手元のデータをWikidataのデータと照合させたいとき、すなわち、手元のデータをWikidataと関連付けてリンクを張りたいときに便利なツールとしてOpenRefineがあります。本記事を執筆している時点でバージョン2.7が公開されており、Windows、Mac OS、Linux向けにそれぞれ実行ファイルが配布されています。OpenRefineの使い方は統合TVで紹介されていますので、そちらをご覧ください。
ここでは、このOpenRefineの提供する照合機能(Reconciliation、以下、照合機能)を用いて、Wikidataのデータと照合する方法を紹介します。OpenRefine開発陣によりGitHubで公開されている英語の文書を基にしています。なお、バージョン2.8から「照合したデータベースから値を取得する」作業がしやすくなり、本家の説明も更新されていますので、本記事も合わせて更新しました(2018年5月17日)。
OpenRefineはバージョン2.7からインターフェースの言語設定を切り替えられるようになったので、本記事では日本語のインターフェースを対象とした説明をしますが、初期設定では英語に設定されているので、日本語に切り替えましょう。その方法は次のとおりです。
- トップページの左側に表示されているメニューのうち、「Language Settings」をクリックします。
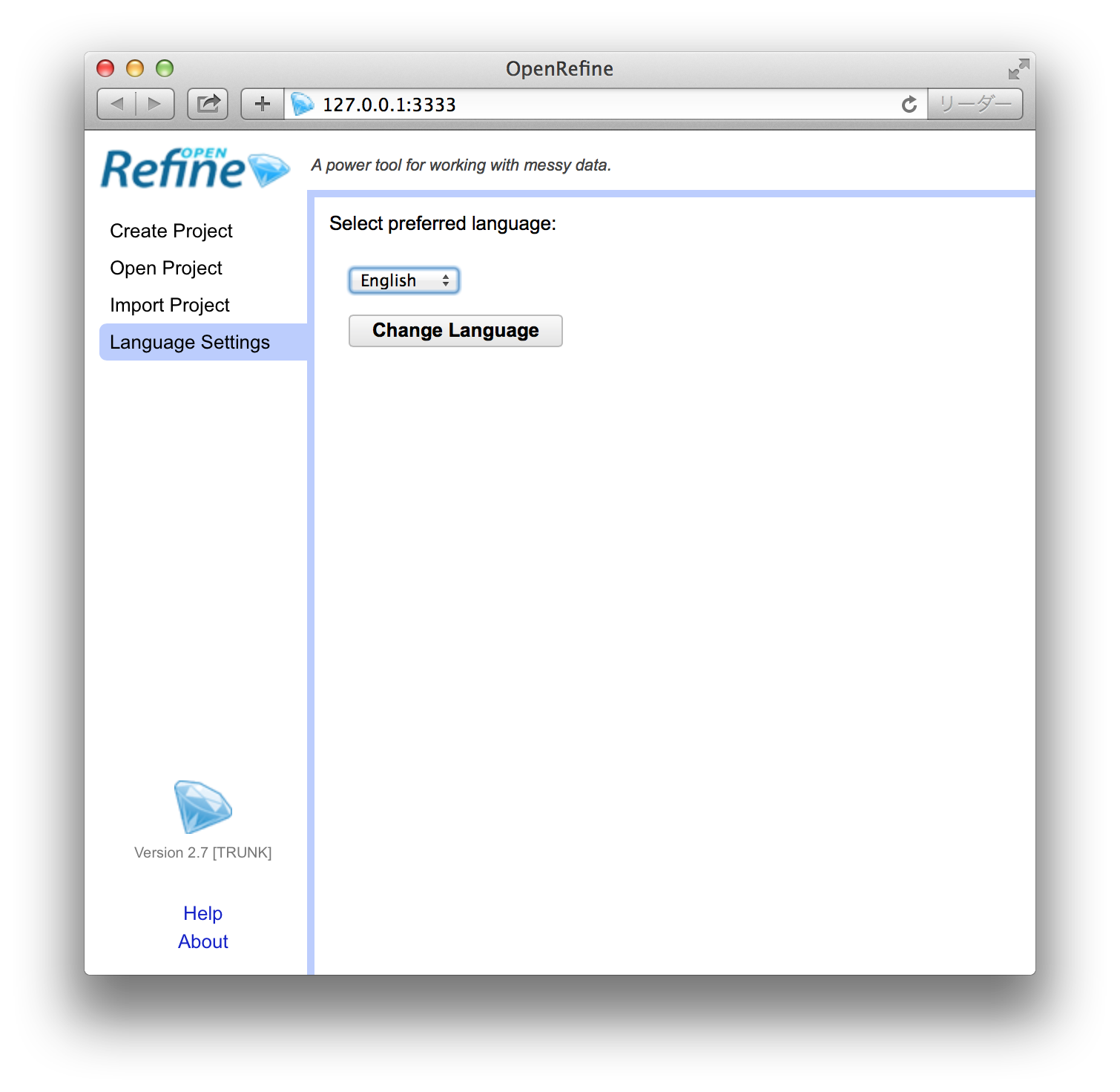
- 「English」と表示されているセレクタを「日本語」にしてから、「Change Language」をクリックします。
なお、日本語インターフェースではReconsiliationを「名寄せ」と表示しますので、OpenRefineの具体的な操作手順で表示内容に触れる場合には「名寄せ」と記述しますが、OpenRefineのReconciliationの機能としては「照合」の方が適切と感じられるので、原則として本記事では照合を使います。
照合機能はテキストを半自動的にデータベースのID、もしくはキーとマッチさせます。機械による全自動ではマッチが不十分なことがあり、そのさいには人手を必要とするので、半自動的になります。たとえば、「Ocean's Eleven」という映画のタイトルに対しては、次のいずれかにマッチさせることになります。
- 1960年に公開された元タイトル(Wikidata項目Q464933)
- 2001年にリメイクされた、ジョージクルーニーが主役を演じるタイトル(Wikidata項目Q205447)
