3.3.3.1 API呼び出し
上記千葉市と同様の操作で出力カラム名とGREL式だけ変更します。(全国地方公共団体コードの先頭5桁を市区町村コードとしてセットします)
左サイドのファセットウィンドウで「千葉市」が選ばれた状態から「反転」でそれ以外を選びます。
千葉市以外が615件表示されました。
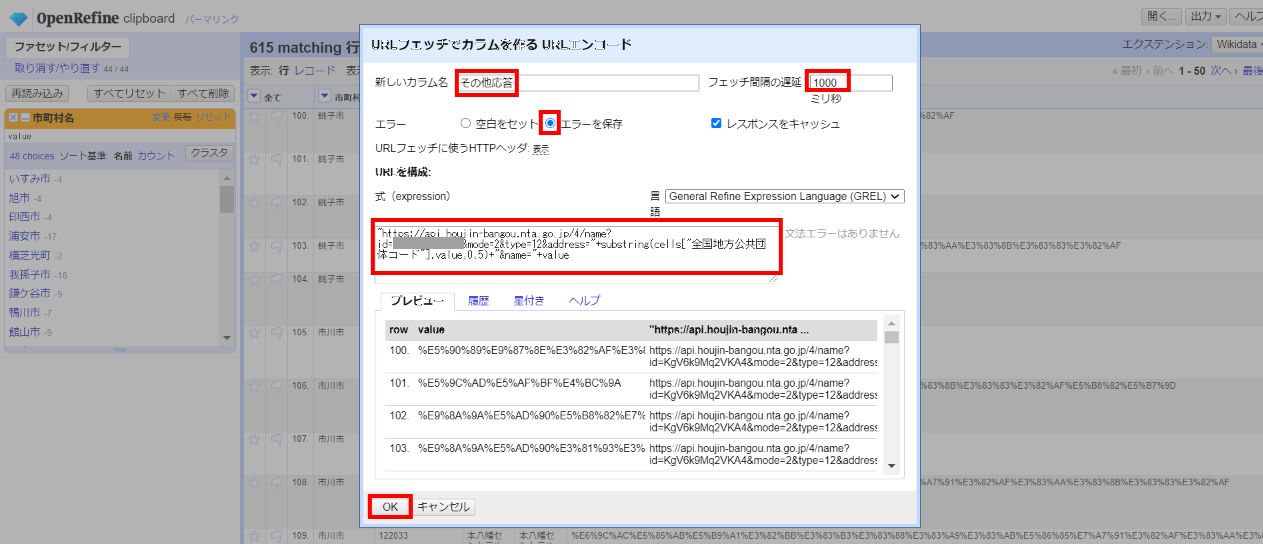
「▼法人名」の▼をクリックして カラム編集>URLでカラムを追加 と選び、以下を設定して「OK」。
新しいカラム名:その他応答
フェッチ間隔の遅延:1000
エラー:「◯エラーを保存」をチェック
式:
"https://api.houjin-bangou.nta.go.jp/4/name?id=****&mode=2&type=12&address="+substring(cells["全国地方公共団体コード"].value,0,5)+"&name="+value
3.3.3.2 戻り値の確認
空白の戻り値がないか確認します。
「▼その他応答」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選び、左サイドのその他応答ファセットで「true」を選びます。
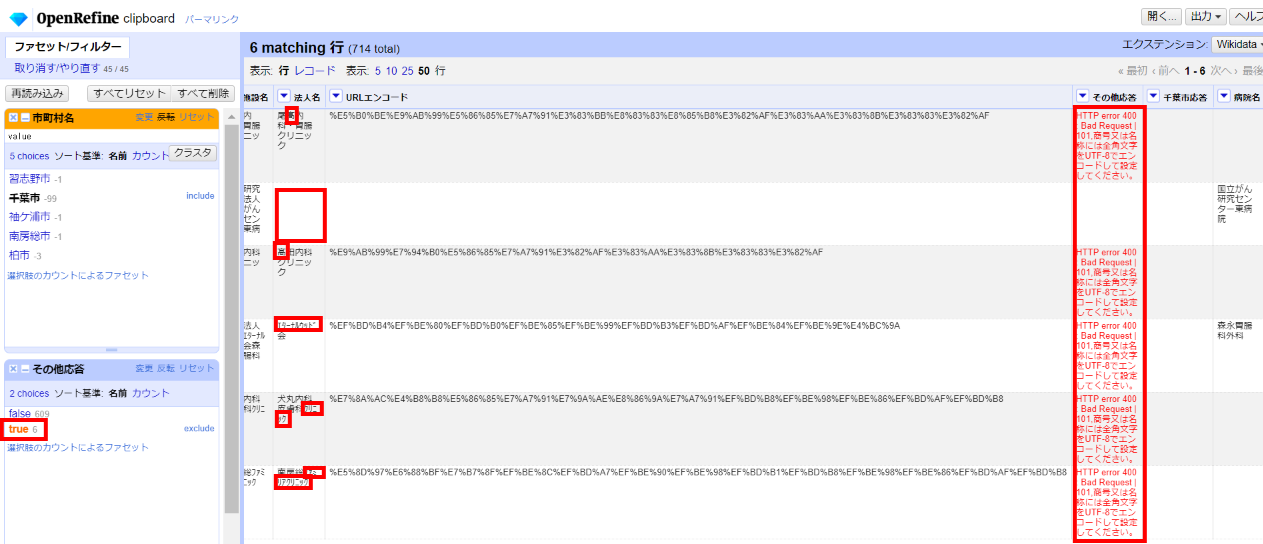
6件あります。「その他応答」カラムにエラー内容を返してくれています。こういうのはありがたいですね。
・1件目と3件目はおそらく「髙」がいわゆる「はしごだか」になっている問題だと思われます。「高」に書き換えます。
・2件目は空白が残っていました。法人名を転記します。
・4件目以下は半角カナがあるので全角に書き換えます。
(手順は省略しますが、エラー分だけやり直して結果をマージします)
左サイドにその他応答ファセットをXで閉じて、千葉市以外が選択された状態に戻します。
3.3.4 応答のマージ
「その他応答」カラムの値を「千葉市応答」カラムにコピーします。
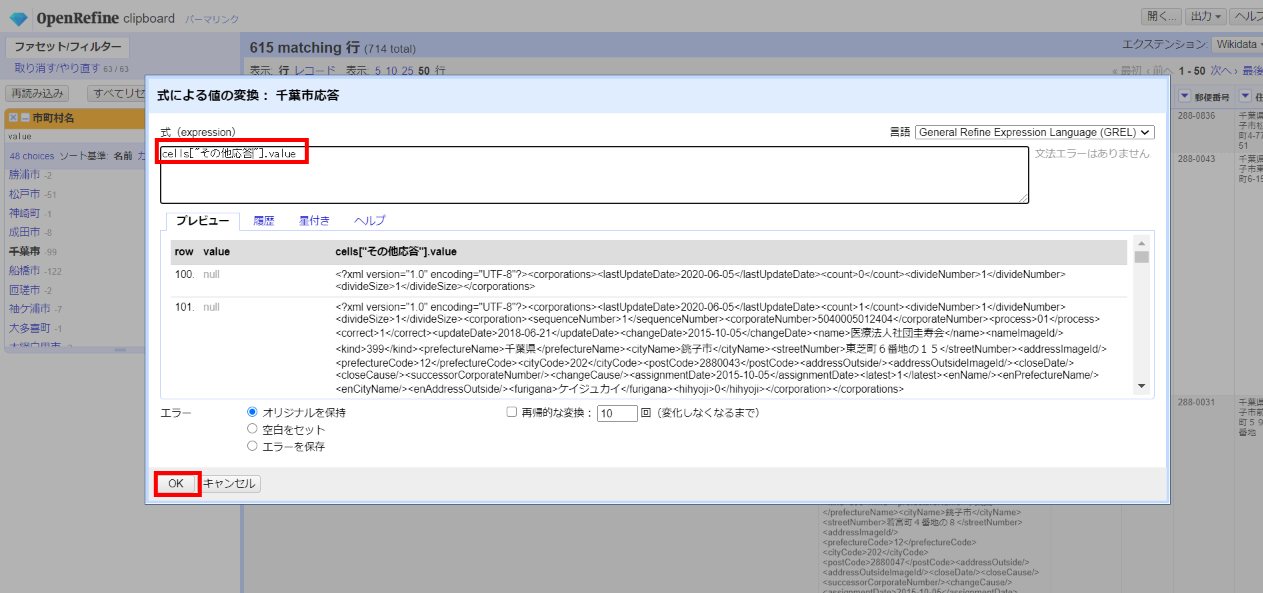
「▼千葉市応答」の▼をクリックして セル編集>変換 と選び、以下を記述して「OK」。
式:
cells["その他応答"].value
「▼その他応答」の▼をクリックして カラム編集>このカラムを取り除く と選び、以下を記述して「OK」。
