前回データエンスージアストの天敵として神エクセルを取り上げましたが、PDFはラスボスというところでしょうか。PDFがなんでもかんでも問題ということではありません。人間に読んでもらうためにPDF形式で公開するのは良いのですが、表形式のデータに関してはできれば元の表もCSVなど特定のソフトウェアに依存しない形式でそのまま出して頂いた方が機械にも読めてみんなが幸せになれる、というのがオープンデータ的主張なわけです。
いずれにしてもデータがあると聞いてアクセスしてみるとPDFが貼り付けてある、という状況はその時点でかなりの徒労感が漂います。そんな時でも気を取り直して前に進むためのツールの紹介、というのが本記事の趣旨です。
OpenRefineには現時点でPDFを直接読み込む機能はありませんので、他のツールを借りて中間的な形式に変換してから使います。そのツールとして今回ご紹介するのはWordです。はい、Microsoft社のWordです。私が試してみた範囲ではいちばん手軽に高確率でPDFの表をコピペしやすい形式に変換してくれます。(さすがに画像PDFはダメです)
1 元データ
今回は先日厚労省がCOVID-19対応の一貫で公開したオンライン診療に対応している医療機関一覧を取り上げさせて頂きます。
公開当初PDF形式であることを惜しむ声が聞かれましたが、即座にCSV形式で二次利用・公開してくれる方が現れたりしたヤツです。
中身を見ると「FAXで文字がつぶれている」といったコメントが付記されていたりと、FAXで全国から情報収集して手作業で入力し直ししたであろうことが推察されます。レガシーなシステムとがんじがらめなネットワークに縛られながらも何より国民へのいち早い情報提供のために職員さんが頑張っておられる姿が目に浮かび、そのご苦労を思うと頭が下がります。

都道府県ごとに分かれており、ここでは千葉県のPDFを選びました。
2 コピーしてgoogle spread sheetに貼り付け
2.1 Firefox
まずPDFをそのままブラウザで開いてみます。Firefoxで開いて

全選択してgoogle spread sheetに貼り付けると

見出しとそれ以外の2行としか区切り文字や改行が認識されていないようで文字がベタっと横長に貼り付けられました。
2.2 Chrome
同様にChromeで開いて全選択で貼り付けると
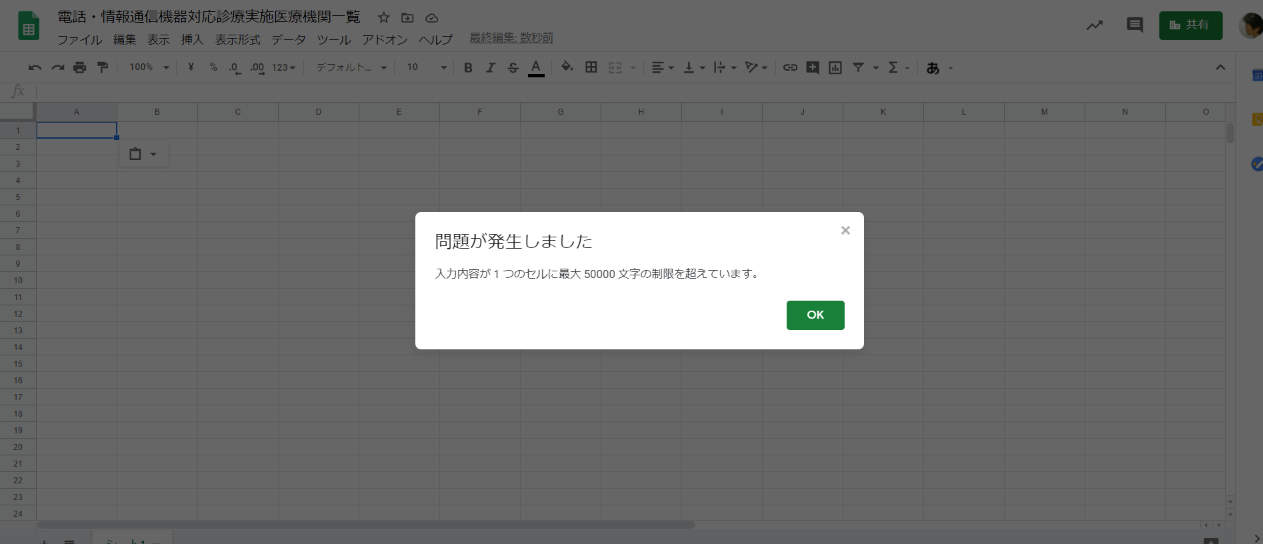
こちらは完全にベタな文字列として認識されているようでひとつのセルには入りきれないと怒られてしまいました。
2.3 Adobe Acrobat Reader
Adobe Acrobat Readerで開いて全選択で貼り付けると

ブラウザよりはましですが、セルごとの区切りが全て改行と認識されているようでここから50ページのデータを整形する気にはなれません。
2.4 Word
Wordで開いてみます。

きれいにWord文書として開かれ、PDFで表現されている形状がほぼ再現されています。これを全選択してコピペすると

しばらく時間が掛かりましたが見事に表がそのまま貼り付けられました。これならやる気も出ようというもの。
残念ながら見出しがコピーされていないので不要な見出し行を削除しつつ、ここだけはPDFを見ながら手打ちします。

50ページあるので全体的にざっとみたところなぜか3箇所ほど、文字がはみ出しているところがあったので
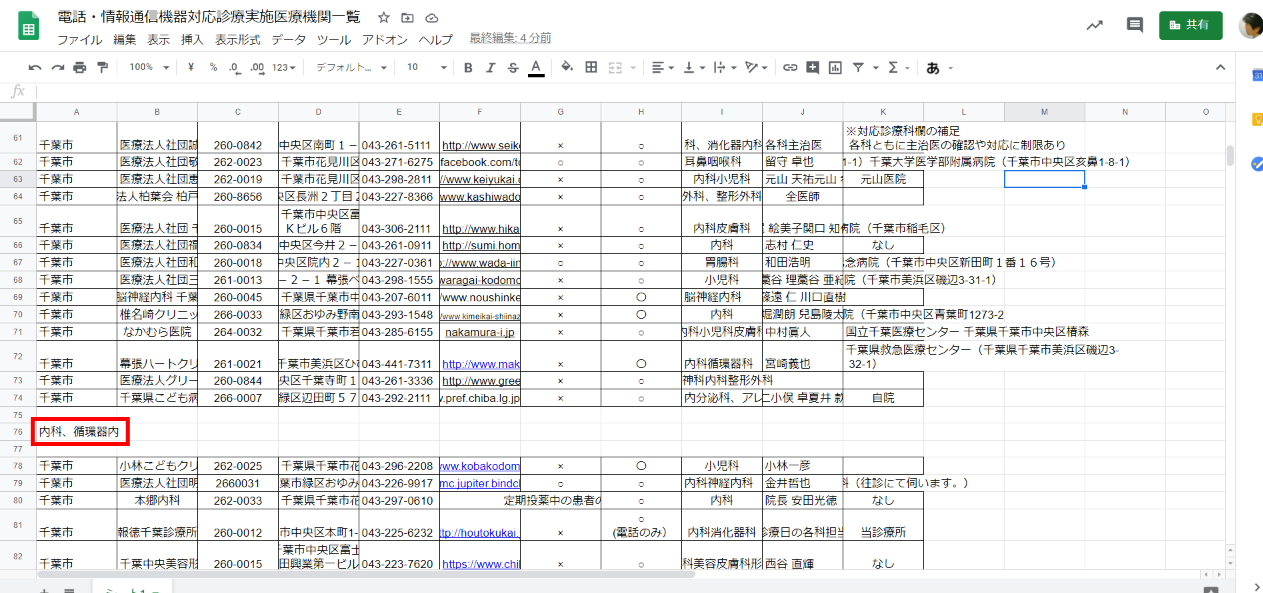
元PDFを見ながら前後の該当セルに戻したり、見当たらないものを削除したりしまた。
これで下準備は終わり。
3 OpenRefineに読み込む
準備したspead sheetの内容をコピーして
「クリップボード」を選んで貼り付けて「次へ」