ここで「データベース」と呼ぶものは、より正確には「名称レジストリ」と呼んだ方が良いかもしれません。そして、「照合」は目新しい概念ではなく、常にそれが行われている分野もあります。たとえば警察が容疑者の名前を入手したさいには犯罪者データベースを当該名前で検索することでしょう。より詳細が分かれば容疑者の特定につながるかもしれません。
OpenRefineを用いることで、手持ちのデータに含まれる様々な名称を、Reconciliation Service APIの仕様に従うウェブサービスを提供しているデータベースに対して照合できます。そして、Wikidataはそのようなウェブサービスを提供しているデータベースです。
基本
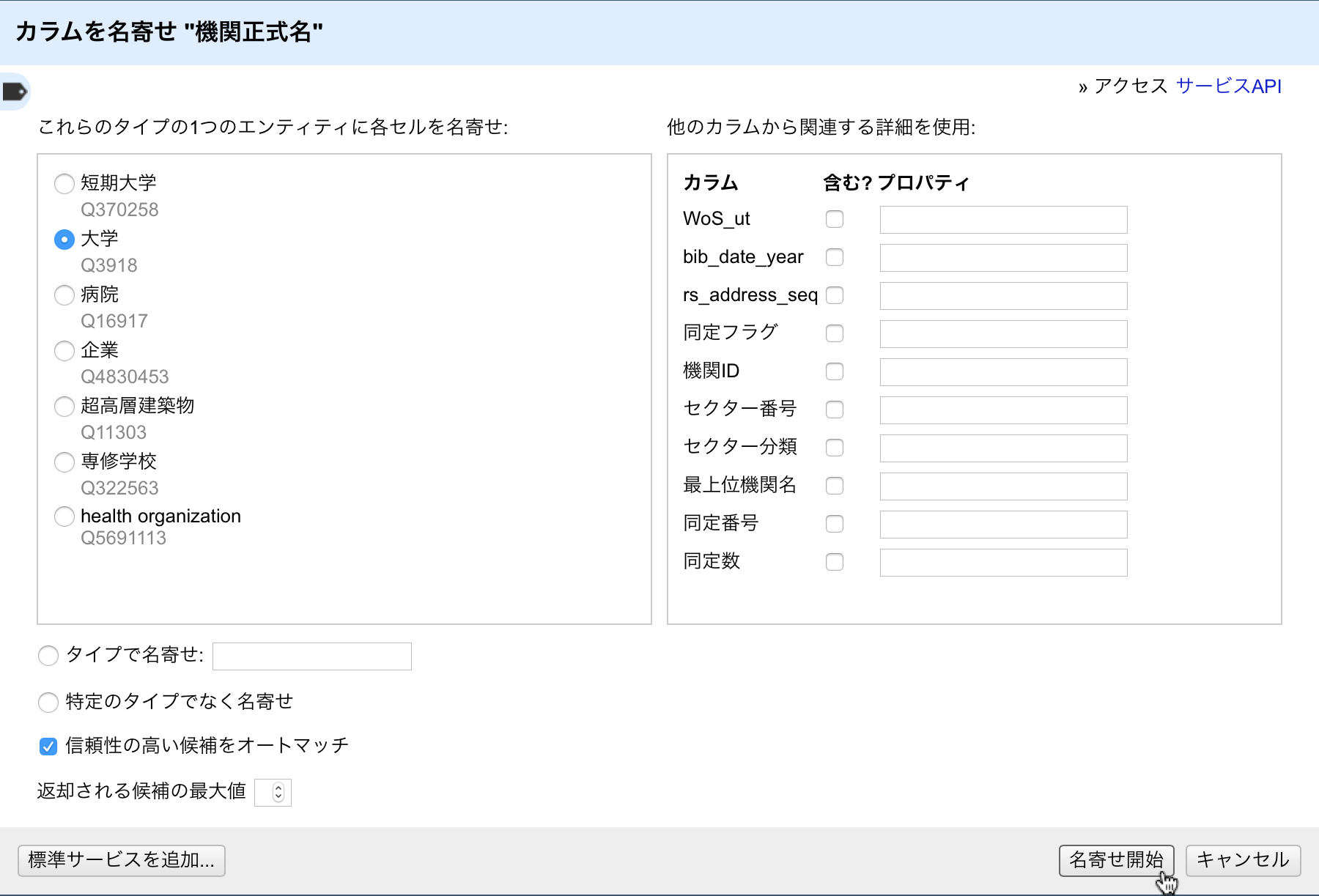
OpenRefineで照合を行うには、列名の左側にあるアイコンをクリックして表示されるドロップダウンメニューから、「名寄せ」→「名寄せ開始...」の順に選択します。なお、この章で例示しているデータは科学技術・学術政策研究所(NISTEP)が公開している「WoSCC-NISTEP大学・公的機関名辞書対応テーブル(ver.2017.1)
」の一部です。

対象になる列の一部のセルに対してだけ照合させたい場合は予めテキストフィルターやファセットを利用して絞っておきます。
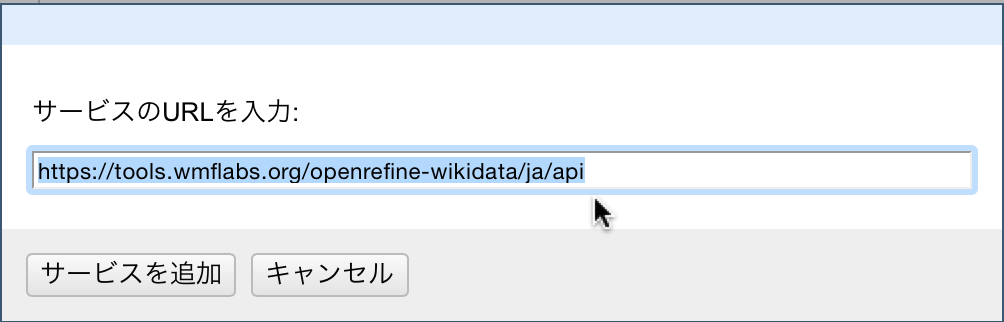
続いて「名寄せ」ダイアログボックスの「サービス」エリアに「Wikidata Reconciliation for OpenRefine (ja)」が表示されていればそれを選択しますが、初めて本機能を使う場合には見つからないでしょう。その場合には、当該ダイアログボックス下部にある「標準サービスを追加」をクリックします。ここで「サービスのURLを入力」と書かれたポップアップウィンドウが現れるので、ここに「https://tools.wmflabs.org/openrefine-wikidata/ja/api」を入力します。

より信頼性のある照合結果が得られるように、照合処理をするためのオプションが幾つか用意されています。これらは次の章以降で説明します。ダイアログボックス下部右側にある「名寄せ開始」ボタンをクリックすることで照合処理が始まります。照合対象となるデータのサイズに依存しますが、それなりの時間がかかります。現在、Wikidata照合サービスは一秒当たり大体3行処理します。処理が終わると結果が各セル内に表示されますが、問題なくマッチした場合と、幾つかの候補が表示される場合があります。
・問題なくマッチした場合は、紺色のリンクが一つだけ表示されます。この場合は処理結果の正確性が高く、人手で改めて確認作業をする必要はありません