「▼千葉市応答」の▼をクリックして カラム編集>カラム名を変更 と選び、カラム名を「応答」に変更。
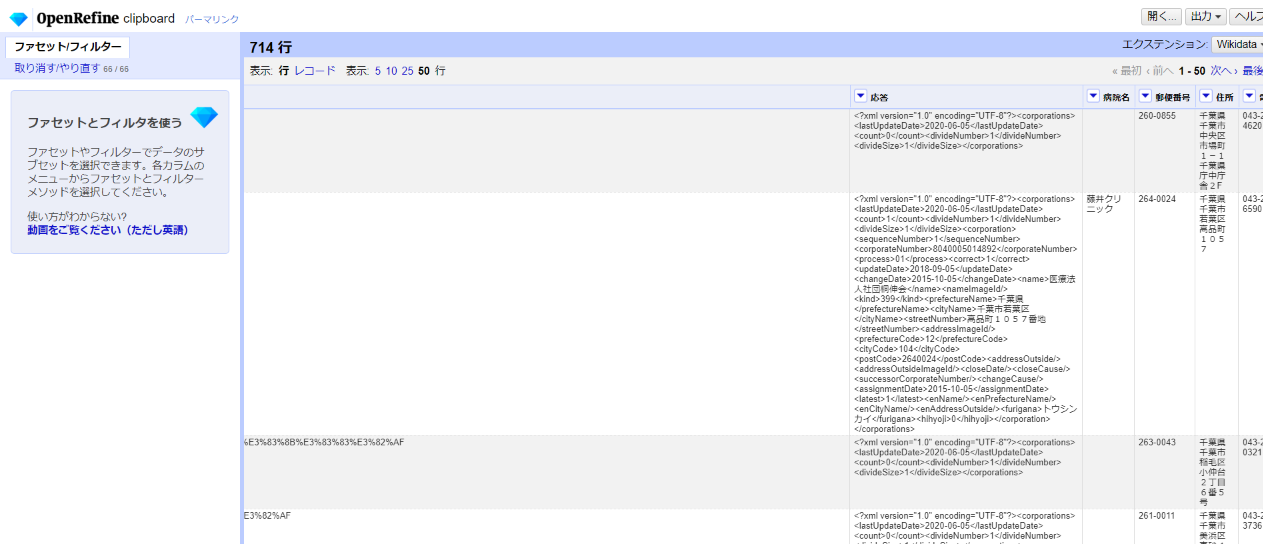
これで千葉市とそれ以外でパラメータを一部変えて呼び出した結果を全て「応答」カラムに集約できました。
左サイドのファセット/フィルターを全て閉じて全件表示します。
3.3.5 件数抽出
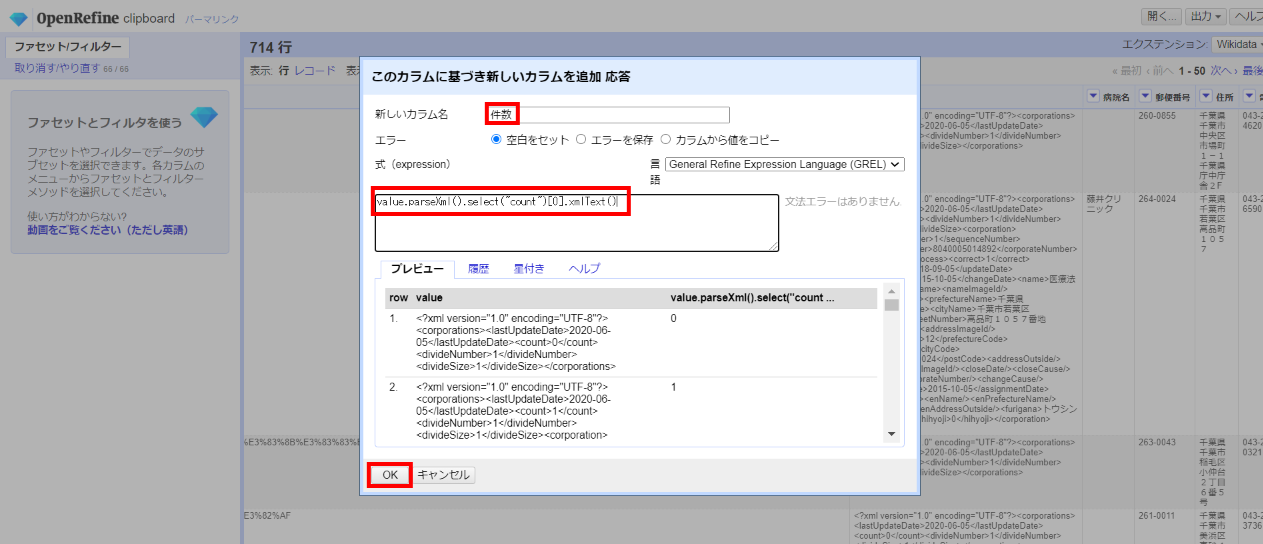
応答の中から<count>(ヒットした件数)の値を抽出します。
「▼応答」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選び、以下を設定して「OK」。
新しいカラム名:件数
式:
value.parseXml().select("count")[0].xmlText()
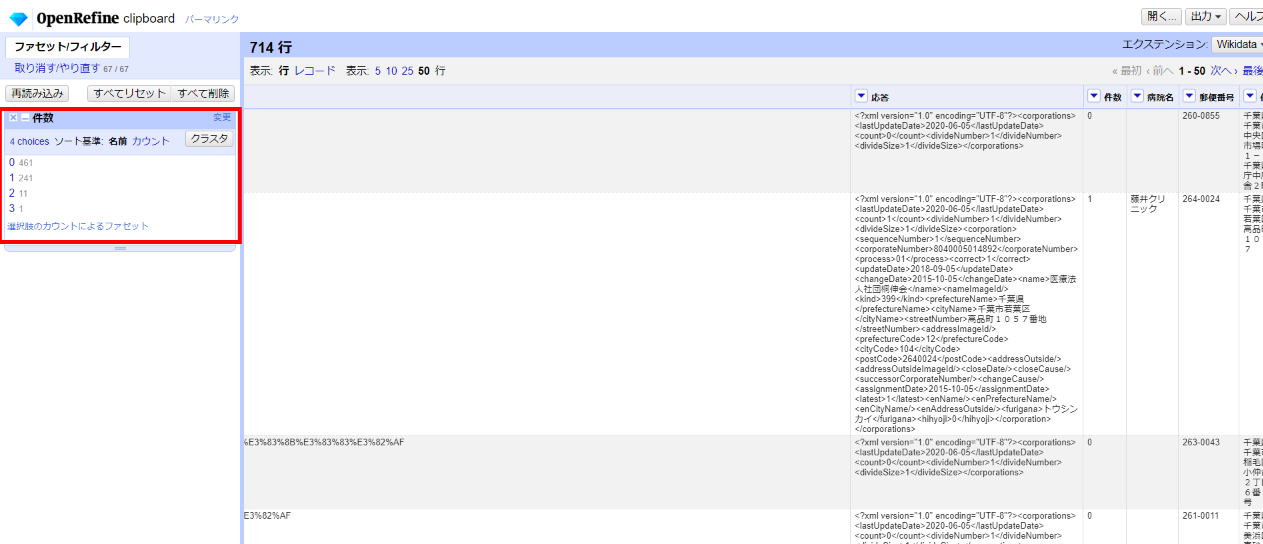
「▼件数」の▼をクリックして ファセット>テキストファセット と選びます。
3.3.6 応答の分析
件数ごとに中身を見て対応方針を考えます。
1件以上が法人登記上の名称と一致した(名寄せできた)ものということになります。
253/714で約35%が一致。頑張った割には一致率が結構低いです。残念。
3.3.6.1 応答0件
左サイドの件数ファセットで「0」を選びます。
「▼法人名」の▼をクリックして ファセット>テキストファセット と選びます。
左サイドのファセットウィンドウで値0を選んで法人名をブラウズしてみると、ほとんどが「◯◯会」のような法人名らしいものではなく、病院名らしいものです。小規模の個人経営などの病院は法人登記上の名前は病院名とは別に持っていて、かつあまり表には出していないことが多いということなんでしょうか。あるいは個人事業主なのでしょうか。いずれにしてもこれ以上の追跡はエンドレスな作業になりそうなのでやめておきます。
3.3.6.2 応答1件
件数「1」を選びます。
病院名らしい値もありますが、多くは◯◯会です。こちらについては応答内の法人名や住所でを元にクレンジングしたり、法人番号という一意の識別子を得たりすることができます。
「URLエンコード」カラムはもう使わないので カラム編集>このカラムを取り除く と選んで削除します。