データの解析形式として「CSV/TSV」を選びます。

空白行は不要なので「□空白行を保存」のチェックを外して

後から検索する時のために分かりやすいタグを適当に付けて「プロジェクトを作成」。
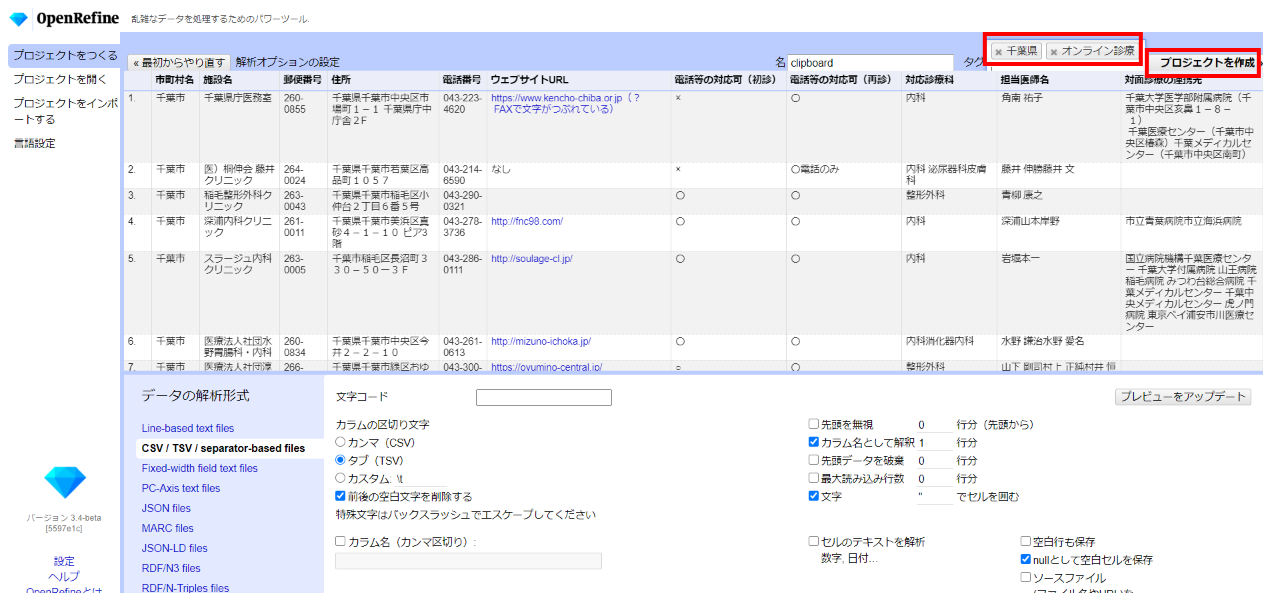
これでOpenRefineで操作するための準備ができました。