・候補が幾つか表示された場合は、それぞれの照合度スコアが、淡青のリンクと共に表示されます。この場合は、候補の中から人手で適切なものを一つ選択する必要があります。選択するに当たり、その結果の適用方法を決めることができます。一つは、現在選択を行うセルにだけ選択結果を適用させるものであり、もう一つは、同じ名称が含まれる他の全てのセルに対しても同じ選択結果を適用させるものです。それぞれ、選択用のチェックボックス風のアイコンにマウスオーバーすると表示されるツールチップに「このトピックをこのセルにマッチ」、「このトピックを一致するすべてのセルにマッチ」と表示されます。
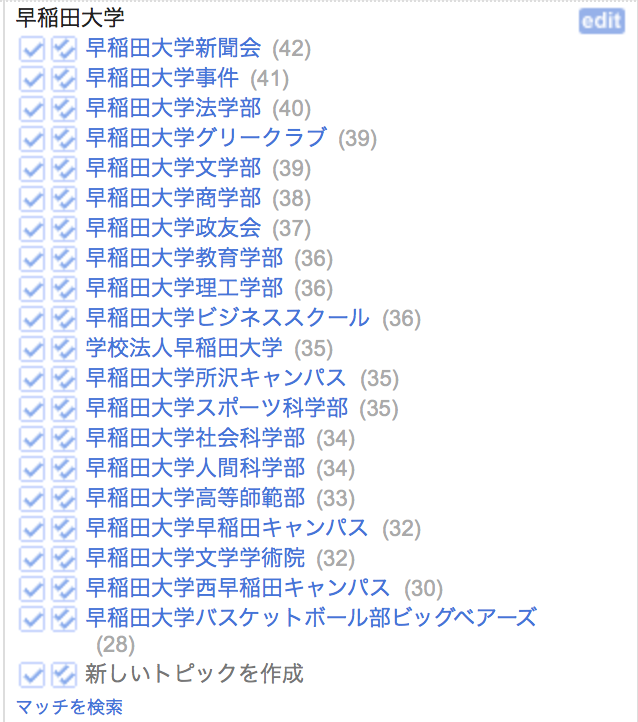
照合されたセルの表示方法が変化することにくわえ、OpenRefineは二つのファセットを自動的に生成します。「judgement」と「best candidate's score」です。これにより、照合結果に基づいてセルをふるい分けられるようになります。マッチスコアが高い場合はそれだけ良いマッチが行われたことを意味するので、高スコアのセルだけを対象として、それらをすべて一括して承認することができます。具体的には、対象の列名の左側にあるアイコンをクリックして表示されるドロップダウンメニューから、「名寄せ」→「Actions」の順に選択します。
「judgement」ファセットを利用することで、マッチできなかったセルだけを表示させることができます。具体的には、当該ファセットで「none」をクリックします。表示されているセルに対して上述の選択処理を行うと、当該セルは「none」から「matched」に数えられることになるので、表示されなくなります。
型でマッチを制限する
より良い照合結果を簡単に得るために、ある特定の型に照合対象を制限する方法があります。照合対象のデータが大学名であれば、「東京」は東京大学(Q7842)であるし、駅名であれば東京駅(Q283196)という具合です。
Wikidataでは型も項目の一つであり、東京駅(Q283196)は鉄道駅(Q55488)型を持つことが、分類(P31)プロパティを用いて記述されています。型はオントロジーの中で位置づけされ、上位クラス(P279)プロパティを用いて型と型の間の関係が定義されています。例えば、鉄道駅(Q55488)の上位クラスは駅(Q719456)になります。ある型のクラス関係を可視化したいときに便利なのが、Wikidata Graph Builderです。例えば、駅(Q719456)の下位のクラス一覧を可視化できます。