詳細については後でチェックします。
3.3.6.3 応答2件
件数「2」を選びます。
「応答」カラムの値をざっと見ていくと、「法人名:病院名」が「1:n」の場合がほとんどですが、法人種別は異なるが法人名が同一という別法人が一致しているケースもあります。これは元データの住所などを手がかりに、後でひとつずつ見ていくしかありません。
3.3.6.4 応答3件
件数「3」を選びます。
該当行は1件だけです。「応答」カラムの値を見ると3つある住所がいずれも元データと違っており、一致しません。
以下の編集方針としては、「件数」カラムを0か1で国税庁APIで名寄せできたかどうかの判断フラグの意味付けとし、一致を確認しながら0または1に書き換えていくことにします。
応答3件のものはいずれも一致していないので「件数」カラムを0にします。
3.4 応答からの値取り出し
「応答」カラムから値を取り出して、処理しやすくします。
3.4.1 操作対象を一覧表示
左サイドで法人名ファセットをXで閉じて、件数ファセットで「0」を選び、さらに「反転」して0件以外のものを一覧表示します。
3.4.2 応答から値をパース
「▼応答」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選びます。
以下のように記述して「OK」で、1件目の法人情報を抽出して別カラムに出力します。
新しいカラム名:応答法人1
式:
value.parseXml().select("corporateNumber")[0].xmlText()+":"+ value.parseXml().select("name")[0].xmlText()+":"+ value.parseXml().select("prefectureName")[0].xmlText()+ value.parseXml().select("cityName")[0].xmlText()+ value.parseXml().select("streetNumber")[0].xmlText()+":"+ value.parseXml().select("prefectureCode")[0].xmlText()+ value.parseXml().select("cityCode")[0].xmlText()+":"+ value.parseXml().select("postCode")[0].xmlText()+":"+ value.parseXml().select("furigana")[0].xmlText()