4 OpenRefineでクレンジング
前回は表形式に整える整形作業に手間がかかりましたが、今回は比較的形式が整っているのでその点は良さそうです。しかし、今回いちばんのポイントは生データに近い状態で公開されていることです。時間のない中でやられたベストエフォートの結果なのでそのこと自体をどうこう言うつもりはありませんが、まさにクレンジングのためのOpenRefineの機能を十分に活用することができます。言い換えればやることが多いということですw
人間が目で見て何かアクションする、という用途であれば元のPDFの状態そのままでも十分利用可能だと思います。しかしながら例えばこれを入力データとして、市町村名を指定して検索したり、URLをタップしてホームページを調べたり、電話番号をタップして電話を掛けられるようなアプリで使おうと思ったら一貫したデータフォーマットに整形されている必要があります。以下、易しそうなところから具体的に見ていきましょう。
4.1 前処理
現在の状態をよく見ると「レコード」モードになっています。これはデータの先頭カラム「市町村名」に空白が入っているためにOpenRefineにグループ化できると判断されたものと思われます。
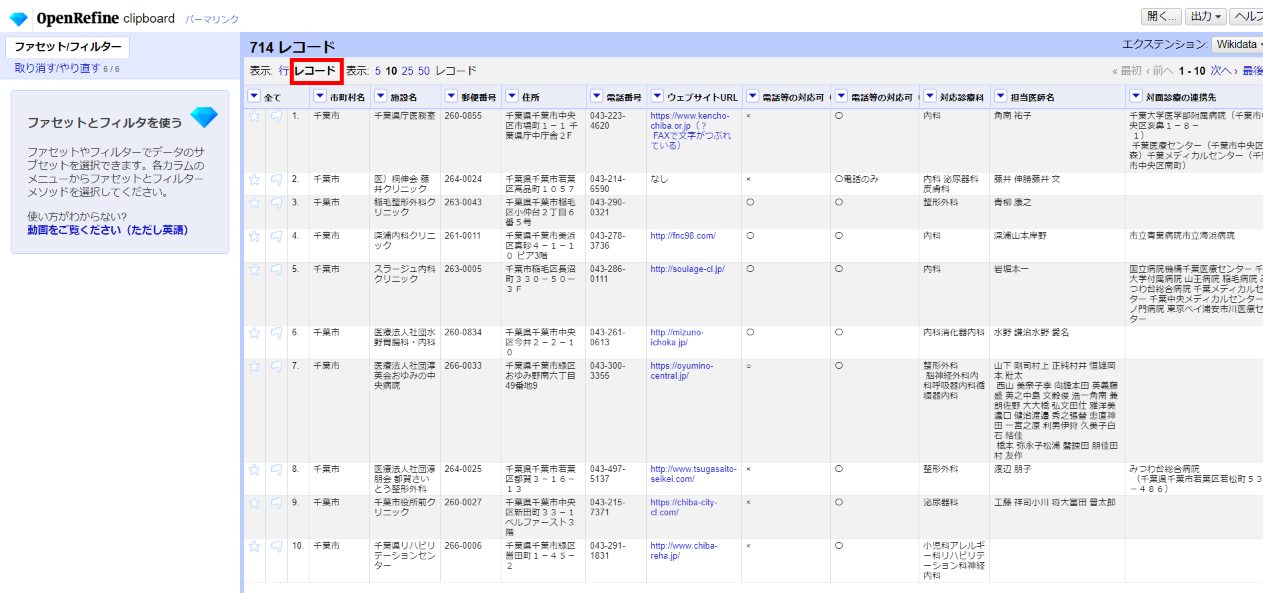
市町村名が空の病院はありえないので、まず「行」モードにしてから、「▼市町村名」 で▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空) を選びます。
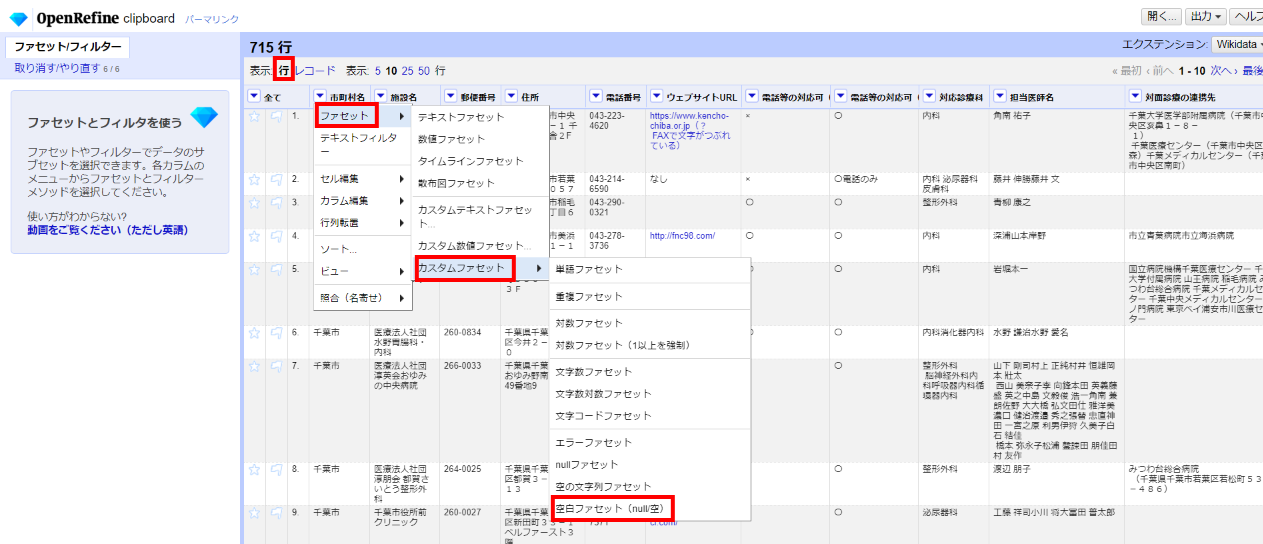
すると左サイドに市町村ファセットウィンドウが開くのでtrue、即ち市町村セルが空白の行を選びます。

1件ありました。「ウェブサイトURL」カラムに「#ERROR!」というメッセージが入っていますね。ゴミということで削除します。
制御カラム「▼全て」で▼をクリックして 行を編集>マッチした行を削除 と選んで現在表示されている行を削除します。

ゴミの入っていた行が削除されます。
Xで左サイドの市町村ファセットを閉じて初期状態に戻します。
4.2 各カラムのクレンジング
以下、取り組みやすそうなものから処理していきます。

4.2.1 郵便番号
パッと見ではきれいに並んでいて何も問題無いように見えますが、データフォーマットが揃っているか確認してみます。郵便番号のフォーマットは
"数字3桁"+"-"+"数字4桁"
が基本です。これを正規表現で記述すると
[0-9]{3}-[0-9]{4}
こんな感じでしょうか。厳密な表現はいろいろあるんだと思いますが、あまり詳しくないので^^;これで検査してみます。
4.2.1.1 正規表現でフィルター
「▼郵便番号」 で▼をクリックして テキストフィルター を選びます。

左サイドに郵便番号フィルターウィンドウが開くので上記正規表現を入力して「□正規表現」にチェックを付けます。

これで正規表現に一致した行(694/714)が表示されました。
4.2.1.2 条件を反転
これだけだと何が起きたのかよく分からないのでウィンドウ見出しの「反転」をクリックして、この条件を「NOT」に反転させます。
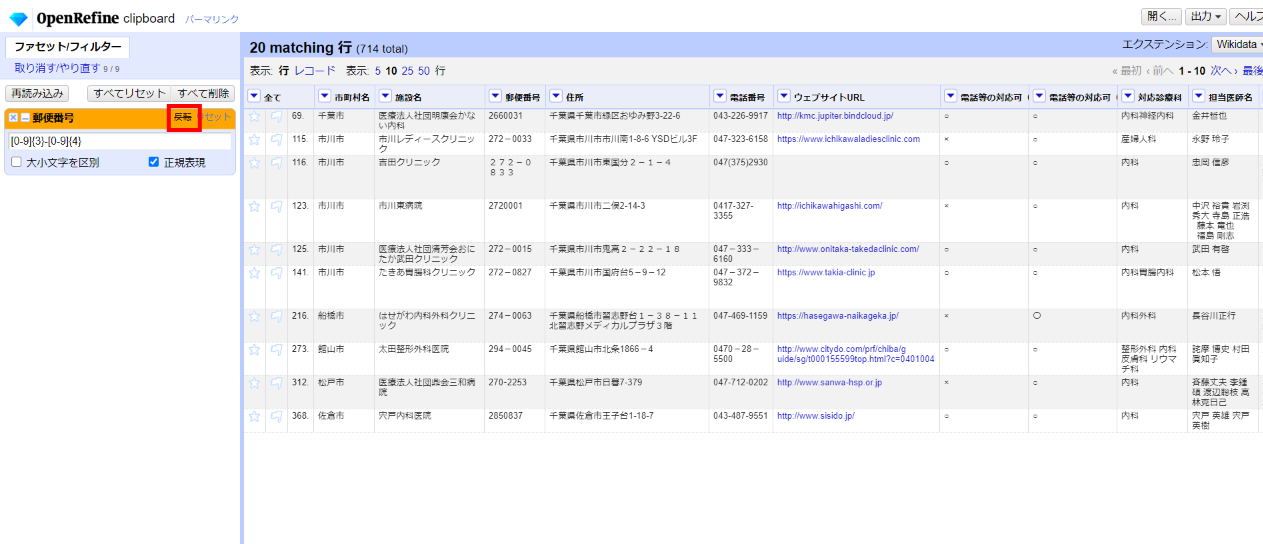
見出し行がオレンジに変わり、指定条件を満たさない行だけが表示されます。"-"が無かったり、全角だったり、まぁ、ありがちなエラーデータが現れました。件数は20件なので修正も簡単です。
4.2.1.3 値の手修正
エラーデータ全体を眺めると、"-"の有無をいっぺんに修正するのは面倒そうです。件数も少ないので"-"が無いものについては該当セルをクリックして