名寄せダイアログでは型を指定することでき、指定したクラスおよびその下位クラスに含まれる項目にマッチ対象を制限できます。たとえば、駅(Q719456)を指定すれば、東京駅(Q283196)がマッチ可能になります。初期設定の状態でOpenRefineは与えられたデータの最初のいくつかをみて型を複数提案しますが、提案されたクラスは下位すぎることが多いことから、より上位のクラスを指定することで、より多くの項目をマッチ対象にできます。
Wikidataの項目にはどのクラスにも属していないものがあり、照合時にある特定のクラスを指定した場合にはそれらの項目は結果に含まれません。ただし、照合対象として指定したクラスに含まれる項目が何も見つからなかった場合には、どのクラスにも属していない項目がマッチすることがあります。それでもマッチスコアは低く、自動的にマッチすることはありません。
プロパティを用いて改善する
一般的に名称データは曖昧であることが多いですが、他の列の値をみることで適切な項目を特定できるかもしれません。照合用のインターフェースではそれらの列を考慮してマッチスコアに反映させる設定ができます。例えば、スポーツ選手名を第一列に、プレイするスポーツを第二列に含むデータセットがあったとします。
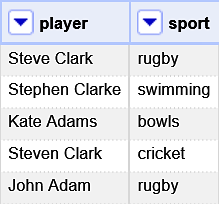
第二列の値をこの目的に利用する場合には、これらの値がWikidataにおいてどのように表現されているのかを知る必要があります。すなわち、スポーツ選手とプレイするスポーツを結び付けているWikidataのプロパティを知る必要があります。ウサイン・ボルト(Q1189)選手についての項目を見ると、スポーツプロパティ(P641)が該当することが分かります。
名寄せダイアログの「他のカラムから関連する詳細を使用」と表示されているエリアで、対象となる列名(カラム)の右隣にあるチェックボックスをチェックし、さらに右隣にある入力ボックスに具体的なWikidataプロパティ名を入力します。
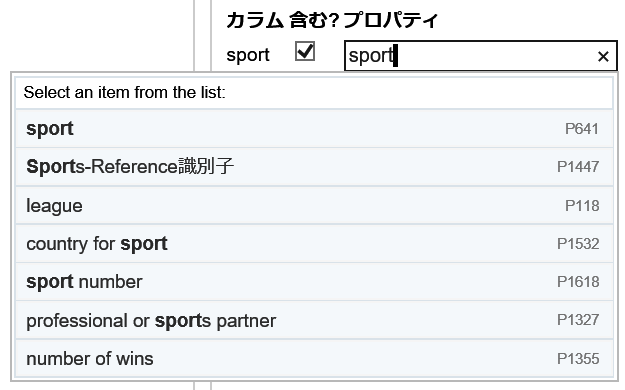
照合処理は双方の列の値に対してファジーマッチを行います。
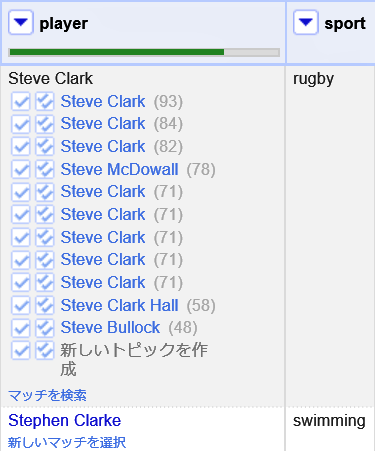
結果としてスポーツプロパティによるマッチがなされた項目についてはマッチスコアが高くなることが確認できます。
プロパティパスを用いる(上級編)
本機能はWikidataに対する照合インターフェースに特徴的なものです