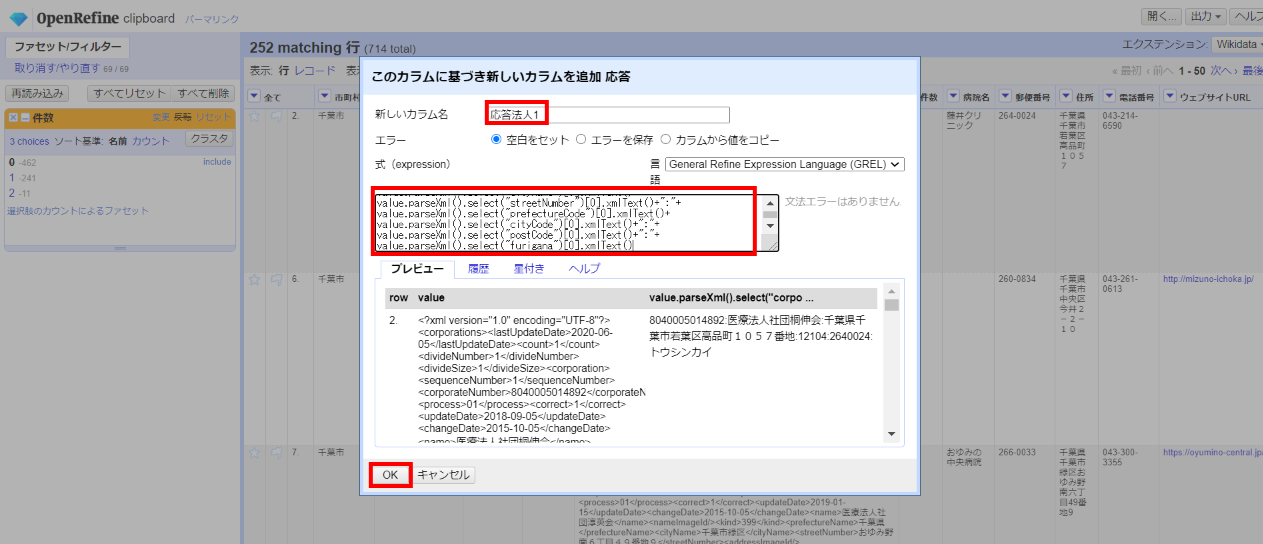
3.4.3 1件目の法人情報値をカラム分割
「応答」カラムはしばらく使わないので ビュー>カラムをたたむ で非表示にして見やすくします。
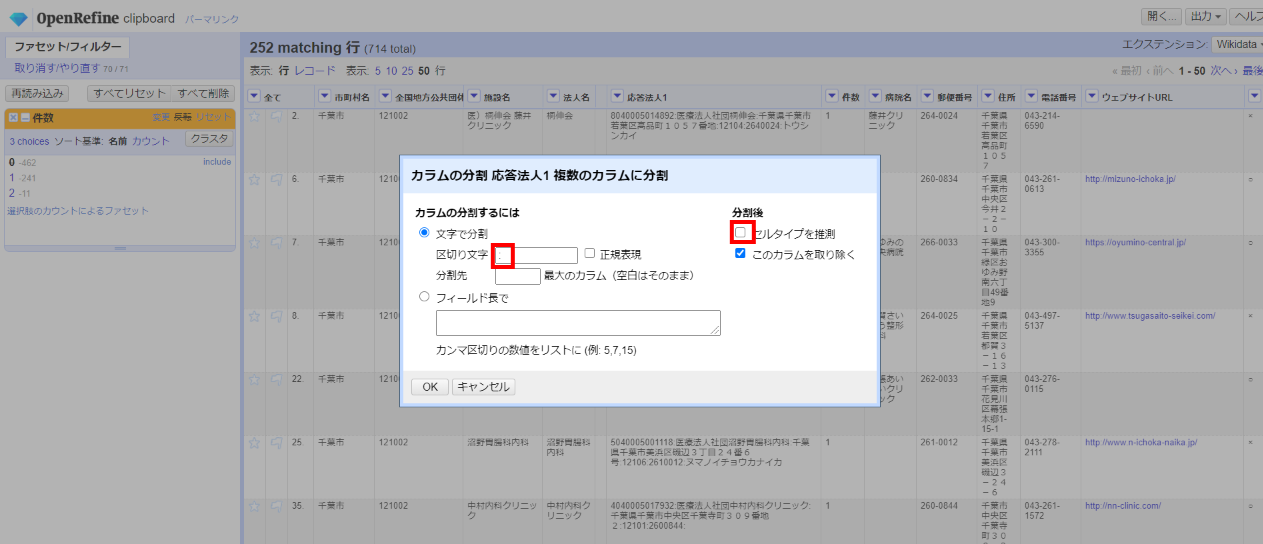
「▼応答法人1」の▼をクリックして カラム編集>複数のカラムに分割 と選び、区切り文字に「:」を指定して「□セルタイプを推測」のチェックを外して「OK」。
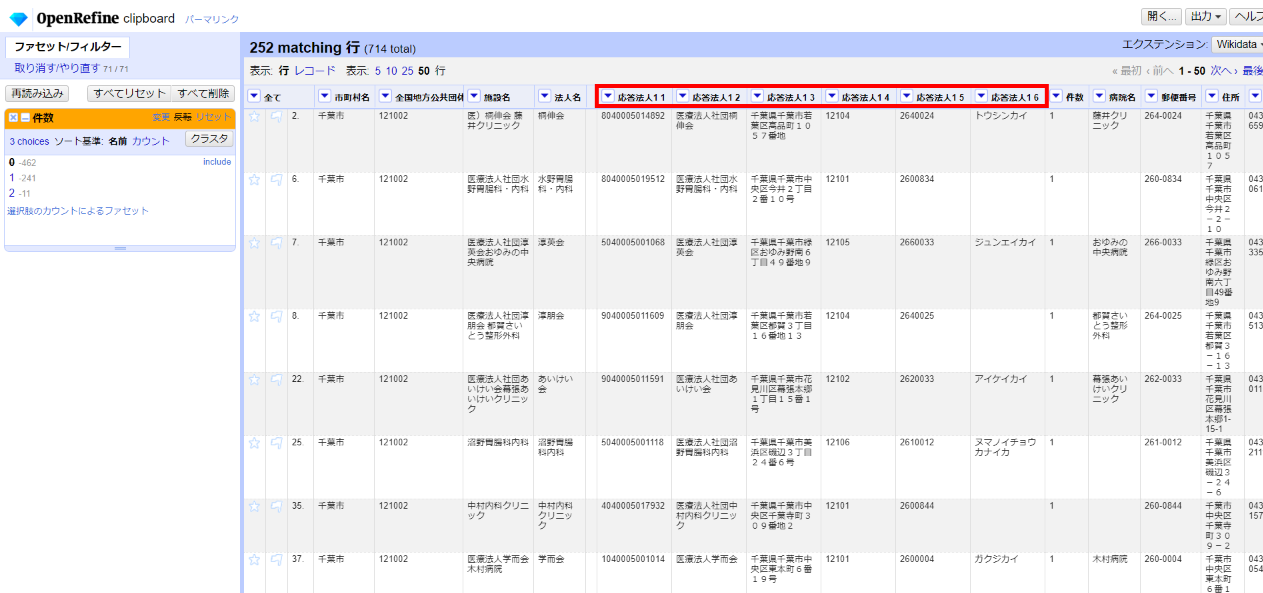
「応答法人番号11」-「応答法人番号16」の各カラム名を適切な名前に変えて分かりやすくします。
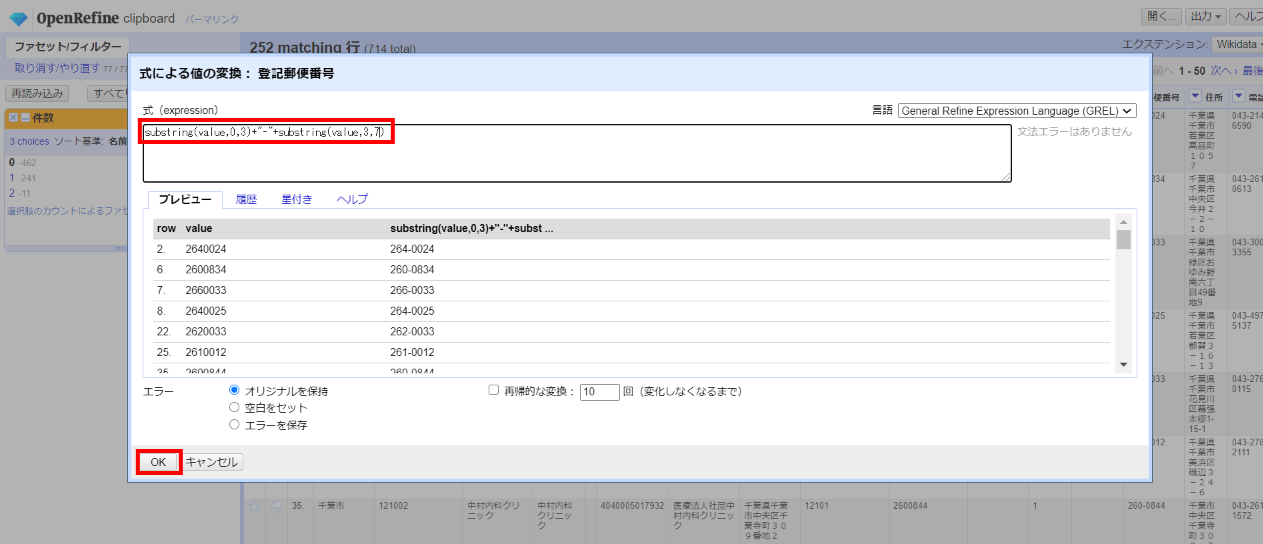
さらに新しい郵便番号カラムで セル編集>変換 から下記を式に設定して「OK」として、3桁目の後に"-"を入れて元データと形式を合わせます。
substring(value,0,3)+"-"+substring(value,3,7)
3.5 元データと取得情報との差分取得
3.5.1 カラムの並び替え
見やすくするため各カラムから カラムの編集>カラムを左に移動 などでに比較対象どうしを隣に並べます。
3.5.2 郵便番号
差分を取って比較します。
「▼登記郵便番号」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選んで、左サイドに現れた登記郵便番号ファセットで「false」を選びます。
「▼登記郵便番号」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選んで、下記を入力して「OK」。
カラム名:郵便番号diff
式:
diff(cells["郵便番号"].value,value)

「▼郵便番号diff」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選んで、左サイドに現れた郵便番号diffファセットで「false」を選びます。