手で"-"を補完して「適用」。

以下同様の誤りを修正します。
4.2.1.4 条件を戻して一括変換
修正が終わったら郵便番号フィルターウィンドウの「反転」をオフ、オンして画面をリフレッシュすると未修正分だけが表示されます。

残りを見ると、数字やハイフンの全角を半角にすれば良さそうです。これなら一括して処理できます。
GRELのreplaceChars機能を使うとvalueにある値を対応する1文字ずつについて一括して変換できます。
ハイフンは全角だったりカナの長音だったり見分けがつきにくいものがいくつかあるのでまとめて半角ハイフンに変換します。
「▼郵便番号」 で▼をクリックして セル編集>変換 を選びます。
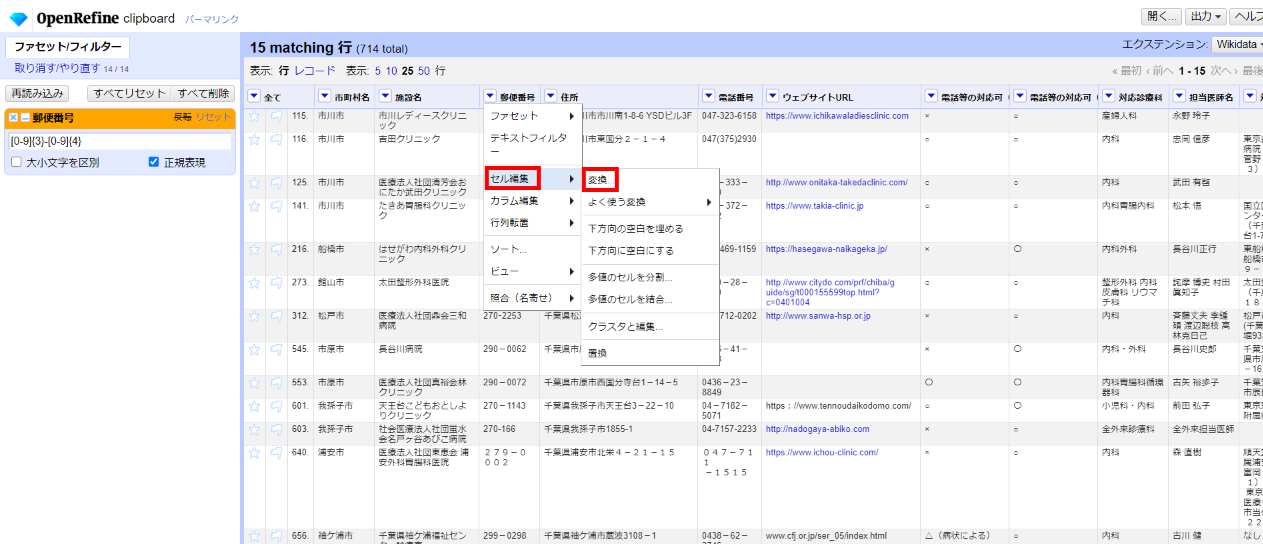
GRELの式に下記を入力して「OK」
replaceChars(value, "0123456789-‐-ーー", "0123456789-----")
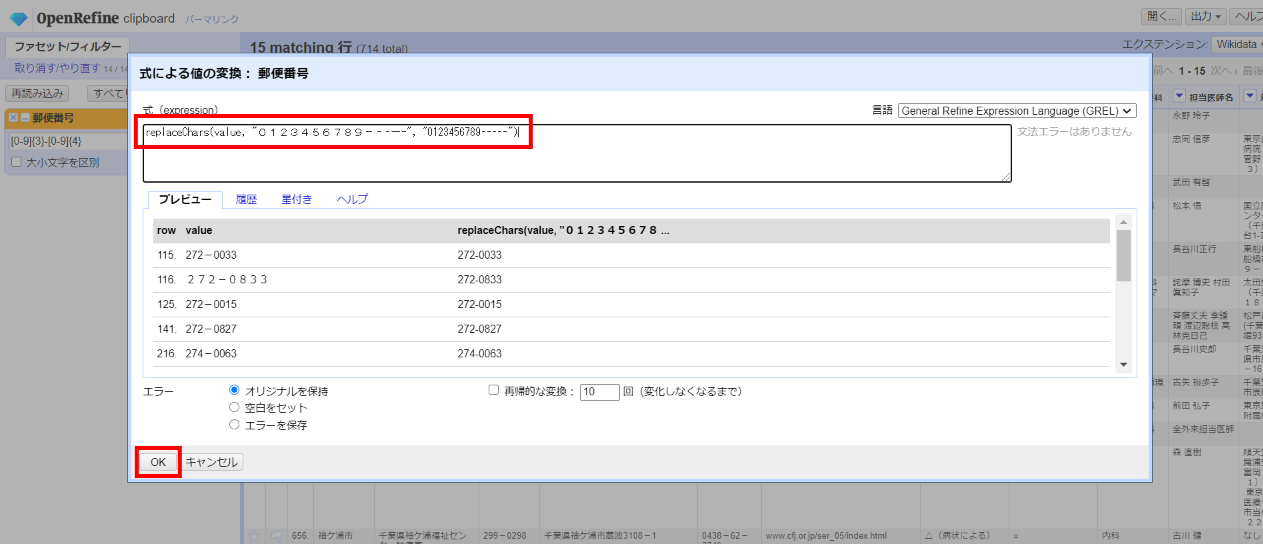
なお、各タブは以下のような使い方をします。
プレビュー:変換前後の値を実行前に確認できます。
履歴:過去に入力した式の履歴が残っており、このタブから再利用できます。
星付き:よく使う式は星を付けておいて、このタブから再利用できます。
ヘルプ:GRELの文法が記載されているので参照しながら式を編集できます。