照合対象の列の値と、曖昧性を解消させるための列の値が直接的でない場合があります。すなわち、両者の間を結ぶプロパティがない場合です。例えば以下のように都市に関するデータを考えてみましょう。
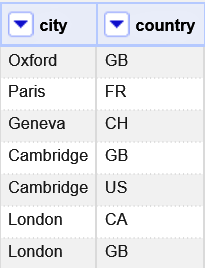
各都市名から対応する国コードを取得するには二つのプロパティを経由する必要があります。
最初に、国(P17)を辿ることで当該都市がある国に対する項目を取得し、続いて国名コード(ISO 3166-1 alpha-2)(P297)を辿ることで2文字の国名コードを示す文字列を取得します。

このような場合に対処するために、SPARQLのプロパティパスの考えからヒントを得て考案された設定方法があります。すなわち、照合インターフェースで、P17/P297のように、プロパティIDを順にスラッシュで区切りながら記述していくものです。
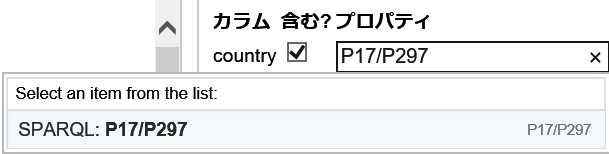
この追加的な情報を用いることで同名問題をある程度は解消できるようになります。「Cambridge, US」は依然として曖昧なので、完全マッチスコアをもつ複数の項目があります。しかし、「Oxford, GB」はうまく曖昧性が解消されていることが分かります。

現在、エンドポイントでは/と|の2種類のプロパティ組み合わせ方法が提供されています。すなわち、前者は上述した通り、二つのパスを結合させ、後者は、両者のパスで得られる値の和集合を取得します。パスの結合を示すスラッシュの方が、和集合を示す縦棒よりも評価順序が高くなります。ドット文字の.は空のパスを示すために利用できます。例えば、以下のプロパティパスは全て等価です。
P17|P749/P17P17|(P749/P17)(.|P749)/P17
値を比較する
初期設定ではOpenRefineから与えられた値とWikidataにある値は文字列ベースのファジーマッチで比較されます。この原則に対する例外規定として以下の項目があります。
- 値が識別子の場合は完全文字列マッチが行われます。
- 値が整数値の場合は整数値同士の同値判定が行われます。
- 値が浮動小数点値の場合は、両者が同値の場合を100とし、両者の差の絶対値が大きくなるに従い0になるようなスコアになります。
- 値が位置情報(OpenRefineにおいては
"lat,lang"形式で特定されます)の場合は、両者が同値の場合を100とし、両者が離れるのに従い0になるようなスコアになります。現状では両者の間が1Kmを超えると0になります。
また、プロパティパスの最後に修飾子を追加することで、値の一部分にマッチさせられます。
-
@latと@lng: 緯度と経度(浮動小数) -