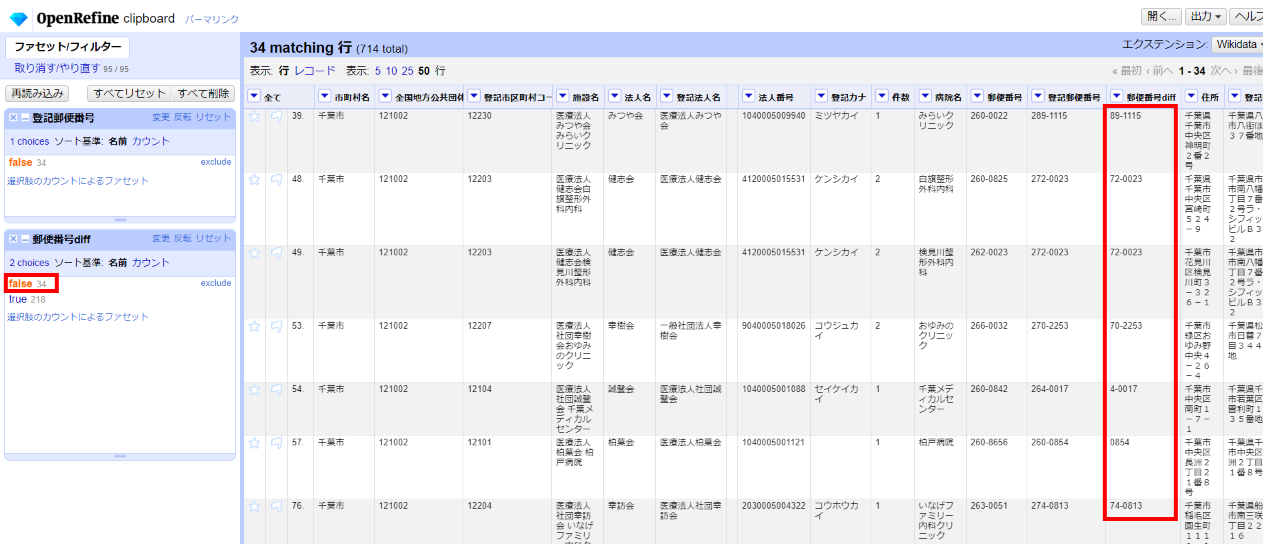
不一致が34件。これは法人が一致していないか、郵便番号が間違っているか(おそらく元データ側)のいずれかです。
3.5.3 法人名
左サイドのファセット/フィルターを全てXで解除します。
「▼登記法人名」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選んで、左サイドに現れた登記法人名ファセットで「false」を選びます。
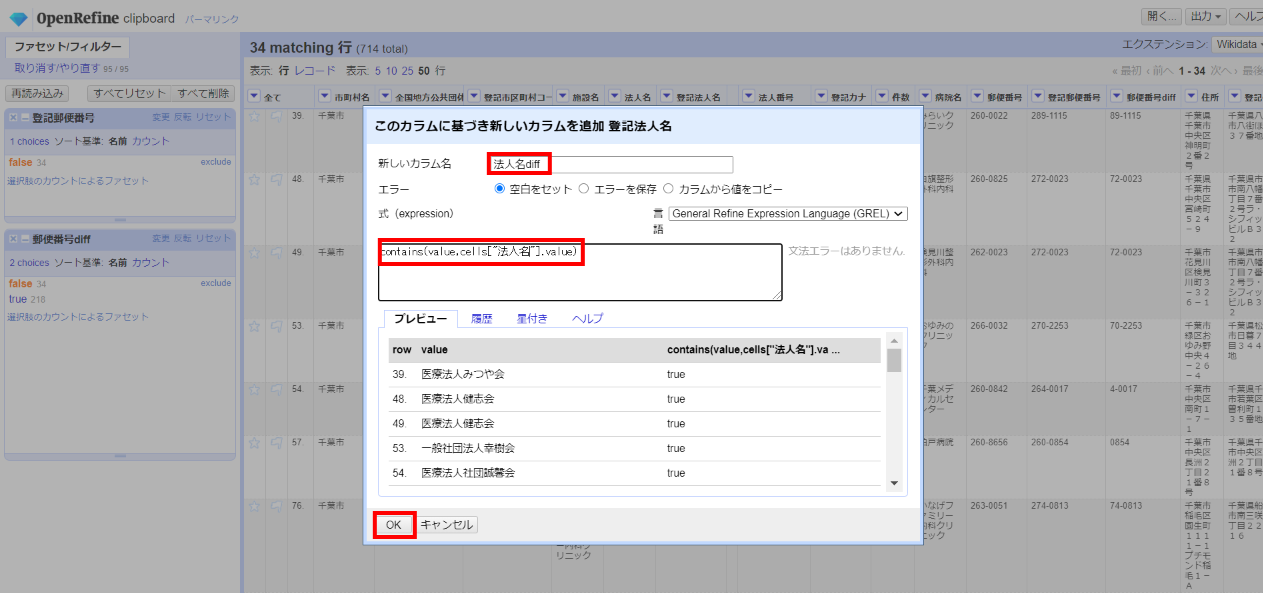
「▼登記法人名」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選んで、下記を入力して「OK」。
カラム名:法人名diff
式:
contains(value,cells["法人名"].value)
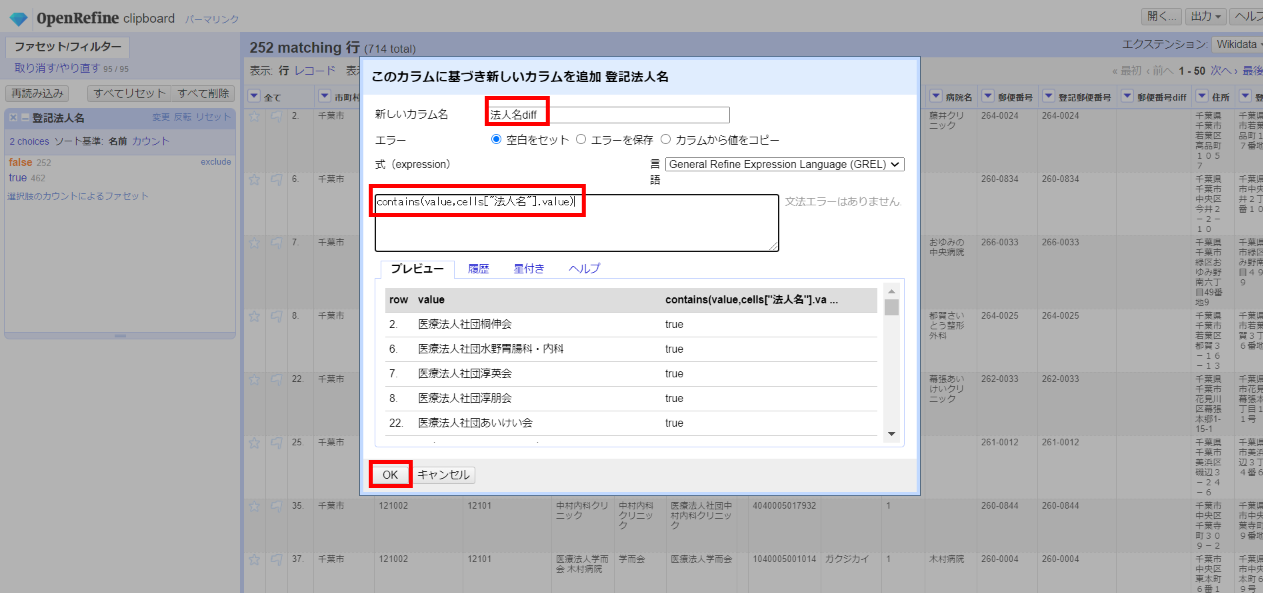
「登記法人名」が「法人名」を含む場合は「true」が出力されます。
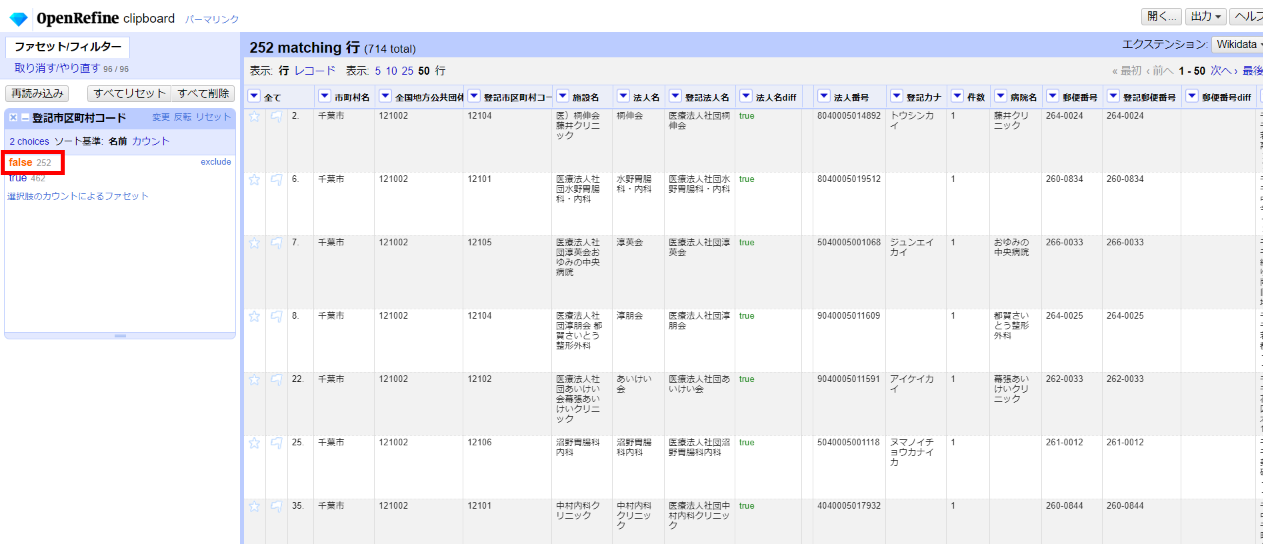
3.5.4 市区町村コード
左サイドのファセット/フィルターを全てXで解除します。
「▼登記市区町村コード」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選んで、左サイドに現れた市区町村コードファセットで「false」を選びます。
「▼登記市区町村コード」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選んで、下記を入力して「OK」。
カラム名:市区町村diff
式:
diff(substring(cells["全国地方公共団体コード"].value,0,5),value)
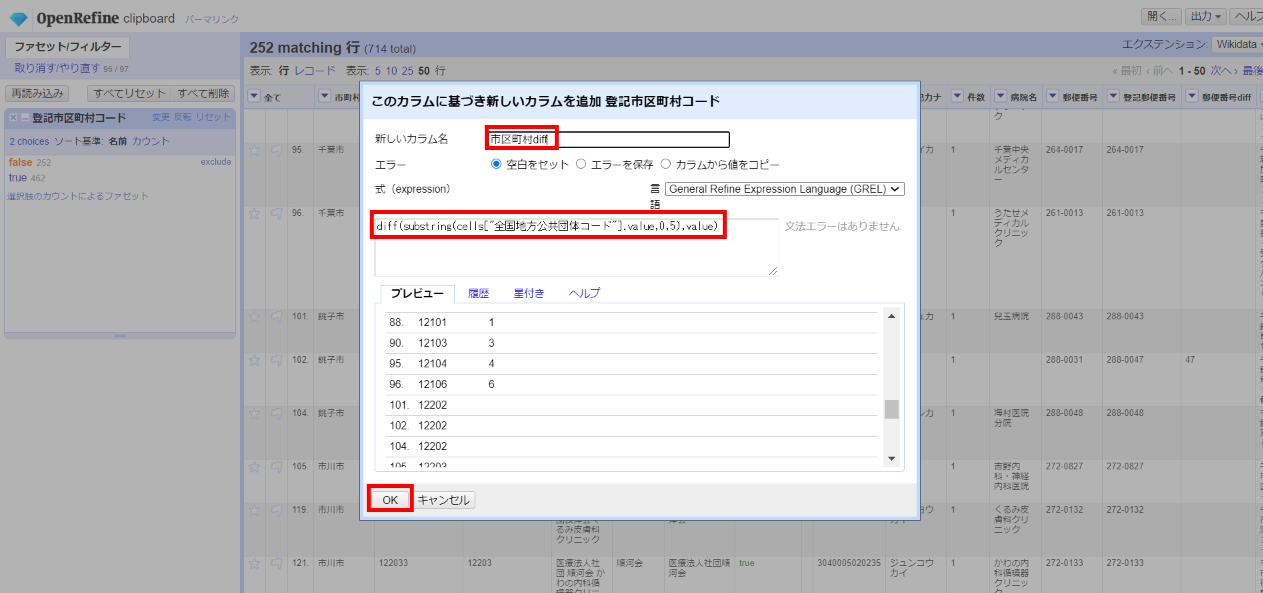
「▼市区町村diff」の▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空白) と選んで、左サイドに現れた市区町村diffファセットで「false」を選びます。
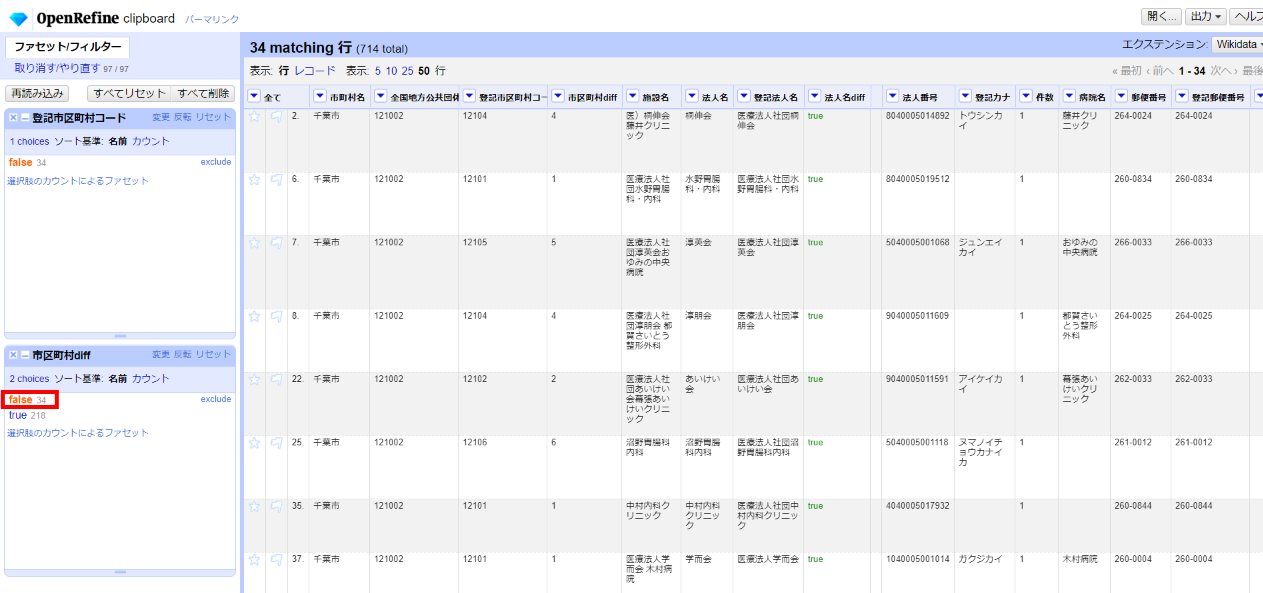