4.2.1.5 残分の微修正
あと2件です。ハイフンの後の数字が一桁足りません。これは推測で補うことはできないのでウェブサイトなどで調べて手で修正します。
4.2.1.6 修正完了
左サイドの郵便番号フィルターウィンドウで「反転」をクリックして元の条件に戻すと714件、全て表示されました。即ち全て正規表現にパスしました。

左サイドの郵便番号フィルターウィンドウはいったん左上のXで消して素の状態に戻します。
4.2.2 電話番号
これは郵便番号と同じやり方でクレンジングできます。詳細は省きますが、下記の正規表現で検査して

0[0-9]{1,4}-[0-9]{1,4}-[0-9]{4}
下記のGREL式(上述のものより変換文字が少し増えています)で変換します。

replaceChars(value, "0123456789-‐-ーー\(\)()", "0123456789---------")

さらに半角スペースと改行を取り除きます。

replaceChars(value, " \n", "")
4.2.3 電話等の対応可(初診)
まずどんな値が使われているかを見るために ファセット>テキストファセット と選びます。

左サイドにファセットが現れ、表記揺れが結構あることが分かります。3段階で対応します。
4.2.3.1 ◯△×記号を揃える
まずはファセットで「カウント」順に並べ、スクロールしながら記号をいちばん数の多いものに揃えます。
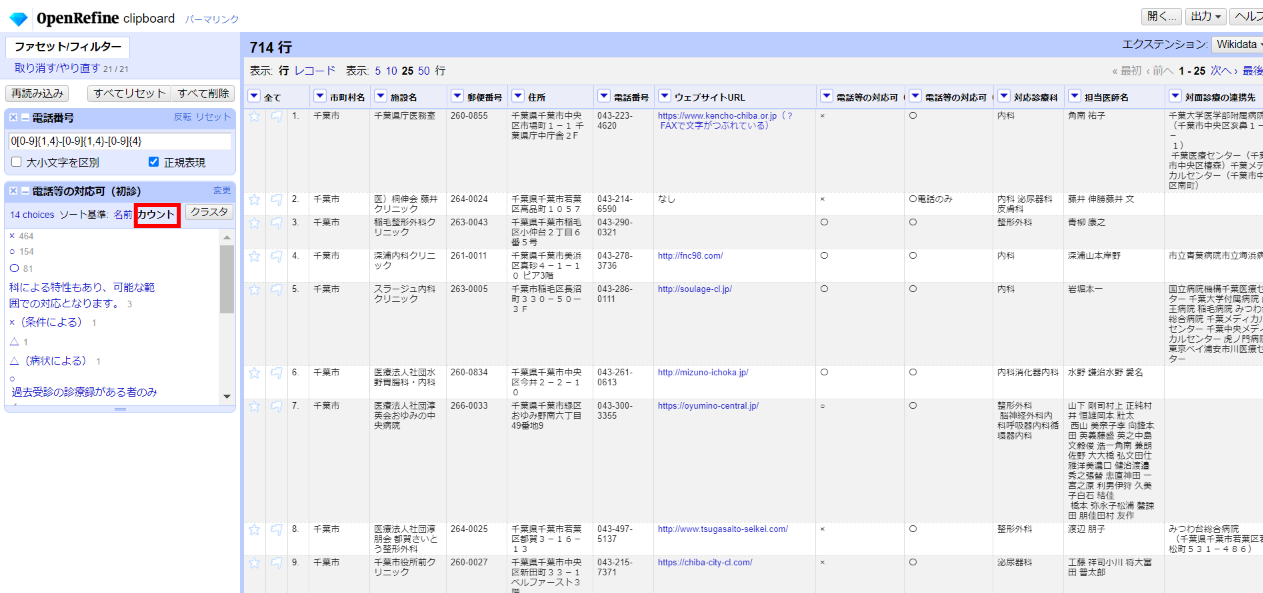
ファセット内で修正する値の上にマウスカーソルを当ててクリックして

内容を書き換えて「適用」します。記号の後ろに付加されている条件文はひとまずそのまま残します。
4.2.3.2 ◯△×の意味付けを揃える
◯であっても条件付きのものは△に書き換える、空白は×など、意味を揃えます。

4.2.3.3 記号と条件欄を分割する
1桁目(記号)と2桁目以降(条件)でカラムを分けます。
カラム編集>複数のカラムに分割

「◯フィールド長で」を選び、「1,50」と入れて「OK」

記号と条件の2つのカラムに分割されました。

4.2.4 電話等の対応可(再診)
上記初診と同じように処理します。

4.2.5 対応診療科
可変繰り返し項目は扱いが面倒ですが、ここではセル内で診療科ごとに改行して列挙することにします。
4.2.5.1 値の確認
まずどんな値が使われているかを見るために 「▼対応診療科」 で▼をクリックして ファセット>テキストファセット を選びます。
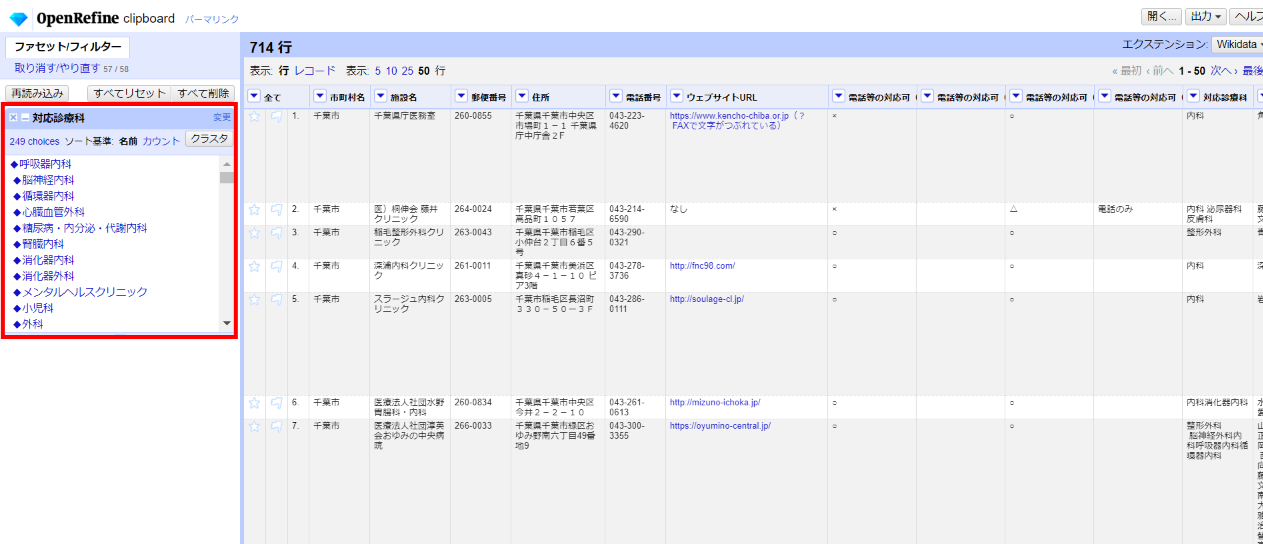
ざっと見ると区切り文字や改行がバラバラです。