@year、@month、@day、@hour、@minute、@second: 日時の一部(整数)。Wikidataの値が適切な時のみ得られます。 -
@isodate: ISO形式(1987-08-23)で日にちを取得します(文字列)。常に値が得られます。 -
@iso: IOS形式(1996-03-17T04:15:00+00:00)で日時を取得します。値はUTC時間で常に得られます。 -
@urlscheme ("https")、@netloc ("www.wikidata.org")、@urlpath ("/wiki/Q42"): これらはそれぞれURLの該当部分を取得するのに使います。
たとえば、誕生日で人に関するデータを処理したいけれども、データとしては月と日しかない場合は、最初に月と日、それぞれの列を用意します。続いて、「他のカラムから関連する詳細を使用」において、各列につき、それぞれ、SPARQL:P569@month、SPARQL:P569@dayとして照合を開始します。
ユニークな識別子を用いて照合する
Wikidataには多くの外部のユニークな識別子を含んでいます。もし照合しようとしているデータにこのような識別子が含まれているなら、それは正確な照合を行うために非常に有益です。ユニークな識別子に対応するWikidataプロパティを指定することで、照合方法を変えることができるからです。最初に当該識別子を持つWikidataの項目を取得し、それに対して完全一致スコア(100)を与えます。他の全てのプロパティは考慮されませんし、照合しようとしている列の値をも同様に無視されます。もしも対応する項目が見つからない場合には、従来のマッチ方法に戻って処理します。
注意点1: 異なる複数のWikidata項目に、同一のユニークな識別子が割り当てられているときがあります。このような場合には、Wikidataのユニーク性の制限に違反することになるので、衝突としてWikidata側で判断されます。得られる結果は複数の項目が含まれることになりますが、自動的なマッチは行われません。
注意点2: 照合しようとしているデータには、Wikidataで表現されているユニークな識別子と全く同一のものを収めておく必要があります。識別子のマッチは厳格な文字列同値性で判断されます。大文字・小文字の違いや空白、冒頭のゼロなどもマッチ対象になります。詳細は関連するWikidataプロパティに関する文書を参照してください。
なお、このマッチ方法は、照合しようとしている列に含まれている識別子に対してだけ行われます。例えば、国名コード(ISO 3166-1 alpha-2)(P297)は国を識別するための識別子ですが、上記の例で示したP17/P297のようなプロパティパスを利用する場合ではユニークな識別子としては使われません。