不一致が34件。しかしこれは全て千葉市です。APIからは千葉市のコードの下位にあたる区のコードが返ってきているために不一致となっており、個々に見ていかないと実際に不一致かどうかは分かりません。
3.6 元データと取得情報との一致確認
法人が1件返ってきたものは一致している可能性が高いと思われますが、差分情報を見比べながら、不一致のものを探していきます。
3.6.1 1件だけ返ってきたものを表示
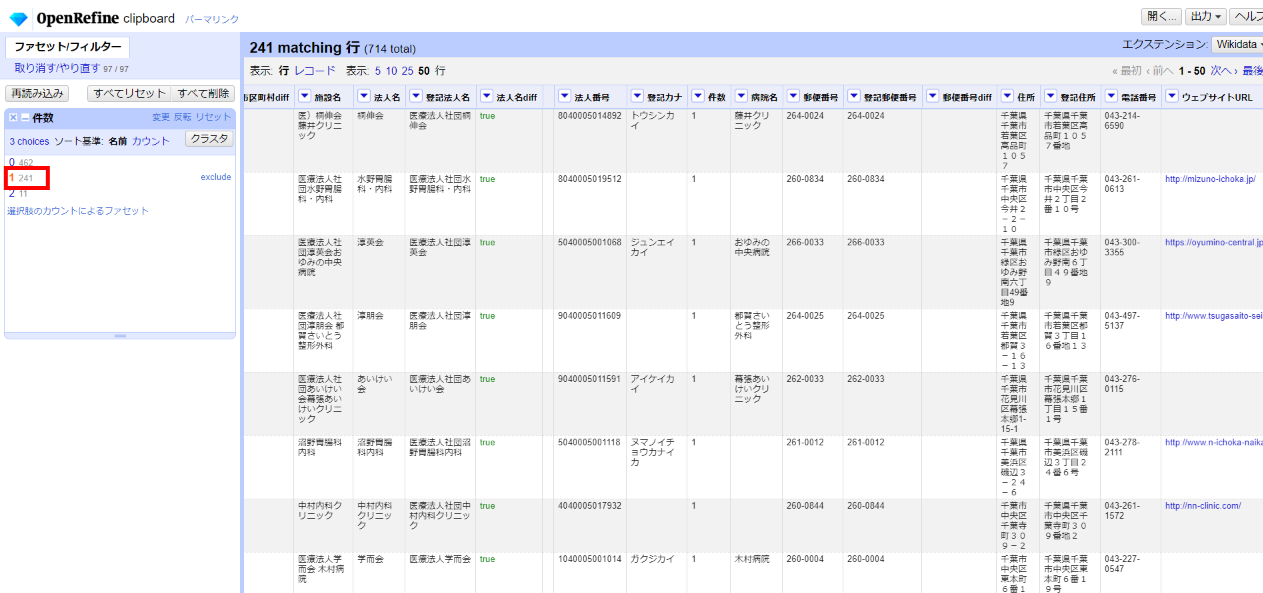
「▼件数」の▼をクリックして ファセット>テキストファセット と選んで、左サイドに現れた件数ファセットで「1」を選びます。
3.6.2 法人名の確認
上で登記法人名に元の法人名が含まれるものに「true」を立てたのでこれを選んでみます。
「▼法人名diff」の▼をクリックして ファセット>テキストファセット と選びます。
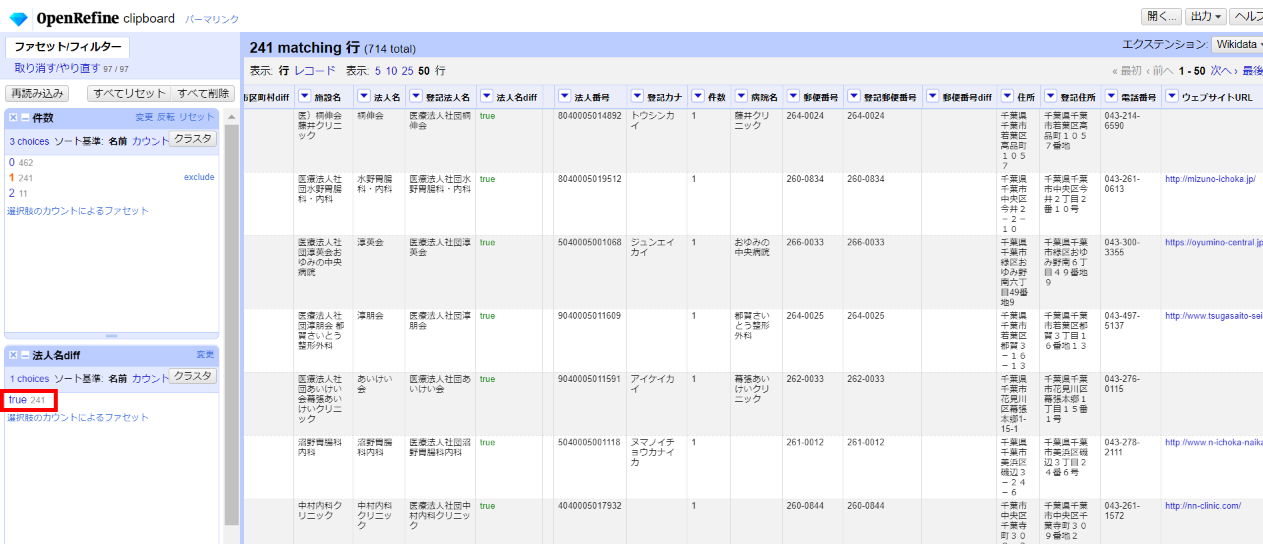
全て「true」で含まれています。考えてみたらこの法人名を元にAPIを呼び出したので当然ですね。
左サイドの法人名diffファセットをXで閉じます。
3.6.3 市区町村コードの確認
「▼市区町村diff」の▼をクリックして ファセット>テキストファセット と選び、左サイドの市区町村diffファセットで「(blank)」を選んで「反転」し、空白以外を選びます。
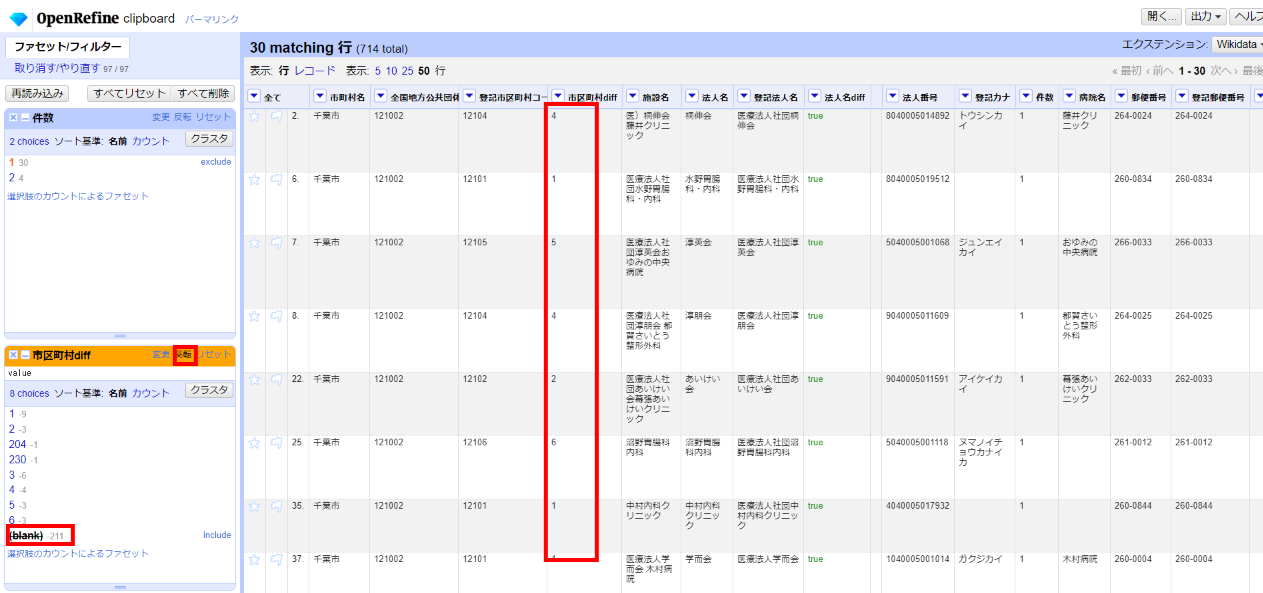
千葉市と区のコードの違いなのか、住所が違っているのか分かりませんが、住所違いであれば郵便番号が違うはずなのでそちらのdiffを条件追加してみます。
「▼郵便番号diff」の▼をクリックして ファセット>テキストファセット と選び、左サイドの郵便番号iffファセットで(blank)を選んで「反転」し、空白以外を選びます。
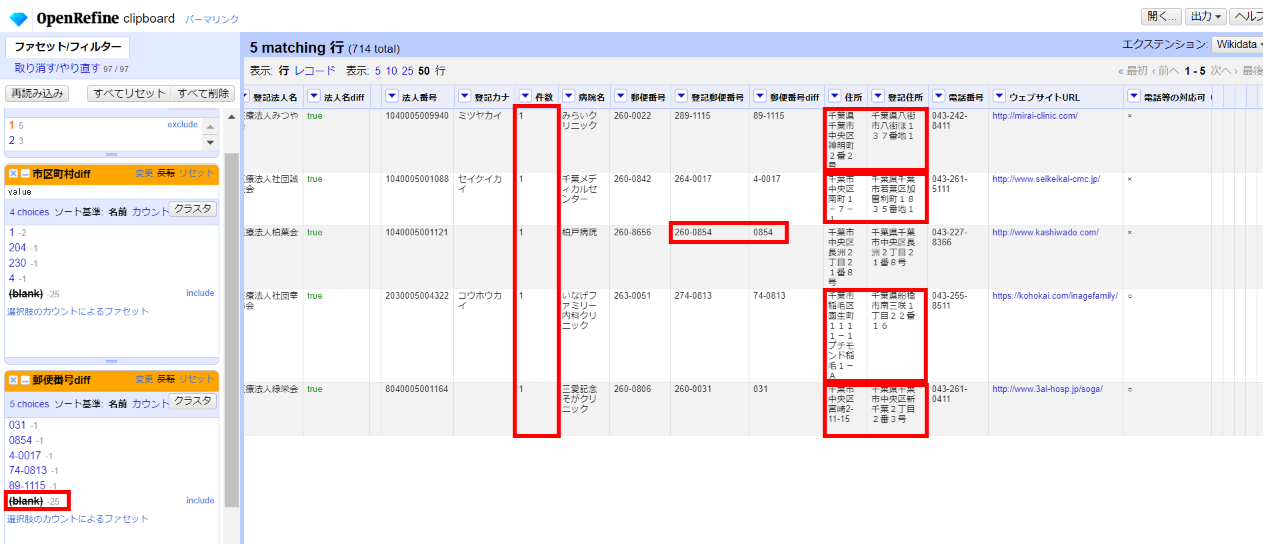
3件目以外は住所が異なるので違う法人と判断できます。これら5件については「件数」カラムを「0」にして不一致に分類します。
3件目は住所は同じですが、郵便番号が異なります。元データの郵便番号はウェブサイトと同じですが、郵便番号検索してみると登記と合っています。これは後者が正しいとみるべきでしょう。結論として、3件目は郵便番号を修正しますが、一致した(名寄せできた)という扱いにします。件数は「1」のままとします。