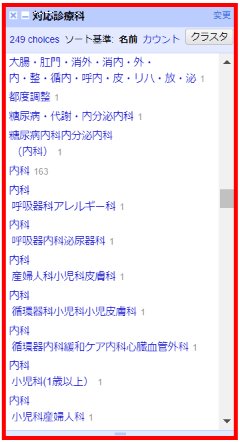
「科」という文字を区切り文字として改行で列挙する方針とします。
ただし、「小児科(1歳以上)」のように「科」で区切ってはいけない表現があるため、括弧の有無でフィルターを掛けて、編集操作を分けることにします。
4.2.5.2 ()表記を取り扱う
全角・半角の丸括弧でフィルターを掛けます。
「▼対応診療科」 で▼をクリックして テキストフィルター を選びます。

[()\(\)]
7件見つかりました。これらは後から手動で編集することにして「反転」でそれ以外の行を選びます。

4.2.5.3 区切り文字などの削除
見出し文字「◆」や区切り文字「・」「/」改行コードなどを削除します。
「▼対応診療科」 で▼をクリックして セル編集>変換 を選びます。
replaceChars(value, "◆、 ・・\/\n", "")

左サイドの対応診療科ファセットで値をブラウズすると、問題なさそうです。
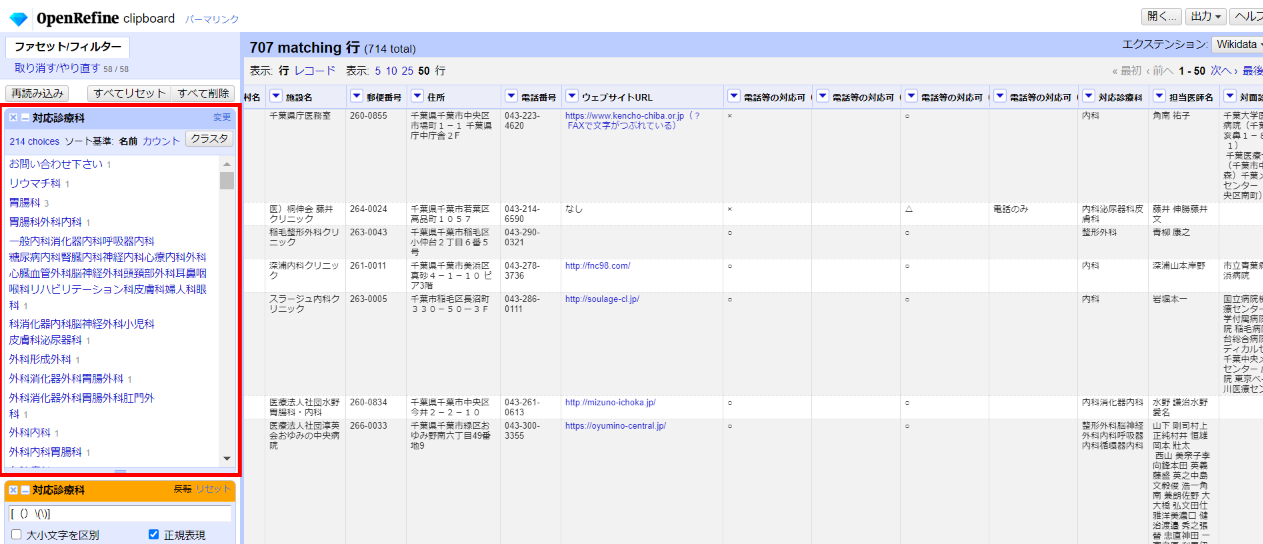
4.2.5.4 改行
「科」の後ろに改行を付加します。
「▼対応診療科」 で▼をクリックして セル編集>変換 を選びます。

replace(value,"科","科\n")

4.2.5.5 ()のある行を手修正
左サイドの全角・半角の丸括弧フィルターを「反転」で元に戻します。

こちらの7件についてファセット内で直接値を整えます。

対応診療科のクレンジングが終わりました。
4.2.6 担当医師名
区切り方がバラバラの人名をデータベースなどを無しに機械的に整形するのは至難の技なのでこのままにします。
4.2.7 対面診療の提携先
頑張って改行を揃えたとしてもクレンジング効果が薄そうなのでメモ的なものとしてこのままとします。
4.2.8 ウェブサイトURL
4.2.8.1 正規表現でチェック
「▼ウェブサイトURL」 で▼をクリックして テキストフィルター を選びます。
左サイドのウェブサイトURLフィルターで下記を入力して「□正規表現」をチェックします。
^(http|https)://([\da-z\._-]+\.[a-z\.]{2,6}|[\d\.]+)([\/:?=&#]{1}[\da-z\.~_-]+)*[\/\?]?$
(改良点は多々あるかもしれません)