一方で、ユニークな識別子の和集合は問題ありません。たとえば、DOIや、CiteCeerX IDを含む列がある場合を考えます。両者の間に表記上の曖昧性が互いに無いことを確認できれば、(P356|P3784)として表現されるプロパティ値との照合処理が行われます。各行について、DOIもしくはCiteCeerXにマッチさせるとともに、その他の値を無視します。
照合したデータベースから値を取得する
あるデータセットを既存のデータベースと照合する理由として、特定のデータを当該データベースから取得してOpenRefineに流し込むことが考えられます。それには基本的に二つの方法があります。
- 使用する照合サービスがデータ拡張APIに対応していれば、OpenRefineの「Add columns from reconciled values」機能が利用できます。なお、OpenRefineの言語設定を日本語にしている場合、バージョン2.8においては下図の通り「undefined」と表示されてしまうので、本機能を利用する場合は言語設定を英語にします。
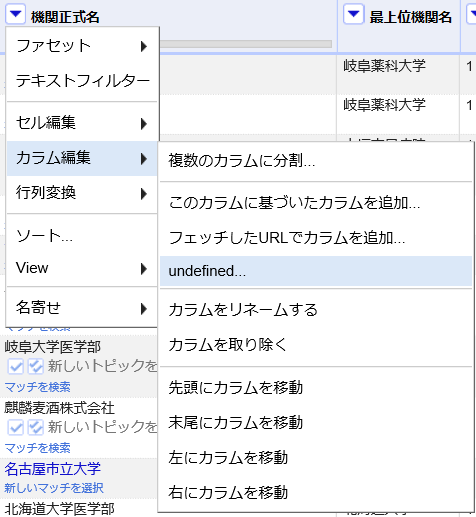
言語設定を英語にすると下図の様になり、作業を進めることができます。

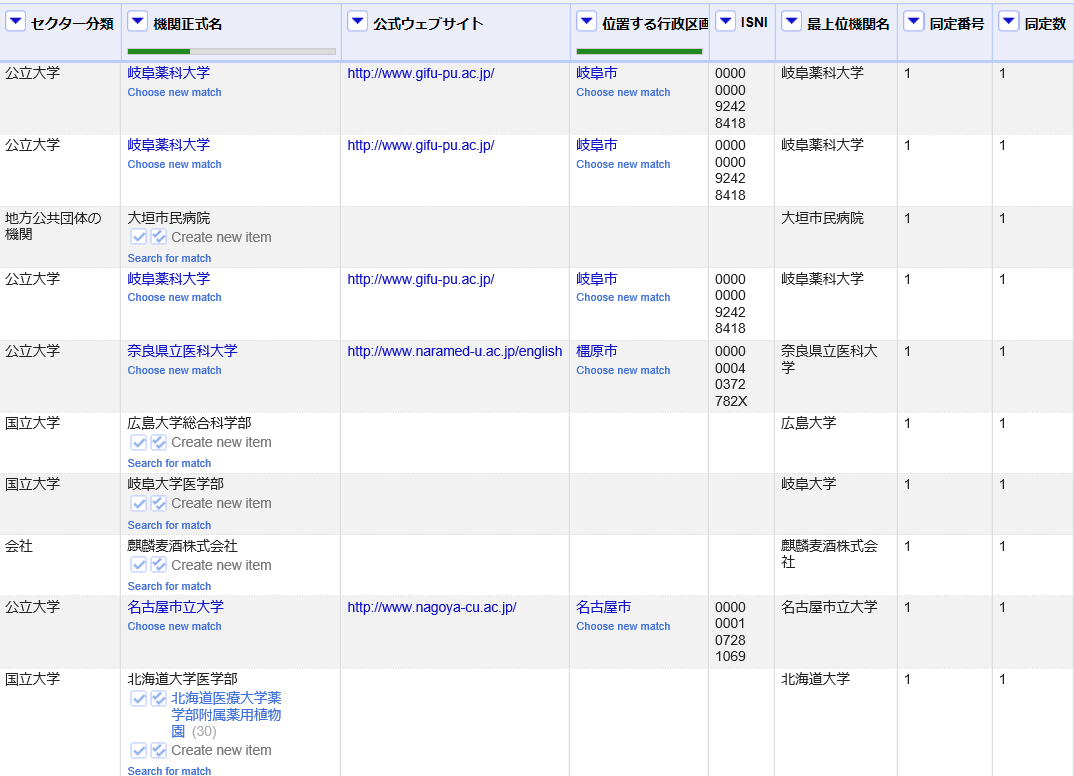
ここでは「機関正式名」と表示されているカラム名の左側の逆三角形(▼)のアイコンをクリックして現れるプルダウンメニューのうち、「Add columns from reconciled values...」を選択すると、追加するカラムに流し込むデータのプロパティを選ぶウィンドウが現れます。適宜、左側にある「Suggested Properties」から所望のプロパティを選ぶか、リストにない場合は直接「Add Property」に記入します。
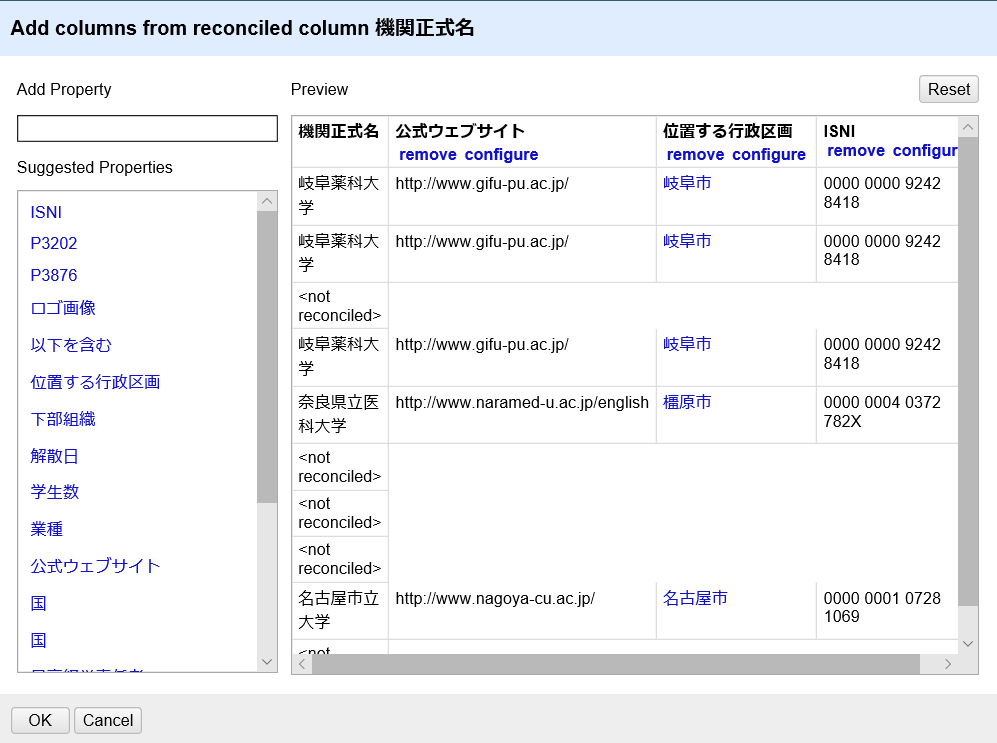
そして左下にある「OK」ボタンをクリックすると処理がなされ、結果として下図のように、設定したプロパティ値が入力されたカラムが追加されます。
- 照合サービスが対応していない場合には、一般的なウェブAPIが提供されていないか調べます。提供されていれば、「フェッチしたURLでカラムを追加」を利用し、照合で利用したIDを用いて当該ウェブAPIを呼び出します。たとえば、OpenCorporatesを利用する場合には、照合で利用した企業名に関するデータをこのAPIによりJSON形式で取得できます。GREL表現として