左サイドの郵便番号diffファセットで「反転」をクリックして元に戻し、空白を選びます。
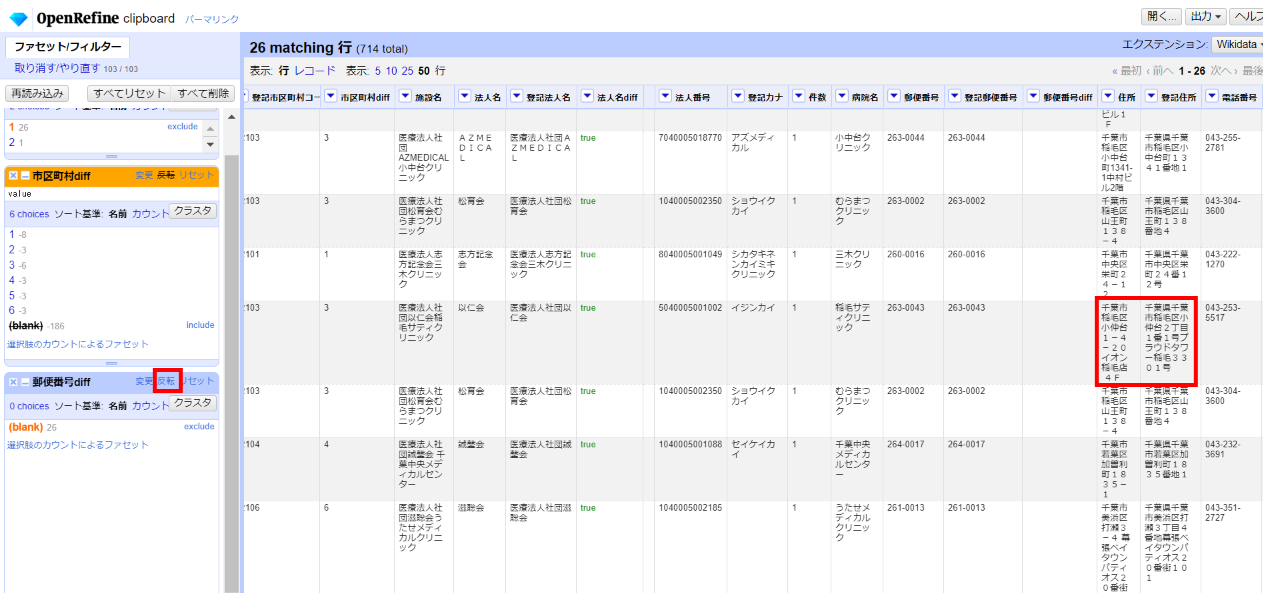
住所不一致が見つかりました。法人名は合っているようですが、住所が少しだけ違います。法人のオフィスと病院が別なんですかね。件数を「0」にして不一致に分類します。
それ以外は一致していました。
左サイドの市区町村diffファセットをXで閉じます。
郵便番号diffファセットで改めて(blank)を選んで「反転」します。
この211件は郵便番号が違っているがまだ一致に分類されています。住所は表記の揺れが大きく機械的な比較はプロ(沼とも言うようですw)の領域なので、ここでは人力でひとつずつ確認し、住所が異なるものは件数を「0」にして行きます。
大字や町名が異なるものは違うものと判断できますが、数字が少しだけ違うものは0と9など数字の打ち間違いがあるのでウェブサイトで確認します。住所が同じものは郵便番号の間違いです。登記情報を正と考えて、後で一括して置き換えます。
(中略)
手修正が終わりました。
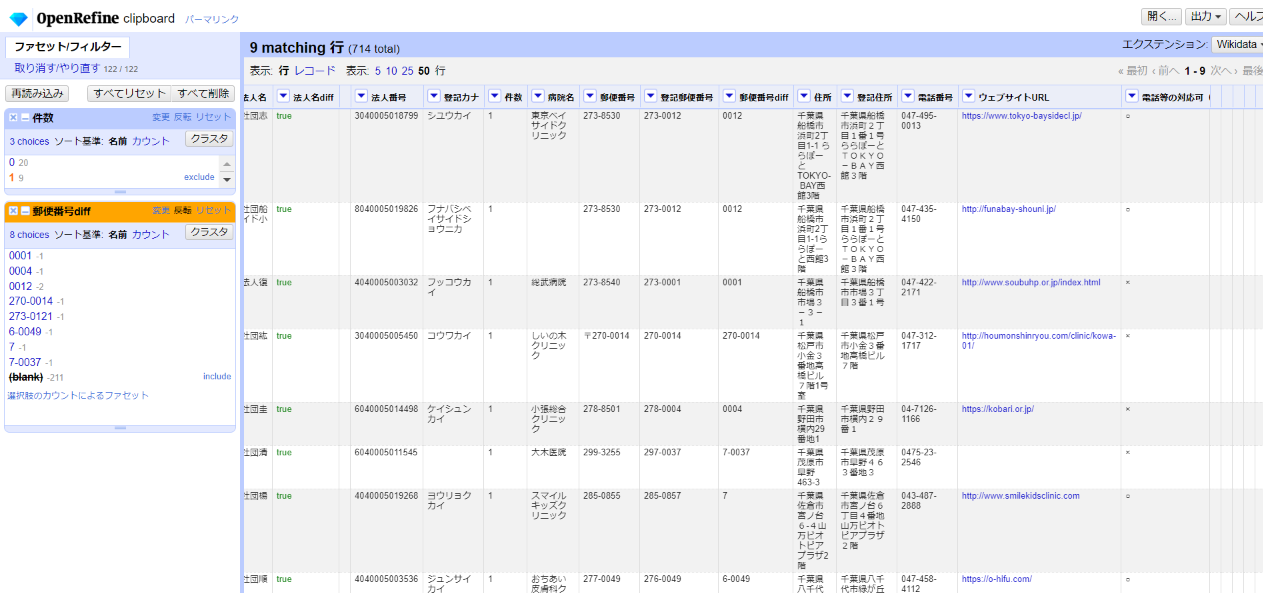
9件が法人名、住所は一致しているが、郵便番号は不一致として残りました。一括して登記郵便番号を上書きします。
「▼郵便番号」の▼をクリックして セル編集>変換 と選び、下記の式を入力して「OK」。
cells["登記郵便番号"].value

さらに郵便番号diffを空にします。
「▼郵便番号diff」の▼をクリックして セル編集>よく使う変換>セルを空白に と選んで「OK」。
郵便番号diffファセットをXで閉じます。
3.6.4 2件返ってきたものを表示
件数ファセットで「2」を選びます。
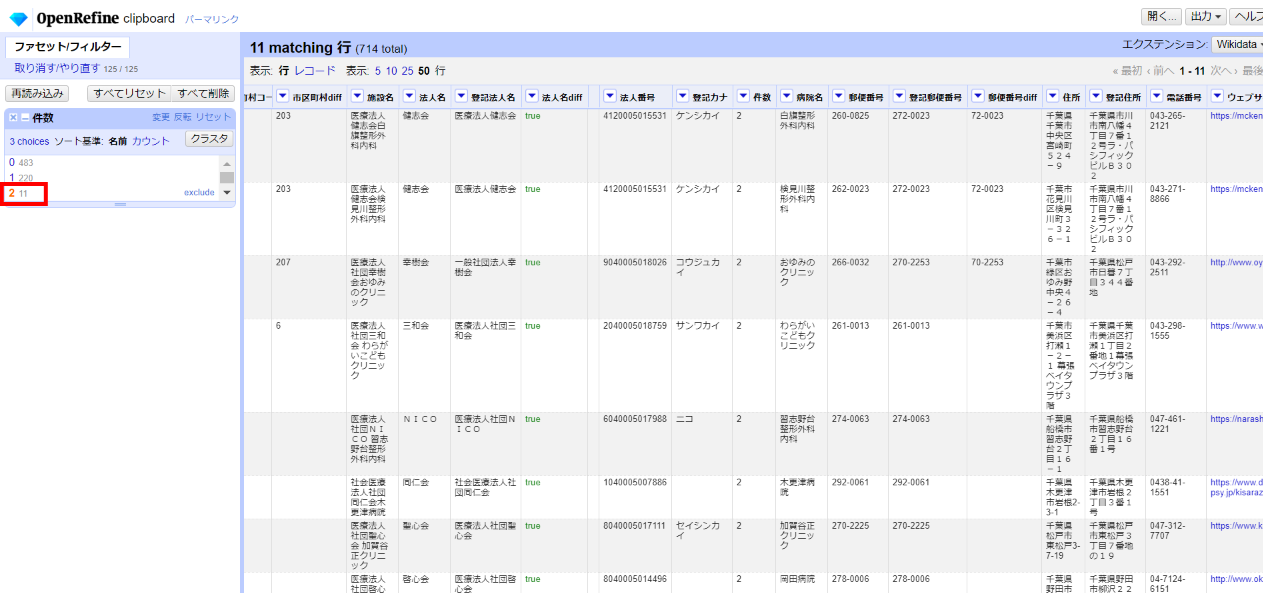
対象が11件と少ないので、まず目で確認します。
法人名は既に一致しているので、住所が合っていれば一致と判断し、件数を「1」に書き換えていきます。
表示をリフレッシュすると残り4件になりました。
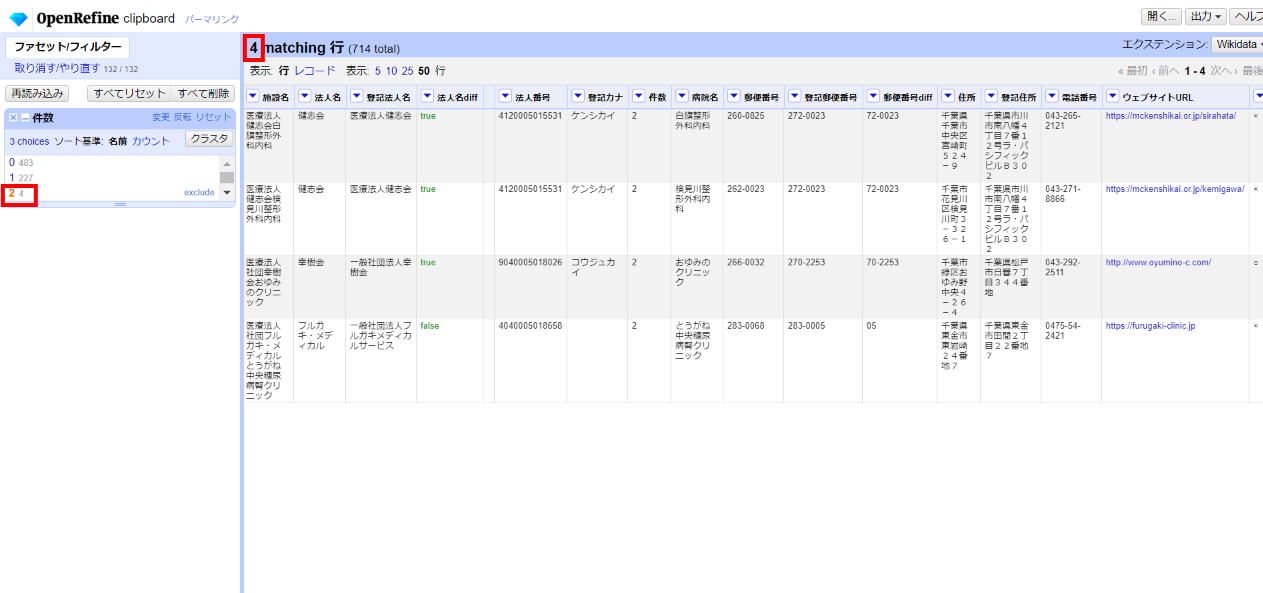