714件のうち453はOKのようです。
4.2.8.2 誤りを抽出
左サイドのウェブサイトURLフィルターで「反転」をクリックして「NOT」条件にします。
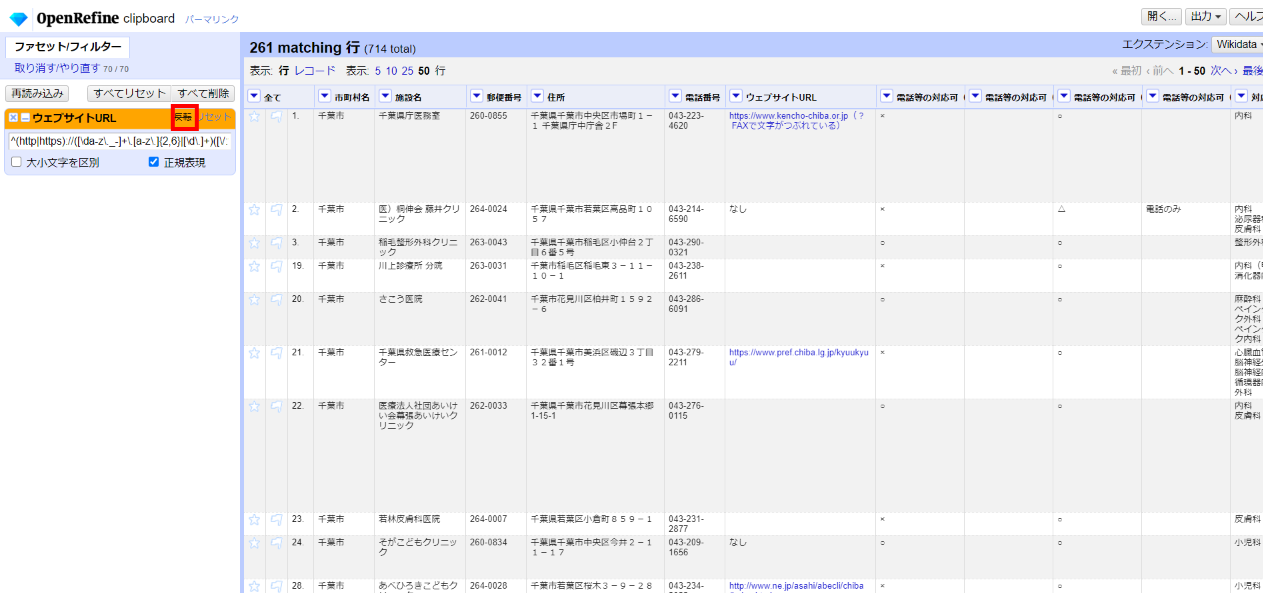
誤りが261/714あります。元々間違っているのか転記ミスなのかは分かりませんが、やはり人間系の操作が入るとバラツキが多いですね。
4.2.8.3 空欄を除外
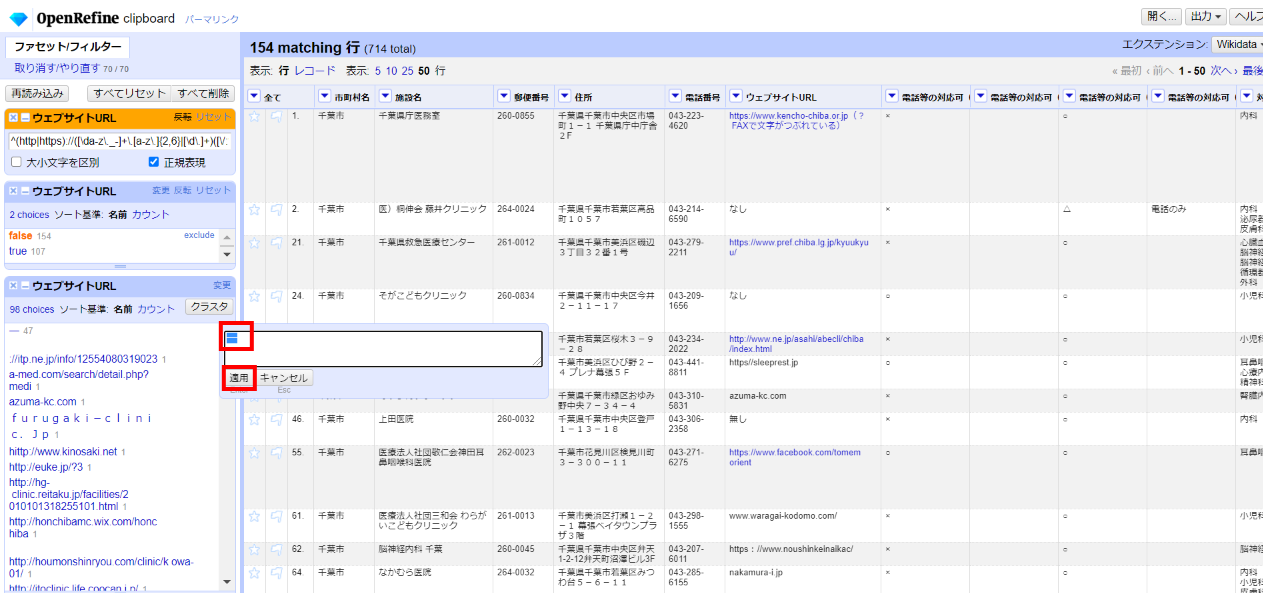
「▼ウェブサイトURL」 で▼をクリックして ファセット>カスタムファセット>空白ファセット(null/空) を選び、左サイドに表示されたウェブサイトURLファセットで「false」を選びます。