"https://api.opencorporates.com/companies/"+cell.recon.match.idとすることで、たとえばhttps://api.opencorporates.com/companies/17087985のようなURLに変換されるので、得られた値はOpenRefineで処理できるようになります。
提示された案をすべて保持する
照合サービスの結果で得られたベストマッチだけを残すのではなく、すべての候補を維持するには、以下のようにします。
- 照合処理を始める前に名寄せダイアログの下部にある「信頼性の高い候補をオートマッチ」のチェックを外します。
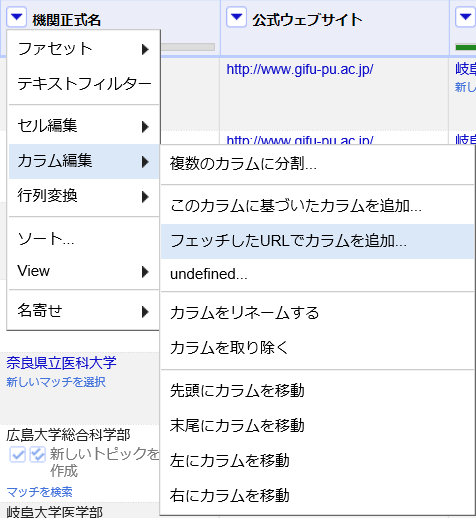
- 照合処理が終わったのちに、照合を行った列の列名部分にあるアイコンをクリックして表示されるプルダウンメニューで「カラム編集」→「このカラムに基づいたカラムを追加…」の順に選択します。
- 各候補の値が欲しい場合には、式の入力ボックスに
cell.recon.candidates[0].nameと入力します。なお、初期値としてはvalueが入力されていると思います。 - Wikidataへのリンクが欲しい場合には
cell.recon.candidates[0].idと入力します。 - 全ての候補の内部IDを列挙したい場合は
cell.recon.candidates.join(',')と入力します。必要に応じて「Split multi-valued cells」を行います。
- 各候補の値が欲しい場合には、式の入力ボックスに
言語を設定する
本記事ではWikidataの照合サービスのうち、言語設定が日本語のものを利用しましたが、ほかにも多くの言語設定が利用できます。照合サービスの言語設定を変えるには、まず、対象となる言語の2文字の言語コードを知る必要があります。そして、名寄せダイアログボックスの下部にある「標準サービスを追加」をクリックして所望のURLを追加します。フランス語の場合では言語コードがfrなので、https://tools.wmflabs.org/openrefine-wikidata/fr/apiとなります。このように、apiの直前に言語コードを含めることで照合サービスの言語を設定します。
なお、照合時には設定された言語に関わらず文字列マッチを行うので、照合結果には影響を及ぼしません。言語設定を切り替える目的は、項目名やプロパティ名が当該言語に翻訳されている場合は、それを表示させることにあります。