3.6.5 2件目を元に登記情報を更新
応答のうち、まだ法人1件目しかパースしていなかったので、2件目をパースします。
見出しが見えなくなっている「応答」カラムの見出し「 」をクリックして広げます。
「▼応答」の▼をクリックして カラム編集>このカラムに基づいてカラムを追加 と選びます。
以下のように記述して「OK」で、1件目の法人情報を抽出して別カラムに出力します。
新しいカラム名:応答法人2
式:
value.parseXml().select("corporateNumber")[1].xmlText()+":"+ value.parseXml().select("name")[1].xmlText()+":"+ value.parseXml().select("prefectureName")[1].xmlText()+ value.parseXml().select("cityName")[1].xmlText()+ value.parseXml().select("streetNumber")[1].xmlText()+":"+ value.parseXml().select("prefectureCode")[1].xmlText()+ value.parseXml().select("cityCode")[1].xmlText()+":"+ value.parseXml().select("postCode")[1].xmlText()+":"+ value.parseXml().select("furigana")[1].xmlText()

再度「応答」カラムを ビュー>カラムをたたむ で非表示にして住所を見比べます。
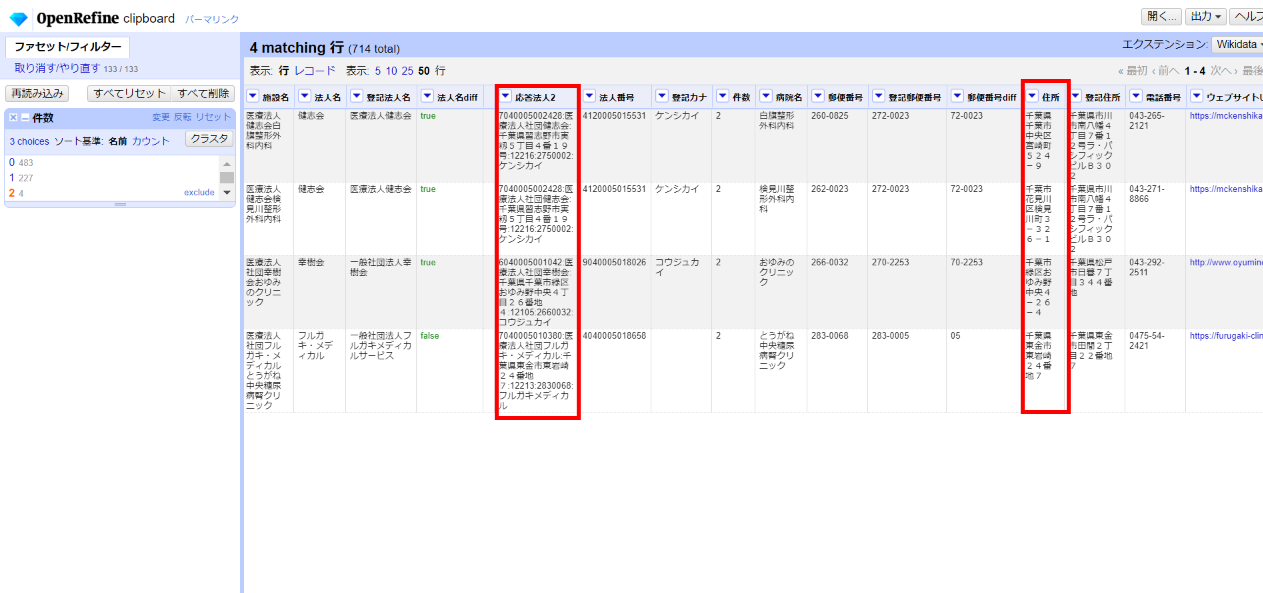
一致しないものは「件数」カラムを「0」にします。
一致したものは「件数」カラムを「1」にし、各登記情報カラムの値を上書きします。

これで229/714が国税庁のAPIで名寄せできました。約1/3と、まだまだです。病院名が特別なのかどうかは知りませんが、法人名にも沼があることがよく分かりました。本当にありがとうございましたw
また随分長くなってしまったので区切ります。読みづらいのであとで短くするかもしれません。
今回書ききれなかった住所とジオコーディングの話は次回に。沼には踏み込みません。