4.2.8.4 値の確認
どんな値が入っているかテキストファセットで見てみます。
「▼ウェブサイトURL」 で▼をクリックして ファセット>テキストファセット を選び、左サイドに表示されたウェブサイトURLファセットでどのような誤りがあるか眺めます。
4.2.8.5 値の修正
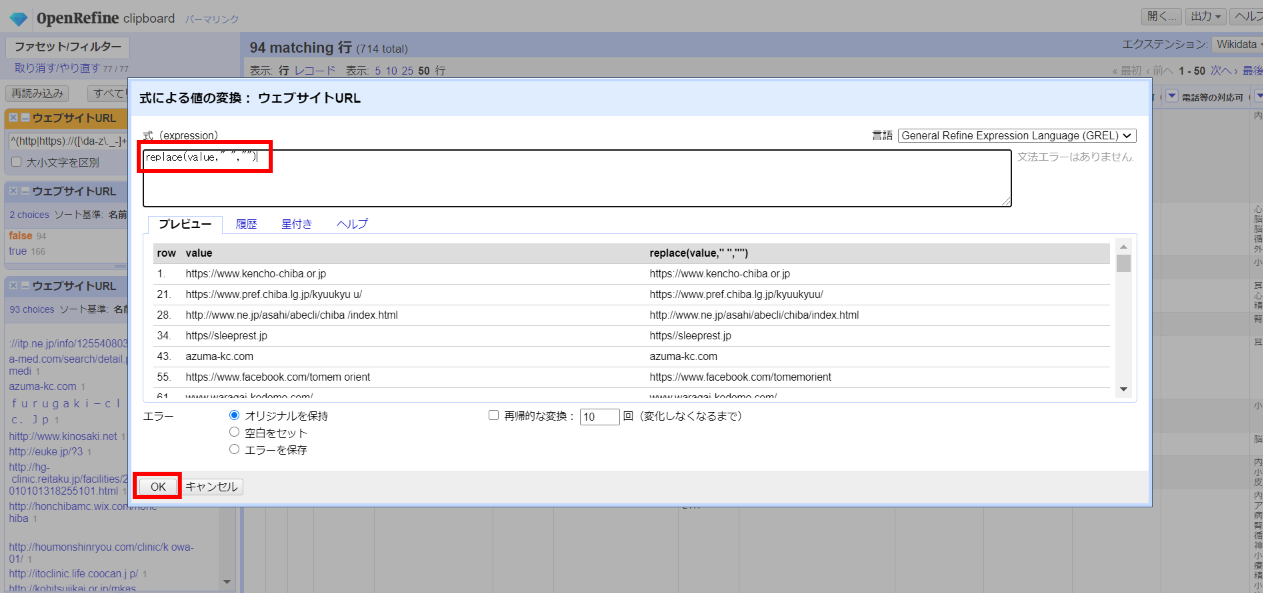
まず誤りのバリエーション数を減らしたいので日本語の「-」「なし」「無し」などを空白にします。
「▼ウェブサイトURL」 で▼をクリックして セル編集>変換 を選びURLに紛れ込んでいる半角スペースを削除します。
replace(value," ","")
先頭に「http」が無いものが結構あるのでテキストフィルターで絞り込みます。(「反転」します)
http
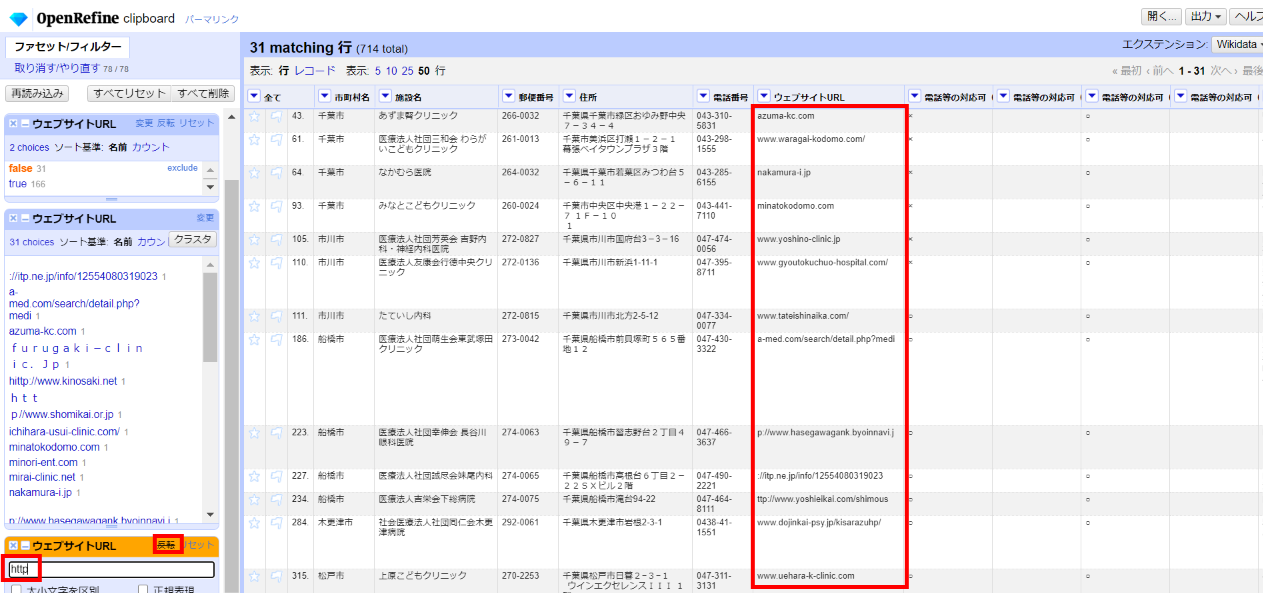
セル編集で(仮にhttps決め打ちで)
"https://"+value
のようにGREL式を記述して「OK」とすると良いと思います。
以下細々バリエーションが多く、長くなりすぎるので省略します。
4.2.8.6 リンク切れチェック
以下のようにしておおまかにリンク切れを確認することができます。
「▼ウェブサイトURL」 で▼をクリックして カラム編集>URLでカラムを追加 を選びます。
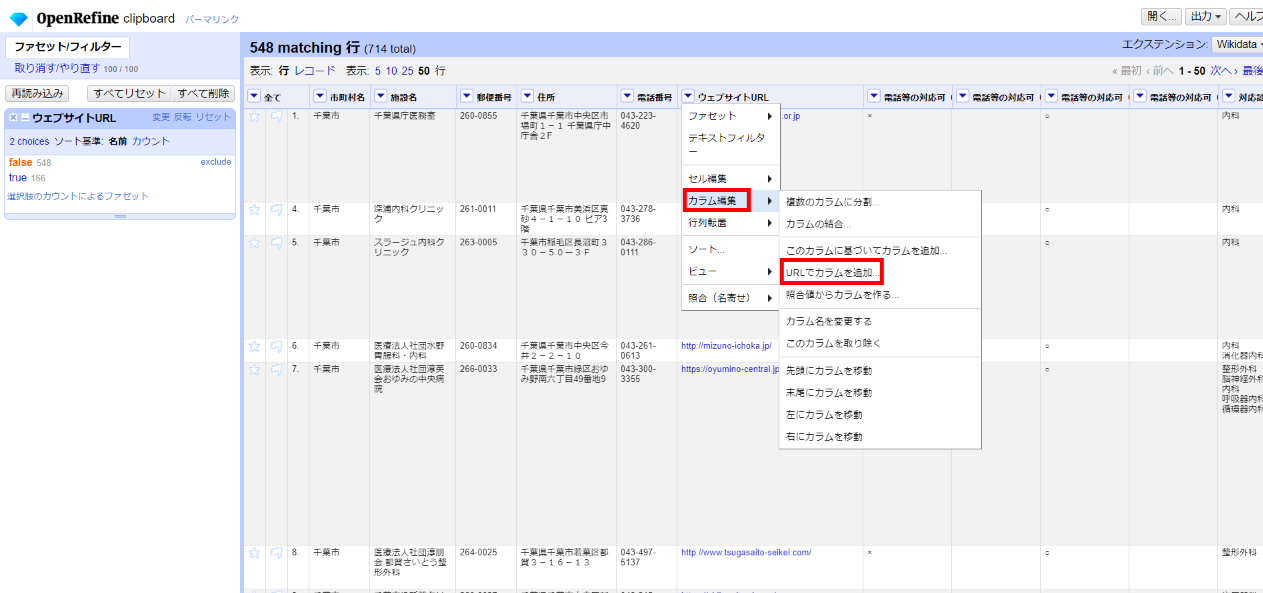
カラム名:応答
フェッチ間隔の遅延:5000
エラー:空白をセット
式:value

以上を設定して「OK」で実行すると、単純に各行のURLからレスポンスを受け取ります。空白であればリンク切れと判断できます。
しかしながら、リンク切れチェックのために数百件のリクエストを送ってレスポンスをまるごと溜め込むことはあまりコストバランスが良くないと思われるので実行は控えておきます。より効率的なやり方があるかもしれません。実際は専用の外部サービスなどで行うのが良いのではないかと思います。
5 最後に
既に有志の方が公開されたCSVがあるのでここでの作業自体に実用性はありませんが、OpenRefineによる生データのクレンジング操作法の例としてお読みください。
今回もずいぶん長くなってしまいましたのでいったんここで区切りとします。まだ「市町村名」「病院名」「住所」が残っており、次回はこれらのカラムに対する名寄せ、照合、エンリッチメントといった作業を中心に書く予定です。余力があればその次はTabulaを。。